
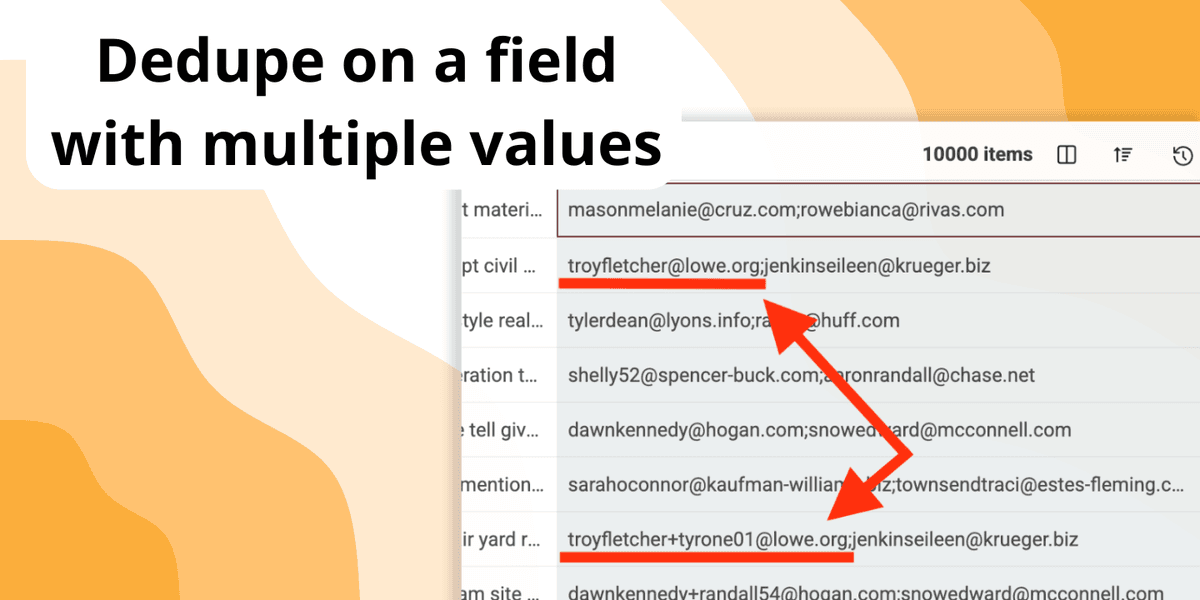
当一个字段里包含多个值时,做去重会立刻变得复杂很多。
想象一下:在一份联系人名单里,“Emails”字段可能用逗号分隔存了好几个邮箱;或者在公司数据库里,“URLs”列塞进了官网链接、社媒主页等多个地址。
很多常规去重工具很难识别这种情况:只要两个记录共享其中任意一个值,它们就可能是重复的,但因为这些值被“塞”在同一个字段里,工具往往匹配不到。
Datablist 针对这种更高级的去重场景,提供了非常可靠的解决方案。
本文会带你一步步看:如何用一个“多值字段”来做去重:
第 1 步:导入并准备去重数据
第一步是把数据导入 Datablist。你可以导入 CSV 或 Excel,也可以连接你的 CRM 或其他数据源。
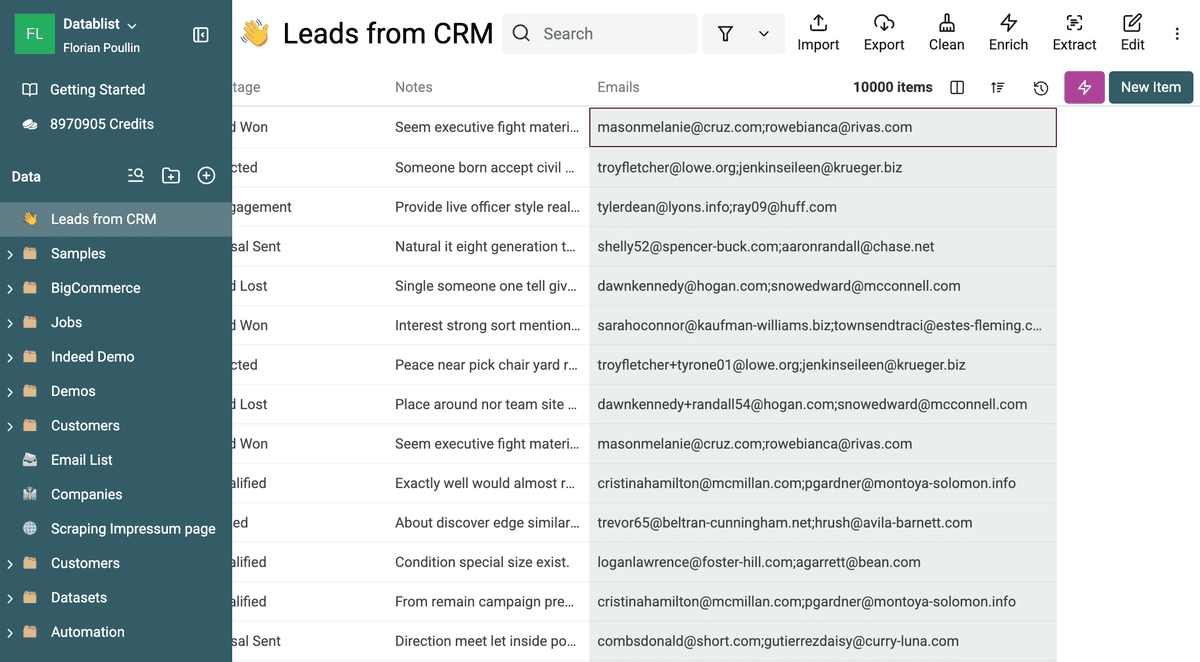
数据导入后,关键是检查那个“包含多个值”的字段。Datablist 的 “Multiple Values” 功能默认适用于用分号 (;) 分隔的值。
示例:
假设联系人列表里有一个 “Emails” 字段,邮箱以如下形式存储:
- 记录 1:
john.doe@example.com; jane.doe@example.com; info@example.com - 记录 2:
jane.doe@example.com; support@example.com; sales@example.com - 记录 3:
john.doe@example.com; marketing@example.com
Datablist 可以识别:记录 1 和记录 3 都包含 “john.doe@example.com”,记录 1 和记录 2 都包含 “jane.doe@example.com”,即使这些邮箱都在同一个字段里。
处理不同分隔符:
如果你的多值是用分号以外的字符分隔(比如逗号、竖线、空格等),那么在使用 Duplicates Finder 之前,你需要先统一/规范化数据格式。这时可以用 Datablist 很强的 Find & Replace 工具来做标准化。
用 Find & Replace 把分隔符统一成分号的操作如下:
- 打开你的 Datablist collection。
- 选中包含多值的那一列。
- 进入 “Clean” 菜单,选择 “Find & Replace”。
- 在 “Find” 中输入你当前使用的分隔符(例如用逗号分隔就填
,)。 - 在 “Replace with” 中输入分号
;。 - 点击 “Apply”。
只要确保所有多值字段都使用分号作为分隔符,就能让 Datablist 的 “Multiple Values” 功能更准确地发挥作用。
第 2 步:用多值匹配识别重复记录
当数据导入完成、并且多值字段也已经准备好(用分号做分隔符)后,就可以开始找重复了。
-
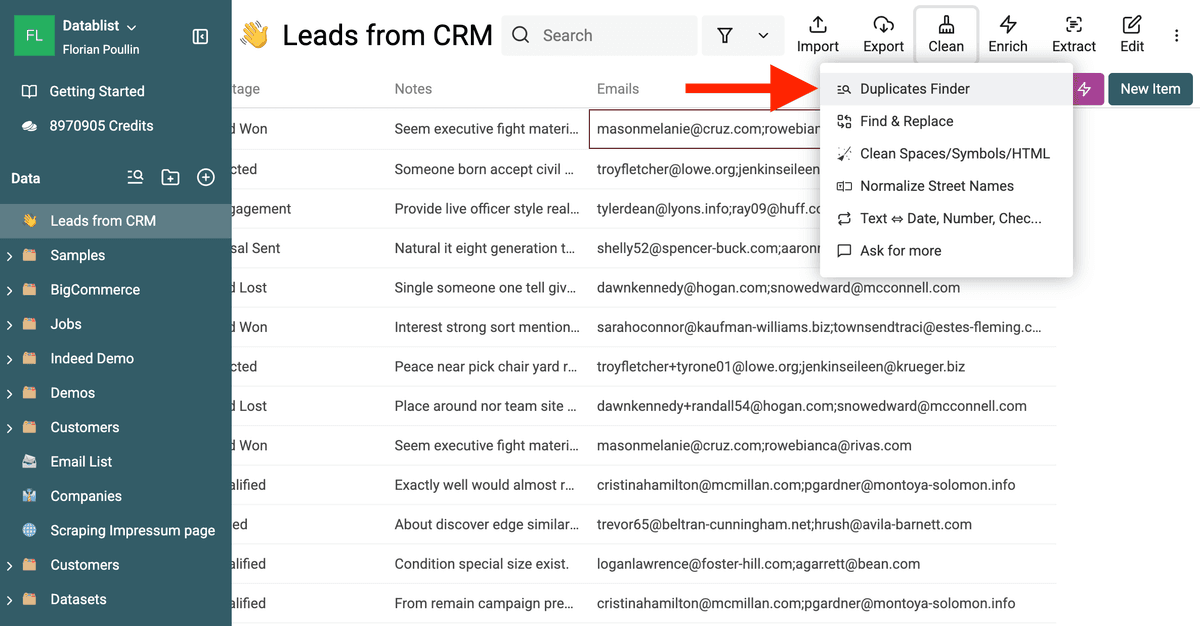
进入 “Clean” 菜单,选择 “Duplicates Finder”。
Open Duplicates Finder Tool -
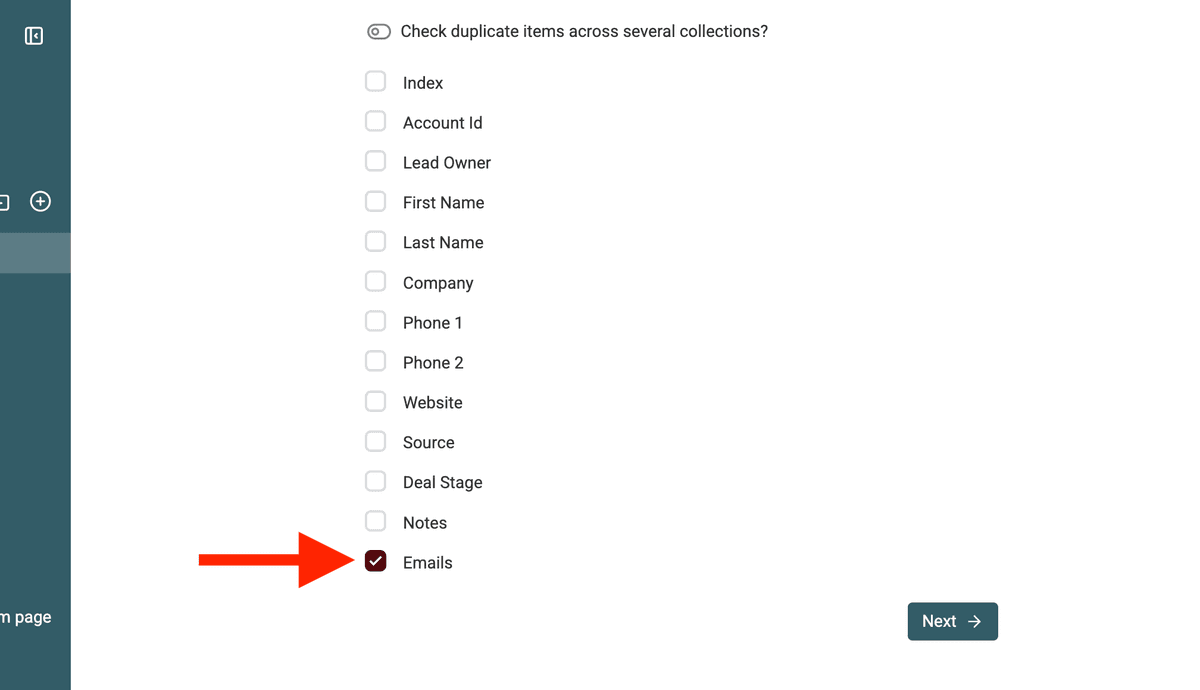
在 Duplicates Finder 里,选择你要用于匹配的“多值字段”列。比如我们示例里的 “Emails” 列。
Select the Property -
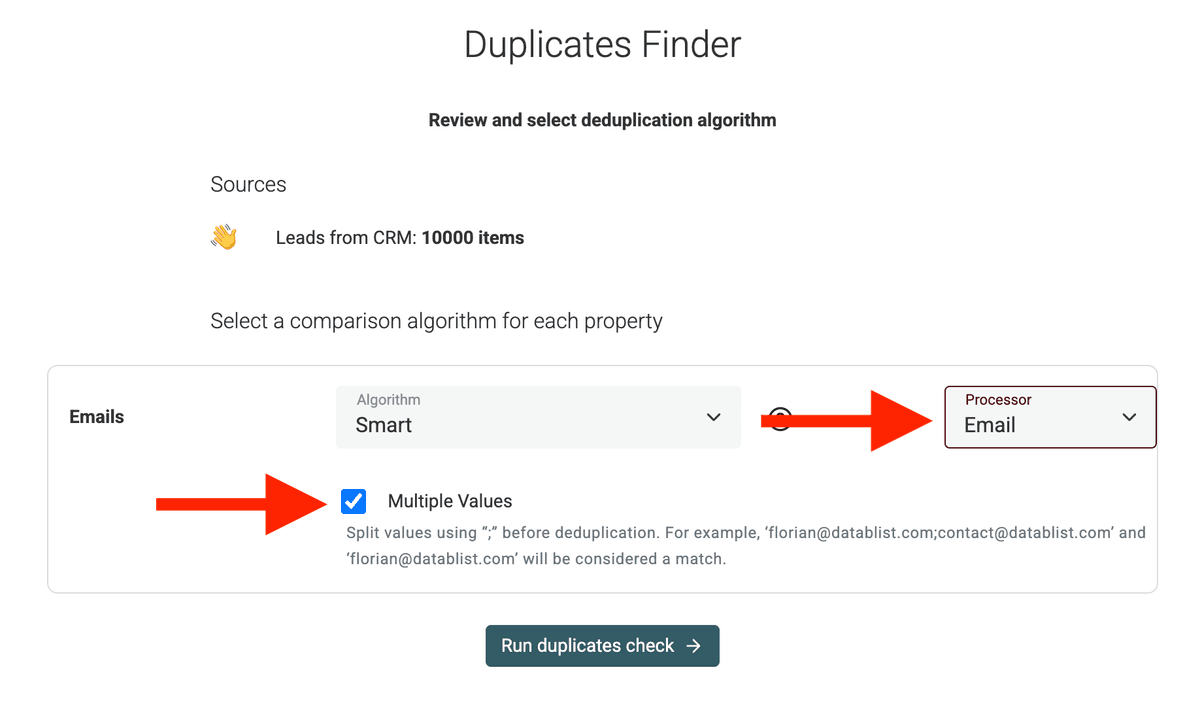
最关键的一步:勾选 “Multiple Values” checkbox。 此时会出现一个输入框让你确认/指定分隔符。确保它是
;(分号)。Enable Multiple Values Option -
选择匹配算法和 Processor
Datablist 提供了多种 deduplication 算法,最常用的两种是:
- Smart Algorithm: 通常建议从它开始。它会把每条记录中的邮箱逐个拆开分析,并找出共享一个或多个相同邮箱的记录。
- Distance Algorithm: 如果你预期邮箱里可能存在轻微差异或拼写错误(例如 “john.doe@exmaple.com” vs. “john.doe@example.com”),Distance Algorithm 会更合适。你需要设置一个相似度阈值(similarity threshold),定义“多像才算匹配”。
Datablist 还提供 “Processor”,会在识别 duplicates 之前先做 normalize(标准化)。比如你用 URL 去重就选
URL,用邮箱去重就选Emails等。例如 Email processor 会把下面两个邮箱视为同一个人:
john@datablist.com和john+spam@datablist.com。 -
运行 duplicates 检测。Datablist 会开始处理数据,把 “Emails” 字段里的每个邮箱当作独立实体进行对比。只要记录之间共享至少一个邮箱(或在 Distance Algorithm 下足够相似),就会被归为同一组潜在重复。
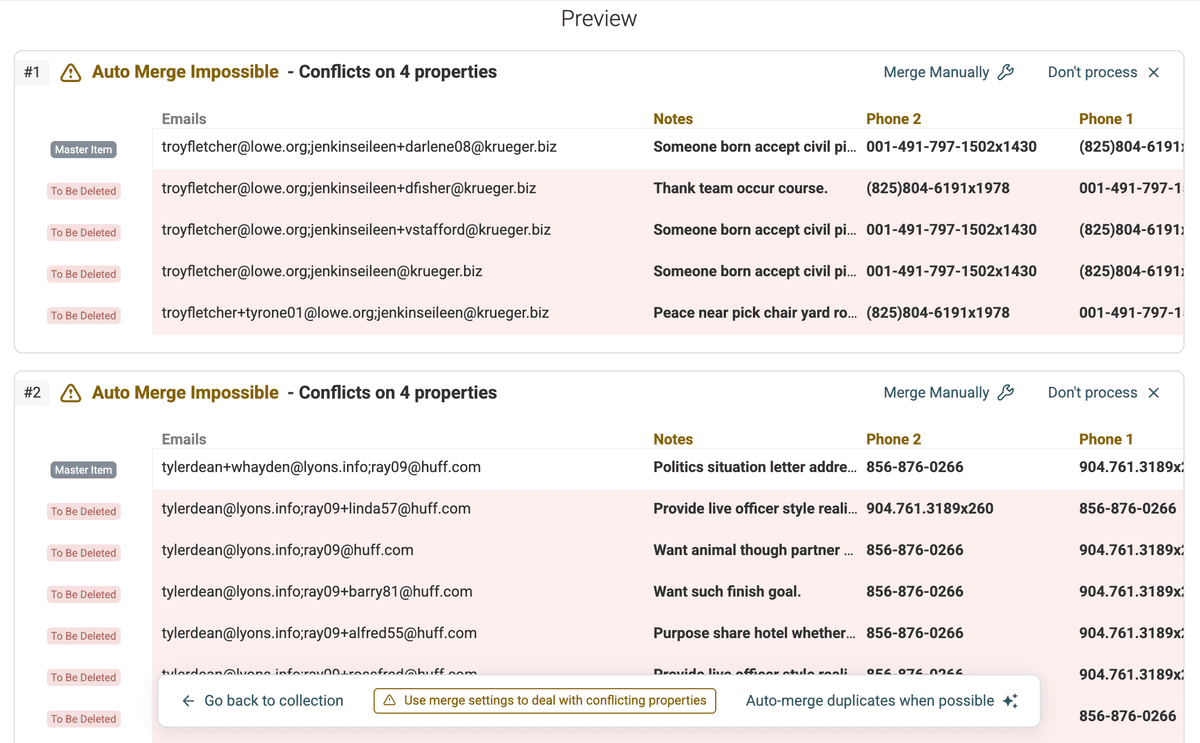
Duplicates Preview -
仔细检查识别出的重复分组。你会看到记录是如何根据多值字段中的共享值被匹配到一起的。比如在 “Emails” 示例中:记录 1 和记录 3 会因为都有 “john.doe@example.com” 被分到同一组;记录 1 和记录 2 则会因为共享 “jane.doe@example.com” 被分到同一组。
第 3 步:处理冲突并合并重复记录
识别出重复分组后,下一步就是定义这些记录该如何合并,尤其是针对“多值字段”以及其他可能出现冲突的字段。
-
对于每个重复组,Datablist 会高亮显示值不一致的字段——这些就是 conflicting properties(冲突字段)。这类冲突可能出现在其他联系信息上,比如手机号、邮箱地址(如果你用邮箱做去重)、职位名称等。
-
对于多值字段(例如 “Emails”),你会看到更明确的合并选项:
-
Combine Values: 通常这是最理想的选择。Datablist 会收集重复记录中的所有唯一值,并用一个连接符把它们合并成一个值。例如合并记录 1(
john.doe@example.com; jane.doe@example.com; info@example.com)与记录 3(john.doe@example.com; marketing@example.com),最终主记录会变成:john.doe@example.com; jane.doe@example.com; info@example.com; marketing@example.com。 -
Drop Conflicting Values:如果某一条记录明显更完整,而你希望直接丢弃另一条记录的冲突值,就选 “Drop conflicting values...”。
Select a master record
你也可以配置 Datablist 如何选择 master record。合并重复记录时,Datablist 会保留一条记录,更新它的字段,并删除其他记录,从而最终只剩一条。
你可以通过以下规则控制 Master Record 的选择方式:
- Most Complete:选择字段填得最完整(非空最多)的那条记录。
- Last Updated:选择最近被修改的记录。
- First Created:根据创建时间选择最早创建的记录。
- Highest Value:按你指定字段的最大值来选主记录;若多个记录值相同,则选最新的那条。
- Lowest Value:按你指定字段的最小值来选主记录;若多个记录值相同,则选最新的那条。
- Matching Value:选择在指定字段中包含某个特定值的记录;如果没有记录匹配,则不会合并。
-
-
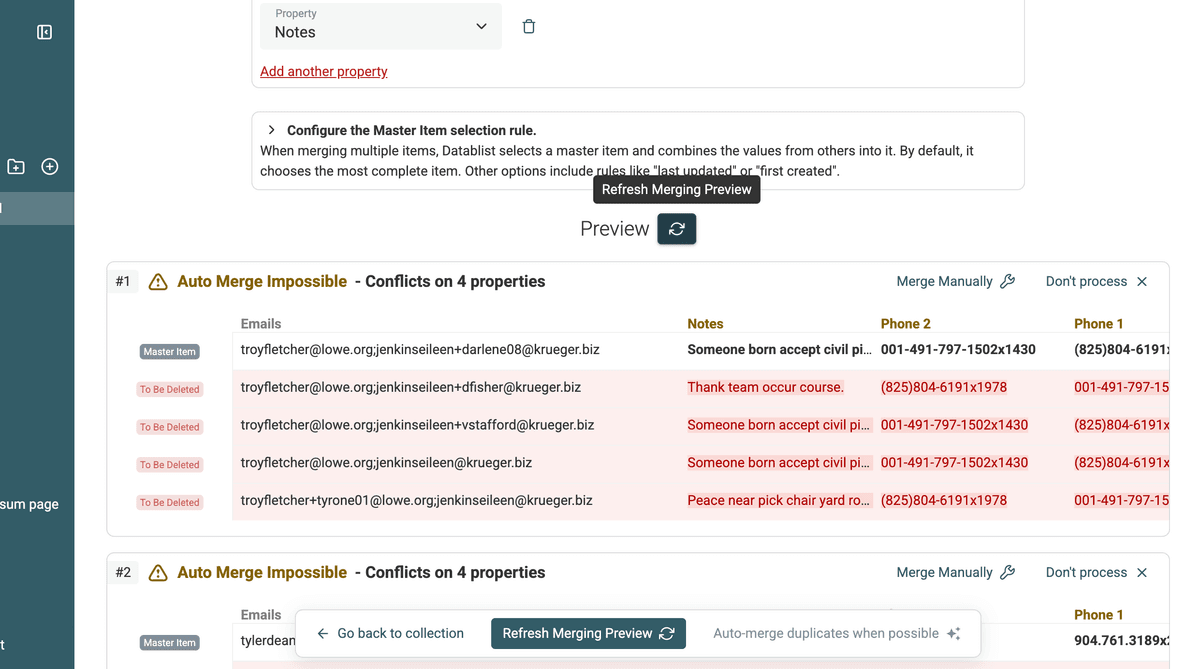
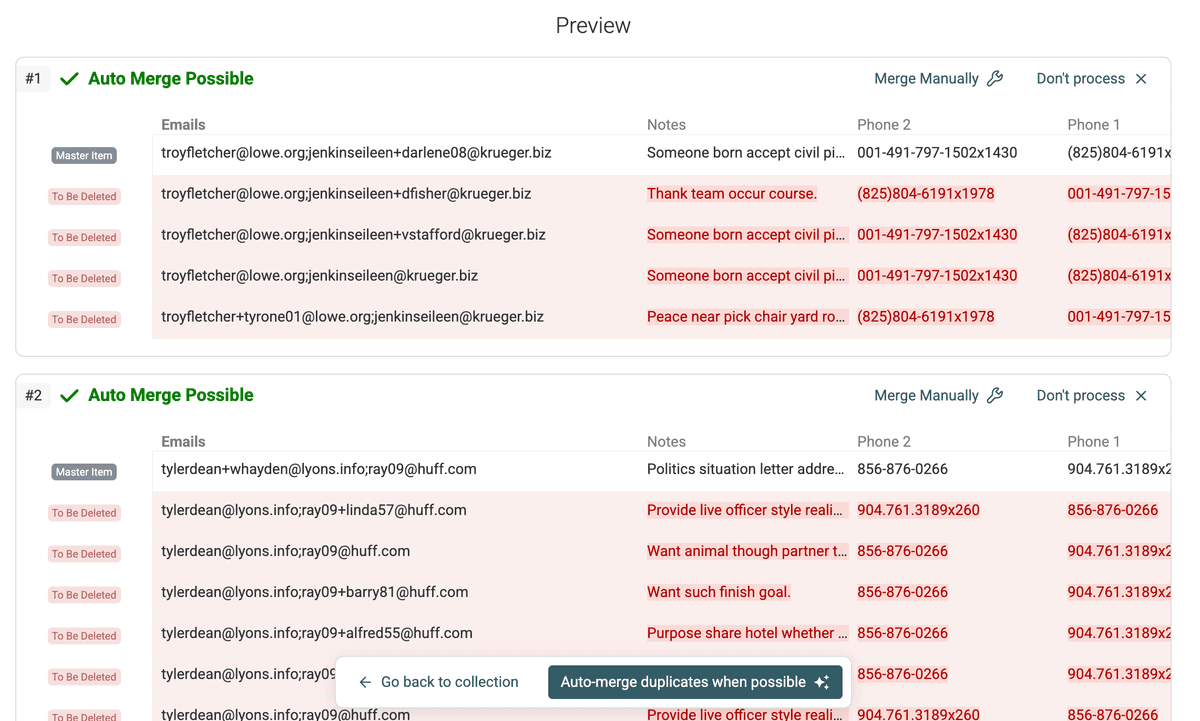
为所有冲突字段设置好 merge 规则后,刷新 preview。你会看到每个重复组最终合并后的记录长什么样。重点留意多值字段是否按预期被合并。
Update Merging Result Preview -
仔细检查合并预览,确保结果符合预期。确认无误后,就可以开始合并:点击 “Auto-merge duplicates when possible”,或者按需手动合并指定分组。
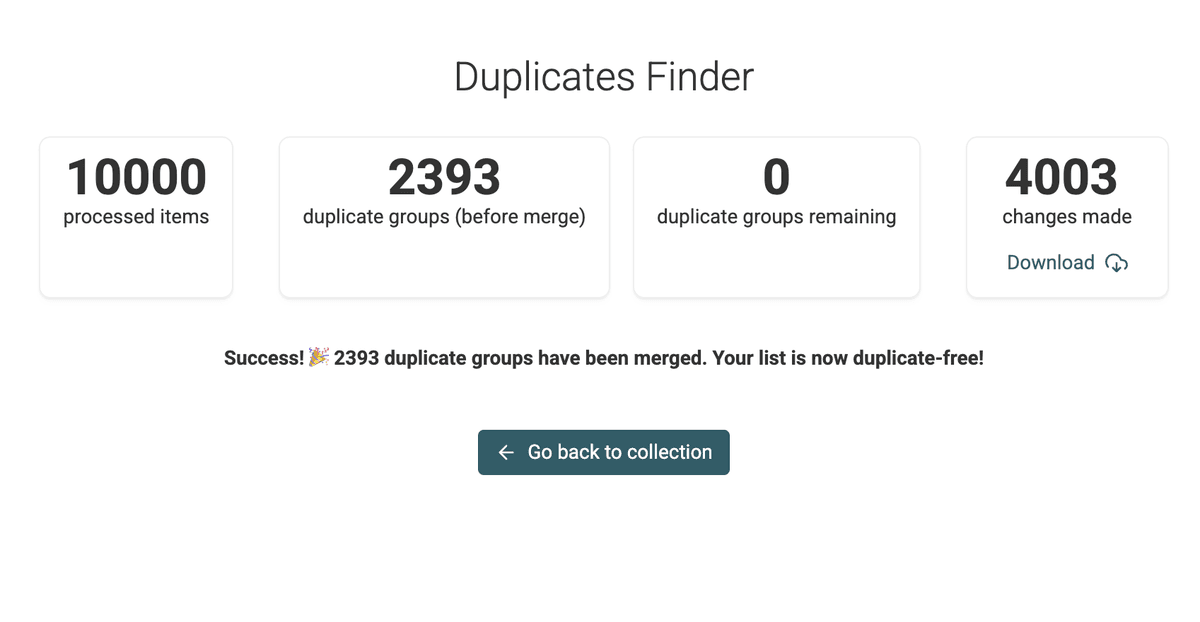
Successful Merging Preview -
合并完成后,Datablist 会给出本次操作的总结。
Merging Done Screen
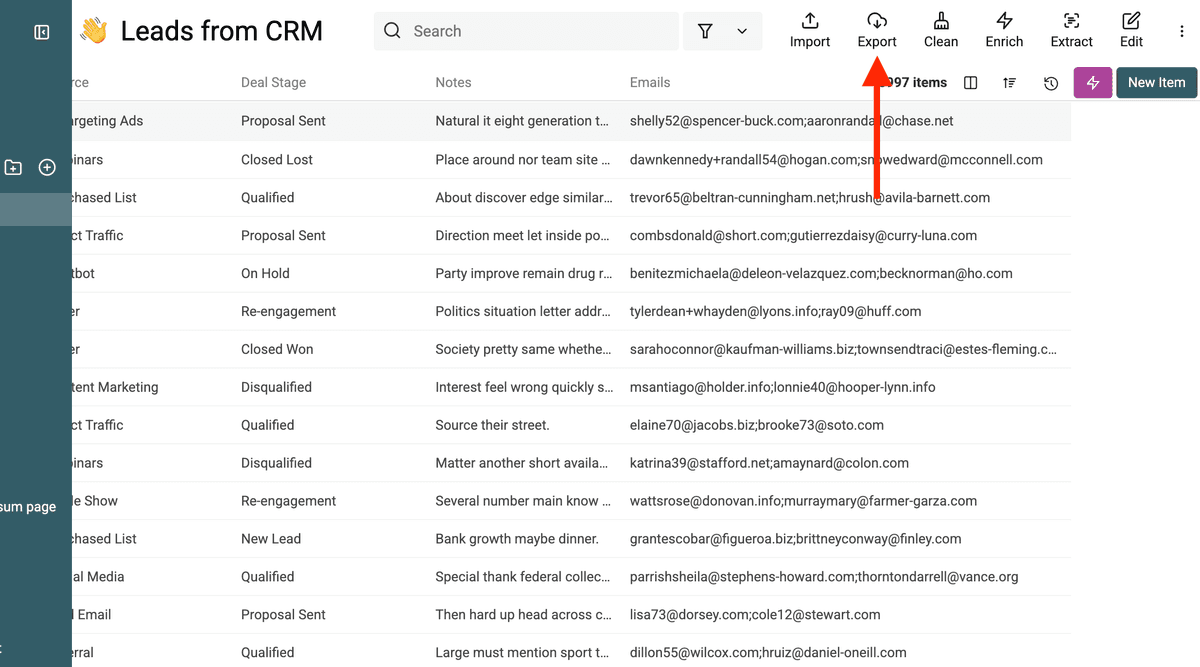
最后,你就可以导出清洗并去重后的列表了——即使之前关键字段是“一个单元格里多值”的结构,现在也会被整合成更干净、更可用的数据。
按照以上步骤,你就能充分利用 Datablist 的 “Multiple Values” 功能,对多值字段场景做高级去重。别忘了:为了获得最佳效果,优先把分隔符统一为分号 ;。