

手动做调研,会让公司一直停在低效和不赚钱的状态。
原因很简单:
- 这是枯燥、重复、没人喜欢做的活
- 调研非常耗时,而我们都知道:时间就是钱
- 如果靠人工做,信息的质量和数量会因人而异
这件事我们都经历过。我们在 Google 上“挖信息”花的时间实在太多了,但这根本不是我们想把精力投入的地方。(McKinsey 提到,知识工作者有 19% 的时间用在搜索和收集信息上[4])
这就是 AI Research Agent 的用武之地:它帮你在表格里把 AI search 规模化。这篇指南会把你需要知道的内容一次讲清楚——从核心概念到今天就能落地的实际用法。
📌 给赶时间的人:快速总结
这篇文章讲的是:如何用 AI Agents 在表格里规模化 AI search。如果你没时间细看,先看这段:
**问题:**手动做 AI search 很耗时,而且无法规模化。你要为很多家公司逐个搜索,会浪费大量工作时间。
**为什么这是个问题:**传统搜索每次查询约 ≈ 5 分钟(100 次查询约 8.3 小时);AI chatbot 每次查询约 ≈ 3 分钟(100 次查询约 5 小时);两者都需要不断复制粘贴。
**解决方案:**像 Datablist 的 AI Research Agent 这种工具,可以在表格里规模化 AI search,把 100 个调研任务从“几小时”压缩到“15 分钟以内”。
**你会学到什么:**AI search 的关键概念、AI Research Agent 与 chatbot 的区别、常见用例,以及规模化 AI search 的功能与限制。
**为什么用 Datablist 来规模化 AI search:**3 个核心优势
- 能在表格上同时跑 AI search,支持最多 10 万行记录
- 自动把结果回填到你的列表里,彻底告别手动 copy-paste
- 不只靠 LLM,还会结合多种工具(web scraping、API 调用、分页等)完成更复杂的调研任务
本文将覆盖的内容
AI Research Agent 是什么?一文讲透
要真正理解规模化 AI search 能带来什么收益,我们得先理解 AI research agents。为了更直观,我们先把 AI search 和传统搜索做个快速对比。
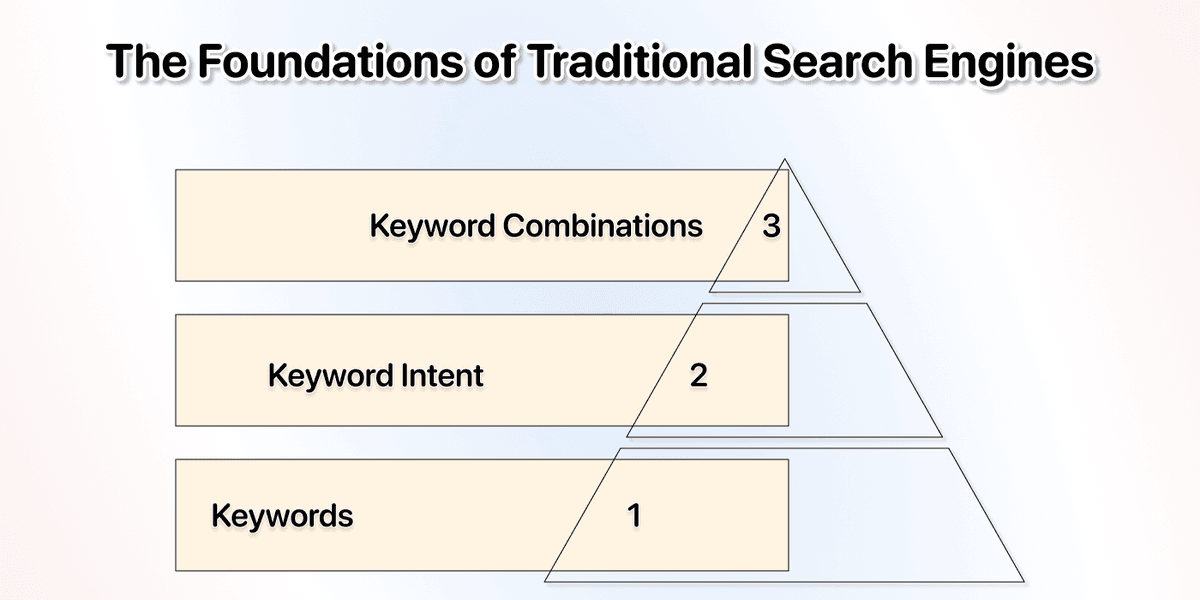
传统搜索
这就是 Google、Bing 等搜索引擎多年来一直在做的事。它过去有用,现在也依然有用。问题在于:搜索引擎并不真正“懂”你想要什么,因为它主要依赖:
- 关键词
- 关键词意图
- 关键词组合
它不会分析你的目标,更不会替你思考;它只是在做“匹配”[1]。
AI search(AI 搜索)
**现在大家基本都在做这件事。**你可以把 AI search 想象成:你在和一个人对话,而对方正在帮你找他原本不知道的答案。
**过去,AI 往往会直接编一个答案;**现在它会去“找”,而且找得还挺好,因为它能:
- 分析你的语气与意图
- 理解你的目标
- 换不同角度尝试
AI search 最爽的一点是:你不需要自己去找、去看、再复制粘贴。AI 会访问大量文章、论文、产品页,然后把你需要的信息提取出来。
AI 搜索引擎示例
- Claude
- Perpelexity
- Google AI Mode
- ChatGPT search
总结一下:用了 AI search,你通常不需要再:
- 重复做很多次查询
- 自己筛选相关页面
- 打开一堆标签页
- 手动提取信息
- 来回访问网页
但 AI search 再好,你还是被限制在“一个 chatbot 一次只能搜一个问题”。

Datablist 的 AI Research Agent:规模化的价值
假设你要查:
- Anthropic AI 是什么时候成立的
- 谁创办的
- 最新产品是什么
- Reddit 上大家对这次发布的反应如何
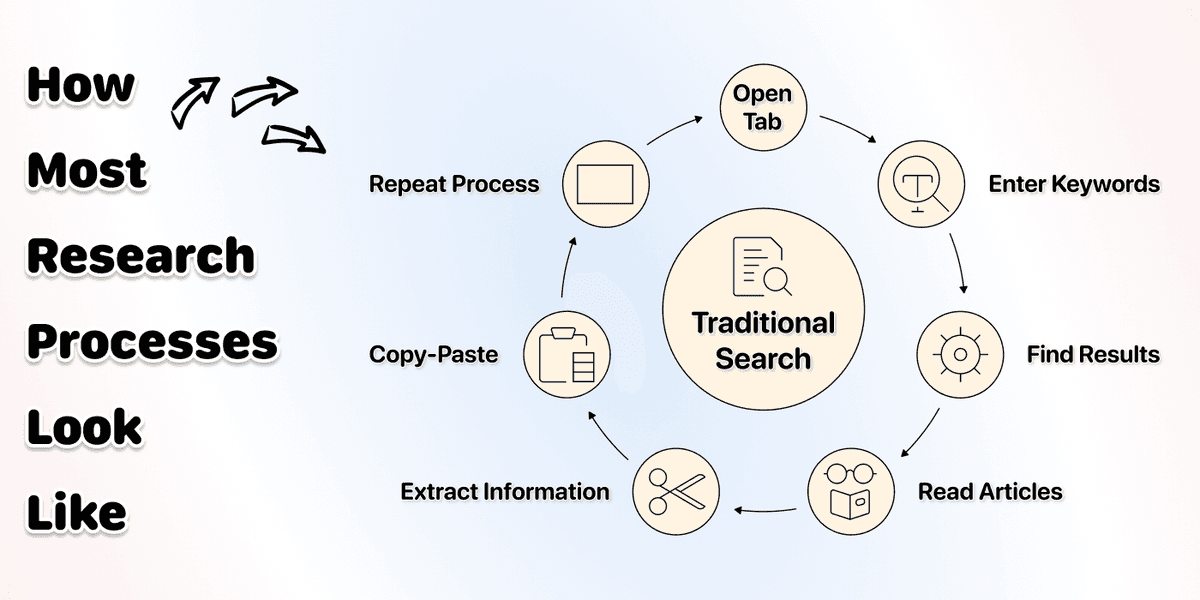
如果用传统搜索引擎,你得:
- 做多次搜索
- 打开好几个标签页
- 读文章/网页
- 再把信息手动复制到表格里
单一公司至少 5 分钟。现在如果你要对 100 家公司做同样的调研,就是 500 分钟 ≈ 8.3 小时。
如果用 chatbot 做 AI search,你通常要:
- 输入 query
- 等它回答
- 把结果复制粘贴进表格
如果 prompt 写得不错,这个流程大约 3 分钟一次。可你要做 100 次,就是 300 分钟 = 5 小时。
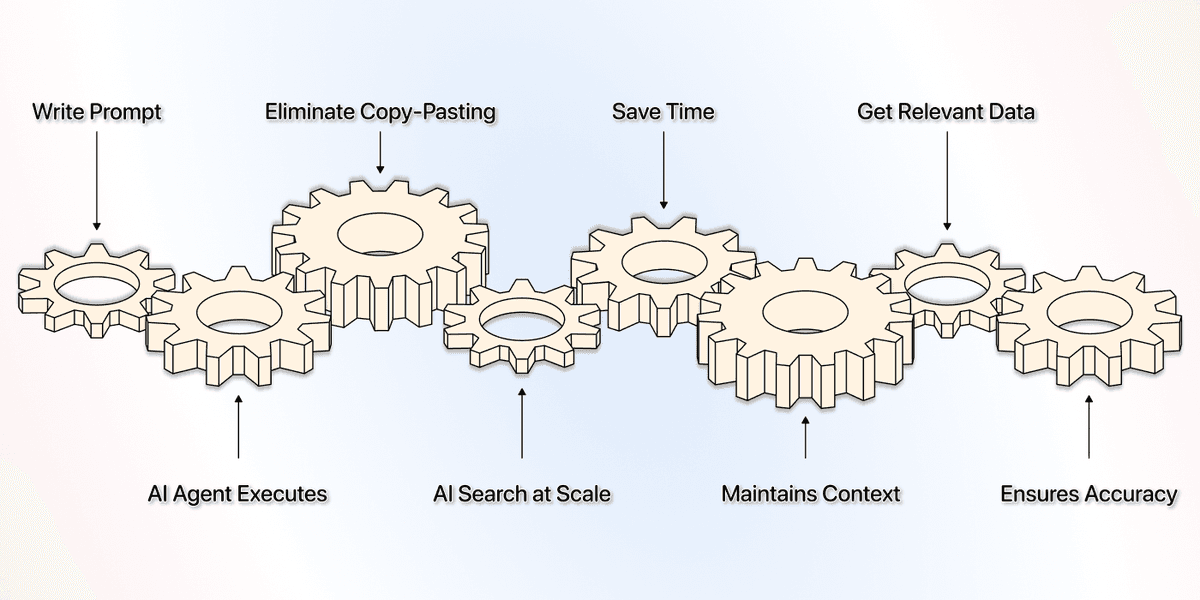
用 Datablist 的 AI Research Agent,这件事大概 15 分钟就能跑完:
- 5 分钟写清晰有效的 prompt
- 10 分钟让 AI Research Agent 执行任务
等于你省下 485 分钟 ≈ 8 小时的手动调研[2]
这之所以能做到,是因为 Datablist 的 AI Research Agent:
- 能在表格上跑 AI search
- 把 copy-paste 这一步直接干掉(自动回填)
- 不会像 chatbot 一样每次都要“重新开始”
本质上,Datablist 的 AI Research Agent 是为规模化 AI search 设计的。
差别非常大,原因是:
- 它把表格里的每一行当作一个全新的 query,节省上下文记忆
- 它可以对同一类问题用同一套 prompt 反复执行,保证准确性与一致性
- 除了 LLM,它还有多种工具可用,能完成更复杂的调研链路
📘 Chatbots 里的 AI search vs Datablist
Claude、ChatGPT 这类 chatbot 的 AI search 能力和 Datablist 的差距其实不在“聪不聪明”,因为它们都不只是传统 LLM。
真正的关键差异是:Datablist 的 AI Research Agent 能把同一个调研任务跑在最多 10 万行记录的列表上;而 chatbot 仍然一次只能做一个搜索。
Datablist 的 AI Research Agent = 瑞士军刀
在 Datablist 里,AI Research Agent 不只是搜索工具;它更像一台多功能机器,专门用来规模化 AI search。你可以把它理解成:让 Claude/Perplexity/ChatGPT “住进你的表格”,然后它能:
- 搜索 Google 和 Google News
- 访问网页
- 做分页(pagination)
- 执行多步骤任务
- 进行 API 调用
- 提取信息
- ……
更关键的是:它会根据你的 prompt 判断每一步该用什么工具,这也是 Datablist 的 AI Research Agent 特别适合在列表上做 AI search 的原因。
效果就像有一个人类研究员,只是更快、更准、更一致。
AI Processors vs AI Research Agent:别搞混
为了让你更清楚 AI Research Agent 的定位,我再用一个对照概念解释:AI processor。
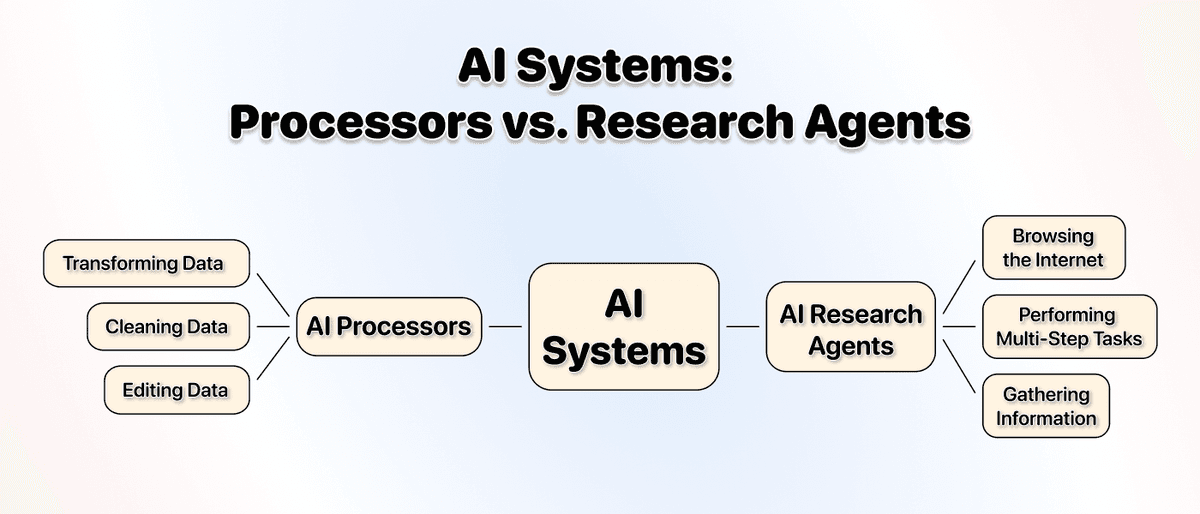
AI Processors
很多人都用过 Excel 或 Google Sheets 上的 AI 插件。这类工具通常是在受控环境里调用 LLM API(比如你的表格)。
顾名思义,它更像“处理器”,主要优化的是:在不离开表格的前提下处理你已有的数据。常见用途是:
- 数据转换
- 数据清洗
- 数据编辑
AI Research Agents
和 AI processor 不同,Datablist 这类 AI research agent 是带约束的自治系统(autonomous system),设计目标是与外部世界交互[3]。它同样用 LLM,但会搭配更多工具,因此可以:
- 浏览互联网
- 执行多步骤任务
- 从不同来源采集信息
- ……更多
💡 一句话讲明白
AI Research Agent:负责“去外部世界做调研,把数据带回来”(而且能规模化)。
AI processor:负责“在你已有的数据里做加工处理”。
为什么你需要 AI Research Agent
很多人第一次用 AI Research Agent 才意识到它有多重要。所以我用目前最常见的场景来解释:用它来构建 lead generation 的列表。
真实问题
在 lead generation 里,大多数人都会遇到两个问题:
- 回复率太低
- 竞争太激烈
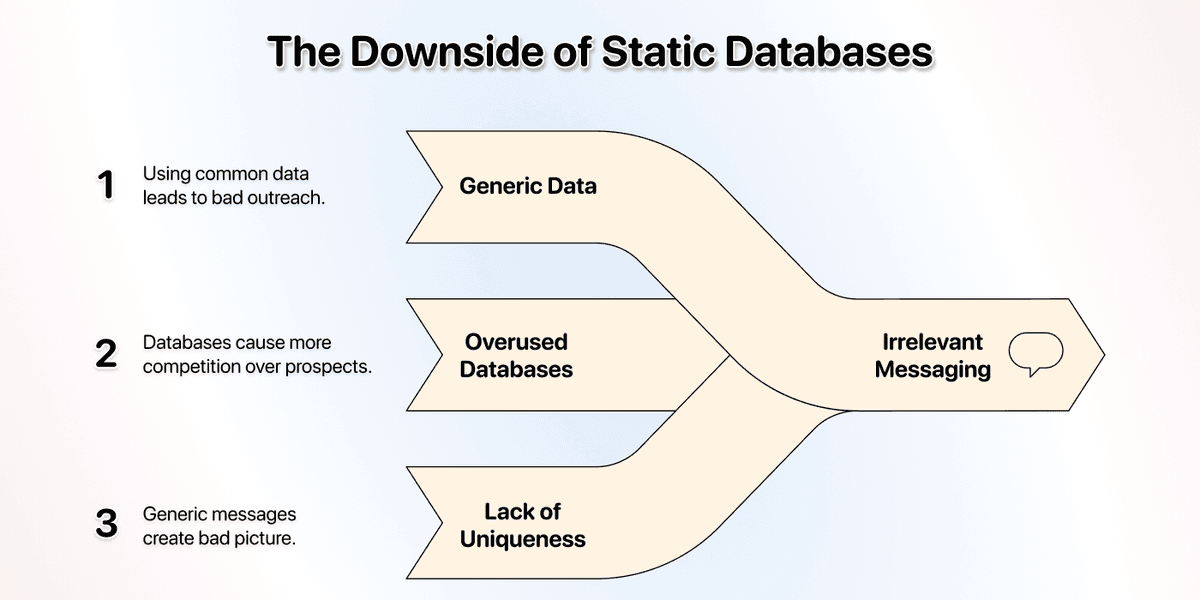
原因是:大家都想要 leads,大家都在做 cold outreach。很多人没意识到:真正决定回复率的是相关性(relevance),不是尴尬的“伪个性化”。而相关性无法靠通用数据实现,这意味着:
↳ 当你只用 B2B 数据库 + 基础 scraper
↳↳ 你拿到的是“所有人都拿到的一样的数据”
↳↳↳ 你在同一池子里跟所有人抢同一批 prospects
↳↳↳↳ 你用的就是大家都在用的数据
这样一来,你的消息默认就是“不相关”的。
解决思路
解决问题通常从理解原因开始。既然原因讲清楚了,那我们直接说怎么让你的信息更相关,从而:
- 拿到更多回复
- 从竞争中跳出来
方法其实很简单:先把“不相关”这个问题修掉。怎么修?
↳ 规模化 AI search
↳↳ 拿到真正有用的数据
↳↳↳ 在收件箱里变得更突出
很多人已经意识到这点,所以他们会人工调研 prospect,然后手写 hyper-personalized 文案。但 其实可以更轻松、更快。

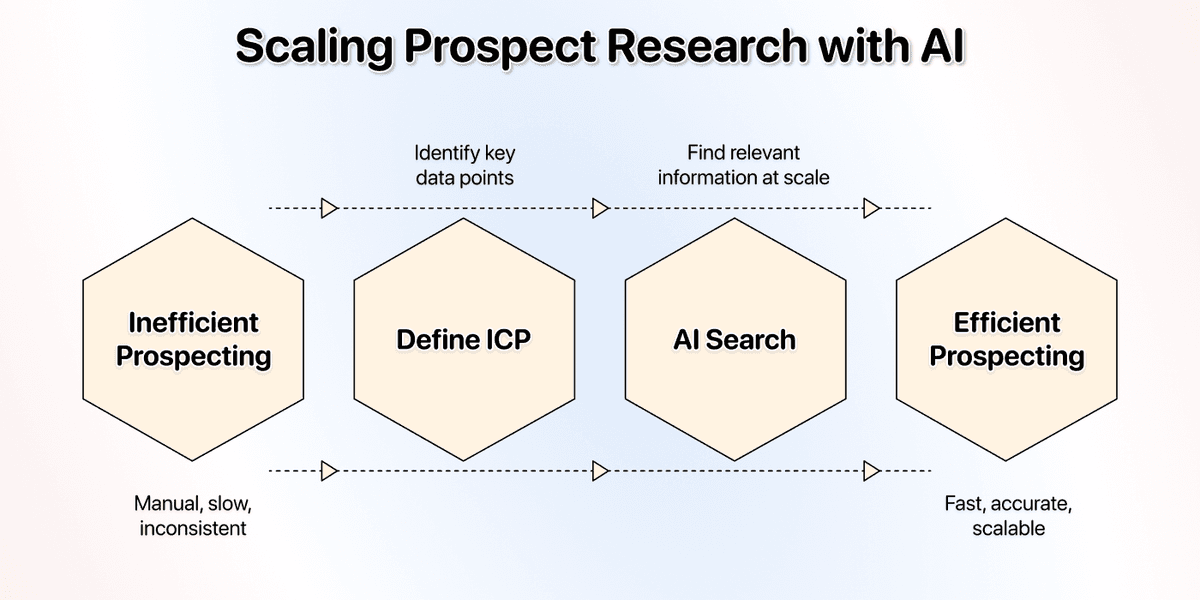
规模化 Prospect Research
**换个角度想:**你的 prospects 其实没那么“独特”,我的也一样。因为我们筛选和判断一个 prospect 时,看的往往是同一组数据点——也就是用来做 ICP definition 的那些特征。
而能定义 ICP 的数据点,通常也是你写出“相关文案”的数据点。所以只要这些数据来自定制化调研,而不是数据库,你就赢了。
如果你手上有成千上万家公司要触达,最该做的就是:把 AI search 规模化,批量找到相关且准确的信息。
**当然,**规模化 AI search 不只对 lead list building 有用;下面这部分会给你更多灵感。
AI Research Agent 能用来做什么?
AI Research Agent 的用途几乎没有上限:本质上,你能用它做所有 AI search 能做的事——只不过是规模化。先从最常见、最有效的用例讲起。
P.S. Datablist 也提供一些预置模板,让你可以尽快上手。
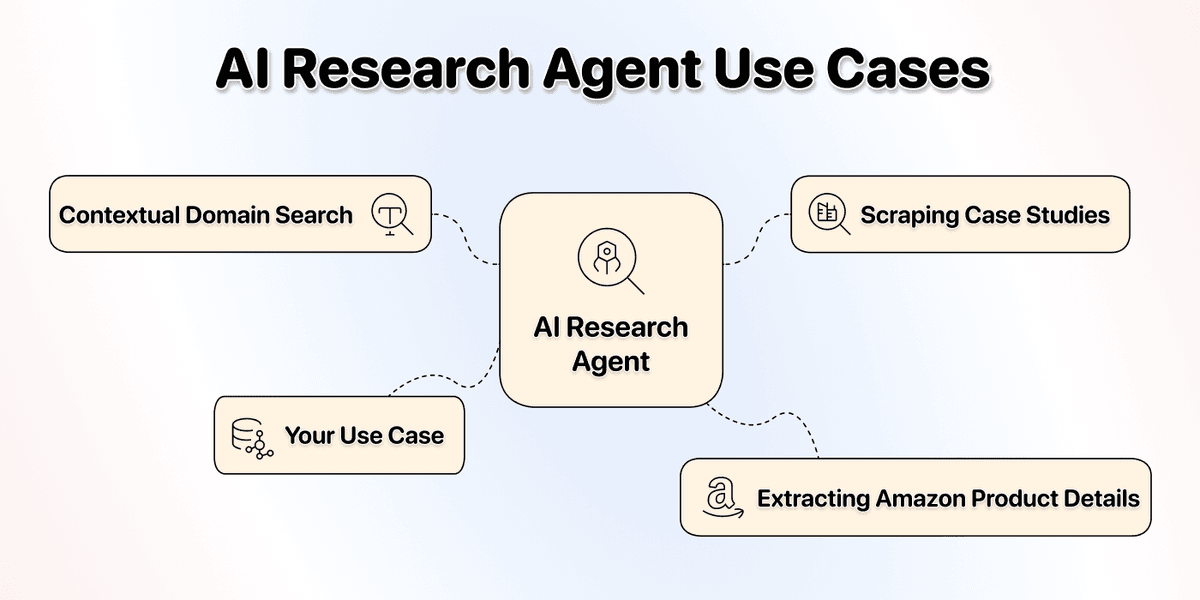
- **带上下文的域名搜索(Contextual Domain Search):**有时只有公司名根本找不到正确官网。比如 “Apollo LLC” 或 “Pioneer GmbH” 这种名字,可能对应成千上万家公司。你给出行业、城市等上下文后,AI Research Agent 就能像人一样进行更精准的定位,找出正确 domain。
- **批量抓取 Case Studies:**AI Research Agent 可以批量访问公司官网,找到 case studies / portfolio 页面,提取客户名、项目细节等关键信息。
- **提取 Amazon 商品详情:**如果你有一组 Amazon 商品列表,可以用 Datablist 的 AI Research Agent 把商品详情批量提取出来。
上面这些事,如果不能规模化 AI search,靠人工做都会非常耗时。如果你想落地这些用例,这里有对应的 how-to:
- How to find domains from a company name
- How to scrape case studies
- How to extract products from Amazon
来自客户的自定义用法
除了模板,我们的客户也会用 AI Research Agent 做各种定制化调研任务。真正的限制只有想象力。下面这些用法我很喜欢:
- **发现最新研究论文:**找到某公司或研究机构最新发布的论文/出版物链接。
- **找到 LinkedIn 上没有列出的员工:**通过官网、新闻稿、会议讲者列表等渠道发现团队成员。
- **识别“首次担任 CEO”的管理者:**调研其职业路径,判断是不是第一次当 CEO。
- **判断医院的所有权结构:**确认医疗机构是私立还是公立/上市体系。
- **追踪近期新闻提及:**判断公司最近是否出现在新闻报道、press release 或行业媒体中。

实际应用看完了,我们切换到更“产品化”的部分:AI Research Agent 的功能与限制。
💡 限制只有想象力
文中的例子只是 AI Research Agent 能力的一小部分。如果你有想法,我们也可以帮你一起把 prompt 打磨出来。
AI Research Agent 功能与限制全解析
知道一个工具“能做什么”和“做不了什么”,才能真正用好它。下面用最直接的方式,讲清 Datablist 的 AI Research Agent 的能力边界。
它能做什么
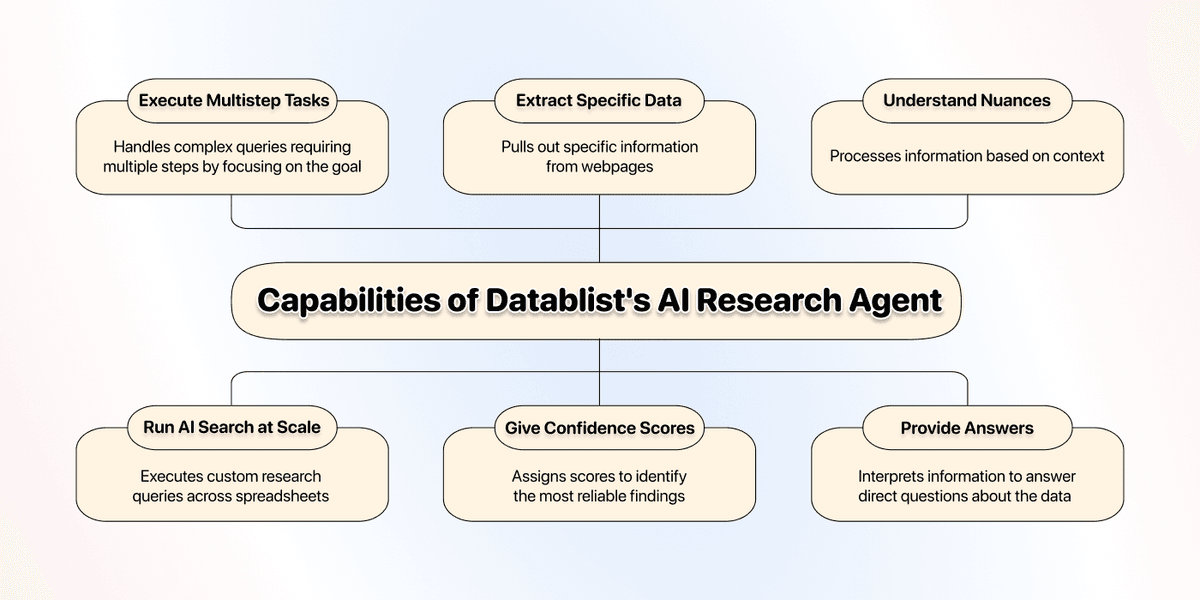
Datablist 的 AI Research Agent 目标是复刻并自动化人类研究员的工作。比如它可以:
- **规模化运行 AI Search:**对整张表执行自定义调研 query。
- **评估信息质量:**它会判断找到的信息是否相关,过滤噪音,只保留有价值内容。
- **提供置信度分数:**每条结果都会给 0-100 的 confidence score,帮你快速识别哪些结论更可靠(尤其适合复杂调研)。
- **执行多步骤任务:**你可以给它一个需要多步完成的目标,比如“找到 careers 页面,筛选 marketing 岗位,提取职位名称,再总结 JD”。
- **理解上下文:**它不只是关键词匹配;它能理解你提供的上下文,从而区分同名公司,或找到网页里没有直接写明但能推断的信息。
- **提取指定字段:**你可以让它从网页中抽取非常具体的信息,比如 About Us 里的 mission statement,或 Amazon 商品页的某个参数。
- **输出面向业务的问题答案:**不仅返回原始数据,它还能综合信息回答直接问题,比如“这家公司在德国是否有 manufacturing plant?”
任何工具都有边界。了解限制,才能建立合理预期,并设计更顺的 workflow。
- **无法抓取登录后的内容:**凡是需要用户名密码的内容,它都访问不了,比如私密社媒资料、会员论坛、公司内部后台。
- **少数网站可能无法访问:**部分网站有很强的反自动化机制,会阻挡 scraper/自动化工具。AI Research Agent 能覆盖绝大多数公开网页,但确实可能被少量“防护很强”的站点拦住。
- **无法保证 100% 准确:**它整体准确度很高,也提供置信度分数,但毕竟还是 AI;当任务链路超过 5-6 步时,偶尔可能误读信息或漏掉细微点。
- **无法与表单或 CAPTCHA 交互:**它不能填写表单、提交数据,也无法解决 CAPTCHA。它擅长“读与提取”,不做交互式网页操作。
既然在表格里规模化 AI search 已经可行了,为什么还要继续手动搜?
手动调研会成为瓶颈:吞噬生产力,还带来不一致的结果。
AI Research Agents 解决的就是这个问题:让你的数据采集进入自动驾驶模式。所以,只要你需要的信息不是那种“每次都必须人类核验的高度细腻判断”,那你大概率都应该用 AI Agent 来做规模化调研。
当 AI Research Agents 能执行复杂的多步骤任务时,你就能:
- **拿到真正有价值的数据:**在成千上万行数据上规模化 AI search
- **节省成百上千小时:**把过去要做几周的人工工作自动化
- **Personalization:**采集独特数据点,让你的 outreach 很难被忽略
- **构建更好的 Lead Lists:**用数据库给不了的标准去 qualify prospects
- **从任何地方提取数据:**用自然语言批量抓取网站信息,而不是写代码
你的竞争对手不睡觉,我们的竞争对手也不睡觉,我们也不睡
工具都在那儿了;接下来拼的就是谁用得更好。

Scaling AI Search 常见问题(FAQ)
使用 AI Research Agent 会很难吗?
一点也不难。用 Datablist 这类平台,你不需要任何特殊技能,只要能把“你想要什么”描述清楚即可。我们也提供常见用例的预置模板,比如查 case studies 或做 contextual domain search。对于自定义任务,你只需要写一个简单、口语化的 prompt,把需求讲明白。
AI Research Agent 能帮我找联系方式吗?
不能。AI Research Agent 主要用于网页调研和从网站提取数据。如果你要找 email、手机号这类 contact information,Datablist 提供专门的 enrichment 工具,比如 Waterfall Email Finder(会把多个数据供应商串联起来,以最大化覆盖率)。
AI Research Agent 和 ChatGPT 有什么不同?
两者都用大语言模型,但用途不同。ChatGPT 是对话式 AI,主要基于训练数据回答问题;AI Research Agent 是功能型工具,能够主动浏览实时互联网、访问具体网站,并在当下提取最新信息来完成任务。
AI Research Agent 到底是什么?
AI Research Agent 是一种自治系统:它能理解目标、浏览互联网,并执行多步骤调研来查找、提取和综合信息。它不同于简单 web scraper 的地方在于:它能理解上下文,并根据目标动态调整策略。
怎么写一个好的 AI Research Agent prompt?
最有效的 prompt 往往清晰、具体、并提供上下文。你可以用下面这个简单框架:
- **说明目标:**清楚告诉它要找什么。
- **提供上下文:**给起点,比如公司官网链接。
- **设置约束:**告诉它要做什么、不要做什么(例如“只输出项目名称,不要开场白或解释”)。
- **定义输出格式:**明确你希望数据以什么格式回填。
怎么在列表上执行 AI search?
要在列表上做 AI search,你需要像 Datablist 这样的 AI Research Agent,它能把类似 ChatGPT 的搜索能力跑在表格上。你把数据上传,写一个 prompt 说明要找什么,agent 就会对每一行自动执行同一个调研 query。这样就不需要手动复制粘贴,也能把类似 Perplexity 的搜索规模化到成千上万条记录。
有没有办法把 AI search 规模化?
有。用 Datablist 的 AI Research Agents 就可以在表格里规模化 AI search。你不再需要在 chatbot 里一次搜一个问题,因为这些 agents 能把同一个“带上下文的调研 query”跑在整张列表上,最多支持 10 万条记录。原本要花好几小时手动做的 ChatGPT 搜索,现在可以变成几分钟、并且结果更一致的自动化调研。
如何在表格里跑 Perplexity-Like Search?
你可以用 Datablist 的 AI Research Agent 在表格里实现 Perplexity-like search:它会浏览互联网、访问网页,并对每一行数据自动提取所需信息。你只需要提供数据,以及一个清晰的 prompt 描述要找什么。agent 会把每一行当作独立的上下文搜索,输出一致结果,无需人工干预。