

大多数零售商网站的设计目标是卖货,而不是公开数据。这也是为什么,想抓取这类网站的数据,通常不是要找开发者,就是要自己和代码死磕。
而且,这和抓取 Shopify 店铺不一样。Shopify 店铺通常结构相似,但零售商网站的页面结构五花八门,抓取过程也更不可预测。这个时候,AI scraping 的价值就体现出来了:它理解的是页面“语义”,而不是死盯代码。
这篇指南会带你完整走一遍流程:为什么自定义 scraper 往往不划算、我们成功抓取了哪些零售商网站(以及哪些没抓成),以及如何使用 Datablist 的 AI Scraping Agent 一步步抓取商品数据。
📌 给赶时间读者的摘要
这篇文章会教你如何使用 Datablist 的 AI Scraping Agent 抓取零售商网站。
问题: 零售商网站结构各不相同,传统 scraper 很容易频繁失效,而定制方案的维护成本又很高。
解决方案: 使用 Datablist.com 的 AI Scraping Agent,通过自然语言 prompt 从零售商网站提取商品数据。
你将学到:
- 为什么为零售商网站单独开发 scraper 往往是在浪费时间和预算
- 我们测试了哪些零售商网站,以及分别能提取哪些数据
- 如何用完整的分步流程,在几分钟内抓取任意支持的零售商网站
为什么选择 Datablist:
- AI scraping 像人一样“看懂”页面,因此能适配不同的网站结构
- 自动处理分页(单次最多支持 5,000 页)
- 无需写代码、无需配置 API,只要一个 URL 和一段 prompt
本文包含哪些内容
为什么自定义 scraper 是在浪费资源
如果你认真考虑过自己做一个 scraper,专门从零售商网站提取商品数据,那么下面这三个理由值得你重新想一想。
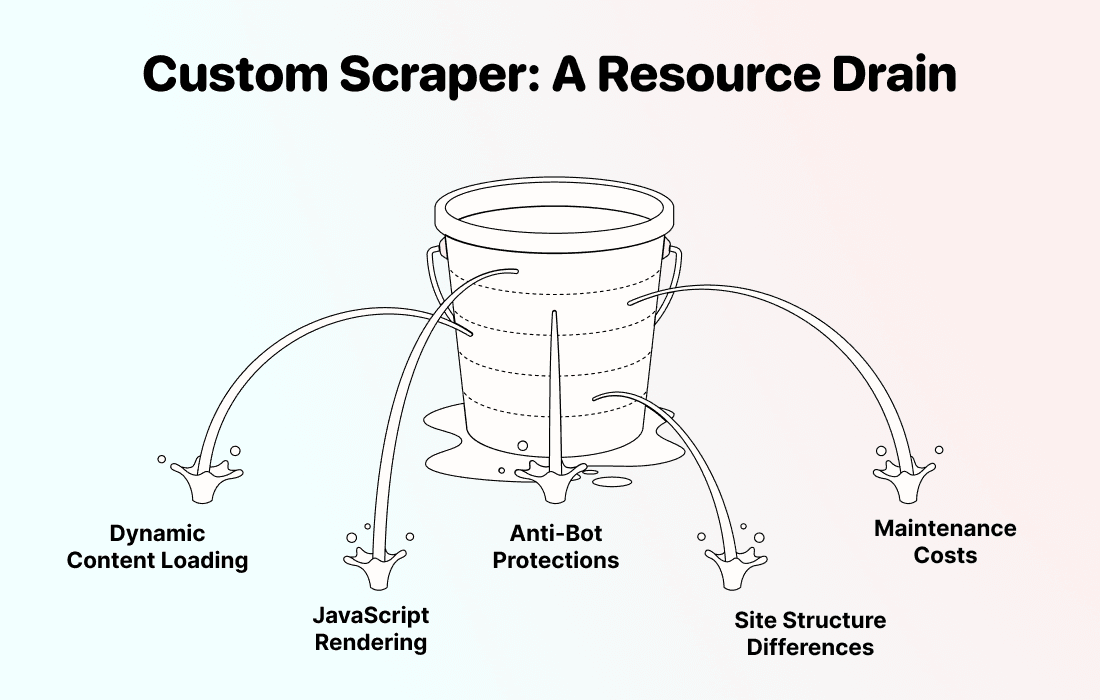
成本高
要做一个能稳定抓取零售商网站的自定义 web scraper,绝不是周末抽空就能搞定的小项目。这类网站通常会用到动态内容加载、JavaScript 渲染以及 anti-bot 防护,没有扎实的开发能力,很难处理好。
常见的几种零售商网站抓取方式,基本都各有坑:
- 找自由开发者外包:单个零售商网站通常就要 $2,000 起,而且一旦失效,还得继续付钱修
- 使用现成 scraper(Apify、GitHub):网站结构不变时还能用,一改版就坏,又得重新排查
- vibe-code 临时写个脚本:遇到 CAPTCHA、IP 封锁、分页商品列表,通常很快就撑不住
如果你不只抓一次,而是要持续抓取零售商网站,成本会很快成倍上涨。 因为每个零售商的网站结构都不一样,也就意味着每个站都要单独写一套抓取逻辑。
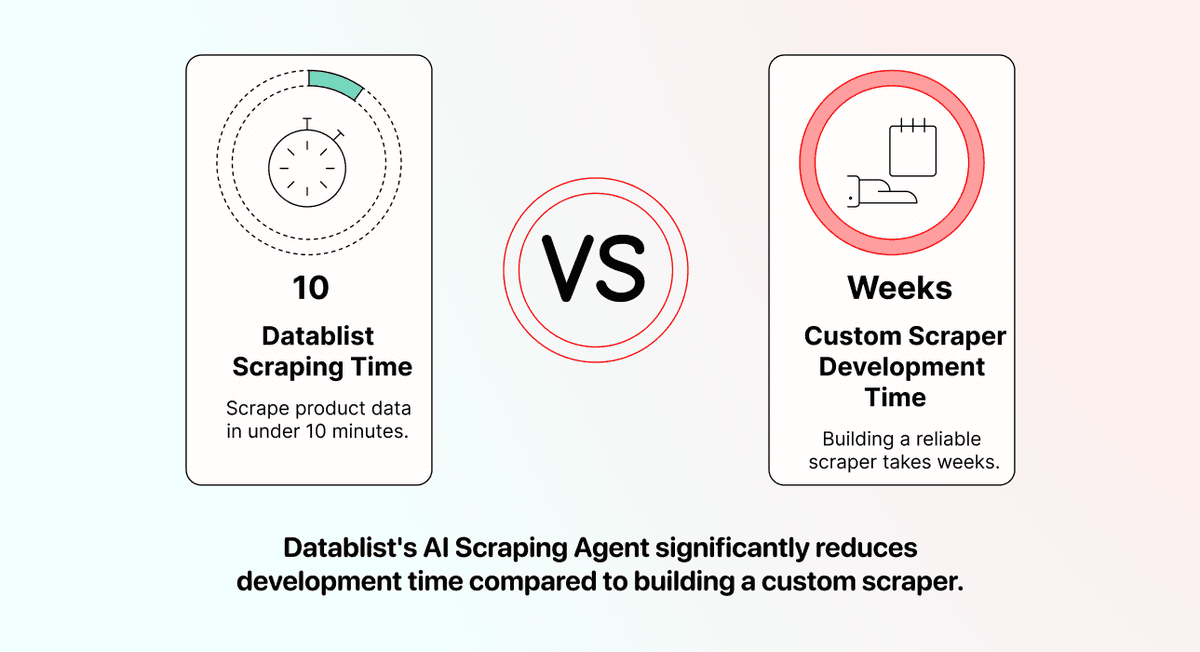
开发周期长
就算你已经找到开发者,做出一个可靠的 scraper 往往也要几周时间。你需要逆向分析每个零售商的网站、处理各种 edge cases、在不同商品分类下测试,还要应对不统一的数据格式。
相比之下,Datablist 的 AI Scraping Agent 已经是现成可用、经过测试、可规模化抓取的网站数据方案。你完全可以在 10 分钟内,从零开始拿到抓好的商品数据。 不用等开发交付,也不用来回沟通需求。
很容易失效
这才是真正的大问题。零售商网站会频繁更新页面布局,有时甚至是每周都改。每当 Tesco 或 Aldi 调整 CSS class、移动价格元素,或者重构商品列表布局,你的自定义 scraper 都可能立刻失效。
这意味着,你要么持续花钱请开发者维护,要么自己每隔几天就花时间 debug 代码。
AI scraping 没这个问题。因为 AI agent 读取的是页面内容,而不是 HTML 结构,所以它能自动适应布局变化。价格还是那个价格,即使包裹它的 CSS class 变了。
💡 核心区别
传统 scraper 遵循的是规则,比如:“找到 class 为 .product-price 的元素并提取文本。” AI scraper 理解的是语义,比如:“找出这个页面上的商品价格。”
这也是为什么它无需针对每个网站单独配置,也能适配不同的零售商网站。
零售商网站抓取原理(含测试结果)
在进入实操步骤之前,你最好先了解几件事:哪些零售商网站能抓、能抓出哪些数据,以及它的边界在哪里。
从零售商网站可以抓取哪些数据
使用 Datablist 的 AI Agent 抓取零售商网站时,你可以在一次运行中提取多个维度的商品信息。以下是 agent 通常可以从零售商商品列表页提取的数据:
- Product Name - 页面展示的完整商品名称
- Product URL - 商品详情页直达链接
- Brand Name - 商品所属品牌或制造商
- Price - 当前展示币种下的零售价
- Sale Price - 促销价;如果没有促销,则返回 “N/A”
- Product Category - 商品所属分类、部门或货架分类
- Availability - 是否有货、缺货,或支持预订
- Rating - 用户评分或评价分数(如页面有展示)
- Image URL - 商品主图链接
- SKUs - 商品的 SKU / ID
这些基本覆盖了大多数人在抓取零售商商品信息时最关心的核心数据。无论你是做价格监控、竞品分析,还是给现有商品数据库做 data enrichment,这些字段都足够帮助你完整理解每一条商品 listing。
在运行 scraper 之前,你可以自行定义需要哪些输出字段,因此只会拿到对当前业务场景真正有用的数据,不会有多余噪音。
我们测试过的零售商网站
我们在德国、英国和美国的 8 个零售商网站 上测试了 Datablist 的 AI Scraping Agent。其中 8 个里有 5 个在第一次尝试时就抓取成功,不需要任何站点级配置。
成功抓取的网站(5/8)
✅ Tesco (tesco.com) - 商品名称、价格、分类和库存状态都能稳定提取
✅ Morrisons (morrisons.com) - 商品列表和分页抓取都没有问题
✅ Waitrose (waitrose.com) - 成功提取促销价和商品分类
✅ Netto Marken-Discount (netto-online.de) - 虽然是德国零售商、网站结构也完全不同,但首次尝试依然成功
✅ Aldi (aldi-nord.de) - 商品列表、价格和 SKU 都顺利提取出来
这些网站的页面结构彼此差异非常大,但 AI agent 依然可以用同一套 prompt、相同设置和相同输出字段完成抓取。
被 anti-bot 防护拦截的网站(3/8)
❌ Walmart (walmart.com) - anti-bot 防护较强,加上动态内容加载,导致抓取结果无法保持稳定
❌ Costco (costco.com) - 类似的 bot 防护机制,使得稳定提取数据较为困难
❌ Edeka (edeka.de) - 网站结构与内容分发方式导致难以持续获得稳定结果
这 3 个网站在 anti-scraping 技术上的投入明显更高。 不过对于大多数零售商网站,尤其是连锁超市和区域型零售商,AI agent 的表现依然很不错。

零售商网站抓取完整步骤
前面我说 Datablist 很好上手,并不是客套。整个流程真的只要 5 个步骤,换句话说,就是点几下鼠标而已。不过开始之前,请先确认你已经准备好:
- 想抓取的零售商页面 URL(分类页、品牌页或“全部商品”页面通常最适合)
- 对想提取哪些商品信息有一个大致想法
零售商网站抓取分步教程
接下来这部分会带你走完整个抓取流程。你几乎不需要额外配置,因为我们已经提供了可直接使用的模板。
第 1 步:注册并创建 Collection
首先,注册 Datablist.com

然后,创建一个 New Collection
第 2 步:进入 AI Agent - Site Scraper
- 点击 See all sources
- 向下滚动,选择 AI Agent - Site Scraper
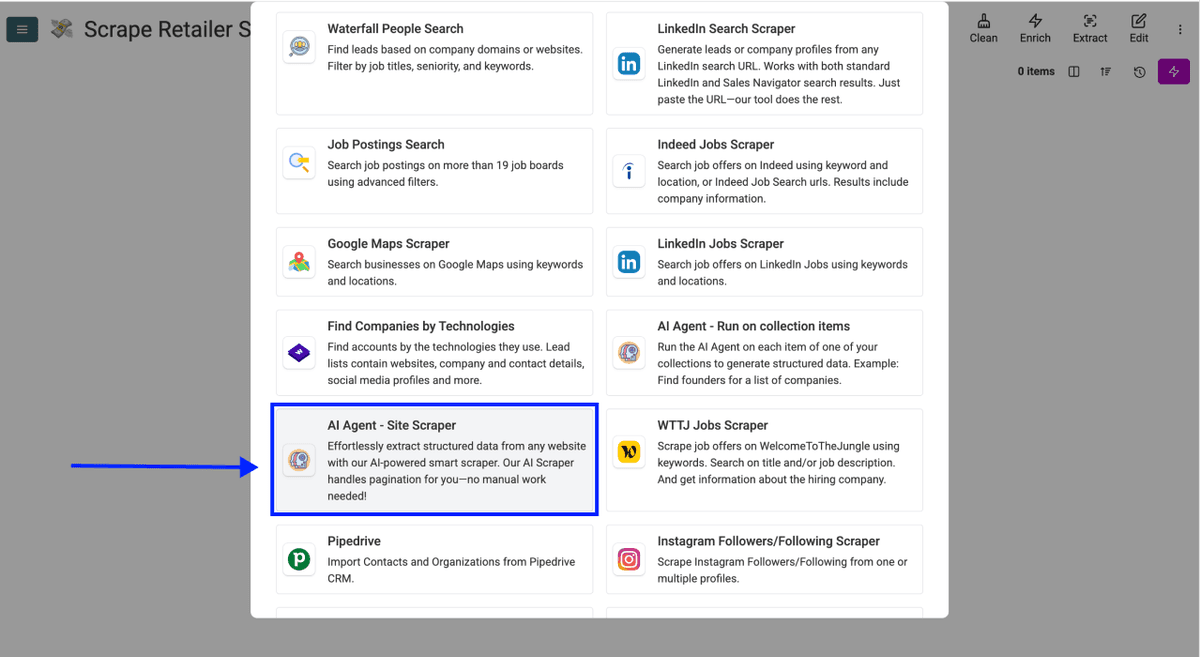
现在你应该会看到一个新的界面,大致如下:
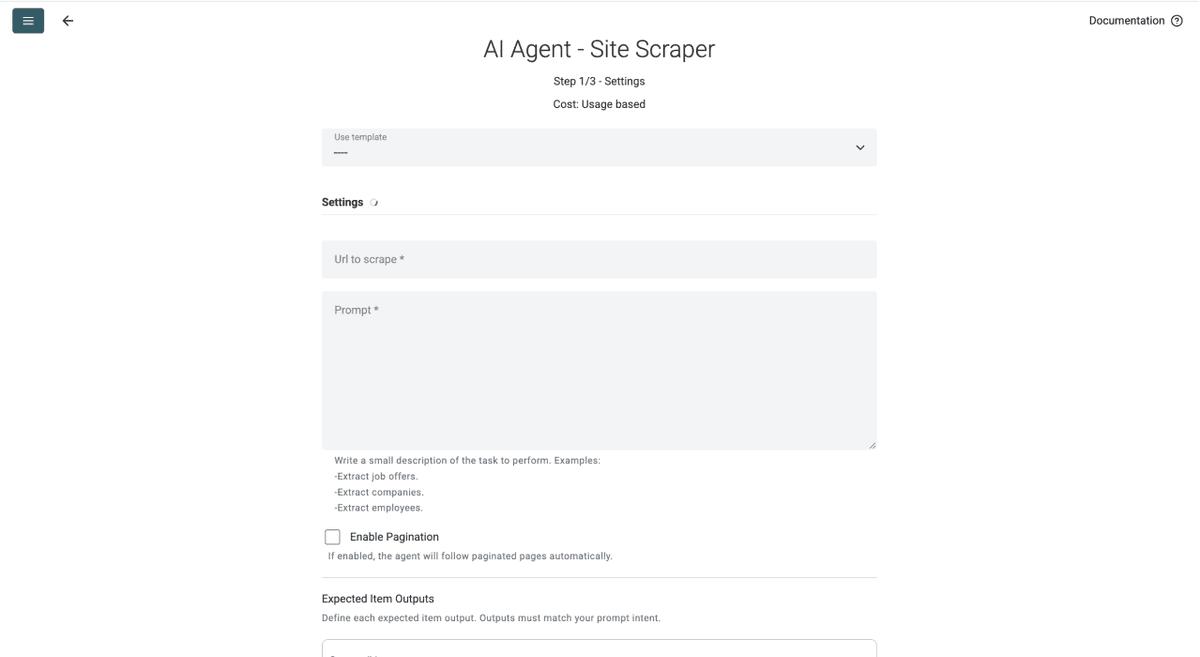
第 3 步:选择模板并配置任务
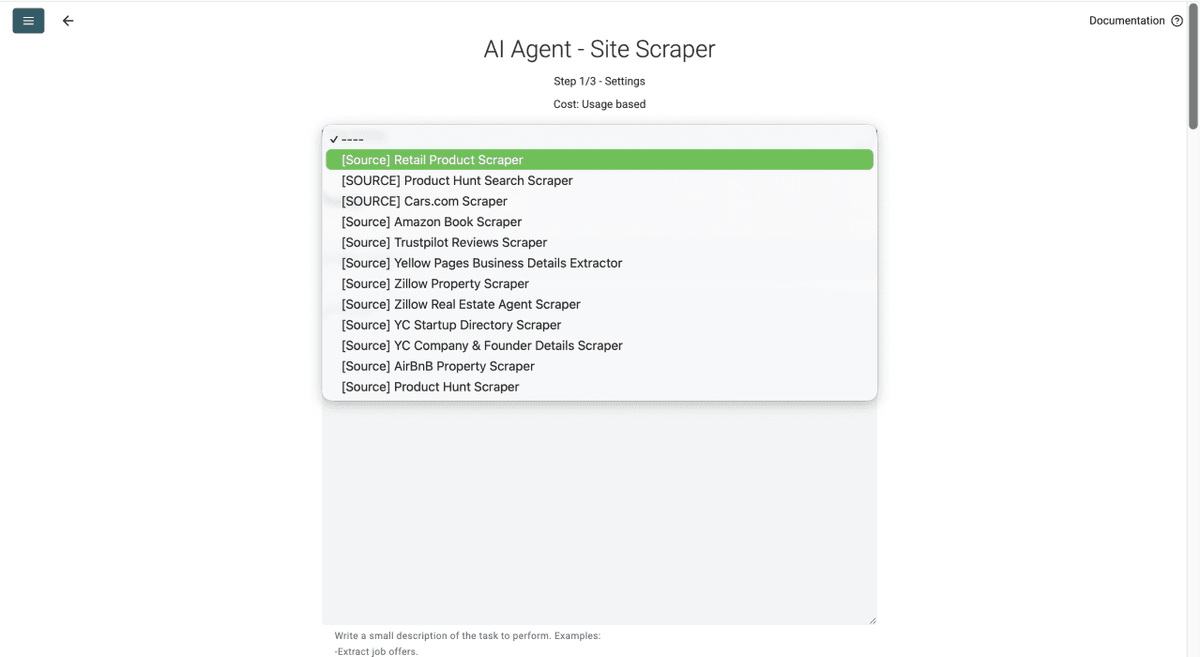
- 点击 Template Drop-Down,选择 “Retail Product Scraper”
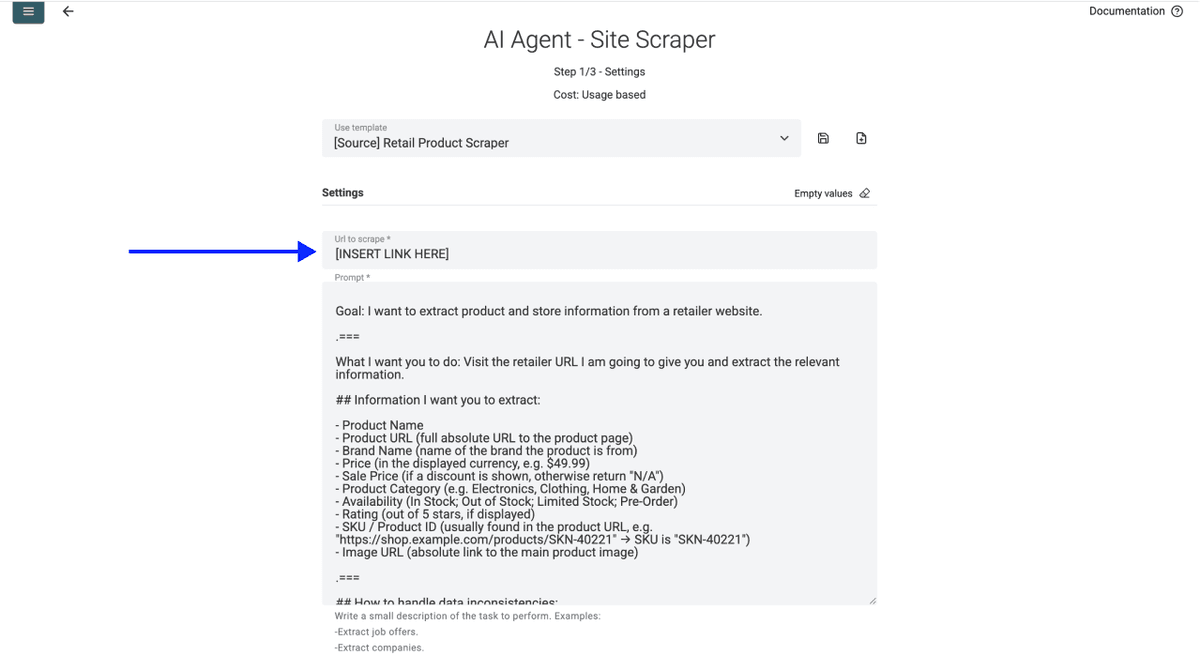
- 在第一个输入框中粘贴你的零售商商品页面 URL
- 选择你要抓取的页数
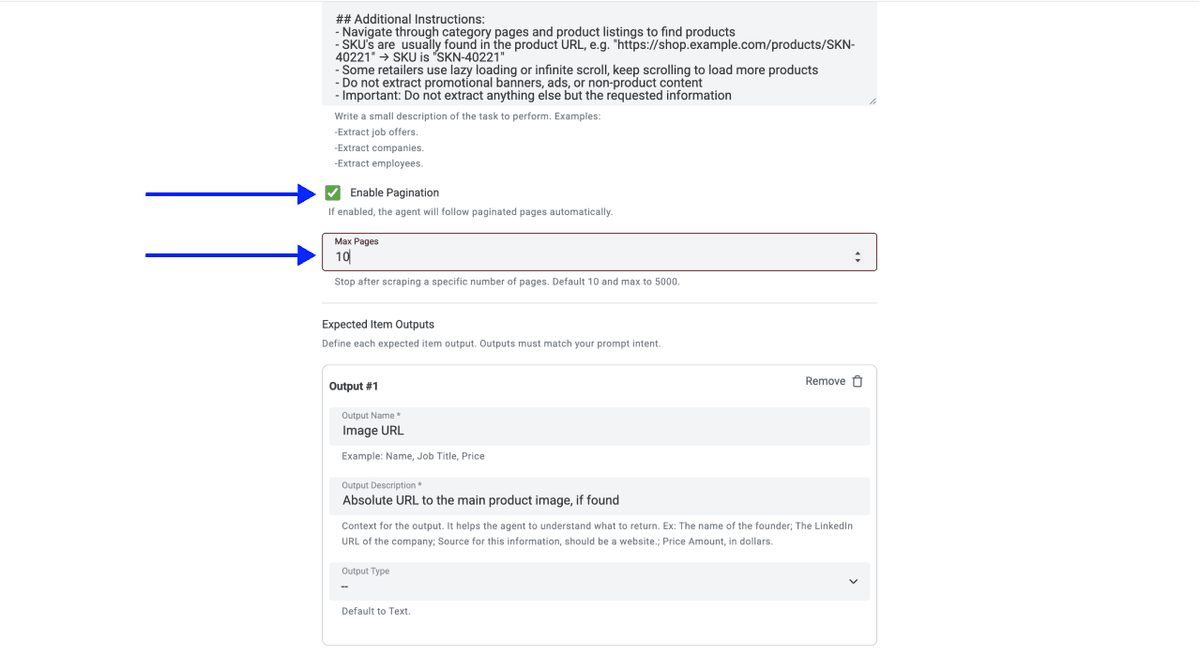
📘 关于零售商网站的分页抓取
大多数零售商网站每页会展示 20 到 50 个商品。如果某个分类下有 500 个商品,你通常需要抓取 10 到 25 页。Datablist 的 AI Scraping Agent 会自动处理分页,单次运行最多可抓取 5,000 页。
如果你想进一步了解 AI scraping,我们还写过一篇关于 如何为 AI agents 编写 prompts 的规则 的文章 👈🏽
- 向下滚动并点击 Continue
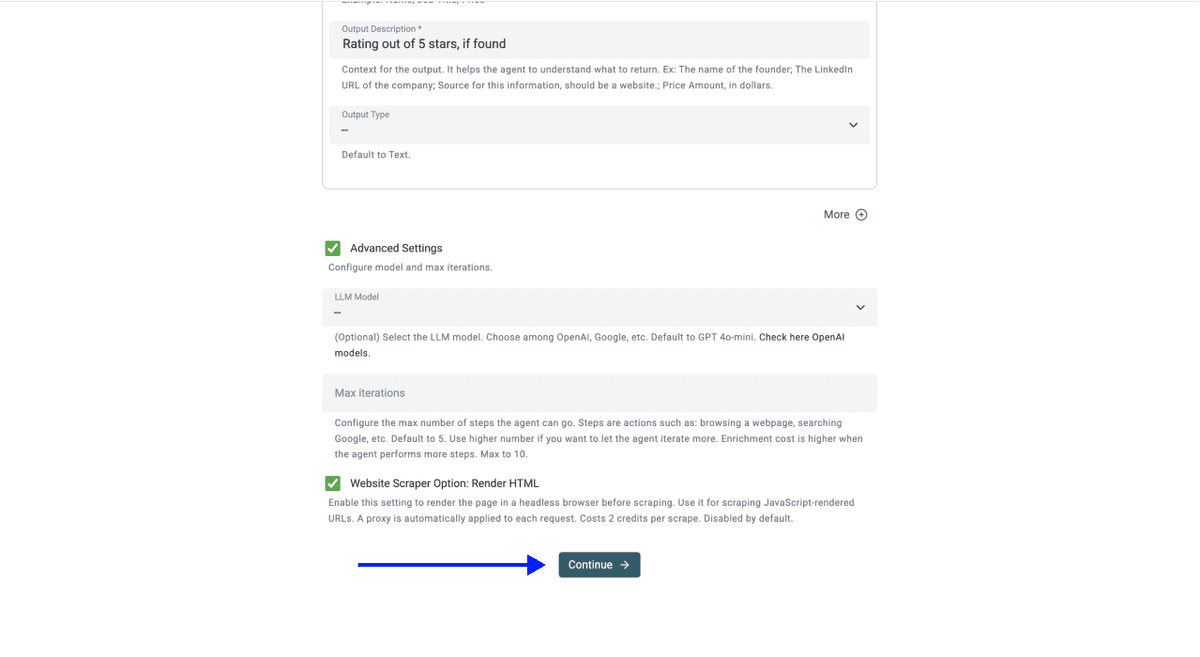
💡 点击 Continue 之前,先检查 Advanced Settings
请确认以下设置已启用:
- LLM: OpenAI: GPT 4.1 mini(性能价格比最佳)
- Max iterations: 10
- Website Scraper Option: Render HTML(这项对抓取零售商网站非常关键,因为大多数此类网站都通过 JavaScript 动态加载商品)
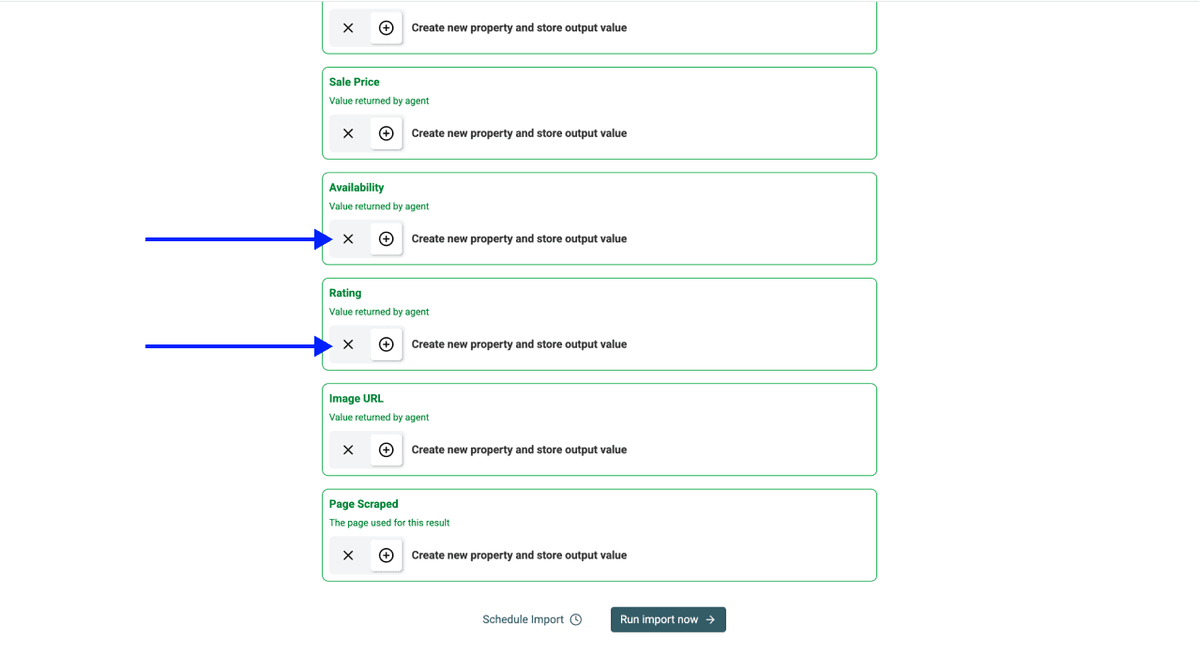
第 4 步:选择输出字段
Datablist 会自动创建输出字段。
点击 X Icons 删除你不想保留在 collection 里的输出项。
第 5 步:运行
完成以上设置后,点击 Run Import Now 开始抓取。
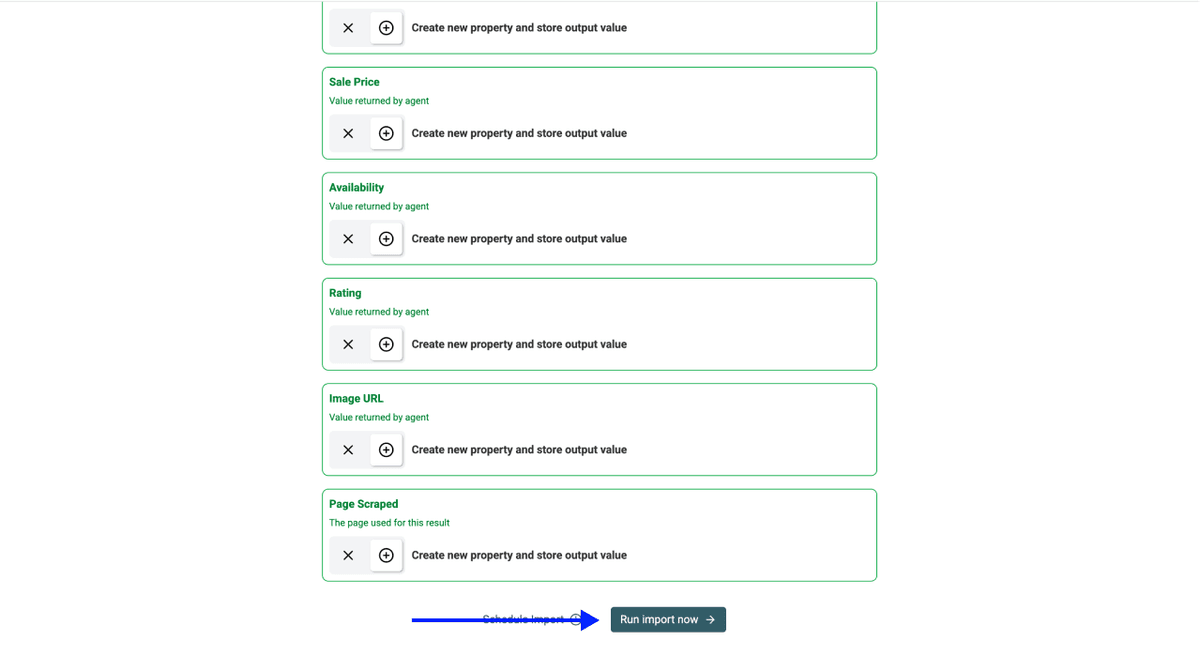
几分钟后,你的结果大致会像这样。接下来,你可以使用 Datablist 的workflow automation features 对数据进行清洗、enrich 和导出。
💡 重复运行时避免重复数据
如果你之后还打算再次抓取同一个零售商网站(比如做价格监控、库存跟踪等):
- 选择一个唯一标识列(通常 Product URL 最合适)
- 点击列标题,依次选择:Rename - Settings - Delete
- 勾选:Do not allow duplicate values
- 点击:Save Property
这样重新运行 scraper 时,只会新增新商品,不会把已有商品重复导入。配合 Datablist 的 workflow automation features,你还可以把定时抓取自动化,几乎不用手动干预。
如果你是把多个零售商的数据抓到同一个文件里,我们也写过一篇关于如何去除 CSV 文件重复数据的指南 👈🏽
关键结论总结
下次你需要抓取零售商网站时,记住这几点就够了:
- 自定义 scraper 对零售行业来说很容易变成无底洞。 网站结构不同,就要写不同 scraper;页面一改版就会失效;而且通常也没有内置的 workflow automation。整体上并不值得投入。
- AI scraping 理解的是语义,不是 HTML。 这也是为什么它可以在 Tesco、Aldi、Morrisons 等不同零售商网站上工作,而无需逐站单独配置。
- 完整流程不到 10 分钟。 URL、prompt、输出字段、运行,就这么简单。
- 不是所有零售商网站都能抓。 Walmart、Costco 和 Edeka 的 anti-bot 防护较强,所以要对可行性保持现实预期。
零售商网站抓取常见问题
抓取零售商网站要花多少钱?
Datablist.com 的 AI Agent 使用按量计费的 credits 系统。每个零售商页面的抓取成本会根据 agent 提取的数据量以及所需迭代次数而变化。Datablist 套餐起价为 $25/月,包含 5000 个免费 credits。如果你需要更多,充值包从 $20 / 20,000 credits 起,更大额度还有最高 35% 的折扣。
从零售商网站抓取商品要多久?
大多数包含 50 到 200 个商品的零售商分类页,都可以在 5 到 10 分钟内抓完。启用分页后的大批量任务(例如 500+ 商品、跨多个页面)通常需要 10 到 20 分钟。第一次配置大概还要额外 3 到 5 分钟;同一零售商后续重复运行时,通常只需几秒钟就能完成设置。
我能抓取的商品数量有限制吗?
Datablist.com 每个 collection 最多支持 100,000 行数据,AI Agent 单次运行最多可抓取 5,000 页。对绝大多数零售商网站来说,这已经足够覆盖完整商品目录。
抓取零售商网站需要会写代码吗?
完全不需要。通过 Datablist.com,整个流程都是 no-code。你只需要粘贴 URL,写一个 prompt 描述你想从零售商网站提取哪些商品,选择输出字段,然后点击运行即可。只要你会写文字说明,你就能用 Datablist.com 抓取零售商网站。
AI 可以抓取任何零售商网站吗?
大多数零售商网站都适合用 AI scraping,尤其是连锁超市和区域型零售商。不过,一些大型零售商,比如 Walmart、Costco 和 Edeka,使用了更强的 anti-bot 防护,会影响自动化数据提取的稳定性。我们的建议是:先用小批量测试,确认目标零售商网站是否受支持。
AI scraping 和传统 web scraping 有什么区别?
传统 scraper 依赖固定规则,比如 HTML 元素、CSS class 或 XPath selector。一旦网站布局改动,scraper 就会失效。AI scraping 的方式不同,它像人一样读取页面,并能推断出商品名称旁边的数字大概率就是价格,即使 HTML 结构发生变化也没关系。这让 AI scraper 在不同网站之间更有韧性,也更适合无需定制配置的通用抓取场景。
可以抓取那些会拦截 bot 的零售商网站吗?
这取决于对方的防护强度。有些零售商网站只使用基础的 bot 检测,Datablist 的 Render HTML 选项就足以应对;但也有一些网站(例如 Walmart 和 Costco)采用了更高级的 anti-bot 系统,会拦截大多数自动化访问方式。如果你不确定,建议先跑一个只包含 10 条数据的小测试,看看我们的 scraping agent 能否稳定抓取该零售商网站。
AI 能抓取网站吗?
可以。像 Datablist 的 AI Scraping Agent 这样的 AI 驱动抓取工具,可以访问网页、读取页面内容,并根据自然语言指令提取结构化数据。AI 会自动处理 JavaScript 渲染、分页以及不同页面布局。
抓取网站最快的方法是什么?
如果目标是抓取零售商网站,最快的 no-code 方法通常就是 AI scraping。你只需要提供 URL,用自然语言描述你想要的数据,agent 就会自动提取。使用 Datablist.com,从配置到拿到结果,整个流程通常不到 10 分钟。
什么是 AI scraping?
AI scraping 是一种基于人工智能的网站数据提取方式,不同于传统的规则型 scraper。它不依赖固定的 HTML selector,而是借助语言模型理解页面内容,再提取你指定的信息。因此,它更灵活、更易上手,也更能适应网站改版。像 Datablist 这样的平台,就是通过 AI Scraping Agents 提供 AI scraping 能力的。
全球最大的零售商有哪些?
按营收计算,全球最大的零售商包括:
- 🇺🇸 Walmart - $648B
- 🇺🇸 Amazon - $620B
- 🇺🇸 Costco - $254B
- 🇩🇪 Schwarz Group (Lidl + Kaufland) - €175.4B
- 🇺🇸 Home Depot - $157.6B
- 🇺🇸 Kroger - $150.8B
- 🇩🇪 Aldi (Nord + Süd) - €112B
- 🇫🇷 Carrefour - €94.1B
- 🇬🇧 Tesco - £63.6B
- 🇪🇸 Mercadona - €38.8B
欧洲最大的零售商有哪些?
欧洲各国头部零售商并不完全相同。按营收来看,主要玩家包括:
- 🇩🇪 德国:Schwarz Group/€175.4B、Aldi/~€117.6B、REWE Group/€96.0B、Edeka/€75.3B、Netto Marken-Discount/€17.6B
- 🇬🇧 英国:Tesco/£63.6B、Sainsbury's/£33.3B、Asda/£21.7B、Morrisons/£15.8B
- 🇫🇷 法国:Carrefour/€94.1B(全球)、E.Leclerc/€50B+、Auchan/€32.3B、Système U/€25.9B
- 🇪🇸 西班牙:Mercadona/€38.8B、Carrefour Spain/€11.7B
参考资料
[1] 完成润色后可在此补充引用来源,包括商品页面、价格文档,以及调研过程中使用的外部资料。
[2] Datablist.com 定价:Growth Plan 为 $50/月,包含 20,000 credits。充值包从 $20 / 20,000 credits 起。完整信息见 datablist.com/pricing