

Le data matching, aussi appelé record linkage ou deduplication, consiste à identifier et relier les enregistrements similaires au sein de plusieurs datasets. C'est le secret pour transformer des données brutes et désordonnées en un actif précieux pour le marketing, la vente ou l'analyse de données.
La plupart des solutions disponibles sur le marché sont complexes et coûteuses. Datablist est une application en ligne, compatible Mac OS, Microsoft Windows, et Linux, pour réaliser du data matching rapidement. Elle propose la correspondance exacte, la correspondance phonétique et des algorithmes avancés de fuzzy matching.
Dans ce guide, vous allez démystifier les complexités du data matching. Que vous soyez débutant ou data analyst chevronné cherchant à optimiser votre process, ce tutoriel a été conçu pour vous.
Voici le résumé des points abordés sur le Data Matching dans cet article :
- Chargement de vos datasets
- Préparation des données : Nettoyage et Normalisation
- Correspondance des enregistrements au sein ou entre plusieurs collections de données
- Déduplication : supprimer ou fusionner les groupes correspondants
Démarrez avec notre outil de Data Matching en ligne en quelques secondes. Pas d'appel commercial, pas de démo sur PowerPoint.
Etape 1 : Chargez vos datasets
La première étape consiste à importer vos datasets dans Datablist. Datablist est un outil de gestion de listes en ligne. Il vous permet de voir et éditer vos fichiers CSV et Excel. C'est l'outil parfait pour gérer vos listes de leads, nettoyer la donnée client ou nettoyer des données issues du scraping.
Pour commencer, créez une collection pour charger votre premier dataset.
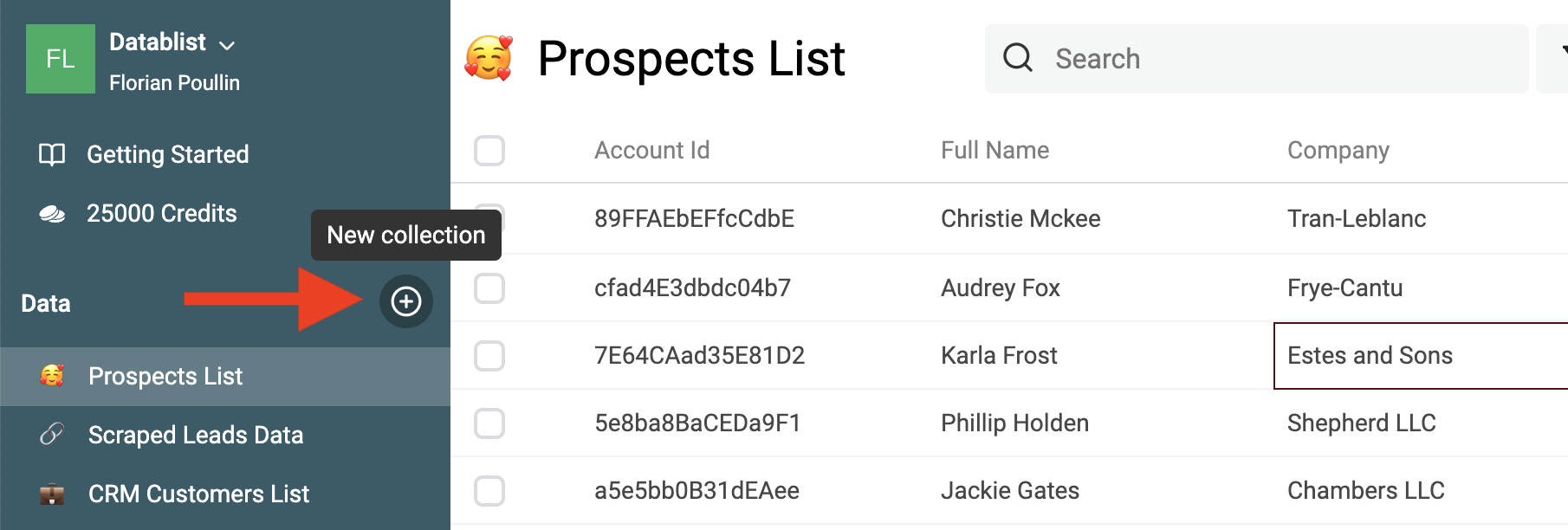
Puis cliquez sur le bouton Import.
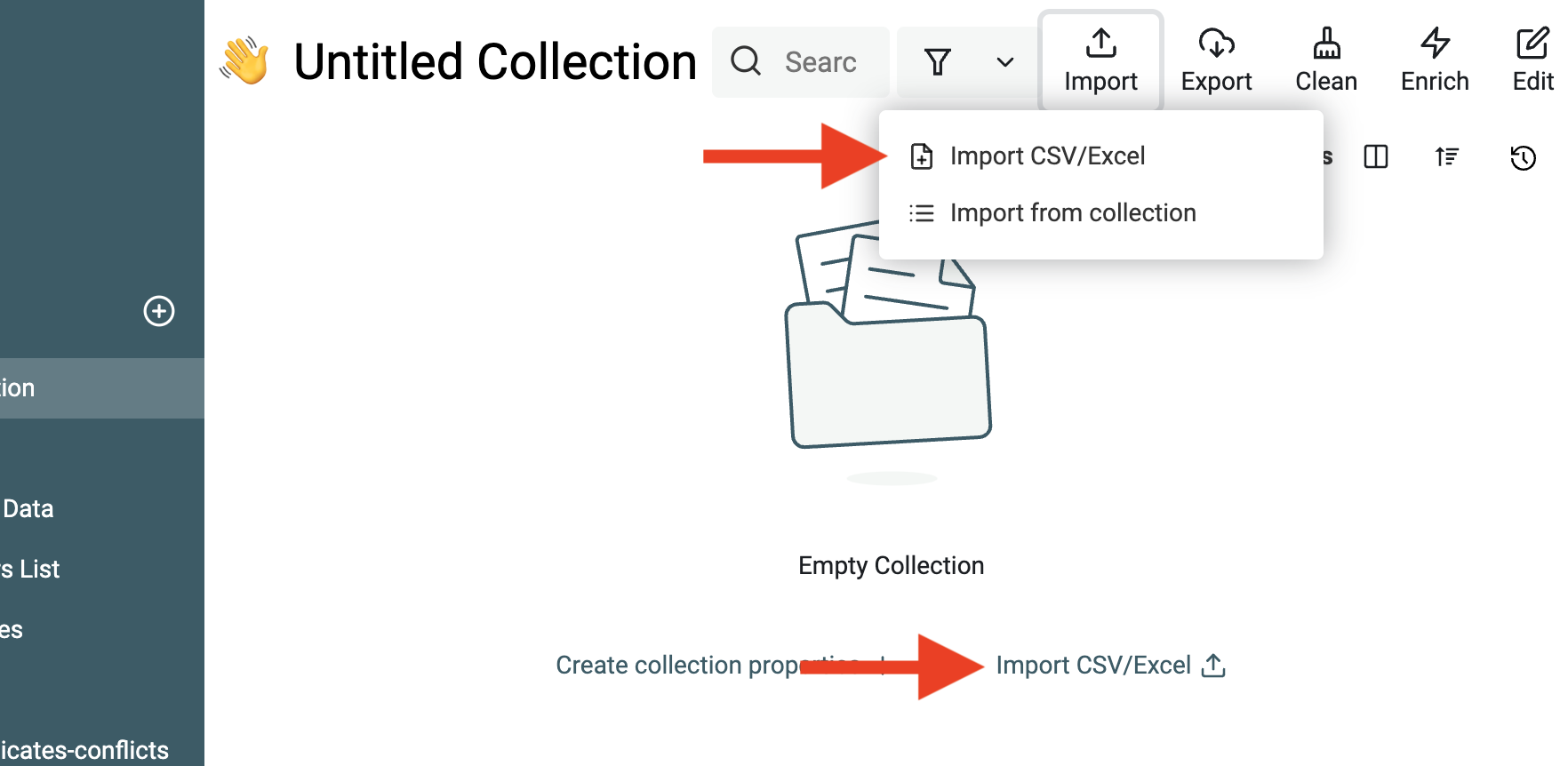
Une fois votre premier dataset importé, vous pouvez :
- Importer d'autres datasets avec des structures similaires dans la même collection.
- Importer des jeux de données avec des structures différentes dans de nouvelles collections.
Le Duplicates Finder de Datablist trouve les enregistrements similaires au sein d'une même collection ou entre des collections ayant des structures différentes.
Etape 2 : Préparez vos données : nettoyage et normalisation
La seconde étape est le Data Cleansing. Le nettoyage de données est une étape incontournable avant toute opération de data matching. Il garantit la fiabilité et la précision du processus. Des données brutes ou incomplètes aboutissent à des correspondances erronées et à des résultats non fiables. En résumé, nettoyer ses données prépare le terrain pour réussir son data matching.
Quand du bruit se glisse dans les noms (prénom/nom ou raison sociale), ils n'apportent aucune valeur et peuvent empêcher l'algorithme de détecter des doublons.
Datablist offre une liste d'outils de data-cleaning intégrés :
- Retirer les symboles et la ponctuation : les textes récupérés via scraping peuvent contenir des symboles ASCII, smileys, ou ponctuation. L'algorithme de matching ignore ces caractères, mais ils peuvent empêcher la fusion automatique lors de la déduplication.
- Retirer les espaces en trop : un espace en trop suffit à rendre deux chaînes différentes. Les algorithmes de Datablist traitent les espaces superflus avant le matching, mais ils bloquent aussi le merge automatique lors de la déduplication.
- Extraire des emails, URLs, etc. du texte : Si vos données contiennent des champs texte non structurés (emails, URLs, mentions, tags...), utilisez notre Data Extractor pour structurer vos données. Le Data Matching est beaucoup plus simple avec des entités structurées.
- Retirer les balises HTML : autre fonctionnalité de nettoyage, la conversion en texte brut. Parfait pour matcher vos listes contenant des balises HTML avec d'autres sources.
- Convertir un texte en DateTime, Number, Boolean… : Datablist offre de vrais formats de données (Datetime, nombre, booléen…). Convertir des champs texte bruts en formats natifs est essentiel pour appliquer des règles avancées de merge et choisir l’élément maître sur une base de comparaison (ex : la date la plus récente).
- Changer la casse du texte : Harmoniser la casse du texte est simple mais nécessaire pour fiabiliser le matching. Datablist propose plusieurs algorithmes pour la transformation de casse).
- Éclater ou fusionner les propriétés : idéal pour les propriétés contenant plusieurs valeurs (ex : plusieurs emails séparés par une virgule/point-virgule/espace). L'outil Split Property crée des champs avec chaque valeur individuelle.
- Supprimer ou remplacer les valeurs vides : Filtrez les champs ou lignes vides avec les fonctions de filtrage de Datablist.
Pour aller plus loin, consultez notre guide sur le data cleaning.
Normaliser les noms de personnes
Travailler sur des datasets de personnes est courant en data deduplication : clients, leads, prospects. Idéalement, le matching s’appuie sur des identifiants uniques (email, ID...). Mais sans unique ID, ou pour recouper des individus entre plusieurs sources, il faut s’appuyer sur les champs prénom/nom pour le data matching.
Pré-traiter les noms de personnes garantit un format uniforme et évite les erreurs de correspondance.
Nettoyer le bruit dans les noms
Les noms de personnes sont très variables (diminutifs, abréviations, orthographe, caractères spéciaux...).
Utilisez l’outil Find & Replace pour nettoyer titres, suffixes, stop-words, ou expressions régionales inutiles.
Exemple pour enlever les titres :
^\s*(mr|mrs|dr|miss|ms|sir|madam|m).?\s
Et remplacez par une chaîne vide.
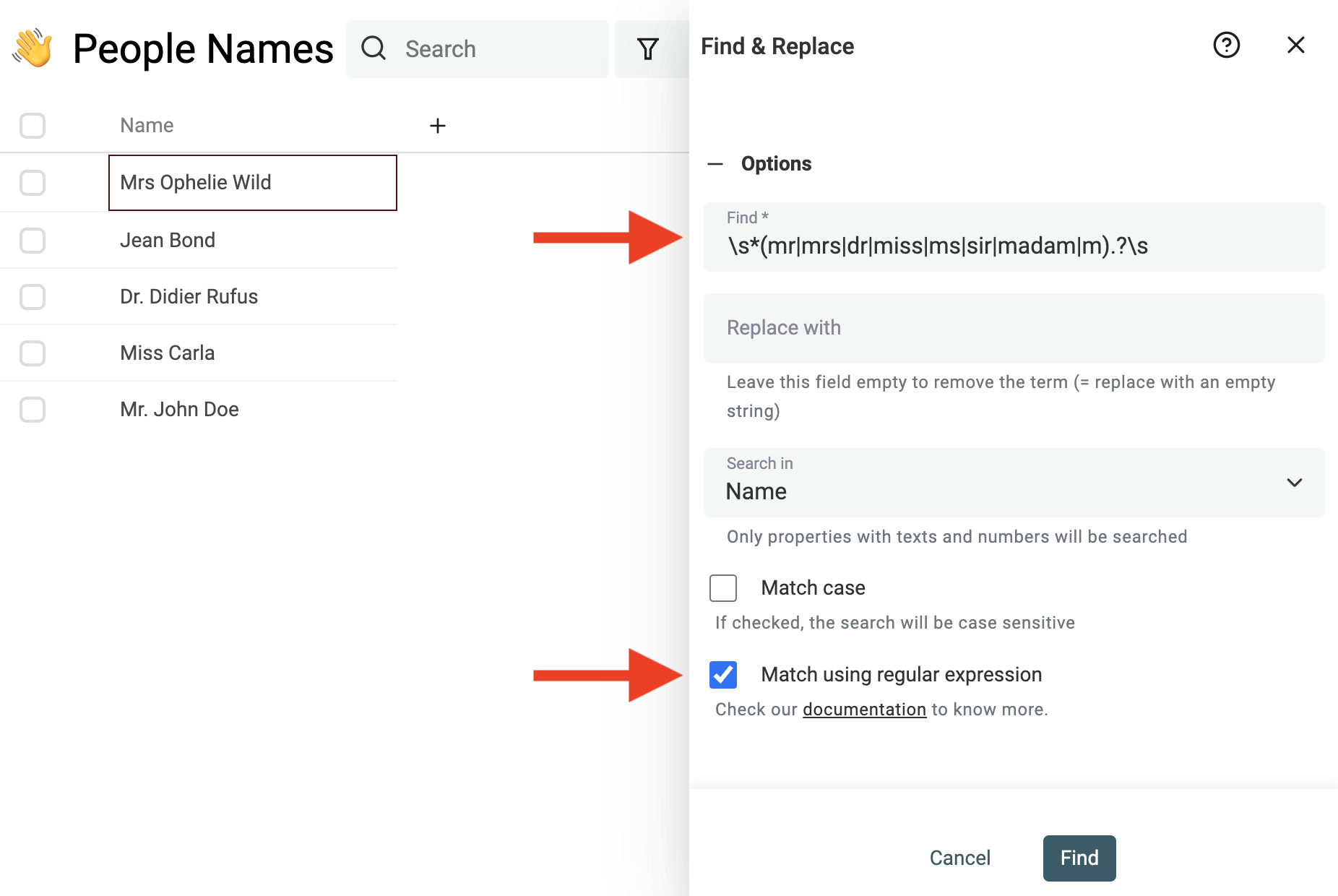
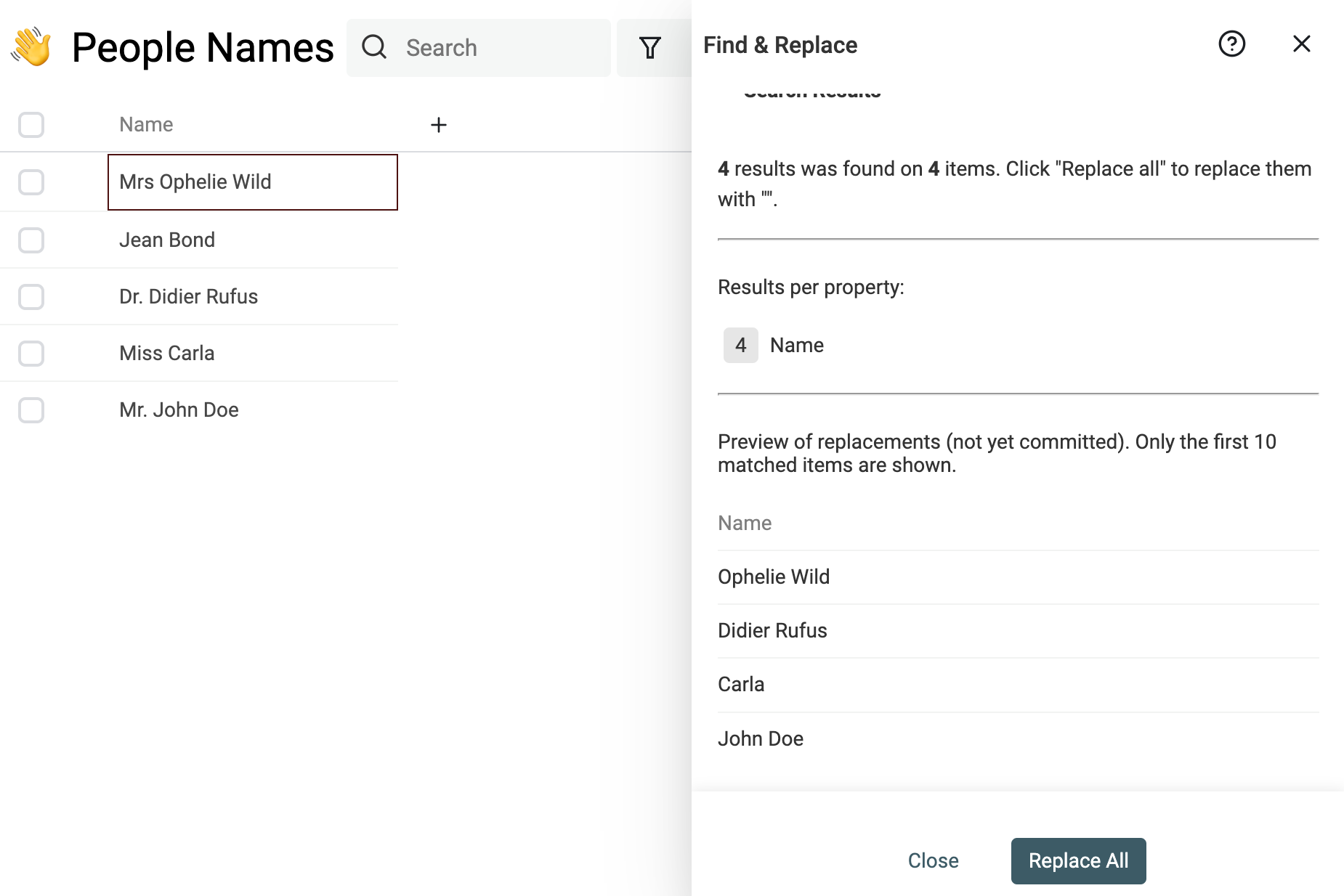
Note Si vous n’êtes pas à l’aise avec les regex, contactez-nous, nous nettoierons vos données pour vous.
Découper un nom complet en parties
Datablist va au-delà du data-cleaning et propose des enrichissements (lead enrichments, traductions csv avec Deepl…).
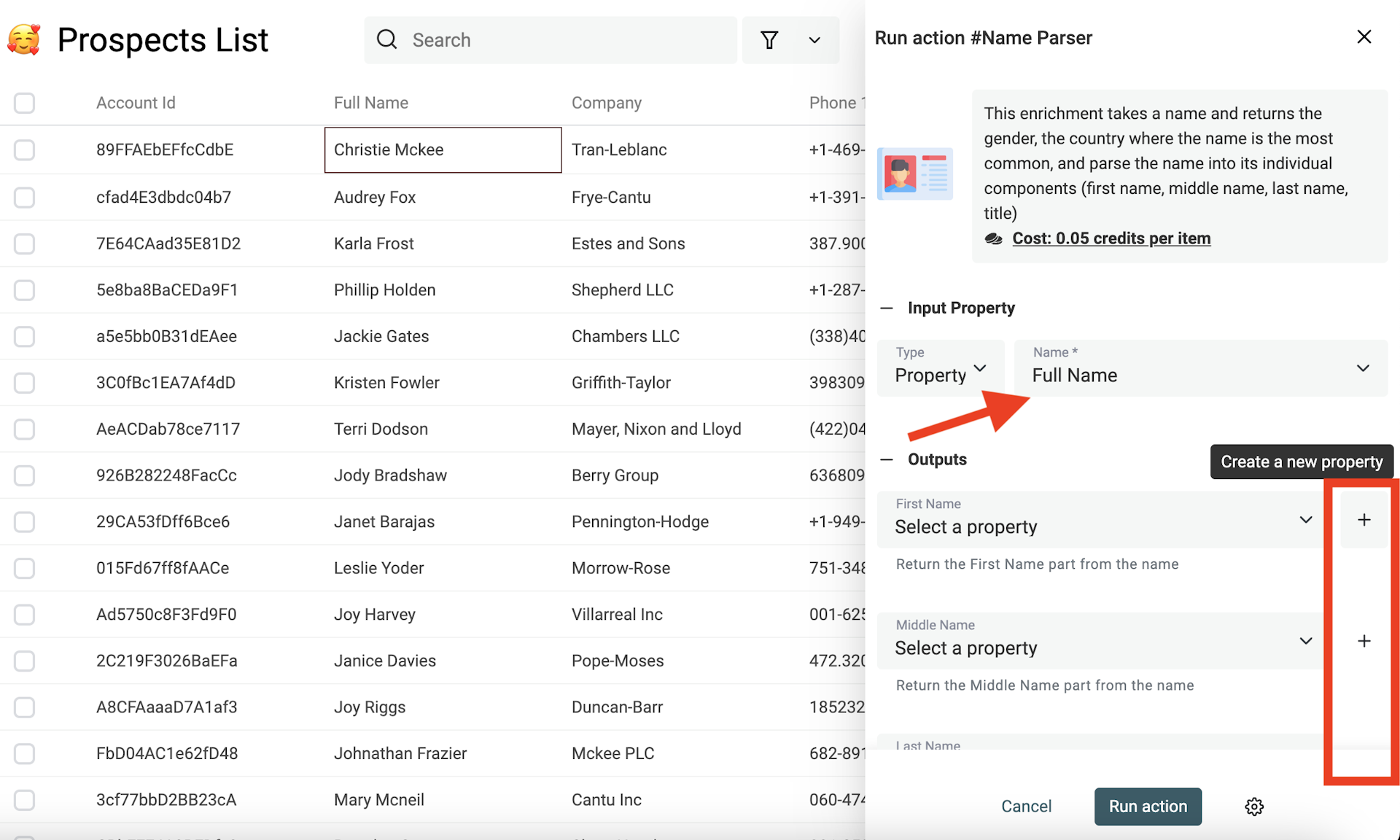
Le Name Parser est un enrichissement parfait pour nettoyer les noms de personne. Il découpe un nom complet (full name) en parties : prénom, deuxième prénom, nom. Et propose aussi le genre et la nationalité les plus probables.
Cette action repose sur des statistiques de noms.
Pour y accéder, ouvrez le menu "Enrich" dans la barre supérieure.
Sélectionnez ensuite "Name Parser".

Sélectionnez le champ contenant les noms, et la propriété qui stockera chaque partie. La propriété d'origine n'est jamais modifiée, seules les nouvelles propriétés récupèrent les résultats.
Normaliser les noms d'entreprise
Le bruit dans les raisons sociales (préfixes, suffixes, stop-words, addenda régionaux…) empêche aussi le bon matching.
Exemple de nettoyage : supprimer les suffixes type "Inc." ou "GmbH".
Utilisez cette regex dans Find & Replace :
,?\s(llc|inc|incorporated|corporation|corp|co|gmbh|ltd).?$
Et remplacez par une chaîne vide.

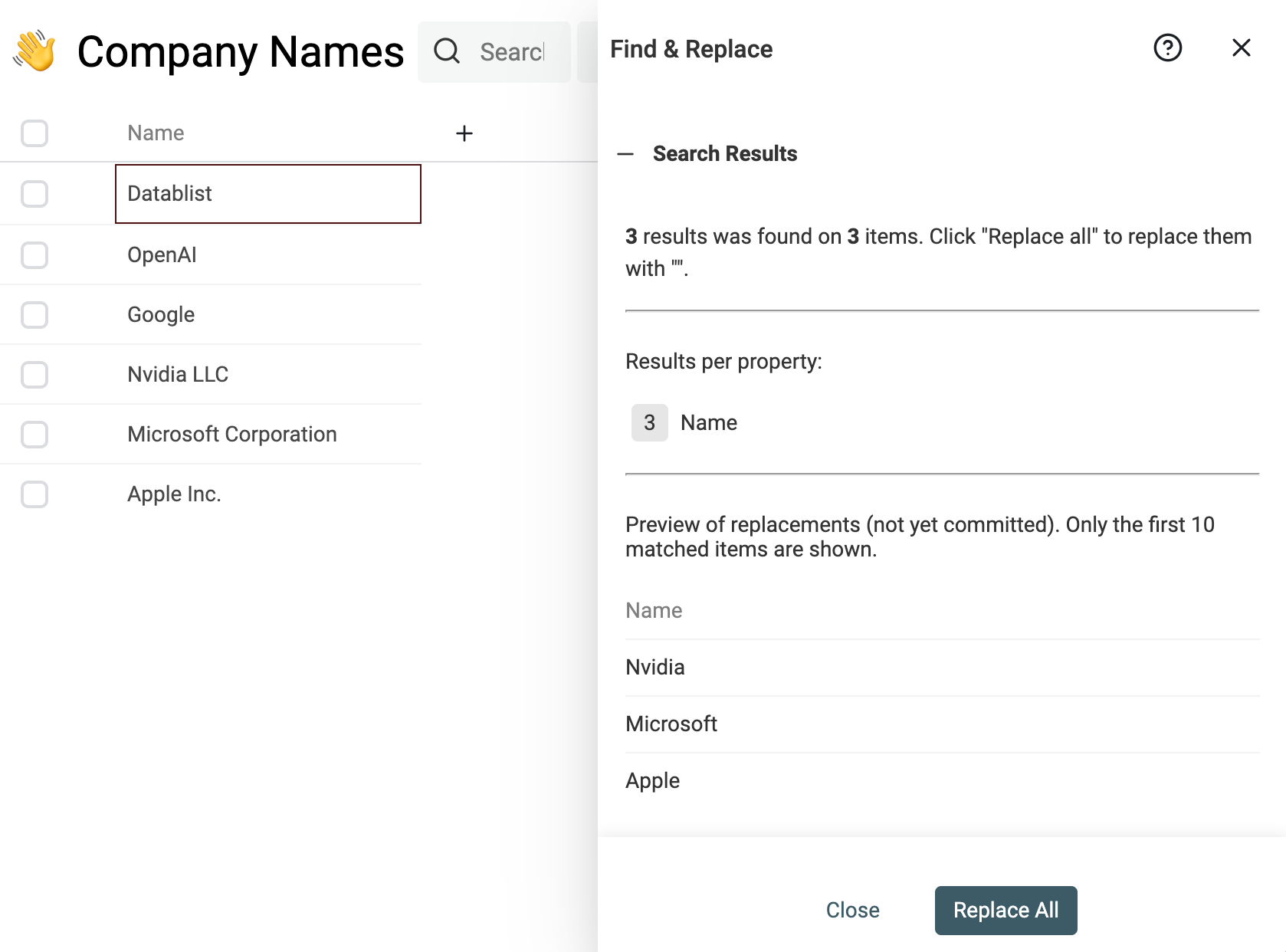
Normaliser les noms d’entreprise et adresses sur tous vos jeux de données permet une comparaison cohérente.
Normaliser les noms de rue
Si vous matchez des adresses postales, la normalisation des noms de rue est indispensable. Les noms peuvent contenir des abréviations, préfixes directionnels, suffixes numériques… Sans cette étape, une même rue peut ressortir sous plusieurs formes, rendant la tâche très complexe.
Exemples : Main 9 St, Main 9TH St., Main 9th Street désignent la même voie. De même pour Washington Blvd et Washington Boulevard.
Utiliser des algorithmes de fuzzy matching pour traiter ces variations n’est pas efficace : plusieurs lettres diffèrent entre Washington Blvd et Washington Boulevard, la similarité calculée par les algos de fuzzy-matching serait faible.
La meilleure solution consiste à normaliser ces noms de rue pour avoir un format unique.
Datablist propose la normalisation des adresses en anglais (abréviations, numéros…).
Note
La normalisation du nom de rue s’applique uniquement à un champ dédié au nom de rue. Impossible avec une adresse complète en un seul champ.
Cliquez sur "Normalize Street Names" dans le menu "Clean".
Sélectionnez ensuite la propriété contenant le nom de rue, puis l’option "Normalize english street names".
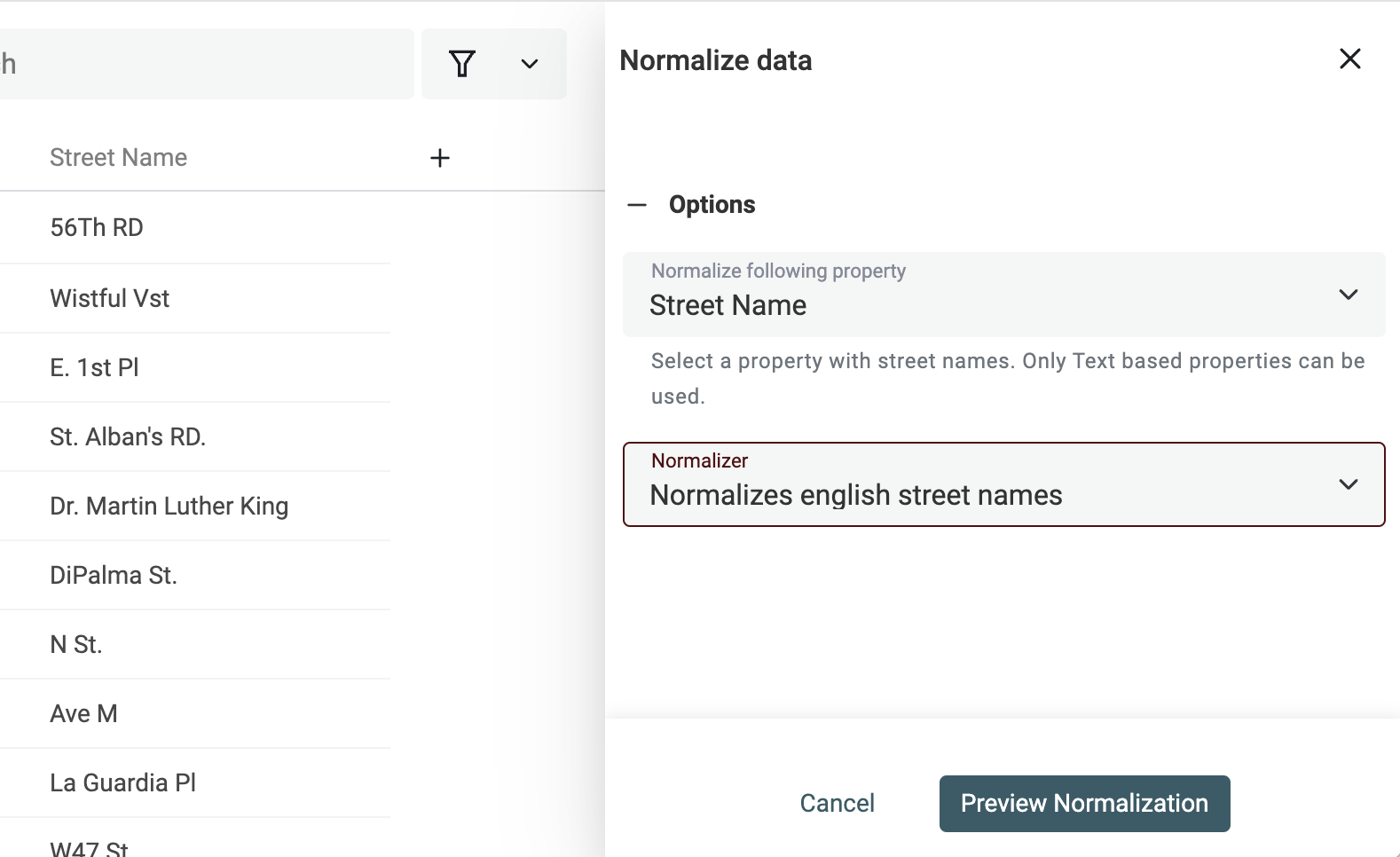
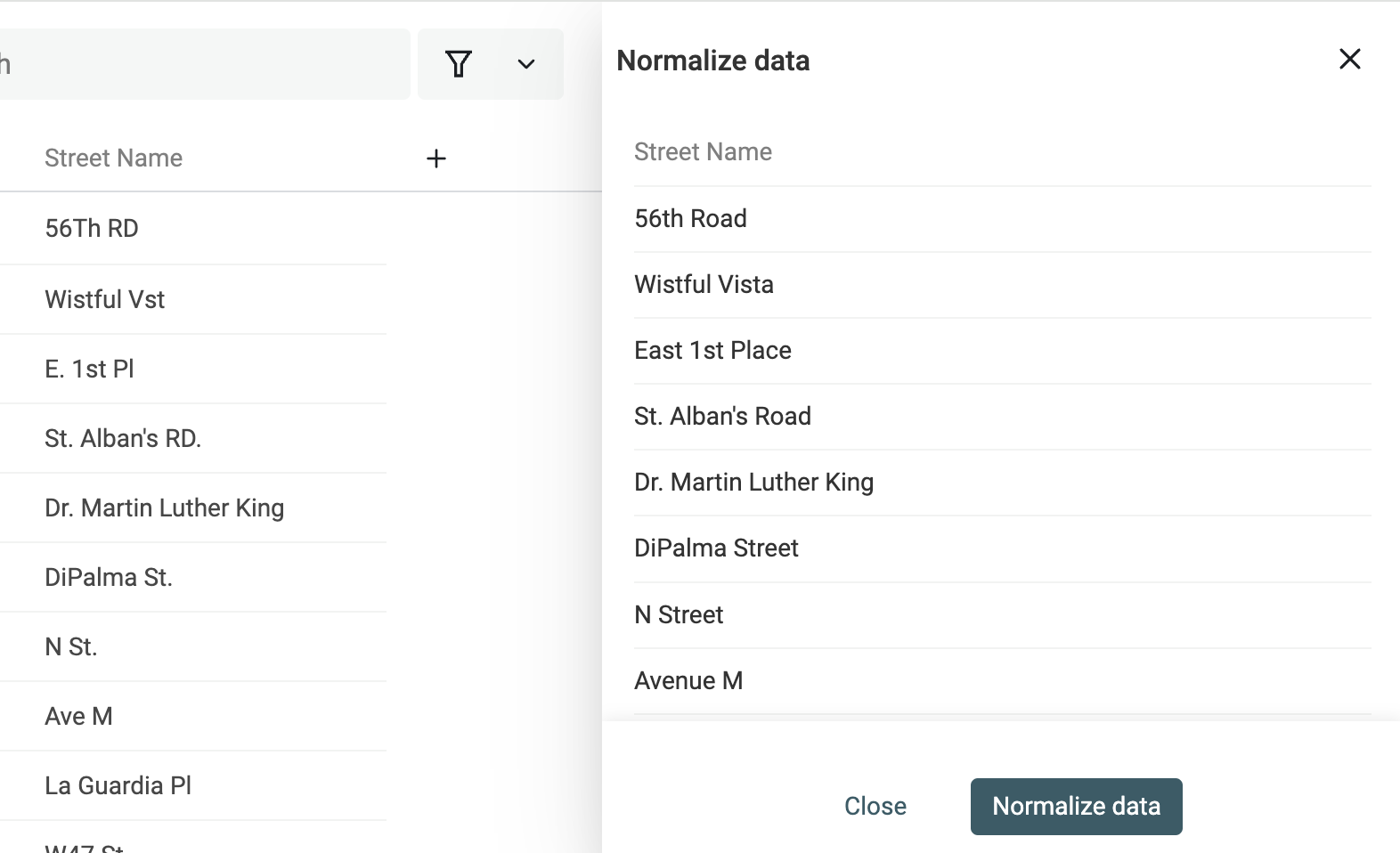
Vérifiez l’aperçu et cliquez sur "Run".
Etape 3 : Correspondance des enregistrements au sein ou entre plusieurs collections
Une fois vos données nettoyées et normalisées, place au matching. Ici, il s'agit de regrouper les enregistrements similaires.

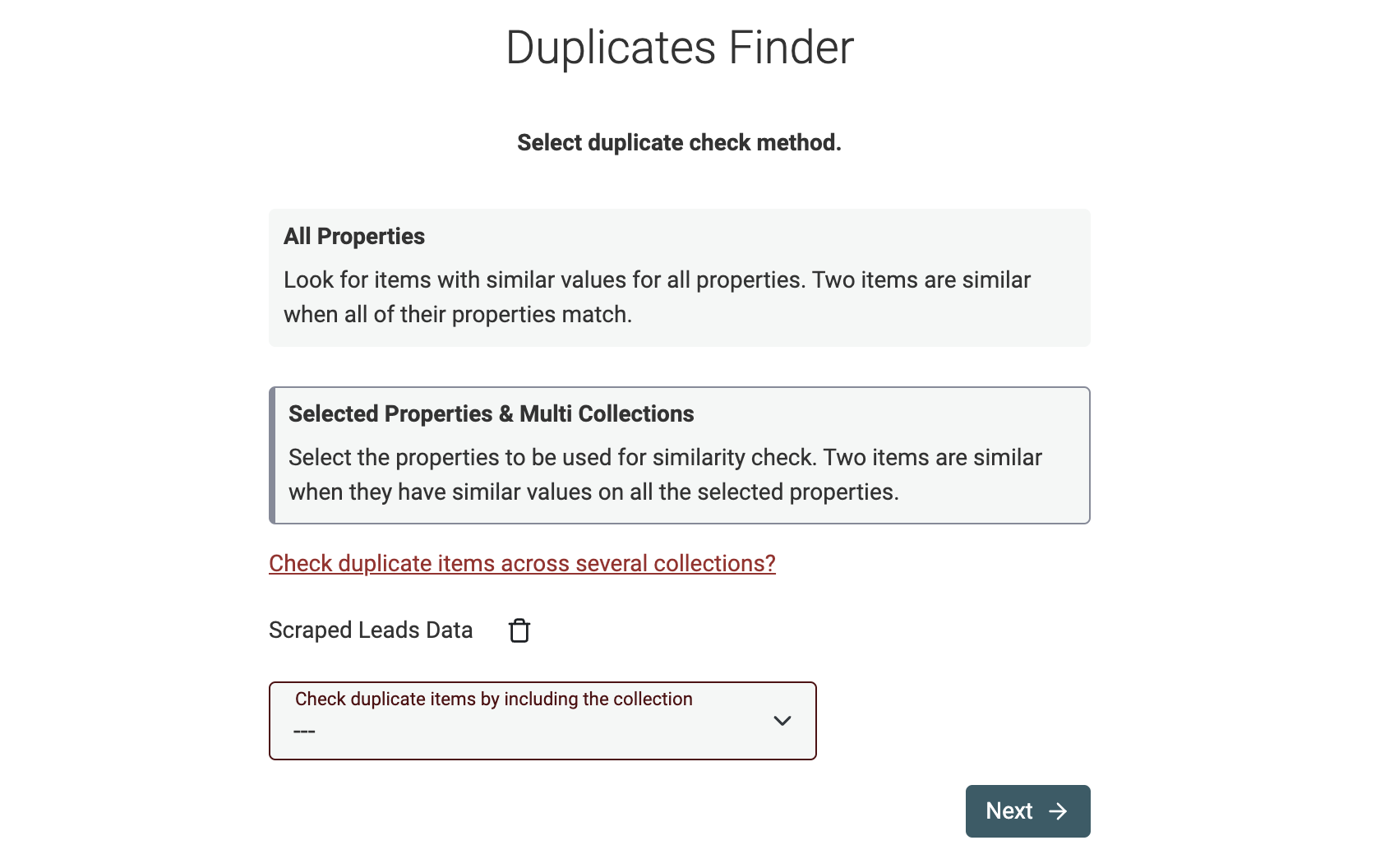
Datablist propose deux modes pour comparer vos données :
- Comparaison de propriétés sélectionnées : le mode le plus utilisé. Vous choisissez les propriétés à comparer. Compatible multi-collections.
- Comparaison complète : le Duplicates Finder détecte et supprime automatiquement les lignes rigoureusement identiques (même données sur toutes les propriétés). Si un champ est vide, la correspondance n’est pas faite.
Sélectionner les propriétés à comparer
Dans cette partie nous utiliserons le mode "Selected Properties & Multi Collections".
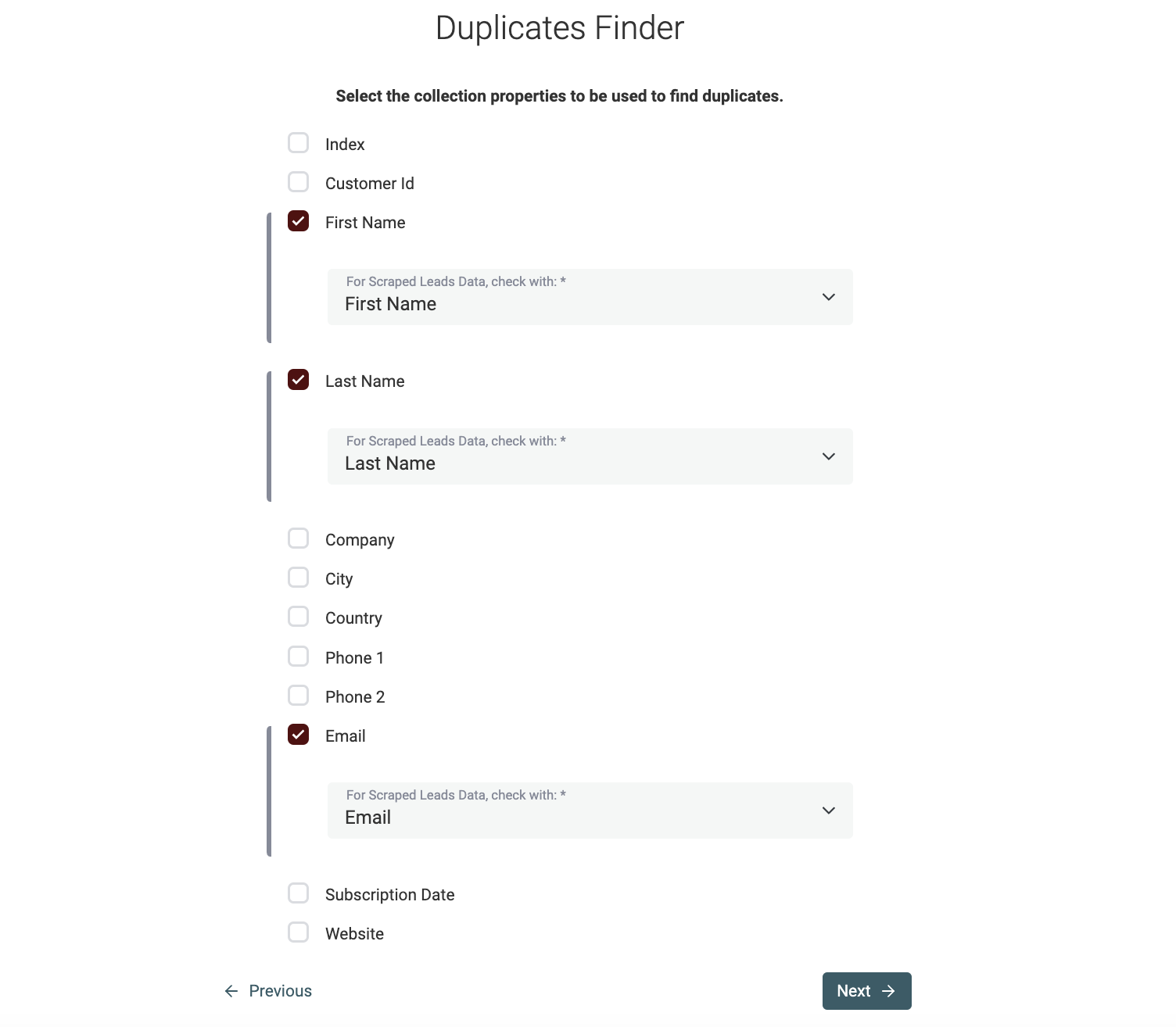
Choisissez à présent les propriétés à utiliser pour identifier les doublons. Si vous sélectionnez plusieurs collections, vous devrez faire un mapping de vos propriétés.
Note
Datablist tente d’auto-mapper vos champs ayant le même nom entre collections.
Choisir l’algorithme de matching
À cette étape, choisissez un algorithme de comparaison pour chaque propriété :
- Exact : idéal pour les propriétés non textuelles (date, nombre, booléen…). Pour le texte, l'option "case-sensitive" est disponible. Le mode exact retire les espaces en début/fin de chaîne.
- Smart : pré-traite la donnée pour accepter les petites variations (URLs avec/ sans protocole, ordre des mots, ponctuation…). "John-Doe" et "Doe John" seront reconnus comme identiques.
- Phonetic en Double Metaphone : implémente l'algorithme Double Metaphone pour la phonétique. Convertit les mots en codes selon la prononciation, permettant de matcher deux mots qui sonnent pareil.
- Fuzzy matching (Jaro-Winkler, Levenshtein) : pour gérer les variations typographiques, avec un seuil de similarité personnalisable.
Voir la documentation pour plus de détails.
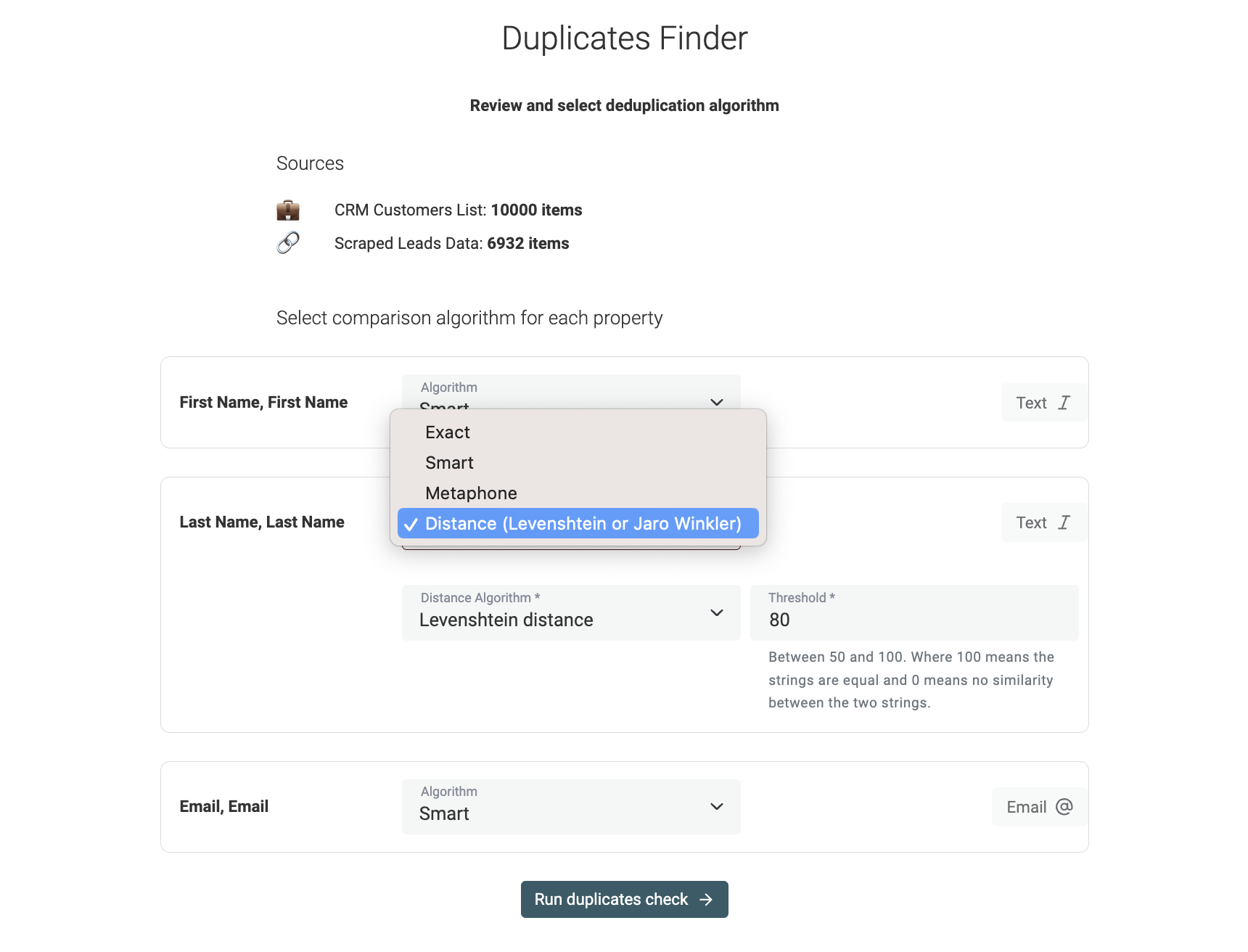
Note
- Smart, Phonetic et Fuzzy s'appliquent uniquement aux propriétés texte (email, text, longtext…)
- Les propriétés type URL ne sont compatibles qu'avec Exact et Smart.
Etape 4 : Suppression ou fusion des groupes matches (déduplication)
Le Duplicates Finder de Datablist retourne en quelques secondes la liste des groupes matches.
Fusion automatique des doublons dans une collection
L’outil de Data Matching propose deux modes pour fusionner vos doublons :
- [Fusion sans conflit] (#auto-merging-without-data-conflicts) (voir ci-dessous)
- [Fusion avec concaténation ou drop de la valeur conflictuelle] (#auto-merging-without-data-conflicts) (voir ci-dessous)
Note :
Cette fonctionnalité n’est proposée qu’en déduplication sur une unique collection (single collection). Sur plusieurs collections, les structures pouvant être différentes.
Auto-Merging sans conflit de données
Datablist détecte les doublons pouvant être fusionnés sans perte de donnée :
- Si tous les items ont strictement les mêmes valeurs, un seul est conservé.
- Si certains doublons sont complémentaires, l’item le plus complet sert de base et les propriétés manquantes sont complétées. Tous les autres sont supprimés.
- En cas de conflit (valeurs différentes pour la même propriété), la fusion passe en mode manuel.
Auto-Merging en cas de conflit
Lorsque le conflit est détecté, deux options sont proposées :
- Combiner les valeurs avec un séparateur. Parfait pour les champs texte (email, téléphone, notes…)
- Supprimer la valeur conflictuelle : pour les propriétés non textuelles (ex : date), à vous de choisir la valeur à conserver. Idem pour les identifiants externes (ID CRM...).
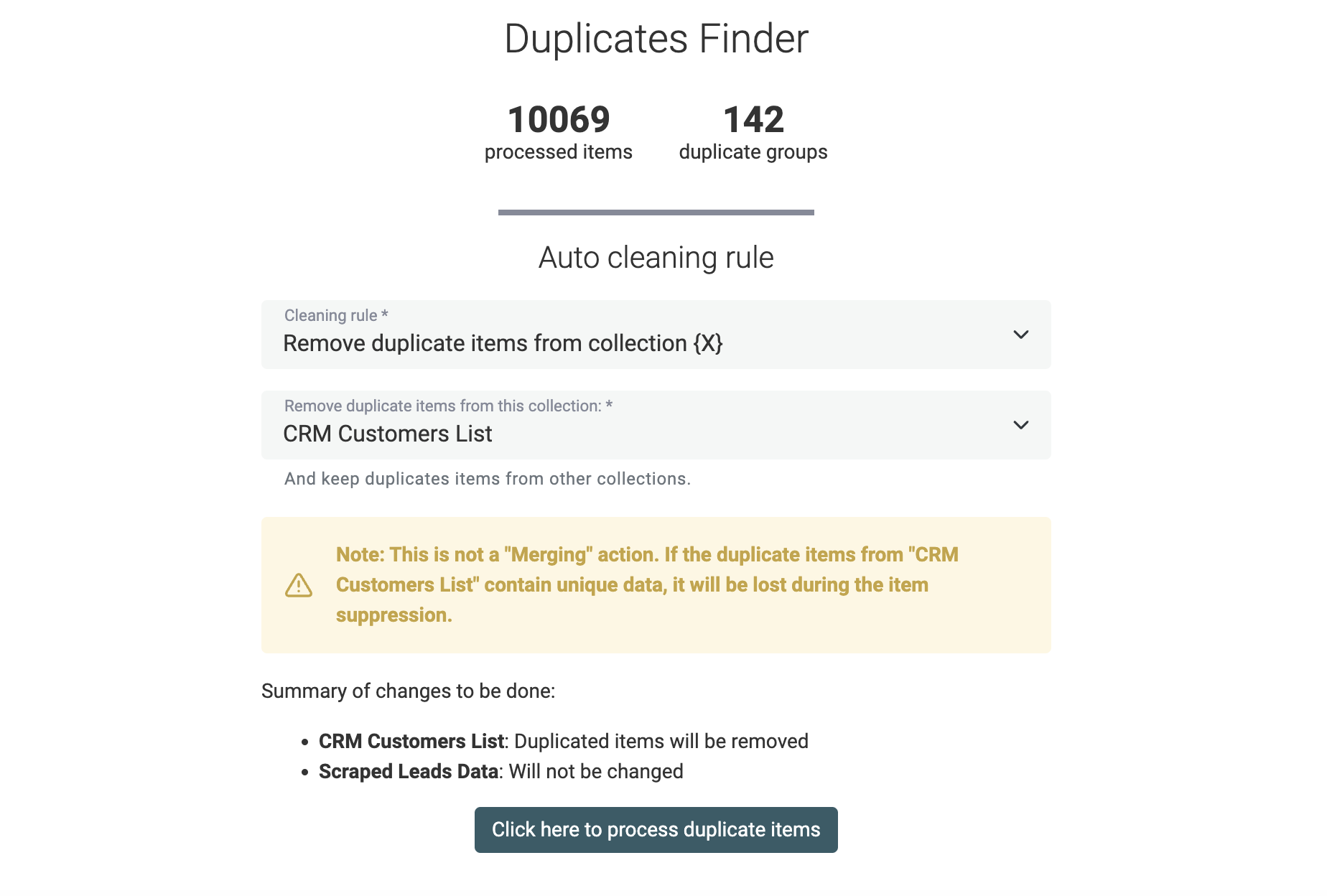
Règles de nettoyage en data matching multi-collections
En mode multi-collections, la fusion automatique est désactivée. Vos structures de données pouvant varier.
À la place, Datablist propose de supprimer les doublons dans toutes les collections sauf une, assurant l’unicité sur l’ensemble de vos datasets.
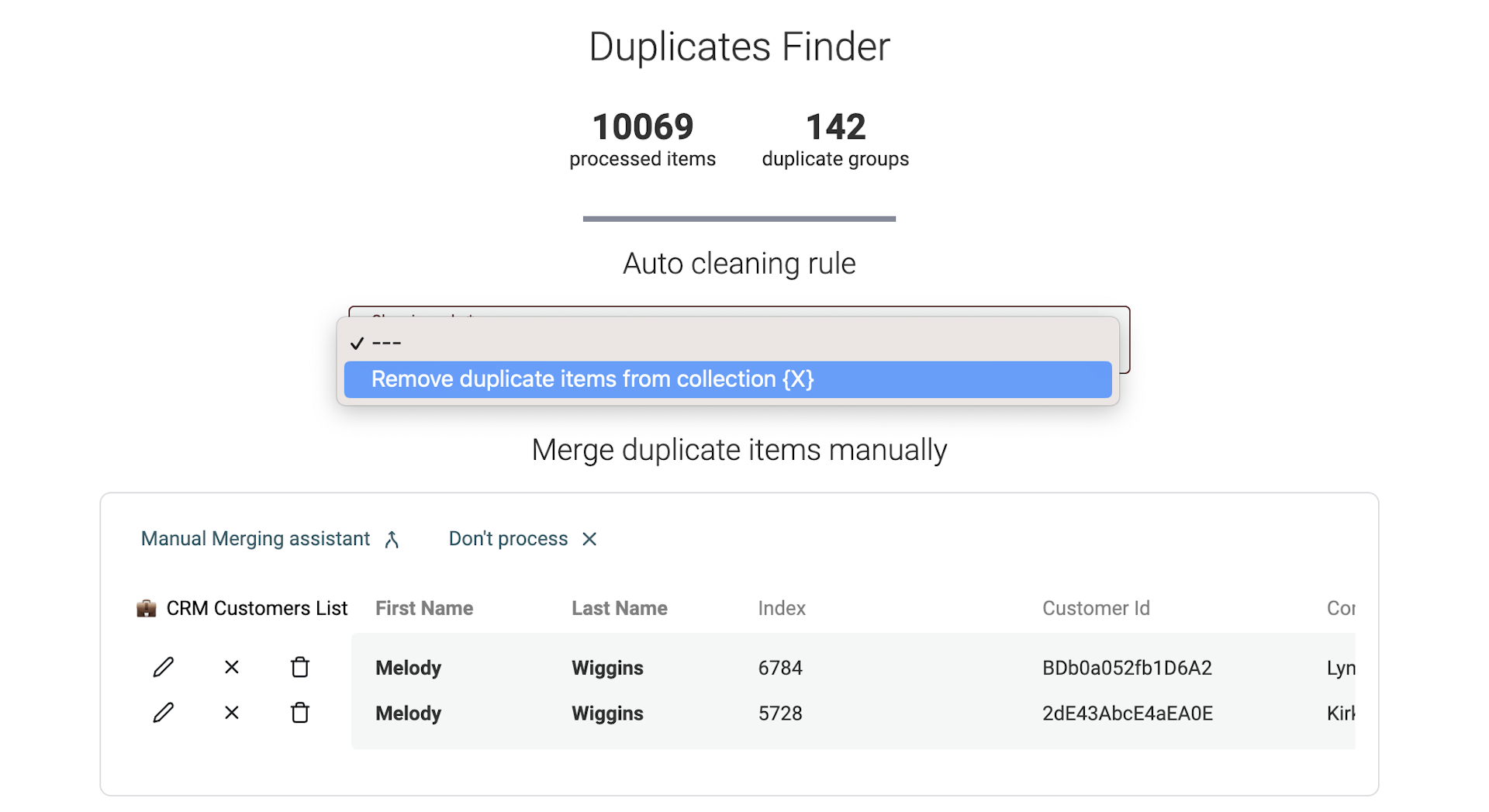
Un aperçu des modifications est proposé avant exécution.
Fusion manuelle des doublons avec l’assistant
Pour les doublons restants, un assistant de fusion manuelle est proposé.
Cliquez sur "Manual Merging Assistant" à gauche de chaque groupe de doublons.
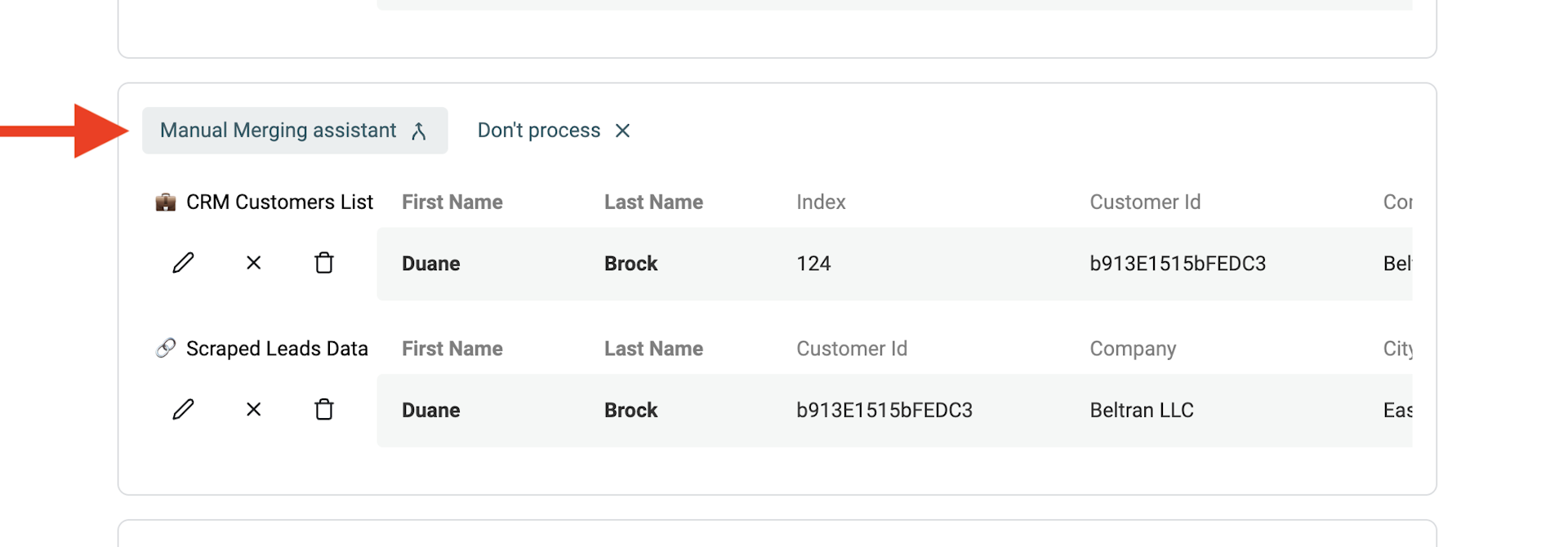
Un écran s’ouvre : à droite "Primary Item" (élément maître), à gauche les autres éléments. Datablist choisit comme item principal celui contenant le plus d’informations.
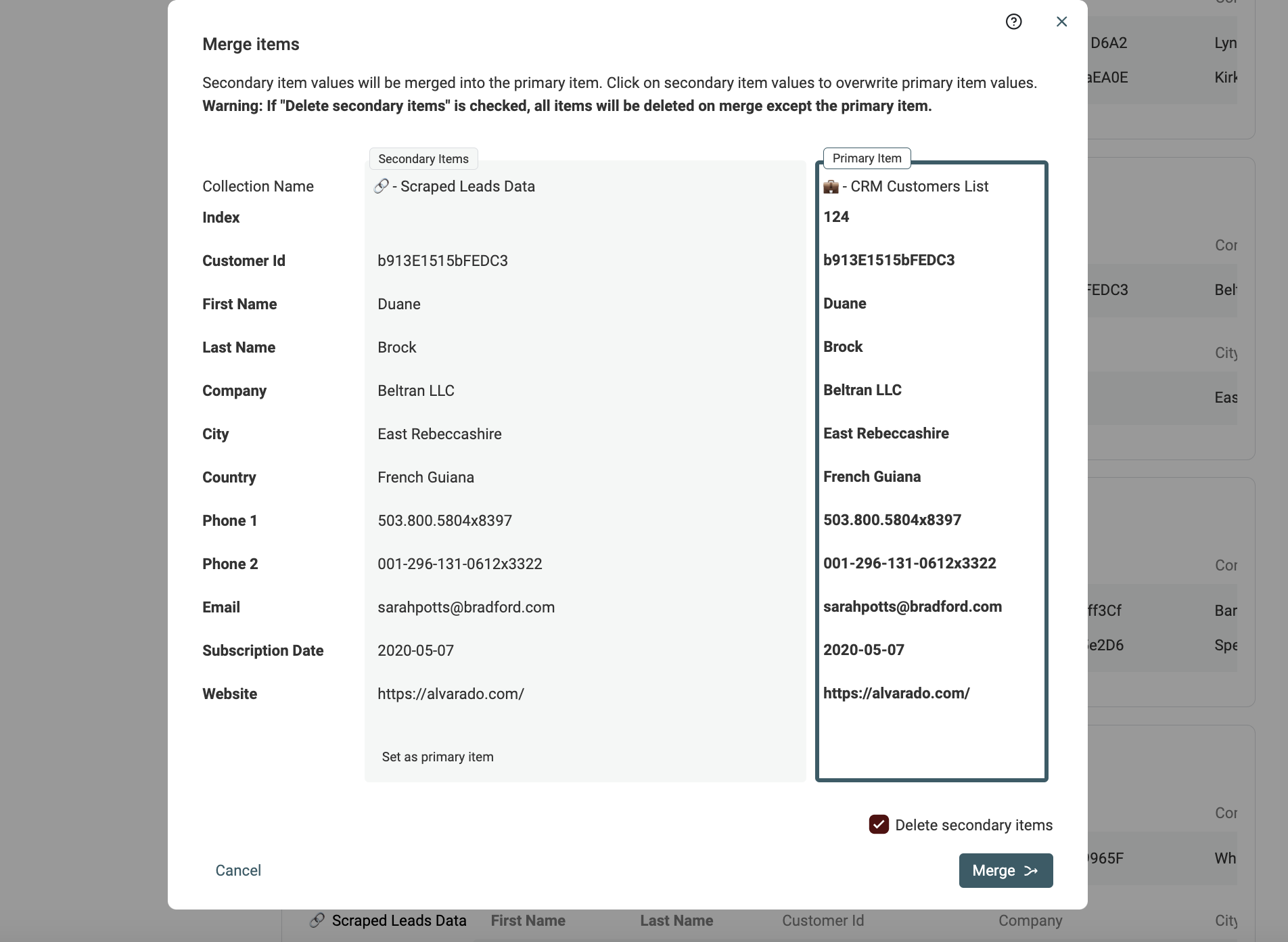
Quand possible, les valeurs manquantes dans l’item principal sont pré-remplies. En cas de conflit, vous choisissez vous-même la donnée à conserver.
Si l’élément fusionné vous convient, cliquez sur Merge pour valider la fusion. Les doublons secondaires sont alors supprimés, seul le nouvel item fusionné reste.
Note L’assistant manuel est aussi disponible en multi-collections si les propriétés sont similaires.
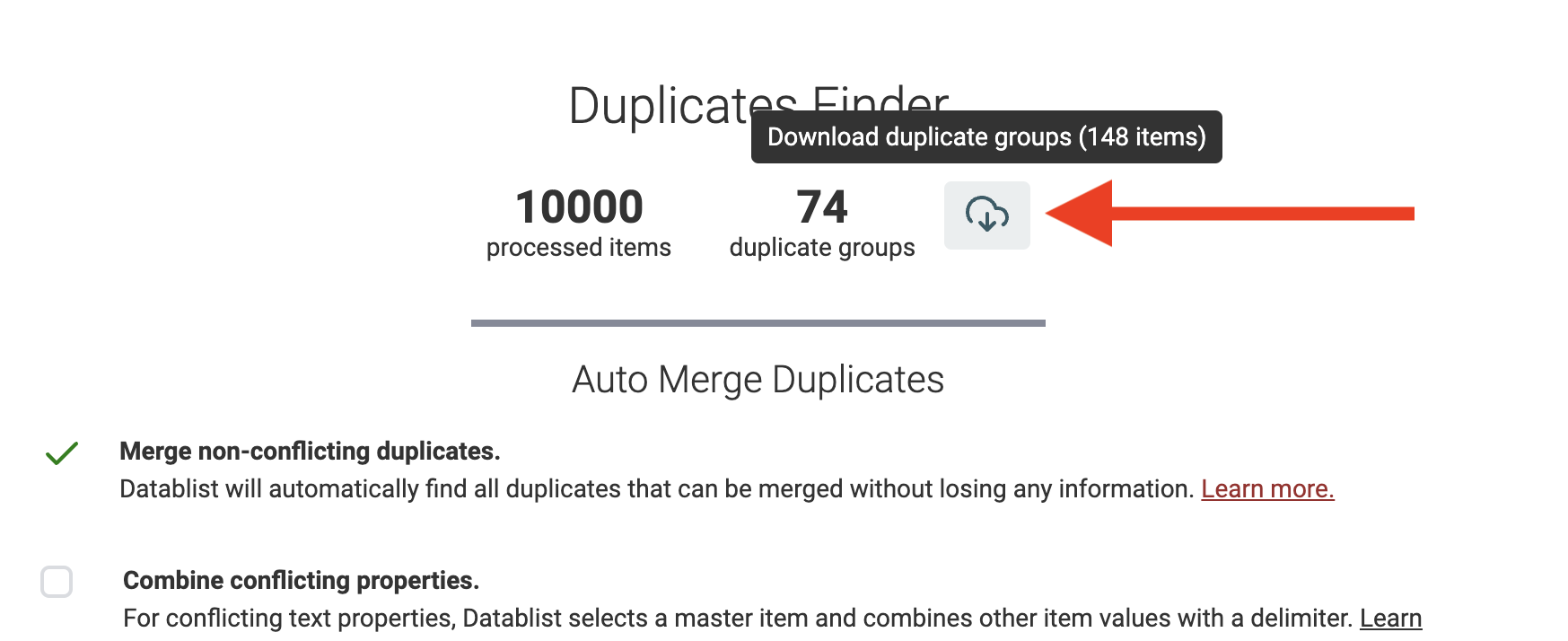
Exporter les groupes de doublons
Enfin, Datablist vous permet d’exporter les groupes de doublons détectés en CSV ou Excel, pour un nettoyage complémentaire via un outil externe (tableur, script, etc.).
FAQ
Qu’est-ce que le data matching ?
Le data matching (ou record linkage, déduplication) vise à identifier et relier des enregistrements similaires, dans une ou plusieurs bases de données. Objectif : améliorer la qualité, la précision et la cohérence de la donnée, en consolidant ou supprimant les entrées dupliquées/similaires représentant une même entité (personne, entreprise…).
C’est indispensable pour nettoyer des bases où les doublons s’accumulent, ou fusionner plusieurs sources avec des données qui se recoupent.
En matching, on s’appuie sur des champs discriminants (email, URL, identifiants…) ou des combinaisons d'attributs non uniques (nom, date de naissance, localisation…) pour calculer une similarité entre enregistrements.
Quelle est la performance de Datablist sur le data matching ?
Datablist charge vos datasets en mémoire pour effectuer l’analyse. L’outil convient pour des jeux de données jusqu’à 1 million d’enregistrements, et la plupart des analyses sont réalisées en quelques minutes.
Faut-il des compétences techniques pour faire du data matching ?
Non. Datablist est une solution no-code conçue pour tous : data analysts, marketing, commerciaux…
Quand utiliser le data matching ?
Le data matching est utile dans de nombreux domaines : finance, santé, marketing, gestion client…
Il sert par exemple à : détecter la fraude, consolider des profils, enrichir la donnée à partir de sources variées.
Et ensuite ?
Si le data cleaning vous intéresse, découvrez :