
Sainsbury's 并没有提供公开的商品 API。这也是为什么大多数想抓取 Sainsbury's 商品数据的团队,要么花 £2000+ 找 freelancer 定制,要么接一个 Apify scraper,结果几天后就失效。
但很多人不知道,其实还有第三条路: AI scraping。它像人一样“读页面”,所以同一套配置既可以抓 Sainsbury's 的分类页、品牌页,也能抓促销页,而且能扛住那些会让传统 scraper 失效的页面改版。
这篇指南会带你完整走一遍流程:为什么定制一个 Sainsbury's 商品 scraper 并不划算、哪些 Sainsbury's 页面能拿到最干净的数据,以及如何使用 Datablist's AI Scraping Agent 一步步完成抓取。
📌 给赶时间读者的总结
这篇文章会教你如何使用 Datablist's AI Scraping Agent 抓取 Sainsbury's 的商品数据。
问题: Sainsbury's 没有公开商品 API,现成 scraper 往往在页面改版后几周内失效,而定制开发通常要 £2000+,后续还要持续维护。
解决方案: 使用 Datablist's AI Scraping Agent,只要一条 URL 加上自然语言 prompt,就能抓取 Sainsbury's 商品。
你将学到:
- 为什么定制 Sainsbury's scraper 是个“烧钱坑”
- 哪些 Sainsbury's 页面最适合抓取、数据最干净
- 如何用 5 个步骤在 10 分钟内抓完任意一个 Sainsbury's 分类页
为什么选 Datablist:
- AI scraping 理解的是页面语义,不是 HTML,所以 Sainsbury's 页面改版也不容易导致抓取失败
- 自动处理分页(单次最多 5,000 页)
- 无需写代码、无需 API key,只要一个 Sainsbury's URL 和一句 prompt
本文内容一览
- 为什么定制 Sainsbury's Scraper 不划算
- 如何用 Datablist's AI Agent 抓取 Sainsbury's 商品
- 抓取 Sainsbury's 的完整步骤
- 关于抓取 Sainsbury's 的常见问题
为什么定制 Sainsbury's Scraper 不划算
如果你曾想过自己做一个 Sainsbury's scraper,那么在你真正开始花钱之前,先看看下面这三个原因。
成本很高
一个稳定可用的 Sainsbury's scraper,绝不是周末随手做完的小项目。sainsburys.co.uk 的商品列表是通过 JavaScript 动态加载的,分类页分页可能多达数百页,而且页面结构更新也相当频繁,所以任何基于固定规则的 scraper 都需要不断修修补补。
大多数团队通常会尝试以下几种方式,而每条路最后都会遇到问题:
- 找 freelance developer 定制开发:首次开发 £2000+,之后 Sainsbury's 每次改商品列表结构,你都得继续付维护费
- 购买 Apify 或 GitHub 上现成的 Sainsbury's 商品 scraper:第一天能用,但下一次页面结构变动后,往往几周内就失效
- 自己用 Puppeteer 或 Playwright 写脚本:Sainsbury's 的分页、JavaScript 渲染,以及不完全统一的商品卡片结构,很快就会把脚本搞崩
如果你只是想抓一次快照数据,找 freelancer 也许还能接受。但如果你需要持续拿到最新的 Sainsbury's 数据(比如价格监控、FMCG 分析、retail arbitrage),维护成本会月复一月不断累积。
开发周期很慢
即使是经验很强的开发者,要做一个干净、稳定的 Sainsbury's scraper,通常也得花上几周时间。他们需要梳理各类分类页、处理渲染后的 HTML、为分页商品列表写逻辑,还要考虑像 Sainsbury's 对促销价返回 “N/A” 或某些商品受年龄限制而被隐藏等情况。
Datablist's AI Scraping Agent 直接跳过了这整个开发阶段。你只需要粘贴一个 Sainsbury's URL,10 分钟内就能拿到结构化商品数据。 不需要写需求文档,不需要来回讨论 edge cases,也不用等 v2 才能真正可用。
很容易频繁失效
这才是真正的隐性成本。Sainsbury's 经常会更新商品列表页面。每次他们上线新的分类模板,或者调整价格元素的位置,你的定制 Sainsbury's scraper 就可能立刻失效。
到头来你只剩两个选择:要么再付钱找开发修,要么自己花半天时间排查问题。
AI scraping 则绕开了这个问题。因为 AI Agent 读取的是页面语义,而不是死板的 HTML 结构,即使 Sainsbury's 换了价格元素外层的 CSS class,价格依然还是价格。
💡 核心区别
传统 scraper 遵循的是规则:比如“找到 class 为 .product-price 的元素并提取文本”。AI scraper 遵循的是语义:比如“找出这个 Sainsbury's 页面上的商品价格”。
这就是为什么今天能用在 Sainsbury's 上的同一套配置,在下个月 Sainsbury's 重排商品列表之后通常依然能工作;也正因为如此,它也能很自然地迁移到 Tesco、Morrisons 和 Asda,而不需要针对每个网站单独写代码。
如何用 Datablist's AI Agent 抓取 Sainsbury's 商品
在开始实操之前,先简单说明一下 AI Scraping Agent 到底是什么、哪些 Sainsbury's 页面更容易抓到干净数据、你可以提取哪些字段,以及它的边界在哪里。
什么是 Datablist's AI Scraping Agent?
Datablist 是一个 workflow automation platform,适合用来构建 lead list、做 data enrichment,以及运行各类 scraping workflow。Datablist 内置了 60 多种不同的数据源和 enrichments,其中 AI Scraping Agent 就是专门用来从零售网站提取商品数据的工具。
这个 agent 的工作方式,本质上结合了三部分: 目标 URL、描述提取内容的 prompt,以及像人一样阅读页面的语言模型。
抓取 Sainsbury's 时,你甚至不需要自己写 prompt。Datablist 提供了一个现成的 Retail Product Scraper template,会预先配置好 prompt 和输出列。你只要贴入 Sainsbury's 的 URL,剩下的模板会自动处理。
这个 agent 在处理 Sainsbury's 时,特别有三个关键点:
- 默认使用 OpenAI GPT 4.1 mini,这是目前 AI scraping 场景里性价比很高的 LLM
- 支持 Render HTML,这对 Sainsbury's 很关键,因为它的商品列表是通过 JavaScript 加载的
- 支持 自动分页,单次运行最多可遍历 5,000 页
这也是为什么同样的配置几乎不用修改,就能迁移到其他英国超市网站。同一个 agent、同一个 template、同一套设置,也适用于 Tesco、Morrisons、Asda、Waitrose 和 Aldi。唯一变化的只是 URL。
最重要的一条规则:只抓品牌页和分类页
一定要抓取 Sainsbury's 的分类页或品牌页,不要抓首页,也不要抓 “all products” 这类总列表页面。超大列表很容易超出 AI Agent 的 context window,运行会在中途停止,而且无法续跑,credits 也会被白白消耗。
AI Agent 在 Sainsbury's 上比较适合处理的页面:
- ✅ sainsburys.co.uk/gol-ui/groceries/... 下的分类页
- ✅ 品牌页(某个品牌/制造商的商品列表)
- ✅ deals 或 offers 页面
建议避免的页面:
- ❌ Sainsbury's 首页
- ❌ “All products” 或全站搜索结果页
- ❌ 一次性无限滚动加载上千商品的页面
你可以从 Sainsbury's 抓到哪些数据
一次 Sainsbury's 抓取任务,通常可以提取出做价格监控、竞品研究,或者补充现有商品目录所需的全部关键字段,包括 data enrichment 场景里常用的数据:
- Product Name:Sainsbury's 网站上展示的完整商品名称
- Product URL:指向 sainsburys.co.uk 商品详情页的直接链接
- Brand Name:商品所属品牌或制造商
- Price:当前英镑价格,包含 £ 符号
- Sale Price:如果有促销则显示折扣价;没有活动时返回 “N/A”
- Product Category:商品所在分类或货架类别
- Availability:是否有货,如 in stock、out of stock 或 limited
- Rating:如果 Sainsbury's 页面展示了评分,则可提取
- Image URL:主商品图片的直接链接
- SKU:Sainsbury's 内部商品 ID
在开始运行前,建议先明确自己真正需要哪些输出字段,这样导出的数据只会保留你后续会用到的列。
抓取 Sainsbury's 的完整步骤
完整的 Sainsbury's 抓取流程一共 5 步。开始前,请先准备好:
- 一个 Sainsbury's 分类页或品牌页 URL(不是首页)
- 大致清楚你实际需要哪些商品字段
第 1 步:注册并创建 Collection
首先,注册 Datablist.com。

然后,创建一个 New Collection。
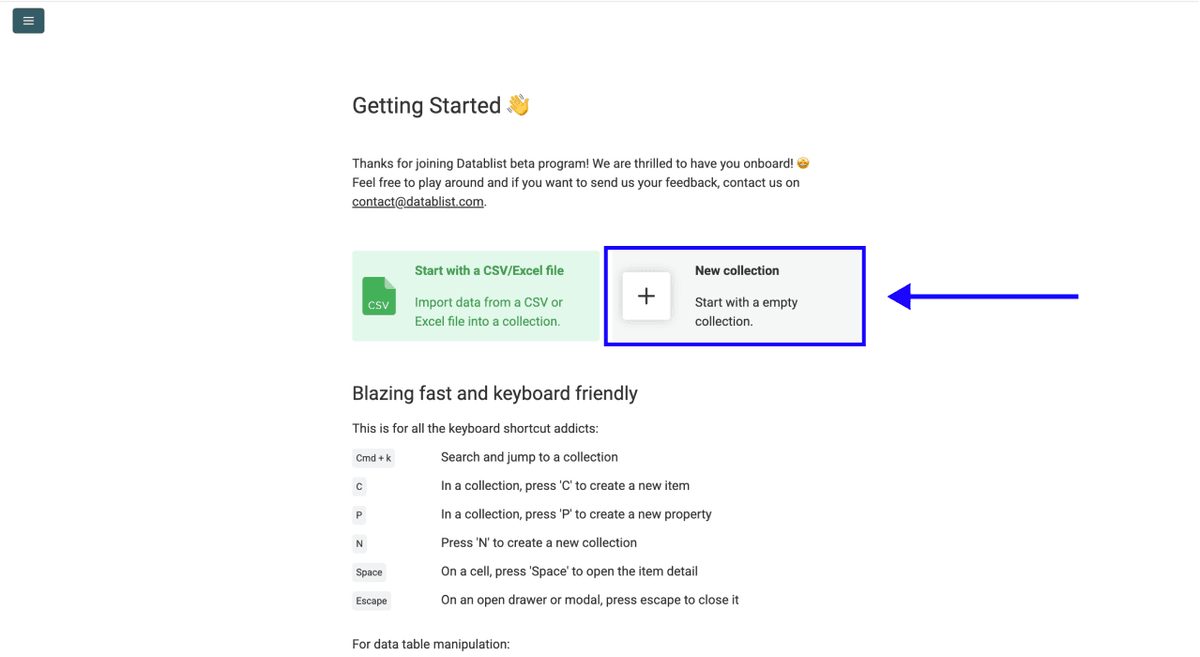
第 2 步:进入 AI Scraping Agent
- 点击 See all sources
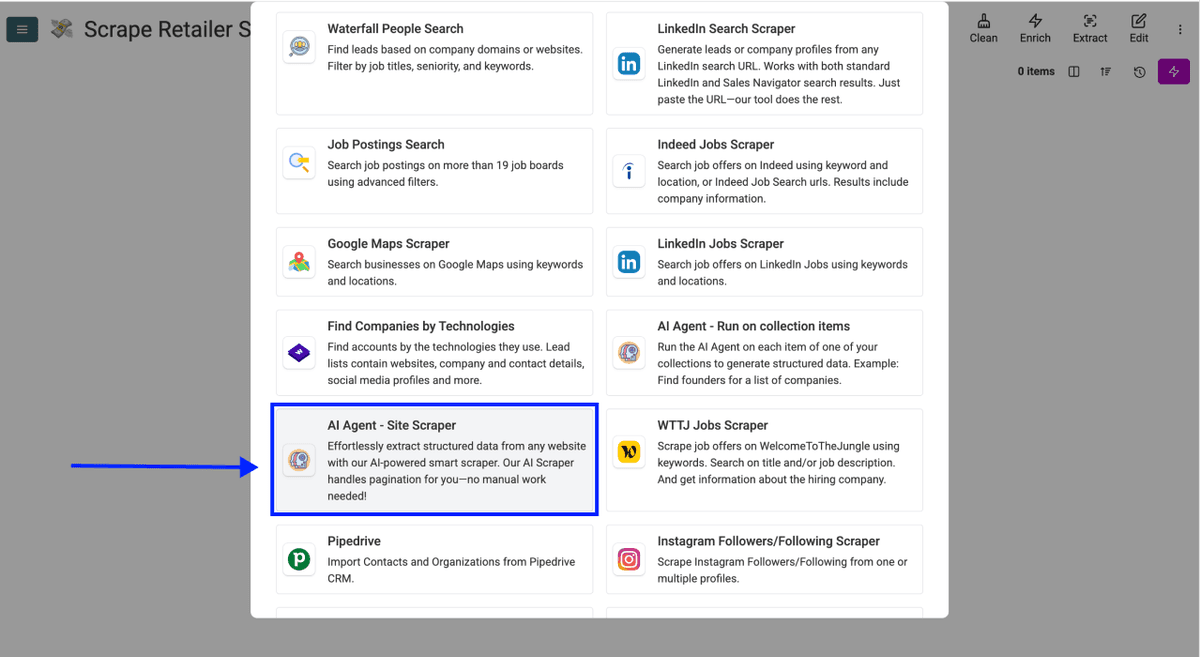
- 向下滚动,选择 AI Scraping Agent (Site Scraper)。
现在你会看到 source 的配置界面,大致如下:
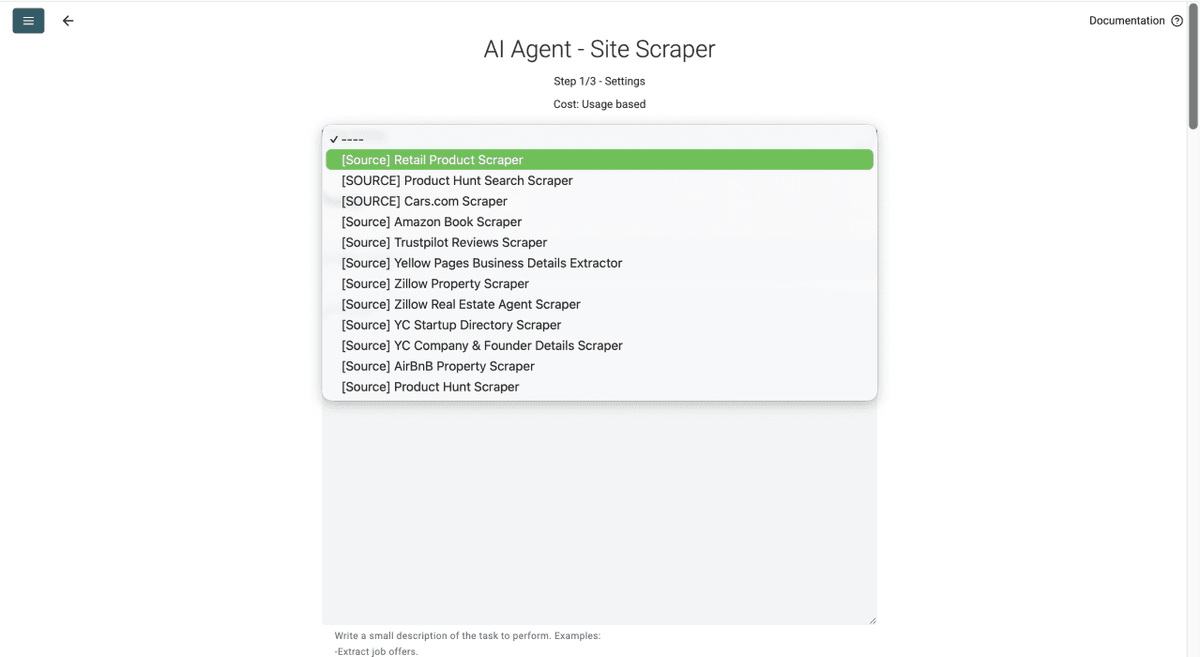
第 3 步:选择 Retail Product Scraper Template 并粘贴 Sainsbury's URL
- 点击 Template Drop-Down,选择 “Retail Product Scraper”
- 将你的 Sainsbury's 分类页 URL 粘贴到 URL 字段,例如:
https://www.sainsburys.co.uk/gol-ui/groceries/frozen/fish-and-seafood/c:1019924/opt/page:2
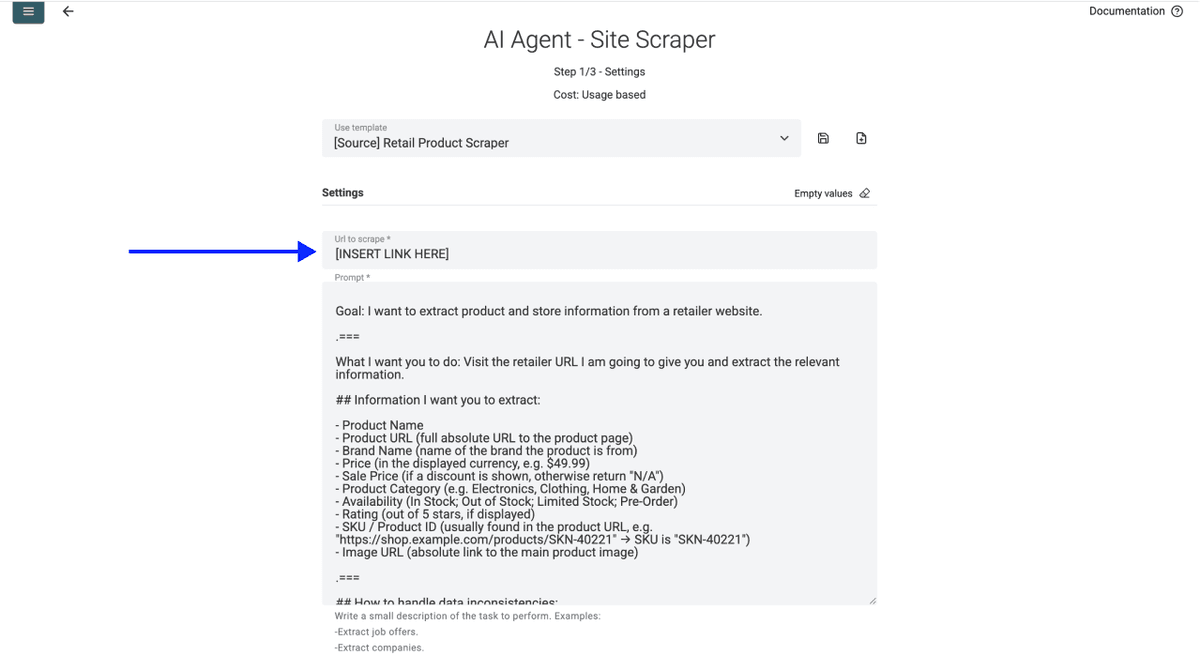
❗️ 只用品牌页和分类页(再次提醒)
不要粘贴 Sainsbury's 首页,也不要用 “all products” 这类 URL。超大列表会超出 AI Agent 的 context window。抓 Sainsbury's 时,最好按分类逐个抓取。
- 设置要抓取的页数(Sainsbury's 通常每页显示约 60 个商品,因此一个 200 个商品的分类页,大概需要抓 3 到 4 页)
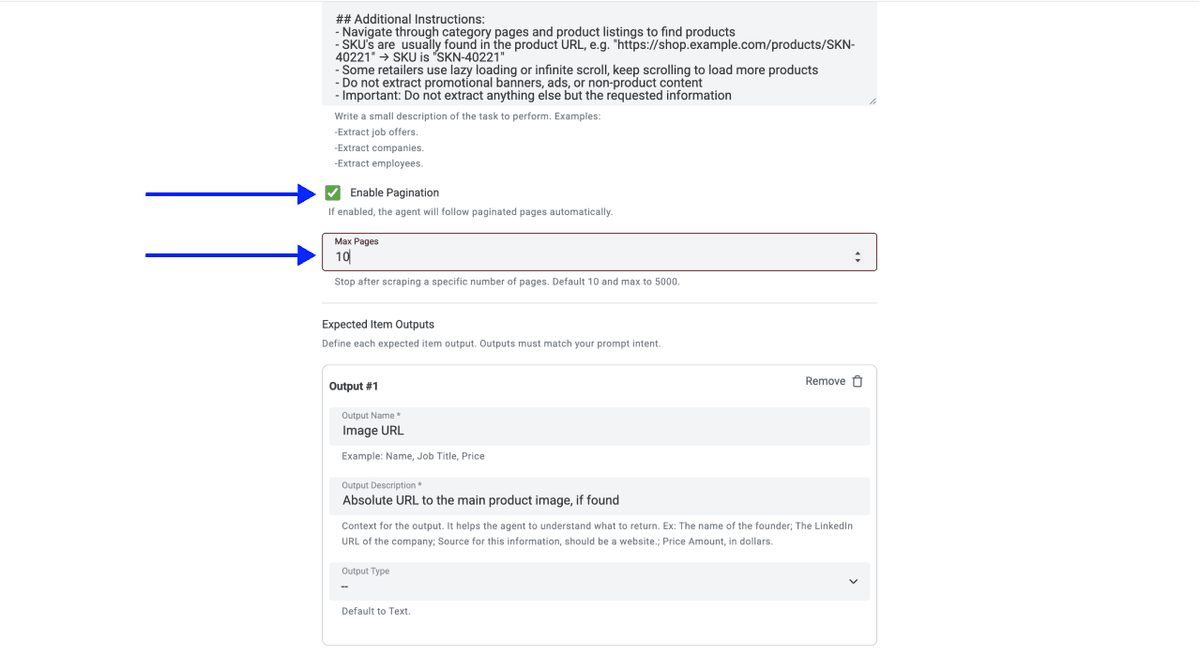
- 向下滚动并点击 Continue
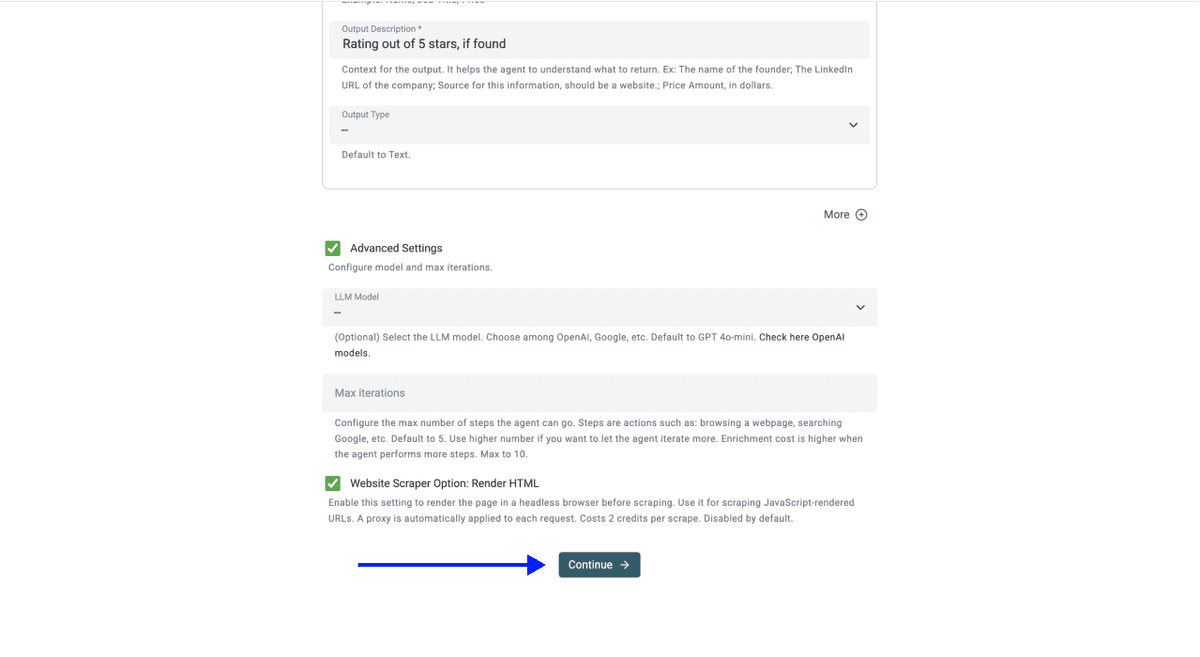
💡 点击 Continue 前,先检查 Advanced Settings
请确保以下选项已开启:
- LLM:OpenAI GPT 4.1 mini(性能与价格比较均衡)
- Max Iterations:10
- Website Scraper Option: Render HTML(对 Sainsbury's 很关键,因为站点通过 JavaScript 动态加载商品列表)
第 4 步:配置输出字段
Datablist 会自动创建输出字段。
如果某些字段你不需要,可以点击对应的 X Icons 删除(例如,如果你只是想做 Sainsbury's 价格监控,就可以移除 Rating)。
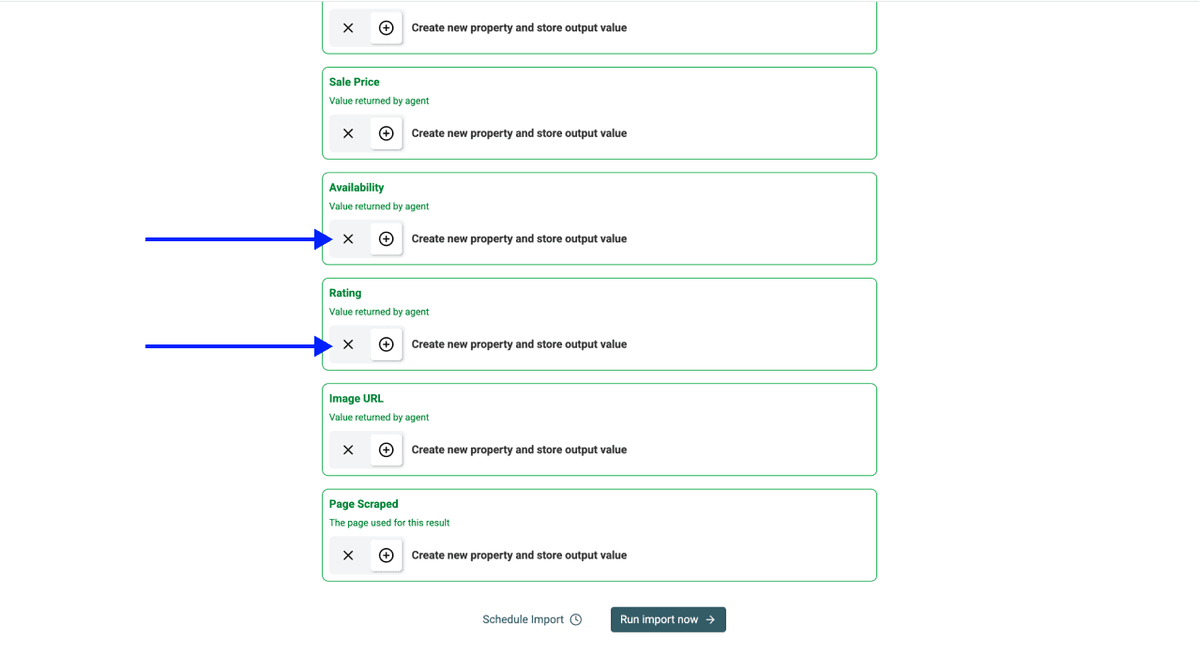
第 5 步:运行
确认输出字段无误后,点击 Run Import Now,开始抓取 Sainsbury's 数据。
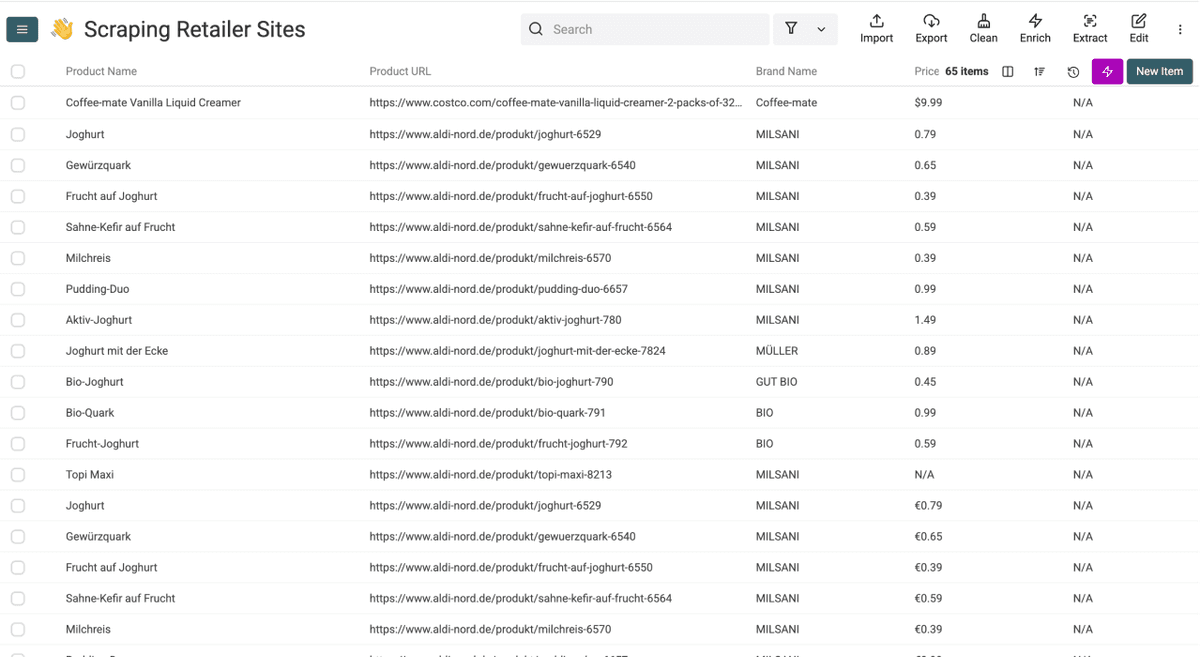
几分钟后,你会看到类似下面这样的 Sainsbury's 抓取结果。接下来,你还可以借助 Datablist 的 workflow automation features 对数据进行清洗、去重和导出。
💡 重复抓取 Sainsbury's 时,避免重复数据
如果你后续还打算再次抓取同一个 Sainsbury's 分类页:
- 选择一个唯一标识列(通常 Product URL 最合适)
- 点击列标题 → Rename - Settings - Delete
- 勾选:Do not allow duplicate values
- 点击 Save Property
如果你还会把 Tesco、Morrisons 和 Asda 的数据也汇总到同一个文件中,可以参考我们这篇关于 removing duplicates from CSV files 的指南,处理跨零售商去重问题。
Datablist’s AI Agent 也适用于其他零售网站
这套 Sainsbury's 抓取方案并不是只适用于 Sainsbury's。我们测试过的英国主流超市网站,基本都可以用同一个 AI Scraping Agent 和同一个 Retail Product Scraper template。你只需要换一下 URL 即可。
如果你也想抓取其他零售商的商品数据,可以继续参考下面这些分步指南:
- 抓取 Morrisons 商品 👈🏽
- 抓取 Tesco 商品 👈🏽
- 抓取 Asda 商品 👈🏽
核心结论总结
- 定制一个 Sainsbury's 商品 scraper,通常就是个烧钱坑。 初始开发成本往往要 £2000+,后续维护还要额外付费,而且 Sainsbury's 页面结构更新后很容易再次失效。
- AI scraping 理解的是语义,不是 HTML。 所以即使商品列表结构变化,同一套配置通常仍能继续抓取 Sainsbury's 商品;同时也能无缝迁移到 Tesco、Morrisons 和 Asda,而不需要为每个网站单独写代码。
- 一定要抓品牌页或分类页,不要抓首页。 超大列表容易超出 agent 的 context window,浪费本次运行机会。
- 整套配置不到 5 分钟就能完成。 选择 template、粘贴 URL、确认输出字段,然后直接运行。
关于抓取 Sainsbury's 的常见问题
抓取 Sainsbury's 商品要花多少钱?
Datablist's AI Agent 采用 按使用量计费的 credit system。每次抓取 Sainsbury's 的成本,取决于 agent 实际处理的商品数量和页面数量。Datablist 套餐起价为 $25/月,包含 5,000 个免费 credits;额外充值包则从 $20 / 20,000 credits 起,大额购买最高可享 35% 折扣。
抓完整个 Sainsbury's 商品目录需要多久?
大多数包含 50 到 200 个商品的 Sainsbury's 分类页,通常可以在 5 到 10 分钟内抓完。如果是跨多个分页分类页的大任务(500+ 商品),通常需要 10 到 20 分钟。首次配置会额外增加 2 到 3 分钟。
为什么应该抓 Sainsbury's 分类页,而不是 “All Products”?
Sainsbury's 的 “all products” 页面会在一个渲染页面里加载数千个商品,这很容易超出 AI Agent 的 context window。结果就是 agent 在中途停止,而且没有续跑选项,前面消耗掉的运行和 credits 也就浪费了。分类页和品牌页的数据量更可控,抓取更稳定;如果你之后需要全量覆盖,也可以再把多个分类结果合并到同一个 collection 中。
可以抓取 Sainsbury's 的促销价和优惠信息吗?
可以。Retail Product Scraper template 内置了 Sale Price 输出字段。当 Sainsbury's 有促销活动时,会返回折扣价;如果当前没有优惠,字段会显示 “N/A”。这实际上也很有用,因为你可以据此快速筛选哪些分类当前在做促销。
在英国抓取 Sainsbury's 合法吗?
抓取公开可见的 Sainsbury's 商品数据(如名称、价格、库存状态),通常在英国法律框架下是允许的,原则上与抓取其他公开网页数据类似。不过你仍然应该先查看 Sainsbury's 的服务条款,避免抓取个人数据,并控制在合理的请求频率范围内。如果是商业用途,最好让你的法务团队先确认一下。
Sainsbury's 会封锁 scraper 吗?
和 Walmart 或 Costco 相比,Sainsbury's 的 anti-bot 机制算是比较温和。大多数通过 Datablist 发起的 Sainsbury's 抓取任务,第一次就能成功,尤其是在开启 Render HTML 的情况下。如果某个分类页没有返回数据,可以先减少抓取页数再重试,或者把任务拆成更细的子分类分别抓取。
可以定时重复抓取,用于 Sainsbury's 价格监控吗?
可以。Datablist 的 workflow automation features 支持你设置周期性运行。再配合一个唯一标识列(通常 Product URL 最好用)以及防重复设置,就可以让每次重复抓取只新增新商品,而不是把已有数据再重复导入一遍。
不会写代码也能抓取 Sainsbury's 吗?
完全可以。整个流程都是 no-code:选择 Retail Product Scraper template、粘贴一个 Sainsbury's URL、勾选你需要的输出字段,然后点击运行即可。只要你会写一句话,你就能用 Datablist 抓取 Sainsbury's。
哪些 Sainsbury's 分类最适合抓取?
标准 grocery 分类通常返回的数据最干净,比如 https://www.sainsburys.co.uk/gol-ui/groceries](https://www.sainsburys.co.uk/gol-ui/groceries 下的 fresh、frozen、bakery、drinks、household 等分类。品牌页通常也很好抓。促销页或 “Last chance” 页面可能会稍微杂一些,因为商品卡片样式更混合,但 AI Agent 依然能从中提取出可用数据。
AI Agent 能自动处理 Sainsbury's 分页吗?
可以。开启 Enable Pagination 后,AI Agent 会按照你设定的上限遍历该 Sainsbury's 分类下的每一页(默认 10 页,最大 5,000 页)。例如,如果某个 Sainsbury's 分类有 240 个商品、每页显示 24 个商品,那么把分页设置为 10,agent 通常就能把整份列表抓全。
什么是 AI scraping?
AI scraping 是一种利用语言模型从网站中提取结构化数据的方法,它不依赖固定的 HTML 规则。agent 会访问页面、理解页面内容,然后按你的自然语言要求返回对应字段。正因为如此,它在像 Sainsbury's 这种页面结构经常变化的网站上,依然具备较强的稳定性。
AI scraping 和传统 web scraping 有什么区别?
传统 scraper 依赖固定规则(如 CSS selector、XPath)。一旦网站结构变化,这些规则就会失效。AI scraping 则理解页面语义,所以即使标记结构变了,Sainsbury's 的价格还是会被识别为价格。这也是为什么同一套 Datablist 配置可以同时适用于 Tesco、Sainsbury's、Morrisons 和 Asda,而不需要针对每个网站单独开发。