
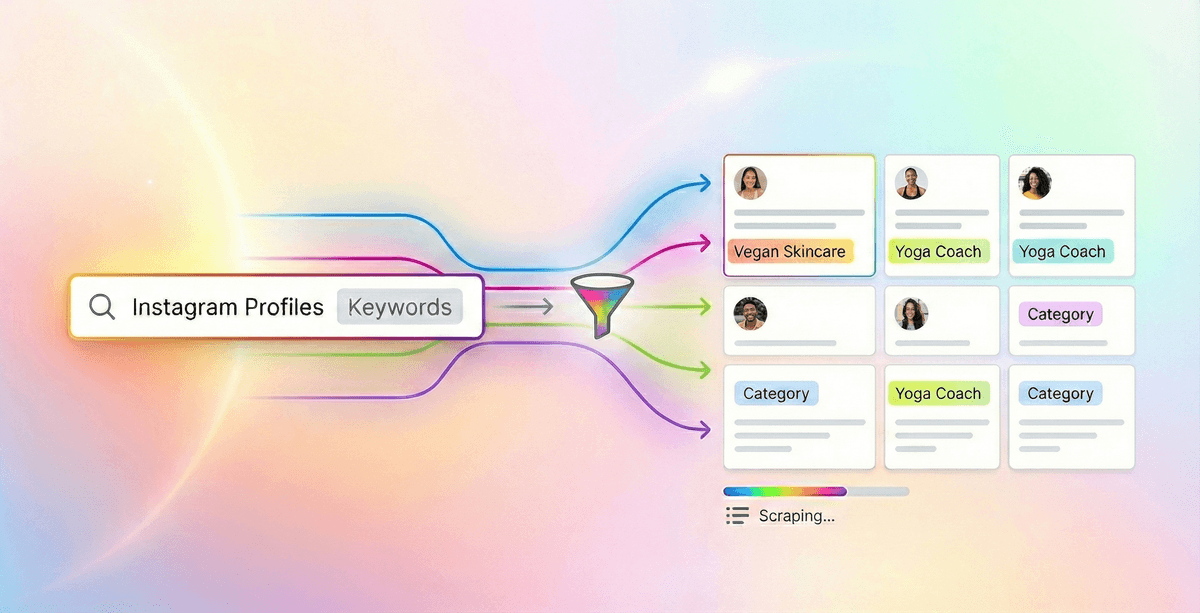
本指南会教你如何批量查找并抓取 Instagram 个人资料,筛选条件是简介(bio)里包含指定关键词。
你还会学到,如何进一步锁定属于特定 Instagram categories 的账号。
Instagram 原生搜索的限制非常明显:按关键词搜账号,通常只会返回十几个结果;搜 hashtag,出来的往往是帖子而不是 profile。
这个问题可以用 Google 来解决。Google 会索引大量 Instagram 页面,所以你可以更高效地定位简介里包含特定关键词的账号,或者按明确的 Instagram category 批量找出目标 profile。
📌 快速导航
为什么这个方法有效
Instagram 本身不支持高级 bio 关键词搜索。但账号 profile 页面是公开的,而 Google 会索引其中相当一部分页面,并且能检索页面中的文本内容。换句话说,Google 可以充当 Instagram bio 的外部搜索引擎。
这个方法之所以有效,是因为我们把“发现目标”和“提取数据”拆成了两步。第一步,用 Google 大规模发现 profile URL;第二步,用我们的 Instagram Profile Scraper 从这些 profile 中提取结构化数据。
Google 在这里还起到了过滤器的作用。它更倾向于优先展示那些已经被索引、被引用、可见度更高的 profile。因此你拿到的结果,通常会更偏向商家、influencer 和活跃创作者。曝光度越高,往往也意味着更适合用于你的 lead list building。
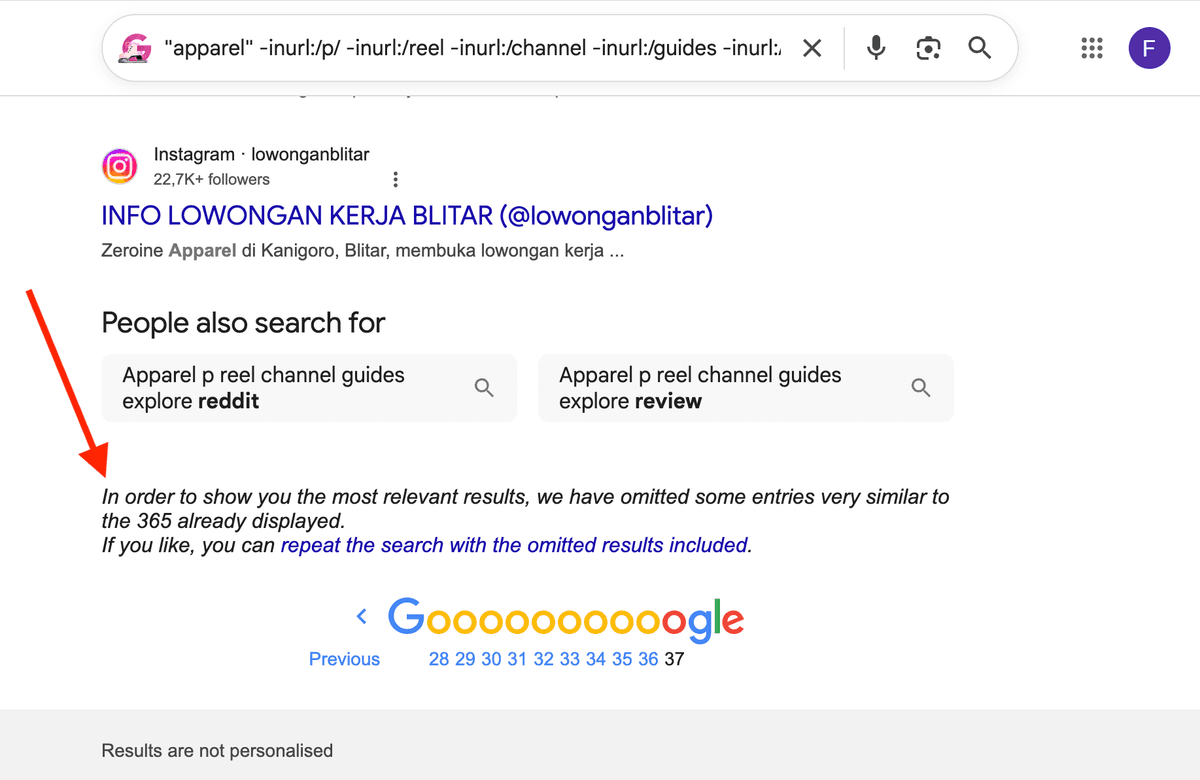
真正的限制:Google 搜索结果上限
单条 Google query 最多通常只能拿到 250 到 350 个结果。这个上限不是“多抓几次”就能突破的,真正可行的方法是换搜索角度。
正因为单个 query 有结果上限,解决方案就变成了:把搜索角度成倍扩展。你可以使用 Datablist 的 Google Bulk Queries scraper ,一次性抓取数百个 query 的结果。
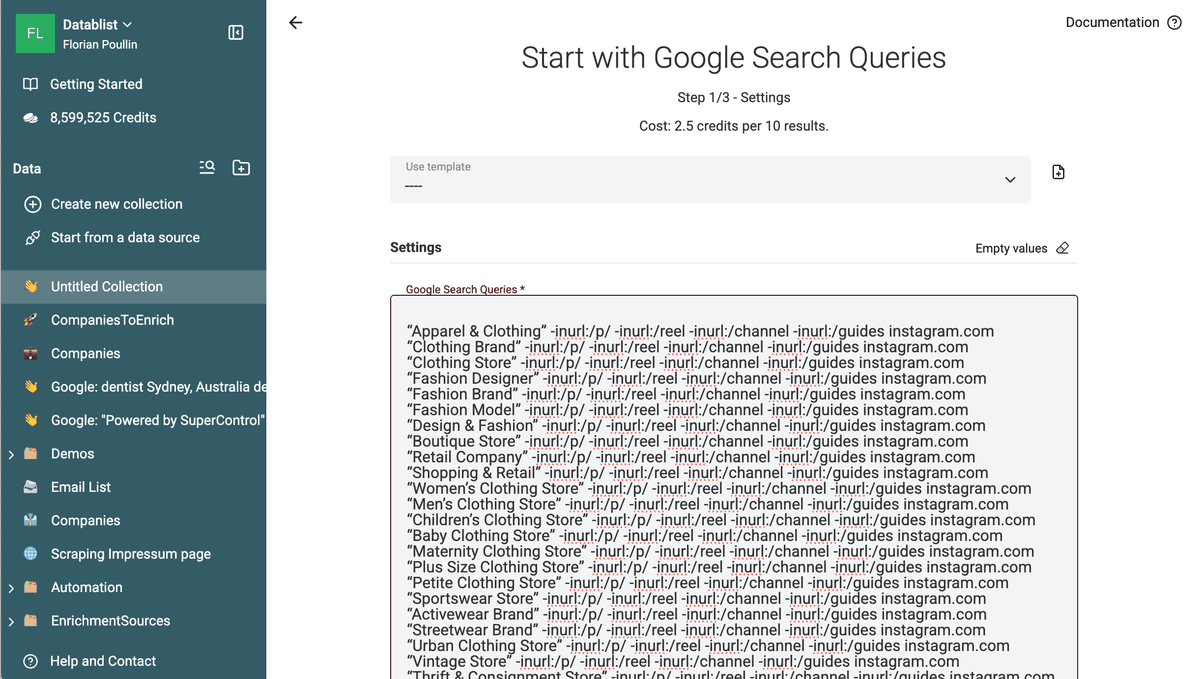
用这种方式,你可以通过关键词抓取几千个 Instagram profile,而且成本通常低于很多替代平台。举例来说,抓取 4,000 个 Instagram profile URL,成本大约只要 10 美元。
Google 搜索法原理详解
Google Query
Google 提供了一些搜索操作符,可以强制只搜某个网站,同时排除包含特定路径的 URL。
把这些操作符组合起来,就能得到一个只返回 Instagram Profiles 的查询语句。
"Keyword" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
这个 query 的含义如下:
"Keyword":强制精确匹配这个关键词。-inurl:/p/:排除普通帖子页面。-inurl:/reel:排除 reels 页面。-inurl:/guides:排除 guides 页面。-inurl:/explore:排除 explore 页面。site:instagram.com:将结果限制在 Instagram 域名下。
💡 先直接在 Google 里测试 query 在正式批量跑之前,先验证思路是否成立。打开 Google,直接粘贴这条 query,把 “Keyword” 替换成你的目标短语。认真检查前几页结果。如果返回的 profile 基本符合你的预期,就可以开始放大规模;如果不符合,就先调整关键词再测试。因为只有基础 query 足够精准,后面的批量抓取才有意义。
生成 Query 变体
LLM 是生成关键词变体最省事的方法之一。你可以先让它产出一组替代关键词,再把这些词批量转换成可直接粘贴进 Datablist Google Queries scraper 的 Google queries。
我最常用的几个 LLM:
- ChatGPT
- Google Gemini
- Claude
抓取与清洗
Google 每个 query 最多返回大约 300 个结果。
100 个变体,就意味着最多 30,000 条潜在结果。
这些结果里会有不少重叠。
完成清洗和去重后,你会留下一个体量可观、且唯一性较高的数据集。
原因很简单:每个关键词都会命中一批略有差异的 profile 集合,所以重叠是正常现象。通过 deduplication 去掉重复 profile 之后,剩下的就是从多个搜索角度挖出来的高价值唯一账号列表。
用关键词搜索 Instagram Profiles
现在你已经理解了整体方法,接下来我们把它实际应用到“按关键词搜索 Instagram profile”这个场景。
Google 会检索 profile 页面中的文本内容。因此,这种方法特别适合做关键词搜索:只要简介/bio 里写了相关词,Google 就有机会把这些 profile 返回出来。
比如你的核心关键词是 fitness coach,那你可以扩展出更多常见变体,例如:
- personal trainer
- strength coach
- online fitness coach
- weight loss coach
- gym coach
- bodybuilding coach
每一种变体,都会打开一批新的目标 profile。
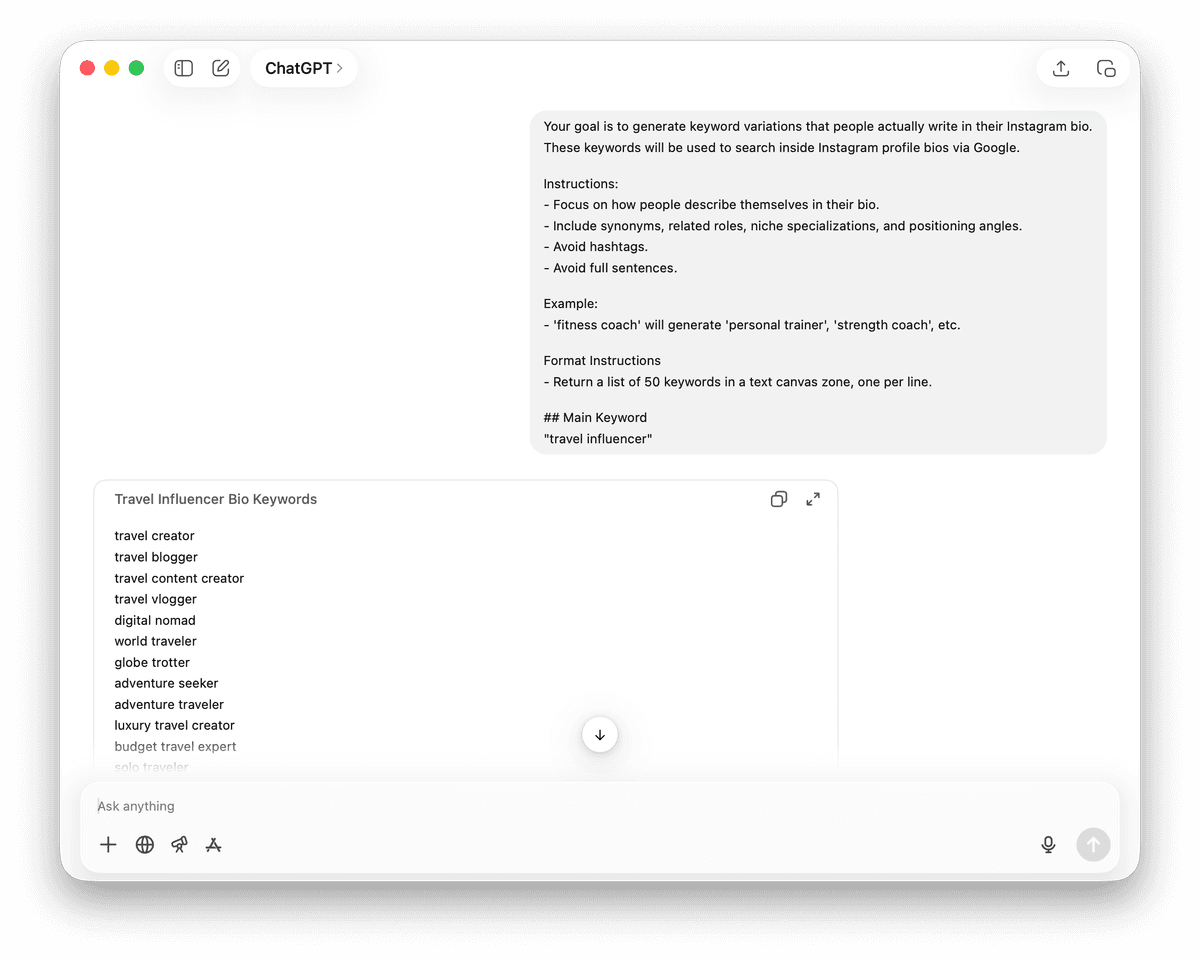
这些关键词将用于通过 Google 搜索 Instagram profile bio。
## 要求:
- 聚焦用户如何在 bio 中描述自己。
- 包含同义词、相关角色、细分领域专长和定位表达。
- 不要使用 hashtag。
- 不要输出完整句子。
## 示例:
- 'fitness coach' 可扩展为 'personal trainer'、'strength coach' 等。
输出格式要求:
- 在文本区域中返回 50 个关键词,每行一个。
## 主关键词:
"travel influencer"
说明:你可以根据需要调整这个 prompt,生成更多关键词,或者从其他维度扩展变体。
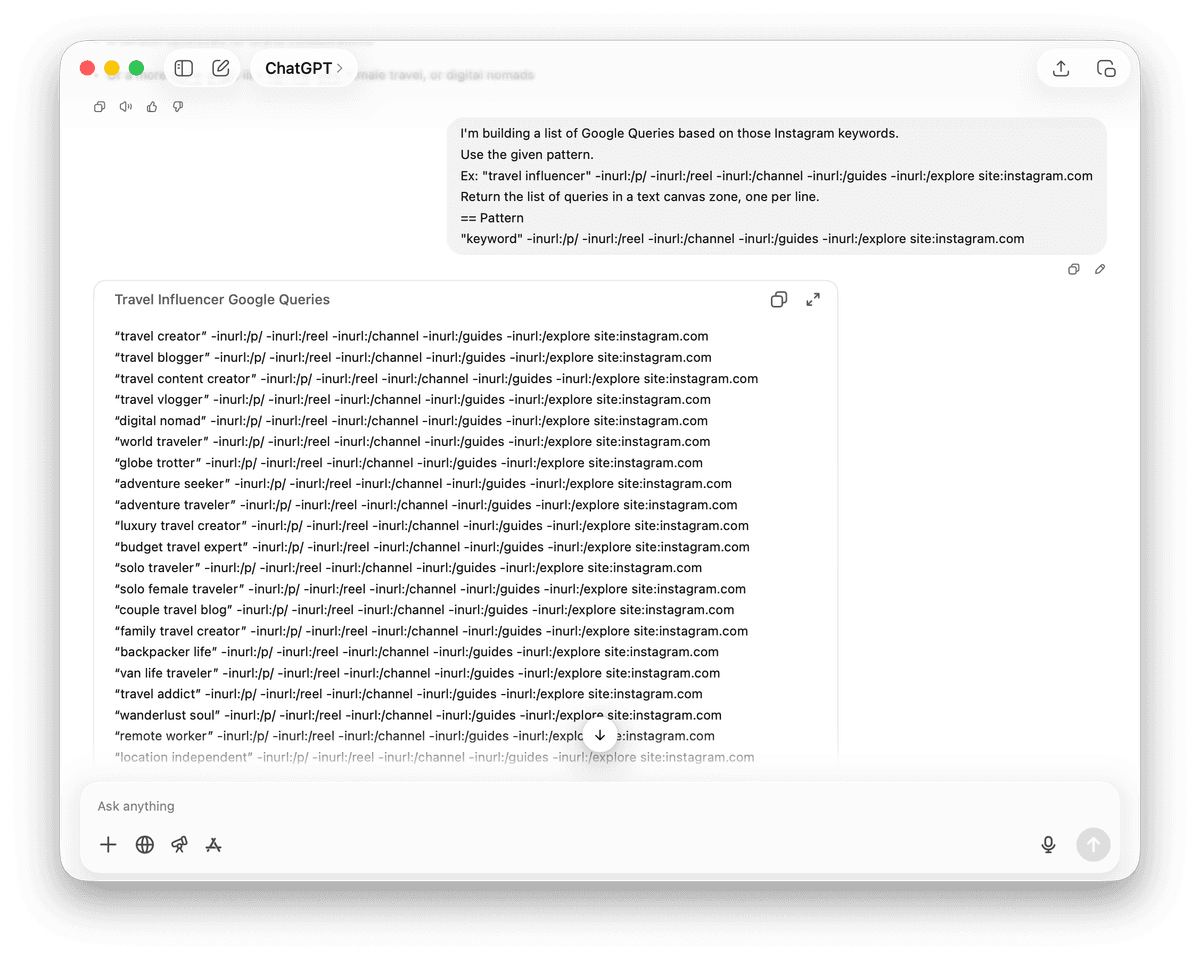
拿到这份关键词列表后,再用 LLM 生成对应的 queries。
请使用下面给定的模式。
示例: "travel influencer" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
请在文本区域中返回 query 列表,每行一个。
## 模式
"keyword" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
打开 Datablist,然后点击侧边栏里的 “Start from data source”。
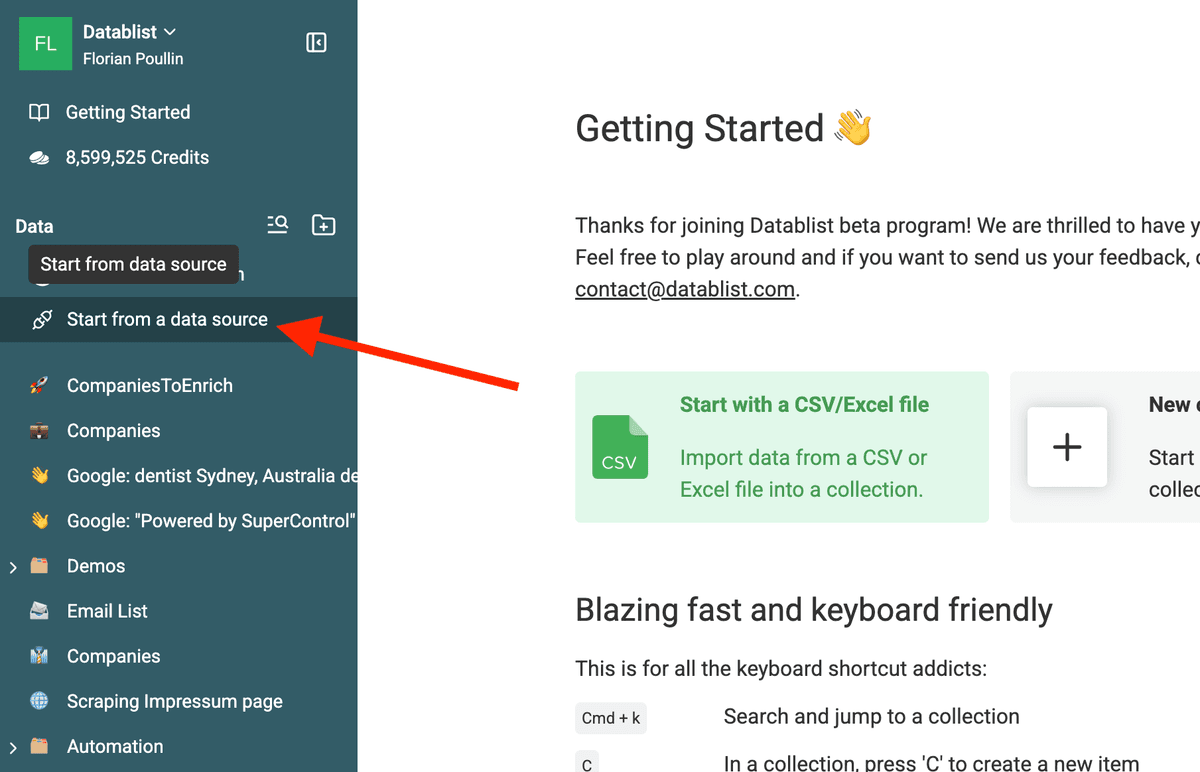
选择 Google Search Queries 这个 data source。

把刚才生成的 queries 粘贴进去。
你也可以根据目标国家或地区,调整搜索设置,以便更精准地抓取本地化 profile。
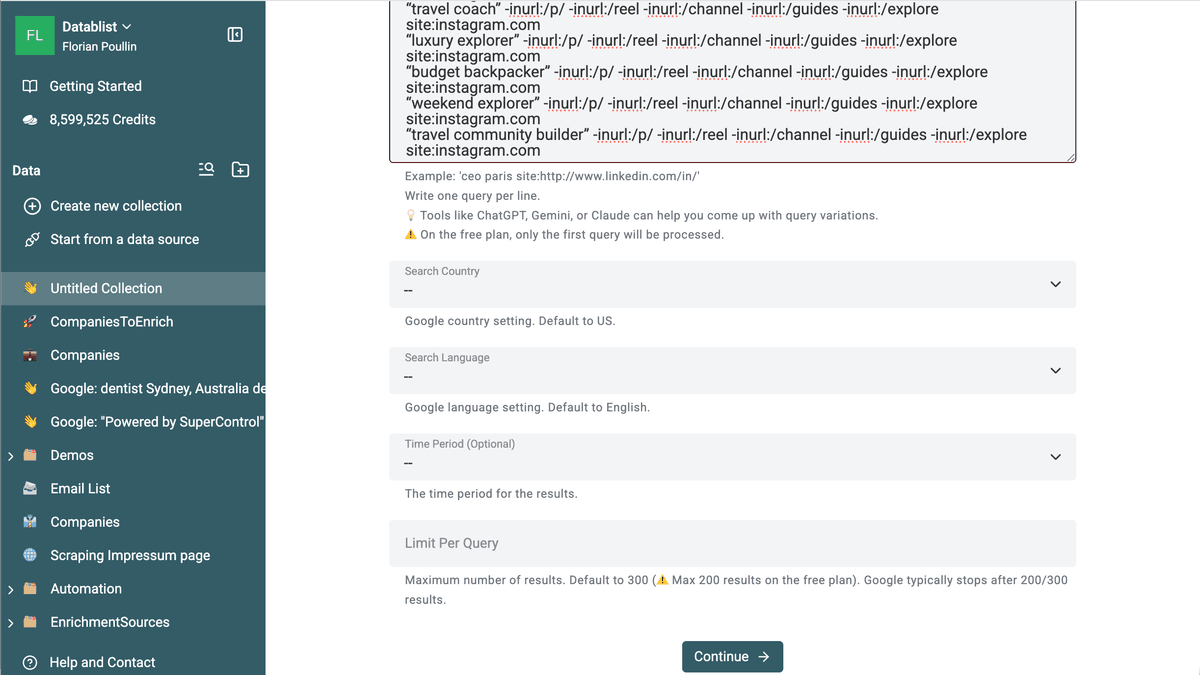
运行 Google Queries scraping。
然后按照后面介绍的清洗、去重与 enrichment 步骤继续操作。
按 Instagram Categories 搜索 Instagram Profiles
这个方法还有另一种非常实用的玩法:不是按关键词搜,而是按 categories 搜 Instagram profile。
Instagram business account 会使用 category 标签,而这些标签通常和你想找的目标账号高度相关。

💡 先拿到英文版 Business Category 名称
访问 Instagram 的 business profile 页面,获取真实的 category 名称示例。
如果你的浏览器使用的是其他语言,Instagram 会显示翻译后的 category 名称。对于 Google 搜索,请始终使用英文 category label。
如果想强制显示英文,可以在 profile URL 后加上?locale=en或?hl=en,并在退出登录状态或隐身模式下访问。你也可以参考这篇教程:force a language when visiting a Instagram Profile。
Instagram 拥有成千上万的层级 categories。每一个大类、子类、再往下的细分类,都是很好的 Google query 变体来源。
例如:
- Broad category = Apparel & Clothing
- Subcategory = Women’s Clothing Store
- Sub-subcategory = Sustainable Women’s Clothing
每一层分类都会打开新的搜索角度。通常我们会让 LLM 一次生成上百个相关 categories,然后把它们批量送入 Google Search。
返回 100 个 categories。
请在文本区域中输出列表,每行一个。
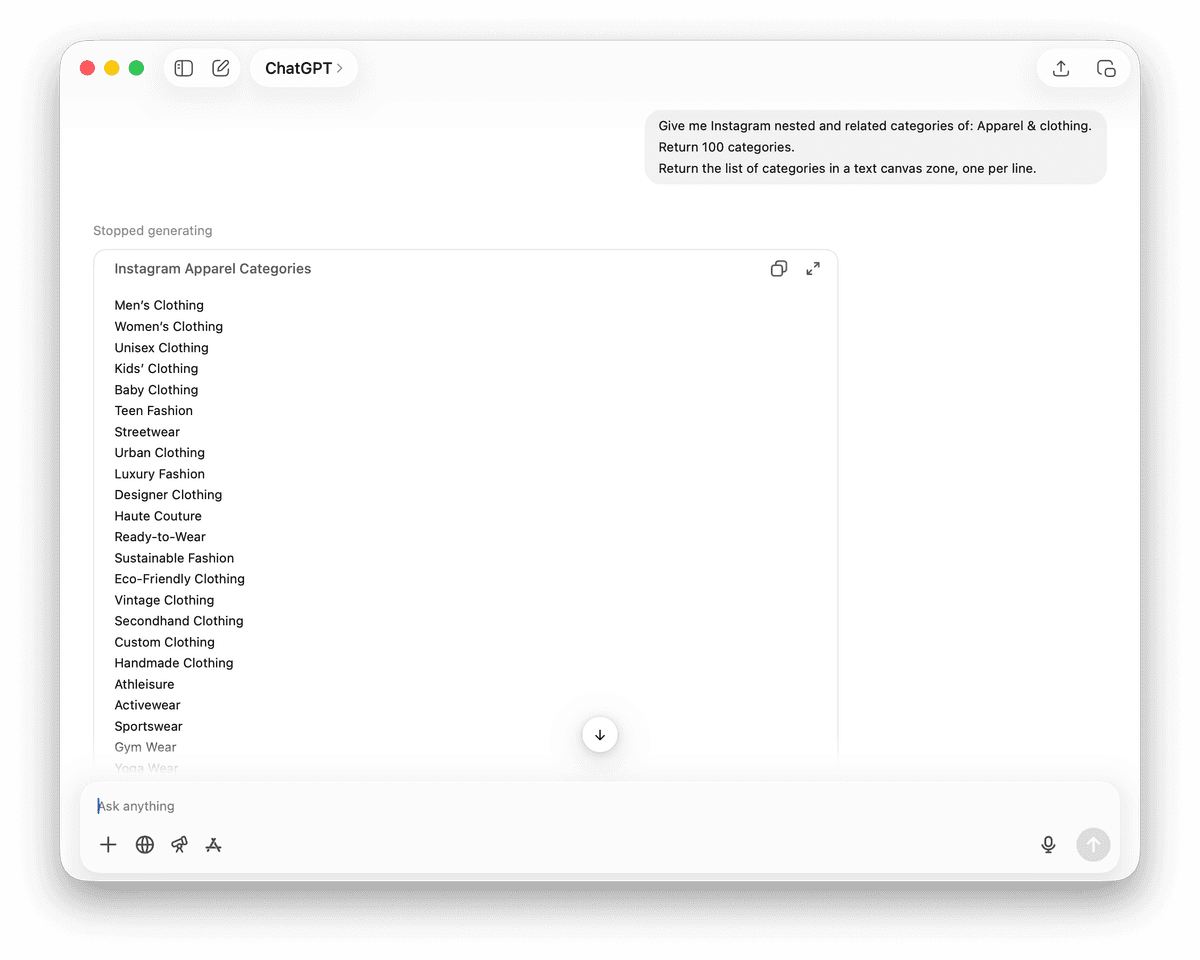
拿到 categories 列表后,再生成 queries。
请使用下面给定的模式。
示例: "Apparel & Clothing" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
请在文本区域中返回 query 列表,每行一个。
## 模式
"Category" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
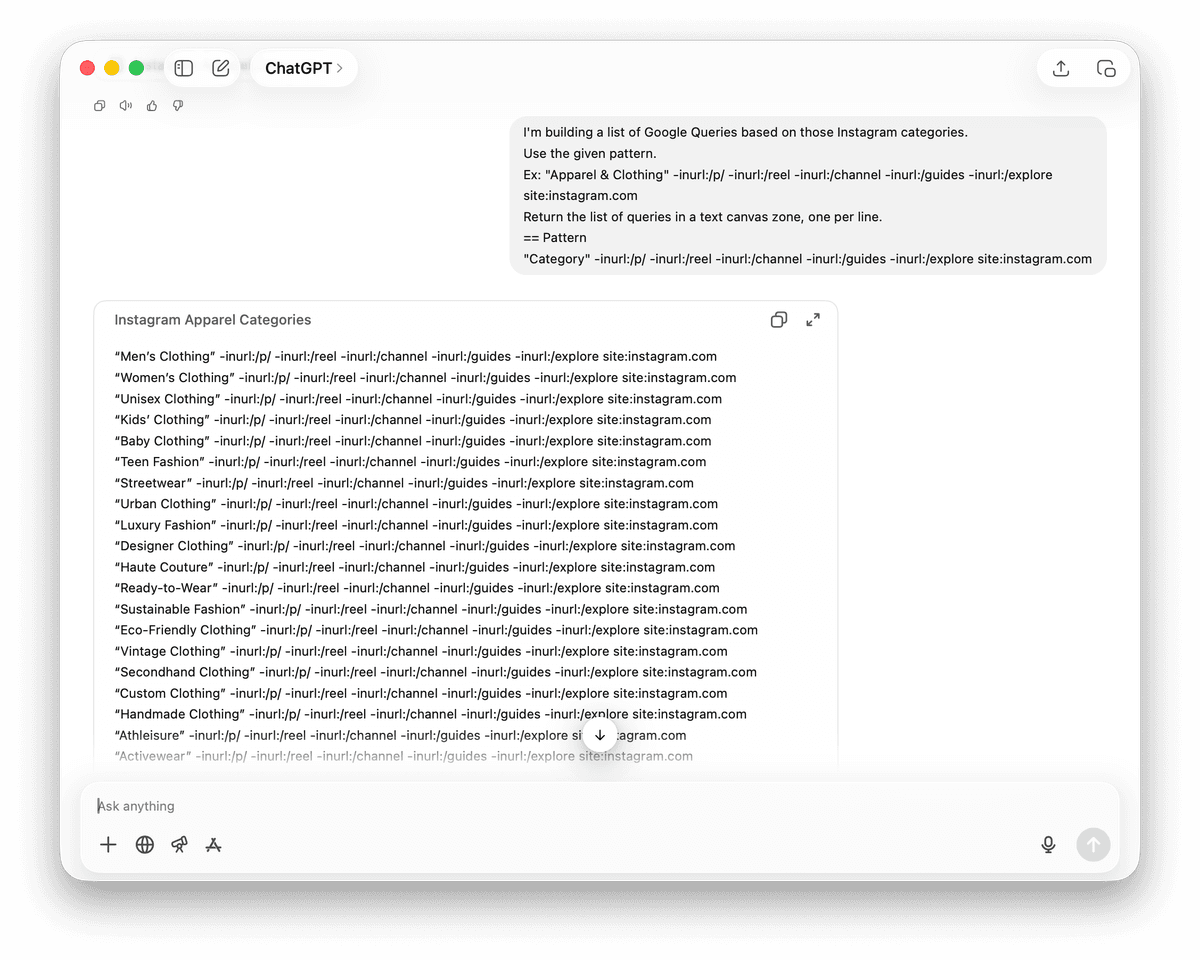
打开 Datablist,并点击侧边栏中的 “Start from data source”。
选择 Google Search Queries 这个 data source。
粘贴 queries。如果你的目标是某个国家或地区的账号,记得同步调整搜索设置。
运行抓取工具。完成后,再进行清洗、去重和 enrichment。
清洗结果
Google Bulk Queries Scraper 在返回正确结果的同时,也可能带来一些无关页面和重复 profile。
所以,在对每个 Instagram profile 做 enrichment 之前,你需要先在线清洗 web scraping 数据,把无效结果和重复项清掉。
清洗步骤 1:移除非 Profile 结果
展开 Result URL 列,检查那些明显不符合 Instagram profile 特征的路径。使用过滤工具,把不符合 profile 规则的结果筛出来并删除。
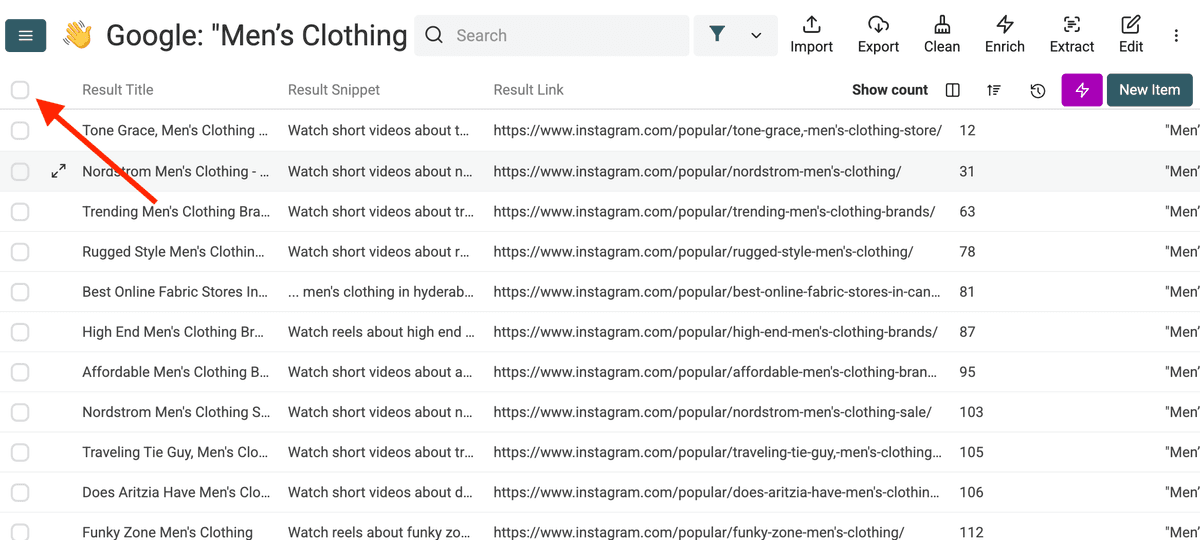
例如,在这个例子里,我们拿到了一些以 /popular 开头的 Instagram URL。它们不是 profile,需要删除。
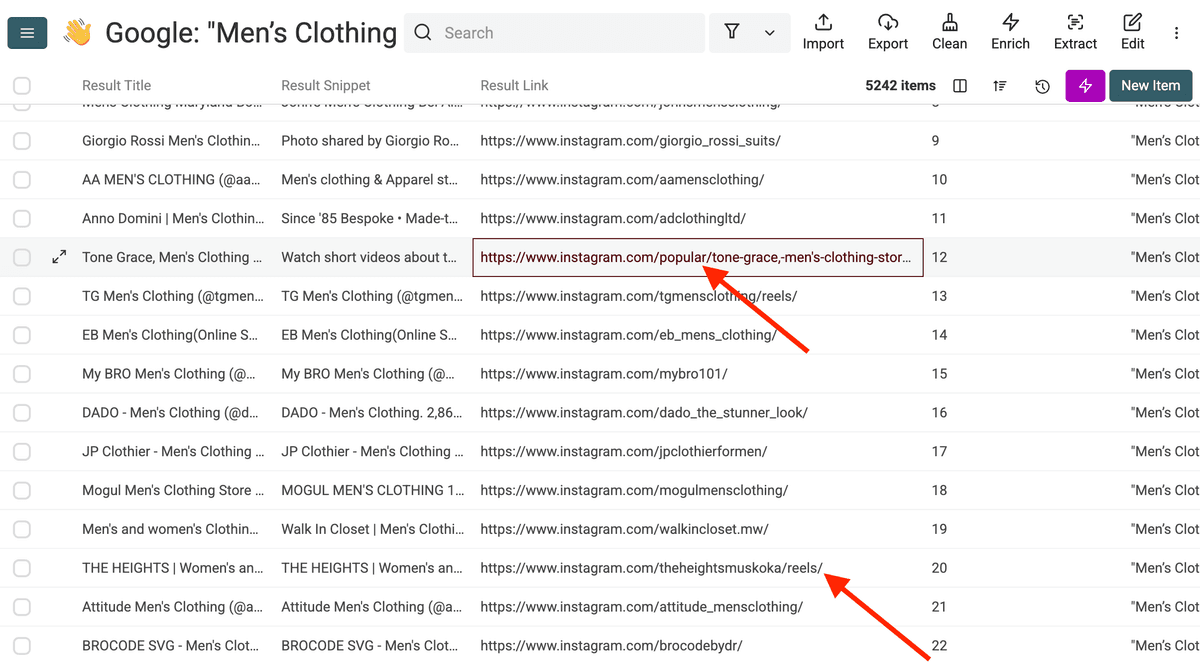
使用过滤工具,按路径关键词批量列出这些项目。
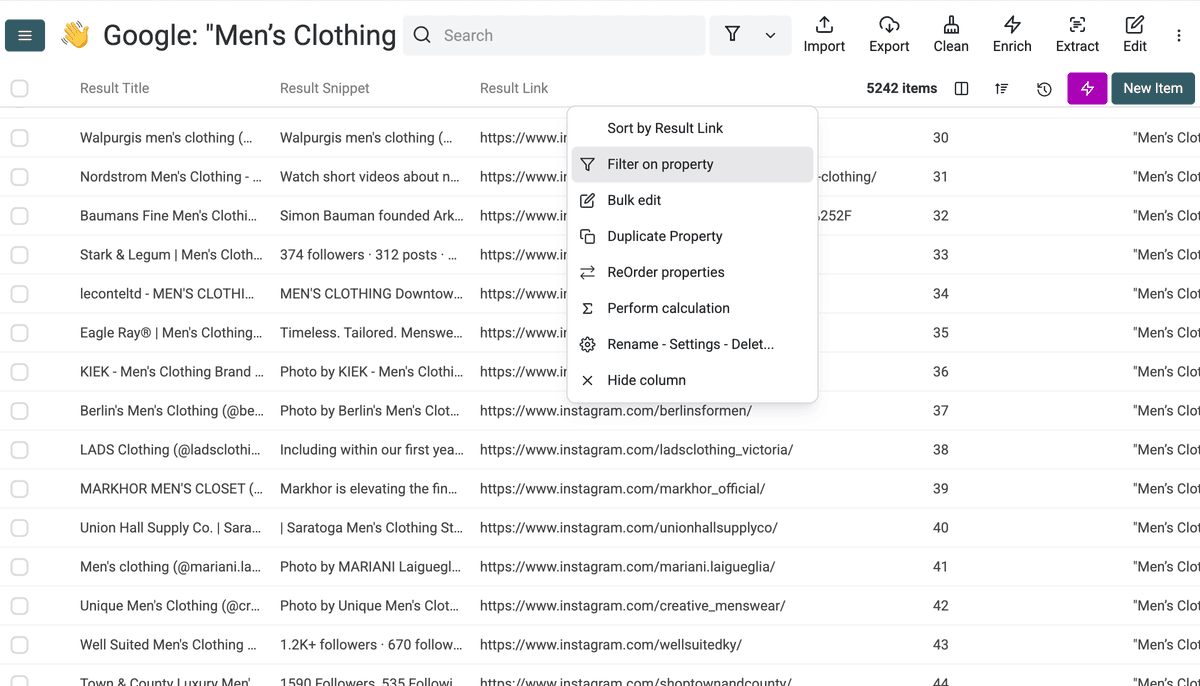
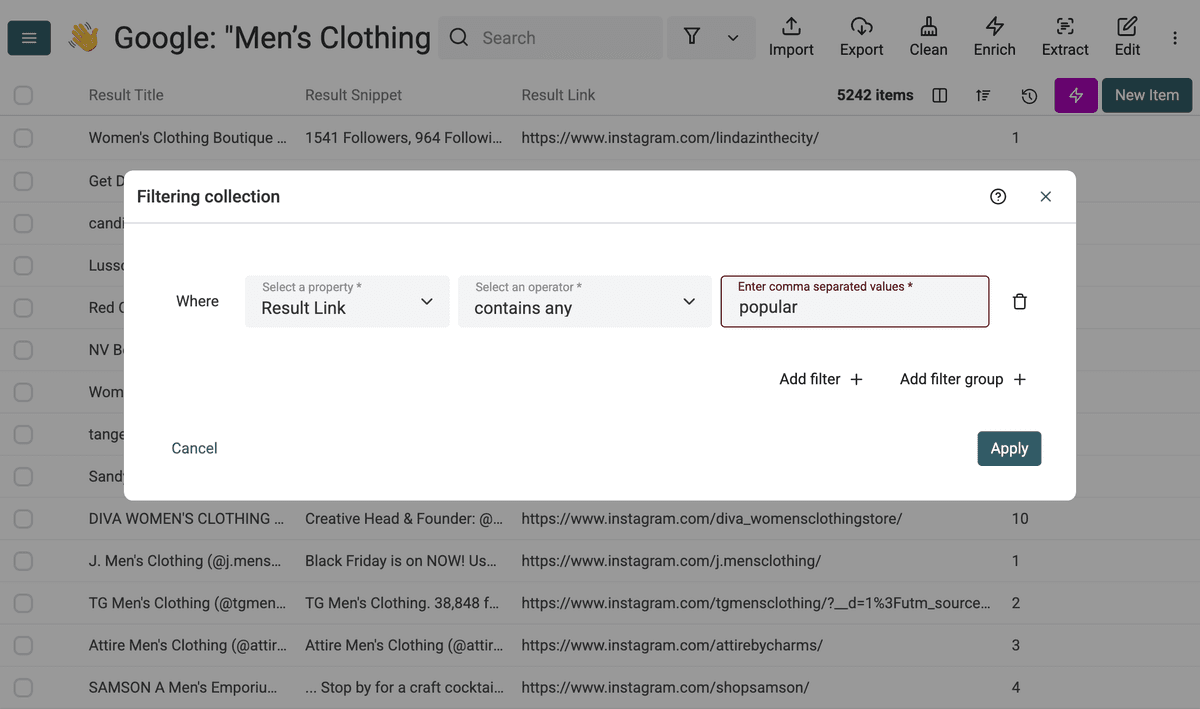
然后直接删除这些记录。
在这个例子中,我们还发现有些 Profile URL 后面多了一段 /reels/。
为了得到标准的 Instagram profile URL,我们需要把这部分去掉。
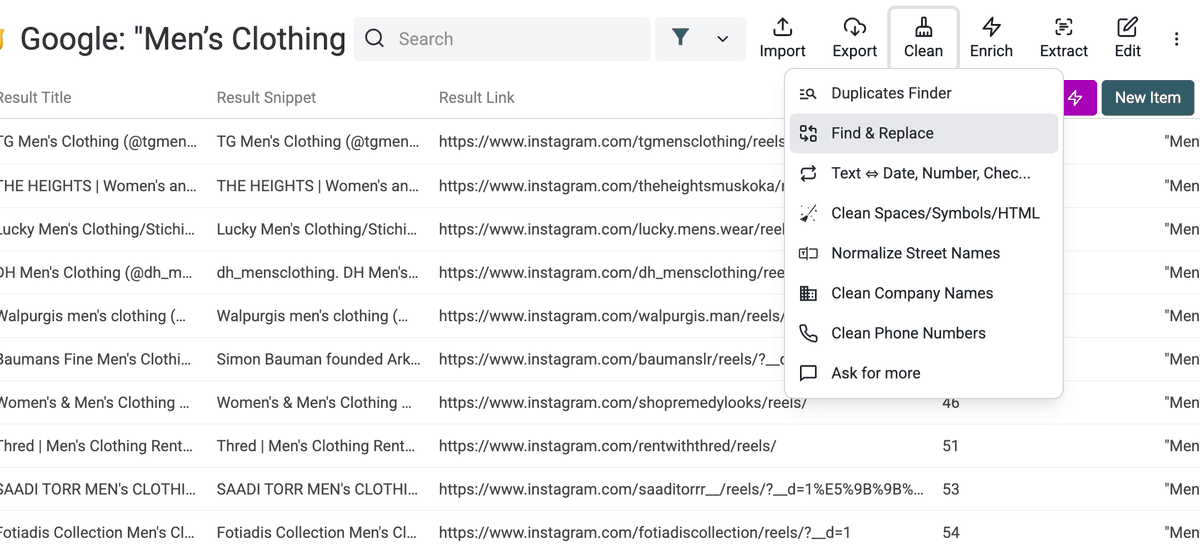
点击 Clean,再点击 Find & Replace。
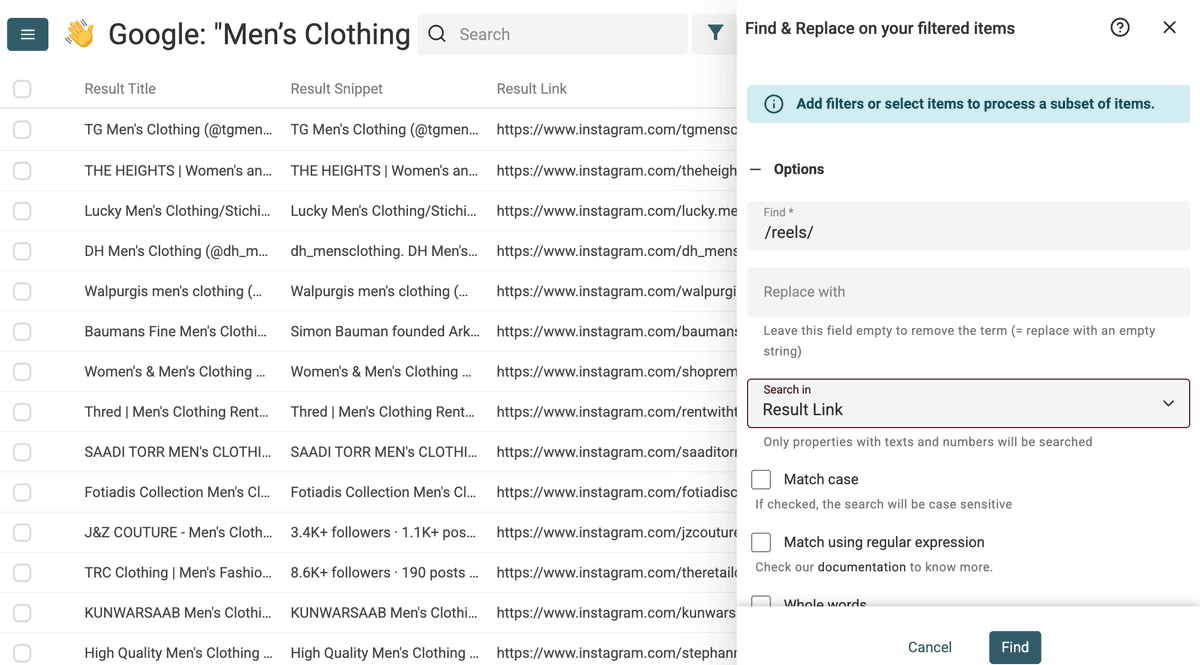
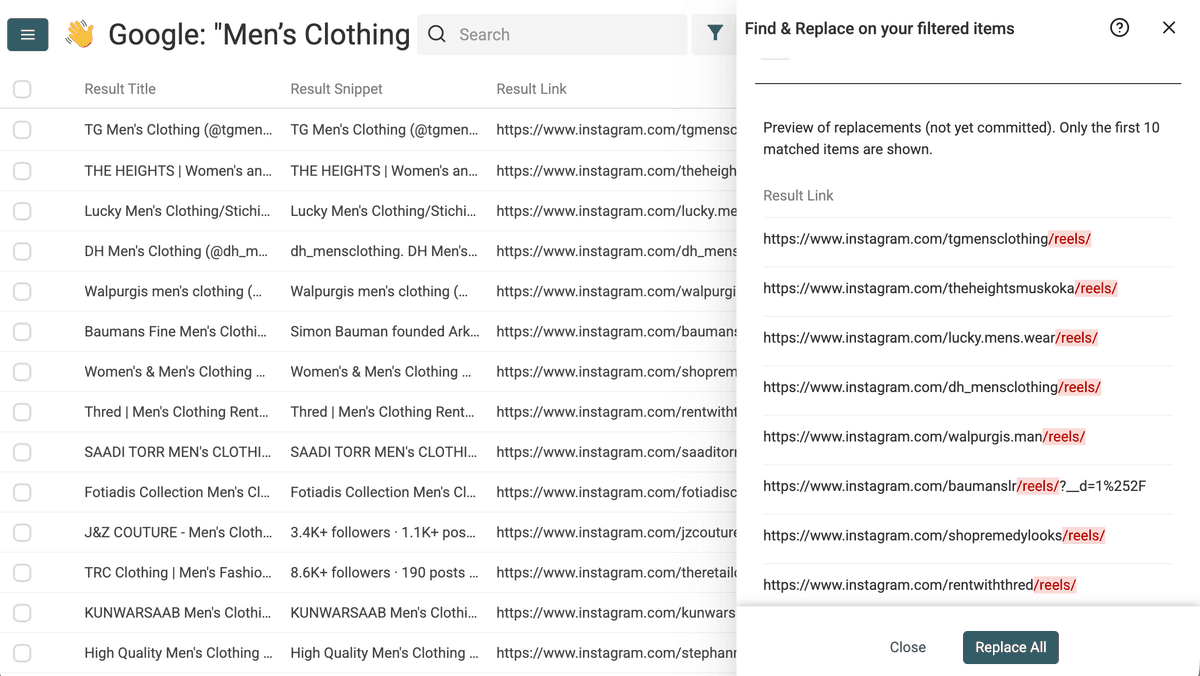
查找 /reels/,替换为空字符串。
清洗步骤 2:去重
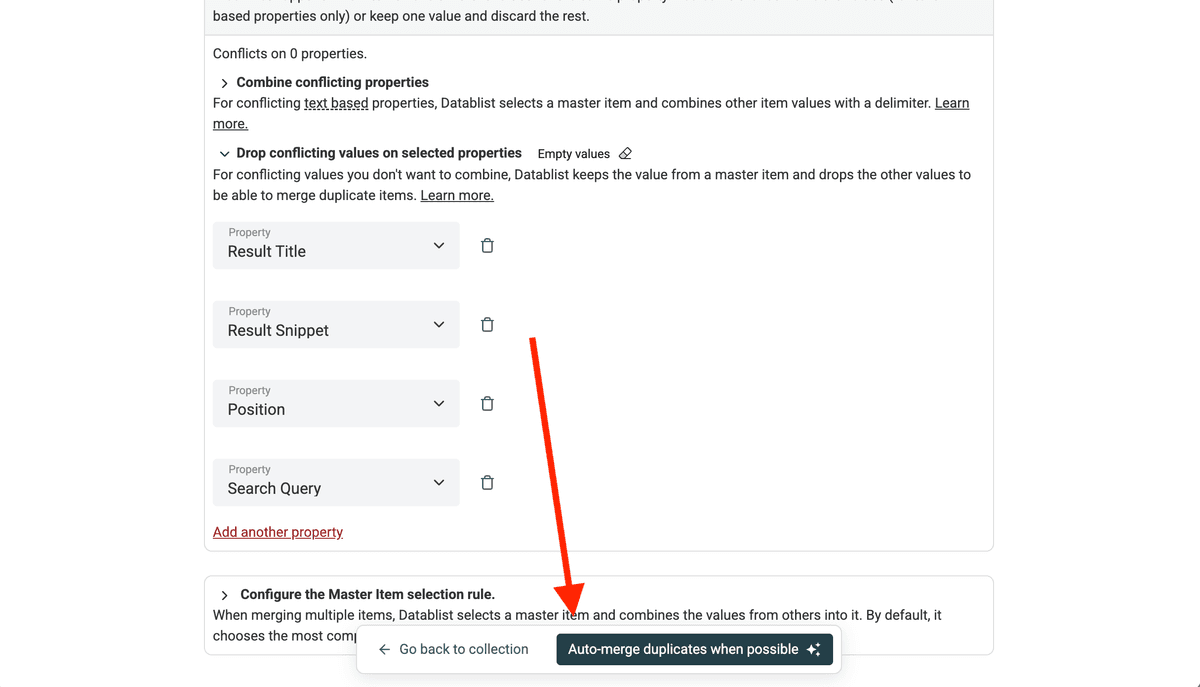
结果出现重叠其实是好事,说明同一个优质 profile 能在多个搜索角度下被命中。为了只保留一份记录,你需要做 deduplication。可以直接使用 Clean - Duplicates Finder 工具来查找并删除重复项。
点击 Clean -> Duplicate Finder 打开去重工具。把 Result URL 设为唯一标识字段。只要 profile URL 相同,就会被识别为重复。
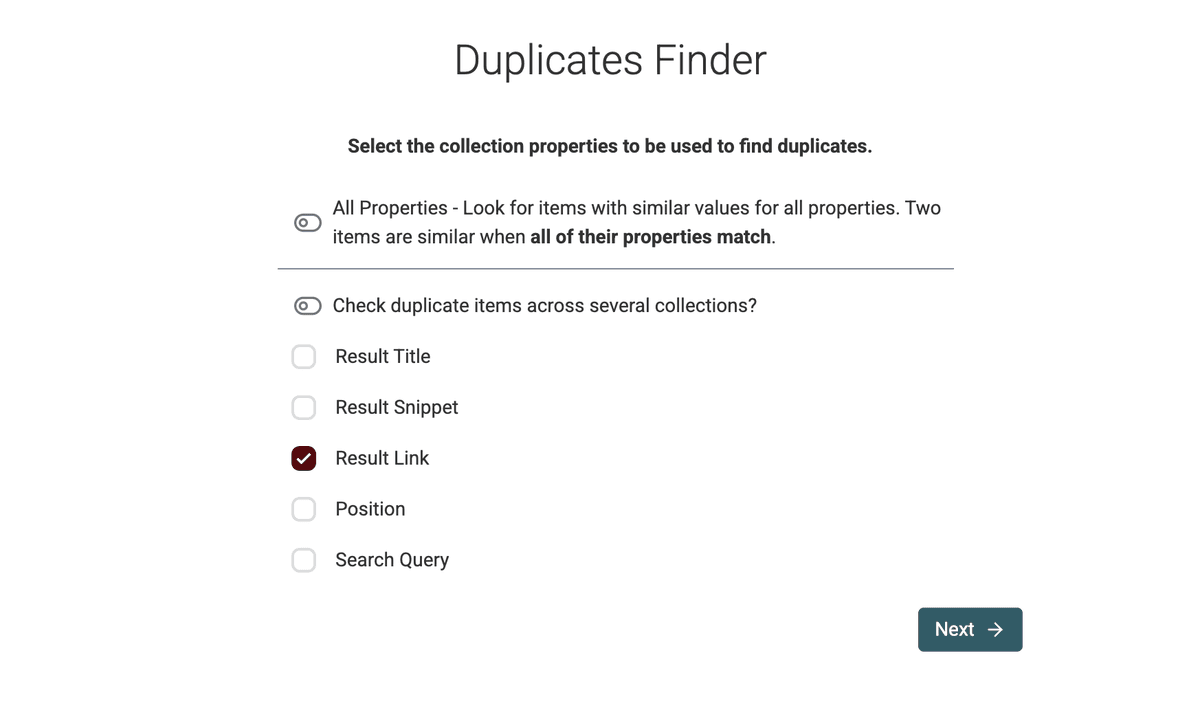
接下来,在下一步设置里选择 URL preprocessor,并开启 “Ignore Query Params” 选项。这样即使两个 profile URL 带有不同的 tracking query parameters,也能被识别为同一个 URL。
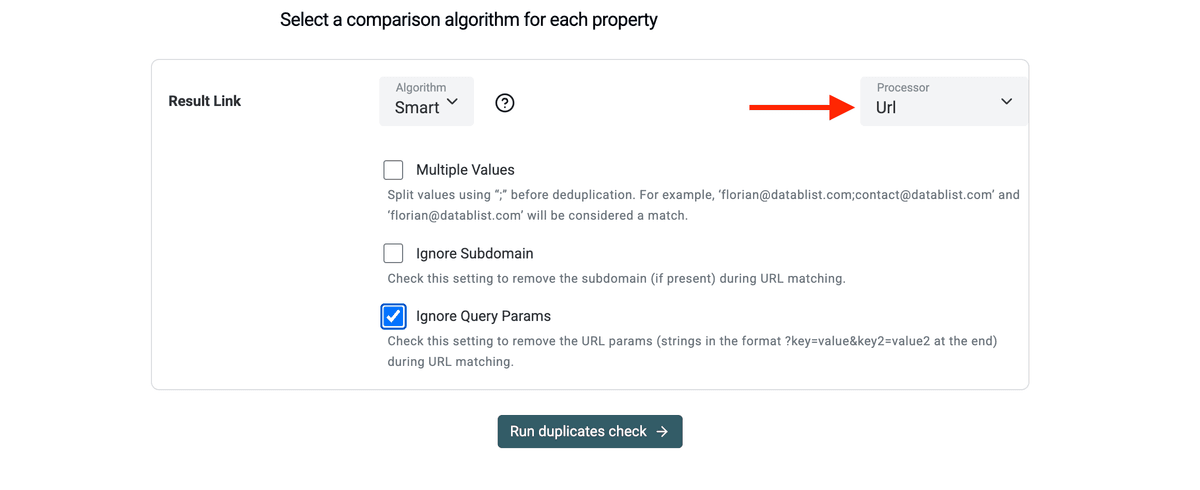
当你看到重复列表后,点击 Drop Conflicting Values。
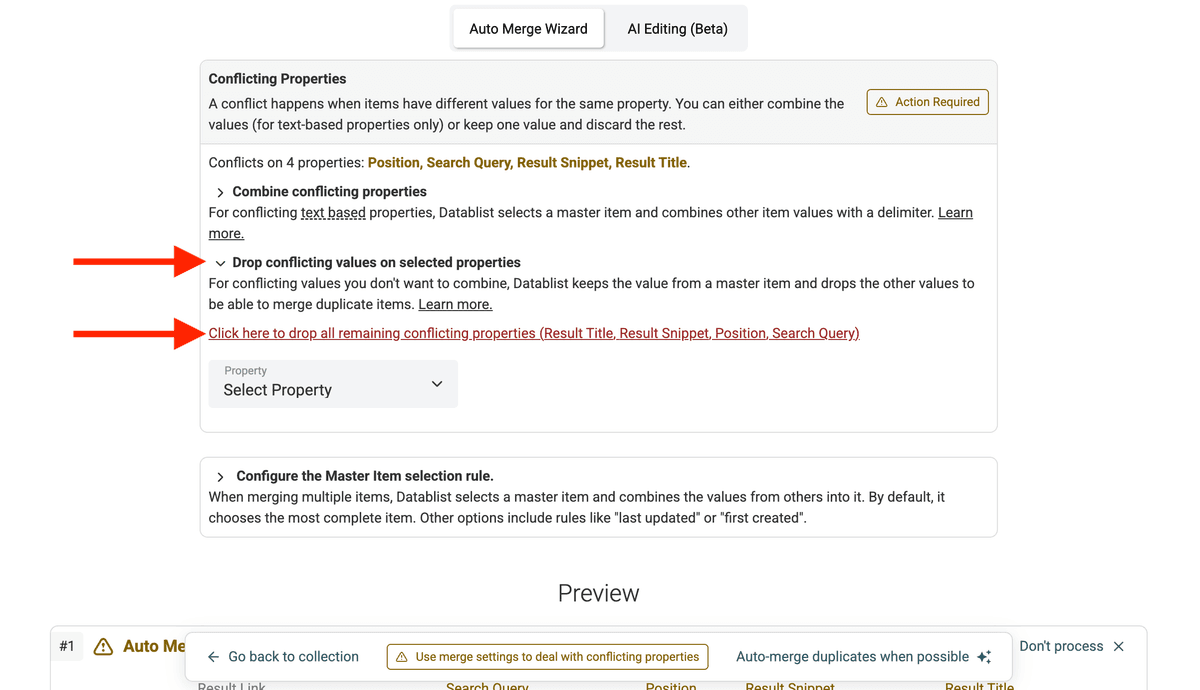
然后用新设置刷新。
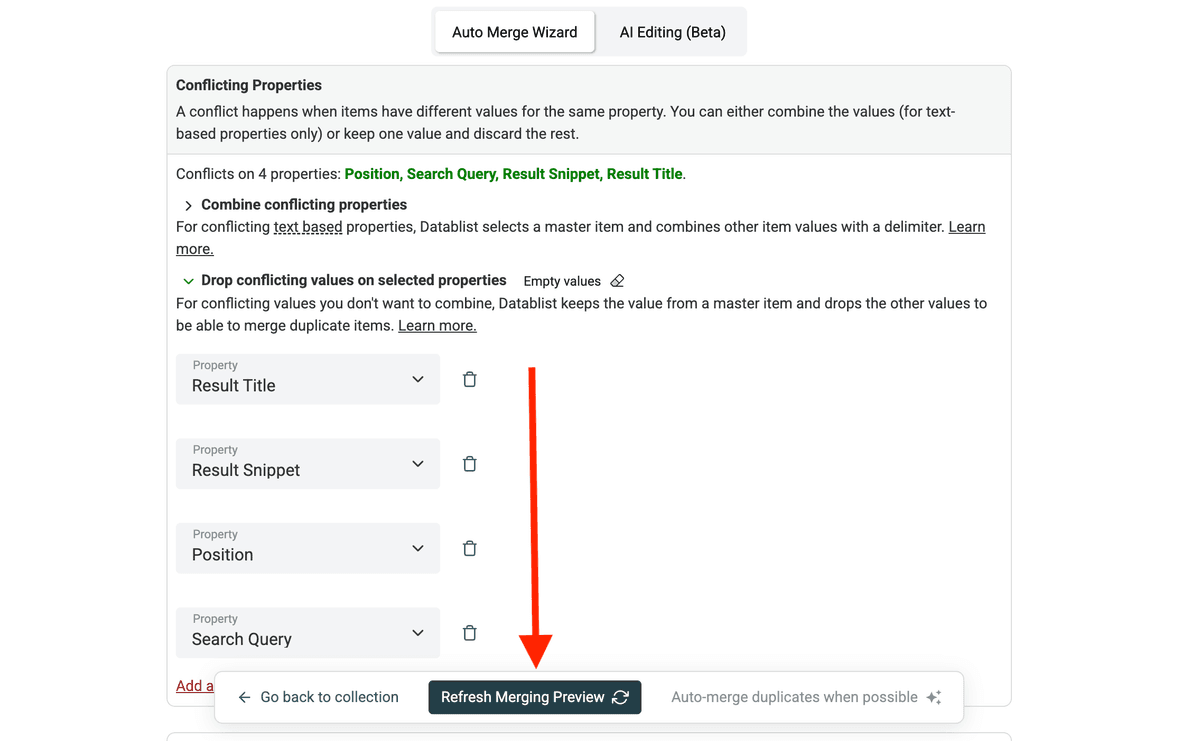
确认预览无误后,点击 Auto Merge。
抓取完整 Instagram Profile 数据
Google Queries Scraper 只负责“发现目标”这一层:它返回的是 result title、URL 和 snippet。也就是说,这一步只是帮你拿到 profile URL,并不会直接提取结构化的 Instagram 数据。
下一步就是 enrichment。Enrichment 会访问每个 profile URL,并直接从 Instagram 提取结构化信息。如果你想拿到完整数据集,就需要使用我们的 Instagram Profile Scraper。
你可以提取的数据包括:
- Bio
- Public email
- Followers count
- Following count
- External link
- Category
有了这些字段后,你就可以按粉丝数筛选、按是否公开邮箱筛选,或者区分 influencer 与小型 creator。
点击 Enrich,然后搜索 Instagram Profile Scraper。
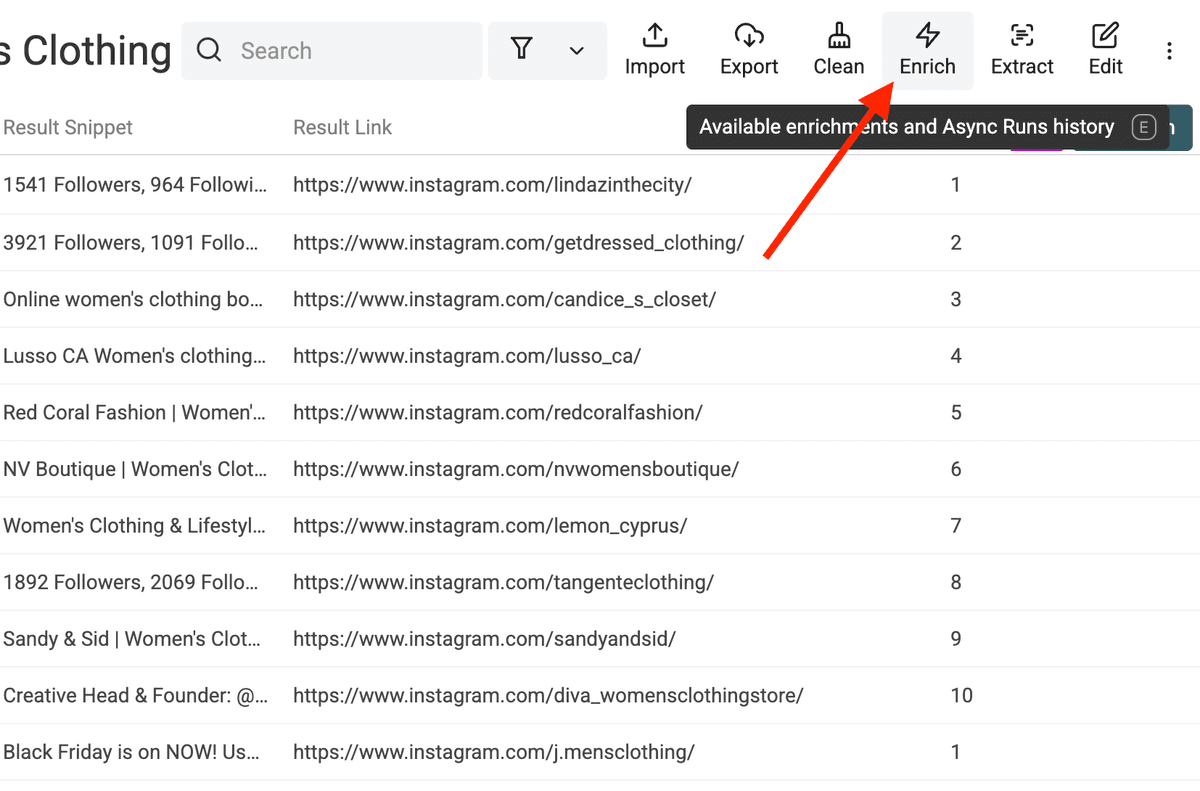
选择 Instagram Profile Scraper。
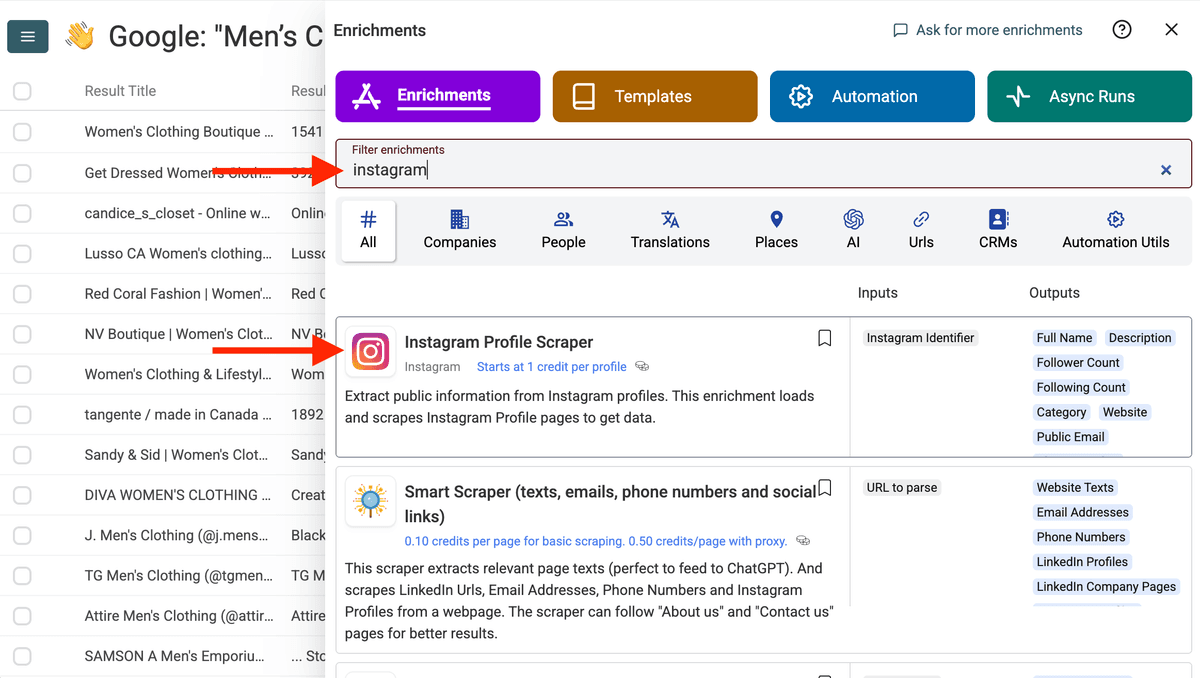
选择你偏好的 Instagram scraper。查看每个 scraper 的设置说明,了解它能提取哪些字段。
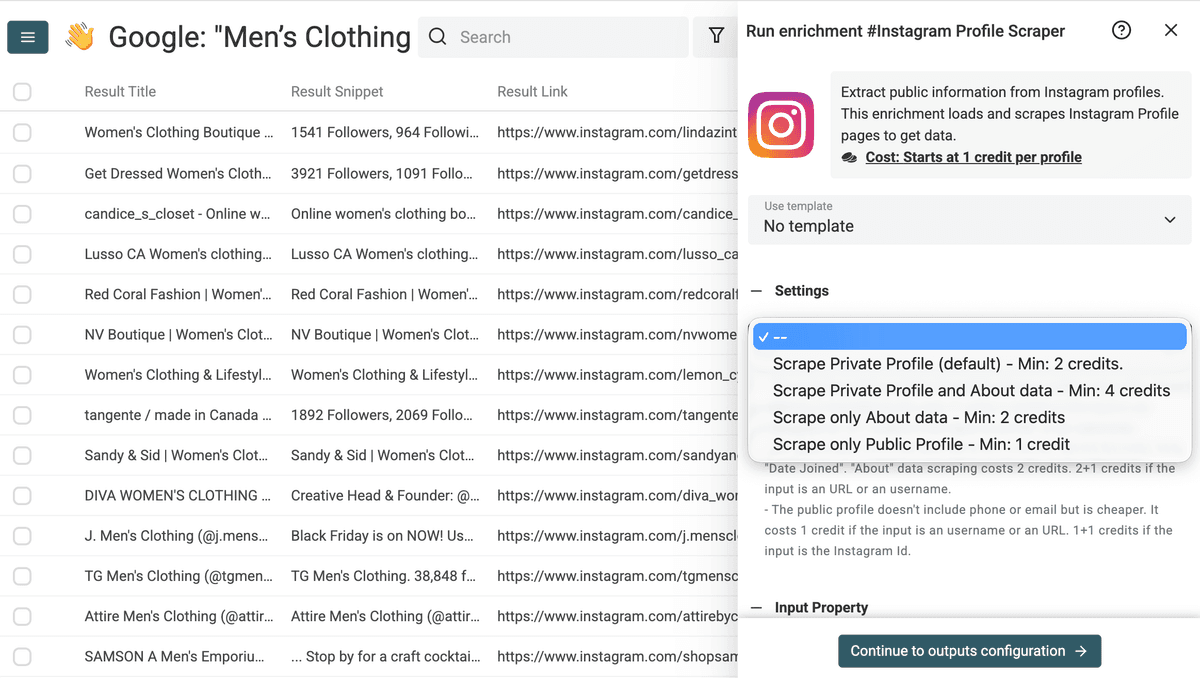
把输入字段映射到包含 Instagram Profile URL 的 Result Link 列。
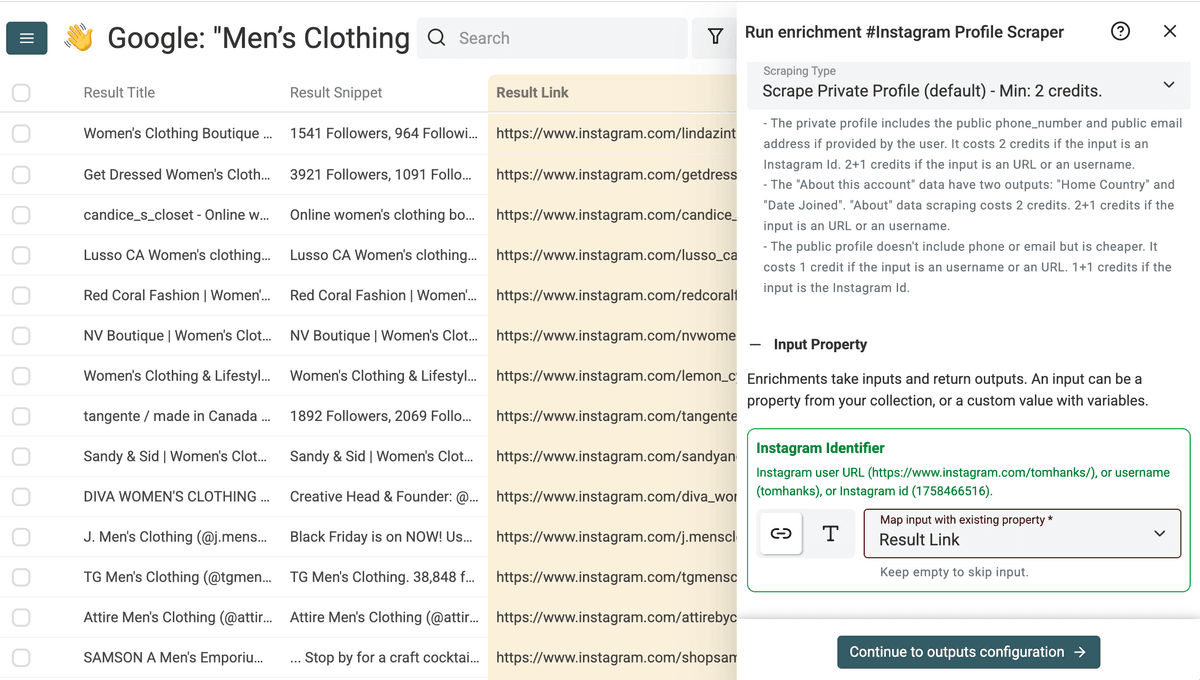
使用 Add all XXX outputs to collection,把 scraper 的输出字段全部加入你的 collection。
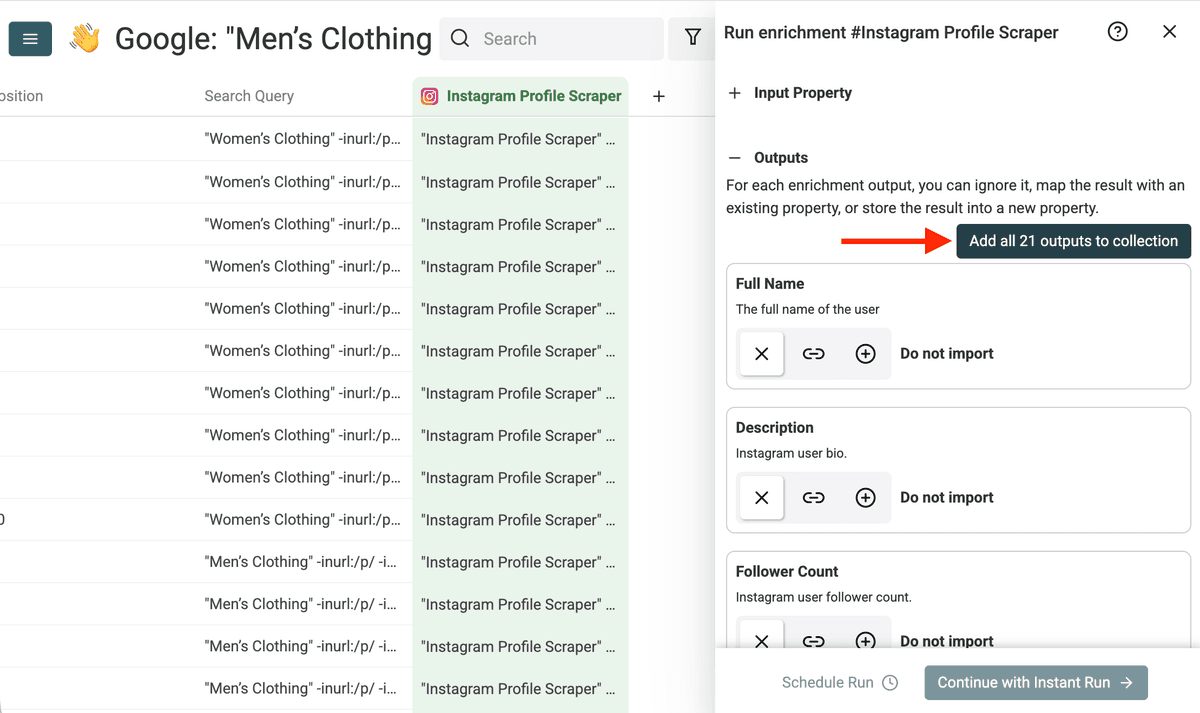
这样,Instagram profile 的各项数据就会作为新列加入 collection。
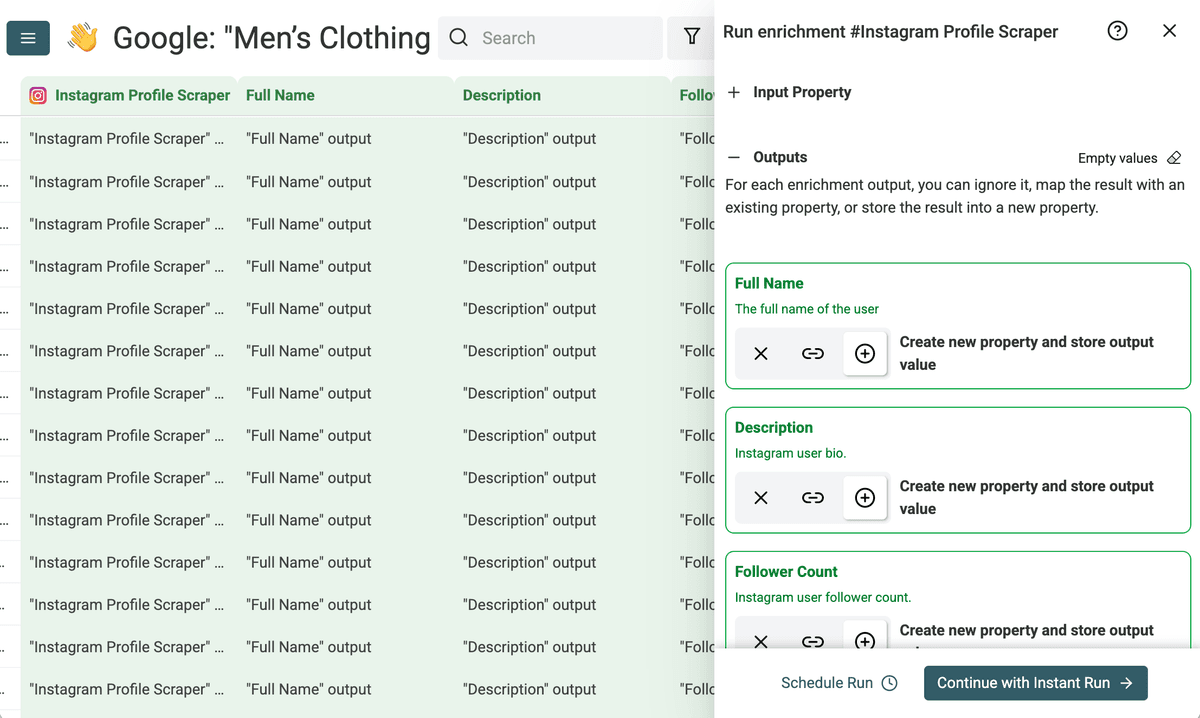
先对前 10 条记录运行 scraper。
如果前面的结果看起来正常,说明 scraping 配置没问题,再继续跑剩余 profile。
价格说明
关于价格,你需要知道以下几点:
- Datablist Google Queries scraper 的费用是:每 10 条 Google 结果消耗 2.5 credits。
- Datablist 提供月度订阅,起价为 25 美元/月,另外也有 credit package。第一个 credit package 的价格是 1 美元可获得 1000 credits。
- 清洗和 deduplication 已包含在订阅内。
- 我们的 Instagram Profile enrichment 起价为每个 profile 1 credit,也就是 1 美元大约可 enrich 1000 个 profile。
💡 先清洗,再做 enrichment 每 enrich 一个 profile 都会消耗 credits。若你把重复 URL 或无效 URL 也拿去 enrich,就是在白白烧钱。正确做法是:先清掉垃圾数据和重复项,再把 credits 只花在真正有效、唯一的 profile 上。
价格示例
- 从 Google 抓取 400 个 profile = 1 美元
- 使用 Instagram Profile Scraper enrich 400 个 profile URL = 0.40 美元
- 总成本 = 1.40 美元
其他实战示例
下面是 3 个可以直接照着做的例子:
示例 1:查找并抓取 Yoga Influencers
如果你想建立一份与瑜伽相关的 influencer、yoga studio 或 yoga coach 名单,可以直接按下面这个流程来做。
第 1 步:生成关键词与 Category 变体
我们的目标是找出:一组常见于 bio 的瑜伽相关关键词,以及一组和瑜伽相关的 Instagram business categories。
请生成:
1) 50 个常见于 Instagram bio 的 yoga 相关关键词
2) 50 个与 yoga 相关的 Instagram business categories
请在文本区域中以两个独立列表返回结果。
每行一个项目。
你可能会得到类似 yoga instructor、certified yoga teacher、wellness studio、holistic wellness coach 这样的变体。每一个词,都是一个新的搜索入口。
第 2 步:生成全部 Google Queries
拿到关键词和 categories 列表后,就可以自动生成 Google queries。
请使用下面这个模式:
"Keyword" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
请基于下面的列表,每行生成一个 Google query。
不要添加解释。
只返回 query,并放在文本区域中。
## 列表:
[你的 yoga 关键词和 categories 列表]
你可以把这些 query 全部粘贴到 Datablist Google Queries Scraper 中。
第 3 步:抓取、清洗、去重
每个 query 最多返回 250 个结果。
如果你生成了 80 个瑜伽相关变体,就最多可以拿到 16,000 条原始 URL。删除非 profile URL,并完成 deduplication 后,你通常能保留几千个唯一的瑜伽相关 Instagram profile。
第 4 步:Enrich 并做分层筛选
清洗完成后,运行 Instagram Profile Scraper enrichment。
这时你就可以:筛选粉丝数超过 10,000 的 influencer,保留公开 email 的账号,区分 yoga studio 和个人教练,并按 bio 关键词(如 online classes)做更细的分组。
示例 2:查找细分领域 Micro Influencers
如果你要建立的是细分 niche 的 micro-influencer 名单,流程就需要更聚焦一些。假设你的 niche 是 vegan skincare,你的目标是找到这个细分赛道里的小体量 creator,而不是泛泛的美妆 influencer。
第 1 步:生成细分领域关键词与 Category 变体
这里我们需要两类变体:一类是这个 niche 中 micro-influencer 常写在 bio 里的关键词;另一类是与该 niche 相关的 Instagram business categories。
请生成:
1) 50 个这个 niche 中常见的 bio 关键词
2) 50 个与该 niche 相关的 Instagram business categories
请在文本区域中返回两个独立列表。
每行一个项目。
你可能会得到这样的变体:vegan skincare blogger、clean beauty creator、cruelty free skincare、eco beauty influencer、plant based skincare expert、sustainable beauty advocate。
每个变体,都是一个新的发现路径。
第 2 步:生成全部 Google Queries
使用标准的 Google 模式:
"Keyword" -inurl:/p/ -inurl:/reel -inurl:/channel -inurl:/guides -inurl:/explore site:instagram.com
为每个关键词和 category 生成一条 query。这样你就拥有了几十个搜索角度,专门定位这个 niche 下的小型 creator。
第 3 步:抓取、清洗、去重
把所有 query 粘贴进 Datablist Google Queries Scraper。这个工具会返回数百甚至数千条 profile URL。接下来,删除那些不符合 profile 特征的 URL,再清除重复项。重叠非常常见,因为优质 profile 往往会在多条 query 中同时出现。
第 4 步:Enrich 并筛选 Micro Influencers
运行 Instagram Profile Scraper enrichment。
现在你可以:
- 按粉丝数筛选 1,000 到 20,000 的账号
- 保留公开 email 的 profile
- 搜索 bio 中是否包含
UGC、collab或DM for partnership - 按国家或语言进行分组
这样你就能得到一份干净的 niche micro-influencers CSV,可直接用于 outreach。
示例 3:查找特定细分领域的教练账号
像 business coach 这样的宽泛词,通常只会带来非常泛的结果。真正更有价值的,往往是更窄的 niche,比如 Notion productivity coach、ADHD business coach,或者专做创业者 breathwork 的教练。你可以按照下面这些步骤来建立自己的 lead list。
第 1 步:把细分 niche 扩展成 Bio 关键词
先从你的窄 niche 出发。
请生成 50 个这些教练常写在 bio 中的关键词。
每行一个。
不要添加解释。
你可能会拿到这样的结果:ADHD productivity coach、neurodivergent entrepreneur mentor、focus coach for founders、executive function coach。每个关键词都对应一条新的搜索路径。
第 2 步:加入 Instagram Business Categories
接着让 LLM 生成相关的 Instagram business categories,例如 Business Coach、Mental Health Service、Consultant、Education。把 categories 和 bio 关键词结合起来,覆盖面会更大。
第 3 步:生成并抓取 Google Queries
按同样的模式,为每个关键词和 category 各生成一条 Google query。然后用 Datablist Google Queries Scraper 批量抓取。
第 4 步:清洗并 Enrich
删除非 profile URL,并对重叠结果做 deduplication。然后 enrich profile,提取 bio、category、followers 和 email。接下来你就可以按 bio 中的精确 niche 关键词筛选、按最低粉丝数筛选,或者按更细的子领域打标签。这样,一个非常小的 niche,也能被你转化成一份结构化、可筛选、可直接用于合作、研究或 lead generation 的优质教练名单。
总结
这个工作流提供了一种简单、可重复、可规模化的方法,帮助你通过关键词和 Instagram categories 查找并抓取 Instagram profile。
完整流程如下:
- 生成关键词变体。
- 构建 Google queries。
- 使用 Google Queries Scraper 抓取结果。
- 删除非 profile URL。
- 对列表去重。
- Enrich Instagram profiles。
FAQ
用 Google 做 Instagram scraping 合法吗?
Instagram scraping 是否合规,取决于你如何收集和使用数据。本文的方法只会访问 Google 已索引的公开 profile 页面。你仍需自行确保符合当地法律法规以及 Instagram 的平台条款。请始终以合规、克制的方式使用数据,避免 spam。
我能直接在 Instagram 里按关键词搜索 profile 吗?
不能。Instagram 对 bio 内的高级关键词搜索限制很多。你可以搜索用户名或 hashtag,但无法大规模检索 bio 文本。这也是我们借助 Google 来绕过限制的原因。
为什么不用 Instagram 搜索工具,而要用 Google?
大多数 Instagram 搜索工具价格偏高,而且往往也会限制结果数量和关键词深度,本质上还是会撞上结果上限。把 Google queries 和 no-code scraping tool 结合起来,你能更自由地控制搜索角度,通过扩展关键词来放大发现规模,同时成本更低。
用这个方法大概能找到多少个 Instagram profile?
单条 Google query 最多大约能返回 250 个结果。生成 100 个关键词变体,理论上最多可发现 25,000 条原始 URL。去重之后,通常还能保留几千个唯一的 Instagram profile。搜索角度越多,数据集就越大。Datablist Google Queries Scraping data source 的上限是 90,000 条结果。如果还需要更多数据,可以拆成多个 collections,分批跑 queries。
为什么一定要去重?
结果重叠是非常自然的现象。优质 profile 往往会同时命中多个关键词变体。如果不去重,你会浪费 enrichment credits、浪费人工审核时间,还会让数据失真。去重可以让名单更干净,处理成本也更低。
我可以从 Instagram profile 中提取哪些数据?
通过 Datablist 的 Instagram Profile Scraper enrichment,你可以提取 bio、public email、followers count、following count、external link 和 category。这些数据可以帮助你在 outreach 之前先完成筛选、分层和线索资格判断。
可以按国家筛选 Instagram profile 吗?
可以。如果你想锁定特定国家的 profile,可以在 Google scraping 设置中指定目标国家,或者使用本地化关键词。Instagram Profile Scraper 也会提取 profile 的国家信息,方便你在最终数据集里做进一步过滤。
这个方法能用来找 micro influencers 吗?
可以。完成 enrichment 后,直接按粉丝数筛选即可。比如你可以把 1,000 到 10,000 followers 定义为 micro-influencers。你还可以进一步搜索 bio 中是否出现 UGC、collab 或 DM for partnership。
这个方法只适合找 influencer 吗?
不止。你也可以用它来找本地商家、细分领域教练、B2B prospect list,或者某个特定赛道下的 creator。只要目标 profile 的 bio 里包含相关关键词,就有机会被搜出来。
为什么要用 Datablist,而不是手动做?
手动复制粘贴 Google 结果非常耗时。Datablist 可以把 AI web scraping 自动化并规模化执行:同时跑数百条 Google queries、收集 URL、去重、enrich profile,并导出干净的 CSV。原本非常琐碎的任务,会变成一个结构化、可复用的工作流。
可以把 Instagram profile 导出为 CSV 或 Excel 吗?
可以。完成清洗和 enrichment 后,你可以把 collection 导出为 CSV 或 Excel,用于导入 CRM、团队共享、发起 outreach campaign,或者做进一步数据分析。