
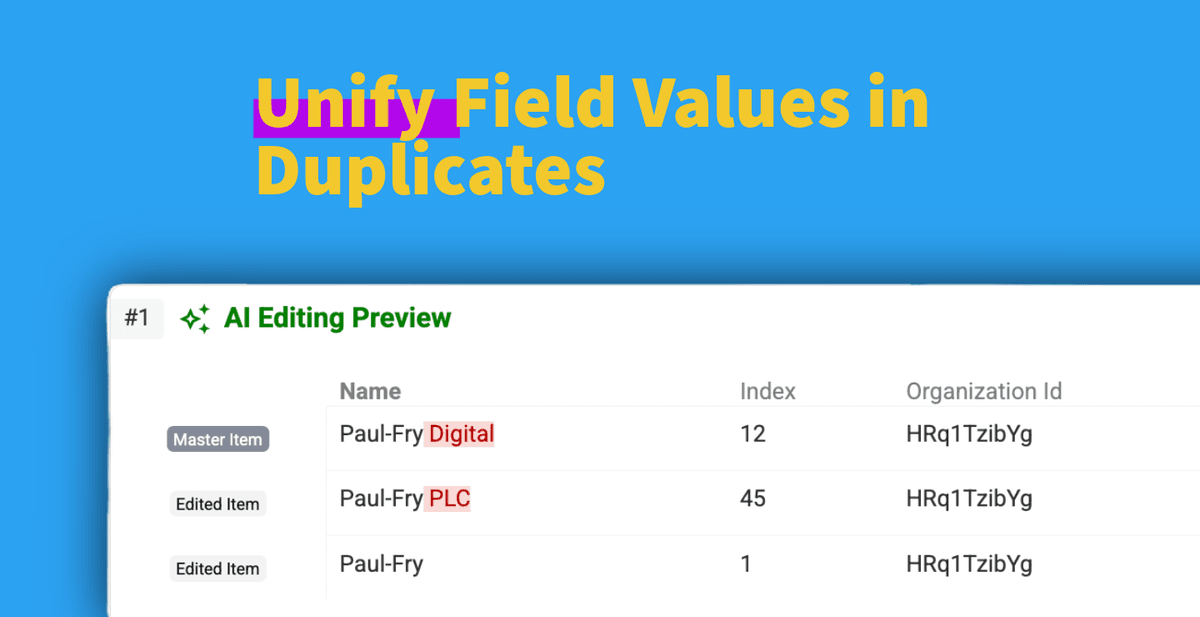
Gestire record duplicati nei tuoi dataset è un classico grattacapo. Trovare i duplicati è solo il primo passo; ripulirli spesso è l’altra metà della sfida.
A volte non vuoi ancora fare un merge completo dei duplicati.
Potresti avere la stessa azienda con nomi leggermente diversi ("Innovate Corp", "Innovate Corporation", "Innovate Corp.") in più record duplicati.
E se potessi standardizzare un campo specifico, come il company name o il job title, su tutti i record dentro lo stesso gruppo di duplicati senza fare merge dei record?
In questa guida scoprirai come normalizzare i valori di un campo specifico all’interno dei gruppi di duplicati mantenendo intatti i singoli record:
- Che cos'è la normalizzazione dei dati?
- Introduzione ad AI Processing in Duplicates Finder
- Come normalizzare i dati nei duplicati (step-by-step)
Che cos'è la normalizzazione dei dati?
La normalizzazione, in questo contesto, significa portare i dati a un formato coerente. Con i duplicati, le incoerenze nascono spesso in campi specifici. Per esempio:
- Company Names: "Tech Solutions Inc.", "Tech Solutions, LLC", "Tech Solutions"
- Job Titles: "Software Engineer", "Software Dev.", "Eng., Software"
- Addresses: "123 Main St", "123 Main Street", "123 main st"
- Countries: "USA", "United States", "U.S.A."
L’obiettivo della normalizzazione è scegliere un unico valore standard (ad esempio "Tech Solutions" o "United States") e applicarlo al campo rilevante su tutti i record identificati come duplicati.
Questo rende i dati più puliti, facili da analizzare e affidabili per filtri o report, anche se i record duplicati restano separati. È un passaggio cruciale nel data cleaning.
Introduzione ad AI Processing in Duplicates Finder
Il Duplicates Finder di Datablist è già uno strumento potente per identificare record simili. Oltre alle opzioni per fare merge automatico o manuale dei duplicati, la modalità AI Processing aggiunge un livello di flessibilità in più.
Invece di regole predefinite per il merge, con AI Processing sei tu a definire la logica usando un prompt in linguaggio naturale. Puoi dire all’AI esattamente come gestire i duplicati. Questo include attività come:
- Selezionare un master record in base a criteri specifici (es. il più recente aggiornamento).
- Fare il merge solo di alcuni campi mantenendone altri separati.
- Eseguire calcoli durante il merge (come somma dei valori).
- 👉 E, cosa fondamentale per questa guida: aggiornare un campo specifico su tutti i duplicati con un unico valore normalizzato senza fare merge dei record.
Trasforma la complessità di uno script di manipolazione dati in una semplice conversazione con la nostra AI.
Come normalizzare i dati nei duplicati (step-by-step)
Vediamo come usare AI Processing per normalizzare un campo (es. Company Name) tra record duplicati.
Step 1: Prepara i dati
Per prima cosa, importa i tuoi dati in Datablist.
- Create a Collection: Clicca sul pulsante "+" nella sidebar per creare una nuova collection.
- Import Data: Importa i dati da un file CSV o Excel. Se provengono da più file, importali nella stessa collection. Datablist ti guiderà nel mapping delle colonne alle proprietà. Assicurati di importare correttamente il campo da normalizzare (es. Company Name) e i campi che userai per identificare i duplicati (es. Email, Website).

In questo dataset di esempio, vediamo già nomi azienda duplicati che andranno normalizzati.
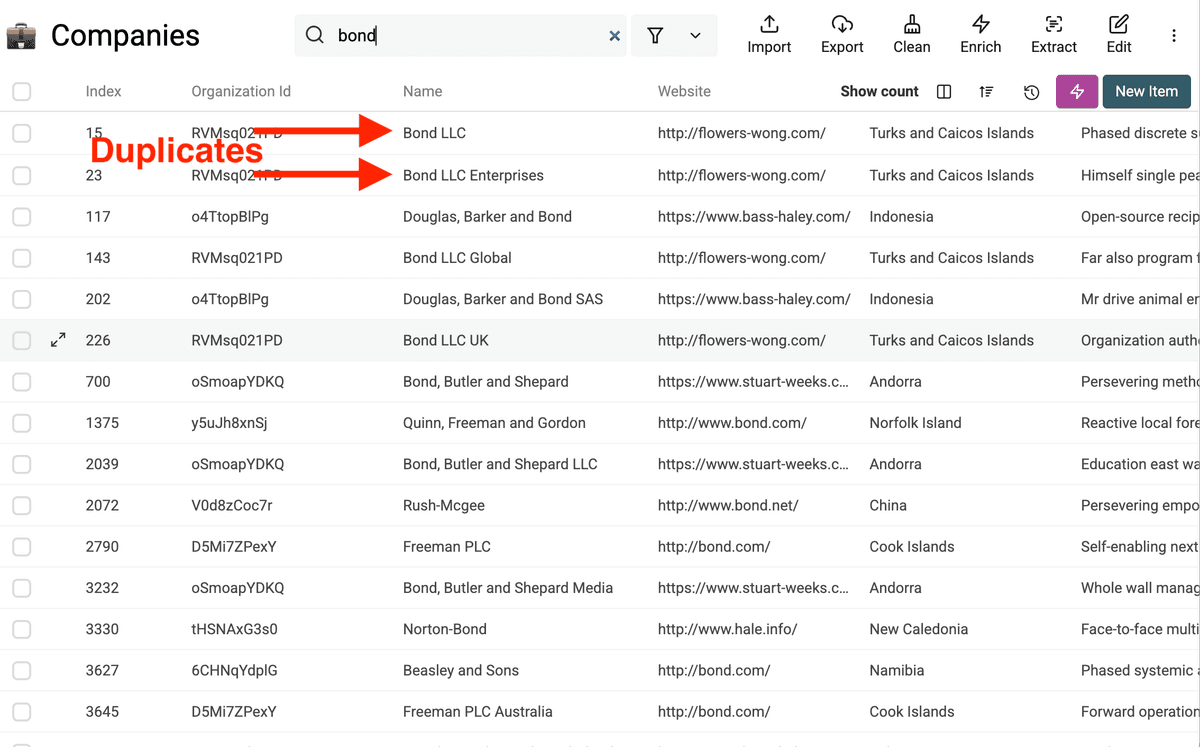
Step 2: Trova i duplicati
Ora identifica i record duplicati.
2.a Apri Duplicates Finder
Clicca su "Clean" nel menu in alto, poi seleziona "Duplicates Finder".
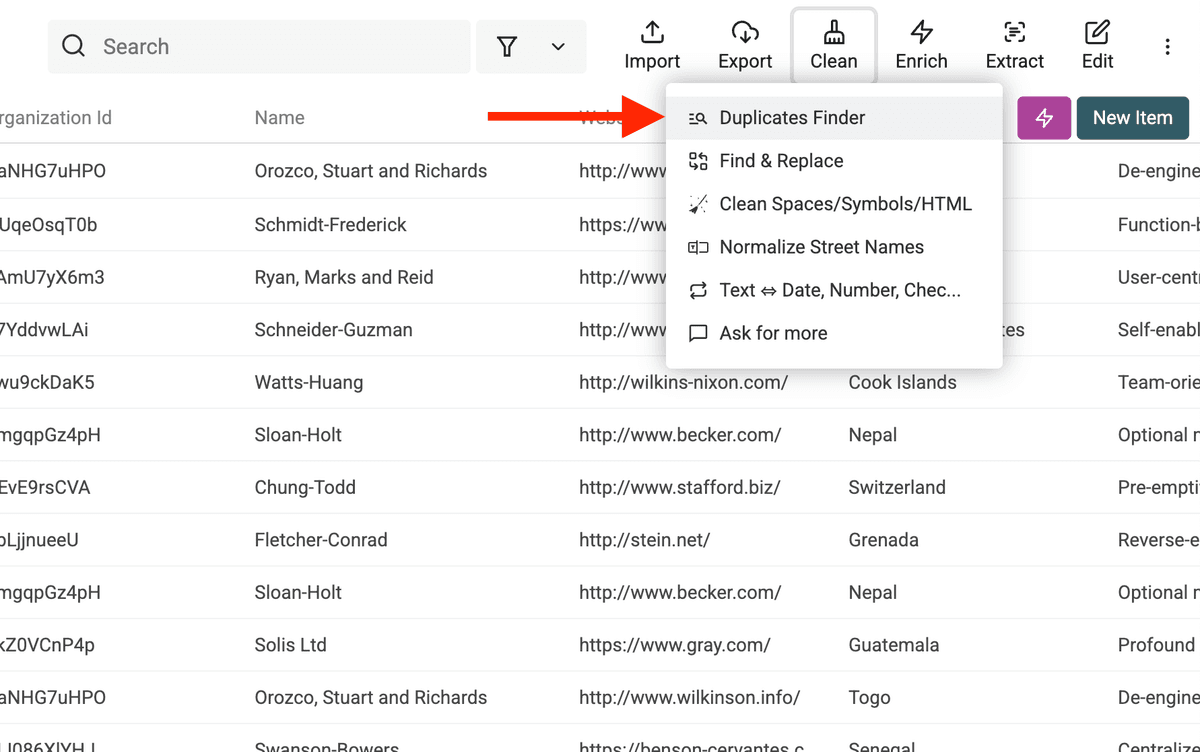
2.b Scegli gli identificatori per la deduplica
Seleziona la proprietà (o le proprietà) che identificano un duplicato in modo univoco.
Nel nostro esempio, vogliamo dedupe company names. Quindi selezioniamo il campo del nome.
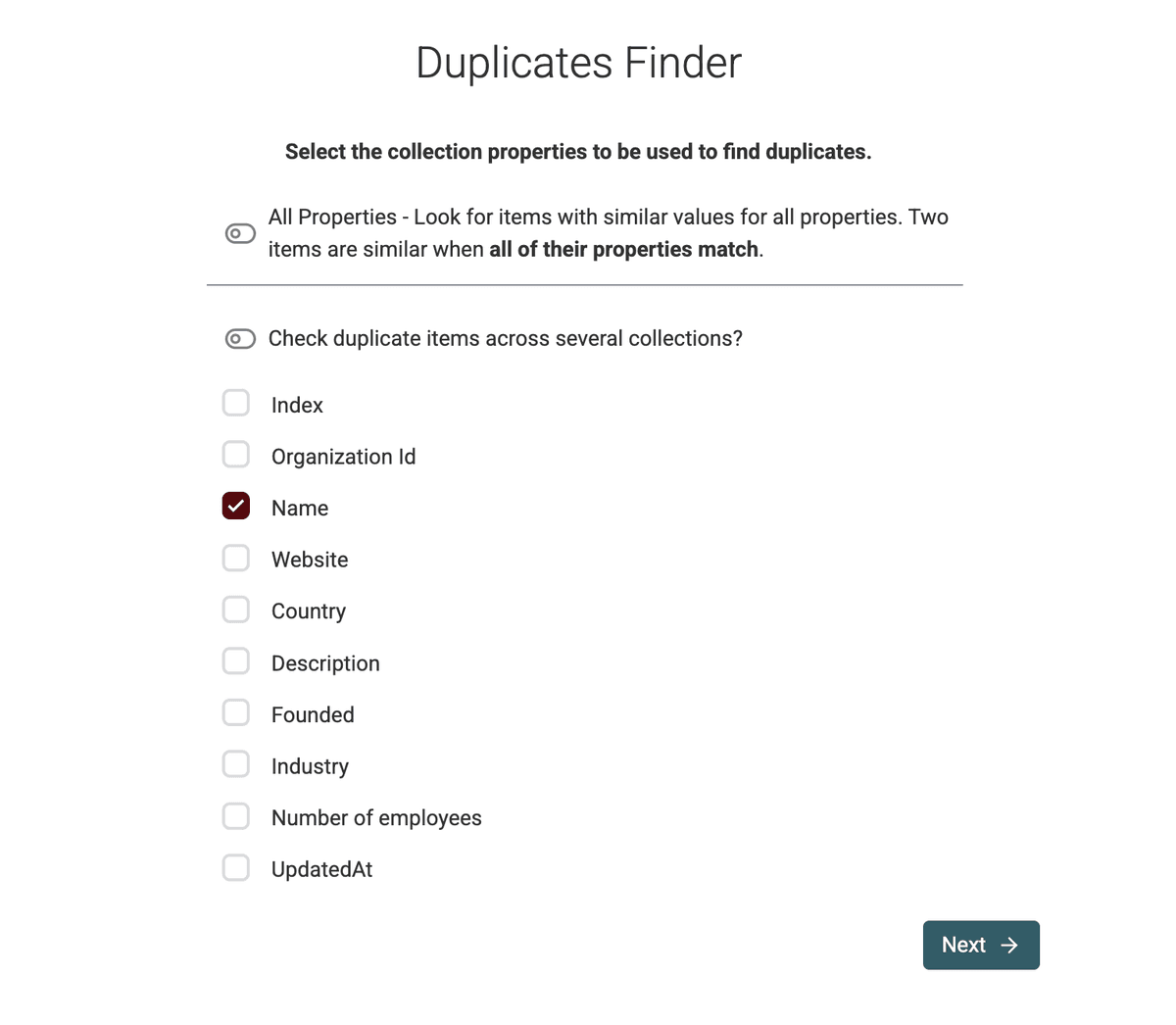
Per le aziende puoi anche usare
Website URLoLinkedIn Company Page URL.Per i contatti,
Phone Numbersono scelte comuni.
2.c Configura l'algoritmo
Nel passo successivo, scegli l’algoritmo di matching.
"Smart" funziona bene con URL o email, gestendo piccole variazioni. "Exact" è più rigoroso. Puoi anche usare matching fonetico o fuzzy per i nomi.
Seleziona anche il Processor adatto ai tuoi dati.
Qui seleziono il Company Name processor per gestire specifiche variazioni dei nomi aziendali (suffissi societari, termini geografici, ecc.)
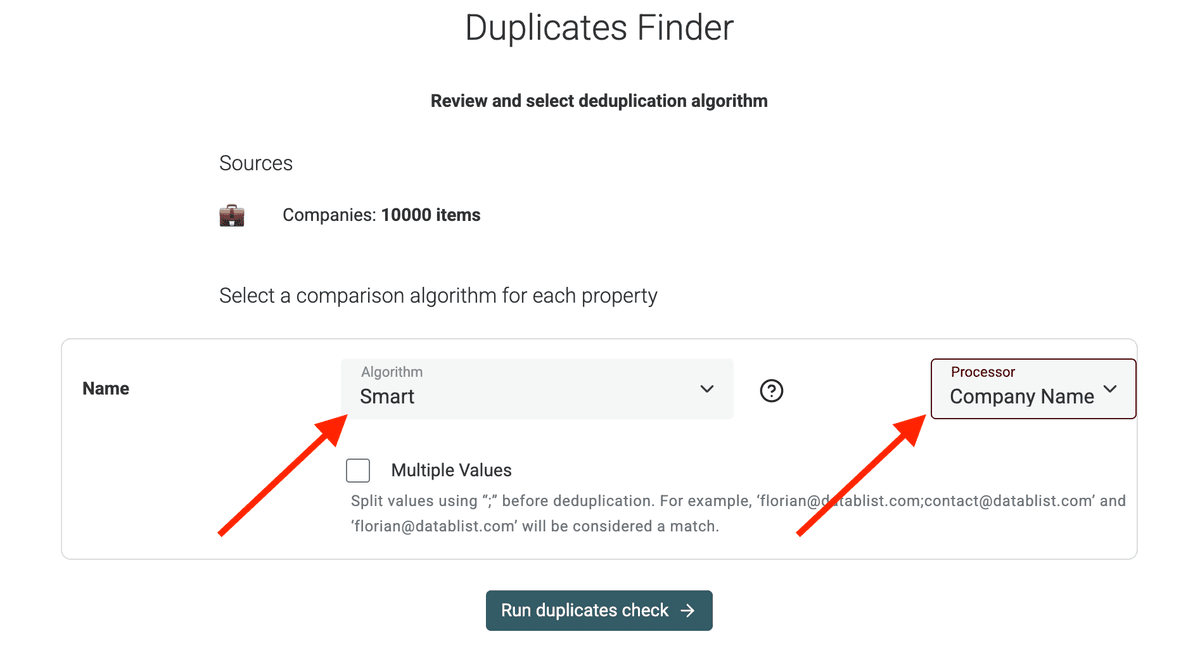
2.c Esegui la verifica
Clicca su "Run duplicates check".
Datablist analizzerà i dati e mostrerà gruppi di potenziali duplicati.
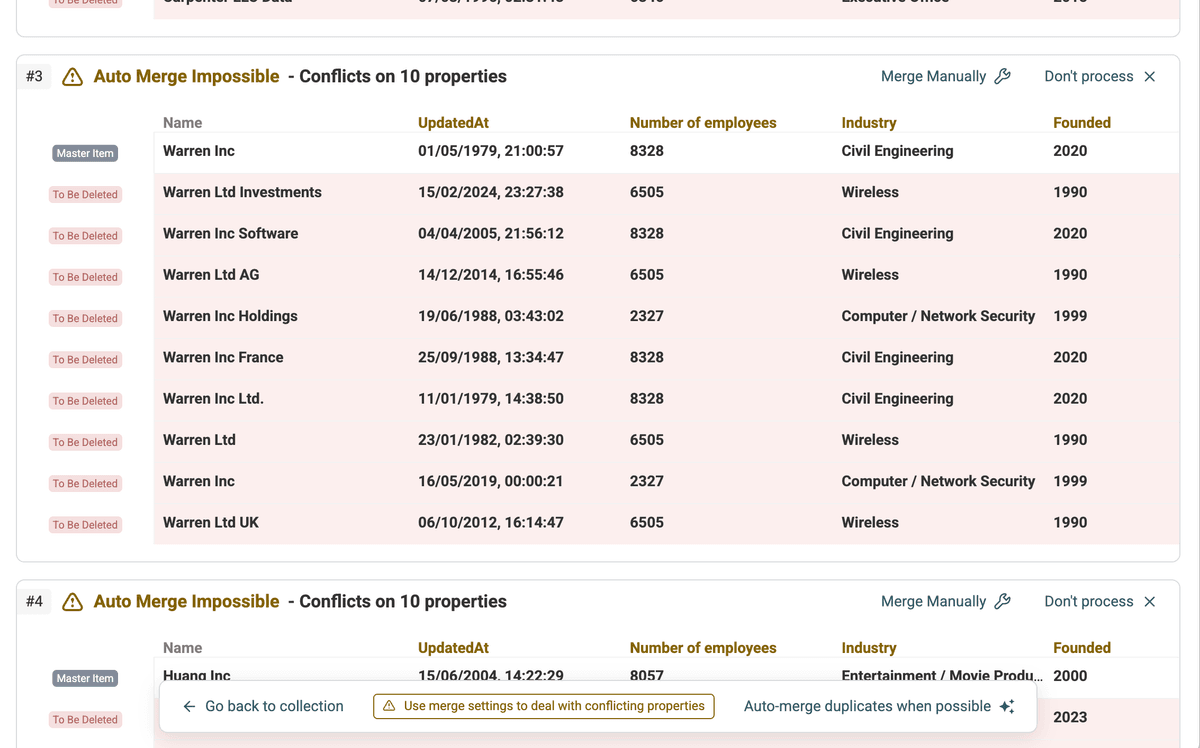
Step 3: Seleziona AI Processing
Invece di usare "Auto Merge" o il merge manuale, clicca il pulsante AI Editing nella pagina dei risultati dei duplicati. Questo attiva la modalità guidata dall’AI.
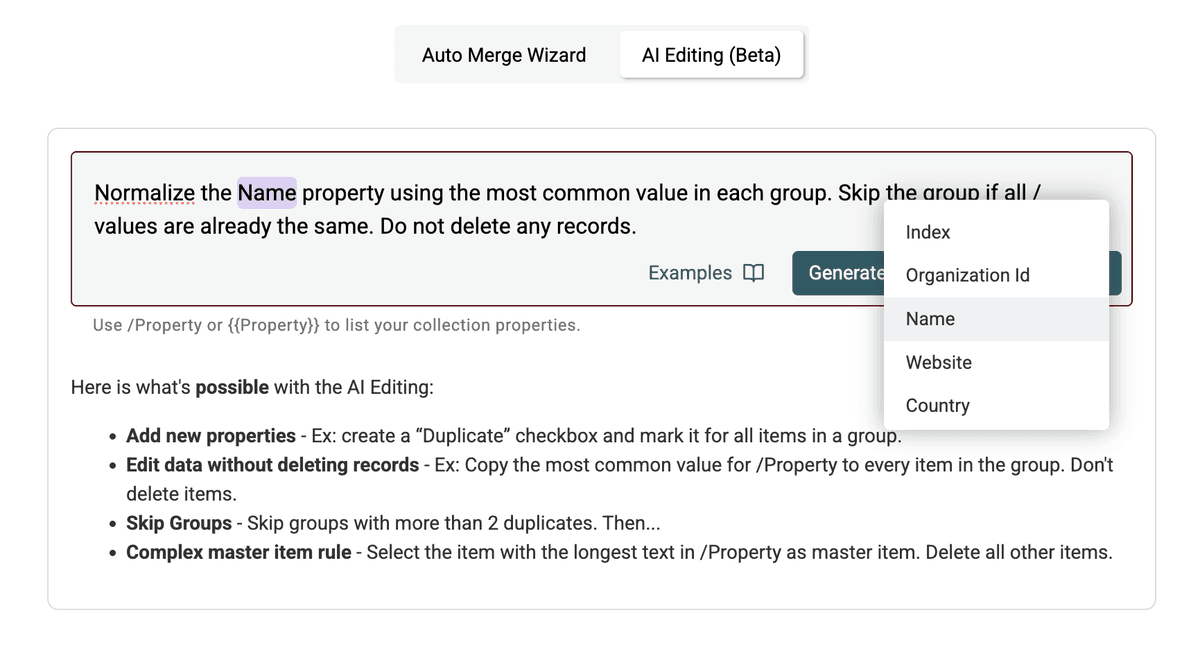
Step 4: Scrivi il prompt di normalizzazione
Qui dici all’AI cosa fare. Devi indicare di:
- Identificare il valore più comune per la proprietà target all’interno di ciascun gruppo di duplicati.
- Aggiornare tutti i record del gruppo usando quel valore per quello specifico campo.
- Specificare chiaramente di non eliminare alcun record.
Ecco un esempio di prompt per normalizzare la proprietà /Company Name:
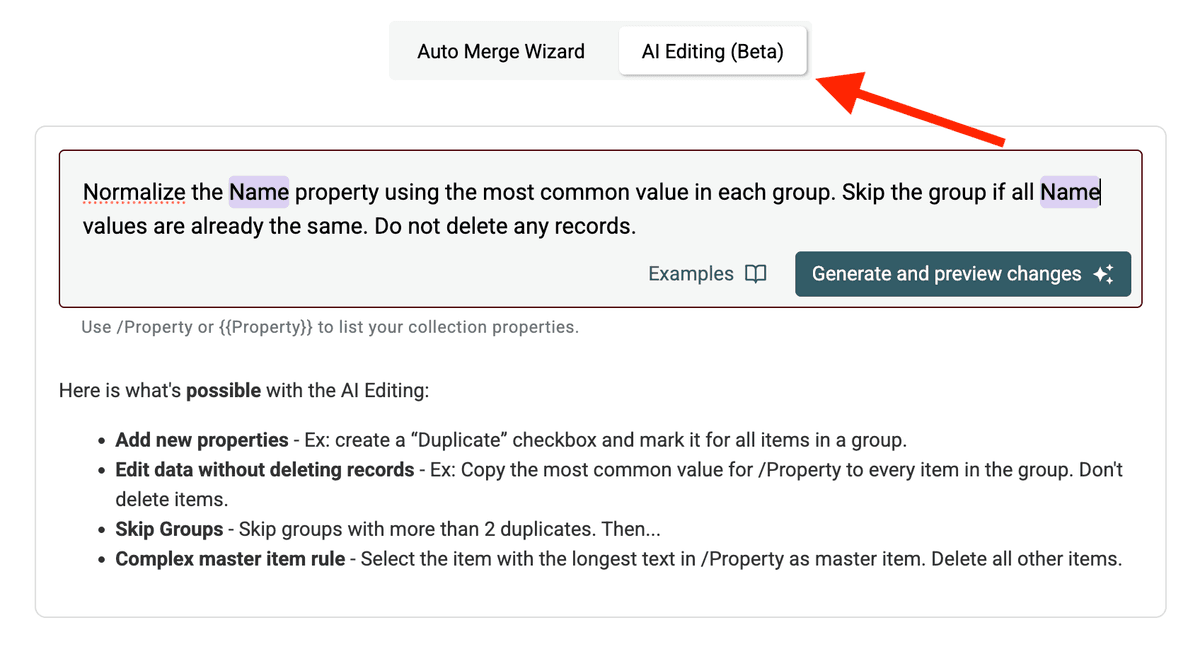
Spiegazione del prompt:
Normalize/Normalizza la /CompanyName property...: specifica il campo target. Usa/PropertyNameo{{PropertyName}}per riferirti alle colonne....using the most common value in each group.: definisce la logica per scegliere il valore standard. Puoi anche usare criteri come "valore più lungo", "più corto", oppure riferirti a un altro campo (es. "usa il valore del record con la data /UpdatedAt più recente").Skip the group if all /CompanyName values are already the same.: istruzione di efficienza per evitare elaborazioni inutili.Do not delete any records.: fondamentale per assicurarsi che vengano aggiornati solo i campi, senza unire o rimuovere record.
Step 5: Genera e anteprima dello script
Clicca Generate and preview changes. L’AI di Datablist interpreterà il prompt e genererà uno script per eseguire l’azione.
Tranquillo, non devi scrivere o modificare alcuno script.
- Script Explanation: un riepilogo in inglese semplice di ciò che farà lo script. Verifica che sia allineato alla tua intenzione.
- Result Preview: una tabella che mostra in anteprima come lo script modificherà un campione dei gruppi di duplicati, prima che vengano applicate le modifiche. Controlla il campo target (es.
/Company Name) per assicurarti che riporti il valore normalizzato previsto su tutto il campione.
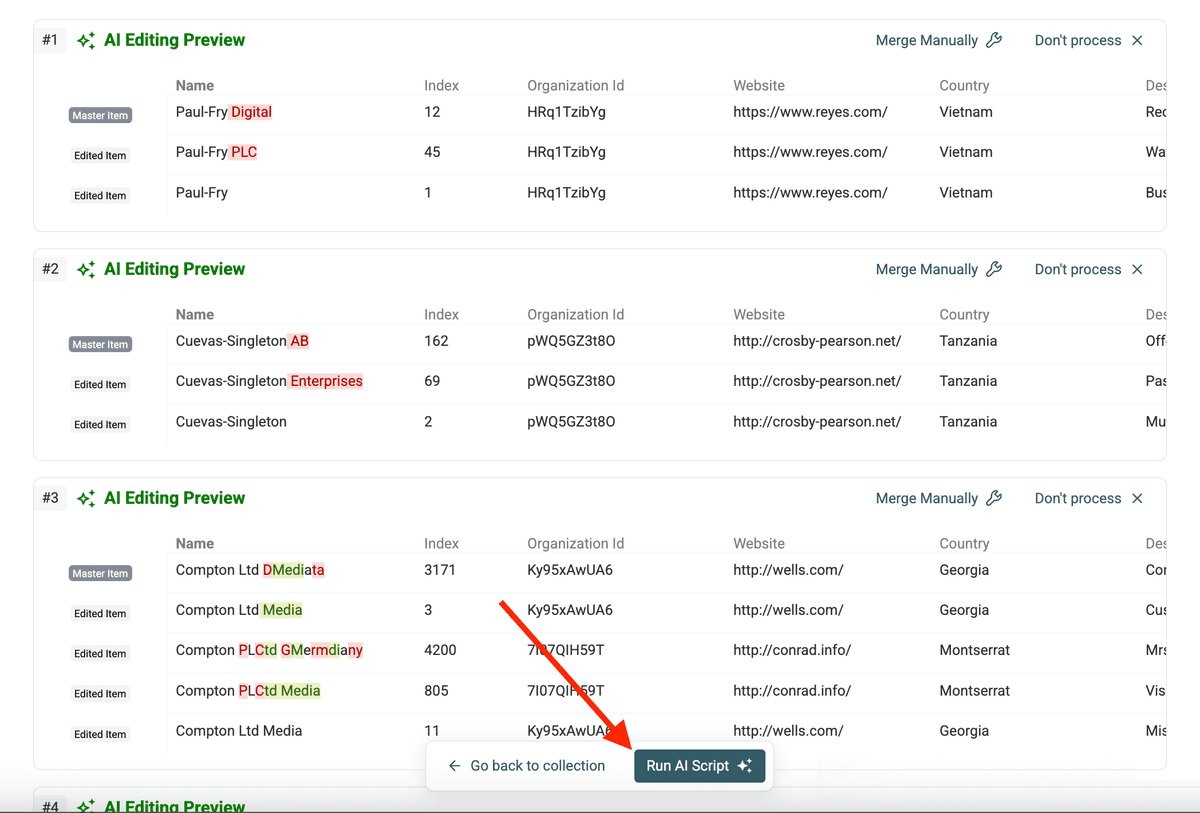
Step 6: Esegui lo script
Se spiegazione e anteprima sono corrette, clicca Run AI Script. Datablist eseguirà lo script generato su tutti i gruppi di duplicati identificati.
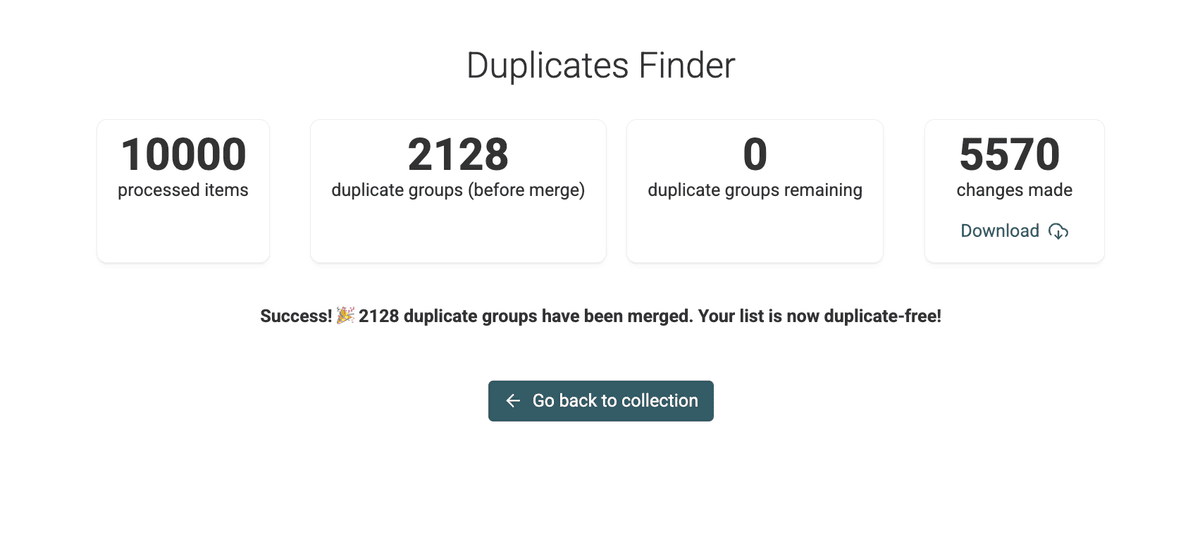
Step 7: Verifica le modifiche
Al termine, Datablist fornisce un riepilogo e un Changes List scaricabile.
Utile se devi replicare le modifiche in un sistema esterno (ad esempio per modificare i lead nel CRM, ecc.)
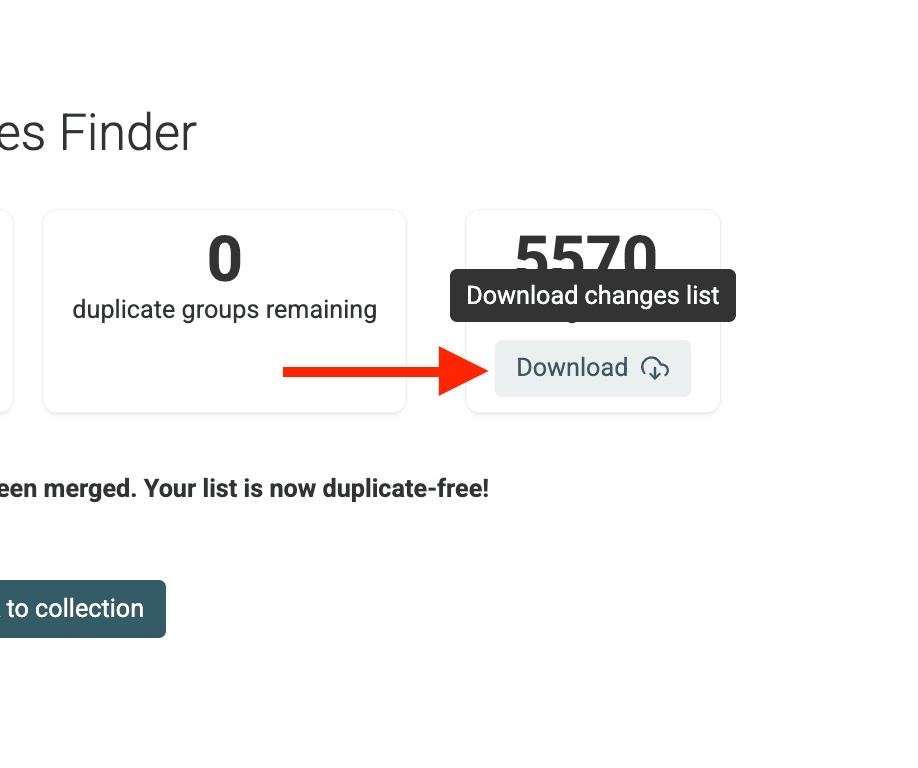
Torna alla vista principale della collection. Vedrai che il campo target (es. /CompanyName) è ora coerente in tutti i record all’interno dei gruppi di duplicati, mentre i record restano separati.
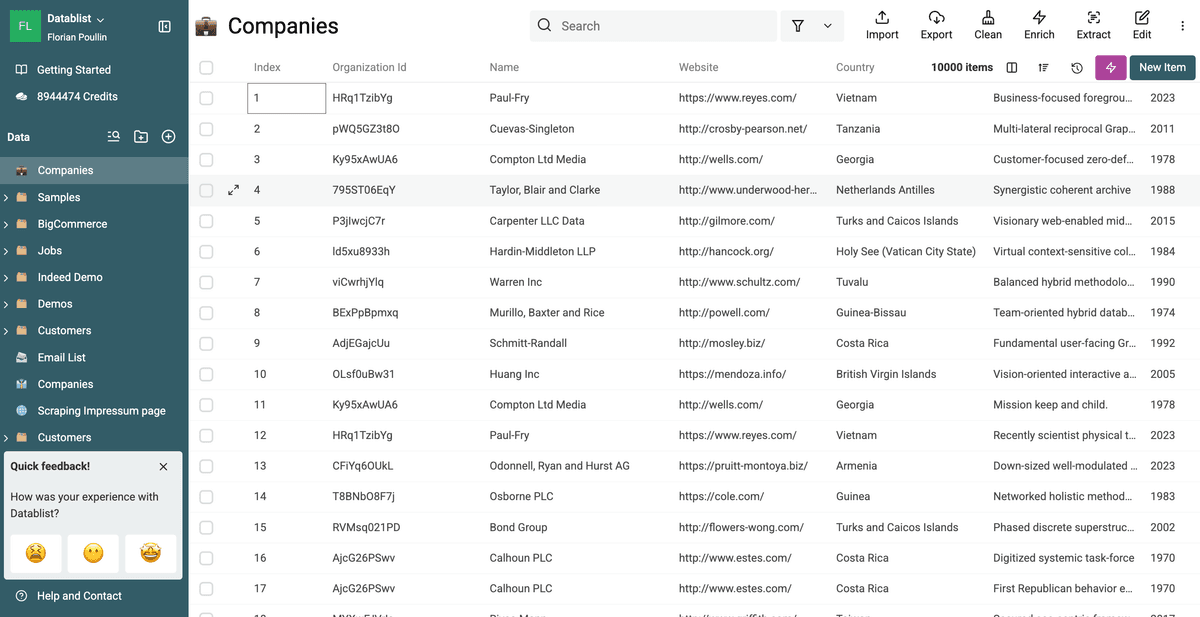
Hai normalizzato con successo un campo tra duplicati senza fare merge! 🚀
Quando normalizzare senza fare merge
Quando conviene normalizzare un campo invece di fare un merge completo?
- Standardizzare nomi di aziende o contatti: Ripulisci varianti come "Example Ltd", "Example Limited" o "Jon Doe", "Jonathan Doe" sui duplicati prima di definire la strategia di merge finale.
- Pulire i job title: Unifica titoli come "VP Marketing", "Vice President Marketing", "Marketing VP" per report e analisi coerenti.
- Normalizzare le location: Assicura nomi paese coerenti ("UK", "United Kingdom") o abbreviazioni di stato ("CA", "California") nei record di indirizzo.
- Preparare un import/update nel CRM: Standardizza i campi chiave prima di importare in un CRM con regole di validazione rigide, anche se mantieni temporaneamente i duplicati.
- Data auditing: Conserva i record duplicati originali per audit o storico, ma normalizza gli identificatori chiave per facilitare l’analisi.
- Pulizia incrementale: Normalizza un campo alla volta come parte di un flusso di data cleaning più ampio, prima di arrivare a merge o cancellazioni definitive.
Perché normalizzare invece di fare merge?
- Preserva la granularità dei record: Mantieni intatti i singoli duplicati, utile per tracciare origini, interazioni specifiche o dati storici associati a ciascun record.
- Gestisce l’incertezza: Utile quando i duplicati non sono corrispondenze perfette. Normalizzare un campo chiave dà coerenza senza forzare un merge potenzialmente errato di record con altri dati divergenti.
- Approccio a fasi: Permette un processo di data cleaning più controllato. Prima normalizzi, poi valuti se fare merge o eliminare.
- Semplicità: Azione mirata. Intervieni su un solo campo senza toccare il resto dei dati nei record duplicati.
Conclusione
La funzione AI Processing nel Duplicates Finder di Datablist offre un modo flessibile e potente per gestire i dati duplicati. Consentendo di normalizzare campi specifici nei gruppi di duplicati senza fare merge dei record, diventa uno step intermedio decisivo in molti workflow di data cleaning. Con semplici prompt in linguaggio naturale, ottieni coerenza dei dati in modo rapido ed efficiente, risparmiando ore di lavoro manuale e riducendo il rischio di errori. Che tu stia standardizzando company name, job title o location, questa funzione ti aiuta a migliorare la qualità dei dati.
FAQ
-
AI Processing è incluso nel mio piano Datablist? AI Processing, inclusa la generazione e l’esecuzione di script per la normalizzazione, è disponibile nei piani a pagamento di Datablist. Consulta la Pricing Page per i dettagli.
-
Posso normalizzare più campi con un unico prompt? Sì, puoi scrivere un prompt per normalizzare più campi in una volta. Ad esempio: "Normalizza la proprietà /Company Name usando il valore più comune in ogni gruppo. Normalizza la proprietà /Country usando il valore più comune in ogni gruppo. Non eliminare alcun record."
-
Cosa succede se l’AI interpreta male il mio prompt? Controlla sempre con attenzione la spiegazione dello script e l’anteprima dei risultati prima di eseguire. Se l’anteprima non è corretta, affina il prompt rendendolo più chiaro e specifico, quindi rigenera lo script.
-
Posso annullare le modifiche fatte dallo script AI? Una volta eseguito, lo script applica le modifiche direttamente. Datablist ha una funzione di undo per le azioni recenti all’interno della sessione, ma la best practice è clonare la collection prima di trasformazioni importanti, così da poter tornare indietro se necessario.
-
In cosa differisce dalla classica opzione di merge "Combine conflicting properties"? L’opzione standard "Combine" unisce i record duplicati in un unico master e concatena i valori di testo in conflitto in un solo campo. Con AI Processing, usando il prompt giusto, aggiorni il campo su tutti i record duplicati a un unico valore scelto e mantieni separati i record. Non fa merge dei record né concatena valori, a meno che tu non lo chieda esplicitamente.