

Gérer les doublons entre plusieurs fichiers Excel est un vrai cauchemar chronophage qui mène à des incohérences, des erreurs coûteuses et une perte de temps pour tout le monde.
Sans méthode fiable de déduplication, vous prenez le risque d’envoyer plusieurs fois le même email à un contact, de prendre de mauvaises décisions business sur des données faussées, et de perdre des heures à comparer vos fichiers à la main.
Voici comment dédoublonner efficacement vos données dans plusieurs fichiers Excel : gagnez du temps, préservez l’intégrité de vos données, et évitez les futurs doublons.
Dans ce guide, vous verrez comment retirer les doublons entre plusieurs listes (parfois structurées différemment) :
- Comment importer vos fichiers Excel (ou CSV)
- Comment détecter les doublons sur plusieurs listes
- Comment supprimer automatiquement les doublons
Étape 1 : Importez vos fichiers à dédoublonner sur Datablist
Créez un compte sur Datablist et importez au moins deux fichiers.
Assurez-vous qu’il y ait au moins un identifiant unique commun à vos fichiers.
Note : Le Duplicates Finder de Datablist fonctionne avec autant de fichiers Excel/CSV que vous voulez. Leur structure peut être différente. Il suffit qu’ils aient un identifiant commun à chaque fichier.
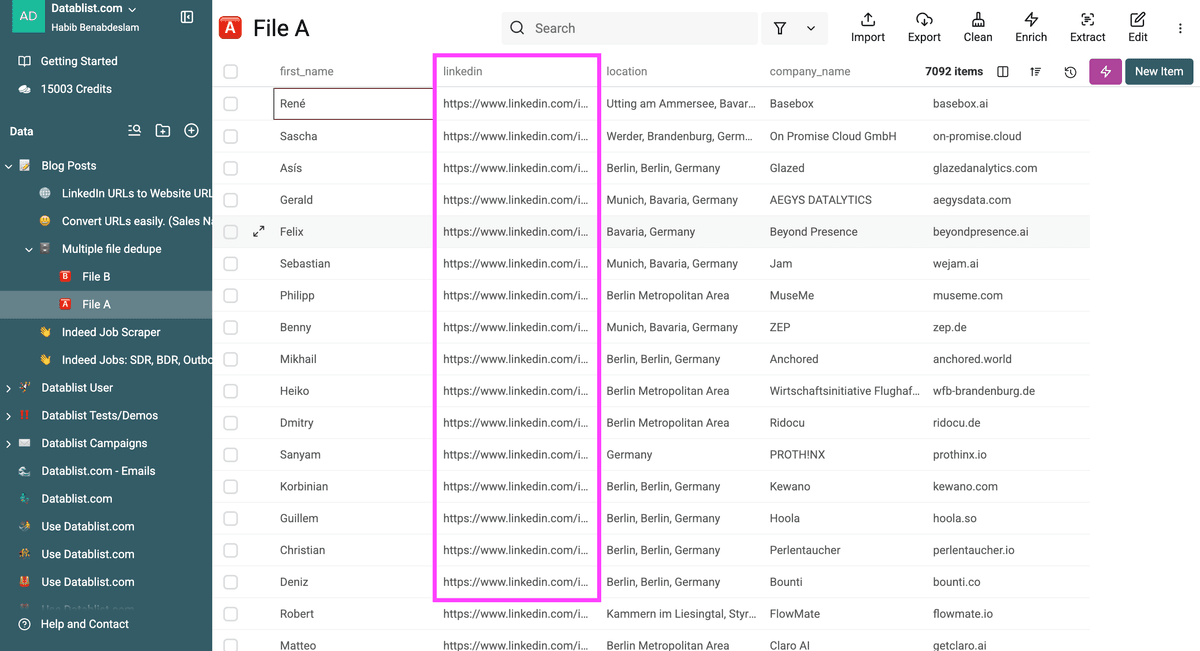
Dans mon exemple, j’utilise l’URL LinkedIn du prospect comme identifiant unique.
Un identifiant unique n'est pas forcément "vraiment" unique. Cela peut aussi être un nom d'entreprise ou un prénom si c’est LE critère de correspondance choisi.
Étape 2 : Détectez les doublons entre vos listes
Cliquez sur « Clean » puis sélectionnez "Duplicates finder".
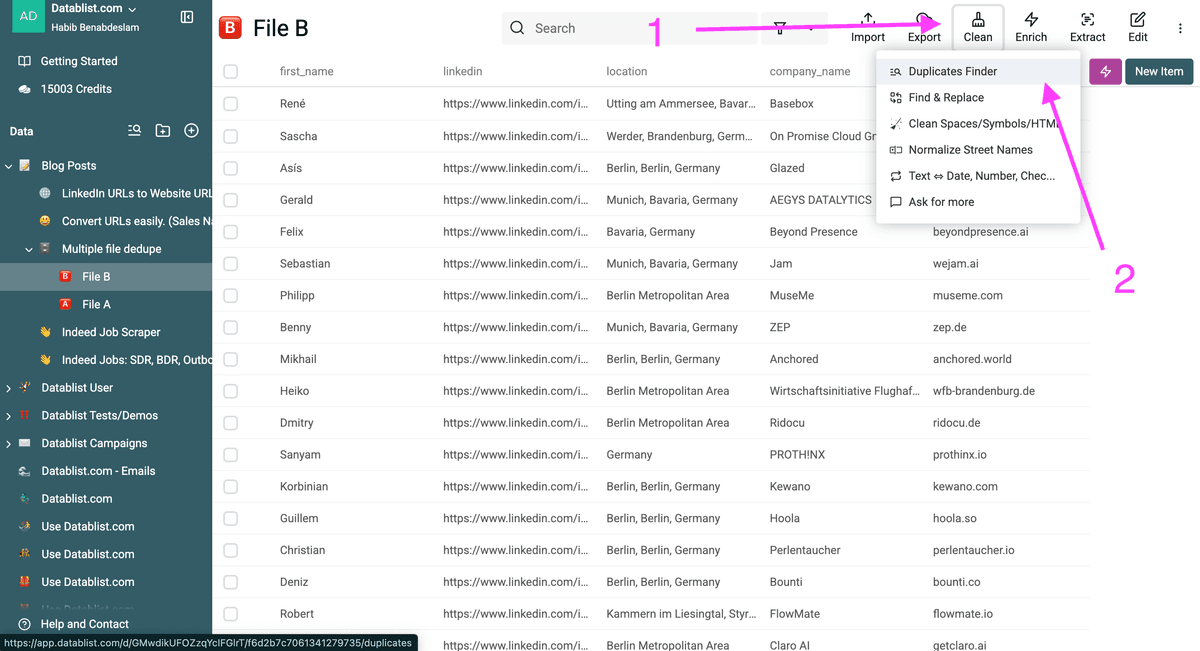
Note : Vous pouvez démarrer depuis n'importe lequel de vos fichiers — le résultat sera le même.
Réglez la recherche pour croiser vos différents fichiers CSV/Excel :
- Cliquez sur "Selected Properties and Multi Collections"
- Cliquez sur "Check Duplicate Items Across Several Collections"
- Sélectionnez toutes les collections/fichiers à comparer (2 fichiers ou plus, sans limite)

Choisissez ensuite le champ sur lequel faire la déduplication.
Chaque fichier doit avoir un champ équivalent à comparer. Pour chaque propriété, sélectionnez l'équivalent dans chaque fichier.
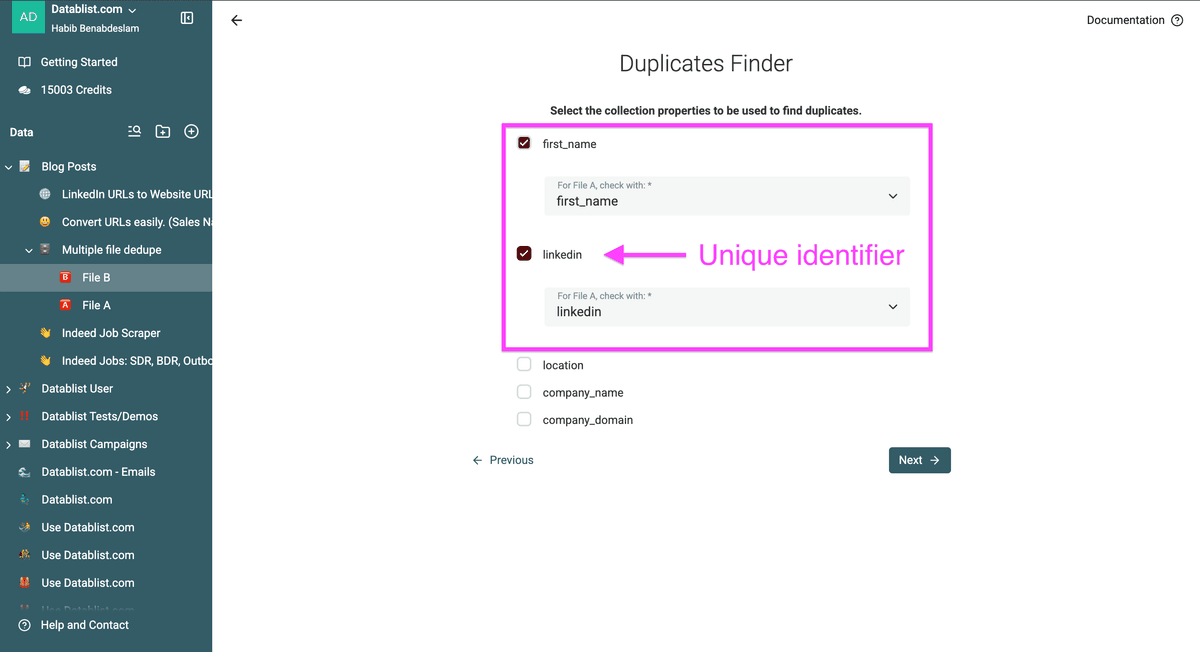
Dans cet exemple, je veux retirer de "Fichier B" tous les prospects présents dans "Fichier A", selon l’URL LinkedIn.
Vous pouvez sélectionner plusieurs propriétés pour matcher les doublons. Dans ce cas, tous les champs doivent matcher pour qu’il y ait détection. Si vous voulez trouver les doublons sur telle OU telle propriété, faites deux passages séparés.
Choisissez l’algorithme de comparaison.
Pour des IDs purs (numéros CRM, IDs internes), laissez "Exact". Pour des propriétés texte (URL, emails), optez pour "Smart" pour la meilleure précision entre fichiers différents.
Si vous travaillez sur des noms avec possible typo/variations, prenez un algorithme de distance (Levenshtein ou Jaro-Winkler).

Cliquez sur « Run duplicates check » une fois votre paramétrage choisi.
Étape 3 : Choisissez les opérations de nettoyage des doublons
Définissez votre logique :
- Supprimer les doublons dans une collection donnée
- OU : Ne garder que les doublons dans une collection spécifique (utile à 3+ fichiers)

Cliquez sur "Process duplicate items" pour valider.
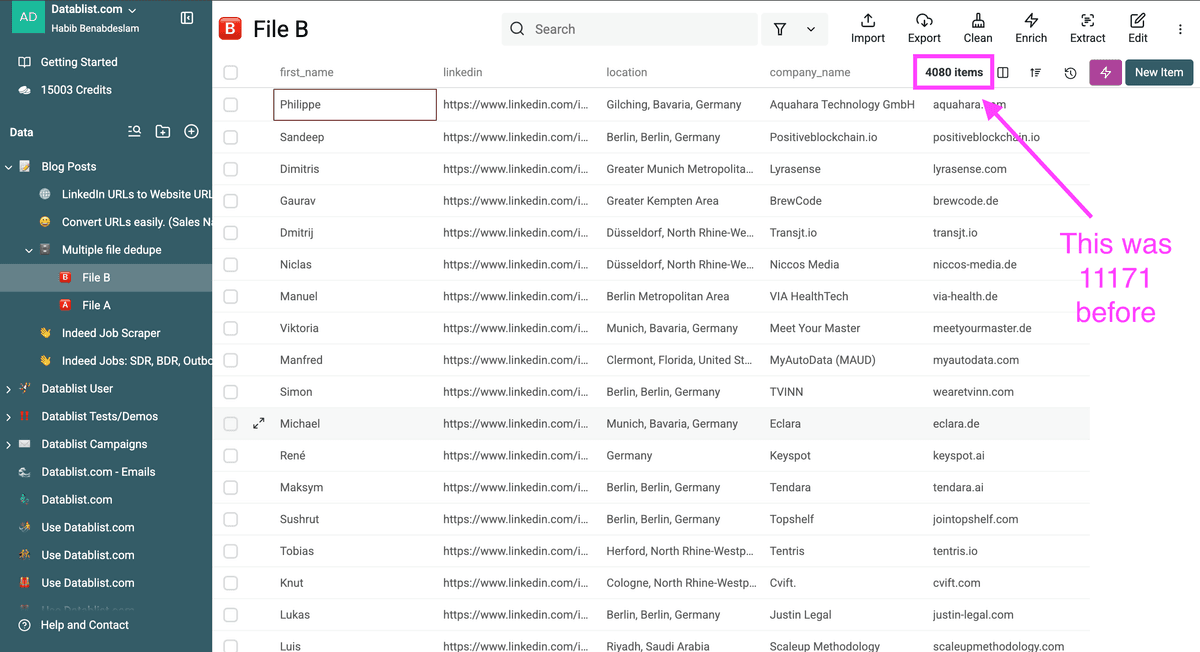
Votre fichier propre ne contient maintenant que les nouveaux prospects, sans aucun doublon !
Important : Lorsque vous croisez plusieurs listes, l’algo ne retire pas les doublons à l’intérieur de chaque fichier ! Si vos fichiers contiennent des doublons internes, commencez par les nettoyer séparément.
Exemples d’utilisation de cette méthode
- Ne pas contacter deux fois le même prospect
- Éviter de solliciter plusieurs personnes de la même entreprise
- Consolider des bases clients issues de différents services ou agences
- Nettoyer et fusionner plusieurs listes de contacts issues de diverses campagnes
- Centraliser des feedbacks clients issus de plusieurs sources