

Vous traînez une liste pleine de doublons ? Que ce soit des contacts clients, des abonnés email ou un stock produit : les doublons doivent disparaître, sinon vous perdez temps et argent. Imaginez envoyer 2 fois le même mail à un client : non seulement c’est agaçant, mais ça dégrade votre image.
La bonne nouvelle ? Vous pouvez dédupliquer vos listes gratuitement et en ligne grâce à Datablist. C’est un outil simple mais puissant pour nettoyer les doublons rapidement. Pas de code, pas de migraine.
Dans ce guide, découvrez comment dédoublonner une liste en 3 étapes faciles :
- Importer et préparer votre liste
- Identifier et matcher les doublons
- Fusionner et nettoyer votre liste
Partie 1 : Importez votre liste avec doublons
La première étape pour dédupliquer votre liste avec Datablist : importer vos données dans la plateforme.
Datablist gère tous les formats courants (CSV, Excel), et vous pouvez aussi charger vos fichiers depuis des sources comme Pipedrive.
Étape 1 : Créez une nouvelle Collection
Dans Datablist, une collection, c’est comme un tableau Excel. Commencez par cliquer sur le bouton « + » dans la barre latérale pour créer une nouvelle collection.
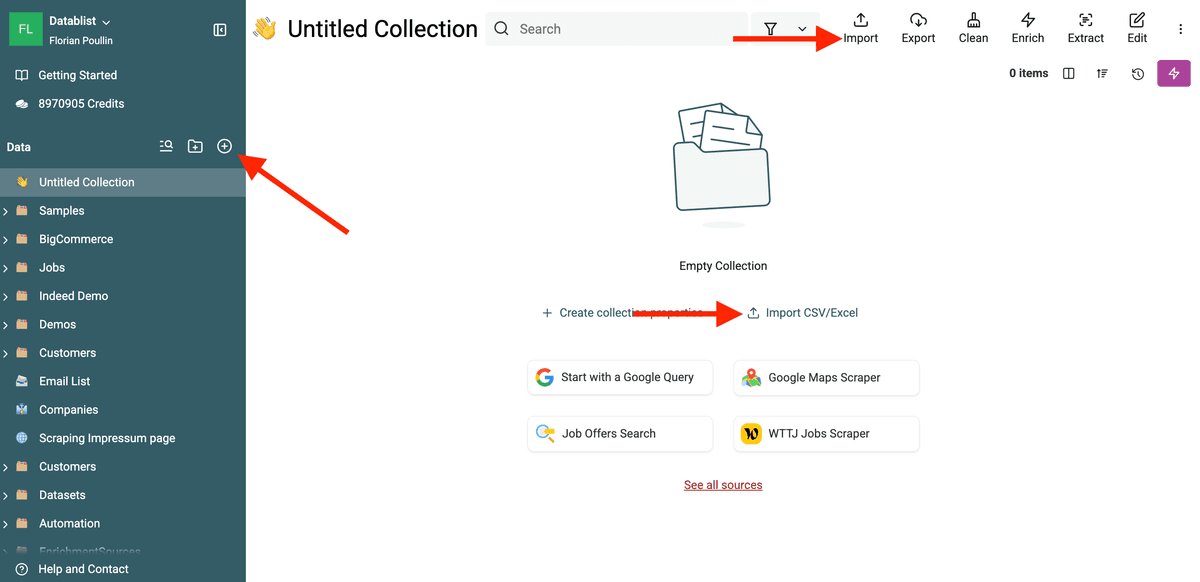
Dans cette collection, cliquez sur "Import CSV/Excel". Pour des intégrations avancées, cliquez sur "Sources".
Une fois le fichier importé, Datablist vous montre un aperçu : colonnes (propriétés) et quelques lignes. Vérifiez que tout est correct.
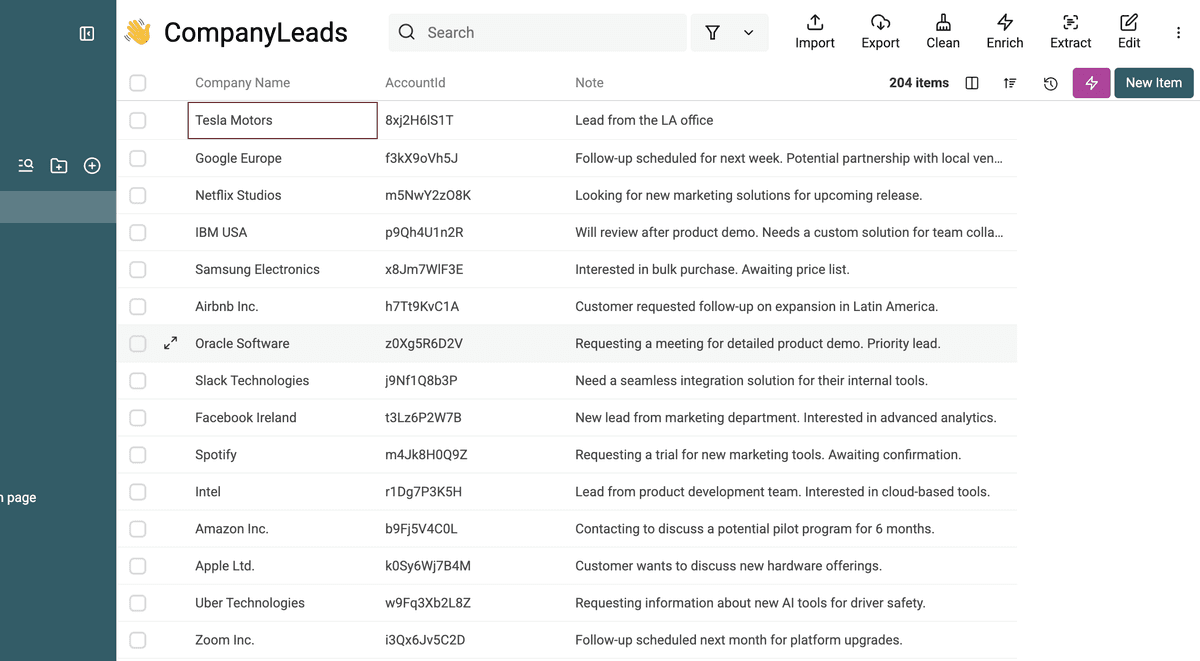
Partie 2 : Détection des doublons dans la liste
Votre liste est prête. Passons à la traque des doublons.
Datablist utilise des algos avancés pour retrouver les doublons probables, même quand les lignes ne sont pas tout à fait identiques.
Étape 1 : Ouvrir le Duplicates Finder
Dans votre collection Datablist, rendez-vous dans le menu "Clean" et cliquez sur "Duplicates Finder".
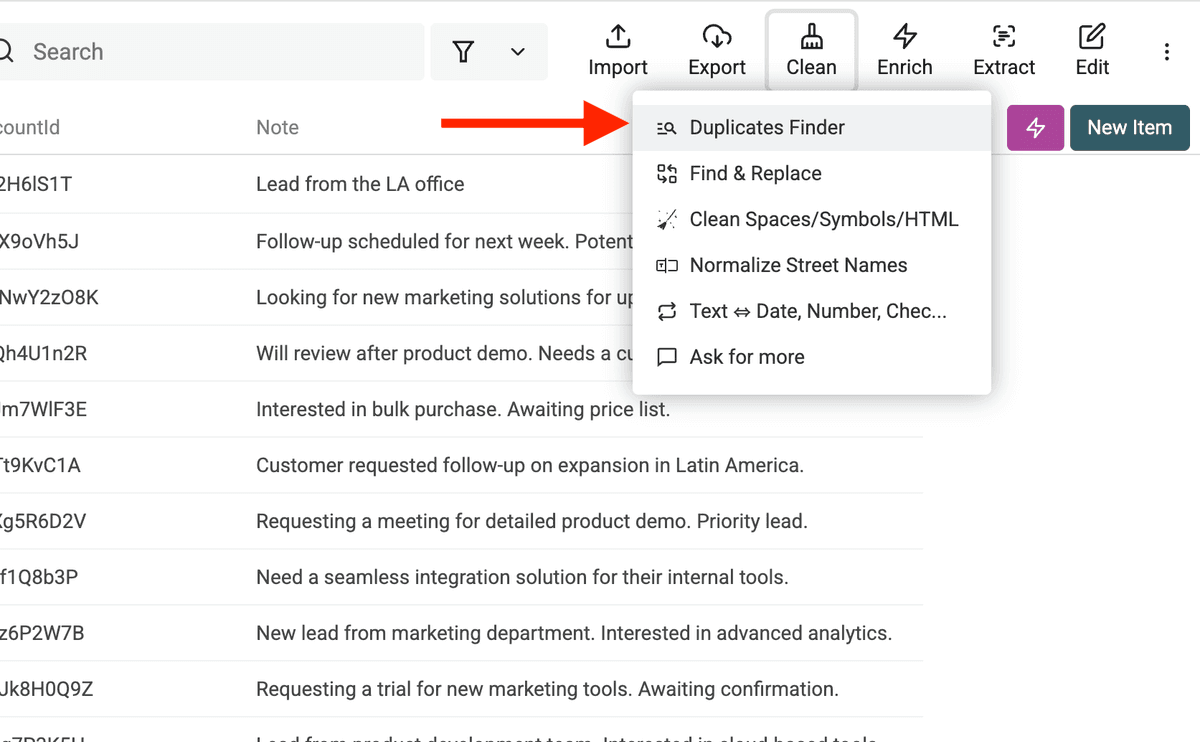
Cela ouvrira le Duplicates Finder, où vous allez dire à Datablist comment repérer les doublons.
Étape 2 : Choisissez les propriétés à comparer (propriétés de déduplication)
La "propriété de déduplication", c’est la colonne clé sur laquelle Datablist va comparer les enregistrements pour voir s’ils sont des doublons.
À adapter selon votre liste :
Exemples :
- Liste de contacts : comparez les emails (le plus fiable), ou à défaut (si tout le monde n’en a pas), les noms ou le duo prénom + nom.
- Produits : comparez le nom produit ou un ID unique (EAN, GTIN, SKU).
- Sociétés : le nom de la société ou l’URL du site sont de bons candidats.
Sélectionnez votre ou vos colonnes dans le Duplicates Finder.
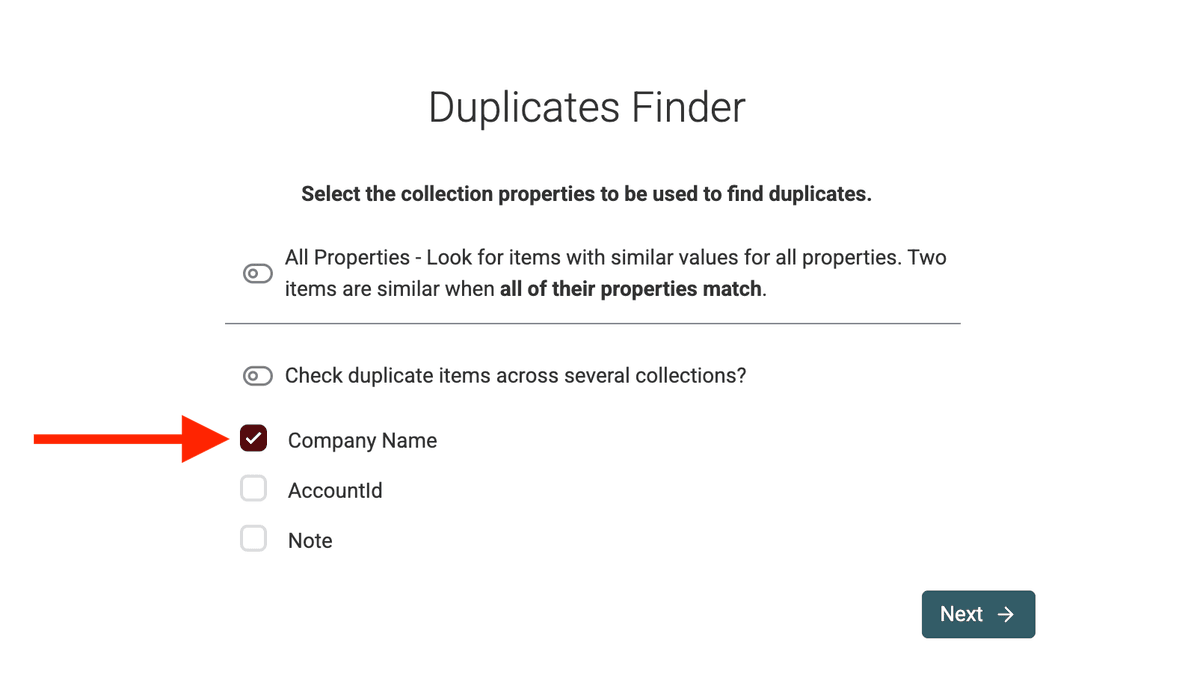
Étape 3 : Sélectionnez l’algorithme de matching & le processor
Datablist propose plusieurs méthodes :
- Exact : détecte seulement les doublons 100% identiques
- Smart : plus tolérant, il gère par exemple les URLs équivalentes même si l’écriture diffère (http/https, etc.) ou les variations mineures.
- Phonétique (Double Metaphone) : identifie les entrées qui "sonnent" pareil même si l’orthographe n’est pas identique (très utile pour les noms propres)
- Fuzzy Matching (Jaro-Winkler & Levenshtein) : détecte la similarité textuelle (pratique pour fautes de frappe, abréviations…)
Remarque : L’algo Exact est accessible même sans compte. Le Smart requiert un compte gratuit. Les algorithmes Metaphone et Fuzzy sont réservés aux comptes payants.
Pour chaque colonne, choisissez l’algo et le processor le plus adapté. Cela permet de normaliser vos données avant la comparaison.
Processors courants Datablist :
- URLs : enlève protocoles (http/https), paramètres de tracking, etc. → liens équivalents sont groupés.
- Exemple : https://exemple.com?utm_source=nl → exemple.com
- Emails : ignore les alias (+truc) sous Gmail.
- Exemple : john+travail@gmail.com → john@gmail.com
- Noms d’entreprise : enlève indices légaux (SARL, SAS…), termes business et géographiques.
- Exemple : Acme Inc. → Acme
Remarque : le processor sur les noms d’entreprise est réservé aux comptes payants.
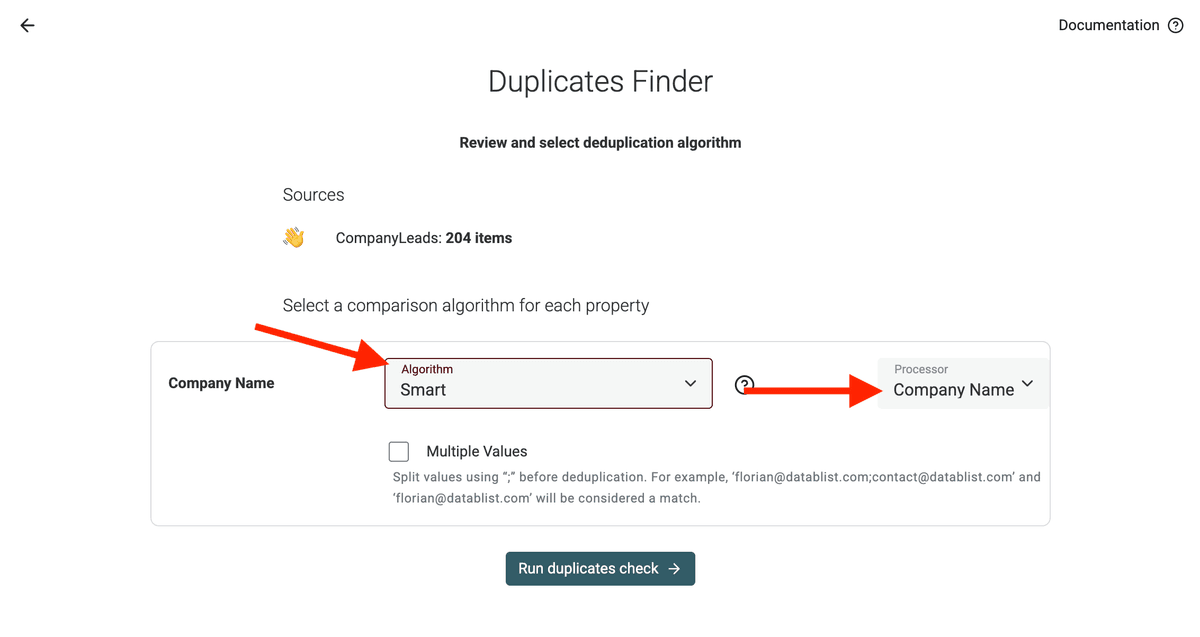
Dédupliquez des champs à valeurs multiples : si la colonne contient plusieurs valeurs (ex : emails), activez "Champs à valeurs multiples".
👉 Important : dédupliquez en plusieurs fois
Pour la plupart des listes, commencez avec le matching "Smart", puis enchaînez avec un passage "Fuzzy" sur la même colonne (ou une autre, ex : nom à la place de l’email).
Les doublons trouvés par Smart sont quasi sûrs, vous pouvez merger rapidement. Mais les algo de distance peuvent proposer des faux positifs, à valider manuellement !
✅ Astuce : Commencez par Smart, puis affinez avec Fuzzy (distance).
Étape 4 : Lancez la détection de doublons
Après avoir défini les propriétés et l’algo, cliquez sur "Run duplicates check" pour commencer.
Datablist scanne votre liste et groupe les fiches considérées comme doublons.
Étape 5 : Passez en revue les groupes détectés
Une fois le scan fini, vous obtenez la liste des "Duplicate Groups".
Chaque groupe contient deux (ou plus) entrées considérées comme doublons. Inspectez comment elles se ressemblent… et s’il y a des conflits (valeurs différentes dans un champ).
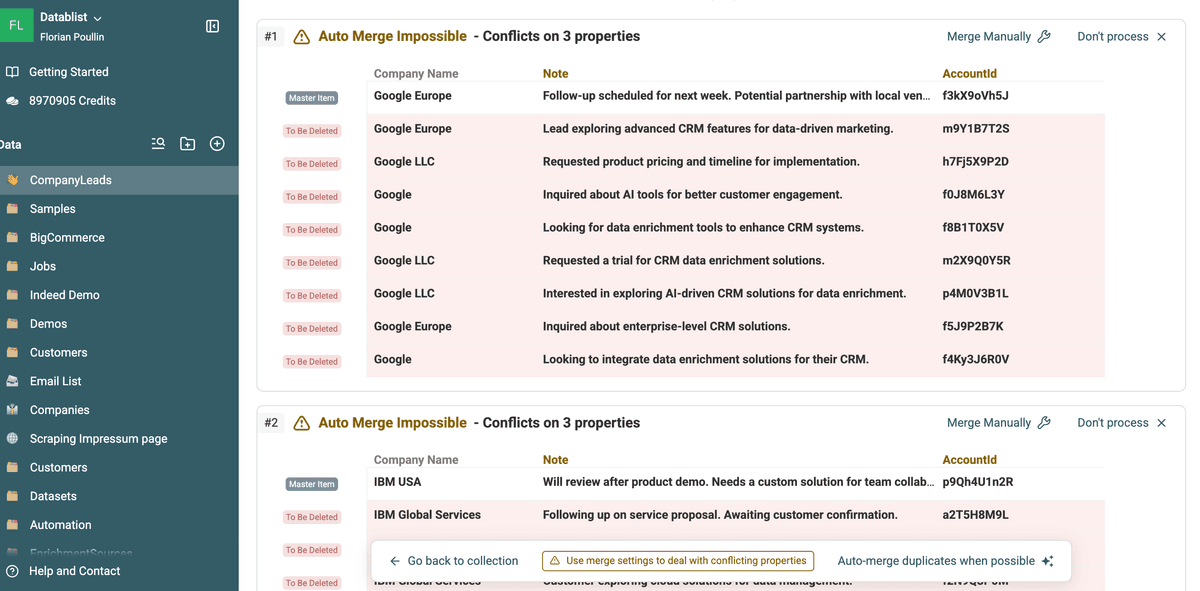
C’est l’étape clé pour ne pas merger à tort de vraies fiches distinctes.
Remarque : Vous pouvez télécharger un CSV/Excel des groupes de doublons. Pratique si vous n’avez besoin que des stats, ou d’un reporting des groupes détectés (avec identifiant unique).
Partie 3 : Résolution et fusion des doublons
Ça y est, vos doublons sont repérés ! Reste à nettoyer la liste en réalisant la fusion.
Il va falloir statuer sur les éventuels conflits et fusionner les fiches pour obtenir un enregistrement propre.
Étape 1 : Comprendre groupes et conflits
Les doublons peuvent comporter des valeurs différentes sur certains champs : ce sont les "valeurs en conflit". Exemple classique : deux fiches, même email, mais téléphone ou poste différents.
Étape 2 : Choisir la règle de fusion des champs en conflit
Datablist vous permet de gérer précisément ces conflits lors de la fusion. Vous pouvez définir pour chaque propriété :
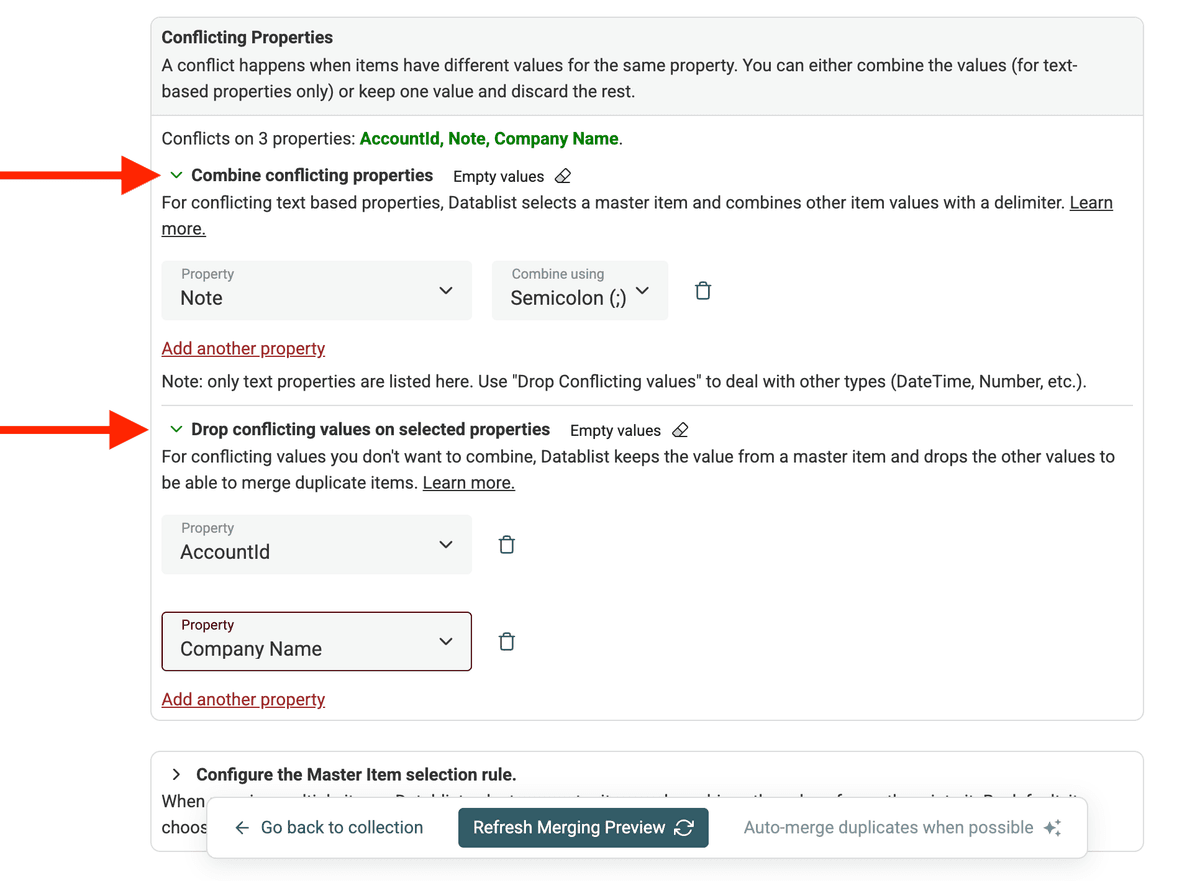
Deux choix principaux :
- Combiner les valeurs : par exemple pour des numéros de téléphone ou des notes ; toutes les infos sont gardées.
- Ignorer les valeurs conflictuelles : on ne conserve qu’une valeur (utile quand une seule info est pertinente).
Petit plus : il existe un lien "Tout sélectionner" pour appliquer la règle à tous les champs d’un coup.
Exemple de combinaison :
Fiche 1 : Email : john.doe@example.com, Tél. : 01 23 45 67 89
Fiche 2 : Email : john.doe@example.com, Tél. : 06 87 65 43 21
Fusion combinée : Email : john.doe@example.com, Tél. : 01 23 45 67 89 ; 06 87 65 43 21
Étape 3 : Configurer la règle de Master Item
Lors d’une fusion, Datablist choisit un "master record" pouvant servir de base (les infos des autres y sont fusionnées).
Plusieurs règles existent :
- Le plus complet : la fiche la mieux renseignée prime
- Dernière mise à jour : la fiche la plus récente l’emporte
- La plus ancienne : on garde la 1ère créée
- Valeur max/min : utile pour des notes, quantités, scores, etc. Si égalité, on prend la plus récente.
- Valeur spécifique : ne merge que si une valeur bien précise figure dans un champ donné
Étape 4 : Auto-fusionner les doublons simples
À chaque règle ajustée, cliquez "Refresh Preview" pour visualiser la fusion finale.
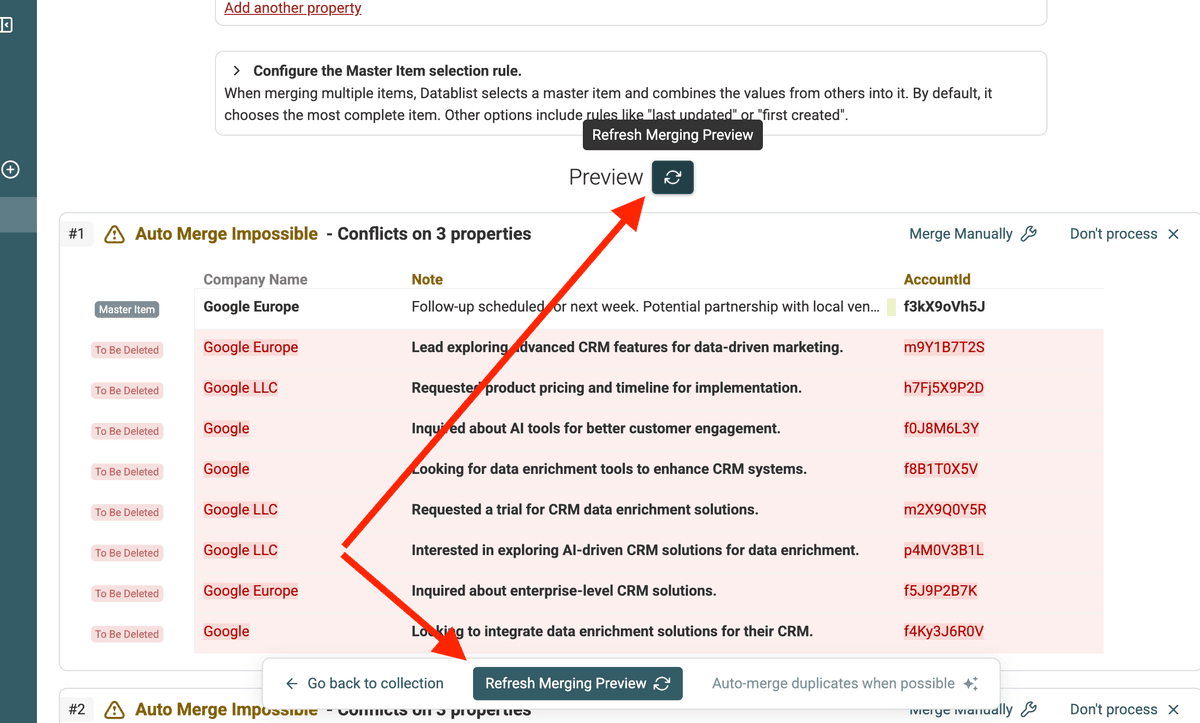
Quand il n’y a plus de conflits, Datablist peut automatiquement fusionner les groupes.

Repérez la mention "Auto-merge when possible" pour laisser Datablist fusionner.
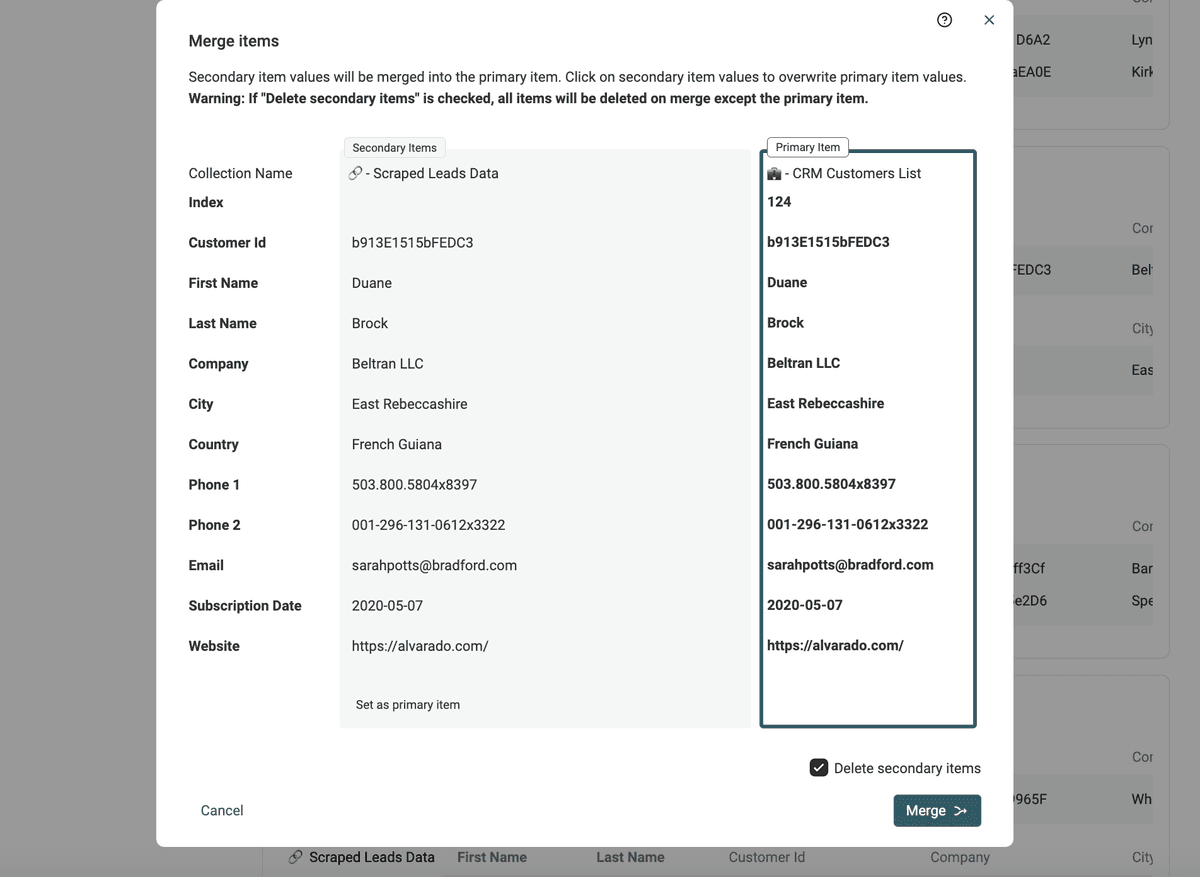
Étape 5 : Fusion manuelle des doublons restants
Quand des conflits persistent, la fusion manuelle s’impose. Datablist propose un "Manual Merging Assistant" pour arbitrer chaque valeur entre les fiches du groupe.
Cliquez sur le bouton du groupe concerné, examinez les valeurs, et validez !
Étape 6 : C’est fini ! Vérifiez et exportez
Une fois la fusion terminée, prenez une minute pour inspecter votre liste nettoyée.
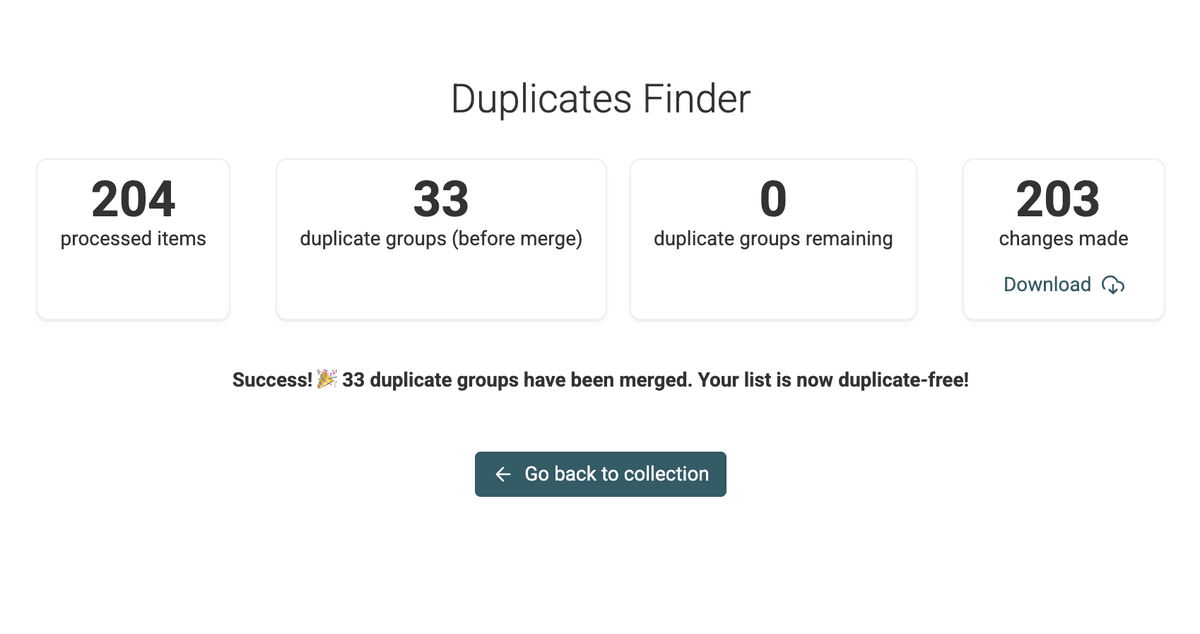
Assurez-vous que la déduplication est réussie, puis cliquez sur "Export" pour télécharger votre fichier propre.
Essayez Datablist pour tous vos besoins de cleaning !
Foire Aux Questions (FAQ)
Est-ce que Datablist est vraiment gratuit pour la déduplication ?
Oui ! Vous pouvez supprimer les doublons de vos listes gratuitement (même sans inscription).
Il suffit d’uploader votre fichier pour commencer. Les algos avancés sont accessibles avec un compte gratuit. Les seuls payants sont le matching fuzzy et phonétique.
Datablist gère-t-il de très grosses listes ?
Oui ! Datablist est optimisé pour les listes volumineuses : 10 000, 100 000 ou même 500 000 lignes, le duplicate finder les parcourt et crée les groupes en quelques secondes/minutes.
Pas besoin de découper vos listes : une seule importation suffit.
Est-ce que le fuzzy matching est disponible ?
Oui ! Datablist intègre des algorithmes de fuzzy matching comme Levenshtein et Jaro-Winkler pour rattraper les fautes ou variations proches.
Exemples de match :
- “Jon Smith” et “John Smith”
- “Acme Ltd.” et “Acme Inc”
Vous réglez le seuil de similarité selon besoin.
Je veux dédoublonner mes contacts CRM, leads ou clients — c’est possible ?
Oui ! Exportez votre fichier CRM (HubSpot, Salesforce…) en CSV, chargez-le dans Datablist et supprimez les doublons en quelques minutes. Utilisez ensuite les "Change Files" générés pour importer les modifs dans votre CRM, sans ressaisie manuelle.
Avec Pipedrive on propose une intégration directe pour la déduplication en masse.