
Du hast Deine Daten aus einer Anwendung als CSV exportiert und willst die Duplikate loswerden? Du hast mehrere CSV-Dateien zusammengeführt und jetzt musst Du die große Liste bereinigen? Oder Du hast mehrere Datenquellen, die nicht mehr synchron sind, und willst alles in eine einzige, saubere Liste zusammenziehen. Mit Microsoft Excel oder Google Sheets kommst Du hier schnell an Grenzen – denn dort kannst Du für eine Spalte keine echte Unique-Constraint (Eindeutigkeitsregel) festlegen.
Bei einer kleinen CSV kannst Du das noch manuell machen. Bei größeren Dateien dauert es Stunden, wenn Du Eintrag für Eintrag durchgehst – und menschliche Fehler sind quasi vorprogrammiert.
Was Du brauchst, ist ein Tool, das CSV-Einträge mit gleichen oder sehr ähnlichen Werten in einer oder mehreren Spalten automatisch erkennt. Und sobald die Duplikate gefunden sind, kannst Du sie bearbeiten oder zusammenführen, um die Daten zu konsolidieren und die Doppelten entfernen.
CSV-Duplikate online zusammenführen

Datablist ist ideal für Daten-Operationen, die mit klassischen Spreadsheets nicht sauber lösbar sind. Nutze es, wenn Du einen starken online CSV editor suchst.
In diesem Guide arbeiten wir mit 2 CSV-Dateien mit tausenden Einträgen. Wir laden beide in eine einzige Collection und deduplizieren die Einträge anhand einer von 4 Spalten. Das Ganze funktioniert natürlich auch mit nur einer CSV.
To download the tutorial CSV files: CSV File 1 and CSV File 2
Die CSV enthält 4 Spalten: First Name, Last Name, Email, Job Title. Wir wollen Einträge zusammenführen, die dieselbe E-Mail-Adresse haben.
Der Ablauf lässt sich so zusammenfassen:
- CSV-Dateien in eine Datablist-Collection laden
- Spalten für den Duplikate-Check auswählen
- Nicht-konfliktierende Duplikate automatisch mergen
- Verbleibende Duplikate manuell zusammenführen
Step 1: Deine CSV-Dateien in eine Datablist-Collection laden
Eine neue Collection erstellen
Der erste Schritt: Lade Deine CSV-Datei in Datablist. Öffne dafür Datablist (No signup required).
Um eine neue Collection zu erstellen, klick auf den Button „New collection“ mit dem +. Sobald die Collection angelegt ist, gib ihr einen Namen und ein Icon.
Dann klickst Du auf Import CSV.
Properties für Deine CSV anlegen
Sobald die CSV geladen ist, kannst Du für Deine Collection Properties anhand der CSV-Spaltennamen erstellen. Datablist zeigt Dir alle Spalten, die in der CSV gefunden wurden, damit Du für jede davon ein Property anlegen kannst.
CSV-Daten haben keine echten Datentypen. Beim Einlesen ist erst mal alles Text. Damit Filter und Sortierung besser funktionieren, versucht Datablist die Datentypen zu erkennen, indem es sich die ersten 100 Zeilen anschaut. Wenn z. B. nur Zahlen vorkommen, wird das Property als Number gesetzt. Ähnlich bei Datum, Email, Checkboxen (true/false) usw.
Prüfen und importieren
Im Review-Schritt werden die CSV-Zeilen direkt aus der Datei angezeigt. Check kurz, ob das Format passt und die Daten konsistent sind. Dann klick auf „Import items“ und fertig! 💪
Wiederhole das für Deine anderen CSV-Dateien
Jetzt hast Du eine Collection mit konfigurierten Properties. Führe den Prozess „Import CSV/Excel“ erneut aus, um Deine weiteren CSV- oder Excel-Dateien in dieselbe Collection zu importieren.
Step 2: Duplikate finden
Nachdem Du die CSV-Dateien geladen hast, kommt Schritt 2: doppelte Werte finden. Klicke in der Collection-Ansicht oben rechts im Menü „Clean“ auf „Duplicates Finder“.
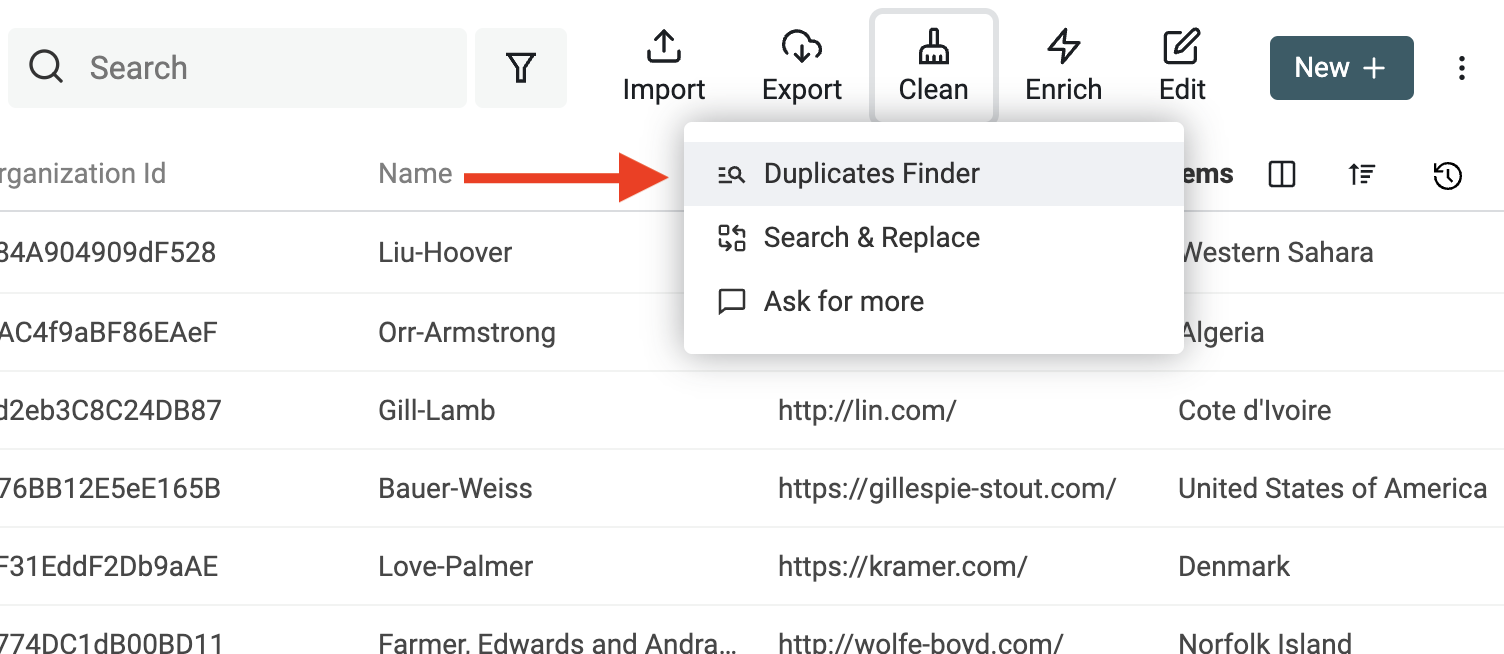
Du hast zwei Modi:
- All Properties – Datablist sucht nach Items, die bei allen Properties identische Werte haben. Zwei Items gelten als ähnlich, wenn alle Properties matchen.
- Selected Properties – Du wählst die Properties aus, die für den Similarity-Check genutzt werden. Zwei Items gelten als ähnlich, wenn sie bei allen ausgewählten Properties die gleichen (oder sehr ähnlichen) Werte haben.
Hier reicht das Property email, um einen Kontakt eindeutig zu identifizieren. Wähle also Selected Properties und setze email.
Nach der Analyse listet Datablist alle Duplikate basierend auf email. Für jedes Item mit einem oder mehreren Duplikaten kannst Du:
- Edit the item – Werte aus unvollständigen Items nutzen, um die Daten in einem Item zu vereinen.
- Merge duplicates – Werte aus Secondary Items in ein ausgewähltes Primary Item übernehmen.
- Delete the extra items – Wenn die Duplikate keinen Mehrwert bringen: einfach entfernen.
Step 3: Duplikate automatisch zusammenführen und kombinieren
In der Regel willst Du alle doppelten CSV-Zeilen zu einem einzigen Item zusammenführen und die Daten konsolidieren – also mergen, ohne dabei Informationen zu verlieren.
Datablist bringt dafür einen Algorithmus mit, der die meisten Duplikate automatisch ohne Datenverlust zusammenführt. Für die restlichen Fälle gibt es einen manuellen Merging Assistant.
Große Listen zu deduplizieren kann dauern. Datablist Auto Merger verarbeitet Deine Duplikate in Bulk und merged sie automatisch, wenn es möglich ist.
Es gibt drei Merging-Algorithmen: Merging non-conflicting rows, Combining duplicate values und Dropping conflicting values. Details findest Du in unserer Doku zum Finden von Duplikaten.
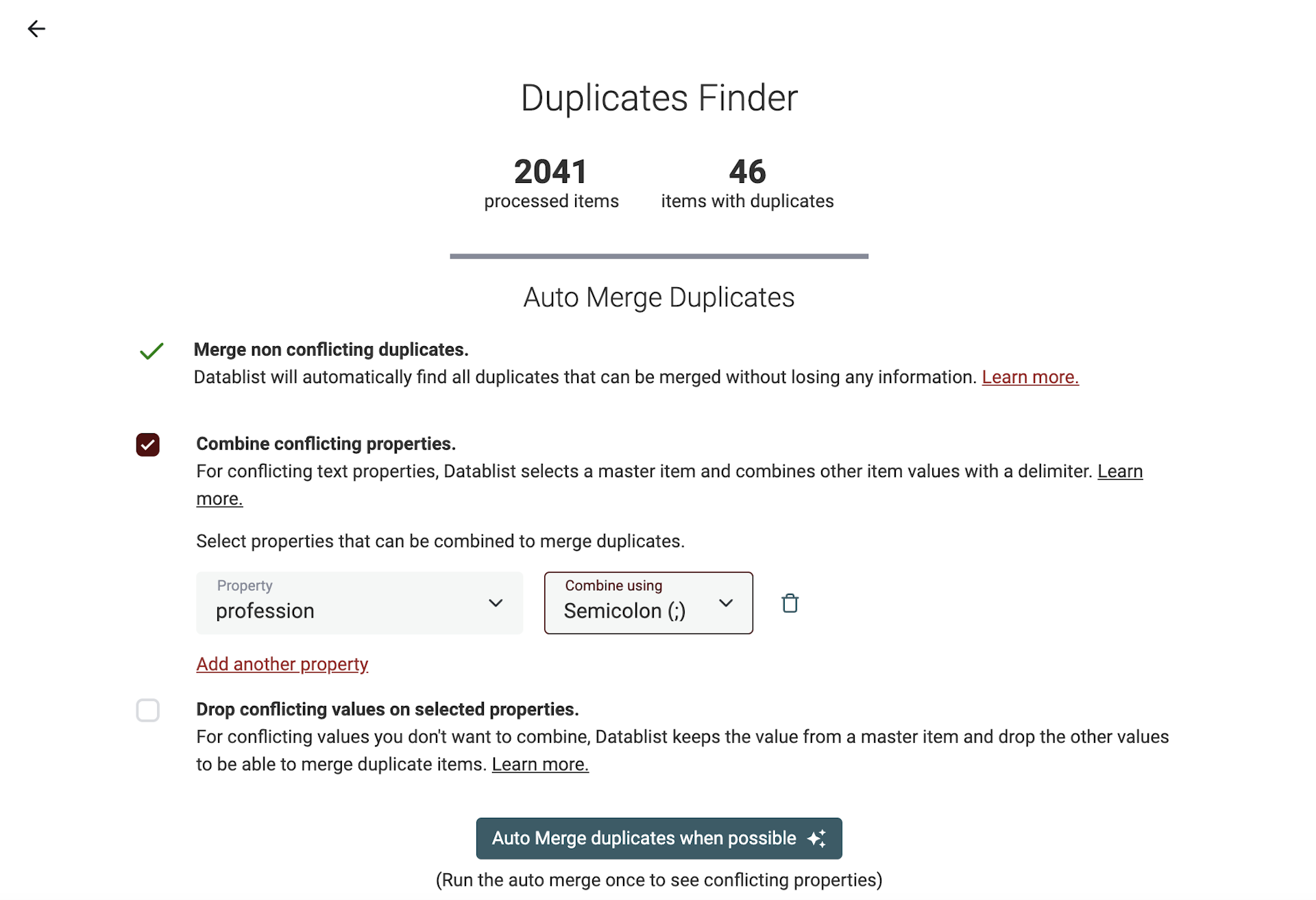
Starte zuerst mit „Merge non conflicting duplicates“, um zu sehen, welche Properties Konflikte haben.

Nicht-konfliktierende Zeilen mergen
Der Algorithmus „Merge non-conflicting duplicates“ macht einen „smart merge“. Er funktioniert, indem er Datensätze mit gleichen oder sich ergänzenden Werten zusammenführt.
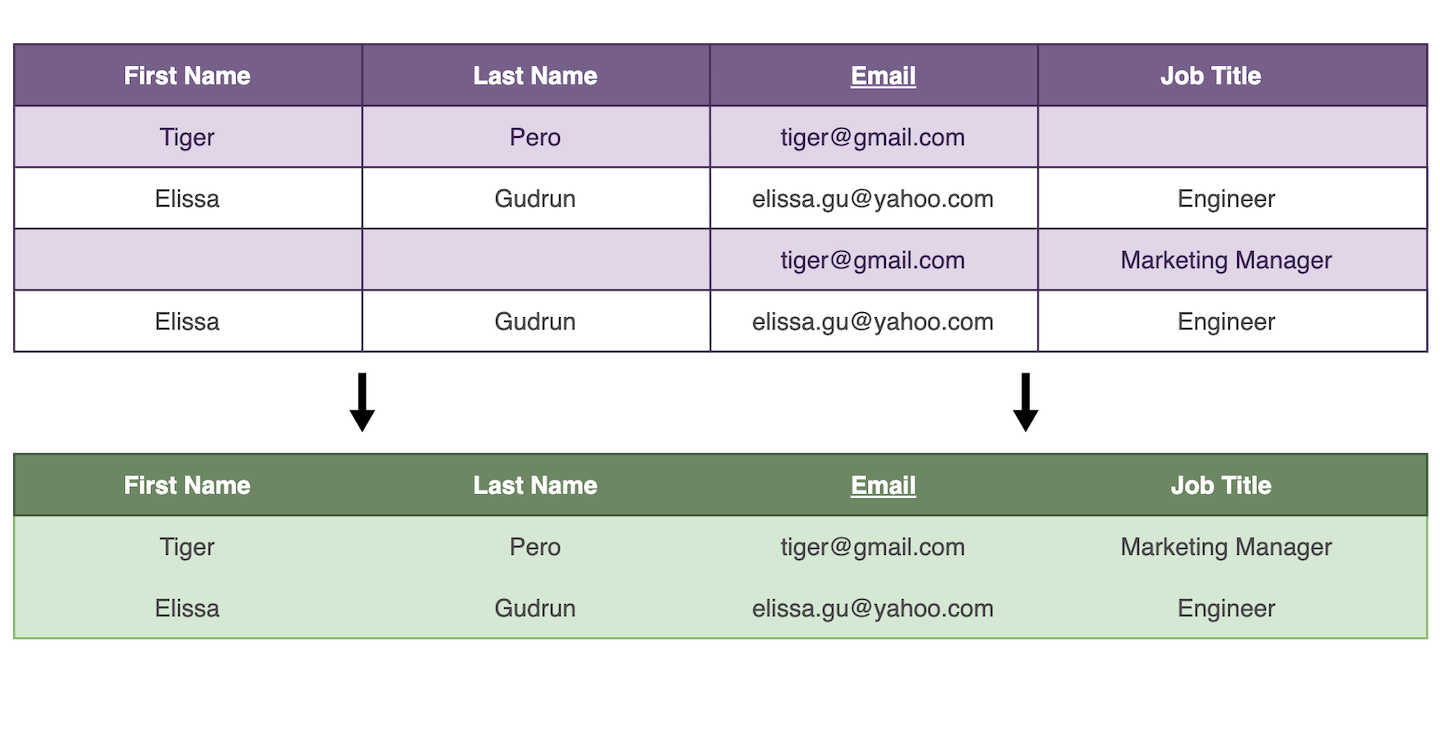
Zum Beispiel diese Duplikate:
email | First Name | Last Name
james@gmail.com | James
james@gmail.com | | Bond
Werden zu:
email | First Name | Last Name
james@gmail.com | James | Bond
Doppelte Werte kombinieren (Consolidate)
Das Kombinieren (bzw. Konsolidieren) ist perfekt, wenn Deine Duplikate unterschiedliche Werte haben, Du sie aber trotzdem mergen willst, ohne Daten zu verlieren.
Zum Beispiel: Das Property Phone wird mit einem semi-colon zusammengeführt:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23 | James |
james@gmail.com | 06 13 42 78 23 | | Bond
Wird zu:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23;06 13 42 78 23 | James | Bond
Jedes Property mit Textinhalt kann kombiniert werden. Verfügbare Delimiter sind line break, semi-colon, comma und space. Du kannst beim Mergen auch mehrere Properties gleichzeitig kombinieren.
Duplikate mergen und Werte kombinieren ist ideal für leads und CRM cleaning. Merge Deine doppelten Leads und kombiniere z. B. Phone, Email, Notes, damit Du am Ende eine saubere Liste hast. Und nachdem Du Deine bereinigte Lead-CSV exportiert hast, importierst Du sie einfach wieder in Dein CRM.
Konfliktierende Werte verwerfen
Dieser Algorithmus behält den Wert aus einem Master-Item und löscht andere konfliktierende Werte, um Leads in einem einzigen Datensatz zusammenzuführen.
Als Master wird das Item gewählt, das bei den meisten Properties Daten enthält.
Nutze die Option drop conflicting values für:
- Technische Properties wie
Account Id, die einen einzigen Wert benötigen. - Properties vom Typ „Relation“, die keine mehreren Werte haben können, z. B.
Lead owner,Account. - Nicht-Text-Properties, die sich nicht kombinieren lassen, z. B. Datetime wie
Last Activity,Contacted onoder Checkboxen.
Step 4: Manueller Merging Assistant
Wenn nach dem Auto Merge noch Duplikate übrig sind, nutze den Merging Assistant. Klicke dafür links bei jeder Duplikat-Gruppe auf „Manual Merging assistant“.
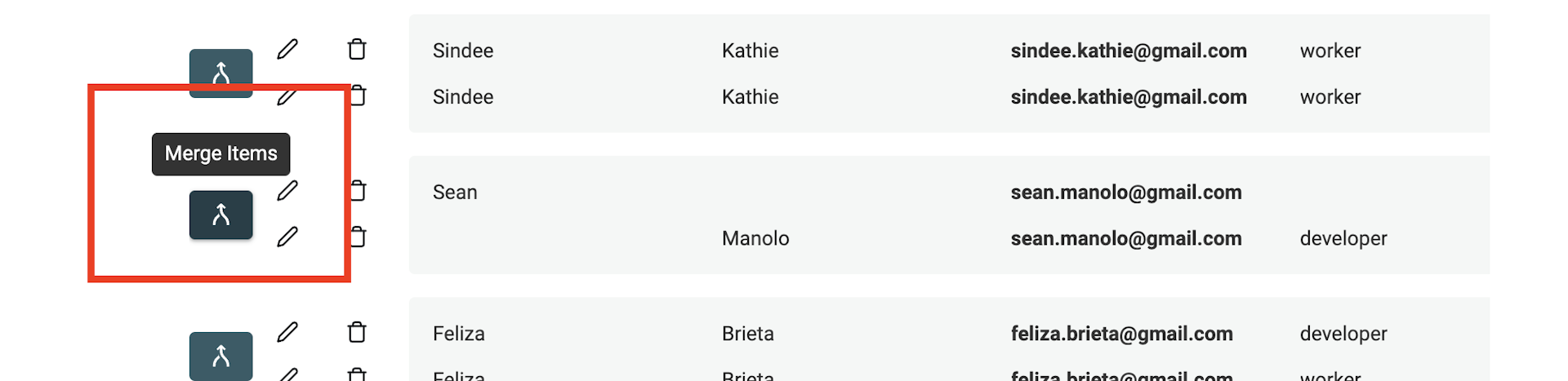
Dadurch öffnet sich ein Merging-Tool. Rechts siehst Du das „Primary Item“, links die übrigen Duplikate als „Secondary Items“. Datablist wählt automatisch das Item mit den meisten Daten als „Primary item“.
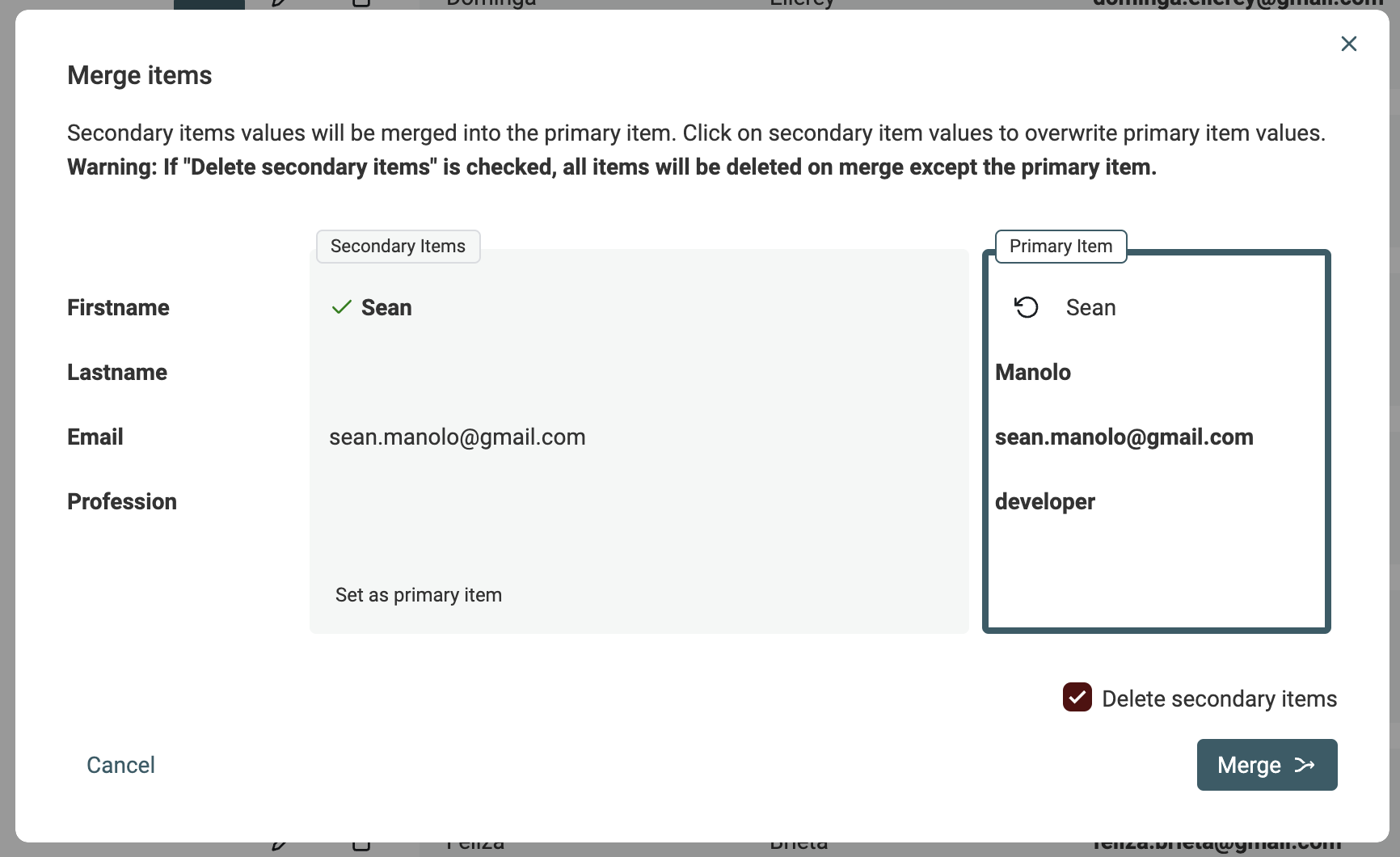
Wenn möglich, werden Values aus den Secondary Items automatisch vorausgewählt, um sie in das Primary Item zu übernehmen. Wenn mehrere Values miteinander im Konflikt stehen, musst Du entscheiden, welchen Wert Du behalten willst.
Wenn das Ergebnis für Dich passt, klick auf Merge, um den Vorgang zu bestätigen. Alle Secondary Items werden gelöscht – übrig bleibt ein einziges, zusammengeführtes Item.
Bei Bedarf als CSV exportieren
Glückwunsch – Du hast Deine CSV-Dateien erfolgreich dedupliziert! Wenn Du das Ergebnis in einem anderen Tool weiterverwenden willst, klick auf „Export“, um die Collection als neue CSV-Datei zu exportieren.
FAQ
Welche weiteren Daten-Operationen bietet Datablist?
CSV files sind überall – als Format für strukturierte Daten in Software-Anwendungen oder Datensätzen. Obwohl CSV so verbreitet ist, ist die Bearbeitung oft mühsam und erfordert nicht selten technisches Know-how.
Für einfache Aufgaben reichen Spreadsheets. Aber sie stoßen schnell an Grenzen, wenn es um Folgendes geht:
Wenn Du mehrere CSV-Dateien über eine eindeutige Spalte zusammenführen willst, schau Dir den Guide join CSV files an.
Kann Datablist große CSV-Dateien verarbeiten?
Datablist kann CSV-Dateien mit bis zu 1,5 Millionen Zeilen verarbeiten. Datablist ist nicht nur dafür gebaut, CSVs zu öffnen, sondern sie auch zu bearbeiten. Um größere Dateien nur anzusehen, eignen sich Analytics-Lösungen. Um große CSV-Dateien zu bearbeiten, ist Datablist weiterhin eine der besten Optionen.
Ist der Dedupe-Algorithmus besser als „Remove duplicates“ in Excel oder Google Sheets?
Spreadsheet-Tools wie Microsoft Excel und Google Sheets haben zwar eine Deduplication-Funktion. Die arbeitet aber im Kern so, dass ähnliche Zeilen einfach gelöscht werden. Für Business-Use-Cases ist „einfach entfernen“ oft nicht ideal.
Der Datablist-Dedupe-Algorithmus merged Duplicate Records: zuerst per Smart Merge, dann durch das Kombinieren von Values und als letzte Option über ein Master-Record-Prinzip.
Wenn Du Fragen hast, kontaktiere uns.