

Nettoyer des doublons, ce n’est pas juste cliquer sur « delete » !
Certaines lignes sont des copies parfaites. D’autres contiennent des infos qui se contredisent. Beaucoup sont complémentaires et doivent être fusionnées plutôt que supprimées.
Selon votre workflow, vous devrez parfois fusionner des fiches, mettre à jour un enregistrement “master”, ou simplement marquer les doublons pour les relire.
Les outils basiques suppriment des lignes sans comprendre les priorités entre champs ni vos règles métier. Résultat : vous détruisez des données utiles.
Une bonne déduplication repose sur une logique claire : définir comment choisir l’élément “master”, comment résoudre les conflits, et quoi faire des enregistrements secondaires.
Dans cet article, on passe en revue des méthodes concrètes pour fusionner, mettre à jour et supprimer des doublons dans des fichiers CSV, des feuilles Excel et des CRM.
C’est parti !
📌 Résumé pour les pressés
Cet article vous explique tout ce qu’il faut savoir pour dédupliquer vos spreadsheets : fusionner, mettre à jour et supprimer des doublons proprement.
Problème : sans comprendre les règles de priorisation et les actions en masse, vous allez soit perdre des données importantes, soit conserver les mauvais enregistrements.
Solution : Datablist propose 3 méthodes de déduplication : fusion/suppression simple, édition assistée par IA pour des règles complexes, et déduplication multi-fichiers.
Les méthodes de déduplication couvertes :
En 10 minutes, vous allez apprendre
- Ce qu’est Datablist et pourquoi on est légitimes sur le sujet des doublons
- Ce qu’il faut comprendre sur les doublons avant de nettoyer / dédupliquer votre liste
- Les 3 méthodes les plus efficaces pour supprimer vos doublons (pas à pas)
Pourquoi vous pouvez nous faire confiance
Datablist est une plateforme pour créer des workflows de lead generation. Aujourd’hui, 26 000 utilisateurs s’en servent pour trouver, enrichir et nettoyer des données grâce à plus de 60 outils : des AI Agents aux Email Finders, en passant par des AI processors, des Technology enrichments, et bien plus.
En plus, Datablist inclut une suite de déduplication complète : vous pouvez fusionner, mettre à jour, supprimer ou marquer des doublons en quelques clics, sans écrire une ligne de code.
Comprendre les bases de la déduplication
Avant de passer au “comment”, voici les principes qui expliquent les différentes techniques de déduplication.
Cette section couvre :
- Une explication rapide des types de doublons
- Les fondamentaux pour traiter des doublons conflictuels
- Les questions à se poser pour clarifier votre objectif
Ce qu’il faut comprendre : bases de la déduplication
Les points suivants sont surtout utiles pour une déduplication sur un seul fichier. Pour une déduplication multi-fichiers, vous pouvez uniquement supprimer des copies dans certains fichiers (pas fusionner ni mettre à jour). Comprendre ces principes reste utile, même si ce n’est pas strictement indispensable.
Par défaut, Datablist essaie de fusionner automatiquement les doublons. En pratique, ce n’est pas toujours possible, car la plupart des utilisateurs ont des doublons conflictuels.
Quand il y a conflit, tout repose sur deux concepts :
- des schémas de priorisation pour choisir l’enregistrement “master” dans un groupe de doublons
- des actions en masse pour gérer les enregistrements secondaires de ce groupe
Comprendre les types de doublons
On classe les doublons selon le niveau de similarité de leurs champs.
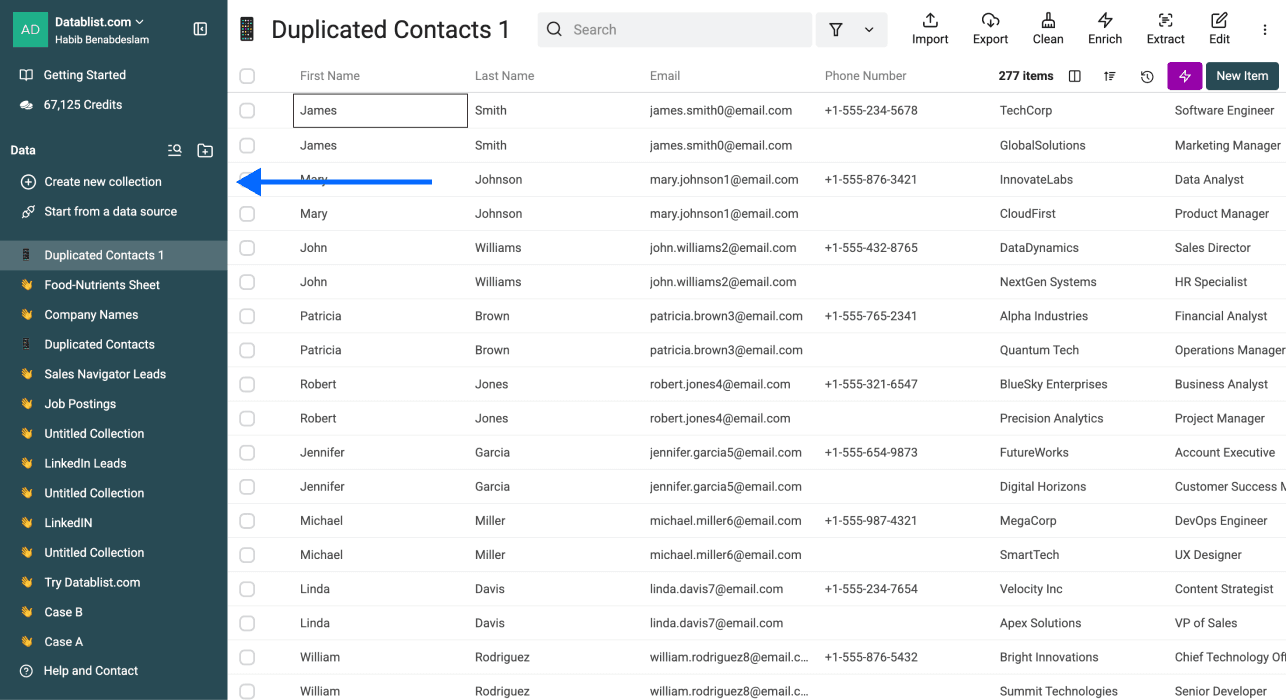
- Doublons exacts : toutes les colonnes ont les mêmes valeurs. Souvent causés par un import en double ou un copier-coller accidentel.
- Doublons conflictuels : les enregistrements représentent la même entité, mais certains champs divergent (téléphone, intitulé de poste, CA, etc.).
- Doublons complémentaires : chaque ligne contient des infos utiles différentes, qu’il faut combiner. Par exemple, un enregistrement a une adresse email et son doublon a un numéro de téléphone.

Première étape : définir un schéma de priorisation
Vous devez décider quel enregistrement devient la référence. On appelle ça la Master Item Rule. Gardez bien ce terme : vous allez en avoir besoin.
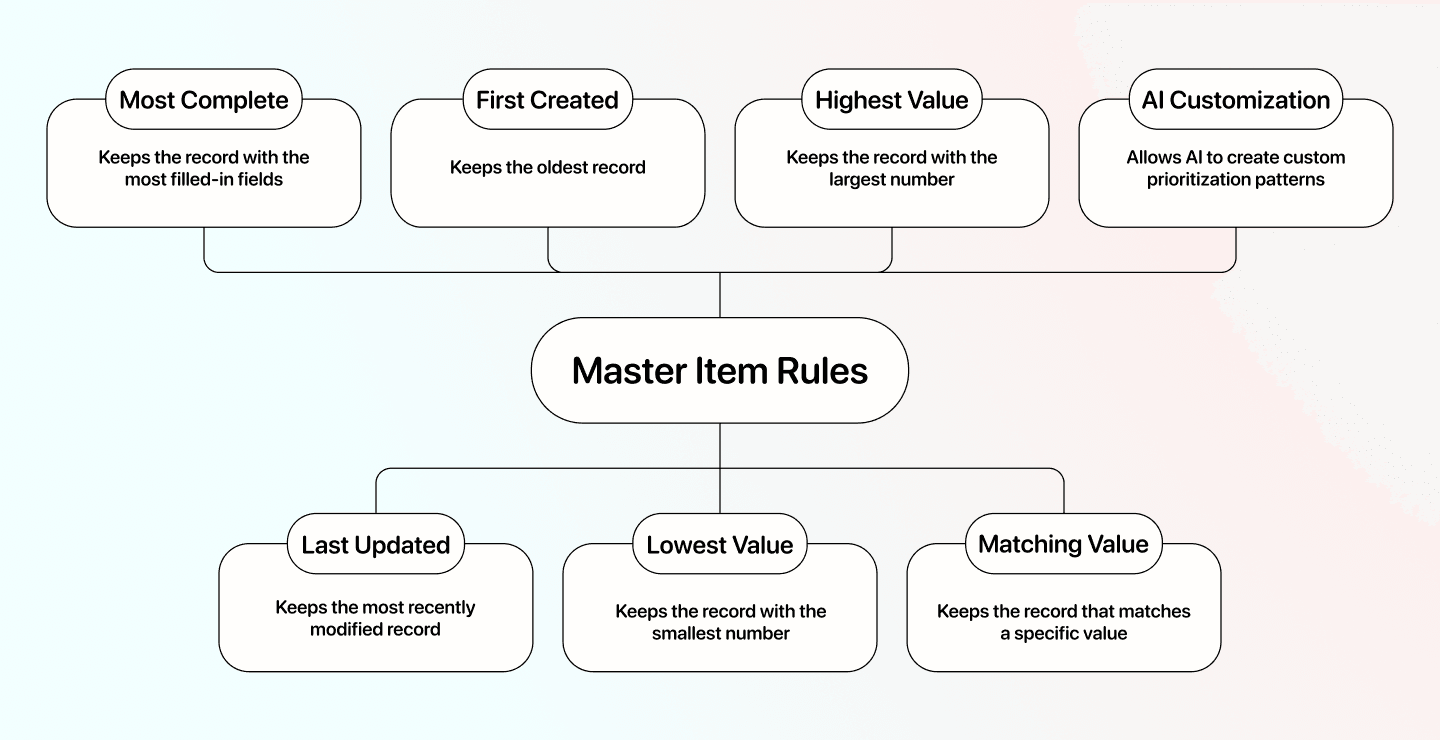
Exemples de schémas/Master Item Rules :
- Most complete : conserve l’enregistrement avec le plus de champs renseignés
- Last updated : conserve l’enregistrement le plus récemment modifié
- First created : conserve l’enregistrement le plus ancien
- Lowest value : conserve l’enregistrement avec la plus petite valeur sur une colonne donnée
- Highest value : conserve l’enregistrement avec la plus grande valeur sur une colonne donnée
- Matching value : conserve l’enregistrement qui correspond à une valeur précise sur une propriété que vous définissez
📘 Master Item Rules
Important : “Last updated” et “First created” ne sont pertinents que pour des données suivies et mises à jour dans Datablist dans le temps. Si vous venez juste d’importer un fichier, ces options ne fonctionneront pas car les spreadsheets importés ne contiennent pas ces métadonnées.
Si vous hésitez, on vous recommande de choisir “Most complete” ou d’utiliser la technique expliquée dans la deuxième partie de cette section.
Pour les cas plus complexes, Datablist vous permet d’utiliser l’IA pour créer des schémas de priorisation sur mesure, par exemple : si la colonne A contient “Hello people” et la colonne B contient “of Germany”.
On détaille ça dans la deuxième partie de la section pas à pas.
Deuxième étape : choisir une action en masse
Une fois votre schéma de priorisation choisi, l’étape suivante consiste à définir ce que vous voulez faire des enregistrements qui ne gagnent pas.
Exemples d’actions en masse pour traiter des doublons :
- Supprimer les éléments secondaires
- Fusionner l’élément master et l’élément secondaire en un seul enregistrement
- Fusionner certaines propriétés de l’élément secondaire avec l’élément master, puis supprimer le reste
- Mettre à jour certaines propriétés de l’élément master avec les valeurs de l’élément secondaire
- Marquer les doublons sans les supprimer (très utile en organisation, quand les enregistrements secondaires sont nécessaires pour la conformité)
- … et tout ce qui fait sens dans votre contexte
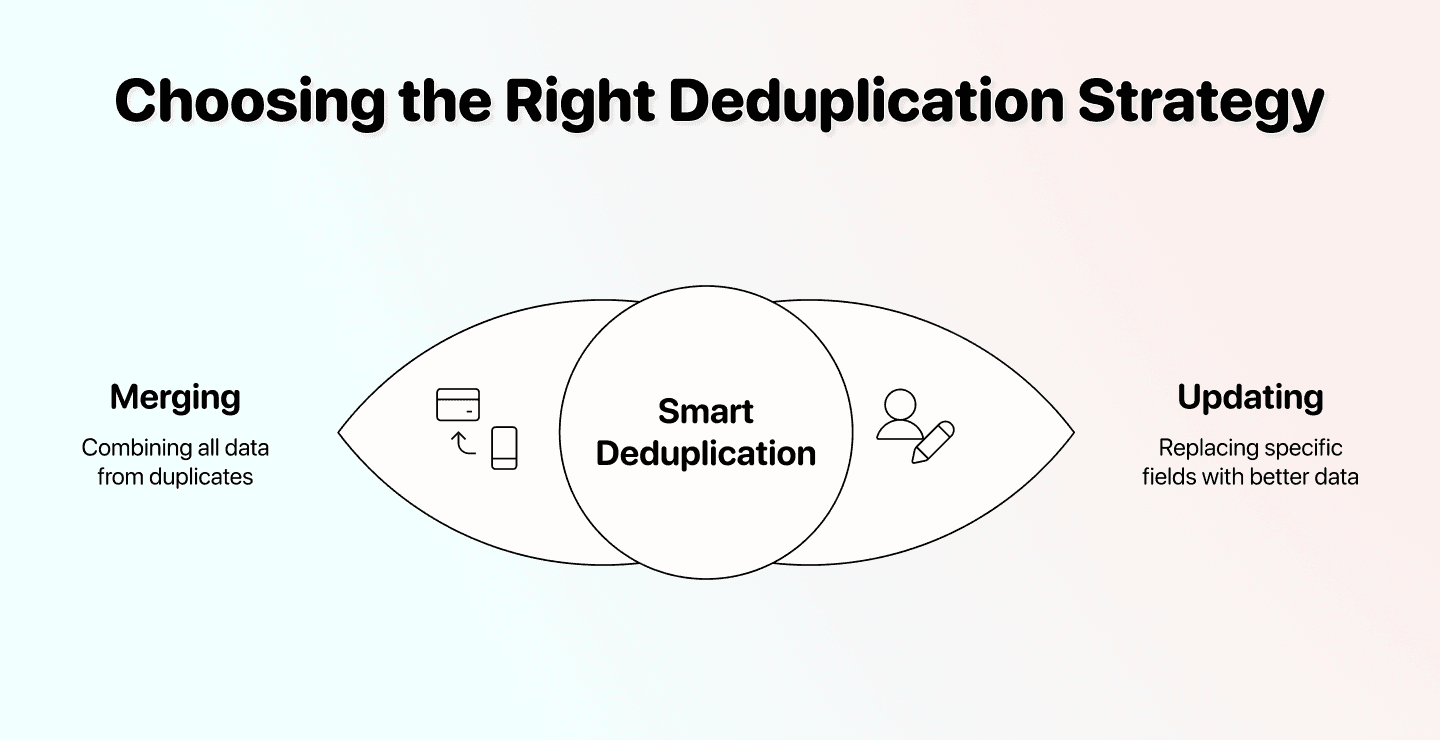
📘 Fusionner des doublons vs. Mettre à jour des doublons
Fusionner, c’est combiner les valeurs des deux enregistrements. Très pratique pour des contacts CRM en double, quand il y a des notes dans les deux fiches.
Mettre à jour, c’est remplacer certains champs par de meilleures données issues d’une autre source. À utiliser quand chaque doublon a une partie “vraie” : par exemple, garder le contact A, mais corriger son job title avec celui (plus exact) du contact B.
Les questions à se poser avant de dédupliquer une liste
Maintenant que vous avez compris la logique “priorisation + action en masse”, voici des questions simples pour identifier rapidement votre schéma et ce que vous ferez des autres enregistrements.
Quel enregistrement doit devenir votre Master Item ?
Cette question vous aide à définir votre schéma de priorisation. Demandez-vous ce qui rend un doublon “meilleur” qu’un autre.
Posez-vous :
- Est-ce qu’un enregistrement est plus complet que les autres ?
- Est-ce qu’une source est plus fiable qu’une autre ?
- Est-ce qu’un enregistrement est plus récent ou plus fraîchement mis à jour ?
- Est-ce qu’une valeur spécifique fait de cette ligne la version “correcte” ?
Votre réponse détermine la Master Item Rule :
- Si la complétude prime → utilisez “Most complete”
- Si la récence prime → utilisez “Last updated” ou “First created”
- Si une valeur précise doit “gagner” → utilisez “Matching value”
- Si la logique est plus subtile → utilisez AI Editing (Méthode 2)
Que doit-il arriver aux enregistrements non-master ?
Cette question vous aide à choisir votre action en masse. Une fois que vous avez un gagnant, que faites-vous des autres ?
Posez-vous :
- Est-ce que les autres lignes contiennent des données utiles que je veux garder ?
- Est-ce que je dois combiner des infos de plusieurs lignes en une seule ?
- Est-ce que je veux juste supprimer le surplus et passer à autre chose ?
- Est-ce que je dois marquer les doublons pour relecture au lieu de supprimer ?
Votre réponse détermine l’action en masse :
- Si les autres lignes n’apportent rien → drop all conflicting values / delete
- Si les autres lignes ont de la valeur → combine the conflicting values ou update le master
- Si vous avez des contraintes de conformité → flag sans supprimer
- Si vous devez sélectionner au cas par cas → AI Editing (Méthode 2)
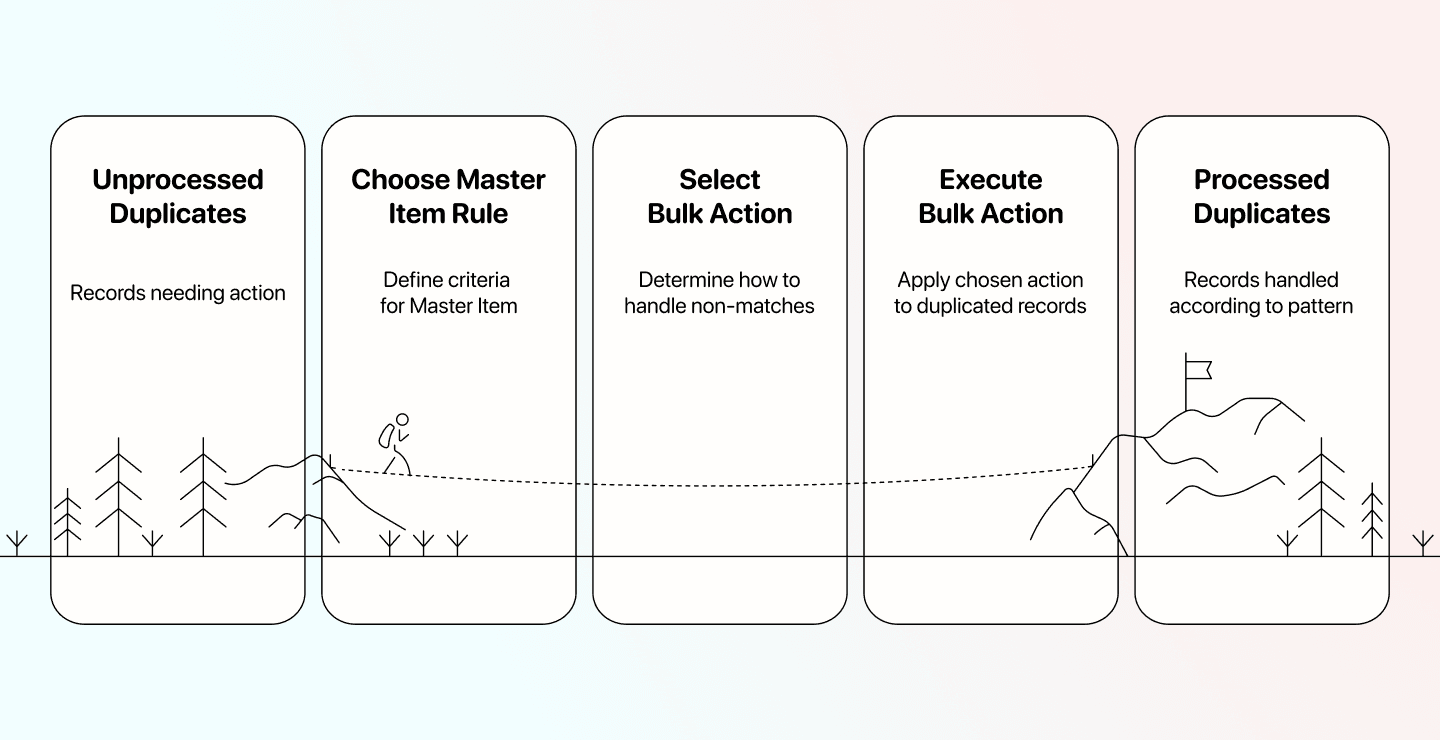
Deduplication : nettoyer les enregistrements en doublon dans vos données
Datablist dispose d’une suite de déduplication qui couvre tous les cas, de la suppression simple de doublons à la déduplication multi-fichiers. Dans cette section, on va donc voir 3 workflows :
- Fusion et suppression de doublons sur un seul fichier avec des règles simples
- Mise à jour et suppression sur un seul fichier avec des règles complexes
- Suppression de doublons entre plusieurs fichiers (pas de fusion possible)
On démarre !
Comment Datablist gère les doublons (rappel rapide)
Si vous avez lu la section précédente, vous pouvez sauter ce passage ; sinon, voici un résumé clair de ce que vous allez faire.
- Datablist scanne vos données et repère les lignes qui “matchent” selon les colonnes que vous choisissez.
- Quand il trouve des doublons, il peut les auto-fusionner pour les doublons exacts.
- Si vos doublons sont conflictuels, il vous demande de choisir un schéma pour prioriser une fiche (la “Master Item Rule”).
- Une fois la Master Item Rule définie, vous pouvez fusionner, mettre à jour, marquer ou supprimer l’autre enregistrement du duo.
Fusion et suppression de doublons simples sur un seul fichier
C’est la manière la plus simple de gérer les doublons : vous avez une liste où certaines entrées apparaissent plusieurs fois et vous voulez garder une seule occurrence de chaque enregistrement.
Quand c’est utile :
- Vous avez importé le même fichier CSV deux fois par erreur
- Votre export CRM contient des contacts en double
- Des données scrapées contiennent des répétitions (erreurs de pagination, etc.)
Étape 1 : créer un compte et importer vos données
- Inscrivez-vous sur Datablist
- Upload votre CSV ou Excel
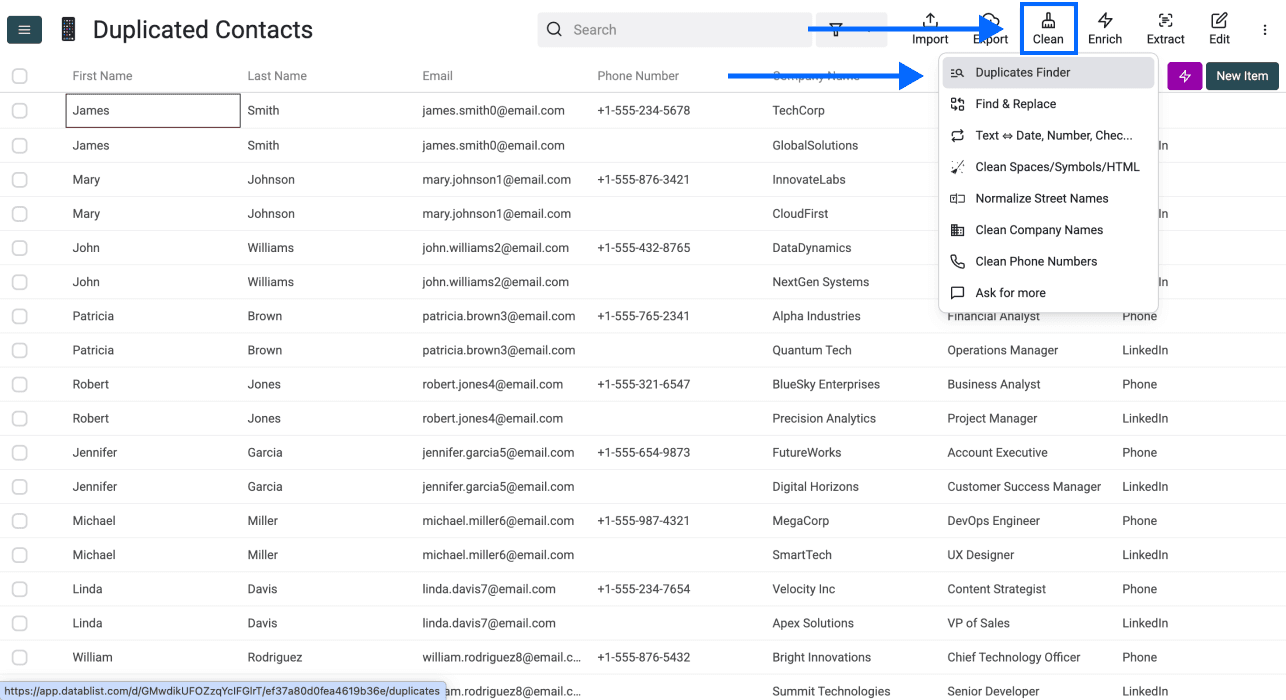
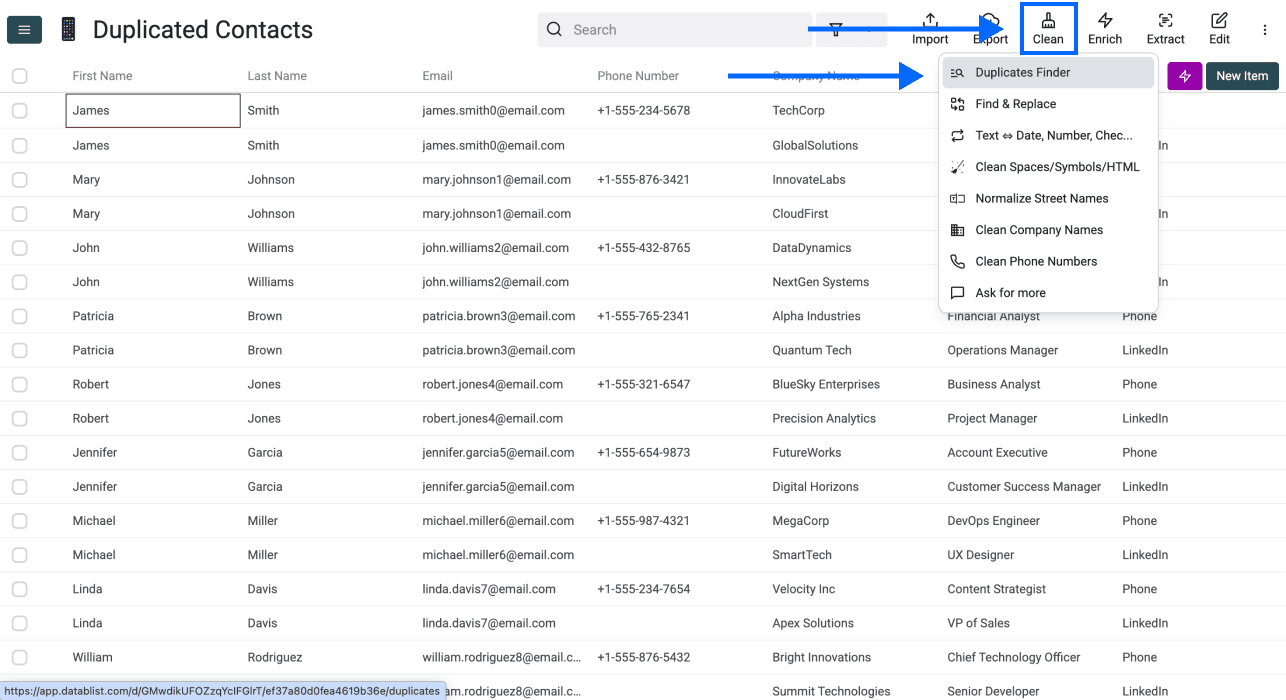
Étape 2 : ouvrir Duplicates Finder
Cliquez sur Clean dans le menu du haut, puis sélectionnez Duplicates Finder
Étape 3 : choisir votre identifiant unique
À cette étape, vous avez deux options :
Option 1 : choisir une ou plusieurs colonnes comme identifiant unique — RECOMMANDÉ
Un identifiant unique, c’est l’info qui permet de distinguer chaque enregistrement. Par exemple :
- Avec une colonne : si vous choisissez “Email”, alors john@example.com sera unique même si le reste “match”
- Avec plusieurs colonnes : si vous choisissez “First Name” + “Company”, alors “John” chez “Microsoft” est différent de “John” chez “Google”
Plus vous sélectionnez de colonnes, plus la comparaison devient stricte. On vous recommande de démarrer avec une ou deux colonnes qui identifient réellement une ligne dans vos données.
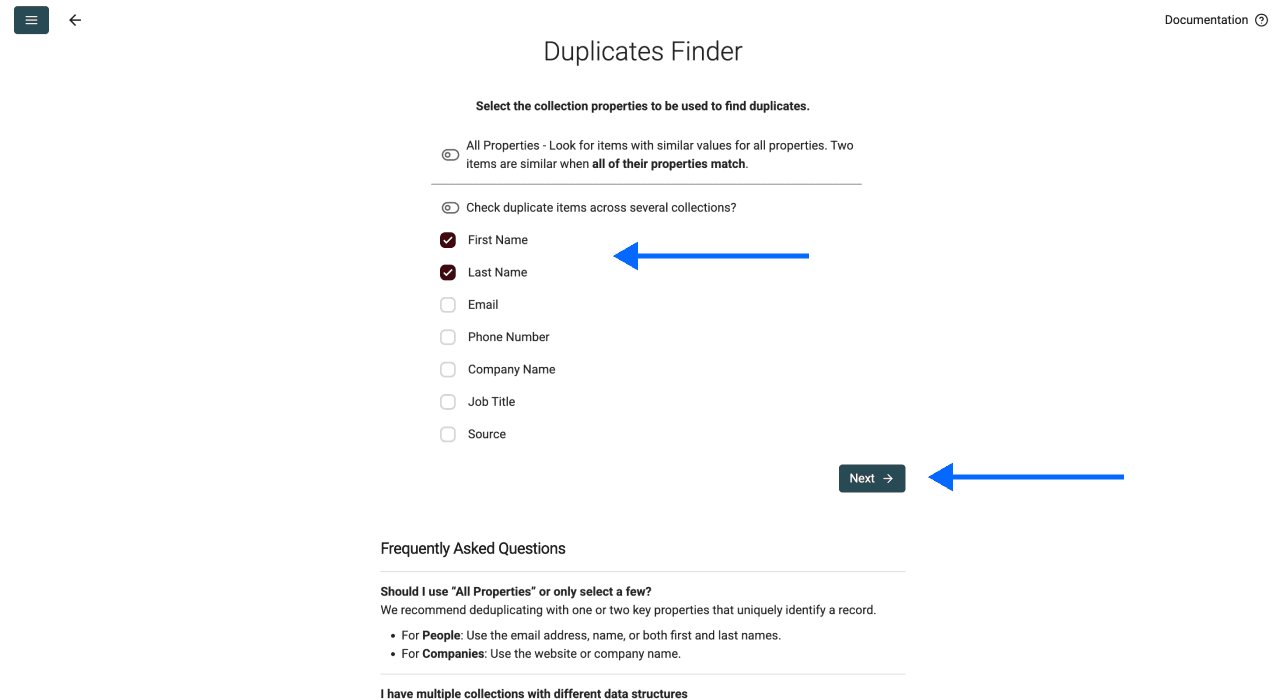
Option 2 : dédupliquer sur toutes les propriétés — NON RECOMMANDÉ
Cette option vérifie si chaque colonne d’une ligne correspond exactement à une autre ligne. Autrement dit, deux lignes ne seront considérées comme doublons que si toutes leurs données sont identiques.
Pourquoi on ne recommande pas : dans la vraie vie, les doublons ne sont presque jamais parfaitement identiques. Une même personne peut avoir des job titles légèrement différents, ou une même entreprise peut avoir des effectifs différents selon la source. Avec cette option, vous allez passer à côté de la plupart des doublons.
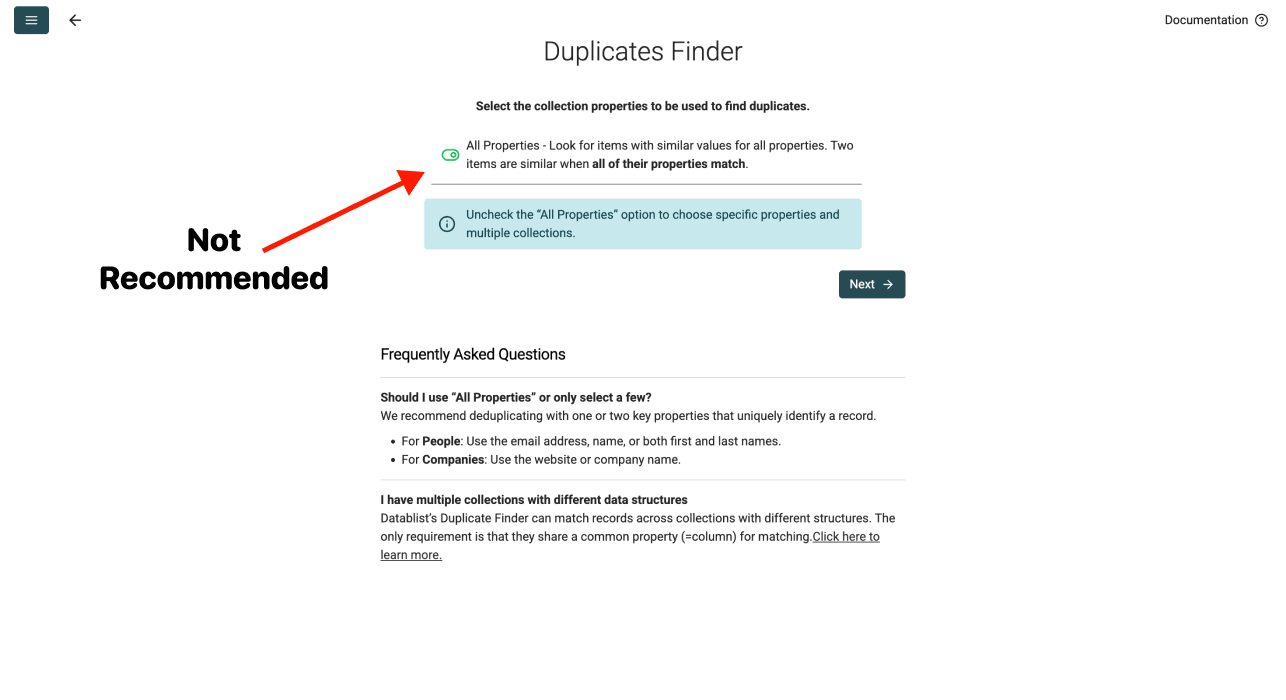
Quand l’option 2 peut être utile : uniquement si vous cherchez des doublons exacts importés deux fois par erreur, où absolument tous les champs sont identiques.
Une fois les propriétés choisies, descendez et cliquez sur Next
Étape 4 : sélectionner l’algorithme de comparaison
Vous devez choisir un algorithme de comparaison et un processor pour chaque propriété utilisée. On vous recommande de garder les réglages par défaut, sauf pour les noms d’entreprise.
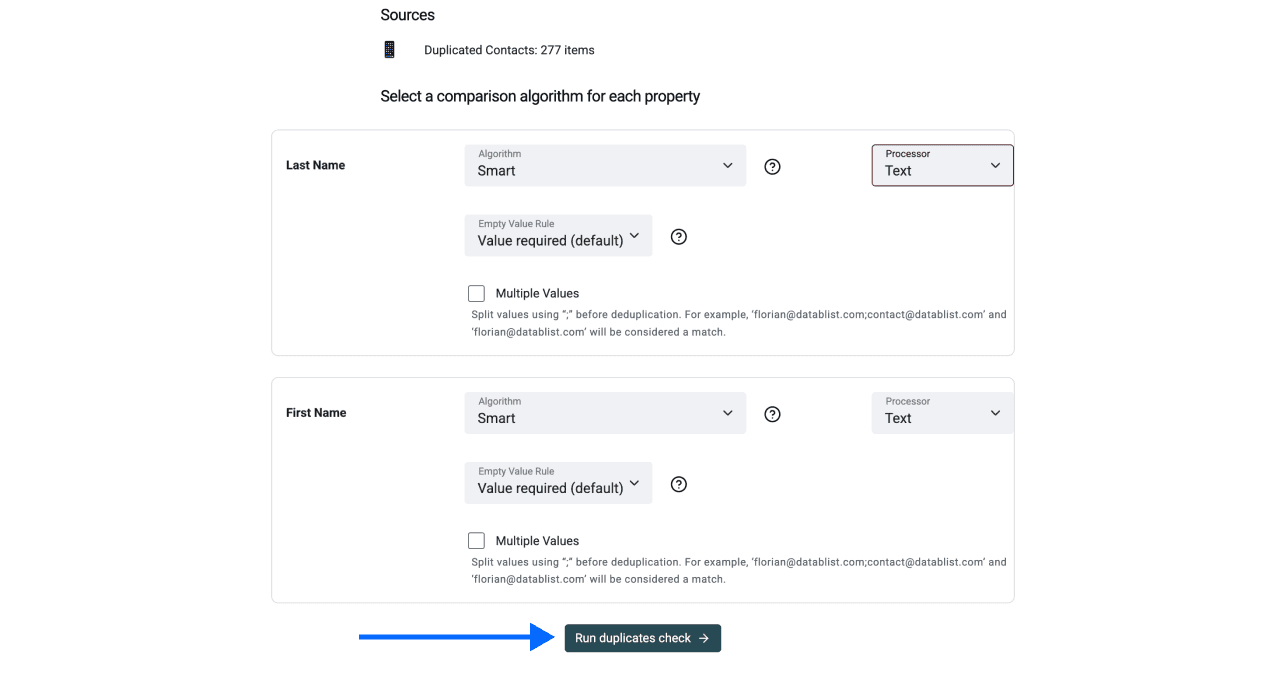
Si vous dédupliquez à partir des noms d’entreprise : choisissez le processor “company names”, car c’est le seul que Datablist ne détecte pas automatiquement.
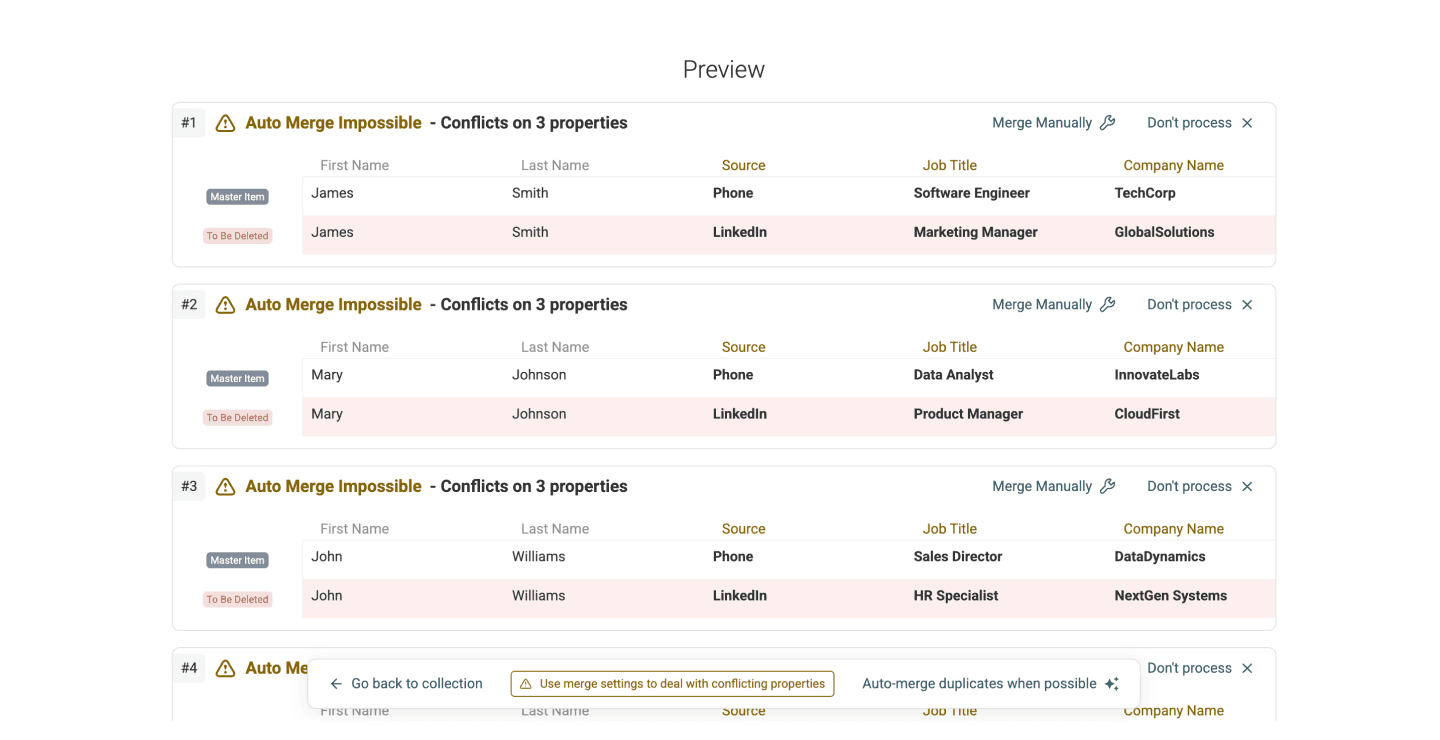
Étape 5 : choisir le Master Item, relire et résoudre les conflits
- Choisir la master item rule : comme expliqué plus haut, Datablist vous demande toujours une Master Item rule. La règle par défaut est “Most Complete”, mais vous pouvez en choisir une autre.
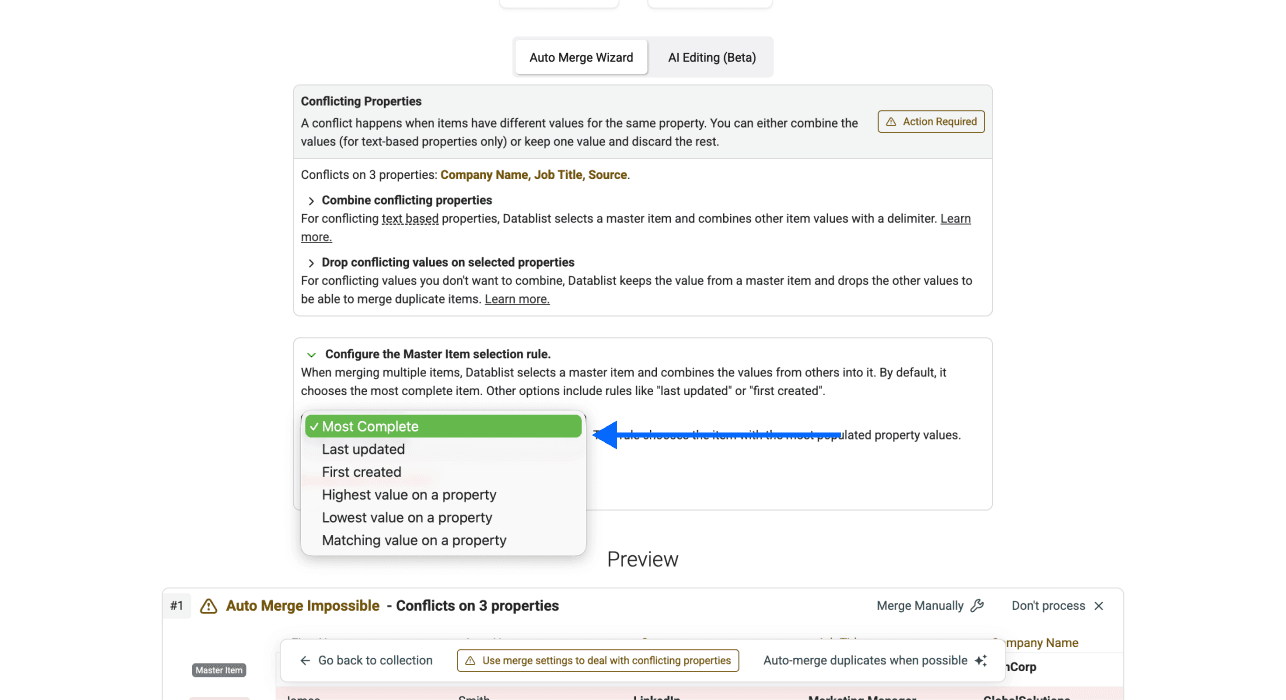
-
Relire et résoudre les conflits si nécessaire : très souvent, vos doublons ne sont pas identiques sur tous les champs. C’est précisément pour ça qu’on vous demande de définir un master item.
Pour résoudre les conflits, vous pouvez soit “combine”, soit “drop” les valeurs en conflit. Attention : “combine” fonctionne uniquement pour des champs texte. Pour des nombres, des dates, etc., il faut généralement combiner les deux approches : “combine” et “drop”.
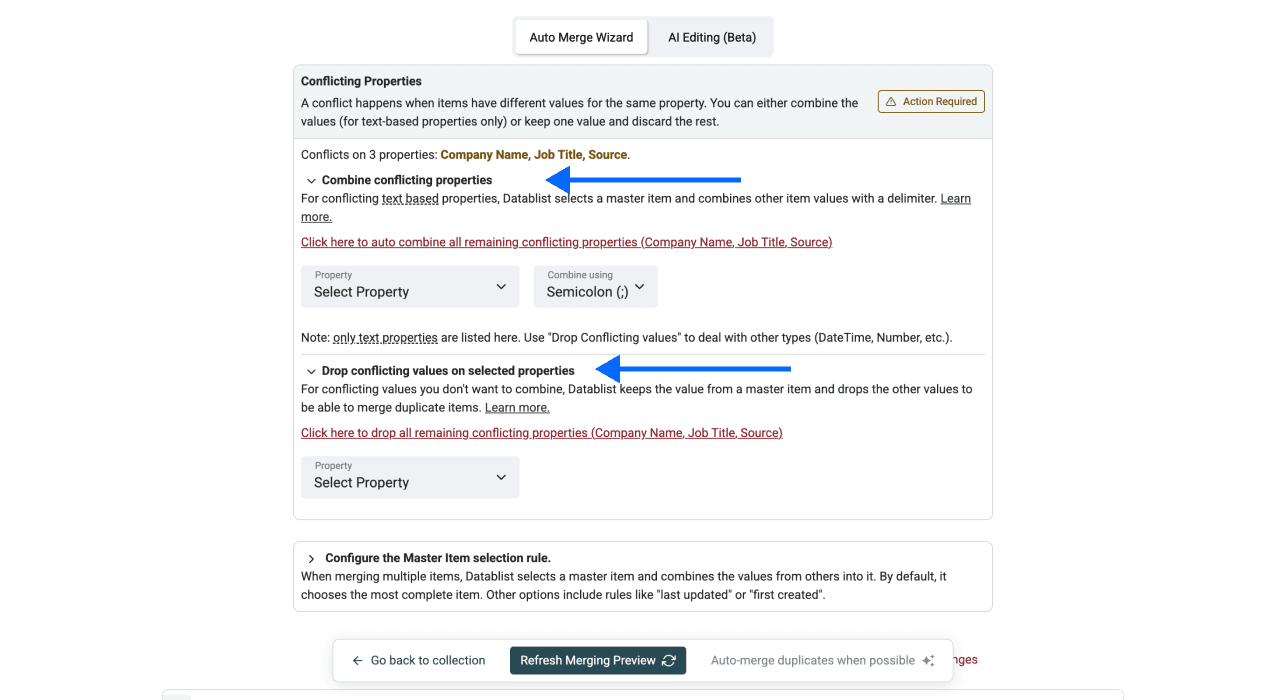
- Cliquez sur Refresh Merging Preview pour voir les changements appliqués
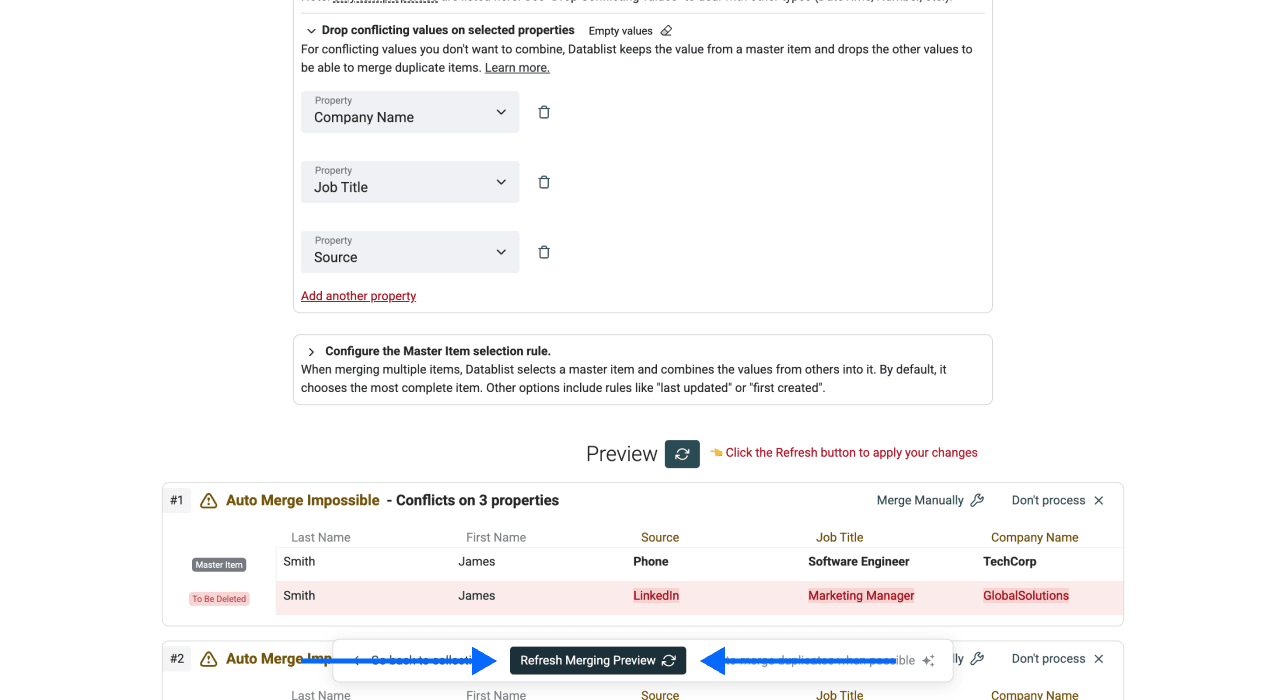
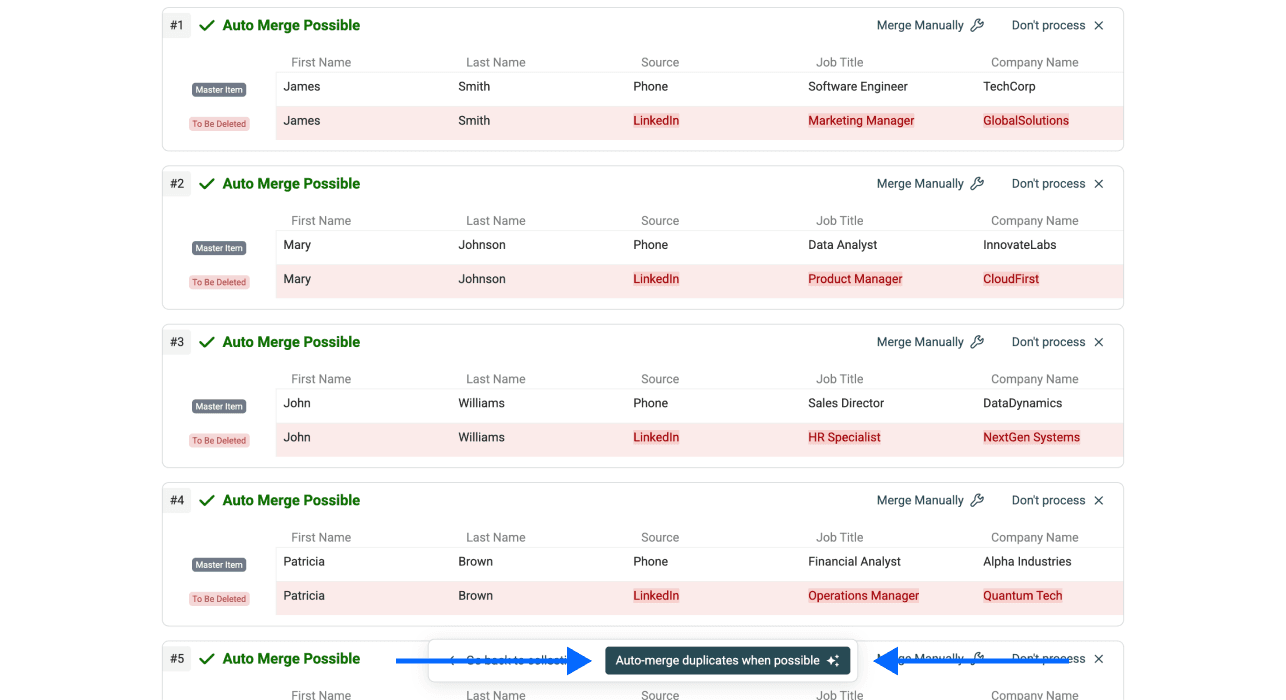
Étape 6 : lancer et vérifier
Il ne vous reste plus qu’à cliquer sur Auto-merge when possible.
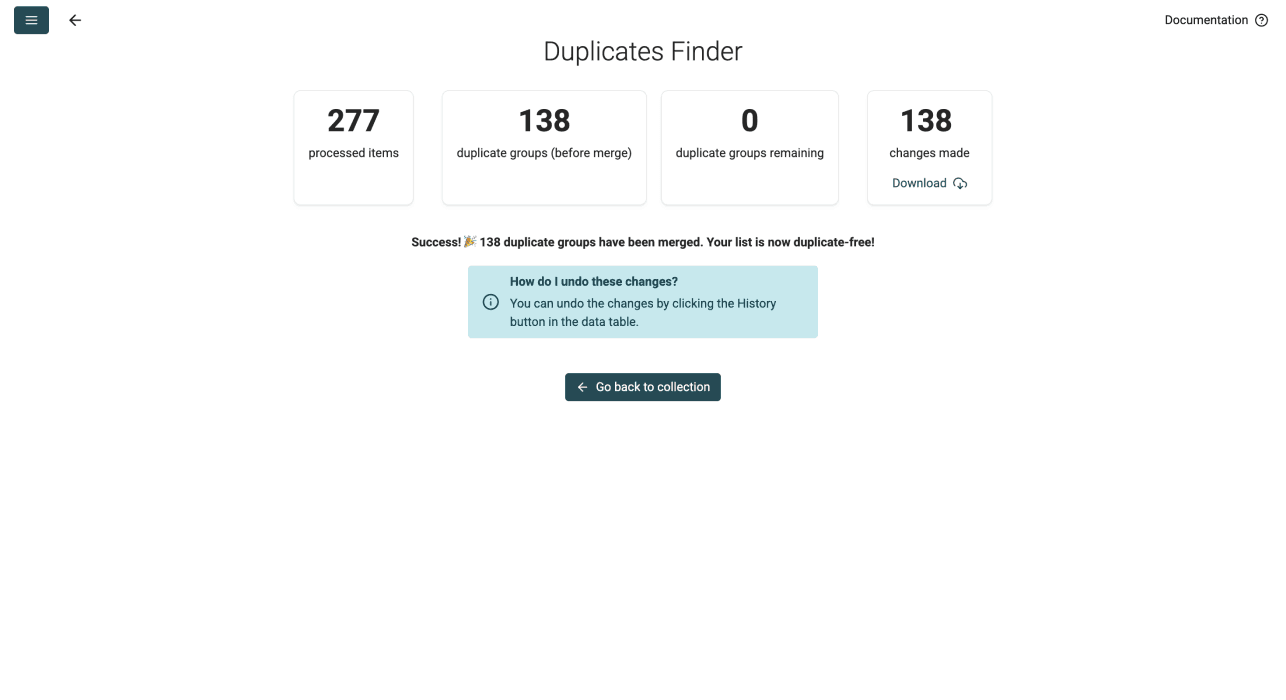
Une fois vos doublons fusionnés, Datablist vous propose de télécharger un CSV avec les changements effectués. Le fichier inclut :
- Tous les doublons présents dans votre fichier
- Les enregistrements vers lesquels ces doublons ont été fusionnés
- Les modifications appliquées
- Le Datablist record ID
Le téléchargement est optionnel.
💡 Si vous vous êtes trompé
Vous pouvez revenir en arrière en cliquant sur le bouton d’historique et en annulant les actions, puis en retournant à la vue spreadsheet.
Éditer les doublons avant de les supprimer
Parfois, les Master Item rules “simples” ne suffisent pas. Et si vous voulez garder le numéro de téléphone d’une fiche, mais le job title d’une autre ? C’est là qu’intervient AI Editing.
Comment ça marche : au lieu de choisir une règle prédéfinie, vous décrivez exactement ce que vous voulez en langage naturel. L’IA de Datablist lit vos instructions, génère un script et applique votre logique à chaque groupe de doublons.
Quand c’est utile :
- Vous avez des contacts issus de plusieurs sources (CRM, LinkedIn, listes de téléphones) et vous voulez combiner les meilleures infos
- Vos doublons ont des champs différents remplis, et vous voulez sélectionner certaines valeurs précisément
- Vous avez une logique “métier” qui ne rentre pas dans les Master Item rules standard
- Vous voulez mettre à jour avant de supprimer, pas seulement choisir un gagnant
- Vous voulez marquer les doublons au lieu de les supprimer (conformité)
Étape 1 : créer un compte et importer vos données
- Inscrivez-vous sur Datablist
- Upload votre CSV ou Excel
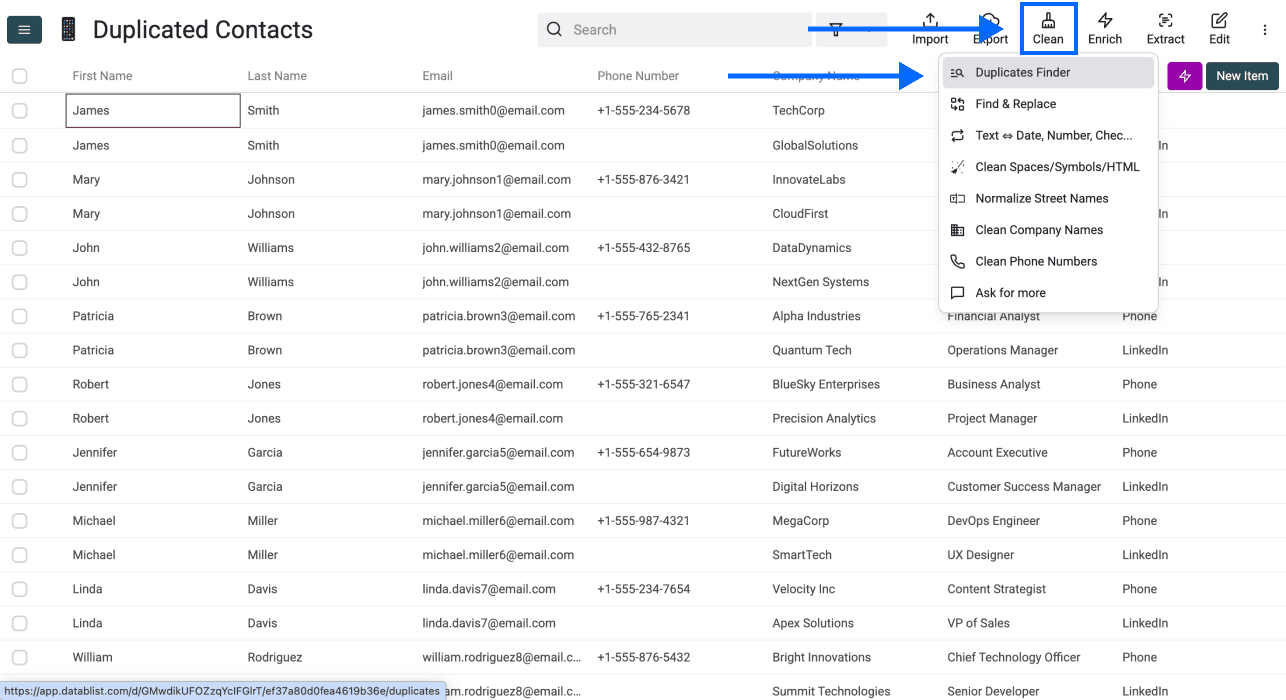
Étape 2 : ouvrir Duplicates Finder
Cliquez sur Clean dans le menu du haut, puis sélectionnez Duplicates Finder
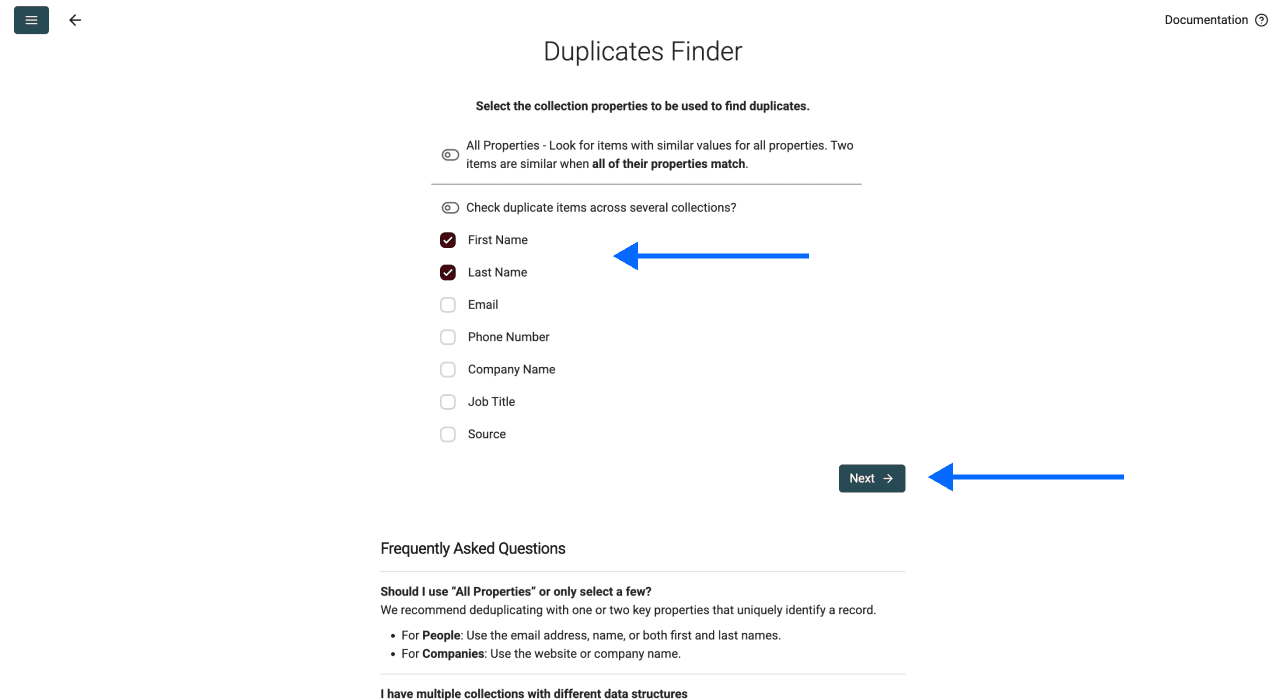
Étape 3 : choisir votre identifiant unique
Sélectionnez la/les colonne(s) utilisée(s) pour faire matcher les doublons. Une fois fait, descendez et cliquez sur Next
Étape 4 : sélectionner l’algorithme de comparaison
Sélectionnez un algorithme de comparaison et un processor pour chaque propriété. On vous recommande de garder les réglages par défaut, sauf pour les noms d’entreprise.
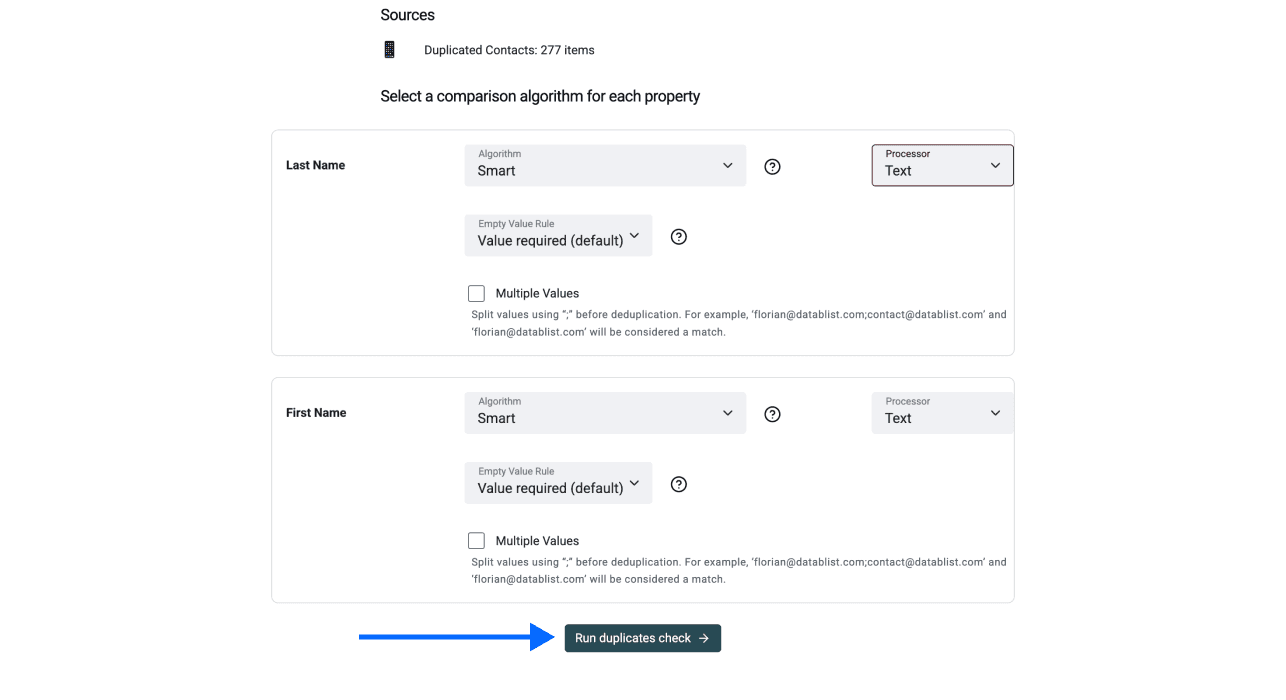
Étape 5 : ouvrir AI Editing
Au lieu de sélectionner une Master Item rule, cliquez sur AI Editing dans le panneau de déduplication.
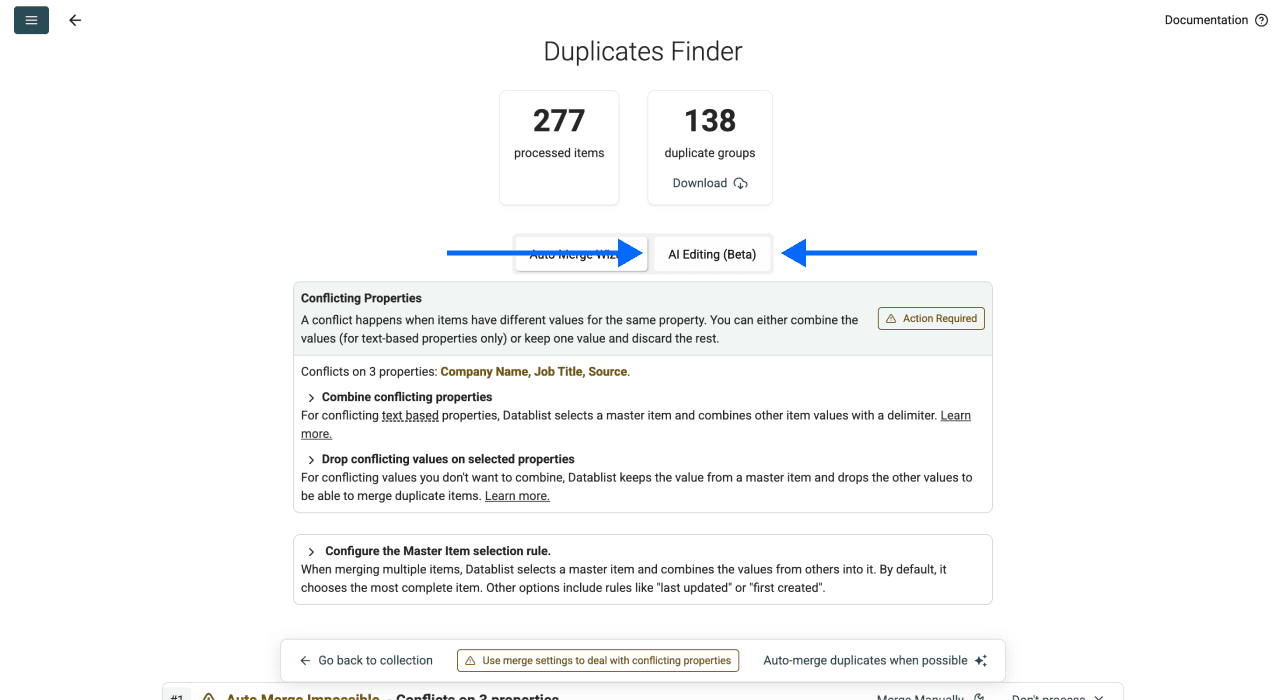
Étape 6 : écrire votre prompt
Décrivez ce que vous voulez en langage naturel. Exemple concret :
Imaginez que vous ayez des données contact issues de deux sources : une vérification téléphone et un scraping LinkedIn. Les fiches téléphone ont des numéros vérifiés, mais LinkedIn contient des job titles et des noms d’entreprise plus à jour. Vous voulez garder la fiche téléphone en master, tout en la mettant à jour avec les infos LinkedIn.
Voici le prompt utilisé :
Select the records with "Phone" as source as master item and update them with the job title and company name from the record with the "LinkedIn" as source.
The source: /source
The job title: /job title
The company name: /company
Delete the second item when finished
Note : n’oubliez pas de mapper vos propriétés dans le prompt avec /
Cliquez sur Generate and preview changes quand c’est prêt.

Étape 7 : vérifier et appliquer les changements
Datablist vous montre exactement ce que l’IA va modifier avant d’appliquer les changements. Vérifiez l’aperçu pour vous assurer que tout correspond à vos attentes.
Quand l’aperçu est bon, cliquez sur Run AI Script pour appliquer la logique à tous les groupes de doublons. Ensuite, exportez vos données nettoyées.
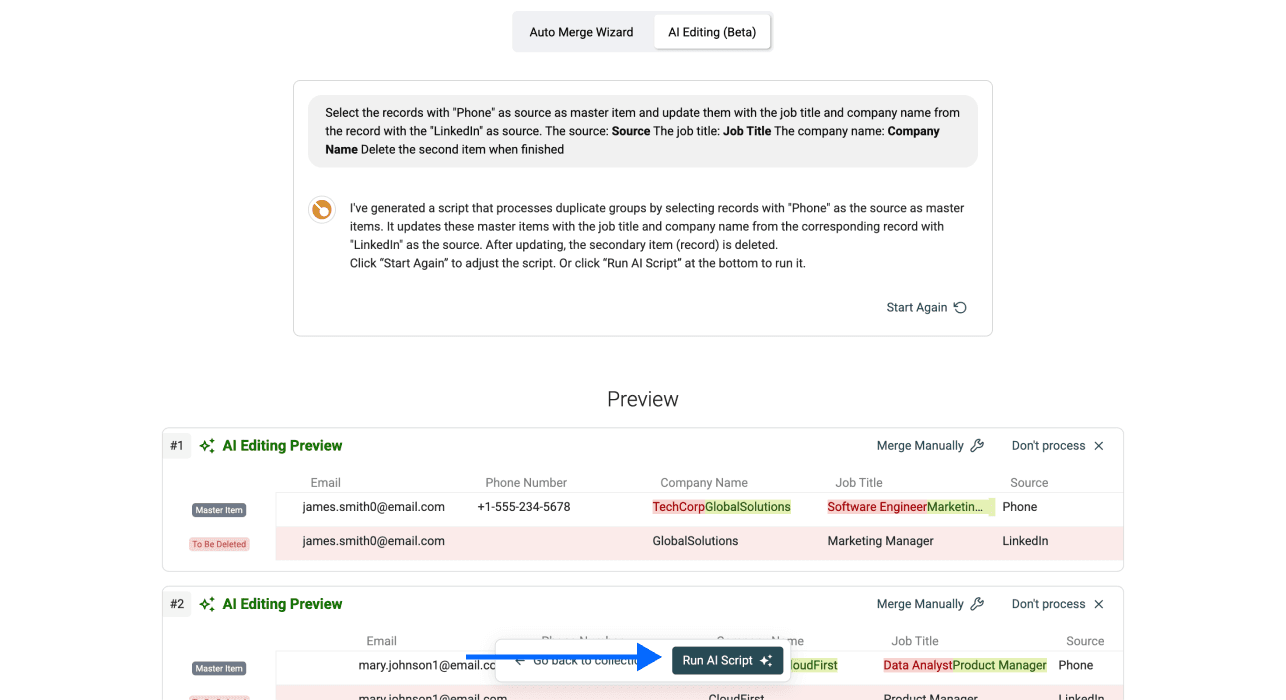
💡 Conseils de prompt pour de meilleurs résultats
Soyez très précis sur vos attentes. Plus vous décrivez clairement ce que vous voulez, meilleurs seront les résultats.
Avec ça, vous pouvez aussi :
- Marquer les doublons au lieu de les supprimer : un prompt du type “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them”
- Fusionner des champs texte : “Merge all notes from duplicate records into the master item's notes field, separated by line breaks”
- Prioriser selon la qualité de la source : “Use Salesforce records as master when available, otherwise use HubSpot, then spreadsheet imports”
- … ou toute autre logique dont vous avez besoin
Supprimer les doublons entre deux feuilles ou plus
Si vous avez deux fichiers CSV différents et que vous voulez repérer les enregistrements présents dans les deux, ou dédupliquer une nouvelle lead list par rapport à un export CRM existant, Datablist rend ça très simple.
Comment ça marche : contrairement à la déduplication sur un seul fichier, ce workflow compare les enregistrements entre plusieurs fichiers et supprime les doublons qui se trouvent dans différentes sources. Vous pouvez sélectionner deux fichiers ou plus, sans limite.
Quand c’est utile :
- Vous importez de nouveaux leads et voulez éviter les doublons avec des contacts existants
- Vous fusionnez des données issues de plusieurs fournisseurs ou sources
- Vous voulez mesurer le chevauchement entre deux listes clients
- Vous voulez éviter de contacter deux fois le même prospect
- Vous devez consolider des données clients entre plusieurs équipes, pays ou filiales
- … et pour bien d’autres workflows de data cleaning
📘 Différence importante avec la déduplication sur un seul fichier
En déduplication multi-fichiers, Datablist supprime les doublons au lieu de les fusionner.
Étape 1 : créer un compte et importer vos fichiers
- Inscrivez-vous sur Datablist
- Import votre premier fichier CSV ou Excel
- Import votre deuxième fichier dans une autre collection (et tous les fichiers additionnels que vous souhaitez inclure)
- Vérifiez que vous avez un identifiant unique
Avant de continuer, assurez-vous que tous vos fichiers partagent au moins une colonne commune qui peut servir d’identifiant unique. Exemples :
- Adresse email
- URL LinkedIn
- Domaine d’entreprise
- Numéro de téléphone
- Tout autre champ qui identifie un enregistrement de façon unique
Étape 2 : ouvrir Duplicates Finder
Cliquez sur Clean dans le menu du haut, puis sélectionnez Duplicates Finder
Étape 3 : activer la déduplication multi-collections
- Cochez Check Duplicate Items Across Several Collections
- Sélectionnez la/les collection(s) / fichier(s) que vous venez d’importer
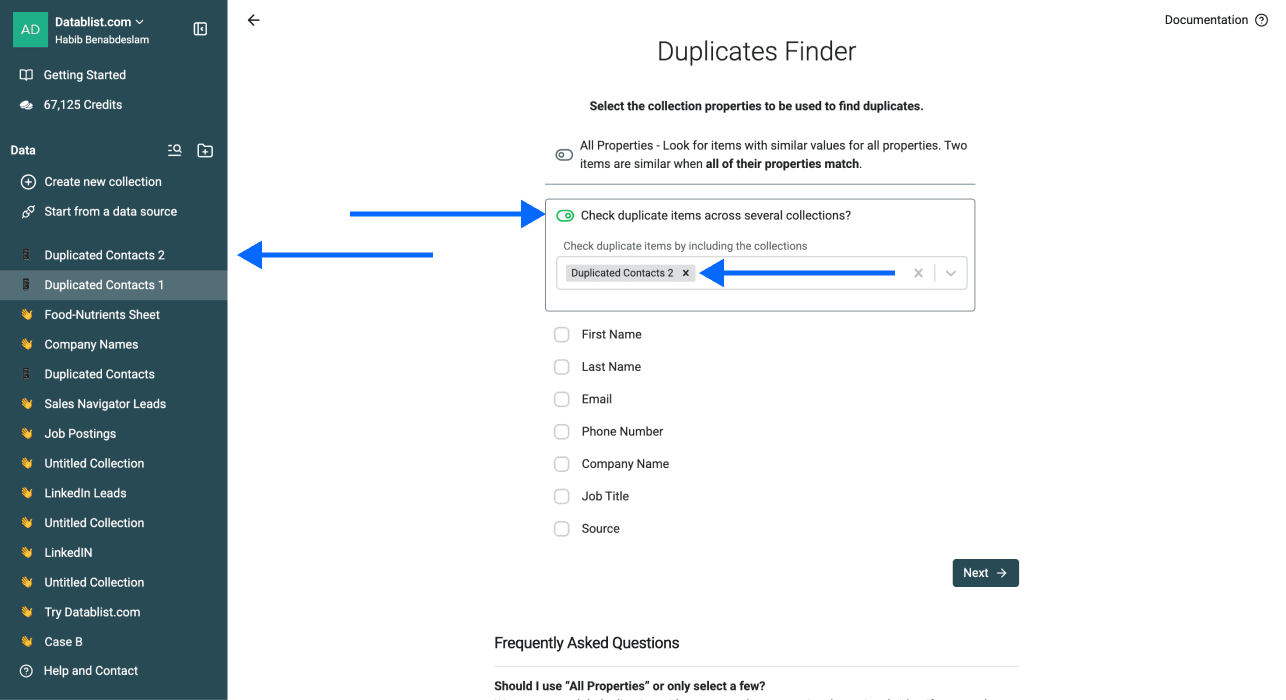
Étape 4 : choisir la propriété d’identifiant unique
Sélectionnez la propriété utilisée pour matcher les doublons entre fichiers. Vous pouvez en sélectionner plusieurs, mais assurez-vous que tous les fichiers contiennent ces propriétés pour garder une déduplication fiable.
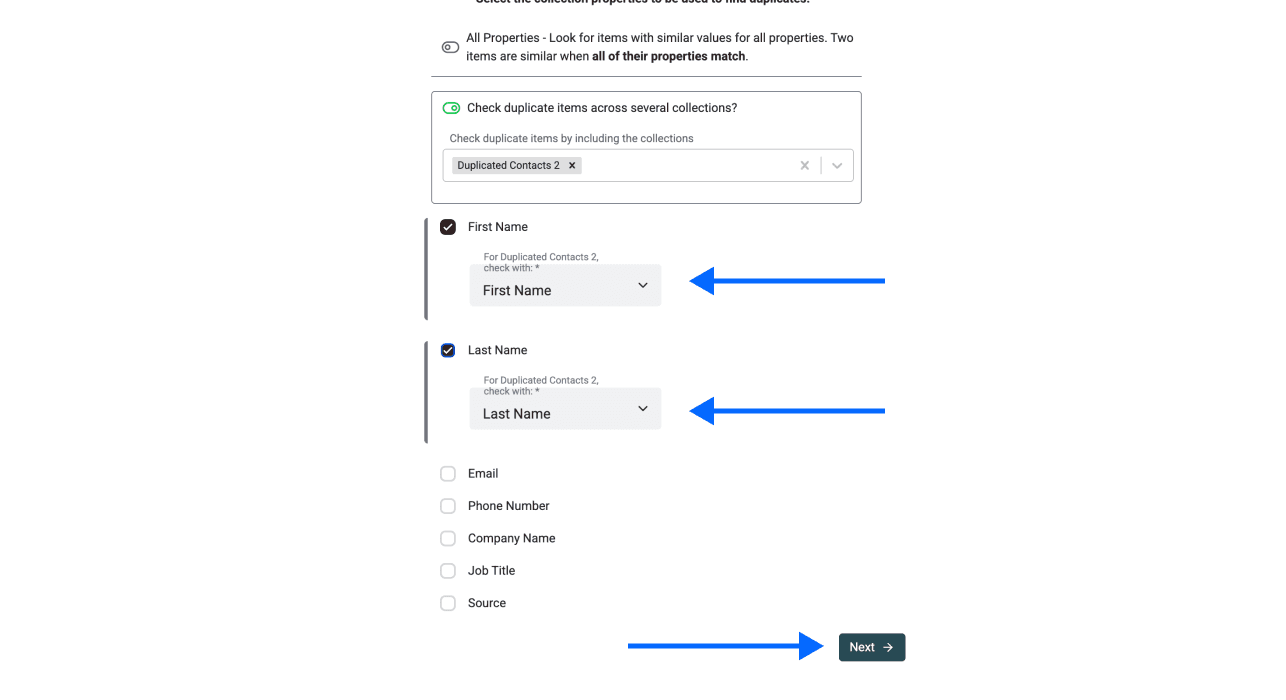
Étape 5 : sélectionner l’algorithme de comparaison
Choisissez le mécanisme adapté à vos données :
- Exact : idéal pour des URLs, domaines ou IDs quand vous voulez un match strict
- Smart : idéal pour du texte, quand il peut y avoir de petites variations
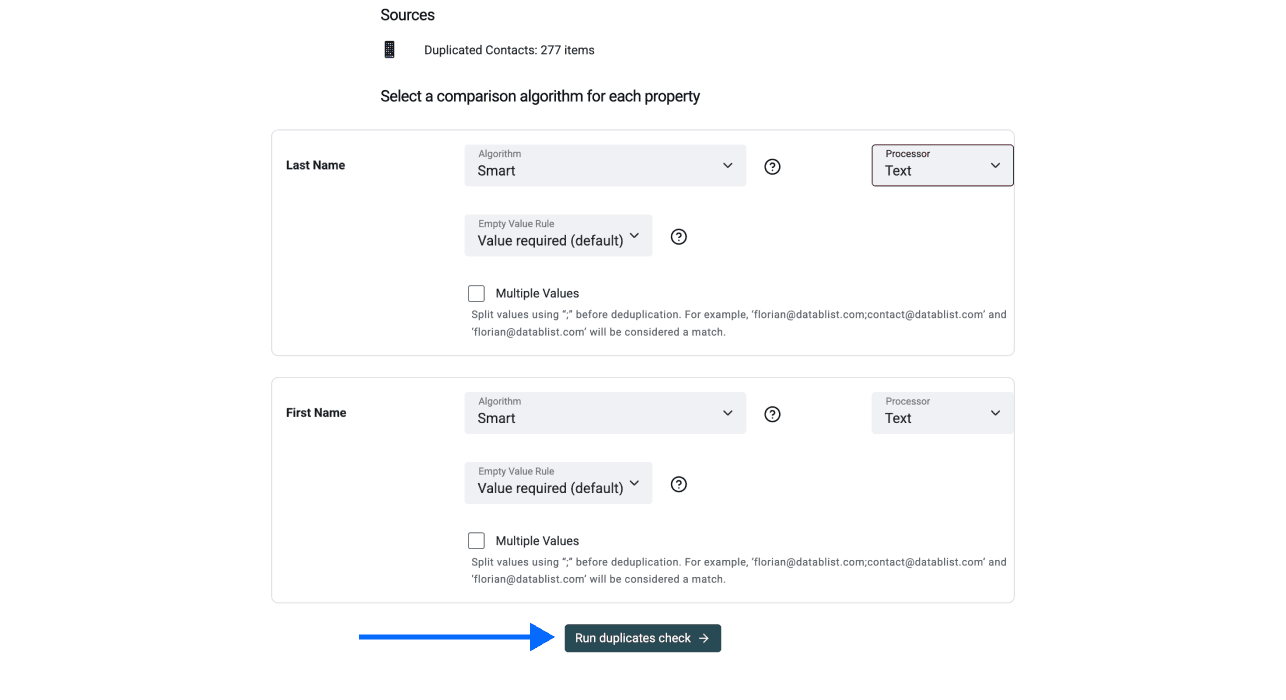
Cliquez sur Run duplicates check après avoir choisi la méthode.
Étape 6 : définir les règles de nettoyage
Choisissez comment gérer les doublons :
- Remove duplicate items from collection X : supprime les doublons du fichier sélectionné
- Keep duplicate items only in collection X : disponible uniquement si vous dédupliquez entre 3 collections ou plus
Cliquez sur Process duplicate items pour continuer.
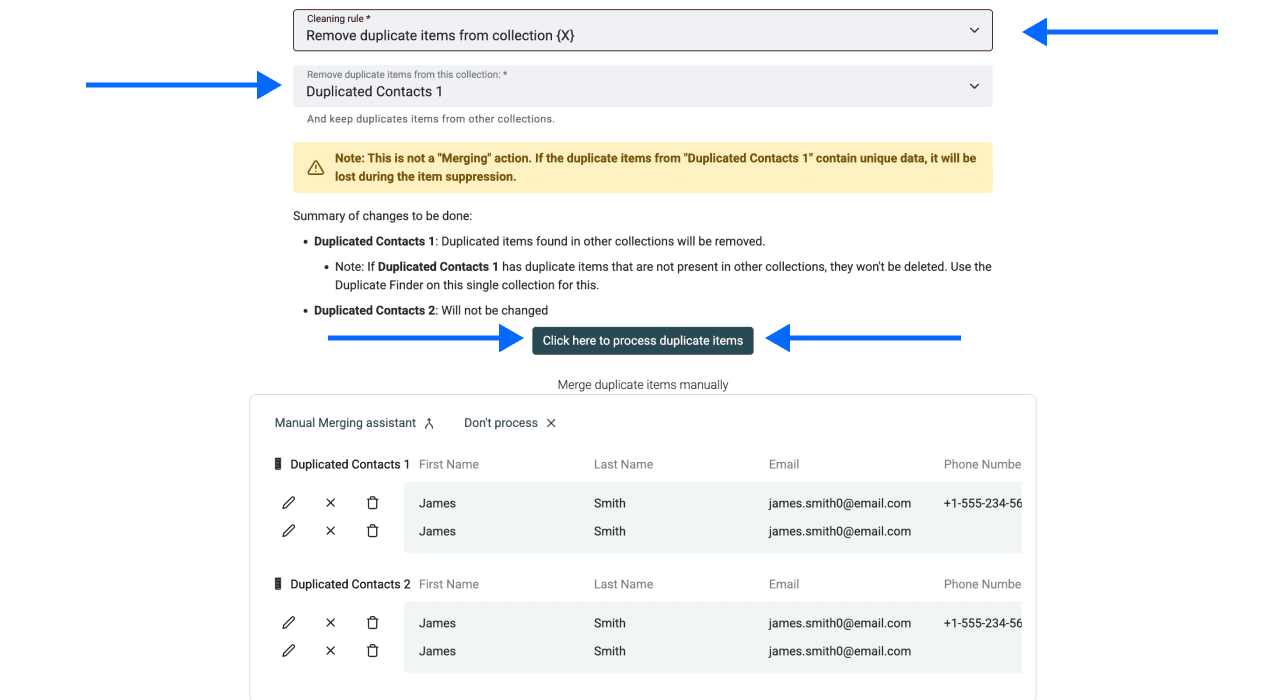
Et voilà !
Conclusion
Bravo, vous êtes arrivé au bout — et vous en savez maintenant plus sur la déduplication que la majorité des gens. Petit récap des enseignements clés :
- Tous les doublons ne se valent pas : identifier le type change tout
- Choisir le bon Master Item et la bonne action en masse peut vous faire gagner des heures
- Là où beaucoup d’outils vous imposent leur façon de faire, Datablist vous laisse gérer les doublons exactement comme vous en avez besoin
Que vous soyez en train de fusionner des contacts d’un CRM “en vrac”, d’appliquer une logique custom via IA, ou de nettoyer de nouveaux leads contre votre base existante, vous avez maintenant la méthode. Bonne déduplication.
Frequently Asked Question
Comment Datablist choisit-il quel doublon conserver ?
Datablist ne choisit pas à votre place : c’est vous qui décidez. Vous définissez une Master Item Rule (par exemple “Most complete” ou “Last updated”) qui indique quel enregistrement prioriser. Si votre logique est plus complexe, vous pouvez utiliser AI Editing pour définir des règles sur mesure en langage naturel (l’assistant IA s’occupe du reste).
Qu’est-ce qui différencie la suite Deduplication and Matching de Datablist ?
Trois choses : la flexibilité, la personnalisation via IA, et le prix. La plupart des outils se limitent à supprimer des doublons. Datablist vous permet de fusionner, mettre à jour, marquer ou supprimer selon des règles que vous définissez. La fonctionnalité AI Editing gère une logique complexe que d’autres outils ne savent pas traiter. Et le produit comparable le plus proche coûte plusieurs milliers d’euros par an (logiciel enterprise).
Et si je ne veux pas supprimer mes doublons ?
Vous pouvez les marquer. Utilisez AI Editing et écrivez un prompt du type : “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” C’est particulièrement utile pour la conformité ou si vous voulez relire les doublons avant suppression.
Et si les Master Item Rules ne correspondent pas à mon cas ?
Utilisez AI Editing. Au lieu de choisir une règle prédéfinie, vous décrivez votre logique en langage naturel, et l’IA de Datablist génère un script custom. Exemple : “Keep the record from Salesforce, but use the job title from LinkedIn.”
Puis-je créer des Master Item Rules personnalisées ?
Oui. La fonctionnalité AI Editing de Datablist vous permet d’écrire n’importe quelle règle de priorisation que vous pouvez formuler. Vous voulez conserver les lignes où la colonne A contient une valeur précise ? Prioriser selon plusieurs conditions ? Décrivez-le, et l’IA gère le reste.
Qu’est-ce qu’un identifiant unique en déduplication ?
Un identifiant unique, c’est la colonne (ou combinaison de colonnes) qui rend chaque enregistrement distinct. Par exemple, si vous utilisez “Email” comme identifiant unique, deux lignes avec le même email seront considérées comme des doublons, même si d’autres champs diffèrent. Vous pouvez aussi combiner “First Name” + “Company” pour un matching plus strict.
Comment dédupliquer une liste avec des valeurs en conflit ?
Les doublons conflictuels apparaissent quand deux enregistrements représentent la même entité mais ont des valeurs différentes sur certains champs. Pour les gérer : (1) choisissez une Master Item Rule pour définir l’enregistrement “gagnant”, (2) décidez si vous devez “combine”, “drop” ou “update” les valeurs conflictuelles, (3) utilisez la suite de déduplication de Datablist pour appliquer vos choix en masse. Pour les cas complexes, AI Editing permet de sélectionner précisément des valeurs entre plusieurs enregistrements.
Comment marquer des doublons sans les supprimer ?
Vous pouvez utiliser la fonctionnalité AI Editing dans la Deduplication and Matching Suite. Écrivez simplement un prompt du type : “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” Vos doublons seront marqués pour relecture tout en gardant l’intégralité de vos données — parfait pour la conformité ou une validation manuelle.
Comment mettre à jour des doublons sans supprimer ?
Mettre à jour des doublons consiste à remplacer certains champs de votre enregistrement master par de meilleures données venant d’une autre source. Pour ça, vous pouvez utiliser AI Editing dans la Deduplication and Matching Suite. Vous avez juste à décrire ce que vous voulez, par exemple : “Keep records from Source A, but update the job title and company name using values from Source B.” L’IA applique votre logique à tous les groupes de doublons, puis vous pouvez supprimer les extras ou les garder marqués.