April 2025
Hi guys, we're back again! This month, we have two highlights and some smaller improvements on the app functionality and enrichments.
Let’s talk about the details!
The Highlights of April
Huge Improvement: Custom Deduplication Rules With AI
Remember the AI Editing feature we dropped in January?
We just built the same functionality for the Deduplication Suite. It’s simple to use, yet powerful, and just like AI Editing, the only thing you need to do is to imagine what you want and tell our AI about it.
What It Does
AI Editing in the Deduplication Suite is basically the same thing as in the spreadsheet editor.
It allows you to edit, create, and transform your deduplicated rows with a single prompt.
You could, for example:
- Label properties - Ex: create a “Duplicate” checkbox and mark it for all items in a group.
- Edit data without deleting records - Ex: Copy the most common value for /Property to every item in the group. Don't delete items.
- Skip Groups - Skip groups with more than 2 duplicates. Then...
- Complex master item rule - Select the item with the longest text in {Property} as the master item. Delete all other items.
Why It Matters
Before, you would have to choose between merge or delete, and had some options to choose a master item, but you were still limited to a few options. Now you’re not limited anymore, just tell our AI Assistant what you want to do and it will do it.
After all, it’s you who knows best what to do with your data.
How to Use It
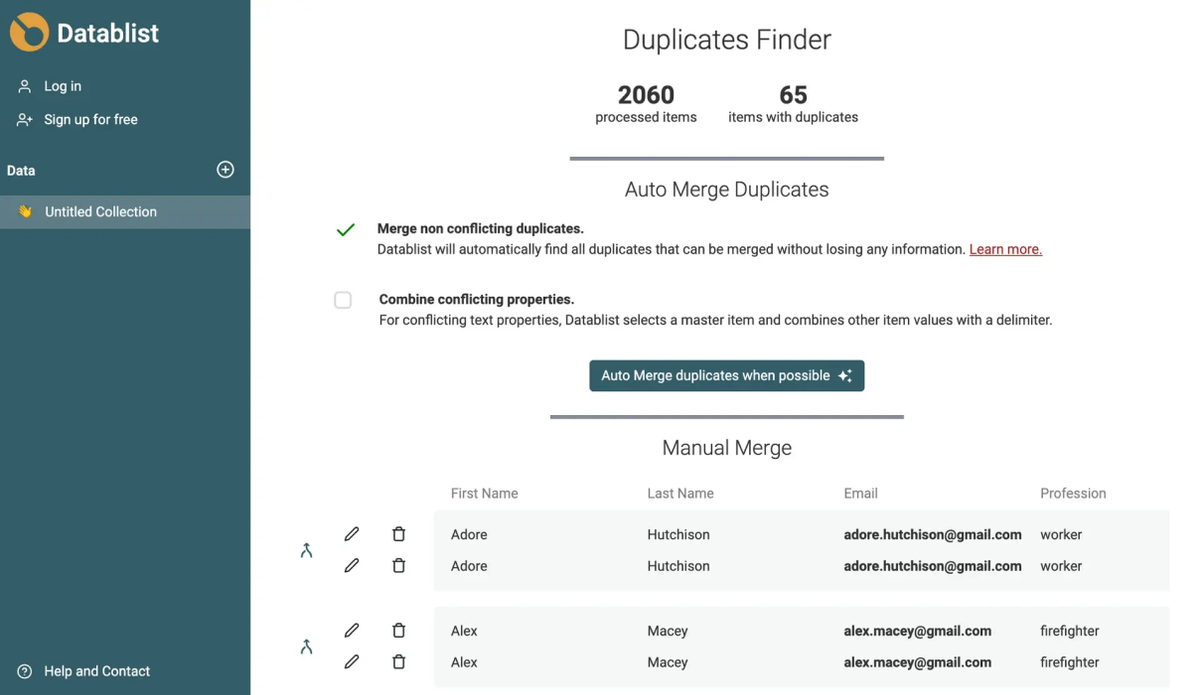
- Go to Clean ⇒ Duplicates Finder
- Run a duplicates check
- Click on AI Editing
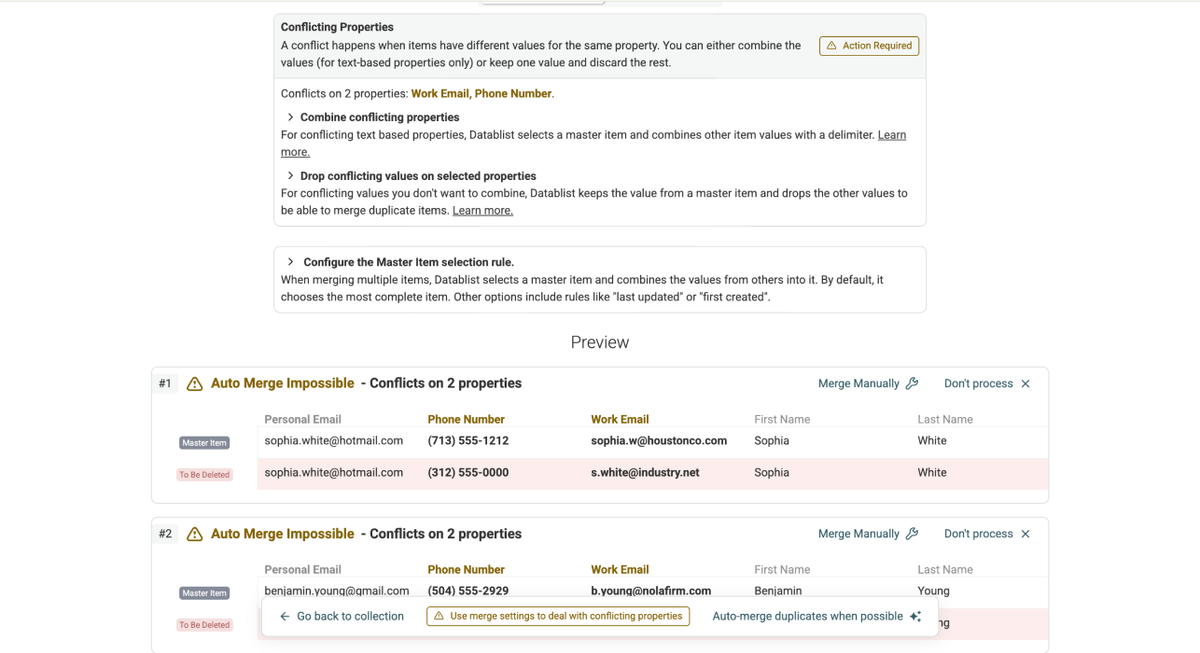
- Imagine anything you want to do with your data
- Write a prompt explaining it to the AI
- Wait 10-20 seconds while the AI is writing the script
- Look at the preview, confirm, or write a follow-up prompt to improve the outcome
Related Guides
- How to Unify Field Values in Duplicates (Without Merging)
- How to Sum Numeric Values When Merging Duplicates
Okay, now to highlight number two!
New Source: AI Agent - Site Scraper
This scraper is the first no-headache option to scrape data from any website; in fact, it makes scraping so easy that it becomes almost too easy. The only thing you do is: Prompting
What It Does
It visits websites, paginates them, understands the content, and extracts the data you need.
Here are some examples of what our AI Scraping Agent can do:
- Visit directory X and extract all listings from it
- Extract products of an Amazon search
- Scrape Shopify Stores
- … and much more
Why It Matters
If scraping isn’t your profession or hobby, then you shouldn’t be required to waste hours learning it. However, that’s what most of the scraping tools push you to do. This scraper is different.
With Datablist’s AI Scraping Agent, you can scrape websites without:
- Writing code
- Configuring unstable API’s
- Click-and-Point on website elements
Or losing your mind watching bad tutorials…..
The only thing you have to do: Tell an AI agent what to do (prompting)
How to Use It
- Create a collection
- Click See all sources, scroll down, select AI Agent - Site Scraper
- Paste a URL and write a prompt (or choose one of our templates)
- Configure output properties
- Set a limit
- That’s it.
Related Guides:
- How To Scrape a Directory
- How To Scrape a Shopify Store
- How To Scrape Zillow Properties
- How To Scrape AirBnB Properties
- How To Scrape Businesses From Yellow Pages
- How To Scrape Real Estate Agents From Zillow
Improvements
LinkedIn People Scraper
You can now choose to either 3, 5, or 10 past experiences when scraping a LinkedIn profile.
Why we did it: One of our customers was dealing with the accuracy of their lead lists.
The problem: LinkedIn and other B2B databases are not good at filtering, so sometimes when they were searching for CEO @ Company, e.g., Apple, they got results for people who are CEO at another company, and worked simultaneously at Apple.
The fix: By getting their complete employment history, they could run the Claude AI processor on their lead list and double-check if the prospect is really working at their target account or not.
Cleaning Preview
You can now see what changes you’re going to make when using the Bulk Edit or other cleaning features.
Why we did it: It makes it easier to understand what you're doing before committing to changes.
That’s it folks, until next time!
If you want us to build something for you, PITCH ME HERE 👈🏽