Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
So verwenden Sie diesen AI Prompt
- Neue Collection erstellen: Erstellen Sie zuerst eine neue, leere Collection in Datablist, in der die Daten gespeichert werden. Klicken Sie in der Seitenleiste auf "+ Create new collection".
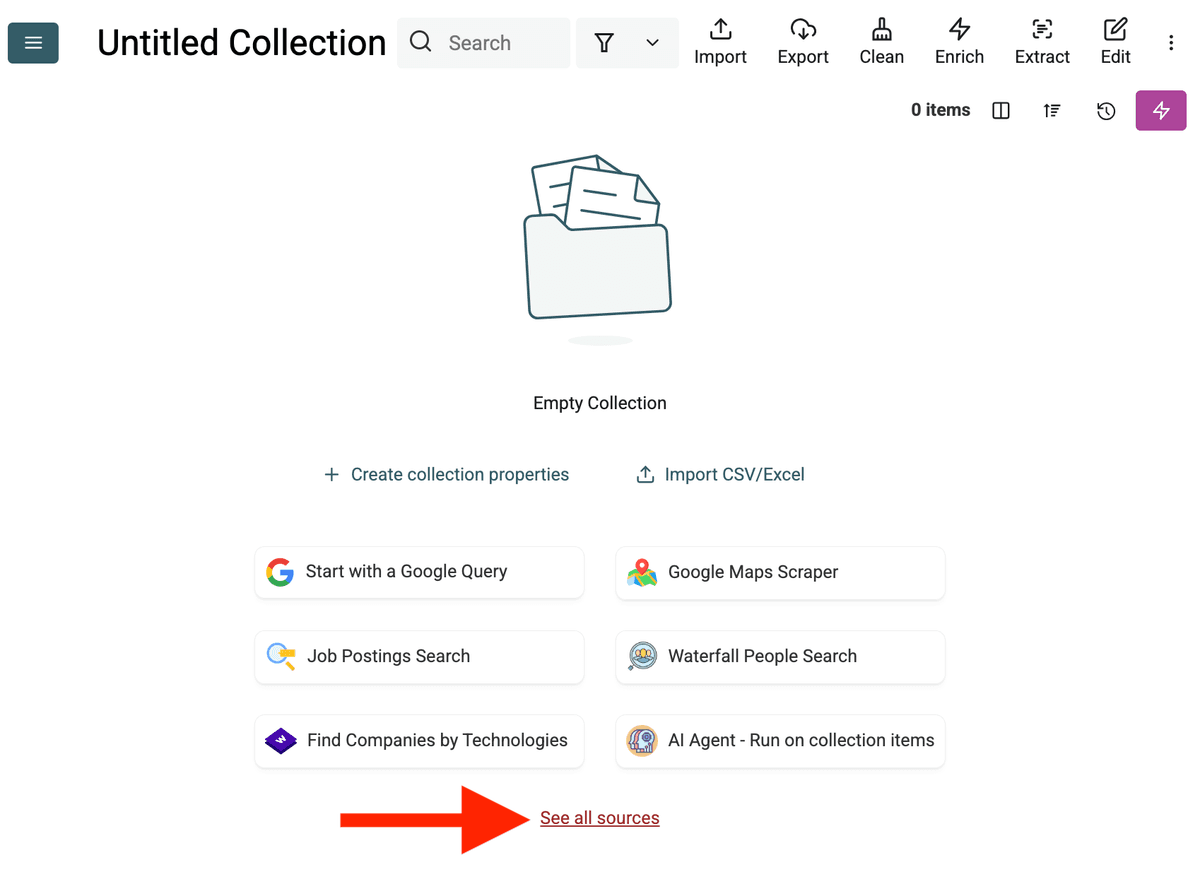
- AI Agent Source auswählen: Klicken Sie auf "See all sources" oder gehen Sie zu "Import" -> "Import From Data Sources". Wählen Sie "AI Agent - Site Scraper".
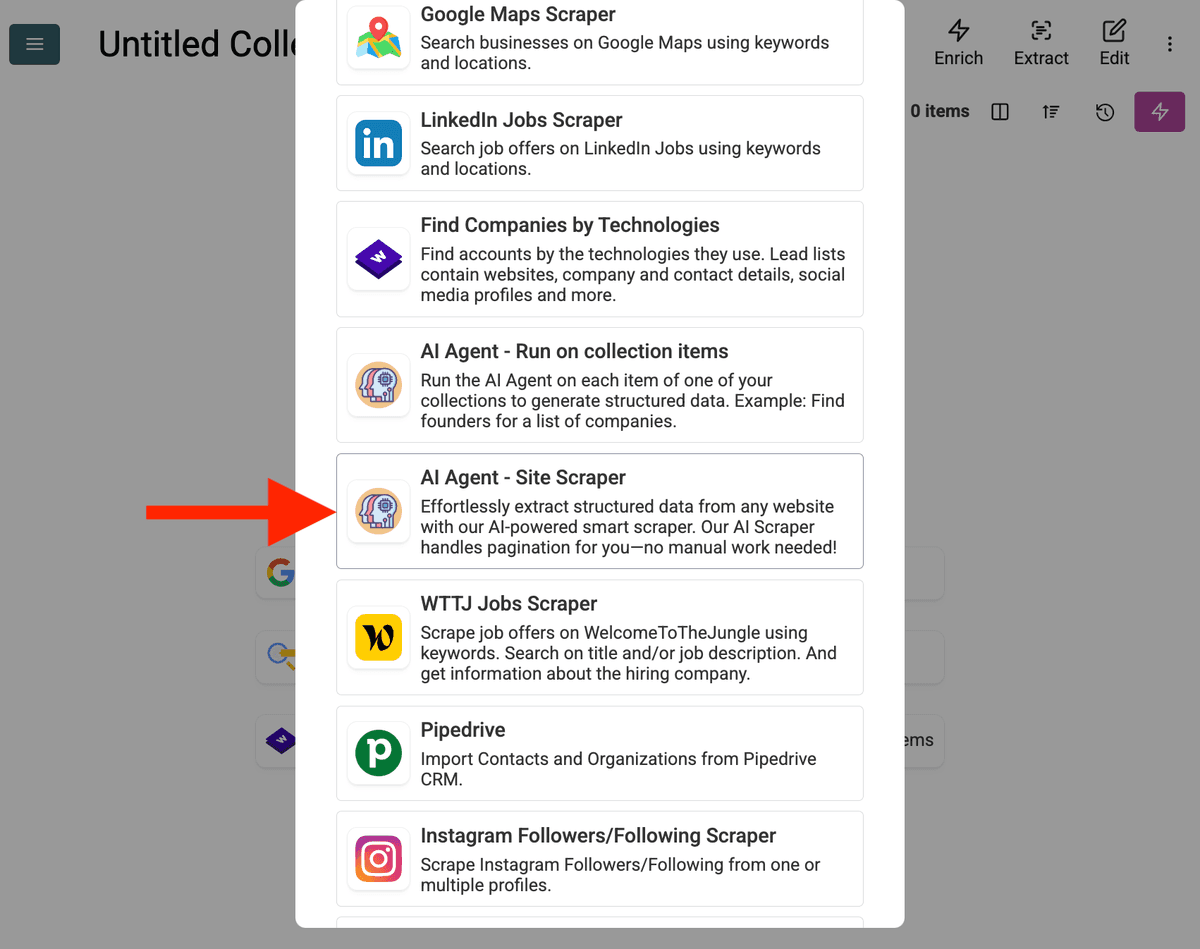
-
Quelle konfigurieren:
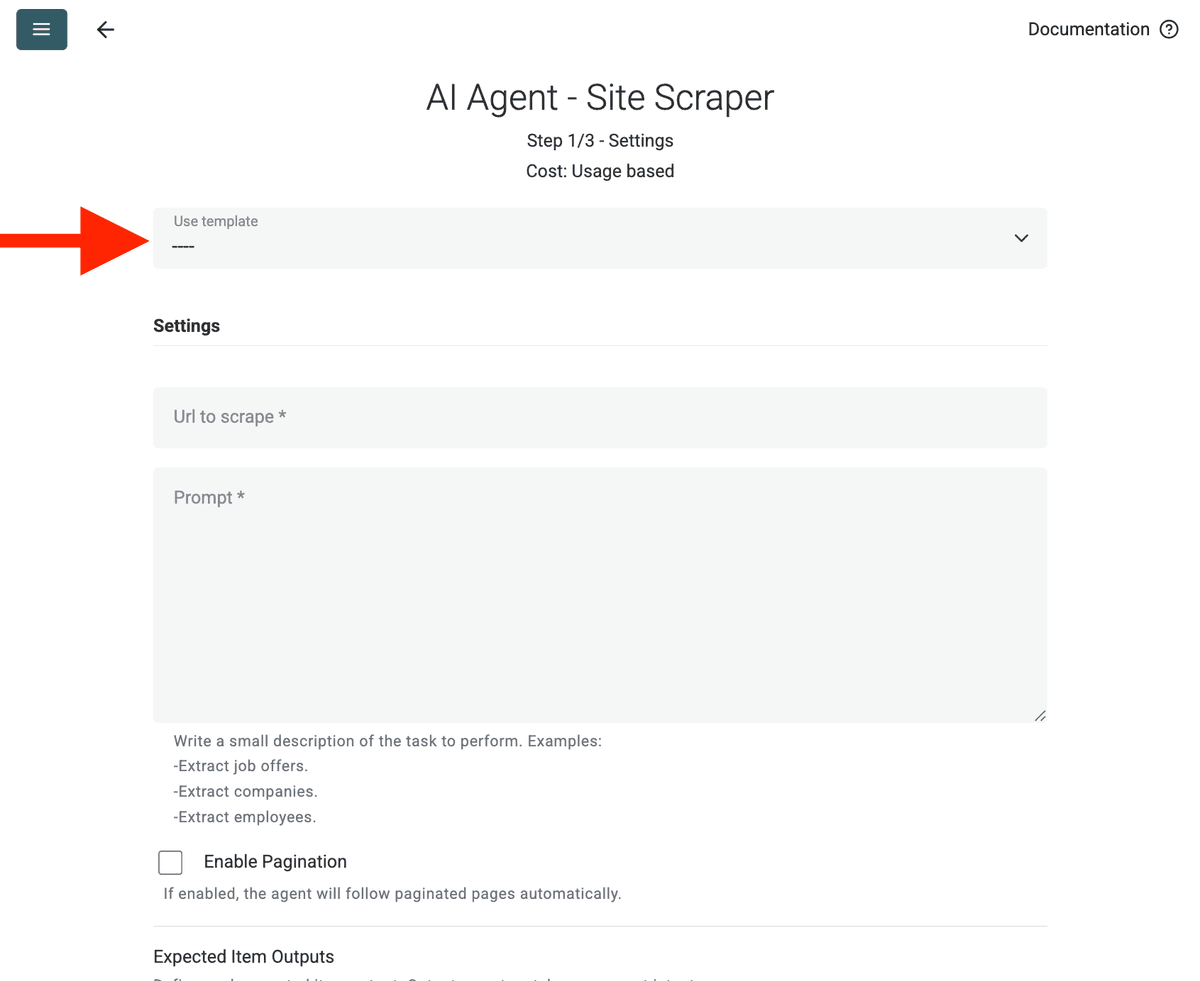
- Select Template: Suchen und wählen Sie den Prompt im "Template"-Dropdown. Der obige Prompt wird automatisch geladen.
- URL to Scrape: Geben Sie die URL ein, die gescrapet werden soll.
- Enable Pagination (Optional): Wenn sich Ergebnisse auf mehreren Seiten befinden, aktivieren Sie Enable Pagination und setzen Sie ein sinnvolles Limit für Max Pages (z. B. 10).
- Customize (Optional): Sie können das AI-Modell anpassen (z. B. ist GPT-4o mini oft kosteneffizient), den Prompt für spezifische Anforderungen bearbeiten oder die erwarteten Outputs modifizieren.
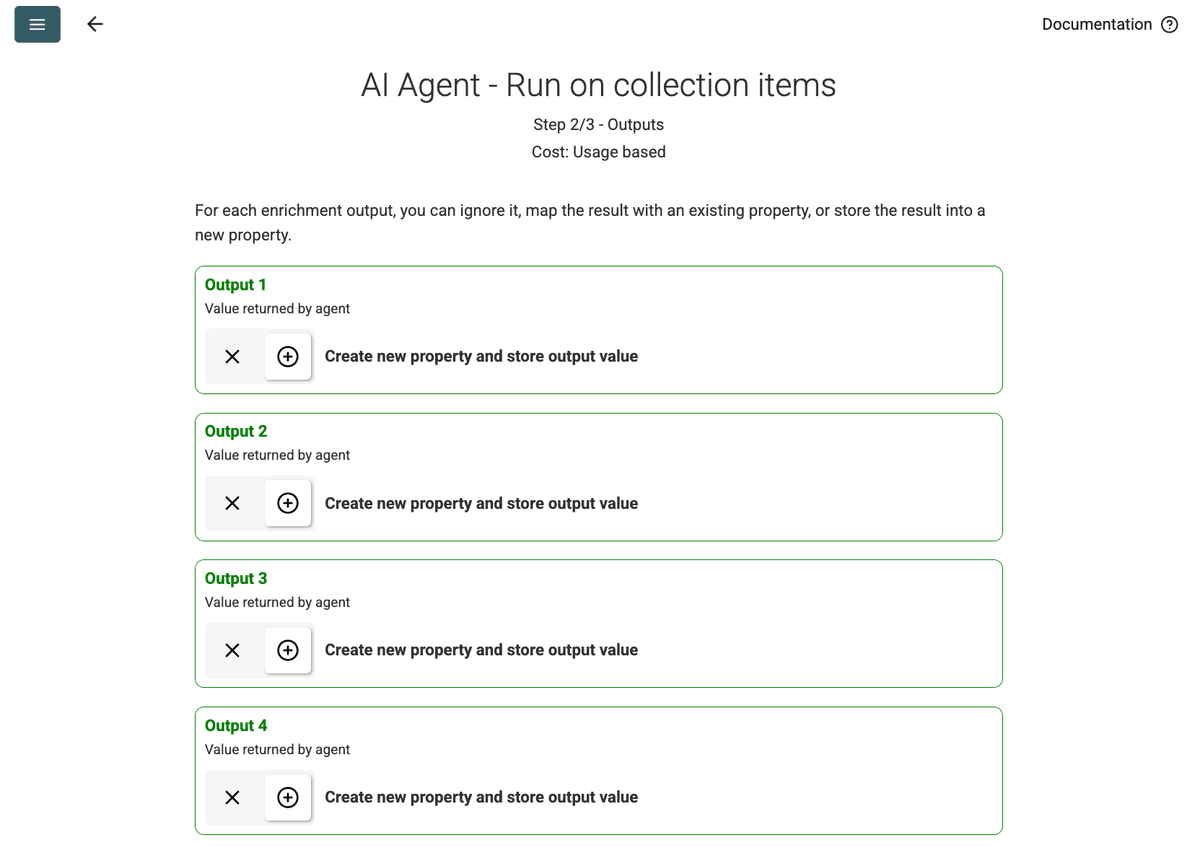
- Outputs prüfen: Klicken Sie auf Continue. Datablist zeigt die im Prompt definierten Output-Felder (Project Name, Client Company Name). Klicken Sie jeweils auf das +-Symbol, um die entsprechenden Properties (Spalten) in Ihrer Collection zu erstellen.
- Import ausführen: Klicken Sie auf Run import now. Der AI Agent beginnt basierend auf dem Prompt mit dem Scrapen der Website und füllt Ihre Collection.
Preise
Diese Datenquelle nutzt Datablist Credits nach Nutzung. Die Kosten hängen von der Komplexität der Website und der Anzahl der besuchten Seiten ab.
Führen Sie den AI Agent zunächst auf einer einzelnen Seite testweise aus, um die Kosten abzuschätzen.
FAQ
Wie starte ich einen weiteren Lauf mit der gleichen Konfiguration?
Nachdem Sie Ihren AI Agent ausgeführt haben, klicken Sie oben rechts in Ihrer Datentabelle auf die rosa Schaltfläche, um ihn mit den zuletzt verwendeten Einstellungen erneut zu öffnen.
Was passiert, wenn der AI Agent versucht, auf eine geschützte Website zuzugreifen oder blockiert wird?
Der AI Agent verwendet bei Bedarf automatisch Proxy-Server, um auf Websites zuzugreifen, die über Scraping-Schutz oder geografische Beschränkungen verfügen. Das erhöht die Erfolgschancen für die Datenerfassung, sehr stark geschützte Seiten können jedoch weiterhin herausfordernd sein.
Wie viele Daten kann ich mit dem AI Agent verarbeiten?
Bei der Ausführung des AI Agent (als Enrichment oder als Datenquelle) können Datablist Collections bis zu 100.000 Items (Zeilen) verarbeiten. Für größere Datensätze müssen Sie die Daten ggf. auf mehrere Collections aufteilen.
Worin unterscheidet sich der AI Agent von den ChatGPT/Claude/Gemini Enrichments?
Die Standard-AI-Enrichments (ChatGPT, Claude, Gemini) verarbeiten Daten, die sich bereits in Ihrer Collection befinden, basierend auf dem vorhandenen Wissen der AI. Der AI Agent kann aktiv mit dem Live-Web interagieren – Google-Suchen durchführen, Websites browsen und neue Informationen gemäß Ihrem Prompt extrahieren.
Wie genau sind die Ergebnisse?
Die Genauigkeit hängt stark von der Klarheit und Spezifität Ihres Prompts sowie von der Komplexität der Aufgabe und den online verfügbaren Informationen ab. Klare Anweisungen, Beispiele und Regeln zur Fehlerbehandlung verbessern die Ergebnisse. Datablist liefert häufig einen Confidence Score für AI-Agent-Outputs, um die Zuverlässigkeit besser einschätzen zu können.