

Gestionar registros duplicados en varios archivos de Excel es una pesadilla que consume tiempo y provoca inconsistencias y errores costosos.
Sin un proceso fiable de deduplicación, corre el riesgo de enviar varios emails al mismo contacto, tomar decisiones de negocio incorrectas basadas en datos duplicados y perder horas comparando registros manualmente.
Aprenda cómo deduplicar datos de forma eficiente en múltiples archivos de Excel con técnicas y herramientas probadas que le ahorrarán tiempo, mantendrán la integridad de sus datos y evitarán duplicaciones futuras.
En esta guía, verá cómo eliminar registros duplicados entre varias listas con estructuras diferentes:
- Cómo importar sus diferentes archivos de Excel
- Cómo encontrar duplicados entre varias listas
- Cómo eliminar duplicados automáticamente
Paso 1: Importe los archivos a deduplicar en Datablist
Regístrese en Datablist e importe al menos dos archivos.
Asegúrese de que en sus archivos exista al menos un identificador único.
Nota: El Duplicates Finder de Datablist puede trabajar con cualquier número de archivos Excel/CSV. Pueden tener estructuras diferentes. Solo necesitan un identificador coincidente en cada archivo/listado.
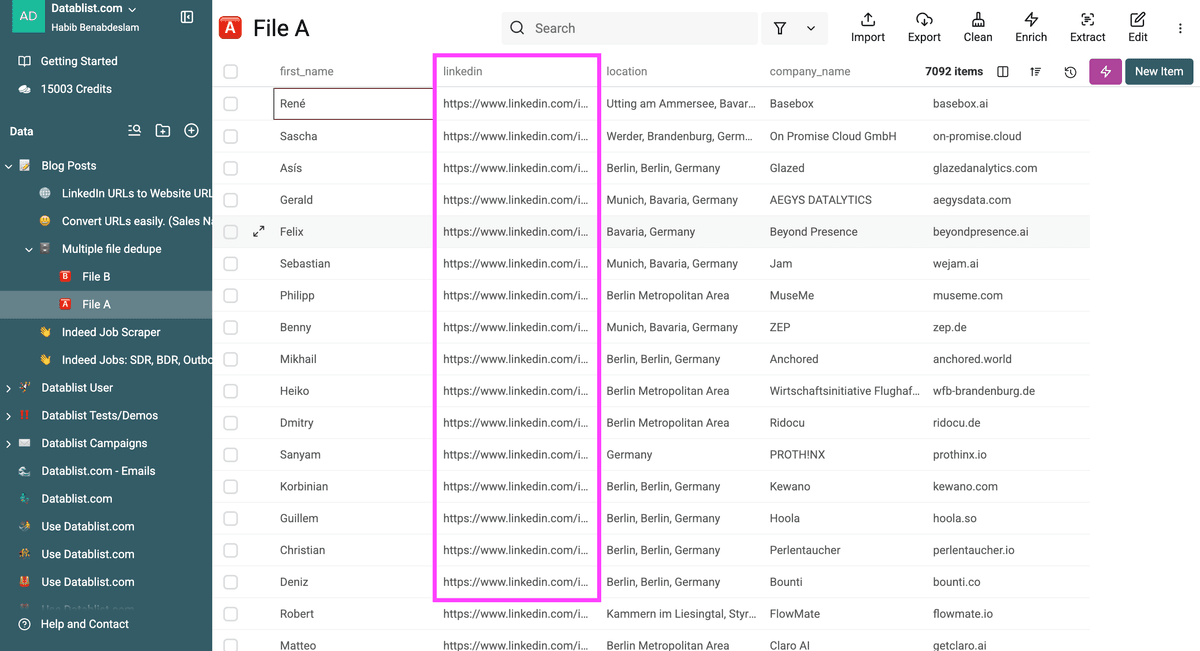
Elegí la URL de LinkedIn de mis prospectos como identificador único.
Un identificador único no tiene por qué ser absolutamente único: también puede ser el nombre de la empresa o un nombre, siempre que lo defina como su identificador único.
Paso 2: Encuentre duplicados entre sus listas
Luego, haga clic en “Clean” y seleccione “Duplicates Finder”.
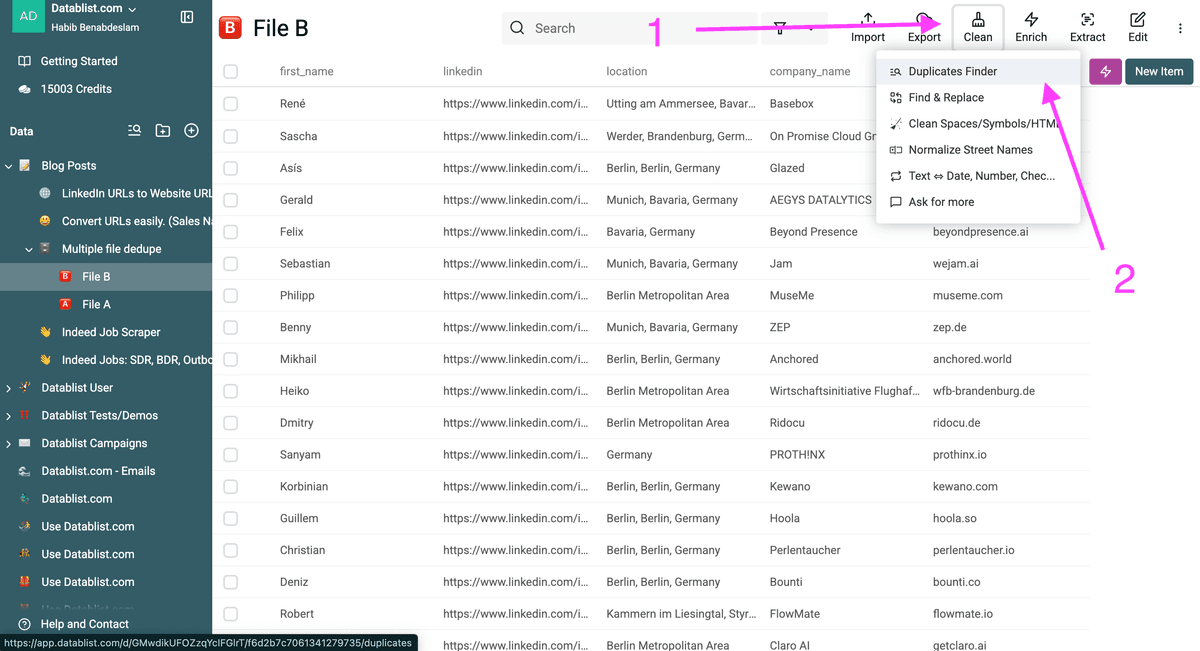
Nota: Puede empezar desde el archivo que prefiera. El proceso y los resultados serán los mismos.
Configure todo para deduplicar entre sus archivos CSV.
- Haga clic en "Selected Properties and Multi Collections" y
- Haga clic en "Check Duplicate Items Across Several Collections"
- Seleccione las colecciones entre las que desea deduplicar — puede elegir dos o más archivos sin límite.

Elija la propiedad que quiere usar para su deduplicación.
Debe existir una propiedad similar en cada uno de sus archivos. Por cada propiedad que use para deduplicar, seleccione la propiedad correspondiente en cada colección.
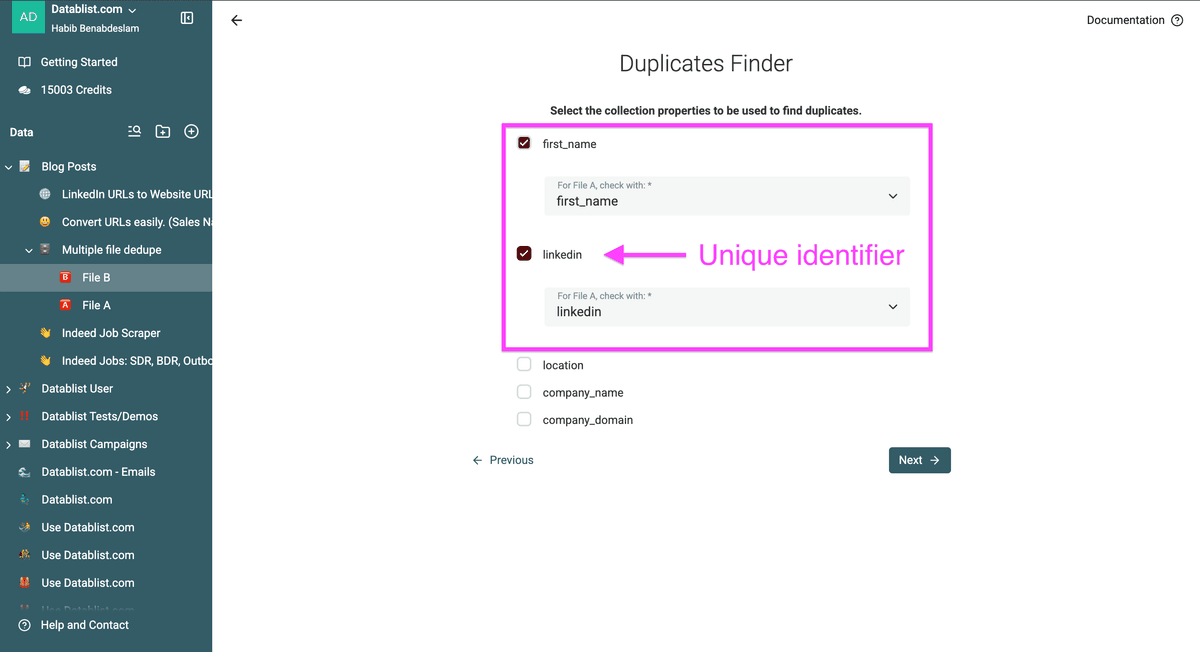
En mi ejemplo, eliminaré todos los prospectos del “Archivo A” del “Archivo B” basándome en la URL de LinkedIn.
Puede seleccionar varias propiedades para el matching de duplicados. En ese caso, los registros deberán tener valores coincidentes en todas las propiedades. Si quiere encontrar duplicados en una propiedad OR en otra, ejecute el proceso dos veces. Una por cada propiedad.
Seleccione los mecanismos de comparación que desea usar.
Para IDs (CRM Ids, Internal Ids), siempre uso "Exact". Para propiedades de texto como URLs, Emails, etc., uso el algoritmo "Smart" para máxima precisión al deduplicar varios archivos.
Si tiene Names con posibles errores tipográficos o ligeras variaciones, use uno de los algoritmos de distancia (Levenshtein Distance o Jaro-Winkler Distance).

Haga clic en “Run duplicates check” cuando haya elegido la opción que mejor se adapte a su deduplicación.
Paso 3: Elija las acciones de limpieza
Configure la regla de limpieza eligiendo entre:
- Eliminar los elementos duplicados de la colección X
- Conservar solo los elementos duplicados en la colección X (esta opción solo está disponible al deduplicar entre 3 o más colecciones)

Haga clic en "Process duplicate items" para continuar.
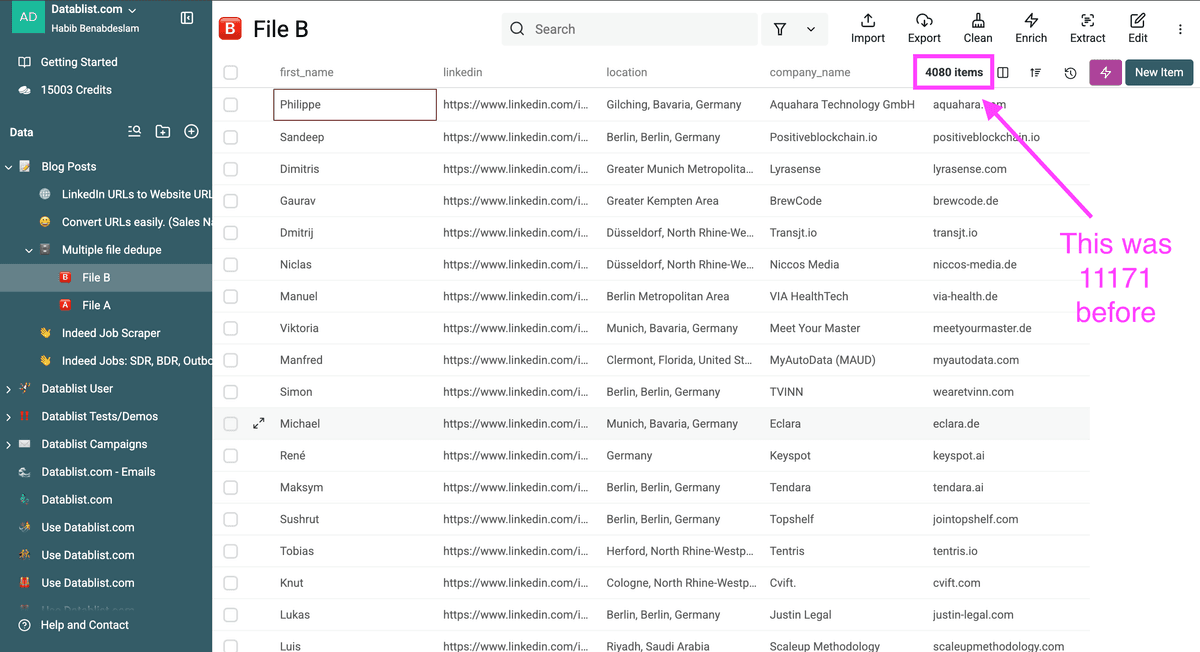
Mi archivo ya limpio contiene únicamente prospectos nuevos sin duplicados.
Importante - Al deduplicar entre varias listas, el algoritmo no elimina duplicados dentro de un solo archivo. Si existen registros duplicados dentro de un archivo, empiece ejecutando la deduplicación en cada archivo por separado.
Casos de uso de este flujo de trabajo
- Evitar contactar dos veces al mismo prospecto.
- Evitar contactar a varias personas de la misma empresa.
- Consolidar datos de clientes de distintos departamentos o sucursales.
- Limpiar y unificar varias listas de contactos de diferentes campañas de ventas.
- Unificar feedback de clientes o respuestas de encuestas desde múltiples fuentes.