

Sainsbury's no ofrece una API pública de productos. Por eso, la mayoría de los equipos que intentan extraer productos de Sainsbury's terminan pagando más de £2000 a un freelance o conectando un scraper de Apify que deja de funcionar a los pocos días.
Lo que muchos no saben es que existe una tercera vía: el AI scraping. Este enfoque lee la página como lo haría una persona, así que la misma configuración sirve para una categoría de Sainsbury's, una página de marca o una página de ofertas, y resiste los cambios de diseño que suelen romper los scrapers tradicionales.
En esta guía verá todo el proceso: por qué no merece la pena invertir en un scraper personalizado para productos de Sainsbury's, qué páginas de Sainsbury's devuelven los datos más limpios y un paso a paso completo con el AI Scraping Agent de Datablist.
📌 Resumen para quien va con prisa
Este artículo explica cómo extraer datos de productos de Sainsbury's con el AI Scraping Agent de Datablist.
Problema: Sainsbury's no tiene una API pública de productos, los scrapers prefabricados se rompen a las pocas semanas con cada cambio de diseño y un desarrollo a medida cuesta más de £2000, además del mantenimiento continuo.
Solución: usar el AI Scraping Agent de Datablist para extraer productos de Sainsbury's con prompts en lenguaje natural y una sola URL.
Qué aprenderá:
- Por qué un scraper personalizado de Sainsbury's acaba saliendo caro
- Qué páginas de Sainsbury's devuelven los datos más limpios
- Un proceso de 5 pasos para extraer cualquier categoría de Sainsbury's en menos de 10 minutos
Por qué Datablist:
- El AI scraping entiende el significado, no el HTML, así que los cambios de diseño de Sainsbury's no rompen la extracción
- La paginación se gestiona automáticamente (hasta 5.000 páginas por ejecución)
- Sin código, sin API keys: solo necesita una URL de Sainsbury's y un prompt
Qué incluye esta guía
- Por qué crear un scraper personalizado de Sainsbury's es un pozo sin fondo
- Cómo extraer productos de Sainsbury's con el AI Agent de Datablist
- Extraer datos de Sainsbury's: paso a paso completo
- Preguntas frecuentes sobre extraer datos de Sainsbury's
Crear un scraper personalizado de Sainsbury's es un pozo sin fondo
Si alguna vez ha pensado en crear su propio scraper para Sainsbury's, aquí tiene tres motivos para replanteárselo antes de gastar un solo euro.
Es caro
Un scraper estable para Sainsbury's no es un proyecto de fin de semana. sainsburys.co.uk carga la cuadrícula de productos dinámicamente con JavaScript, pagina a través de cientos de páginas de categoría y actualiza su diseño con suficiente frecuencia como para que cualquier scraper basado en reglas necesite ajustes constantes.
Esto es lo que suele probar la mayoría de los equipos y por qué cada opción acaba fallando:
- Contratar a un desarrollador freelance: más de £2000 por la primera versión, más costes recurrentes cada vez que Sainsbury's actualiza la cuadrícula
- Comprar un scraper de productos de Sainsbury's ya hecho en Apify o GitHub: funciona el primer día, se rompe en pocas semanas con el siguiente cambio de diseño
- Montar un script en Puppeteer o Playwright: la paginación de Sainsbury's, el renderizado con JavaScript y las fichas de producto inconsistentes lo hacen saltar por los aires enseguida
Si solo necesita una captura puntual, un freelance puede servirle. Pero si necesita datos frescos de Sainsbury's de forma recurrente (seguimiento de precios, análisis FMCG, retail arbitrage), el coste de mantenimiento se acumula mes tras mes.

Lleva mucho tiempo ponerlo en marcha
Incluso con un buen desarrollador, crear un scraper limpio para Sainsbury's lleva semanas. Hay que mapear cada página de categoría, gestionar el HTML renderizado, escribir la lógica para las cuadrículas paginadas y contemplar casos en los que Sainsbury's devuelve "N/A" en los precios promocionales o esconde productos tras controles de edad.
El AI Scraping Agent de Datablist se salta por completo esa fase de desarrollo. Puede pegar una URL de Sainsbury's y obtener datos estructurados de productos en menos de 10 minutos. Sin documentos de especificaciones, sin idas y venidas con casos límite, sin esperar a una v2.

Se rompe constantemente
Este es el verdadero coste: Sainsbury's actualiza su cuadrícula de productos con frecuencia. Cada vez que el equipo publica una nueva plantilla de categoría o mueve el elemento del precio, su scraper personalizado de Sainsbury’s deja de funcionar.
Y eso le deja dos opciones: volver a pagar al desarrollador o perder la tarde depurándolo usted mismo.
El AI scraping evita ese problema. Como el AI Agent interpreta el significado de la página en lugar de su estructura HTML, un precio sigue siendo un precio aunque Sainsbury's cambie la clase CSS que lo rodea.
💡 La diferencia clave
Los scrapers tradicionales siguen reglas: "encuentre el elemento con la clase .product-price y extraiga el texto". Los scrapers con IA siguen el significado: "encuentre el precio del producto en esta página de Sainsbury's".
Por eso, la misma configuración que hoy funciona en Sainsbury's sigue funcionando después de que Sainsbury's reorganice la cuadrícula el mes que viene, y por eso también se adapta bien a Tesco, Morrisons y Asda sin necesidad de código específico para cada sitio.
Cómo extraer productos de Sainsbury's con el AI Agent de Datablist
Antes del paso a paso, conviene aclarar brevemente qué es exactamente el AI Scraping Agent, qué páginas de Sainsbury's ofrecen mejores resultados, qué datos puede sacar y cuáles son sus límites.
¿Qué es el AI Scraping Agent de Datablist?
Datablist es una plataforma de automatización de workflows para crear listas de leads, enriquecer datos y ejecutar flujos de scraping. Dentro de Datablist encontrará más de 60 sources y enrichments, y el AI Scraping Agent es el que se utiliza para extraer datos de productos de la web de un retailer.
El agent funciona combinando tres elementos: una URL de destino, un prompt que describe qué extraer y un modelo de lenguaje que interpreta la página como lo haría usted.
Para extraer productos de Sainsbury's, ni siquiera necesita escribir el prompt. Datablist incluye una plantilla llamada Retail Product Scraper que precarga tanto el prompt como las columnas de salida. Usted pega una URL de Sainsbury's y la plantilla se encarga del resto.
Tres puntos concretos sobre cómo gestiona Sainsbury's este agent:
- OpenAI GPT 4.1 mini por defecto, el LLM con mejor relación calidad-precio para AI scraping
- Render HTML activado, imprescindible para Sainsbury's porque la cuadrícula de productos se carga con JavaScript
- Paginación automática de hasta 5.000 páginas por ejecución
Por eso también puede reutilizar esta configuración sin modificarla en otros supermercados del Reino Unido. El mismo agent, la misma plantilla y la misma configuración funcionan en Tesco, Morrisons, Asda, Waitrose y Aldi. Solo cambia la URL.
La regla más importante: solo páginas de marca y categoría
Extraiga siempre datos de páginas de categoría o de marca de Sainsbury's, nunca de la homepage ni de una vista de "todos los productos". Las listas enormes superan la ventana de contexto del AI Agent, la ejecución se corta a mitad y los créditos se desperdician.
Lo que el AI Agent maneja bien en Sainsbury's:
- ✅ Páginas de categoría en sainsburys.co.uk/gol-ui/groceries/...
- ✅ Páginas de marca (listados de un fabricante concreto)
- ✅ Páginas de ofertas o promociones
Qué conviene evitar:
- ❌ La homepage de Sainsbury's
- ❌ Vistas de "todos los productos" o resultados de búsqueda de todo el sitio
- ❌ Cualquier página que cargue miles de productos en un único scroll infinito
Qué datos puede extraer de Sainsbury's
Una sola ejecución sobre Sainsbury's puede extraer todos los datos de producto que necesite para seguimiento de precios, análisis competitivo o data enrichment dentro de un catálogo ya existente:
- Product Name: nombre completo del producto tal como aparece en la web de Sainsbury's
- Product URL: enlace directo a la ficha del producto en sainsburys.co.uk
- Brand Name: fabricante del producto
- Price: precio actual en GBP, incluido el símbolo £
- Sale Price: precio rebajado si hay una promoción activa en Sainsbury's; "N/A" si no hay ninguna oferta
- Product Category: pasillo o departamento al que pertenece el producto
- Availability: disponible, agotado o stock limitado
- Rating: valoración de clientes cuando Sainsbury's la muestra
- Image URL: enlace directo a la imagen principal del producto
- SKU: identificador interno del producto en Sainsbury's
Elija antes de ejecutar solo las salidas que realmente necesita, para que la exportación incluya únicamente las columnas que va a usar.
Extraer datos de Sainsbury's: paso a paso completo
La configuración completa para extraer datos de Sainsbury's se hace en 5 pasos. Antes de empezar, asegúrese de tener:
- Una URL de categoría o de marca de Sainsbury's (no la homepage)
- Una idea aproximada de qué campos de producto necesita realmente
Paso 1: Regístrese y cree una Collection
Primero, regístrese en Datablist.com.

Después, cree una New Collection.

Paso 2: Vaya al AI Scraping Agent
- Haga clic en See all sources

- Desplácese hacia abajo y seleccione AI Scraping Agent (Site Scraper).

Ahora debería ver la interfaz de configuración de la source, con este aspecto:

Paso 3: Seleccione la plantilla Retail Product Scraper y pegue una URL de Sainsbury's
- Haga clic en el Template Drop-Down y seleccione "Retail Product Scraper"

- Pegue la URL de una categoría de Sainsbury's en el campo URL, por ejemplo:
https://www.sainsburys.co.uk/gol-ui/groceries/frozen/fish-and-seafood/c:1019924/opt/page:2

❗️ Solo páginas de marca y categoría (recordatorio)
No pegue nunca la homepage de Sainsbury's ni una URL de "todos los productos". Las listas enormes superan la ventana de contexto del AI Agent. Extraiga los datos de Sainsbury's categoría por categoría.
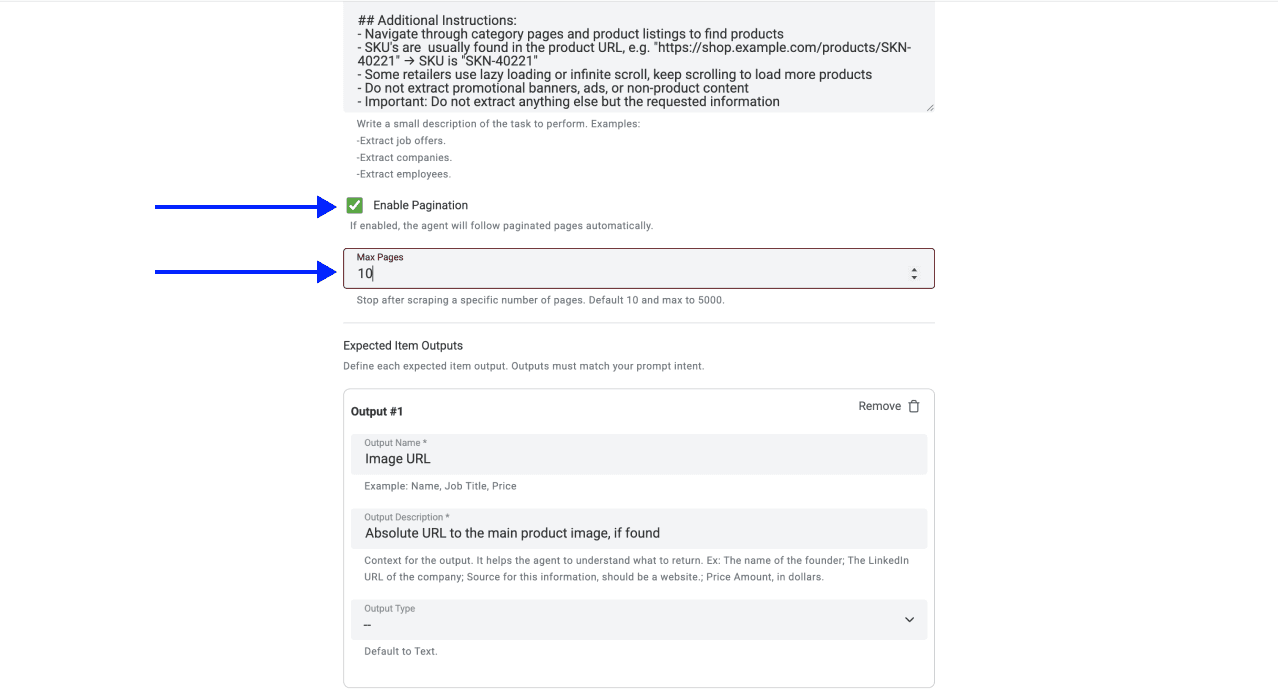
- Defina el número de páginas que quiere extraer (Sainsbury's suele mostrar unos 60 productos por página, así que una categoría con 200 productos necesita aproximadamente entre 3 y 4 páginas)
- Desplácese hacia abajo y haga clic en Continue

💡 Revise la configuración avanzada antes de hacer clic en Continue
Asegúrese de que estas opciones estén activadas:
- LLM: OpenAI GPT 4.1 mini (la mejor relación rendimiento-precio)
- Max Iterations: 10
- Website Scraper Option: Render HTML (crítico para Sainsbury's, porque el sitio carga la cuadrícula de productos dinámicamente con JavaScript)
Paso 4: Configure las salidas
Datablist crea automáticamente las propiedades de salida.
Haga clic en los iconos X para eliminar cualquier salida que no necesite (por ejemplo, quite Rating si solo va a hacer seguimiento de precios de Sainsbury's).

Paso 5: Ejecute
Una vez configuradas las salidas, haga clic en Run Import Now para iniciar la extracción de Sainsbury's.

Tras unos minutos, los resultados de Sainsbury's se verán así. A partir de ahí, las funciones de automatización de workflows de Datablist le permiten limpiar, deduplicar y exportar los datos.

💡 Evite duplicados en ejecuciones repetidas de Sainsbury's
Si tiene pensado volver a extraer la misma categoría de Sainsbury's más adelante:
- Elija una columna de identificador único (Product URL suele ser la mejor opción)
- Haga clic en el encabezado de la columna → Rename - Settings - Delete
- Marque: Do not allow duplicate values
- Save Property
Si también extrae datos de Tesco, Morrisons y Asda en el mismo archivo, nuestra guía sobre cómo eliminar duplicados de archivos CSV explica cómo hacer dedupe entre varios retailers.
El AI Agent de Datablist también sirve para otras webs de retail
La configuración para Sainsbury's no es exclusiva de Sainsbury's. El mismo AI Scraping Agent y la misma plantilla Retail Product Scraper funcionan en todos los supermercados del Reino Unido que hemos probado. Lo único que cambia es la URL.
Si también necesita extraer datos de productos de otros retailers similares, consulte estas guías paso a paso:
Puntos clave
- Un scraper personalizado de productos de Sainsbury's es un pozo sin fondo. El desarrollo inicial supera las £2000, el mantenimiento va aparte y los cambios de diseño de Sainsbury's lo romperán con frecuencia.
- El AI scraping entiende el significado, no el HTML. Por eso, la misma configuración sigue extrayendo productos de Sainsbury's aunque cambie la cuadrícula, y también funciona en Tesco, Morrisons y Asda sin código específico por sitio.
- Extraiga siempre páginas de marca o categoría, nunca la homepage. Las listas enormes superan la ventana de contexto del agent y desperdician la ejecución.
- La configuración completa lleva menos de 5 minutos. Plantilla, URL, salidas y ejecutar.
Preguntas frecuentes sobre extraer datos de Sainsbury's
¿Cuánto cuesta extraer productos de Sainsbury's?
El AI Agent de Datablist funciona con un sistema de créditos basado en uso. El coste por ejecución en Sainsbury's depende de cuántos productos y páginas procese el agent. Los planes de Datablist empiezan en $25 al mes e incluyen 5.000 créditos gratis, y los paquetes de recarga empiezan en $20 por 20.000 créditos, con descuentos por volumen de hasta el 35% en paquetes más grandes.
¿Cuánto tiempo tarda en extraerse todo el catálogo de Sainsbury's?
La mayoría de las páginas de categoría de Sainsbury's con entre 50 y 200 productos se extraen en 5 a 10 minutos. Las ejecuciones más grandes, con varias categorías paginadas (más de 500 productos), pueden tardar entre 10 y 20 minutos. La configuración inicial añade entre 2 y 3 minutos.
¿Por qué conviene extraer una página de categoría de Sainsbury's en lugar de "todos los productos"?
Una vista de "todos los productos" de Sainsbury's carga miles de artículos en una sola página renderizada. Eso supera la ventana de contexto del AI Agent, el agent se detiene a mitad de la ejecución y no hay opción para reanudarla, así que la ejecución parcial se pierde. Las páginas de categoría y marca se mantienen dentro de un rango seguro, se extraen con limpieza y luego puede unirlas en una sola Collection si necesita cobertura completa.
¿Puedo extraer precios promocionales y ofertas de Sainsbury's?
Sí. La plantilla Retail Product Scraper incluye una salida de Sale Price. Cuando hay una promoción activa en Sainsbury's, se recoge el precio rebajado. Si no hay ninguna oferta, la columna devuelve "N/A", lo cual también resulta útil para filtrar por estado promocional entre categorías.
¿Es legal extraer datos de Sainsbury's en el Reino Unido?
Extraer datos públicos de productos de Sainsbury's (nombres, precios, disponibilidad) suele ser legal en el Reino Unido, bajo los mismos principios que se aplican a cualquier dato web público. Aun así, conviene revisar los términos de servicio de Sainsbury's, evitar la extracción de datos personales y mantenerse dentro de volúmenes razonables de solicitudes. Si el uso es comercial, lo mejor es validarlo con su equipo legal.
¿Sainsbury's bloquea los scrapers?
Las protecciones anti-bot de Sainsbury's son moderadas si se comparan con las de Walmart o Costco. La mayoría de las ejecuciones de Sainsbury's con Datablist funcionan al primer intento, especialmente cuando Render HTML está activado. Si una página de categoría no devuelve datos, reduzca el número de páginas y vuelva a intentarlo, o divida la extracción en subcategorías más específicas.
¿Puedo programar ejecuciones recurrentes para monitorizar precios en Sainsbury's?
Sí. Las funciones de automatización de workflows de Datablist le permiten programar ejecuciones periódicas. Si lo combina con una columna de identificador único (Product URL suele funcionar mejor) y la opción de prevención de duplicados, cada nueva ejecución sobre Sainsbury's añadirá solo los productos nuevos en lugar de duplicar los existentes.
¿Puedo extraer datos de Sainsbury's sin saber programar?
Sí, no necesita conocimientos técnicos. Todo el flujo es no-code: seleccione la plantilla Retail Product Scraper, pegue una URL de Sainsbury's, elija las salidas y ejecute. Si puede escribir una frase, puede extraer datos de Sainsbury's con Datablist.
¿Qué categorías de Sainsbury's funcionan mejor para extraer datos?
Las categorías estándar de alimentación en https://www.sainsburys.co.uk/gol-ui/groceries](https://www.sainsburys.co.uk/gol-ui/groceries devuelven los datos más limpios: frescos, congelados, panadería, bebidas y hogar. Las páginas de marca también funcionan muy bien. Las páginas de promociones o de "Last chance" pueden ser algo más ruidosas porque mezclan distintos formatos de fichas de producto, pero el AI Agent sigue devolviendo datos útiles.
¿Puede el AI Agent gestionar automáticamente la paginación de Sainsbury's?
Sí. Con Enable Pagination activado, el AI Agent recorre cada página de la categoría de Sainsbury's hasta el límite que usted configure (10 por defecto, 5.000 como máximo). Para una categoría de Sainsbury's con 240 productos y 24 artículos por página, configure la paginación en 10 y el agent recogerá la lista completa.
¿Qué es el AI scraping?
El AI scraping es una forma de extraer datos estructurados de sitios web usando un modelo de lenguaje en lugar de reglas fijas de HTML. El agent visita la página, interpreta el contenido y devuelve los campos que usted pidió en lenguaje natural. Eso es precisamente lo que lo hace resistente en sitios como Sainsbury's, que cambian su diseño con frecuencia.
¿Qué diferencia hay entre AI scraping y web scraping tradicional?
Los scrapers tradicionales siguen reglas fijas (selectores CSS, XPath). Cuando el sitio cambia, esas reglas dejan de funcionar. El AI scraping interpreta el significado de la página, así que un precio de Sainsbury's sigue siendo un precio de Sainsbury's aunque cambie el marcado. Por eso, la misma configuración de Datablist funciona en Tesco, Sainsbury's, Morrisons y Asda sin código específico para cada sitio.