

抓取 Google 搜索结果,是目前构建 lead list 成本最低、效率最高的方法之一。但大多数人很快就会遇到一个瓶颈:Google 通常只展示前 250 到 300 条结果。
即使你的关键词实际匹配了数百万个页面,翻到后面的结果页也往往只会看到空白。
Datablist 通过 "Start with Google Search Queries" 数据源解决了这个限制。
你不再需要只跑一次搜索、拿到区区 200 条结果,而是可以一次性并行运行几十个甚至上百个变体查询。
大约只需 1 美元,你就能抓取约 4,000 条结果。
这篇指南会带你一步步完成整个自动化流程,让你无需写一行代码,也能批量提取成千上万条高质量搜索结果。
📌 适用场景示例
- 创建包含 LinkedIn 资料的 lead list
- 按关键词搜索并抓取 Instagram Profiles
- 按特定网站技术栈筛选目标公司
- 在数百个城市范围内建立本地企业数据库
快速跳转:
- 理解 Google 300 条结果限制
- 多查询抓取方案 和 如何用 AI 生成查询变体
- Datablist 批量抓取 Google 的操作步骤
- 数据清洗与去重
- 搜索结果数据 enrichment
- 成本分析:低预算也能大规模抓取
理解 Google 300 条结果限制
Google 的搜索引擎本质上是为人类浏览设计的。大多数用户在第一页就能找到自己需要的信息。
因此,Google 没有动力向单个用户持续展示成千上万条结果(当然,它也希望防止 scraping 滥用)。
如果你尝试翻到第 40 页,常常会看到 Google 提示“类似结果已省略”,或者页面干脆什么都不显示。
对 lead generation 来说,这会非常致命。比如你搜索“上海 律师事务所”,可能会找到 250 个不错的潜在客户;但实际上,还有成千上万条相关结果被“藏”在第 301 到第 10,000 位之间。只靠一个宽泛关键词,你根本触达不到它们。
想拿到这些隐藏结果,唯一办法就是让搜索更具体。通过缩小搜索范围,你可以让 Google 针对某个更小的细分场景,重新展示该场景下排名前 300 的结果。如果你对几十个细分场景重复这个过程,最终就能把整张名单一点点拼出来。
多查询抓取方案
所谓多查询抓取,就是把一个很大的搜索需求拆成多个更小、彼此有一定重叠的查询。比如,不再直接搜索“美国律师”,而是分别搜索“纽约律师”“洛杉矶律师”“芝加哥律师”“休斯顿律师”“迈阿密律师”。
每个具体城市的搜索,都会带来一组新的 200 到 300 条结果。如果你覆盖美国前 50 个主要城市,理论上就有机会收集到 15,000 条结果。虽然其中会有一些重复(例如同一家律所可能同时在两个邻近城市都有排名),但最终得到的唯一结果数量,仍然远超一次宽泛搜索。
这个策略之所以有效,是因为它改变了 Google 眼中的搜索“意图”。 通过加入地理位置或其他维度的变体,你可以把原本在大词搜索里排到第 5,000 位的目标对象,移动到细分搜索中的第 1 位。
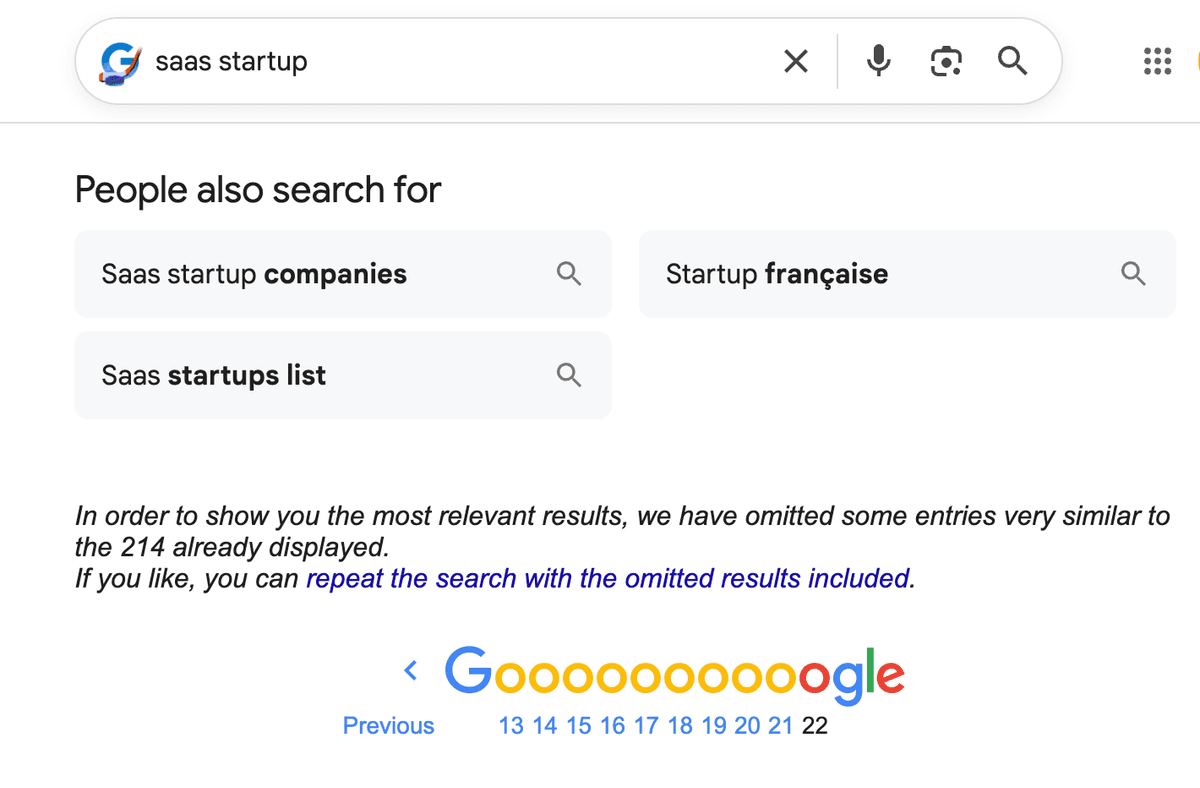
如何用 AI 生成查询变体
手动创建 100 个搜索词变体会非常耗时。 但现在的 LLM,例如 ChatGPT、Gemini 或 Claude,可以几秒内帮你完成。你只需要给 AI 一个 prompt,它就能快速输出格式整齐的查询列表。
地域拆分策略
按地域拆分,是最容易放大结果量的方法。每个国家都有城市、省份或地区列表。
I need to find dentists in Australia. Google limits me to 300 results. Please generate a list of 50 search queries following the pattern.
Use the 50 most populous cities.
Return the list of queries in a text canvas zone, one per line.
## Pattern
dentist [City Name], Australia
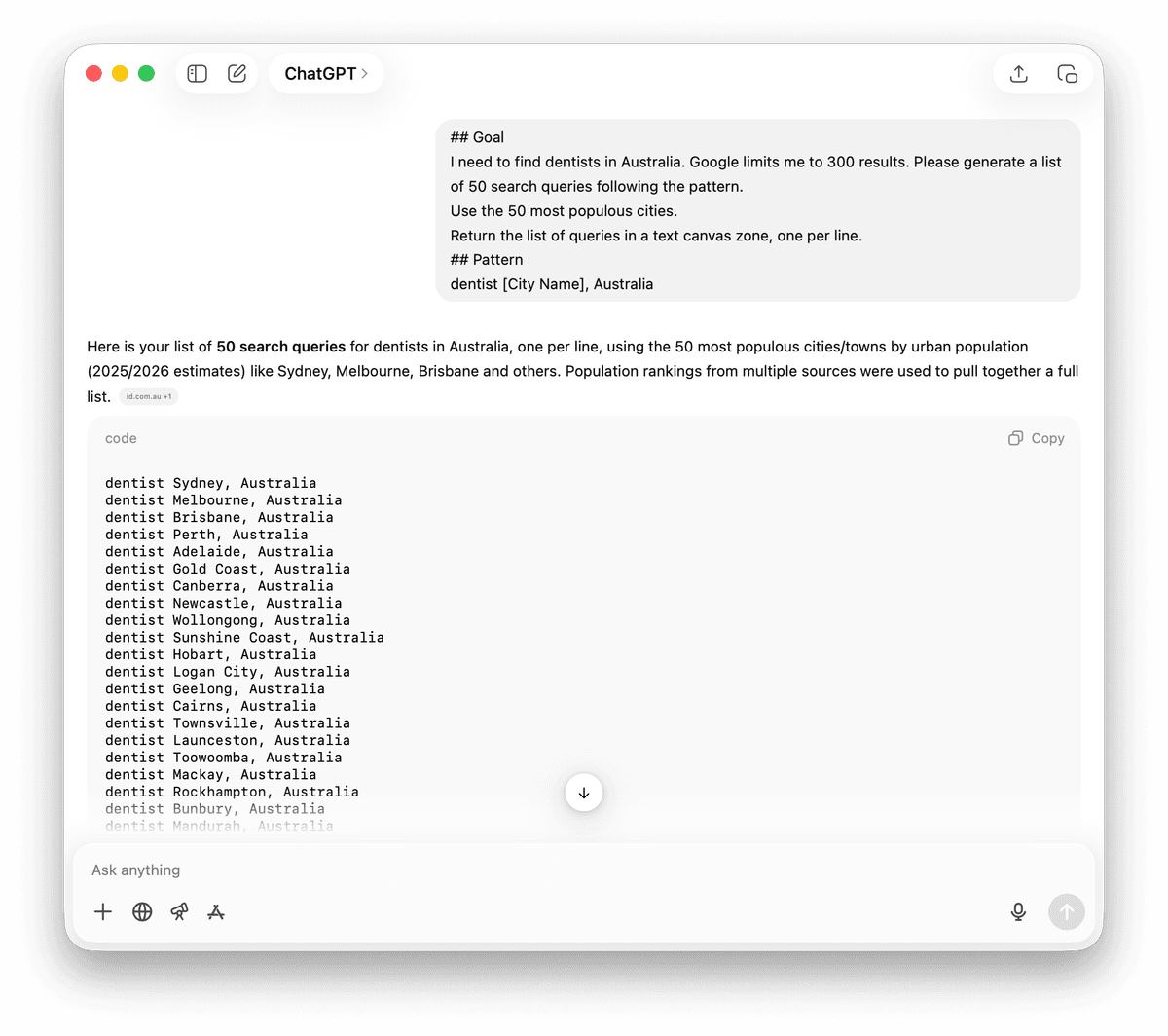
关键词变体策略
有些场景不适合按地域拆分。这种情况下,你可以改用关键词变体。
Examples: 'B2B marketing agency', 'E-commerce marketing agency', 'SaaS marketing agency', 'Real estate marketing agency'. Use diverse industries to ensure different companies appear in the results.
Return the list of queries in a text canvas zone, one per line.
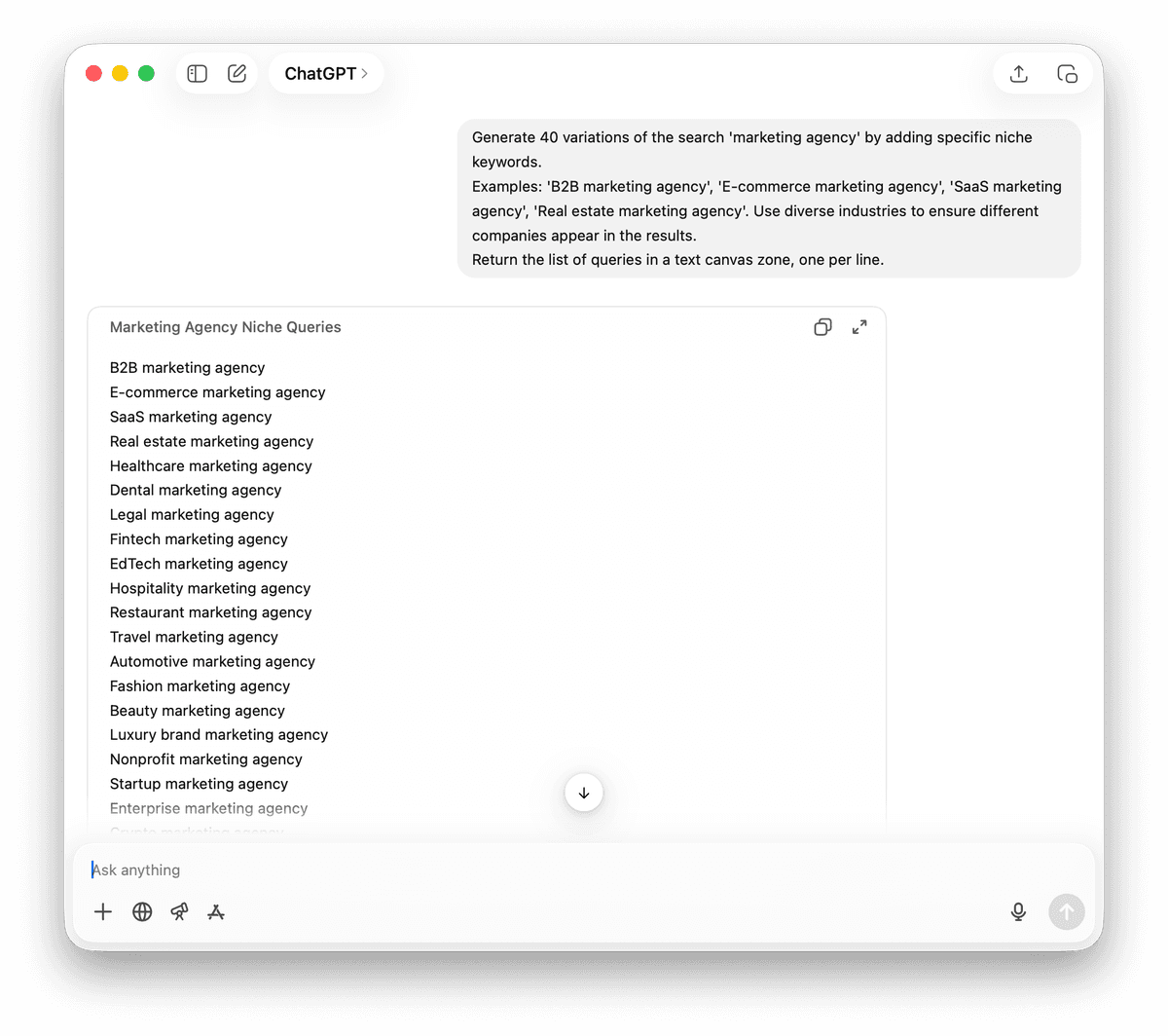
“Fingerprint” 指纹策略
很多网站都会使用特定的软件或建站平台,而这些工具往往会在 HTML 代码或页脚里留下可识别的痕迹。Google 会索引这些文本。
Example: '“Powered by Shopify” jewelry', '“Powered by Shopify” fitness'.
Return the list of queries in a text canvas zone, one per line.
Datablist 批量抓取 Google 的操作步骤
当你拿到查询列表后,Datablist 会把并行执行这些搜索背后的技术复杂度全部隐藏起来。 你不需要操心 rotating proxies、headless browsers,也不用自己解析 html 数据。
1. 进入数据源
打开 Datablist,在侧边栏点击 "Start from a data source"。
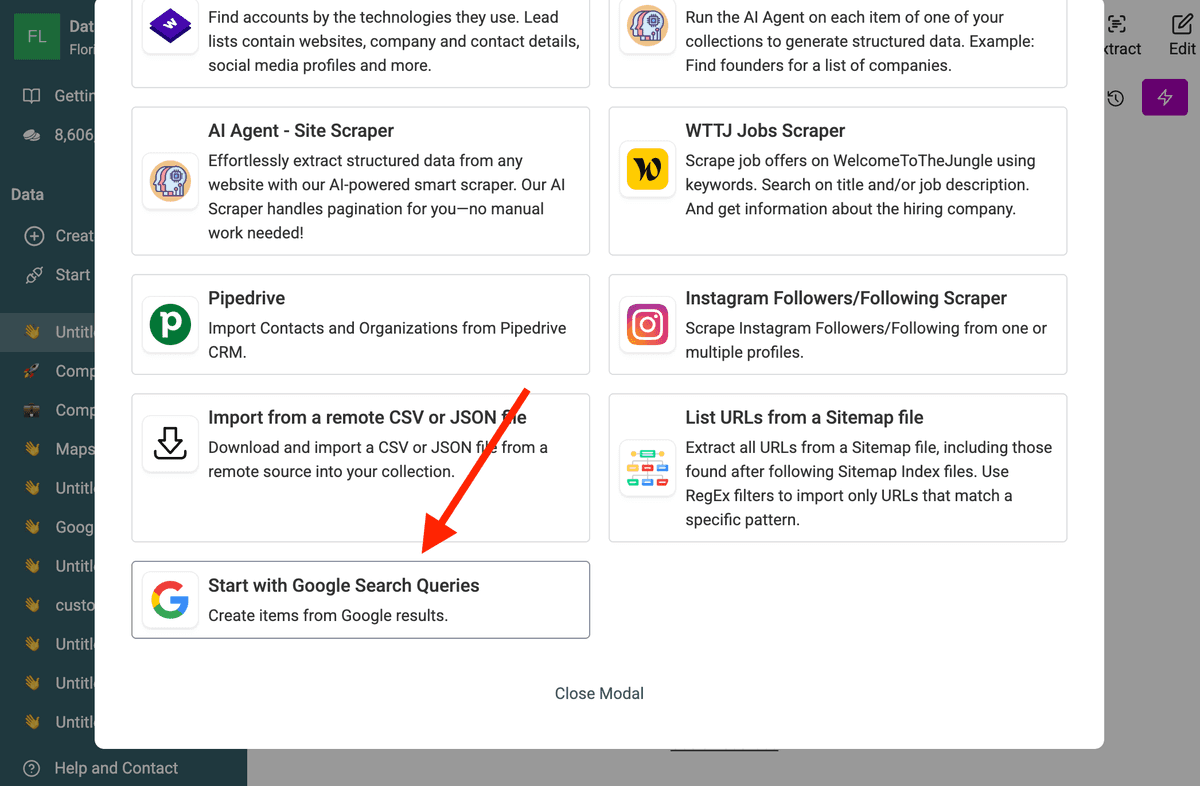
找到 "Start with Google Search Queries" 数据源。这个 source 专门为大批量抓取场景而设计。
2. 粘贴查询并配置搜索参数
复制 AI 生成的查询列表,直接粘贴到 Datablist 的 query 输入框中。你可以一次粘贴几十行,甚至上百行。
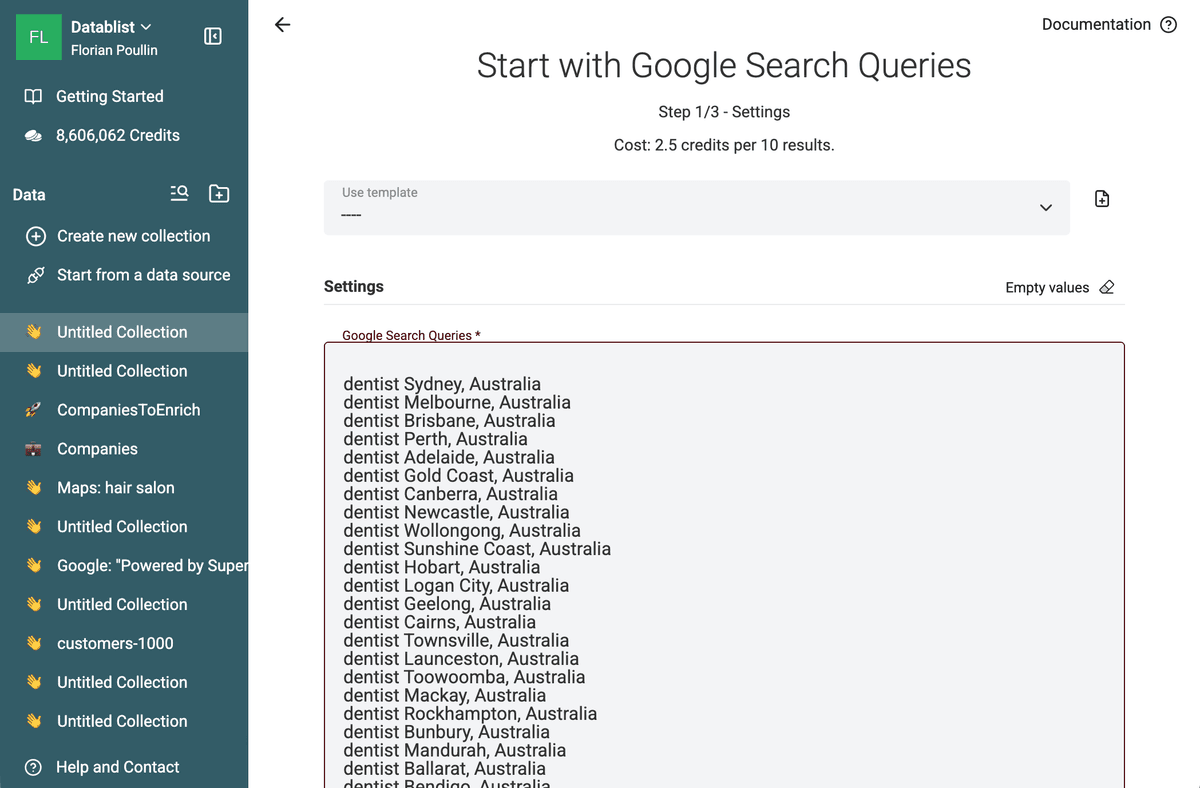
设置目标国家和语言,这一步非常关键。比如你搜的是英国律师,但国家设置成美国,那么 Google 返回的结果就会完全不同,甚至毫无相关性。你还可以指定时间范围,只抓取最近一个月或一年内被索引的结果。
4. 执行并等待
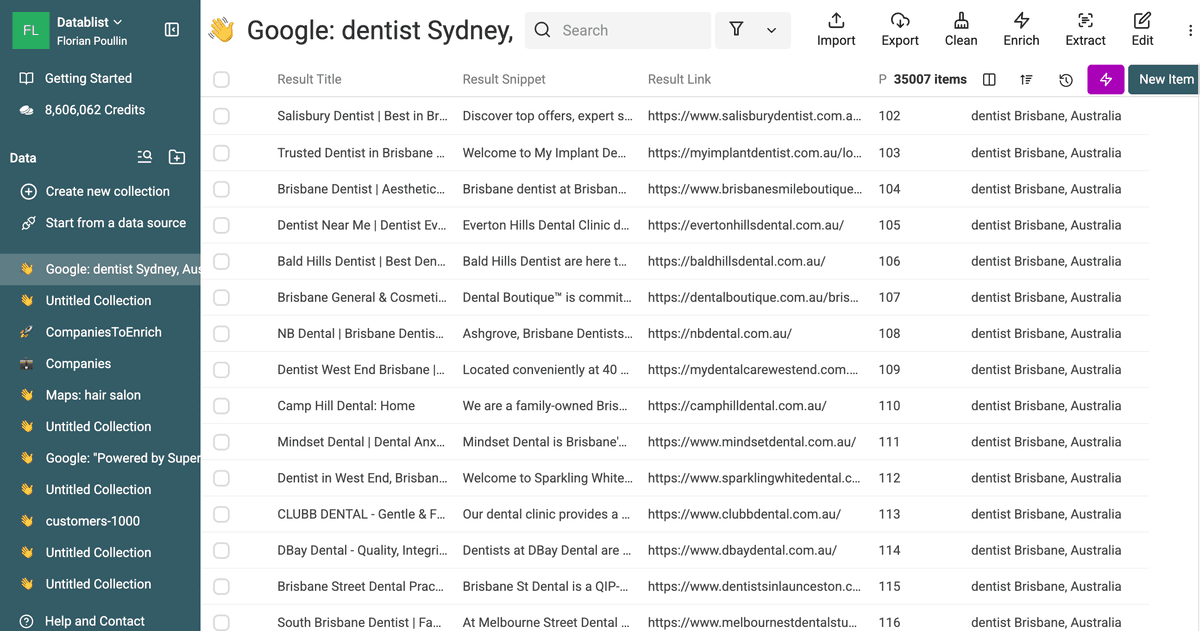
点击运行按钮,Datablist 会开始处理这些查询。由于抓取 Google 需要非常小心地控制节奏、避免被封,系统会自动帮你处理这些细节。
你可以实时看到结果持续写入 collection。
数据清洗与去重
去重
运行 50 个相似查询最常见的副作用,就是会产生大量重复数据。同一家热门律所,可能同时出现在“伦敦律师”“英国律师”“商业律师”等搜索里。当你把这些结果合并进同一个 Datablist collection 后,就会出现多行重复记录。
在开始 outreach 之前,你必须先完成去重。Datablist 内置了功能很强的 Duplicates Finder。
- 打开 "Clean" 菜单。
- 选择 "Duplicates Finder"。
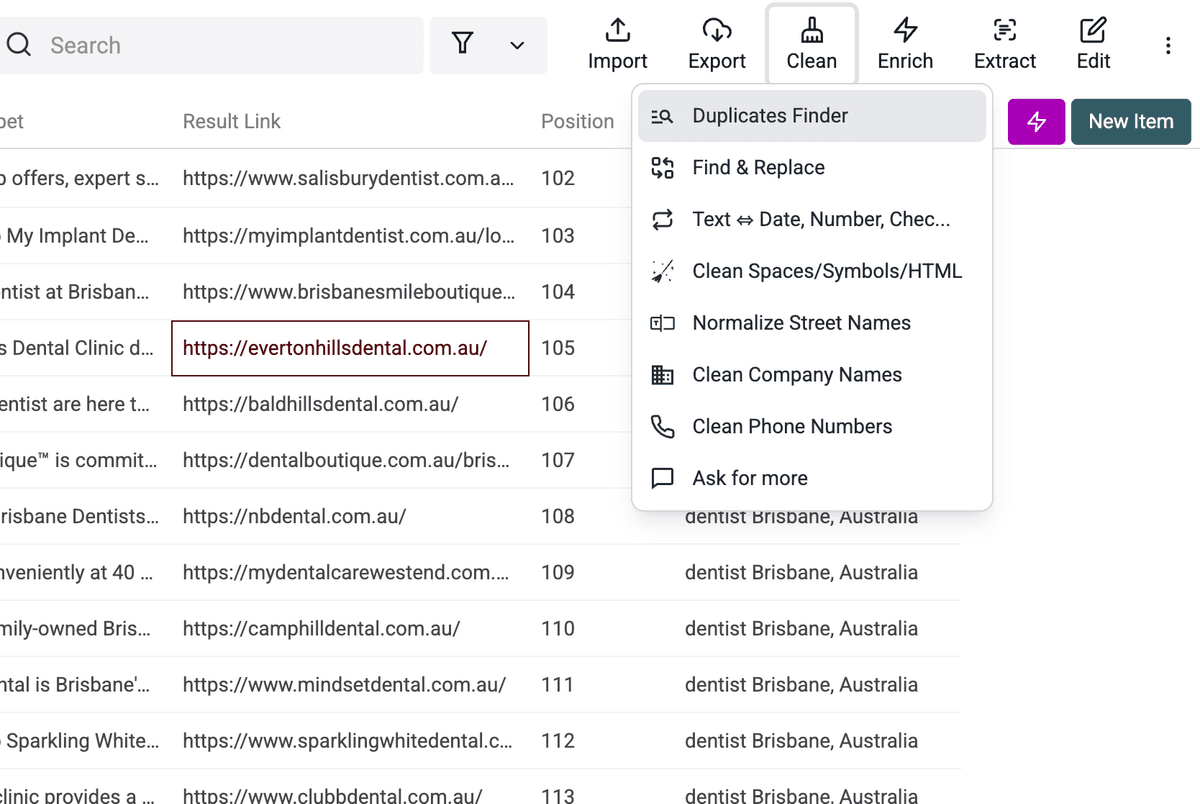
- 选择要比较的字段。对 Google 搜索结果来说,"Result Link" 通常是最佳选择。
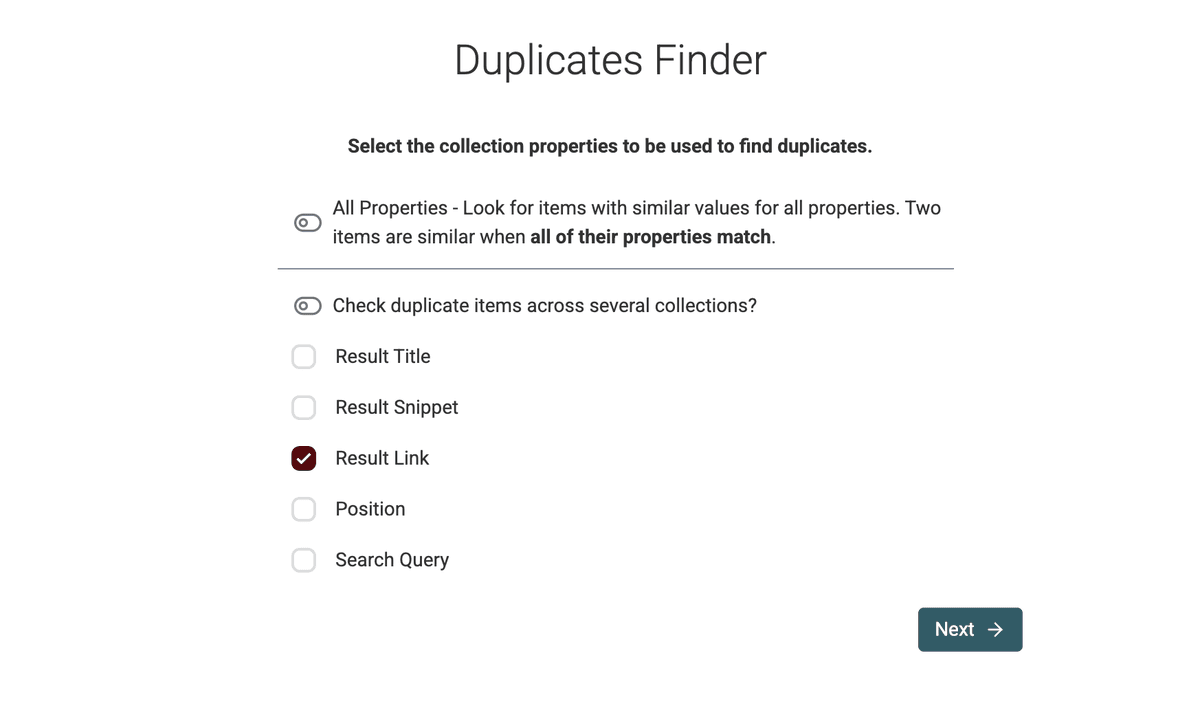
- 选择 "URL" preprocessor,在去重时忽略 path、query params 等差异。
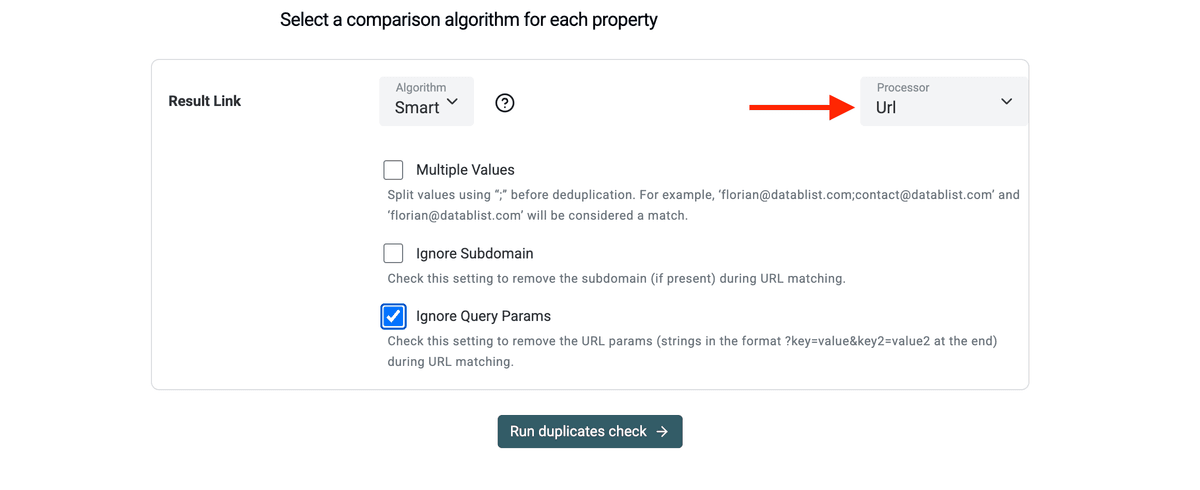
- 让工具识别重复行,然后执行合并或删除多余项。
去除噪音数据
数据清洗还包括去掉无关噪音。Google 结果中经常会混入一些“聚合站”或目录站,比如 Yelp、Yellow Pages、Tripadvisor。大多数情况下,你真正想保留的是企业官网,而不是这些中间平台。
你可以使用筛选功能,排除常见目录站域名。关于这类数据处理的详细操作,可以参考这篇指南:data cleaning this guide。
搜索结果数据 enrichment
只有 URL 或页面标题,通常不足以支撑一场真正可执行的销售活动。拿到唯一网址列表之后,下一步通常就是补充联系人信息。 Datablist 可以作为 enrichment hub,把你抓取到的数据继续流转到其他服务中。
查找邮箱
-
从公司域名获取邮箱
如果你抓取到的是公司域名,可以使用 Datablist 的 "Waterfall People Search" enrichment。它会查找这些公司的在职人员,并返回他们的 profile 信息以及已验证邮箱地址。这非常适合构建精准的 B2B 联系人名单。 -
从 LinkedIn 个人主页 URL 获取邮箱
如果你抓取到的是 LinkedIn profile 链接,可以使用 Datablist 的 Waterfall Email Finder。它只需 LinkedIn profile URL 就能帮你找到职业邮箱。你也可以参考这篇分步教程:Find email addresses from a LinkedIn Profile URL。
从域名匹配 LinkedIn Company Pages
如果你的起点是公司官网,那么也可以一键把它们转换成 LinkedIn 资产。 使用 "LinkedIn Company Page Matcher" enrichment,它会为你列表中的每家公司匹配官方 LinkedIn Company Page。
这个能力非常实用。原本只是一个普通的 Google 搜索结果,经过匹配后就能变成带有行业、规模、活跃度等信息的完整公司档案。
匹配完成后,你还可以继续拉取更详细的企业数据:
这样你就能很快从原始 URL 过渡到结构化 B2B 数据。
用 AI Agent 自动访问网站
有时候,网站里真正有价值的信息并不会直接显示在搜索结果中。 这时就轮到 AI Agent 上场了。
AI Agent 会替你逐个访问网站,并像真人一样阅读页面内容。
它可以:
- 基于网站内容为公司自动分类
- 将 leads 标记为 "High Priority" 或 "Low Priority"
- 从 Contact 或 About Us 页面提取联系信息
你不再需要自己打开 500 个标签页逐个查看,直接把这些重复劳动交给 agent 就行。
案例与应用场景
案例一:细分行业营销机构
一家专注服务宠物医院的营销机构,希望在美国扩大业务。单独搜索 “veterinarian USA” 只能拿到 300 条结果。于是他们生成了美国 500 个最大城市的查询列表,并通过 Datablist 批量运行,最终拿到了 85,000 条原始结果。
在按域名完成去重后,他们得到了 42,000 家唯一的宠物诊所网站。 接着,他们继续补充了联系人信息。
案例二:科技招聘顾问
一位招聘顾问需要寻找柏林 startup 的 CTO。他使用了下面这个查询:
site:linkedin.com/in/ "CTO" "Berlin" "startup"
然后把 “Berlin” 替换成其他德国科技城市,例如 Munich、Hamburg、Cologne。 他们还进一步变化职位名称,例如 “VP Engineering”“Technical Co-founder”“Head of Development”。 通过这种多维度组合策略,他们建立了一个包含 4,000 名高管的候选人池,规模远超普通 LinkedIn 搜索能达到的范围。
案例三:寻找线上分销商
某化妆品品牌创始人想为新推出的有机面部精油寻找独立线上精品店作为分销渠道。与其手动搜索,他们选择了独立零售商中很常见的 “Powered by Shopify” 指纹。
他们使用了 “Fingerprint” 策略:
"organic face oil" "powered by shopify"
然后借助 LLM 为不同产品类别批量生成变体(例如 “natural beauty boutique”“vegan skincare”“botanical serum”),最终识别出超过 1,200 家符合其理想分销商画像的独立网店。
他们将结果导入 Datablist,去重后,再使用 Datablist 的 AI Agent 提取联系信息。
成本分析:低预算也能大规模抓取
传统 web scraping 成本很高。找开发者定制一个 scraper,通常就要花掉几千美元。使用专门的 scraping API,又往往需要月度订阅,同时你还得具备处理 JSON 输出的技术能力。
Datablist 把这套成本模型简化了。它采用 credit 计费,意味着你只为成功抓取到的数据付费。
- 费率: 每 10 条 Google 结果消耗 2.5 credits。
- 成本: credit 套餐最低 1 美元起,可获得 20,000 credits,计算起来非常直接。
- 结果: 大约 1 美元即可抓取 4,000 条结果。
相比从数据中介那里购买“过期”的 lead list(单条 lead 可能要 0.5 美元),从 Google 抓取最新鲜的数据要便宜得多,而且是数量级上的优势。你可以自己控制筛选条件、抓取时机和目标细分市场。
Tips:善用 Google Search Operators
如果你想进一步提升抓取结果的质量,下面这些 Google 搜索操作符非常值得加入查询中。
这些符号可以明确告诉 Google:你的关键词应该出现在哪里。
- site: 用于限定某个平台内的结果。比如查找 LinkedIn profiles,可以使用
site:linkedin.com/in/。 - inurl: 用于匹配 URL 中包含的词。比如查找联系页,可以使用
inurl:contact。 - intitle: 用于匹配页面标题中的词。
intitle:"Index of"经常能找到开放目录。 - filetype: 用于查找特定文档格式。比如
filetype:pdf "marketing plan"可以找到公开的策略文档。 - -(减号): 用于排除关键词。如果你想找律师,但不想包含“recruitment”机构,可以使用
lawyer -recruitment。
把这些操作符和多查询抓取结合起来,效果会非常精准。例如:
site:instagram.com "concept store" -inurl:/p/
这个搜索会查找 Instagram 上与 concept store 相关的 profile 页面,同时排除单条帖子页面(/p/ 路径)。如果你把它扩展到 50 个不同国家或细分领域,就能构建出一个全球范围的 influencer 或竞争对手数据库。
📘 查看这篇指南了解更多
你可以阅读我们的 Search and Scrape Instagram Profiles by Category and Keywords,进一步了解如何借助 Google 搜索 Instagram Profiles。
FAQ
为什么 Google 会把结果限制在 300 条左右?
Google 的目标是提供尽可能好的用户体验。它默认认为:如果你翻到第 30 页还没找到想要的内容,那么后面的结果大概率也帮不上忙。这同时也能保护它的服务器,避免被自动化 bots 拿去下载“整个互联网”。
抓取 Google 合法吗?
抓取公开可访问的数据,通常可用于市场研究、lead generation 等商业场景。但如果涉及个人数据处理,你仍然需要遵守 GDPR 等隐私法规。同时,也建议你查看通过搜索结果访问到的具体网站的服务条款。
这个工具可以抓取 Google Maps 吗?
"Start with Google Search Queries" 主要针对标准 Google Search。如果你需要本地商家数据,比如评分、营业时间、地图坐标,那么更适合使用专门的 Google Maps scraper。简单来说,Search 更适合抓网站和数字化资料,Maps 更适合抓线下门店信息。
遇到 “CAPTCHAs” 怎么办?
如果你使用 Datablist,基本不需要自己处理。平台会自动管理 request headers 和 proxy rotation。如果某个查询触发了验证挑战,系统也会负责重试逻辑。你看到的只有最终处理完成的数据。
这些结果能导入 CRM 吗?
可以。Datablist 支持把清洗和 enrichment 后的数据导出为 CSV 或 Excel 文件。大多数 CRM,例如 HubSpot、Salesforce、Pipedrive,都支持直接导入这些文件。先在 Datablist 中完成清洗,也能确保你的 CRM 里不会堆满重复数据和无效记录。