
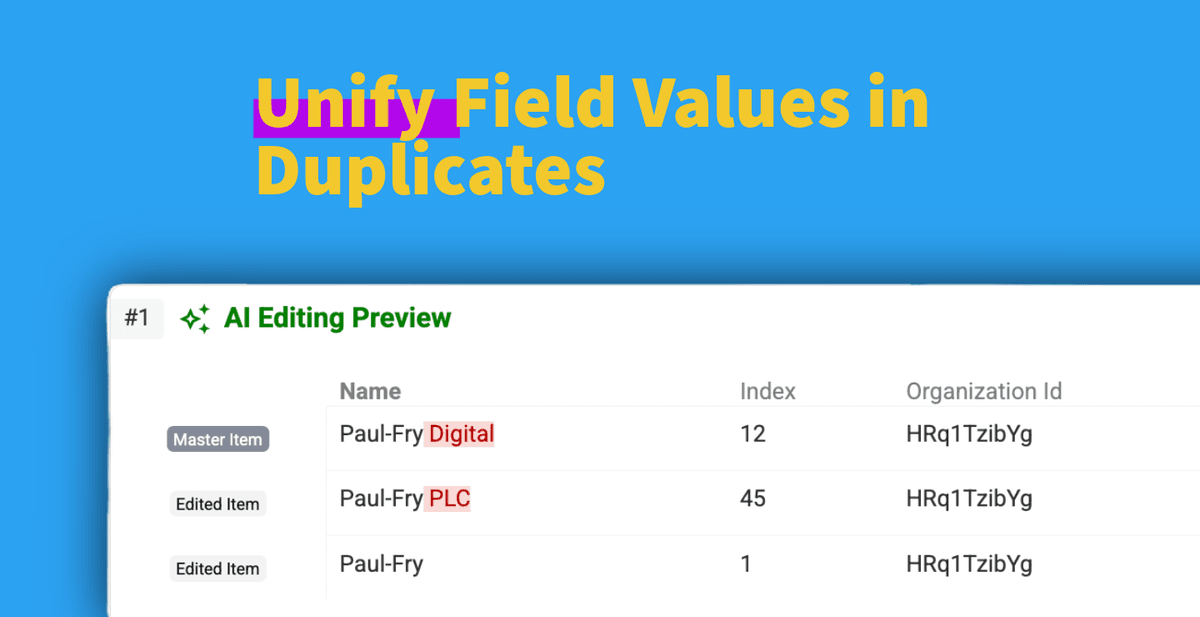
Gérer les enregistrements en double dans vos bases est un vrai casse-tête. Trouver ces doublons est la première étape ; mais les nettoyer est souvent encore plus complexe.
Parfois, vous ne souhaitez pas fusionner totalement vos doublons tout de suite.
Vous pouvez par exemple avoir la même entreprise listée sous des noms légèrement différents (« Innovate Corp », « Innovate Corporation », « Innovate Corp. ») dans plusieurs entrées en double.
Et si vous pouviez standardiser un champ précis, comme le nom d'entreprise ou l'intitulé de poste, sur tous les enregistrements d'un groupe de doublons sans fusionner les fiches ?
Ce guide va vous expliquer comment normaliser les valeurs spécifiques d’un champ à travers les groupes de doublons tout en gardant chaque fiche individuelle :
- Qu'est-ce que la normalisation des données ?
- Découvrez le traitement IA dans Duplicates Finder
- Comment normaliser les données sur les doublons (étape par étape)
Qu'est-ce que la normalisation des données ?
La normalisation, ici, consiste à mettre un champ sous un format cohérent. Avec les doublons, vous retrouvez souvent des variations dans un même champ. Par exemple :
- Noms d'entreprise : « Tech Solutions Inc. », « Tech Solutions, LLC », « Tech Solutions »
- Intitulés de poste : « Software Engineer », « Software Dev. », « Eng., Software »
- Adresses : « 123 Main St », « 123 Main Street », « 123 main st »
- Pays : « USA », « United States », « U.S.A. »
Le but de la normalisation est de choisir une valeur standard (par exemple « Tech Solutions » ou « United States ») puis de l’appliquer au champ concerné pour tous les enregistrements identifiés comme doublons.
Cela rend vos données plus propres, plus faciles à analyser, et plus fiables pour le filtrage ou le reporting, même si les fiches doublons restent séparées. C’est une étape clé de la data cleaning.
Découvrez le traitement IA dans Duplicates Finder
Le Duplicates Finder de Datablist (Duplicates Finder) est déjà un outil très efficace pour identifier les entrées similaires. Il propose des options puissantes pour fusionner automatiquement ou manuellement des doublons, mais le mode AI Processing ajoute encore plus de flexibilité.
À la place de règles de fusion prédéfinies, l’AI Processing vous permet de définir la logique avec un prompt en langage naturel. Vous dites à l’IA précisément quoi faire avec les doublons. Cela inclut par exemple :
- Sélectionner une fiche maître selon un critère de votre choix (ex : dernière mise à jour).
- Fusionner des champs précis tout en gardant les autres séparés.
- Effectuer des calculs pendant la fusion (comme somer des valeurs).
- 👉 Et surtout pour ce guide : mettre à jour un champ précis sur tous les doublons avec une valeur standardisée, sans fusionner les fiches !
Cela transforme la manipulation complexe de données en un simple échange avec notre IA.
Comment normaliser les données sur les doublons (étape par étape)
Voici comment utiliser AI Processing pour normaliser un champ (ex: Company Name) sur plusieurs doublons.
Étape 1 : Préparez vos données
Commencez par importer vos données dans Datablist.
- Créez une Collection : Cliquez sur « + » dans la barre latérale pour créer une nouvelle collection.
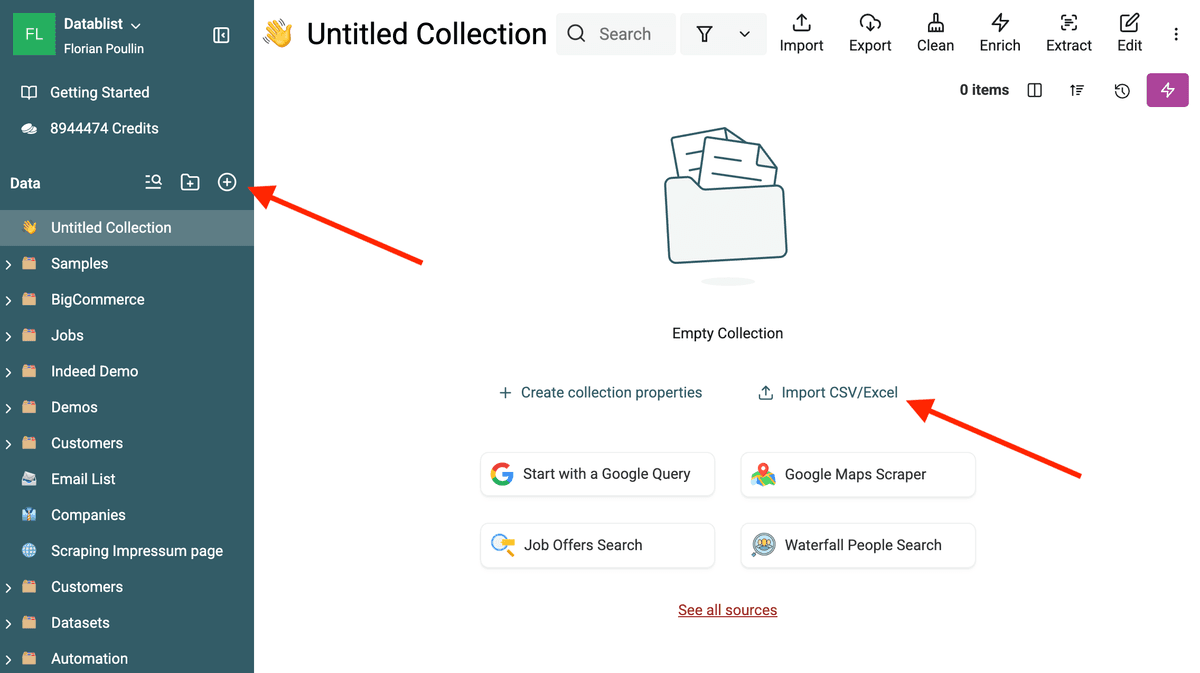
- Importez vos données : Importez un fichier CSV ou Excel. Si vos données proviennent de plusieurs fichiers, importez-les dans la même collection. Datablist vous guidera pour l’association des colonnes. Vérifiez que le champ à normaliser (ex : Company Name) ainsi que ceux servant à l’identification des doublons (Email, Website, etc.) sont bien importés.

Dans ces données d’exemple, on remarque déjà plusieurs variantes sur le nom de la société à normaliser.
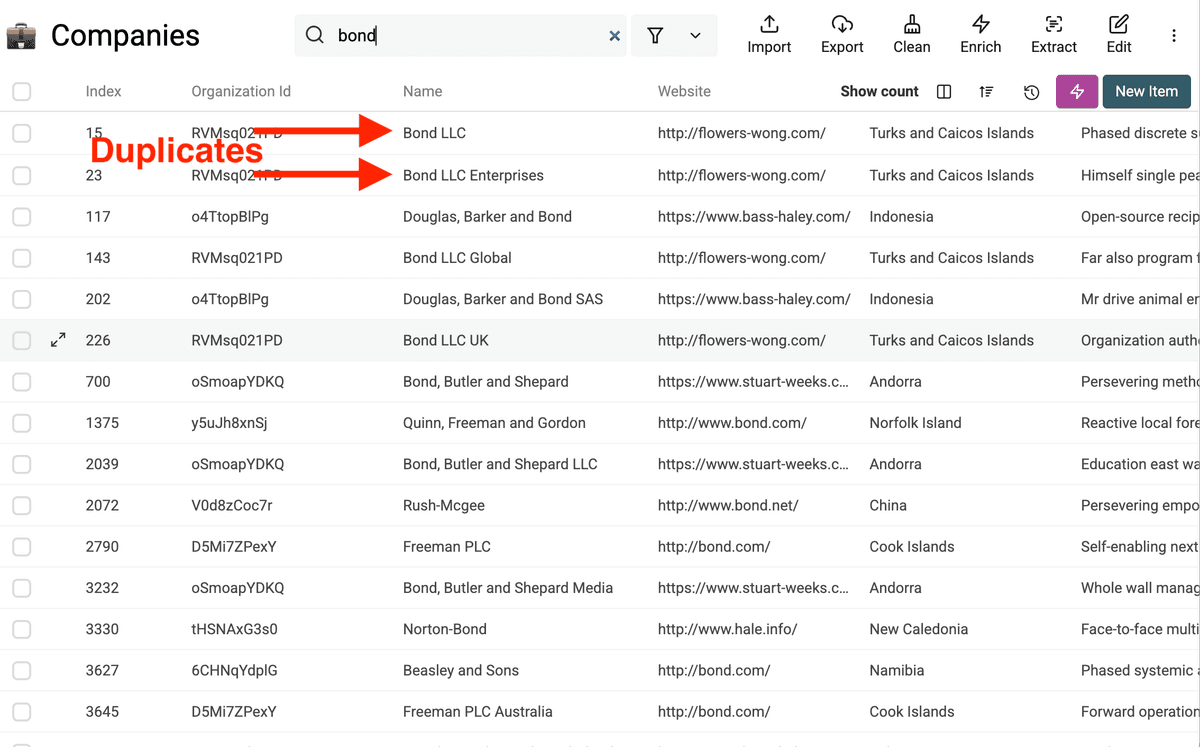
Étape 2 : Détectez les doublons
Trouvez à présent les enregistrements en double.
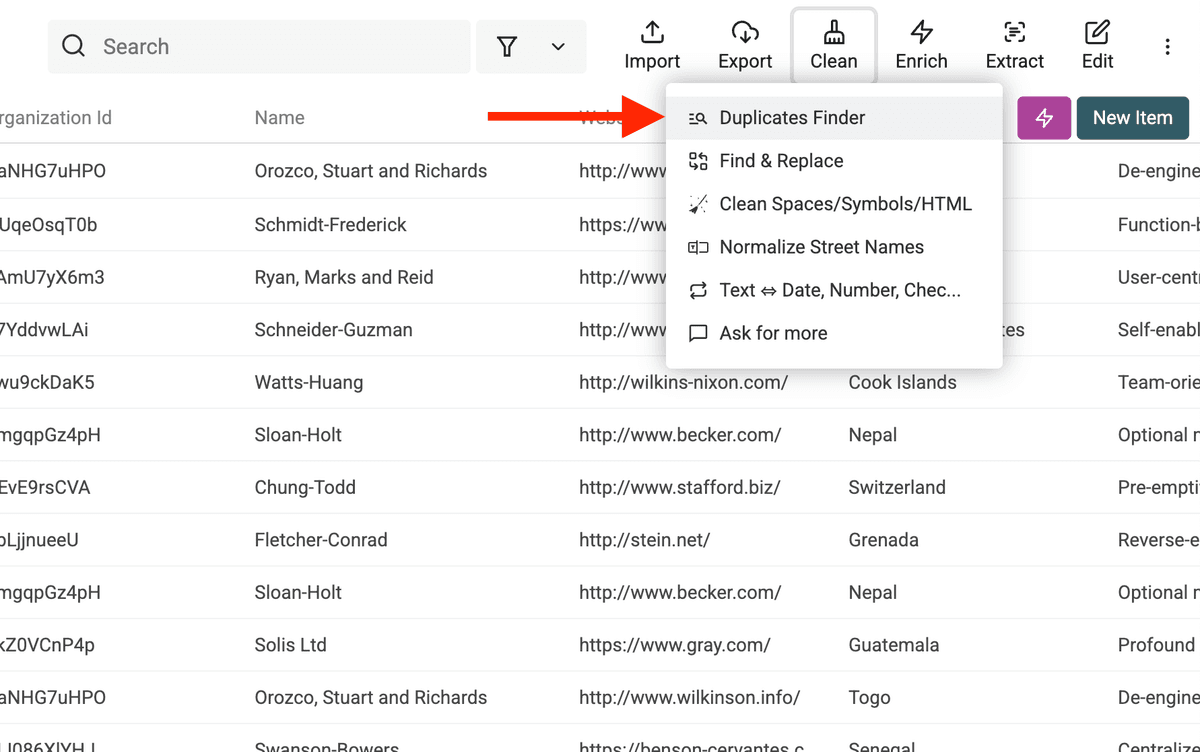
2.a. Ouvrez Duplicates Finder
Cliquez sur « Clean » dans le menu, puis sélectionnez « Duplicates Finder ».
2.b Choisissez les identifiants de déduplication
Sélectionnez la ou les propriétés qui identifient les doublons.
Pour l’exemple, nous voulons dédoublonner les noms d’entreprise, donc on sélectionne le champ name.
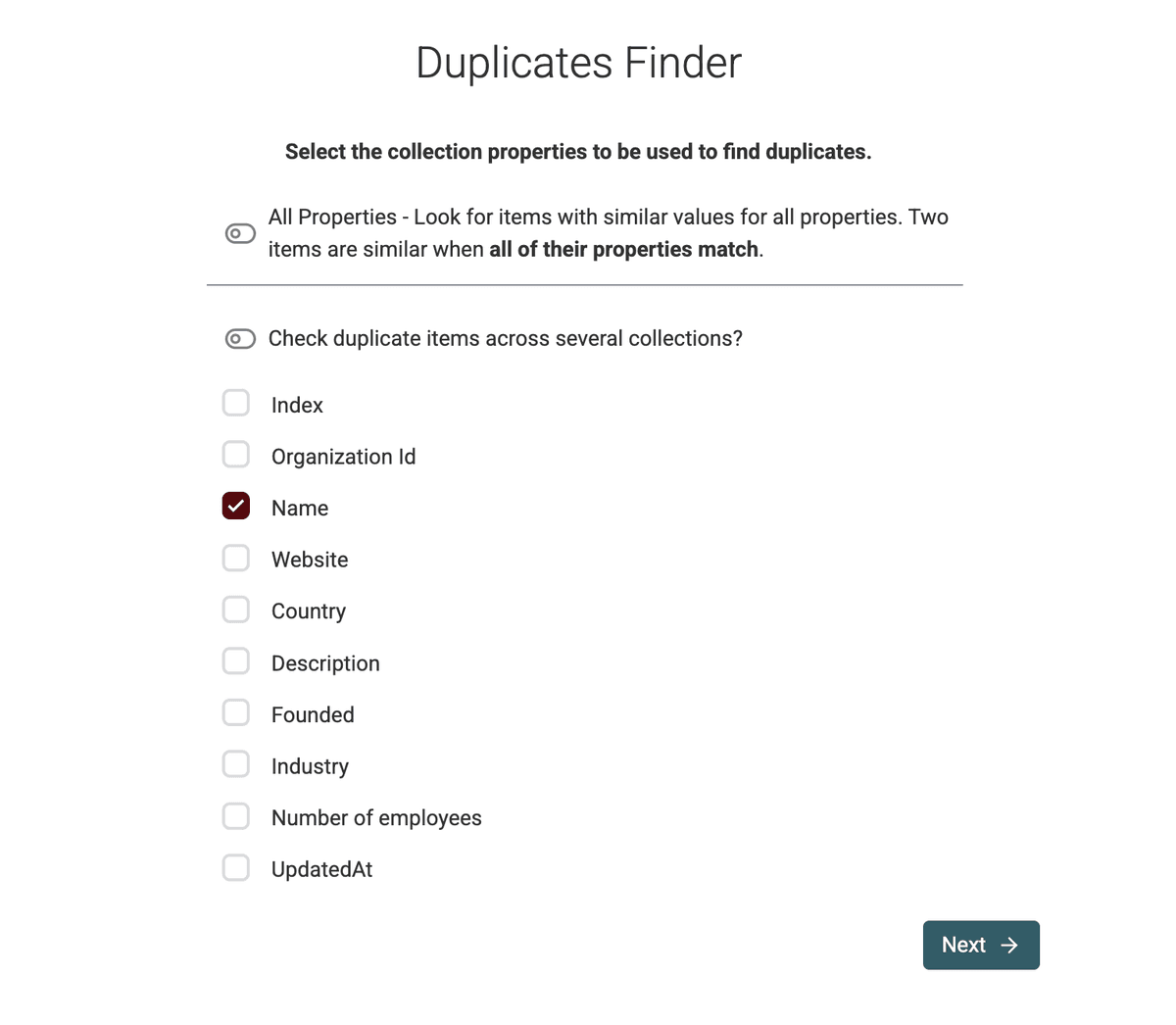
Pour les sociétés, le
Website URLou laLinkedIn Company Page URLpeuvent aussi servir.Pour les contacts :
Phone Numbersont souvent choisis.
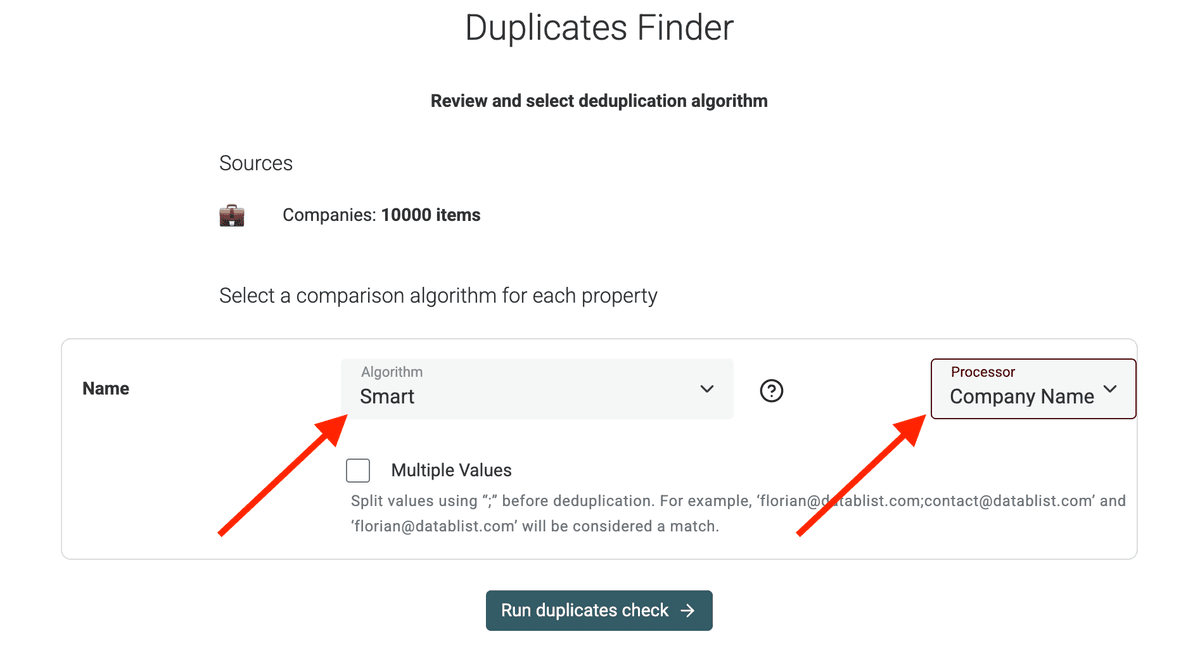
2.c Configurez l’algorithme
À l’étape suivante, choisissez l’algorithme de correspondance.
‘Smart’ fonctionne très bien pour les URLs ou email, en gérant les petites variations. ‘Exact’ est plus strict. Phonétique ou fuzzy sont utiles pour les noms.
Sélectionnez également le Processor le plus adapté (ici, Company Name pour gérer les différences de raison sociale).
2.c Lancez l’analyse
Cliquez sur « Run duplicates check ».
Datablist analyse vos données et présente les groupes de doublons.
Étape 3 : Passez en mode AI Processing
Ne choisissez pas « Auto Merge » ni fusion manuelle. Cliquez sur le bouton AI Editing sur la page des résultats. Vous activez ainsi le mode de traitement par IA.
Étape 4 : Rédigez le prompt de normalisation
C’est ici que vous indiquez à l’IA quoi faire. Il faut préciser :
- Identifier la valeur la plus fréquente pour le champ ciblé dans chaque groupe de doublons.
- Mettre à jour toutes les fiches du groupe avec cette valeur commune pour le champ donné.
- Mentionner clairement de ne supprimer aucune fiche.
Exemple de prompt pour normaliser le champ /Company Name :
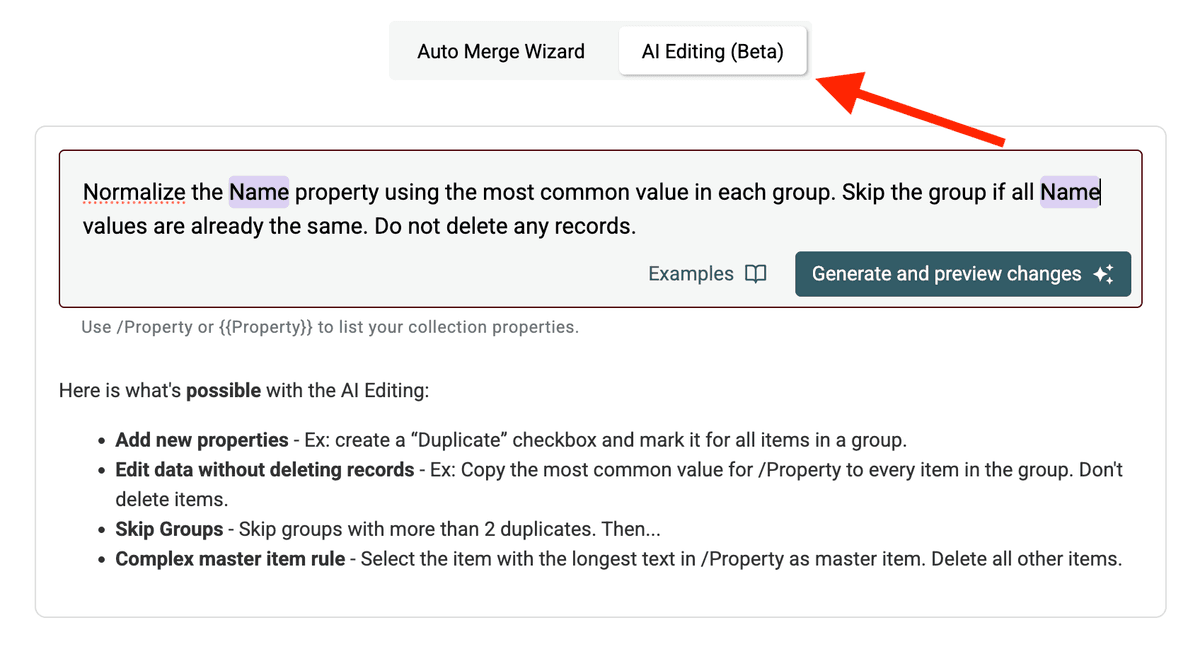
Détail du prompt :
Normalise la propriété /CompanyName...: Précise le champ cible. Utilisez/PropertyNameou{{PropertyName}}pour vos colonnes....en utilisant la valeur la plus fréquente dans chaque groupe.: Définit la logique. Vous pouvez aussi choisir "plus longue valeur", "plus courte", ou une valeur issue d'un autre champ.Passe le groupe si toutes les valeurs sont déjà identiques.: Évite les traitements inutiles.Ne supprime aucun enregistrement.: Essentiel : aucune fiche ne doit être supprimée ni fusionnée.
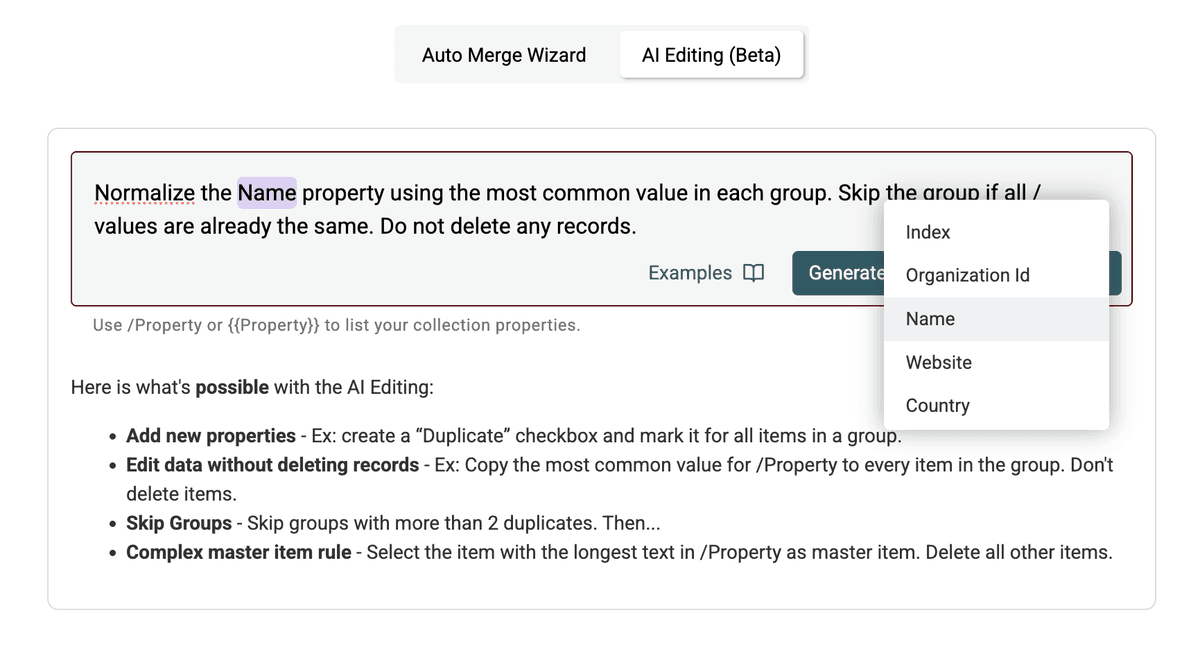
Étape 5 : Générez & prévisualisez le script
Cliquez sur Generate and preview changes. L’IA de Datablist analyse le prompt et génère un script pour effectuer l’action.
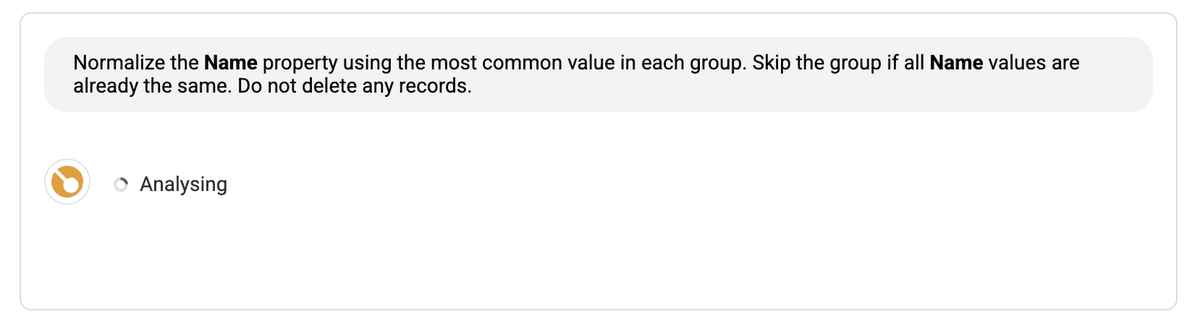
Pas besoin de savoir coder !
- Explication du script : Résumé compréhensible des actions du script. Vérifiez qu’il répond bien à votre attente.
- Aperçu du résultat : Tableau montrant précisément les modifications prévues sur un échantillon, avant l’application. Contrôlez que le champ cible (ex :
/Company Name) affiche bien la valeur normalisée voulue sur tous les doublons de l’exemple.
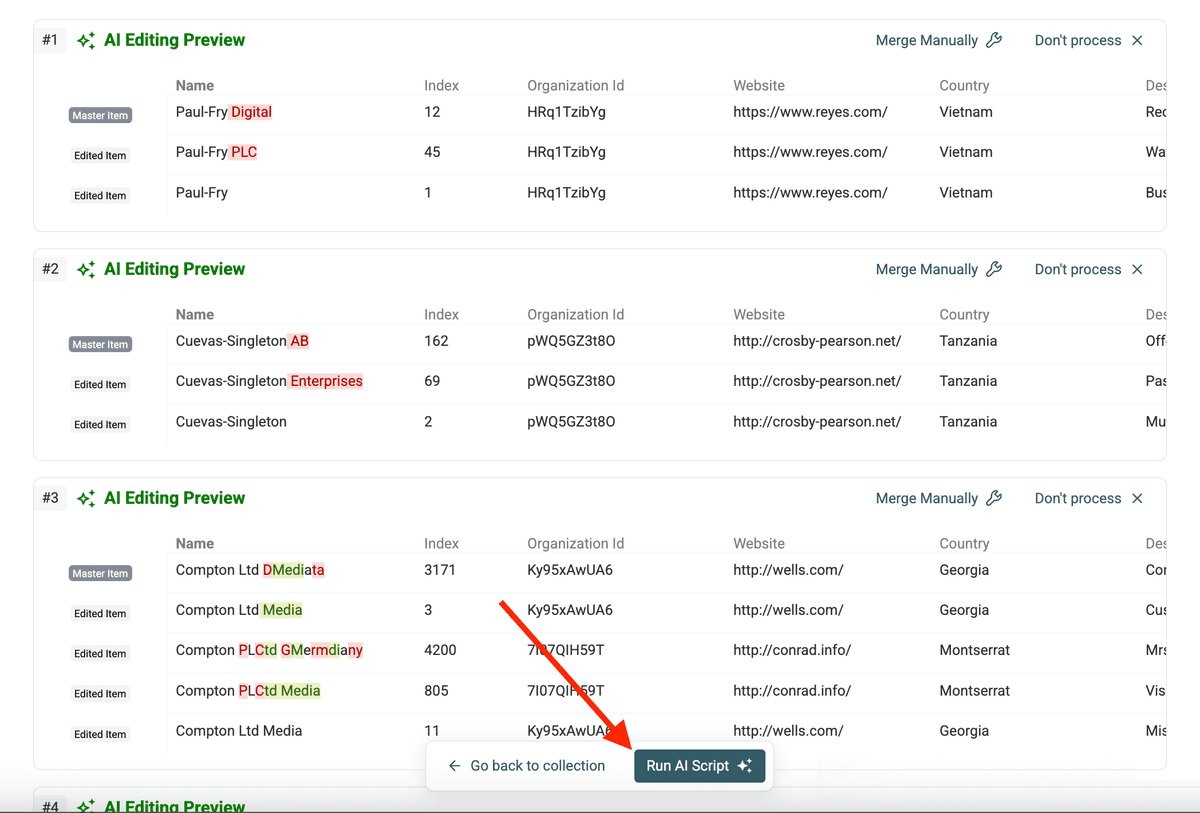
Étape 6 : Exécutez le script
Si tout est conforme, cliquez sur Run AI Script. Datablist applique le script sur tous les groupes de doublons.
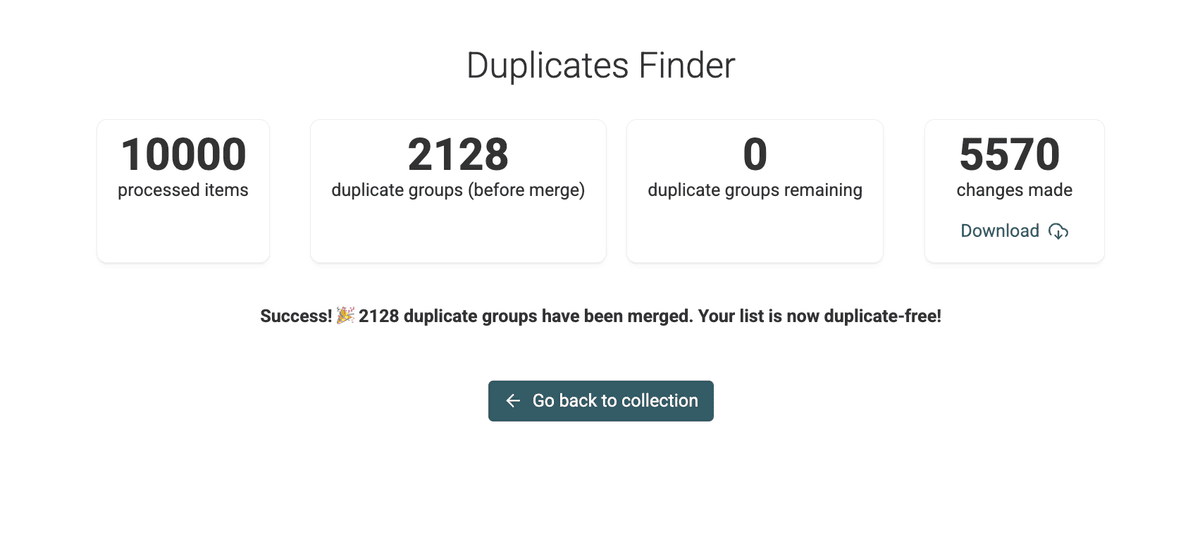
Étape 7 : Vérifiez les changements
Après l’exécution, Datablist affiche un résumé et propose une liste téléchargeable des changements.
Utile pour rejouer ces modifications dans un autre outil (ex : pour éditer des leads CRM, etc.)
Revenez à votre collection principale. Vous verrez que la valeur cible (ex : /CompanyName) est cohérente dans tous les groupes de doublons, sans que les fiches soient fusionnées.
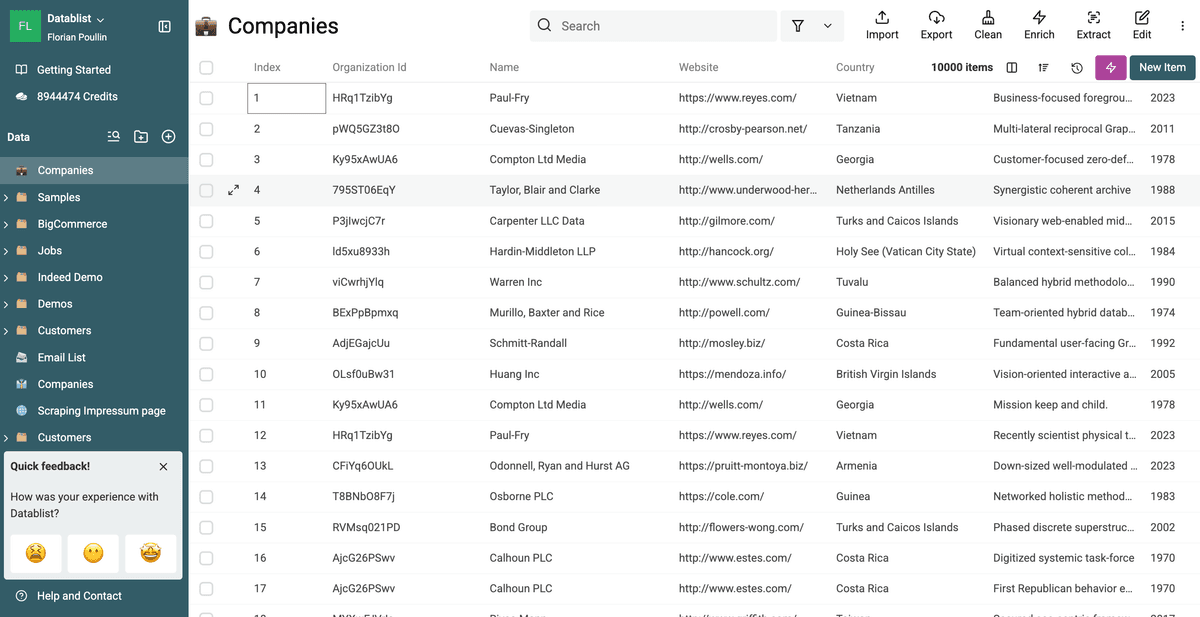
Vous avez réussi à normaliser un champ sur des doublons sans jamais les fusionner ! 🚀
Cas d’usage de la normalisation sans fusion
Pourquoi normaliser un champ plutôt que tout fusionner ?
- Standardiser les noms d’entreprises ou contacts : Éliminer les variantes (« Example Ltd », « Example Limited », « Jon Doe », « Jonathan Doe ») avant d’appliquer une stratégie de fusion.
- Nettoyer les intitulés de poste : Uniformiser « VP Marketing », « Vice President Marketing »… pour des rapports cohérents.
- Normaliser les localisations : Garantir la cohérence des pays ("UK", "United Kingdom") ou des états ("CA", "California").
- Préparer une importation CRM : Standardiser avant l’import, même si vous conservez les doublons un temps.
- Audit de données : Garder les originaux pour l’historique mais normaliser les identifiants pour analyse.
- Nettoyage progressif : Normaliser champ par champ dans un workflow data cleaning avant d’envisager fusion ou suppression définitive.
Pourquoi normaliser sans fusionner ?
- Préserver la granularité : Garde chaque fiche intacte, indispensable pour tracer l’origine ou des interactions spécifiques.
- Gérer l’incertitude : Utile quand les doublons ne sont pas parfaitement identiques ; normaliser un champ clé apporte de la cohérence sans fusion douteuse.
- Approche progressive : Permet de nettoyer étape par étape, en décidant ultérieurement des fusions.
- Simplicité : Action ciblée : on aligne seulement un champ sans toucher aux autres données.
Conclusion
La fonctionnalité AI Processing de Datablist dans Duplicates Finder offre un moyen flexible et puissant de gérer les doublons. Elle permet de normaliser des champs précis sur des groupes de doublons sans fusionner les fiches, ce qui constitue une étape intermédiaire idéale dans de nombreux workflows de data cleaning. Avec de simples prompts en langage naturel, obtenez la cohérence de vos données rapidement et sans risque d’erreur. Que vous vouliez harmoniser noms d’entreprise, de poste, ou des localisations, cette fonction vous fait gagner un temps précieux pour assurer la qualité de votre base.
FAQ
-
Le traitement IA est-il inclus dans mon offre Datablist ? L'AI Processing, incluant la génération/exécution de scripts de normalisation, est disponible sur les offres payantes. Consultez notre page tarifs pour le détail.
-
Puis-je normaliser plusieurs champs avec un seul prompt ? Oui, il suffit d’écrire un prompt pour chaque champ : « Normalise la propriété /Company Name avec la valeur la plus fréquente dans chaque groupe. Normalise la propriété /Country de la même manière. Ne supprime aucun enregistrement. »
-
Que faire si l’IA interprète mal mon prompt ? Relisez systématiquement l’explication et l’aperçu du script avant de l’exécuter. Si le résultat est incorrect, reformulez le prompt et régénérez.
-
Peut-on annuler les changements effectués par l’IA ? Une fois le script lancé, les changements sont appliqués. Datablist possède une fonction annuler pour les dernières actions pendant la session, mais il est recommandé de cloner la collection avant toute transformation majeure, pour pouvoir revenir en arrière si besoin.
-
Quelle est la différence avec l’option "Combine conflicting properties" standard ? L’option "Combine" fusionne les doublons en une fiche maître et concatène les champs texte conflictuels en une seule valeur. L’AI Processing, bien paramétré, met à jour le champ cible sur tous les doublons et conserve chaque fiche séparément. Aucun regroupement ni concaténation, sauf si vous le demandez explicitement.