
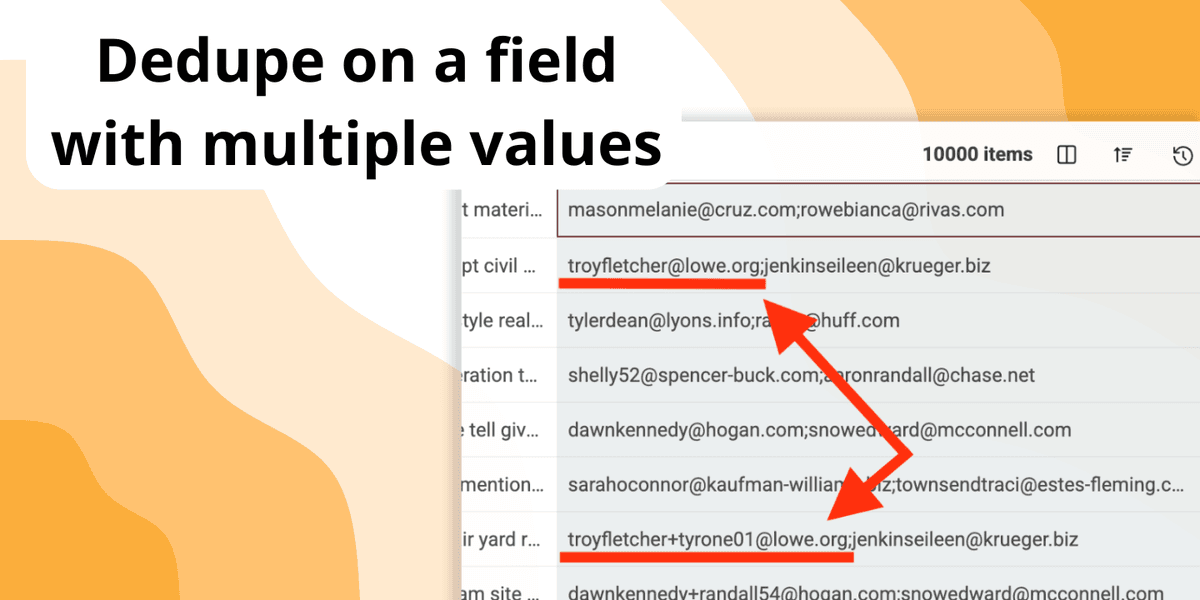
La deduplicación de listas se vuelve mucho más compleja cuando un solo campo contiene varios valores.
Imagine una lista de contactos donde el campo "Emails" incluye varias direcciones separadas por comas, o una base de datos de empresas donde la columna "URLs" reúne varios enlaces al sitio web y a redes sociales.
Las herramientas de deduplicación habituales suelen fallar al reconocer que dos registros pueden ser duplicados si comparten aunque sea uno de esos valores múltiples.
Datablist ofrece una solución sólida para este escenario avanzado de deduplicación.
En este artículo verá cómo deduplicar una lista cuando un campo contiene varios valores:
- Importar y preparar sus datos para la deduplicación
- Detectar duplicados con coincidencia de valores múltiples
- Resolver conflictos y fusionar registros duplicados
Paso 1: Importar y preparar sus datos para la deduplicación
El primer paso es llevar sus datos a Datablist. Puede importar un archivo CSV o Excel, o conectarse a su CRM u otras fuentes de datos.
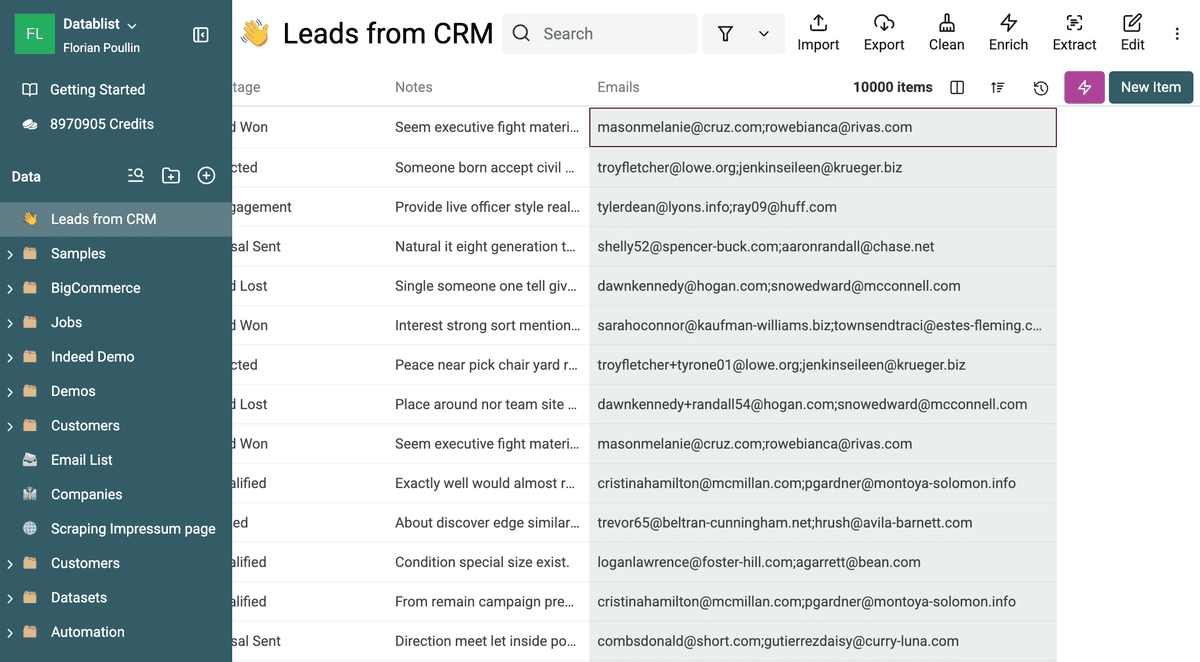
Una vez importados, es clave revisar el campo que contiene múltiples valores. La funcionalidad "Multiple Values" de Datablist está diseñada para trabajar con valores separados por punto y coma (;).
Ejemplo:
Considere un campo "Emails" en una lista de contactos. Si los correos aparecen así:
- Registro 1:
john.doe@example.com; jane.doe@example.com; info@example.com - Registro 2:
jane.doe@example.com; support@example.com; sales@example.com - Registro 3:
john.doe@example.com; marketing@example.com
Datablist puede reconocer que el Registro 1 y el Registro 3 incluyen "john.doe@example.com", y que el Registro 1 y el Registro 2 comparten "jane.doe@example.com", aunque estén dentro de un único campo.
Cómo manejar separadores distintos:
Si sus valores múltiples están separados por otro carácter distinto al punto y coma (por ejemplo, coma, barra vertical o espacio), deberá normalizar sus datos antes de usar el Duplicates Finder. La potente herramienta Find & Replace de Datablist le sirve para ello.
Cómo usar Find & Replace para estandarizar los separadores a punto y coma:
- Vaya a su colección en Datablist.
- Seleccione la columna que contiene los valores múltiples.
- Abra el menú "Clean" y elija "Find & Replace".
- En el campo "Find", introduzca el separador actual (por ejemplo,
,si los valores están separados por comas). - En el campo "Replace with", introduzca un punto y coma
;. - Haga clic en "Apply".
Al asegurarse de que todos los campos multivalor usan el punto y coma como separador, permitirá que la función "Multiple Values" de Datablist trabaje con precisión.
Paso 2: Detectar duplicados con coincidencia de valores múltiples
Con sus datos importados y los campos multivalor preparados (usando punto y coma como separador), ya puede buscar duplicados.
-
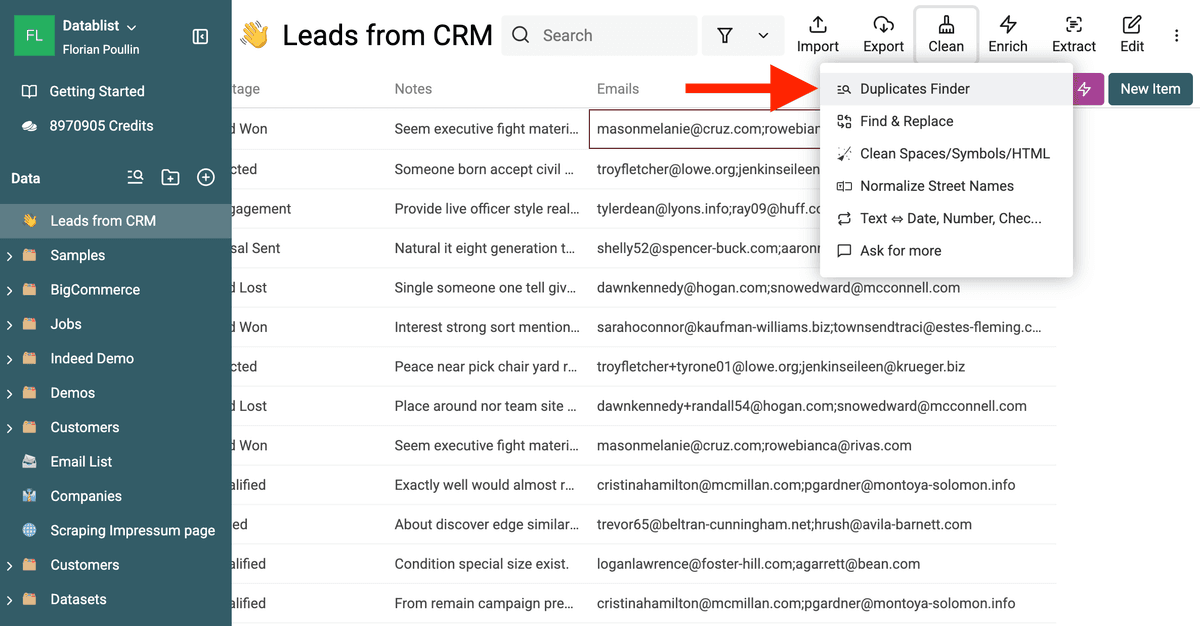
Abra el menú "Clean" y seleccione "Duplicates Finder".
Abrir Duplicates Finder -
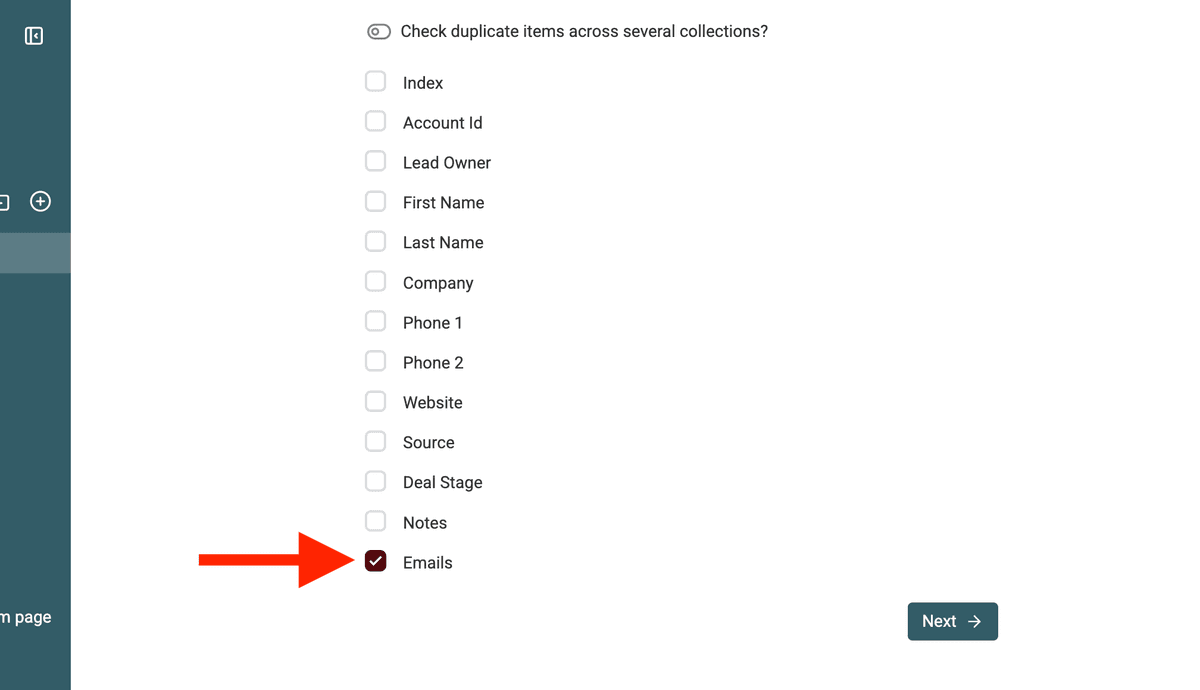
En Duplicates Finder, elija la columna que contiene los valores múltiples que usará para la coincidencia. Por ejemplo, seleccione la columna "Emails" del ejemplo anterior.
Seleccionar la propiedad -
Y, muy importante, active la casilla "Multiple Values". Verá un campo para confirmar o indicar el separador. Asegúrese de que está configurado como
;(punto y coma).Activar la opción Multiple Values -
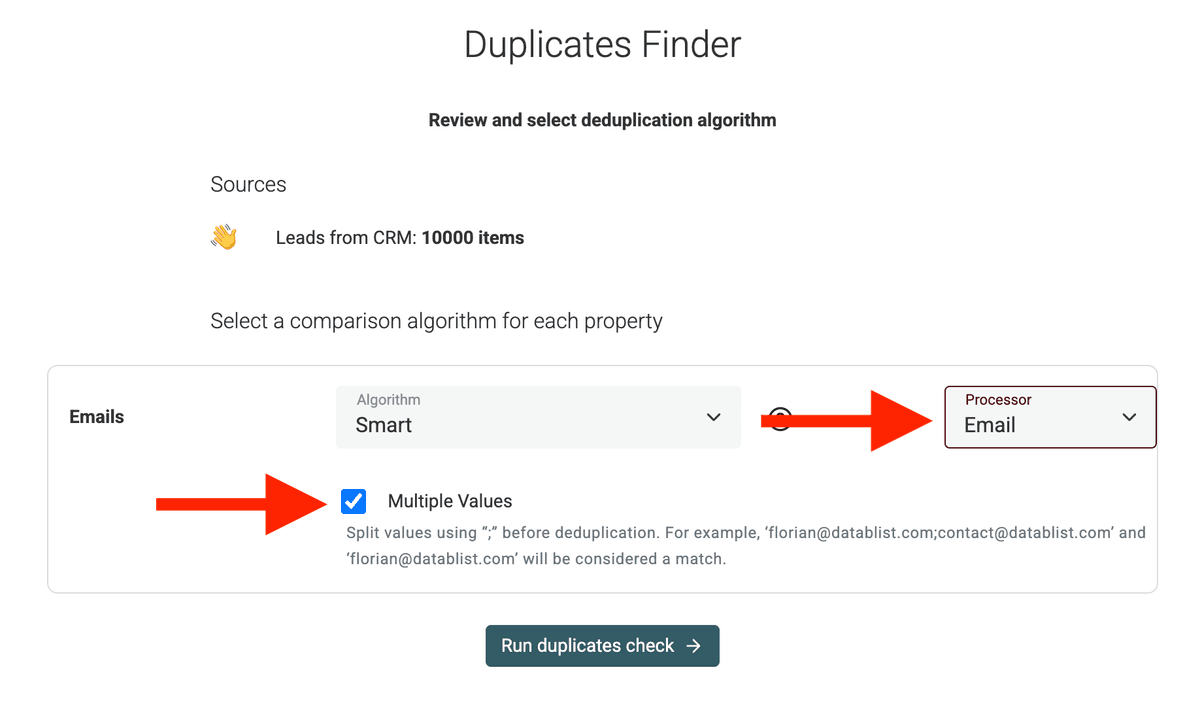
Elija su algoritmo de coincidencia y el Processor
Datablist incluye distintos algoritmos de deduplicación. Estos son los dos principales:
- Smart Algorithm: Suele ser un buen punto de partida. Analiza los emails individuales de cada registro e identifica aquellos que comparten uno o más correos en común.
- Distance Algorithm: Si espera ligeras variaciones o typos en los emails (por ejemplo, "john.doe@exmaple.com" frente a "john.doe@example.com"), el Distance Algorithm puede ayudar. Deberá definir un umbral de similitud para indicar cuán próximas deben ser las cadenas para considerarse coincidencia.
Datablist también incluye "Processor" que normalizan sus datos antes de identificar duplicados. Si va a deduplicar por URLs, seleccione
URL; para correos, elijaEmails, etc.Por ejemplo, el Email processor hará coincidir estas dos direcciones:
john@datablist.comyjohn+spam@datablist.com. -
Ejecute la búsqueda de duplicados. Datablist procesará sus datos tratando cada email dentro del campo "Emails" como una entidad independiente para la comparación. Los registros que compartan al menos un email (o tengan emails similares según el Distance Algorithm) se agruparán como duplicados potenciales.
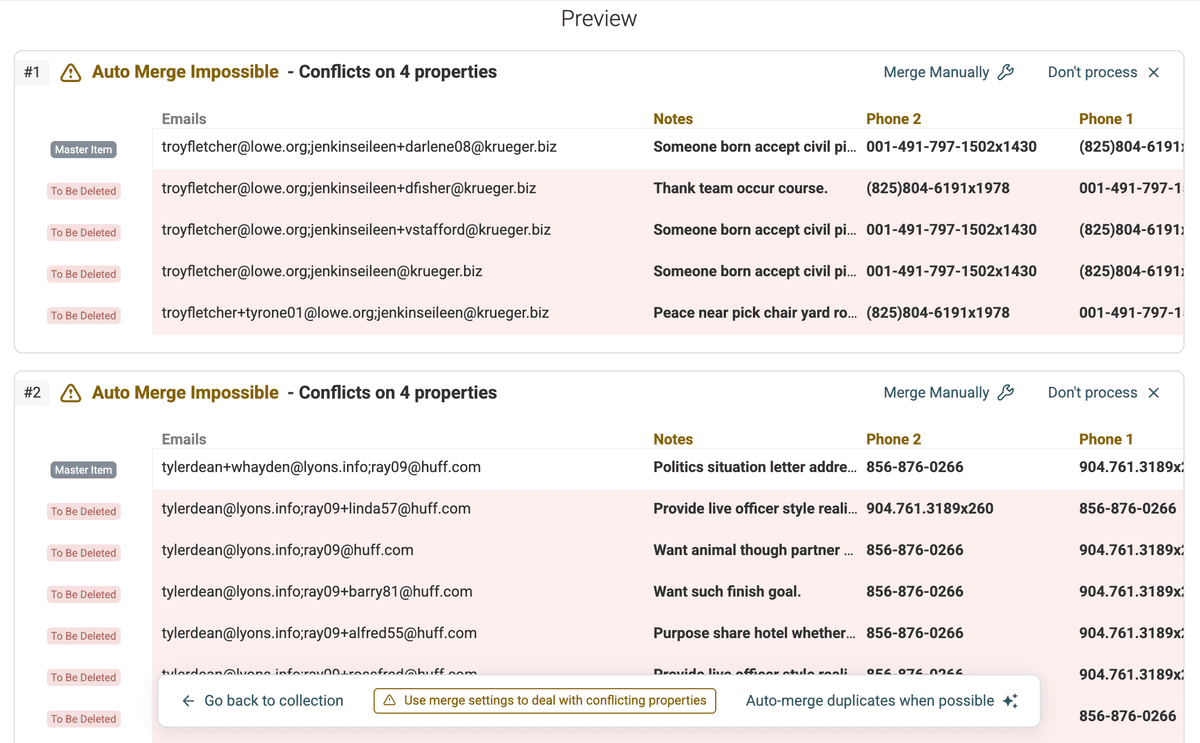
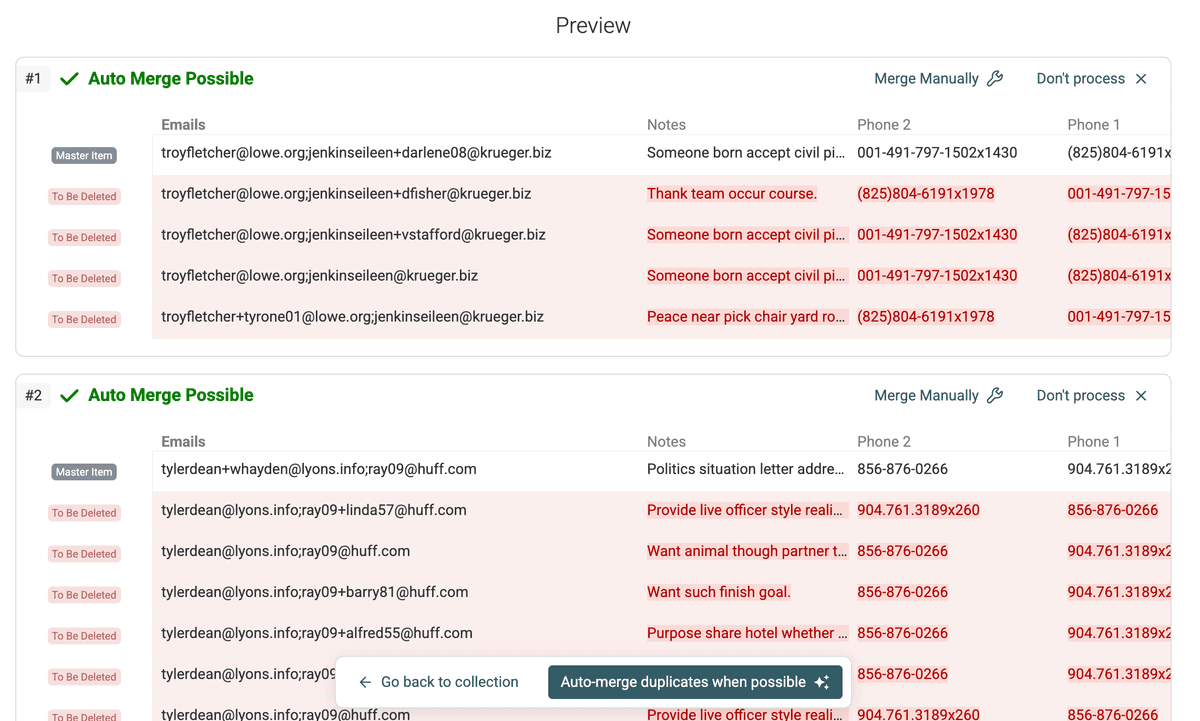
Vista previa de duplicados -
Revise con atención los grupos de duplicados detectados. Verá cómo se han combinado en función de los valores compartidos en el campo multivalor. En el ejemplo de "Emails", probablemente se agruparán los registros 1 y 3 porque ambos incluyen "john.doe@example.com". Los registros 1 y 2 también se agruparán por compartir "jane.doe@example.com".
Paso 3: Resolver conflictos y fusionar registros duplicados
Una vez identificados los grupos de duplicados, el siguiente paso es definir cómo se fusionarán, especialmente el campo multivalor y cualquier otro posible conflicto.
-
Para cada grupo, Datablist resaltará los campos donde los valores difieren; se consideran propiedades en conflicto. Puede incluir otra información de contacto, como teléfonos, direcciones de email (si deduplicó por emails) o cargos.
-
En el caso del campo multivalor (en el ejemplo, "Emails"), tendrá opciones específicas de fusión:
-
Combine Values: Suele ser la opción más recomendable. Datablist reunirá todos los valores únicos de los registros duplicados y los combinará en un solo valor usando un carácter de concatenación. Por ejemplo, fusionar el Registro 1 (
john.doe@example.com; jane.doe@example.com; info@example.com) y el Registro 3 (john.doe@example.com; marketing@example.com) dará como resultado un registro maestro conjohn.doe@example.com; jane.doe@example.com; info@example.com; marketing@example.com. -
Drop Conflicting Values: Si un contacto está claramente más completo y desea descartar el otro, elija "Drop conflicting values...".
Seleccione un registro maestro
También puede configurar cómo selecciona Datablist el registro maestro. Al fusionar duplicados, Datablist conserva un registro, actualiza sus campos y elimina los otros para quedarse con uno solo.
Puede controlar la selección del Master Record eligiendo entre varias reglas:
- Most Complete: Selecciona el registro con más campos rellenados.
- Last Updated: Selecciona el registro modificado más recientemente.
- First Created: Selecciona el registro más antiguo según la fecha de creación.
- Highest Value: Selecciona el registro con el valor más alto en una propiedad elegida. Si varios comparten el mismo valor, elige el más reciente.
- Lowest Value: Selecciona el registro con el valor más bajo en una propiedad elegida. Si varios comparten el mismo valor, elige el más reciente.
- Matching Value: Selecciona el registro que contenga un valor específico en una propiedad elegida. Si ninguno coincide, no se fusionarán.
-
-
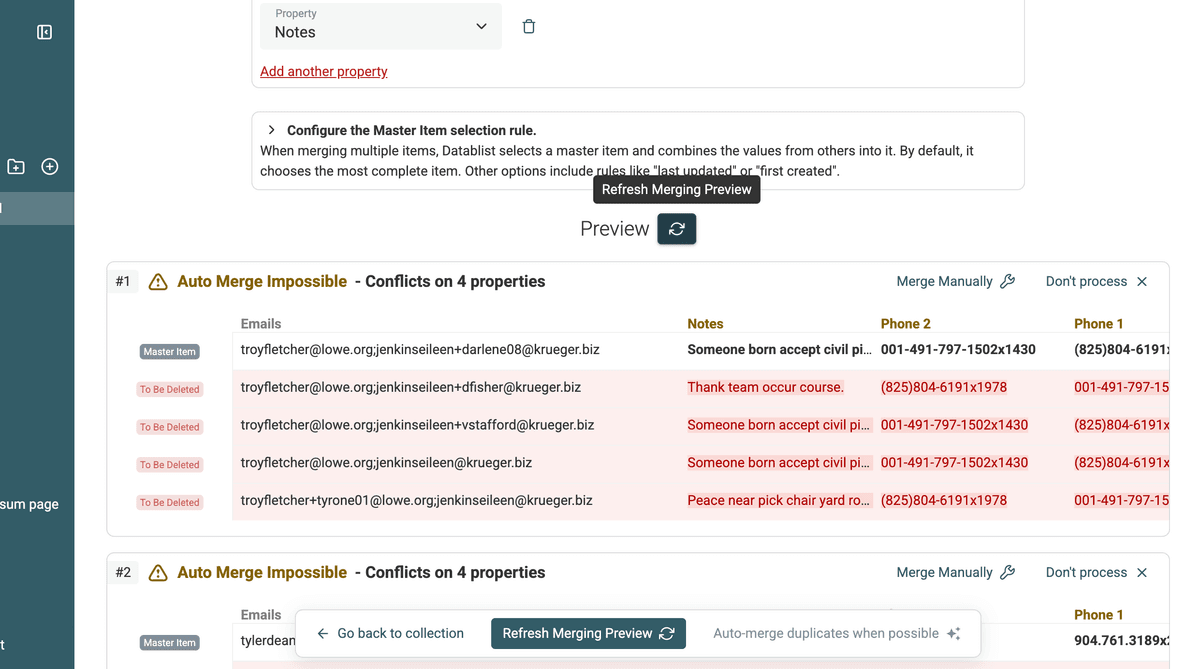
Tras definir las reglas de fusión para todas las propiedades en conflicto, actualice la vista previa. Así verá exactamente cómo quedará el registro resultante de cada grupo de duplicados. Preste especial atención a cómo se han combinado los valores múltiples.
Actualizar la vista previa de fusión -
Revise la vista previa cuidadosamente para asegurarse de que el resultado se ajusta a lo esperado. Cuando esté conforme, proceda con la fusión. Haga clic en "Auto-merge duplicates when possible" o fusione manualmente grupos específicos si lo prefiere.
Vista previa de fusión correcta -
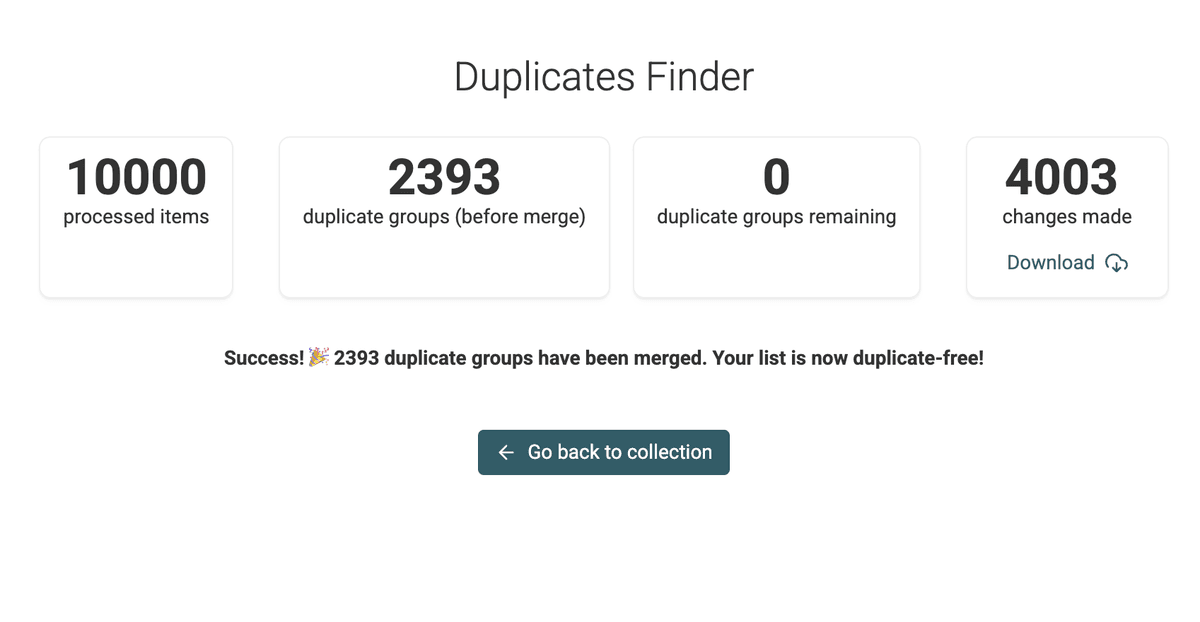
Al finalizar, Datablist le mostrará un resumen de las acciones realizadas.
Pantalla de fusión completada
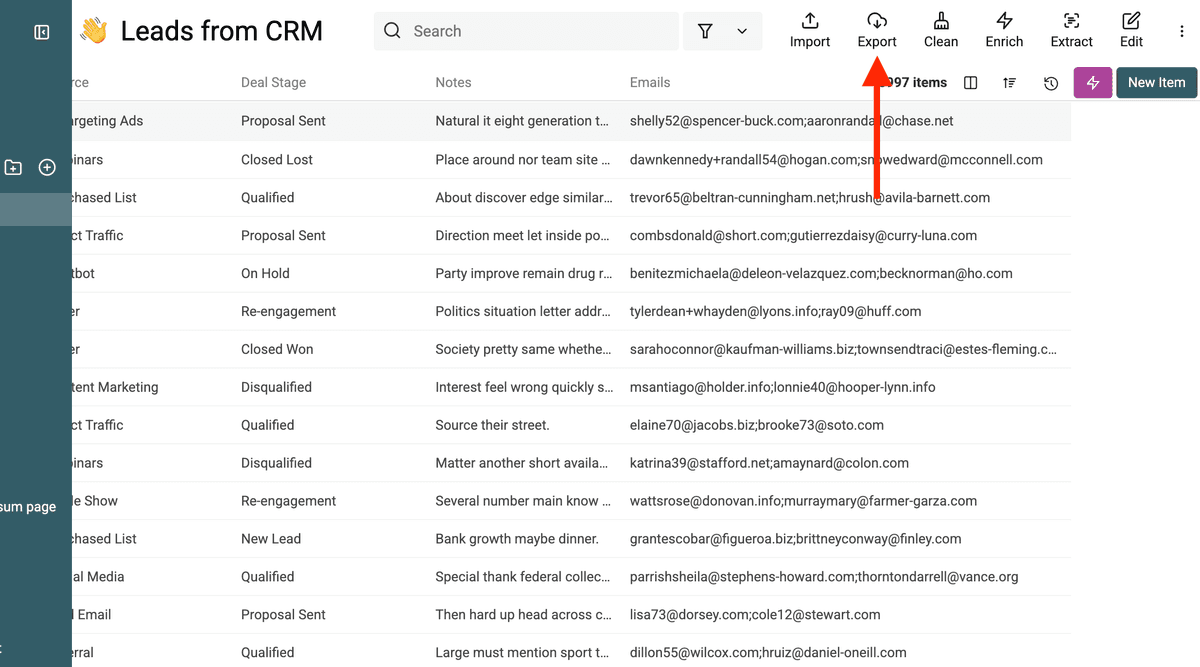
Por último, exporte su lista limpia y deduplicada, ahora con información consolidada incluso para registros que tenían múltiples valores en un mismo campo.
Siguiendo estos pasos, podrá aprovechar la función "Multiple Values" de Datablist para realizar una deduplicación avanzada en listas donde la información clave se guarda en un formato estructurado con múltiples valores. Recuerde estandarizar sus separadores a punto y coma para obtener los mejores resultados.