

Wenn Du Prospect-Listen aus Scraping-Daten baust, landest Du früher oder später bei dieser Frage: Wie bereinige und normalisiere ich meine Daten?
Wenn Du das schon mal in Google Sheets versucht hast, weißt Du: Das Tool ist dafür einfach nicht gemacht.
Daten aus LinkedIn haben zum Beispiel oft nur ein Feld „Full Name“, während andere Quellen getrennte Felder für Vor- und Nachname liefern. E-Mail-Adressen enthalten Tippfehler aus dem Scraping-Prozess, Datumsangaben kommen in zig Formaten, usw.
In diesem Guide lernst Du, wie Du 99% der typischen Scraping-Probleme fixst. Und für das letzte 1%: Schreib mir einfach, ich helfe Dir weiter 👨💻
Hier ist eine kurze Übersicht über die Clean-up-Tasks, die wir in diesem Artikel abdecken:
- Text in Datetime, Number, Boolean umwandeln
- HTML in Text umwandeln (HTML-Tags entfernen)
- Überflüssige Leerzeichen aus Texten entfernen
- Daten normalisieren
- Symbole aus Texten entfernen
- Full Name in First Name und Last Name splitten
- Einträge deduplizieren
- E-Mail-Adressen validieren
- Personen- oder Firmennamen aus gescrapten Texten extrahieren
Import aus CSV oder per Copy-Paste
Datablist ist ideal fürs Data Cleaning. Es ist ein online CSV editor mit Features für Cleaning, Bulk Editing und Enrichment. Und es skaliert problemlos bis zu Millionen von Einträgen pro Collection.
Öffne Datablist, erstelle eine Collection und lade Deine CSV-Datei mit den gescrapten Daten hoch.
Um eine neue Collection zu erstellen, klickst Du in der Sidebar auf den +-Button. Dann auf „Import CSV/Excel“, um Deine Datei zu laden. Alternativ kannst Du den Shortcut auf der Getting-Started-Seite nutzen, um direkt zum Import-Schritt zu springen.
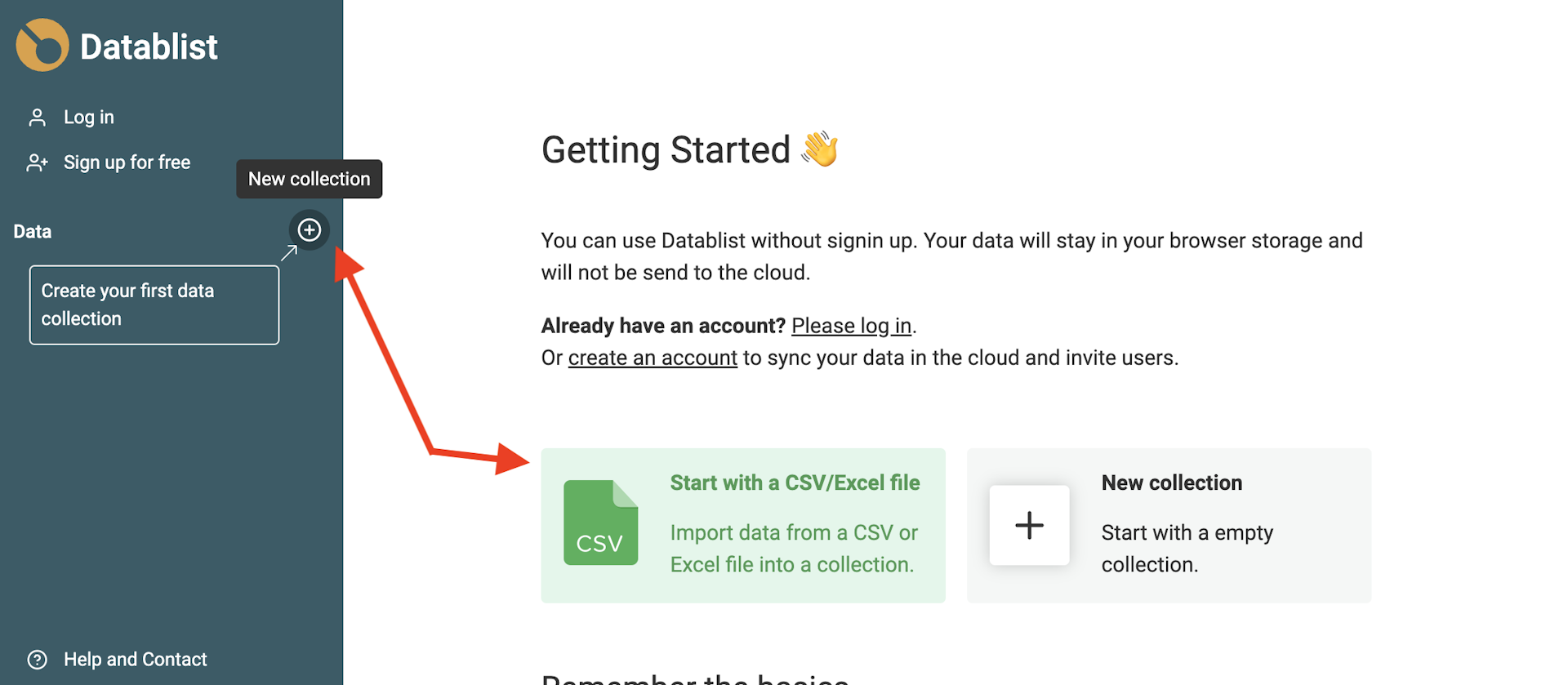
Format automatisch erkennen
Der Datablist Import-Assistent erkennt automatisch E-Mail-Adressen, Datetimes im ISO-8601-Format, Booleans, Numbers, URLs usw. wenn sie korrekt formatiert sind.

Wenn Deine Daten eine komplexere Analyse brauchen (anderes Datumsformat, Tippfehler in URL oder E-Mail), importiere sie als Text-Property. Im nächsten Abschnitt zeige ich Dir, wie Du Text-Properties in Datetime, Boolean oder Number konvertierst.
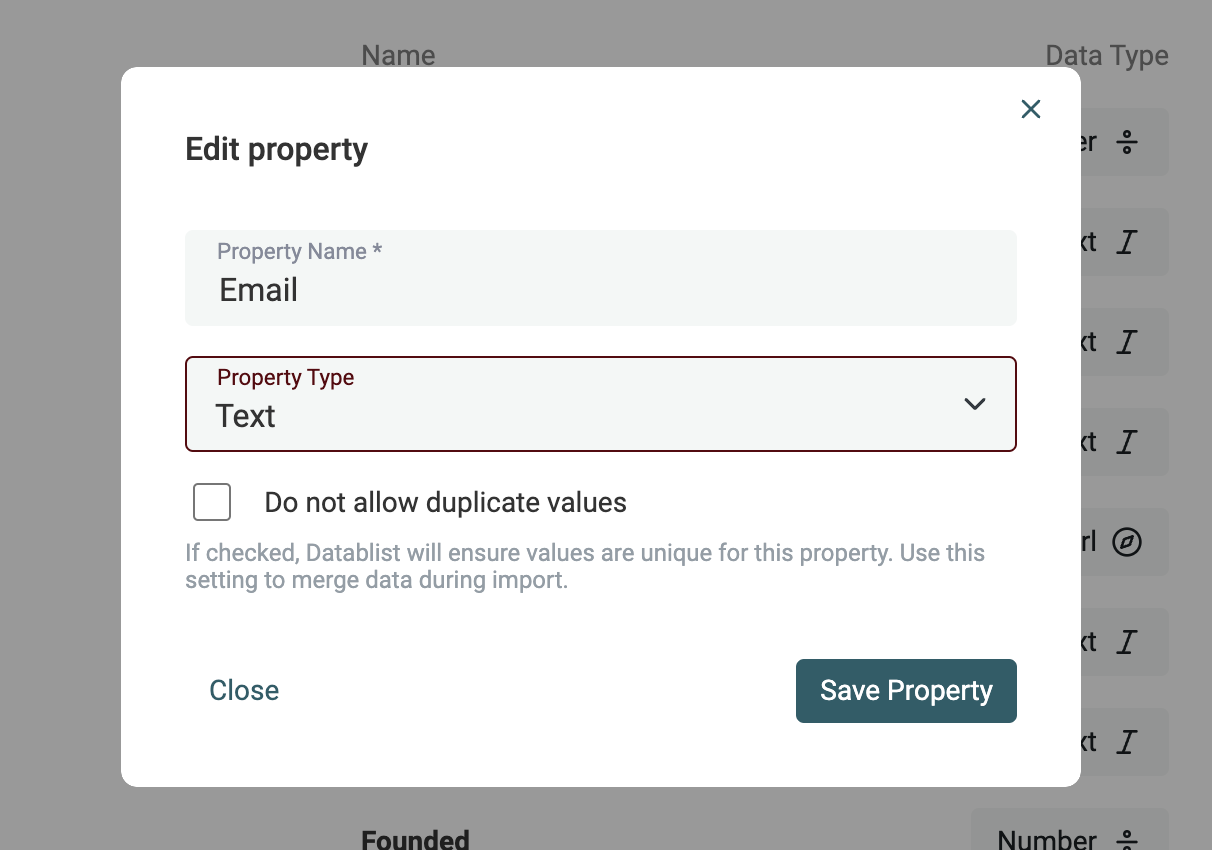
Text in Datetime, Boolean, Number umwandeln
Marie Kondo sagt: „Life truly begins after you have put your house in order.“ Gilt auch für Scraping-Daten: „Sales truly begins after you have put your data in order“! 😅
Nach Datum (Erstellungsdatum, Funding-Date, etc.), Zahl (Preis, Mitarbeiterzahl) oder Boolean zu filtern ist viel einfacher, wenn das echte Datentypen sind und nicht einfach nur Text.
Öffne das Tool „Text to Datetime, Number, Checkbox“ im Menü „Clean“.
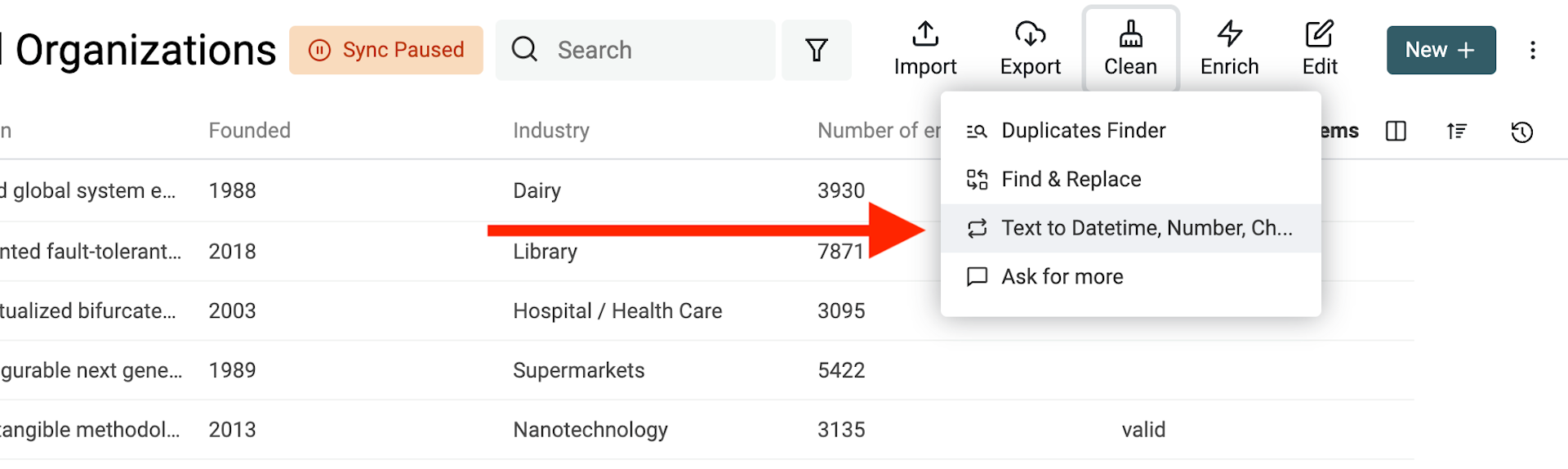
Beliebigen Text in ein Datetime-Format konvertieren
Datetime hat ein internationales Standardformat namens ISO 8601 mit klar definierter Struktur. Wenn Deine Daten ISO 8601 nutzen, wird beim Import automatisch eine Datetime-Property erstellt.
Für Date- und Datetime-Werte in anderen Formaten musst Du das verwendete Format angeben, damit Datablist es in strukturierte Datetime-Werte konvertieren kann.
Wähle die Property aus und dann „Convert to Datetime“.
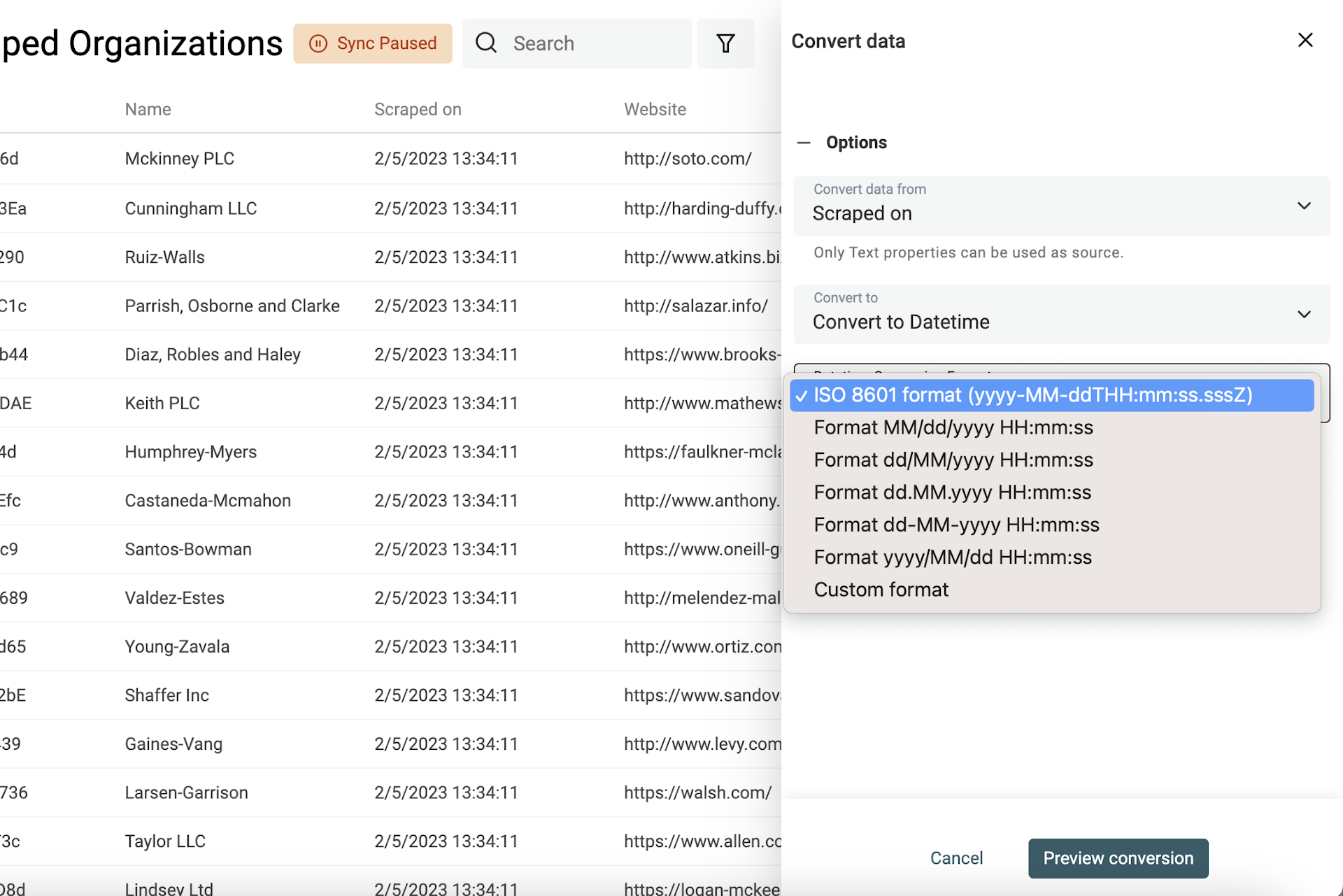
Du kannst aus gängigen Formaten wählen (wie sie Google Sheets und Excel verwenden) oder „Custom format“ auswählen und Dein Format selbst definieren.

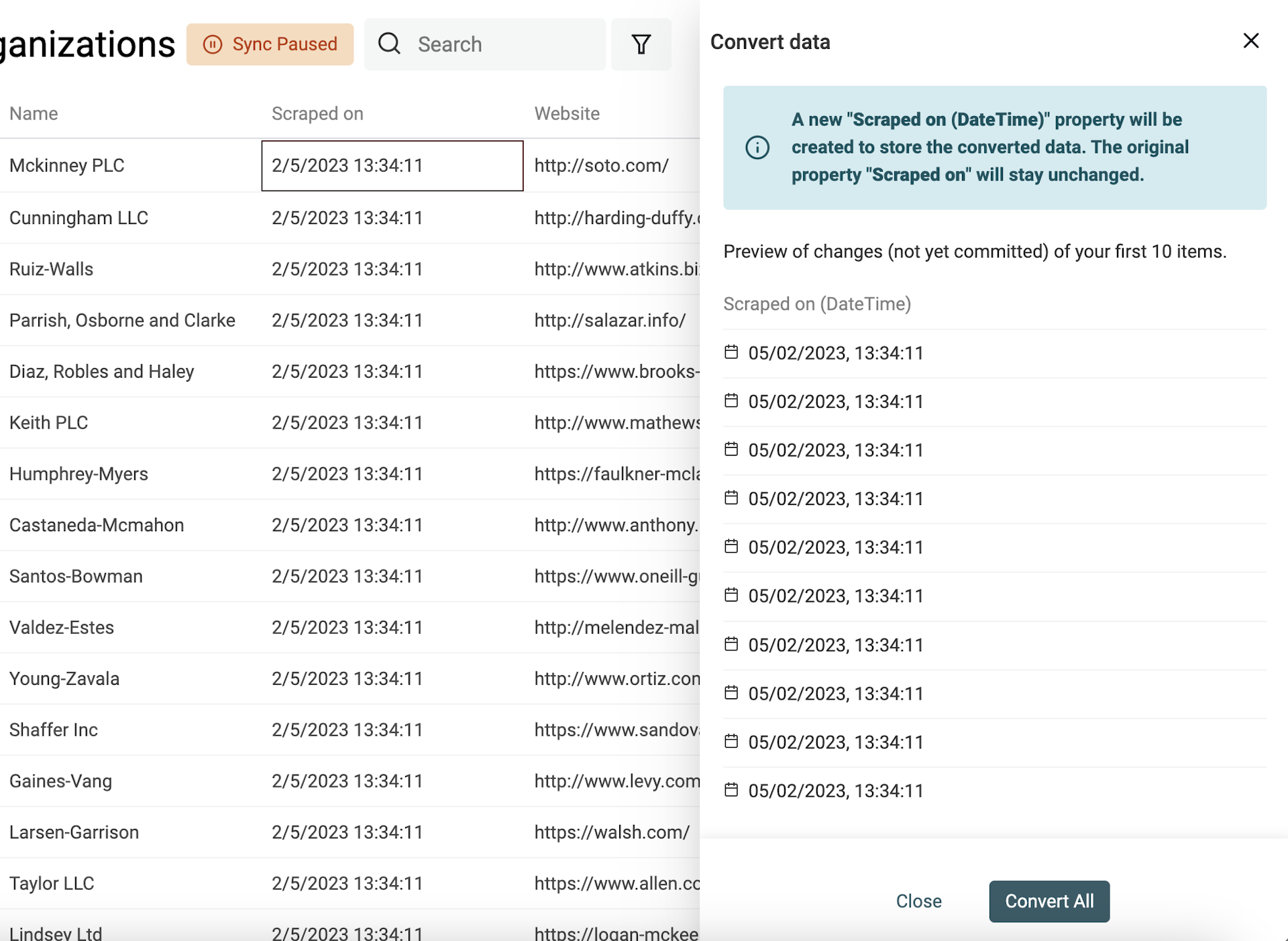
👉 Schau in unsere Dokumentation, um mehr über Custom-Datetime-Formate zu lernen.
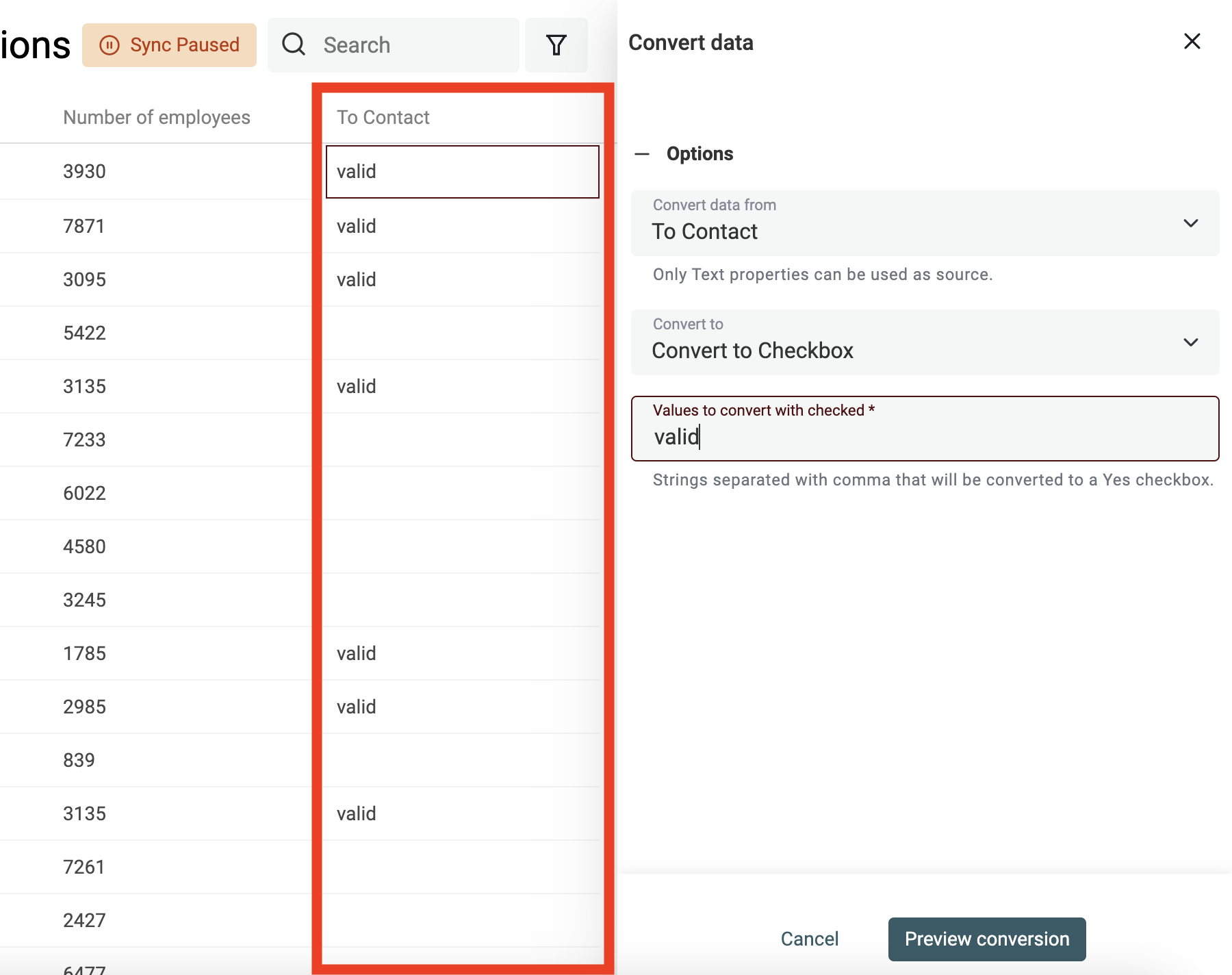
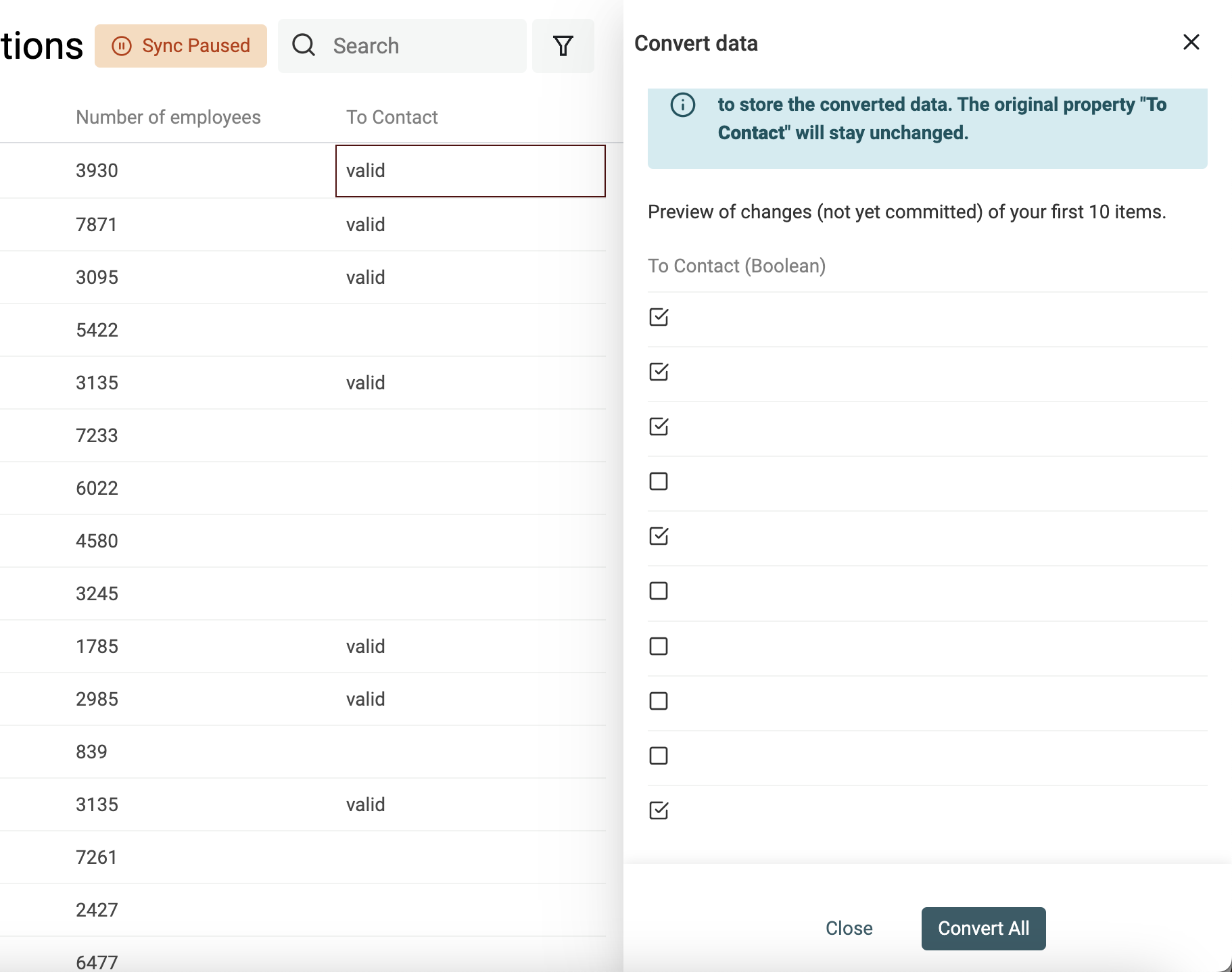
Checkboxes (Boolean) aus Textwerten erstellen
Datablist konvertiert beim Import automatisch Spalten wie „Yes, No“, „TRUE, FALSE“ usw. in Checkbox-Properties. Für komplexere Fälle nutzt Du den Converter.
Definiere die Werte (durch Kommas getrennt), die in eine aktivierte Checkbox umgewandelt werden sollen. Alle anderen Werte bleiben deaktiviert.
Zahlenwerte aus Texten extrahieren
Nutze den Converter „Text to number“, um:
- Zahlen mit eigenen Dezimal- und Tausendertrennzeichen zu normalisieren
- Zahlen aus Texten mit Buchstaben zu extrahieren
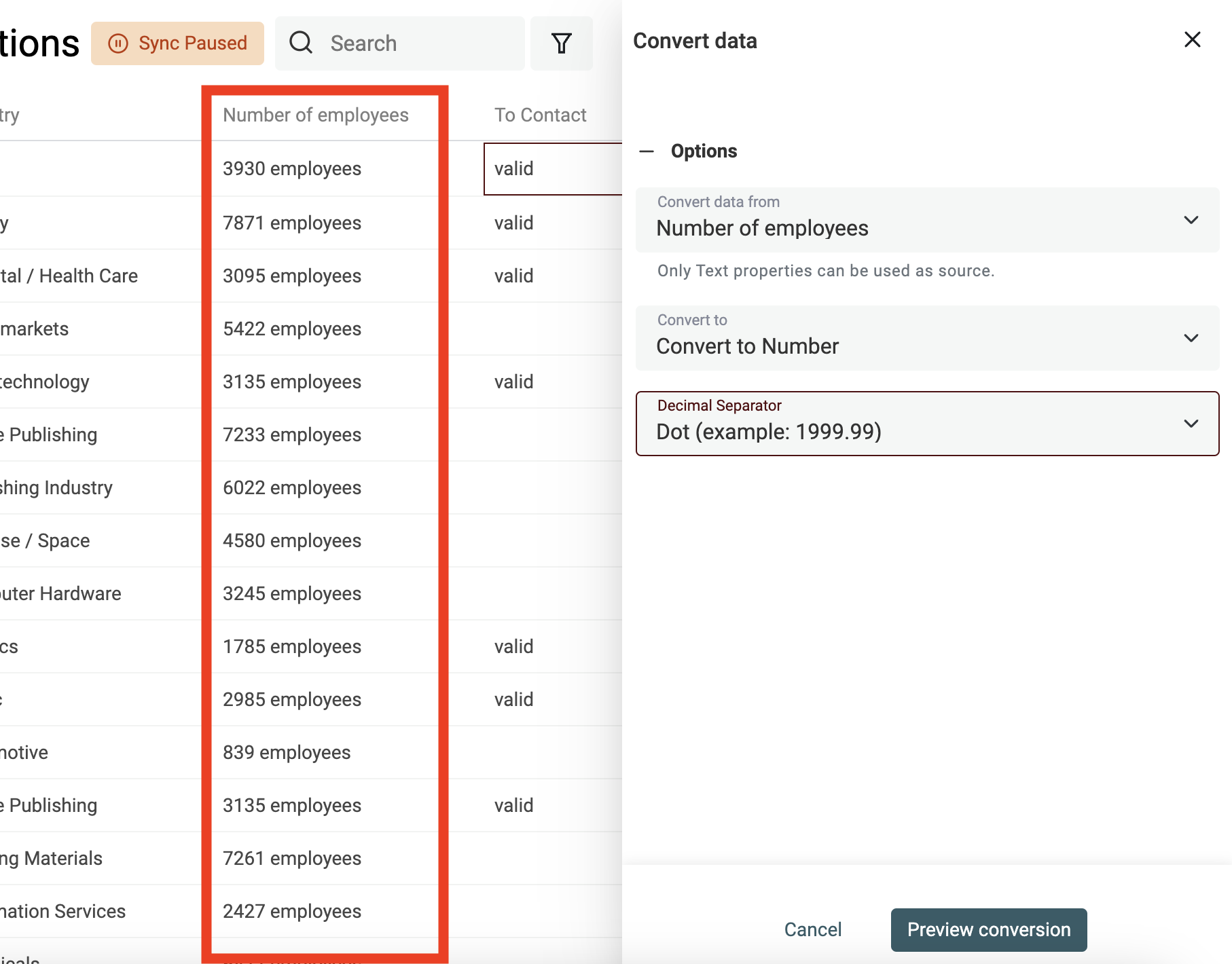
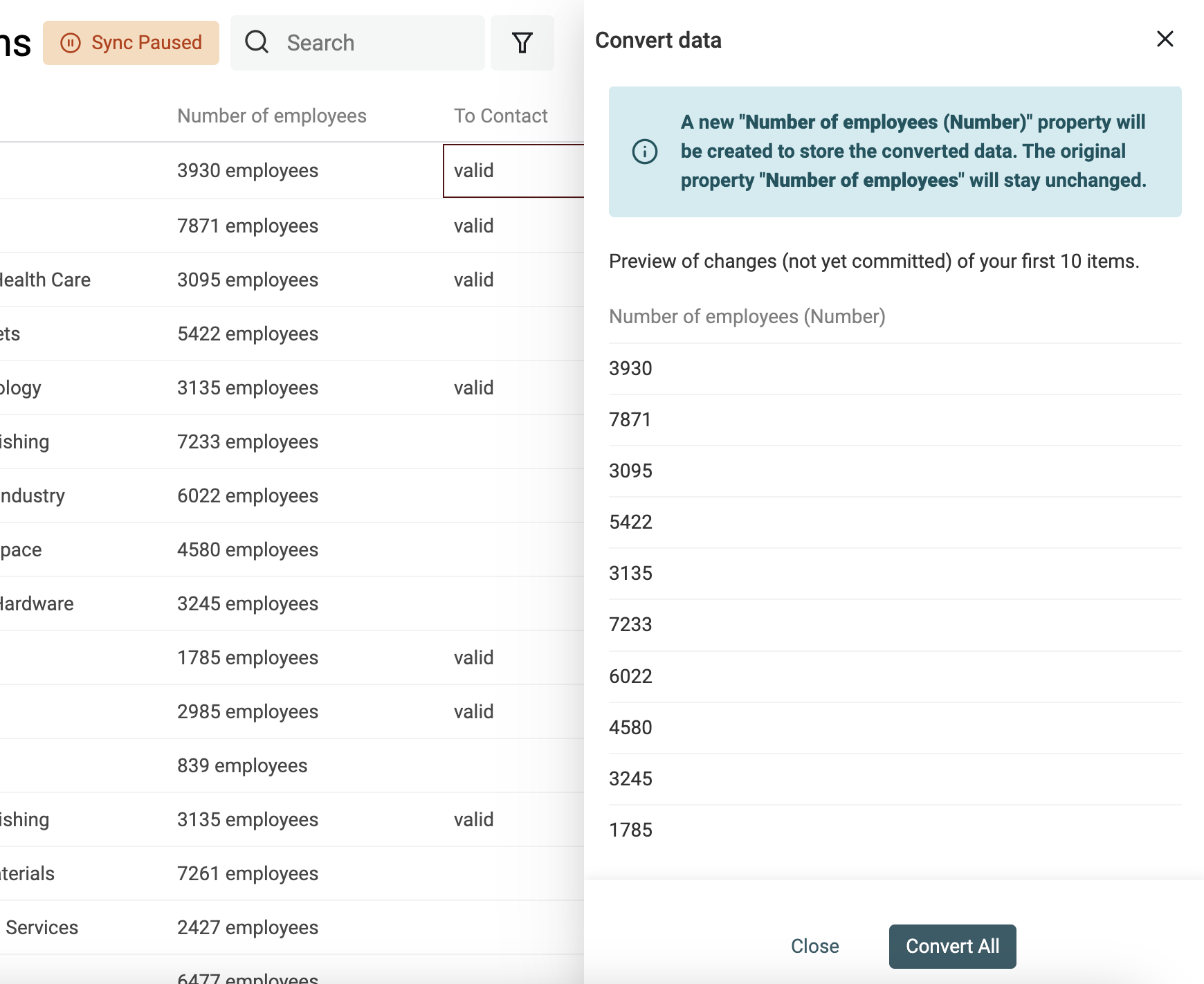
👉 Schau in unsere Dokumentation, um mehr zur Number-Conversion zu erfahren.
Daten bereinigen
HTML in Text umwandeln
Scraping-Tools parsen HTML-Code — und dadurch landen oft HTML-Tags in Deinen Textfeldern.
HTML enthält Links, Bilder und Listen mit Bullet Points. Außerdem ist es in Absätzen, Zeilenumbrüchen und Multi-Lines aufgebaut.
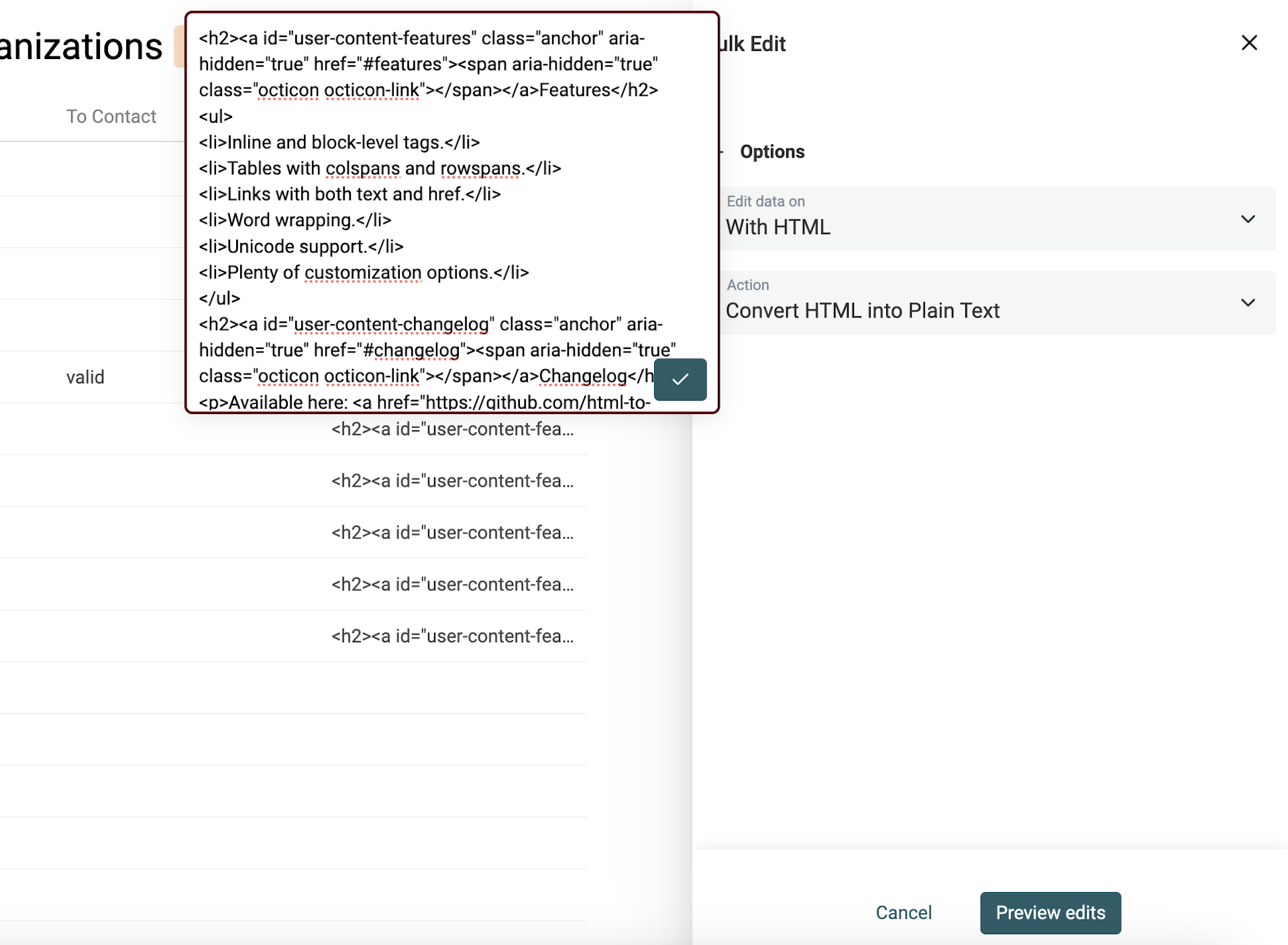
Das Ziel: Einen Teil dieser Struktur behalten, aber den nicht-lesbaren Code in Klartext umwandeln.
Der Datablist HTML-to-Text Converter behält Newlines und wandelt Bullet Points in Listen um, die mit - beginnen.
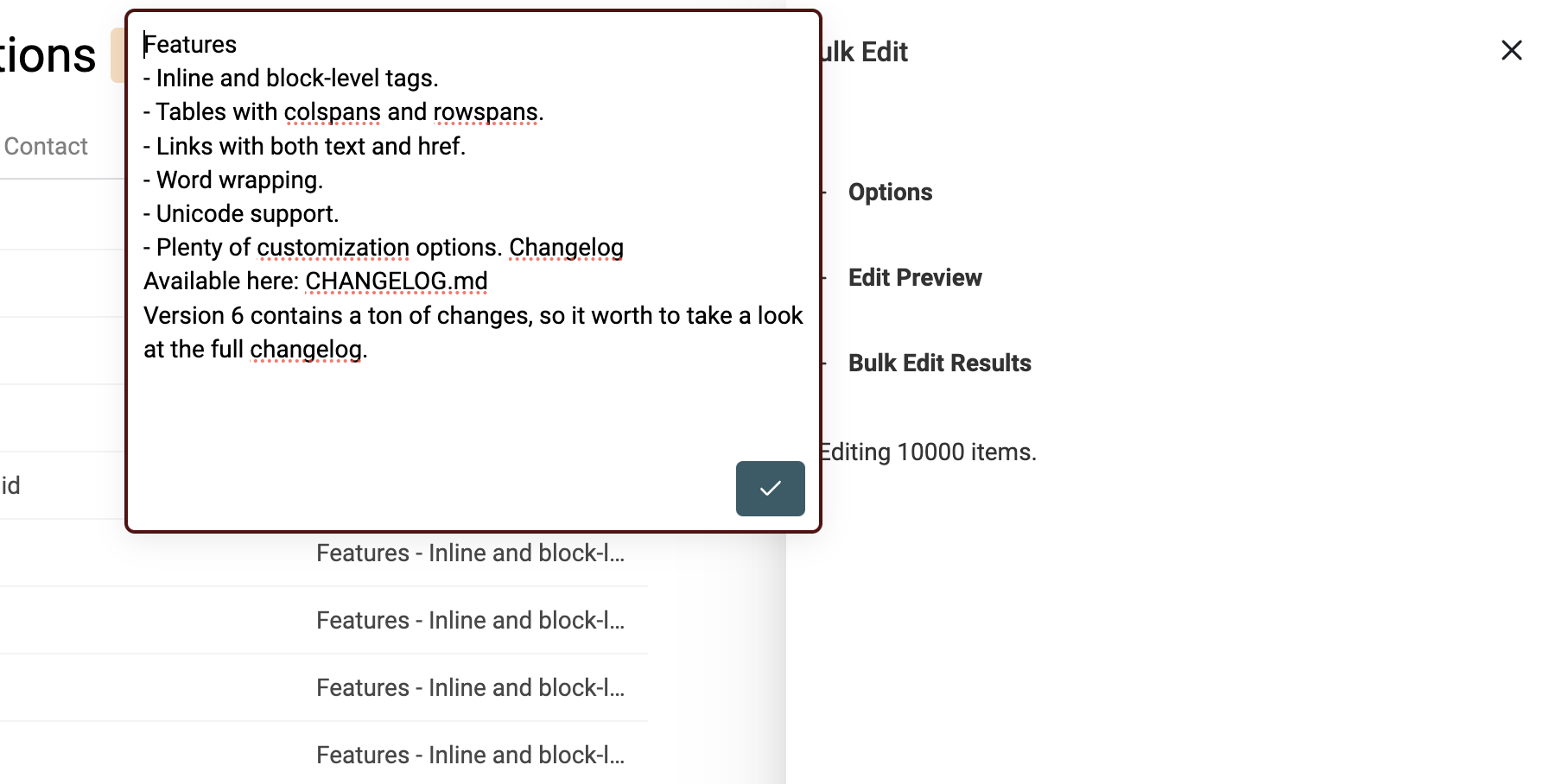
Um Text mit HTML-Tags in Plaintext zu transformieren, öffne das Bulk Edit Tool im Edit Menü.
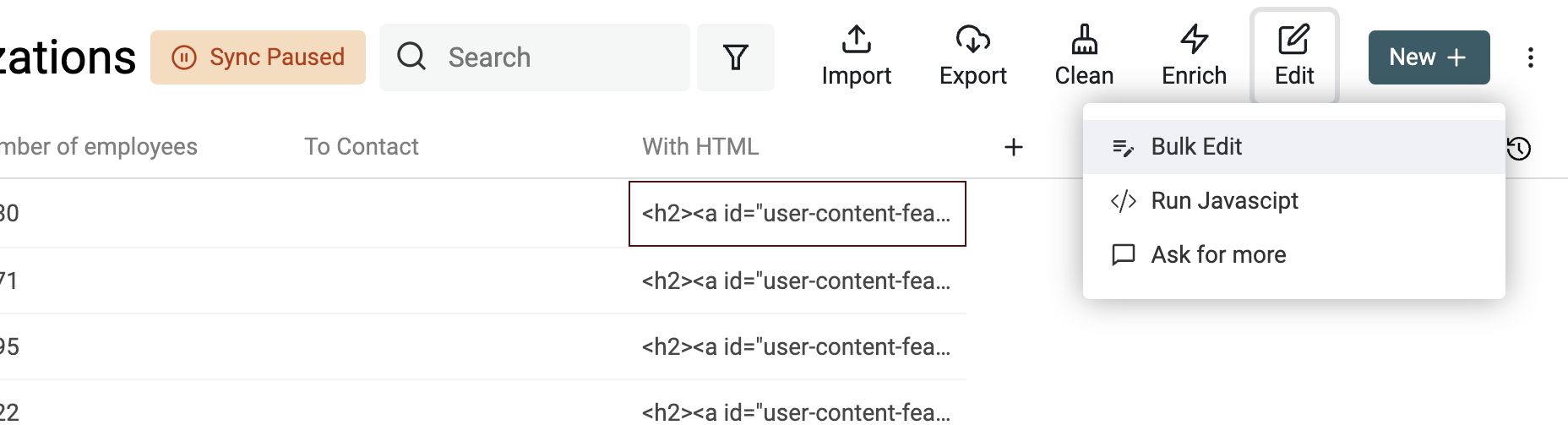
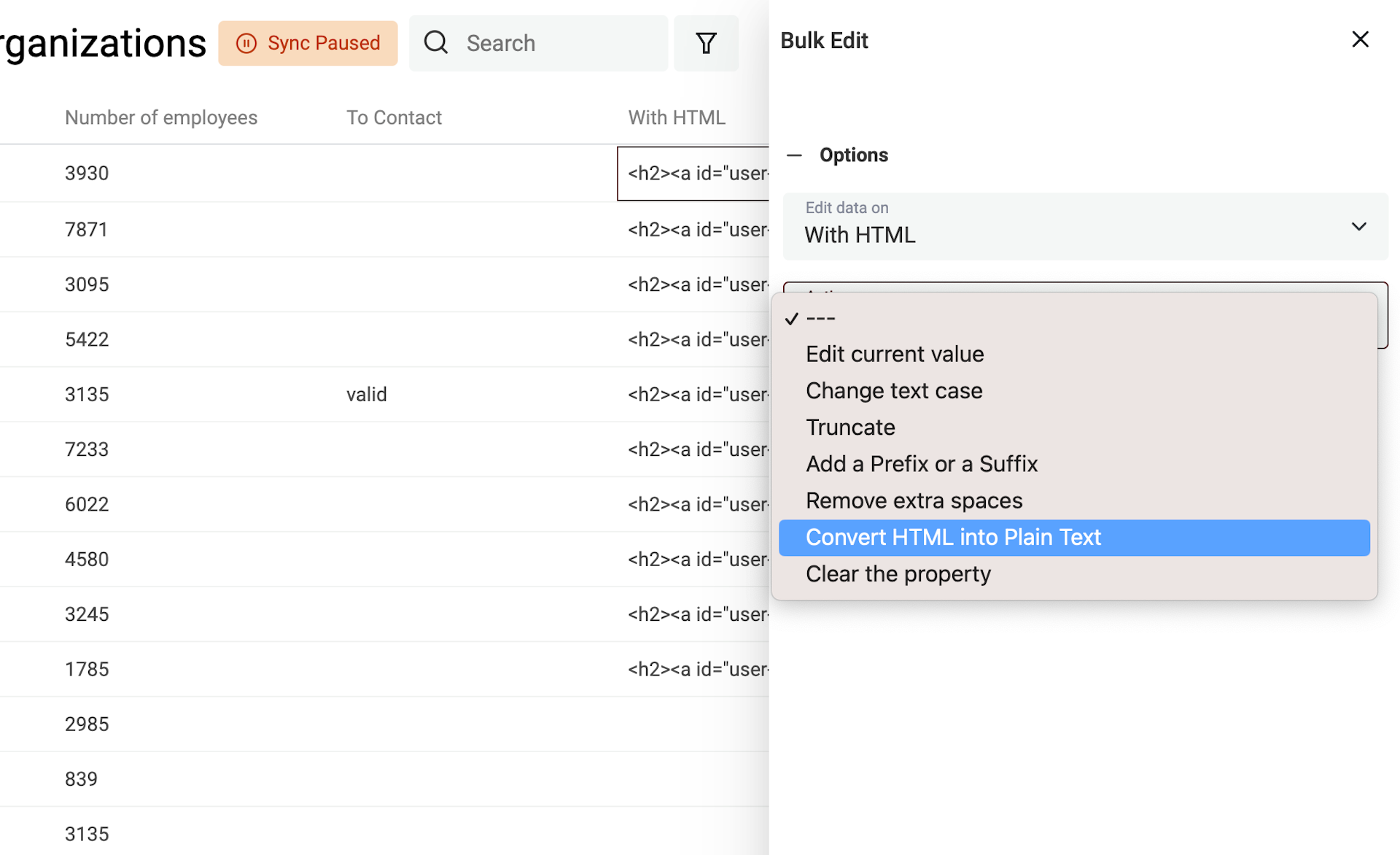
Wähle die Property mit den HTML-Tags aus und dann „Convert HTML into plain text“.
Überflüssige Leerzeichen entfernen
Ein weiteres Standardproblem bei Scraping-Daten: zu viele Leerzeichen. Die kommen durch Zeilenumbrüche, Tab und andere Zeichen, die im HTML als Whitespace auftauchen.
Datablist hat dafür ein Cleaning-Tool, das extra Spaces zuverlässig rausnimmt.
- Entfernt doppelte/mehrfache Leerzeichen zwischen Wörtern
- Entfernt leere Zeilen
- Entfernt führende und nachgestellte Leerzeichen pro Zeile
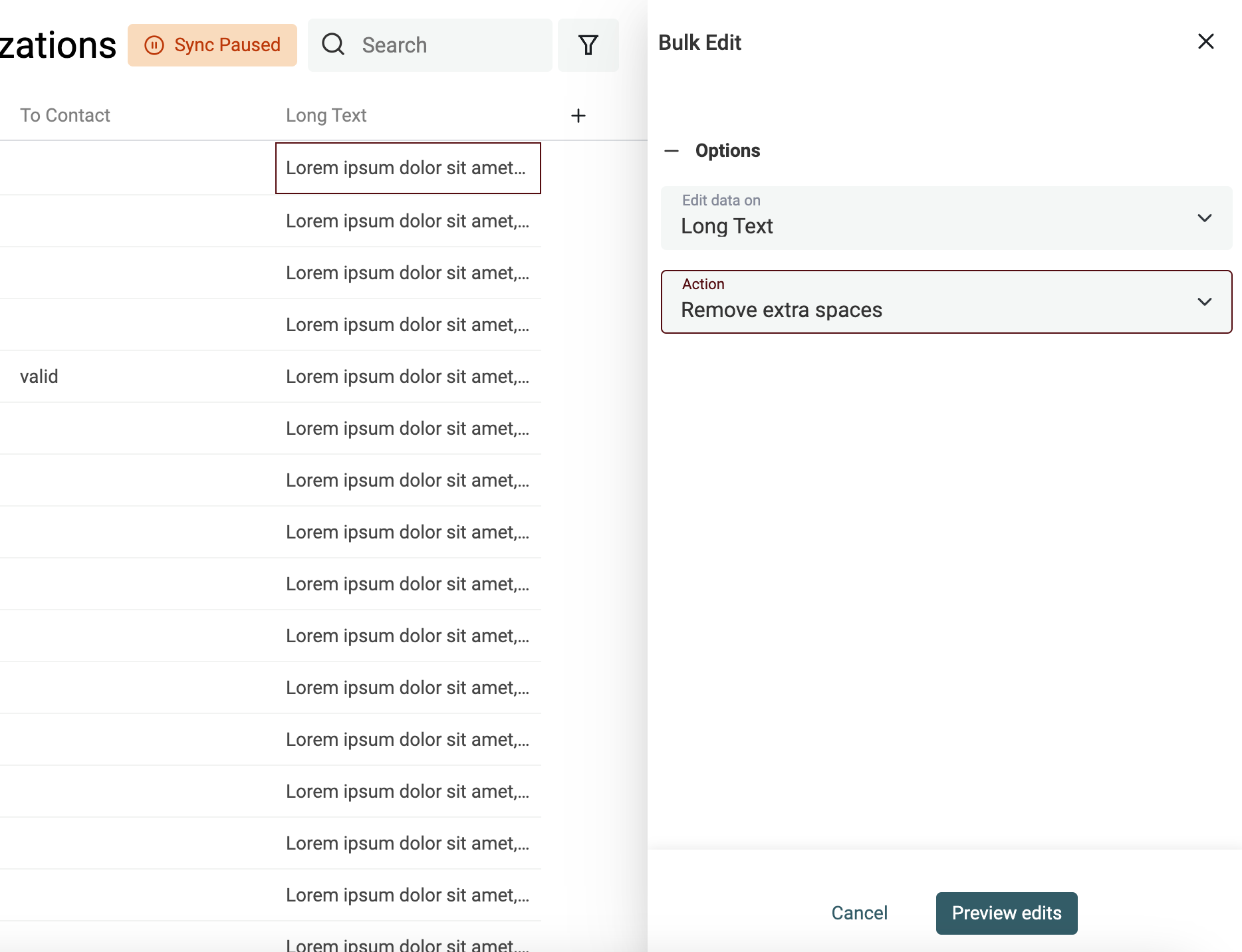
Um extra Spaces zu entfernen, öffne „Bulk Edit“ im Menü „Edit“. Wähle Deine Property und dann die Action „Remove extra spaces“.

Groß-/Kleinschreibung bereinigen
Die Schreibweise anzupassen ist simpel: Öffne das „Bulk Edit“ Tool im Menü „Edit“.
Wähle die Property, die Du bearbeiten willst, und nutze die Action „Change text case“.
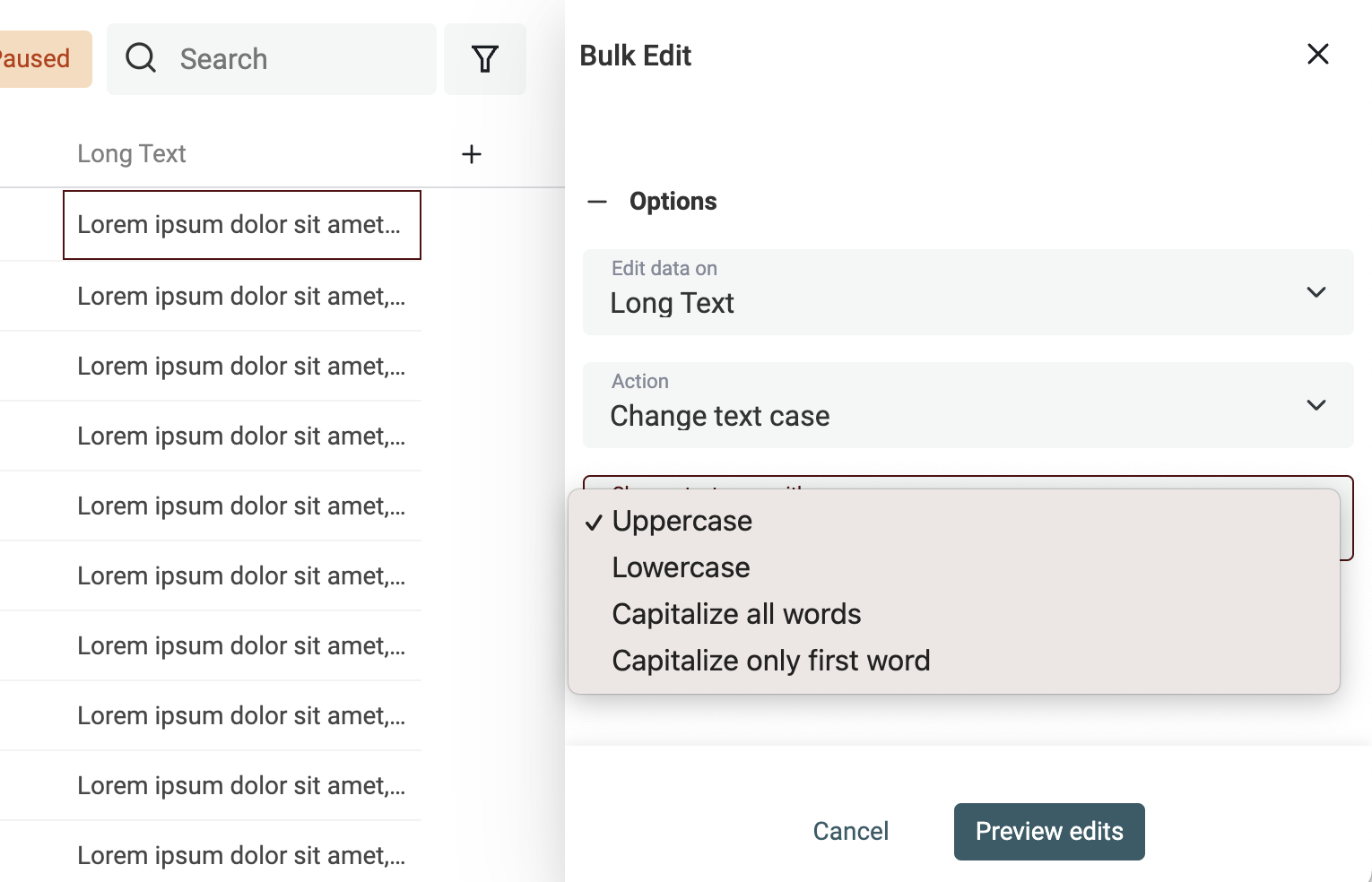
Es gibt 4 Modi:
- Uppercase - Alle Buchstaben werden in Großbuchstaben konvertiert. Bsp.:
john=>JOHN - Lowercase - Alle Buchstaben werden in Kleinbuchstaben konvertiert. Bsp.:
API=>api - Capitalize - Der erste Buchstabe jedes Wortes wird groß geschrieben. Bsp.:
john is a good man=>John Is A Good Man - Capitalize only the first word - Nur der erste Buchstabe des ersten Wortes wird groß geschrieben. Bsp.:
john is a good man=>John is a good man
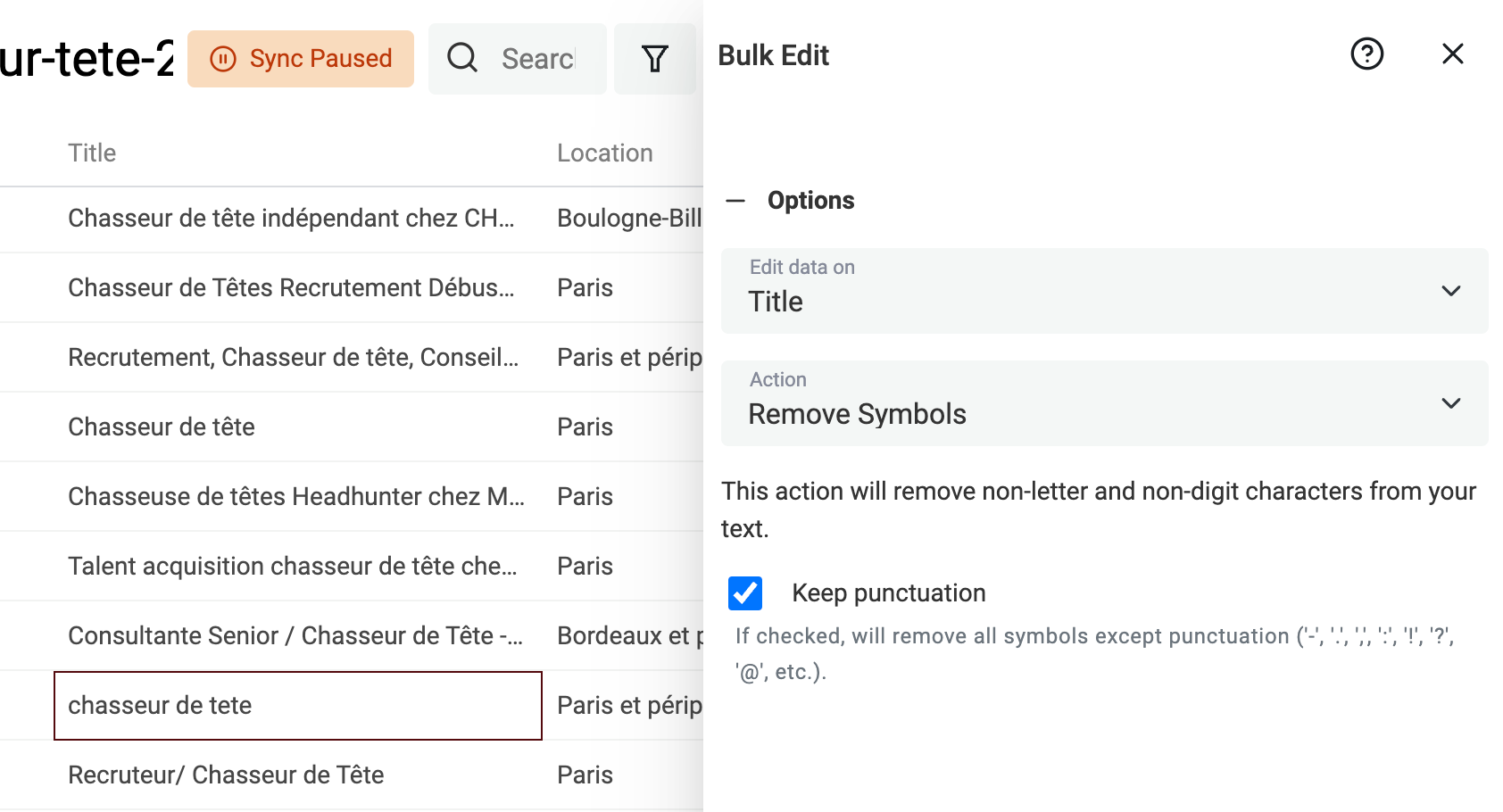
Symbole aus Texten entfernen
Texte, die aus HTML gescraped wurden oder aus User Inputs kommen (z. B. LinkedIn Profile Titles), enthalten oft Symbole: Smileys und andere Sonderzeichen, die Deine Datenverarbeitung stören. Ein einzelner Smiley am Ende eines Namens kann z. B. verhindern, dass ein deduplication algorithm den Datensatz korrekt erkennt.
Datablist hat dafür einen eingebauten Processor, der Nicht-Text-Symbole aus Deinen Daten entfernt.
Klicke im Menü „Edit“ auf „Bulk Edit“, wähle eine Text-Property und dann die Transformation „Remove symbols“.
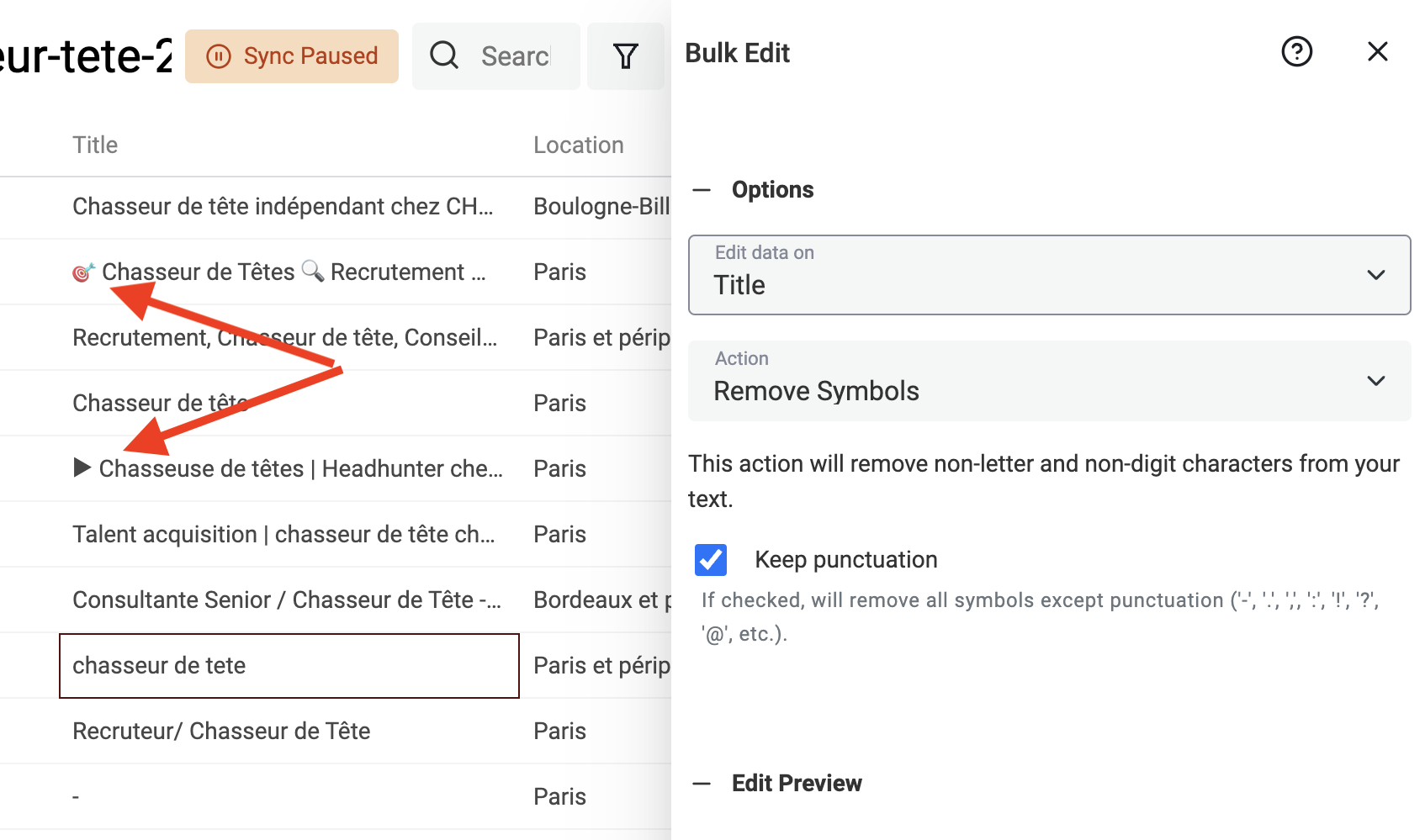
Wenn die Preview passt, starte die Transformation für alle Items.
Normalisierung mit Find and Replace
Wenn Du Segmente in Deinen prospect lists bauen willst, musst Du Deine Daten normalisieren.
- Job Titles normalisieren
- Länder, Städte normalisieren
- URLs normalisieren
- usw.
Dein Ziel: Ein Free-Text-Feld auf eine überschaubare Auswahl an Werten reduzieren. Oder Texte auf eine „Basis-Version“ bringen (z. B. URL mit Pfad → nur Domain).
Datablist hat dafür ein starkes Find-and-Replace-Tool. Es funktioniert mit normalem Text und mit Regular Expressions.
Regular Expressions sind nicht gerade „easy“, aber extrem mächtig.
Hier ein paar Beispiele, wie Du mit RegEx Scraping-Daten sauber bekommst.
Query-Parameter aus einer URL entfernen
Gescrapte URLs enthalten oft unnötige Query-Parameter (Tracking/Marketing). Wenn Du sie entfernst, bekommst Du saubere URLs — und Du kannst sie besser für Deduplication nutzen, z. B. um über die URL duplicate items zu finden.
Um Query-Parameter zu entfernen, aktiviere „Match using regular expression“ und nutze folgenden Ausdruck mit leerem Replacement-Text:
\?.*$
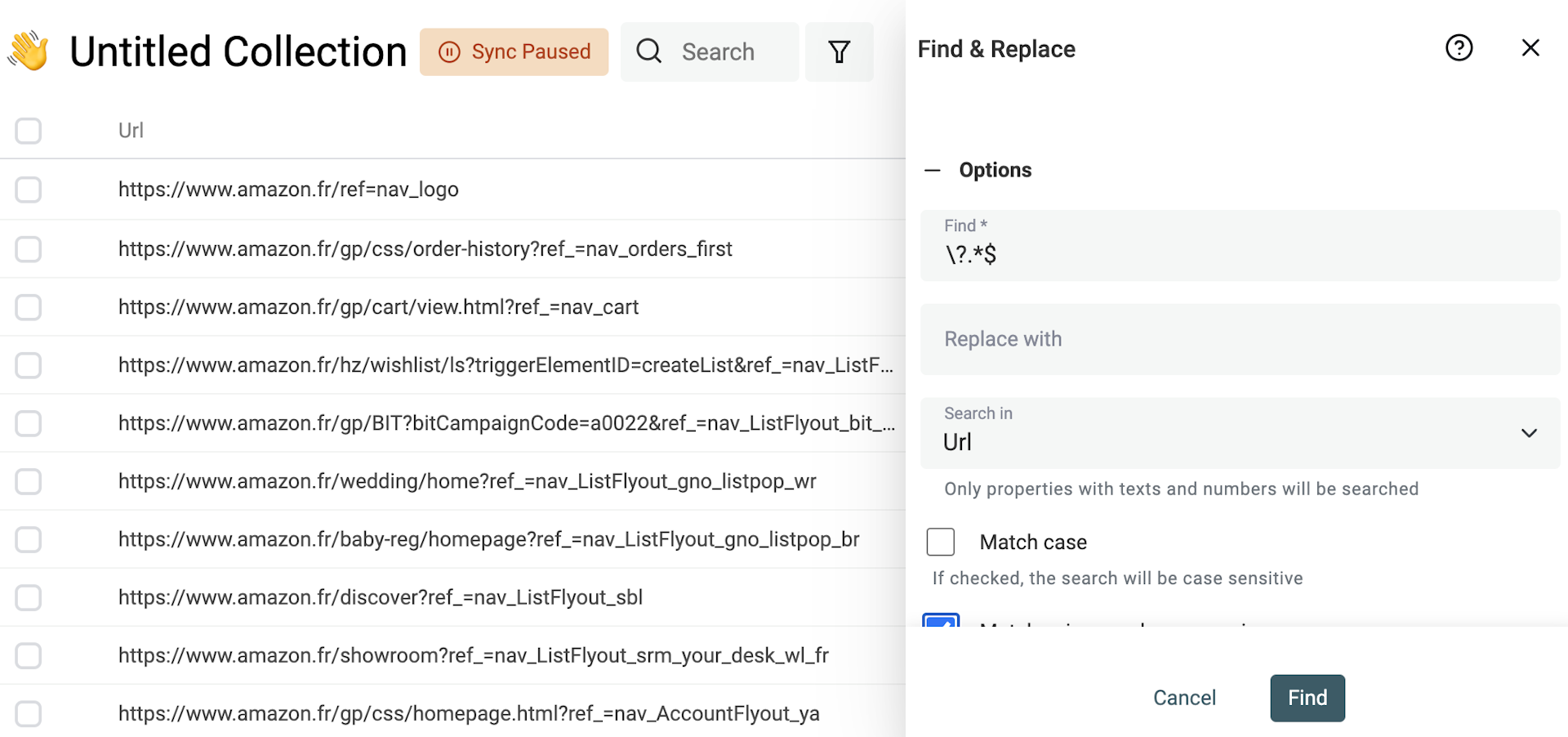
Wende es auf Deine URL-Property an.

Domain aus E-Mail-Adressen ziehen
Ein weiterer Use Case für Find and Replace mit Regular Expressions: Domains aus E-Mail-Adressen extrahieren.
Dupliziere Deine E-Mail-Property, damit Du die Quelldaten behältst. Dann nutze folgenden Ausdruck mit leerem Replacement-Text:
^(\w)*@

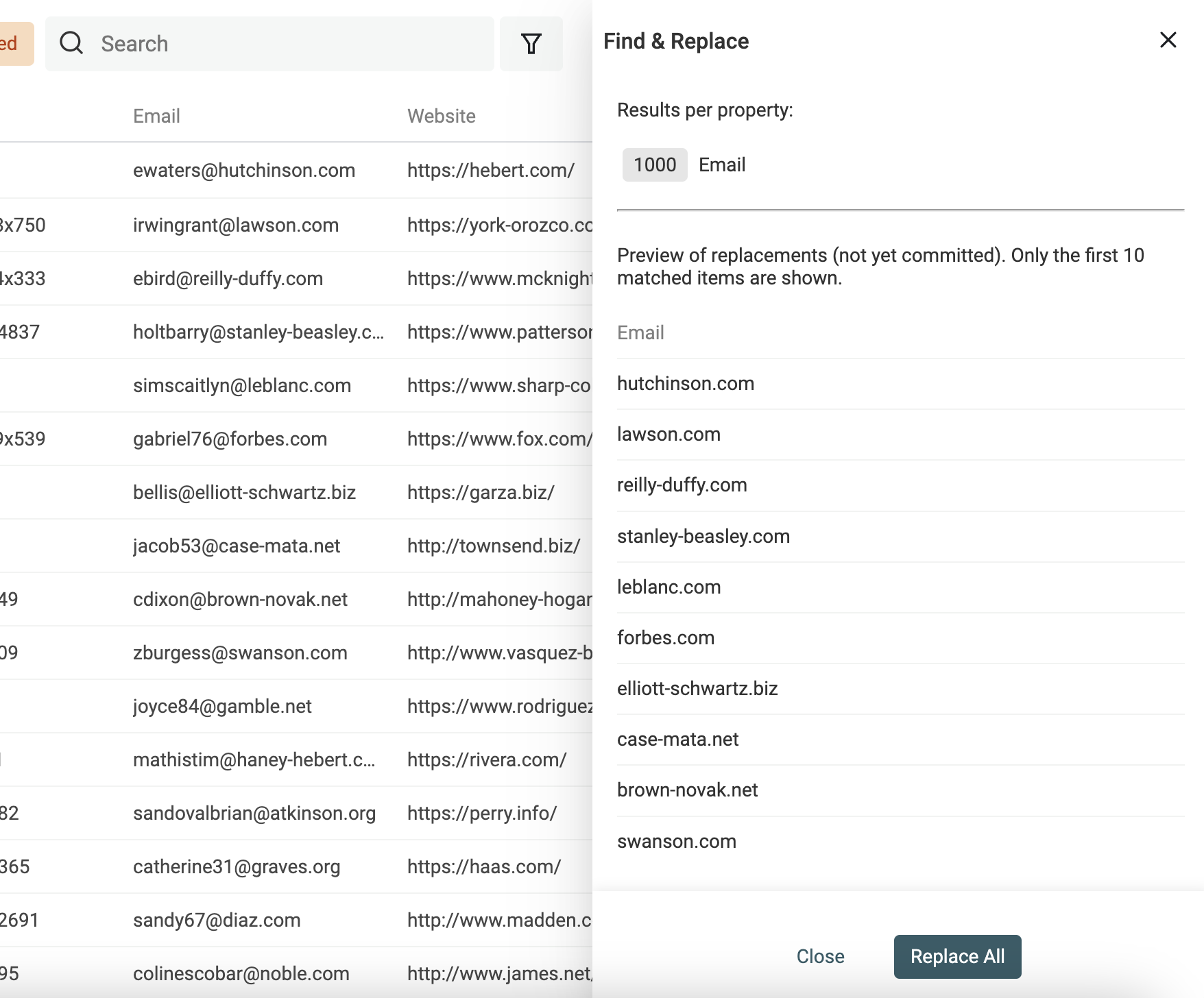
👉 Mehr dazu findest Du in unserer Find-and-Replace-Dokumentation.
Full Name in First Name und Last Name splitten
Wenn Du Lead-Listen scrapest, bekommst Du oft Kontakte mit „Full Name“, den Du in „First Name“ und „Last Name“ aufteilen musst. Ein Name sauber in seine Bestandteile zu zerlegen, ist ein wichtiger Schritt.
Vorname/Nachname getrennt zu haben ist z. B. hilfreich, um Menschen in Cold Emailing Kampagnen persönlicher anzusprechen, um das Geschlecht abzuleiten oder um akademische Titel zu erkennen.
Namen zu splitten kann tricky sein. Zum Glück bietet Datablist ein einfaches Tool, um „Name“ anhand von Leerzeichen in zwei Werte zu zerlegen.
Starte, indem Du im Menü „Edit“ das Tool „Split Property“ öffnest.
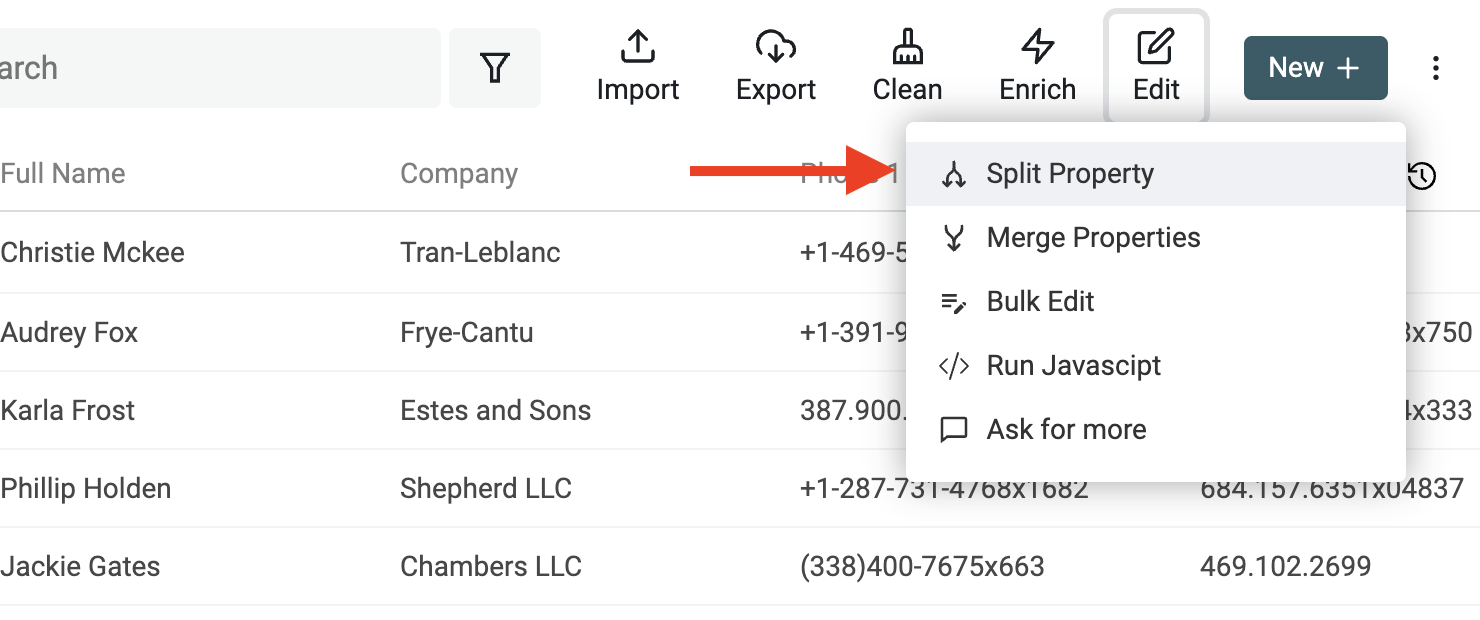
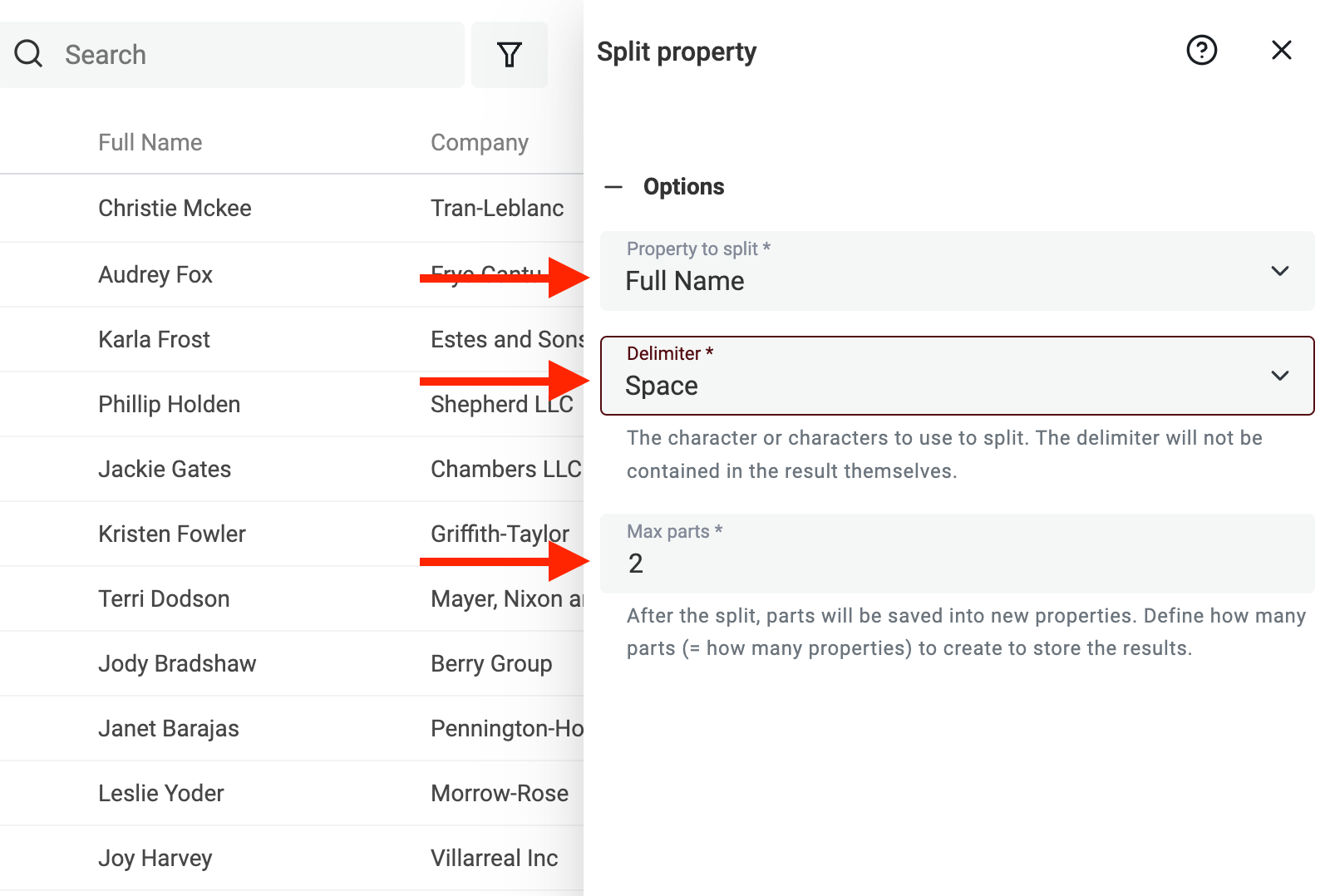
Dann wähle die Property mit den Namen aus. Setze als Delimiter Space und die maximale Anzahl an Parts auf 2.
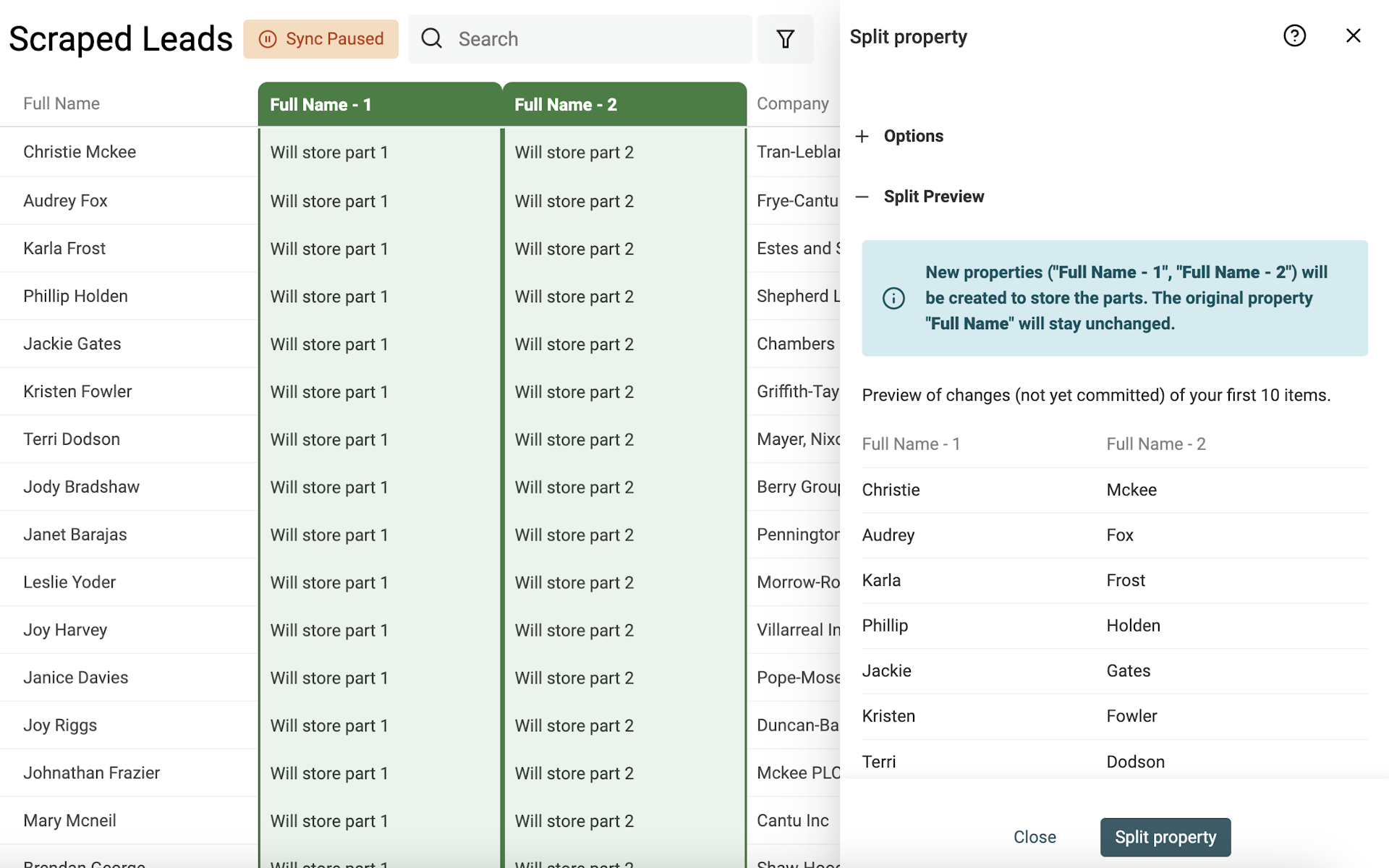
Starte die Preview. Datablist parsed Deine ersten 10 Items und erstellt eine Vorschau. Wenn die Ergebnisse passen, klickst Du auf „Split Property“, um den Split auf alle aktuellen Items anzuwenden.
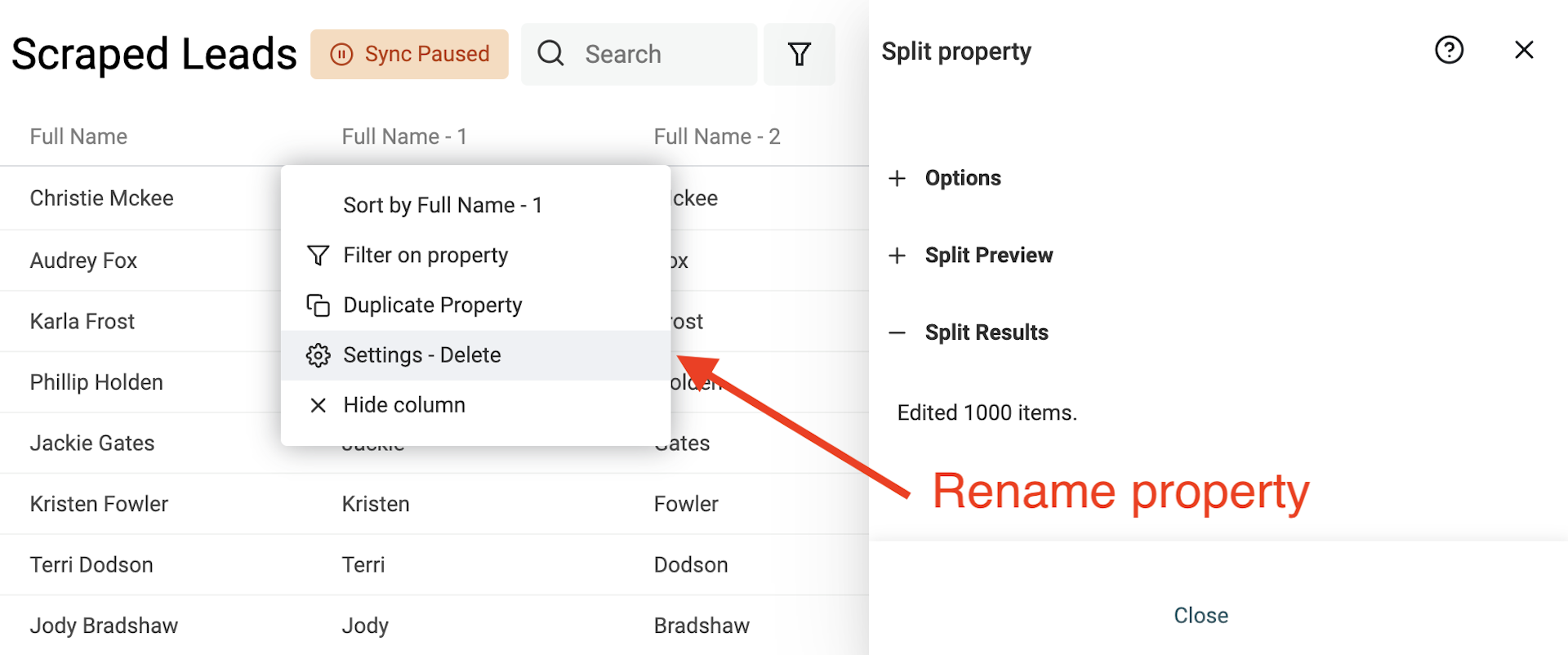
Nach dem Split benennst Du die beiden neuen Properties in „First Name“ und „Last Name“ um.
Dieses Beispiel fokussiert sich auf westliche Namenskonventionen (typisch: Vorname + Nachname). In der Praxis kann es komplexer werden, z. B. bei nicht-westlichen Namenssystemen, mehreren Vornamen/Nachnamen oder bei Titeln und Suffixen.
Daten deduplizieren
Datablist hat einen starken Deduplication-Algorithmus, um Records zu dedupen. Er findet ähnliche Items anhand einer oder mehrerer Properties und kann Duplikate automatisch mergen, ohne dass Du Daten verlierst.
Um den Deduplication-Algorithmus zu starten, klicke im Menü „Clean“ auf „Duplicate Finder“.
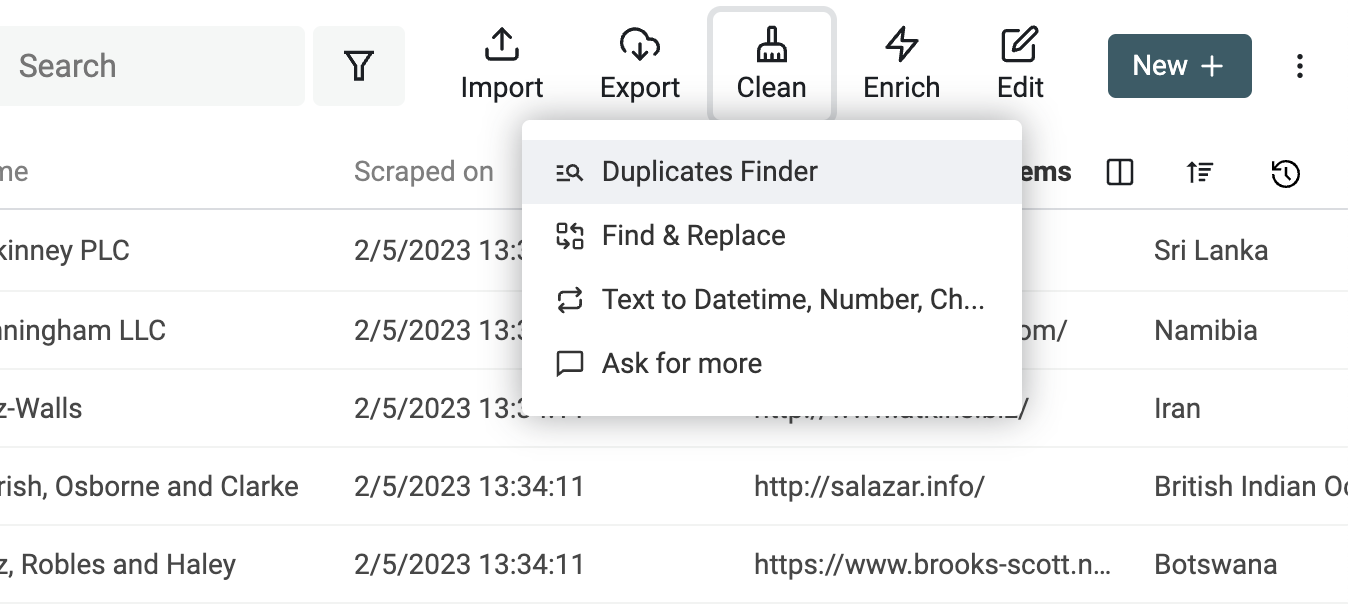
Wähle die Properties, die fürs Matching verwendet werden sollen.
Auf der Results-Seite führst Du den „Auto Merge“-Algorithmus einmal aus — und zwar nur mit der Option „Merge non-conflicting duplicates“. Damit werden Duplikate gemerged, die eindeutig zusammenpassen, und Properties mit Konflikten werden aufgelistet.
Der dedupe algorithm bietet zwei Optionen für Konflikte: Du kannst „Combine conflicting properties“ mit einem Delimiter nutzen oder konfliktbehaftete Werte droppen und nur ein Master-Item behalten.
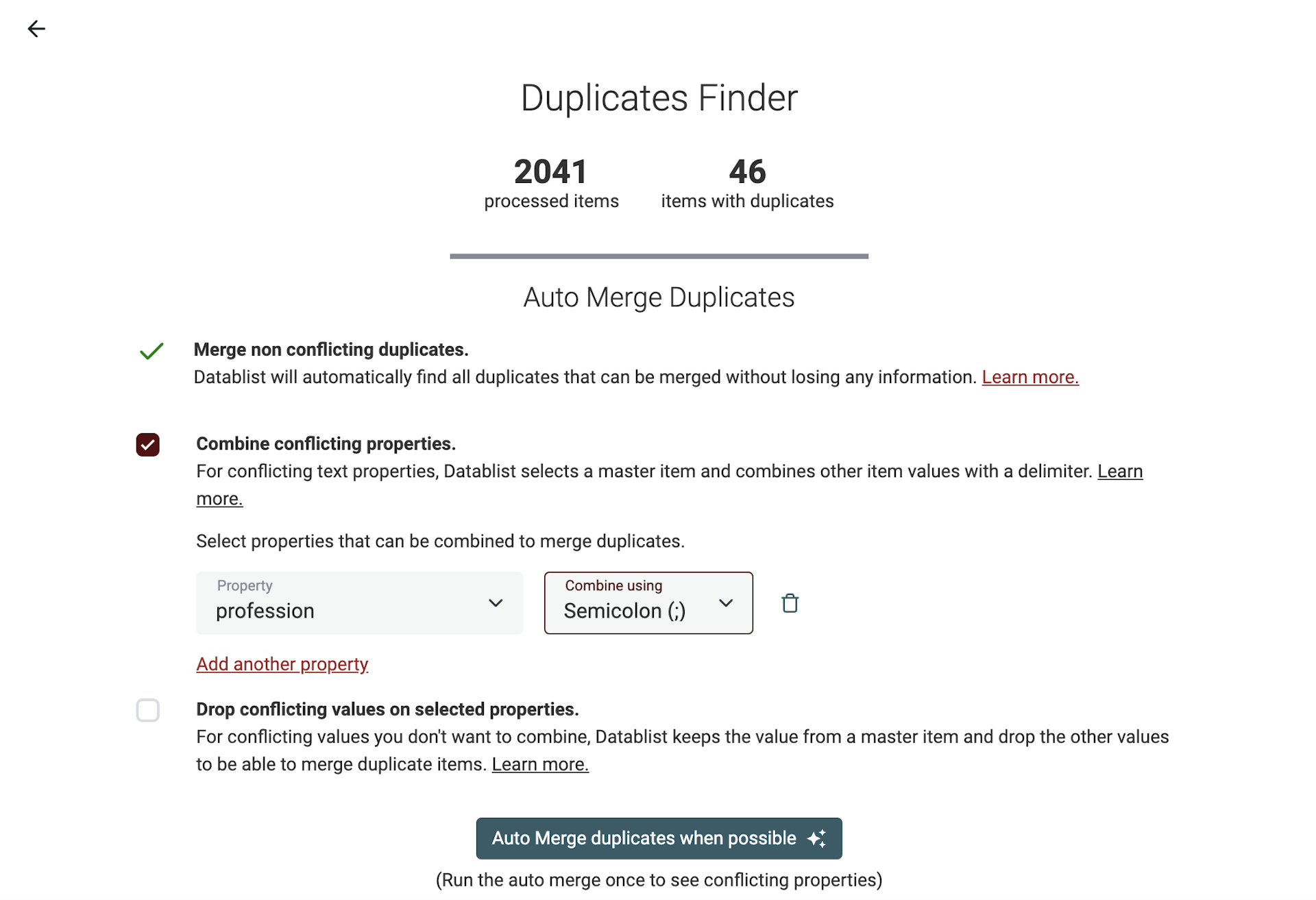
👉 Hier ist unser Guide zum Merge von Duplikaten in CSV-Dateien.
E-Mail-Adressen validieren
Scraping-Daten können veraltet sein, Tippfehler enthalten oder schlicht ungültig sein. Das gilt besonders für E-Mail-Adressen, die Du per Scraping einsammelst.
Wenn Daten user-generated sind, landen außerdem oft Fake-E-Mails in Deiner Datenbank — oder Adressen von Disposable Providern.
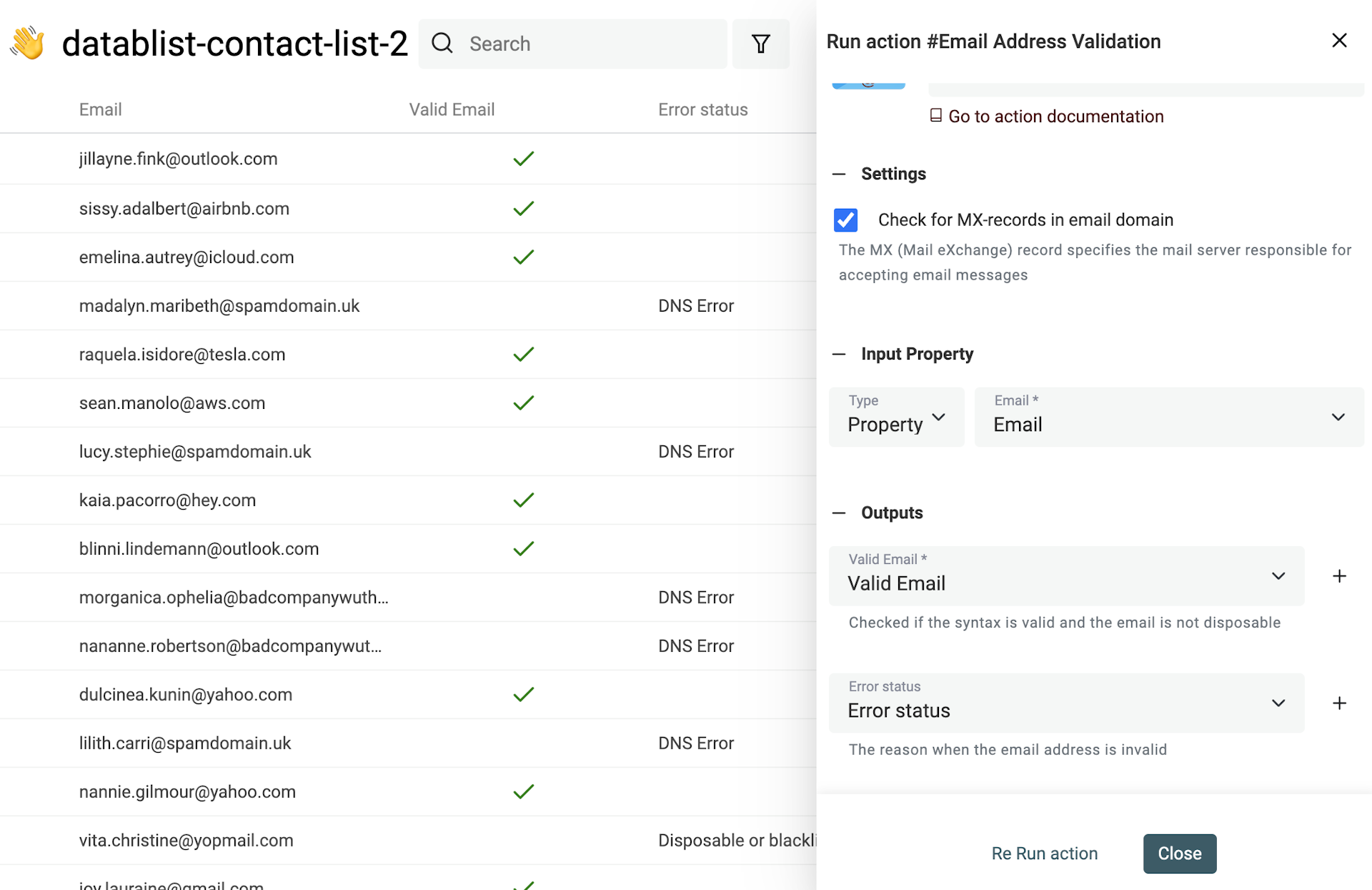
Datablist hat ein eingebautes Email Validation Tool, mit dem Du tausende E-Mail-Adressen validieren kannst.

Der Email-Validation-Service liefert:
- Email syntax analysis - Der erste Check stellt sicher, dass die E-Mail dem IEFT-Standard entspricht und führt eine vollständige Syntaxanalyse durch. Dabei werden Adressen ohne @, mit ungültigen Domains usw. markiert.
- Disposable providers check - Der zweite Check erkennt temporäre E-Mails. Der Service sucht nach Domains, die zu Disposable Email Address (DEA) Providern gehören, z. B. Mailinator, Temp-Mail, YopMail, etc.
- Domain MX records check - Eine gültige E-Mail-Adresse braucht eine Domain mit konfigurierten MX-Records. Diese MX-Records definieren den Mailserver, der E-Mails für die Domain annimmt. Fehlende MX-Records sind ein starkes Zeichen für ungültige Adressen. Für jede E-Mail-Domain prüft der Service die DNS-Records und sucht nach MX-Einträgen. Wenn die Domain nicht existiert, wird die E-Mail als ungültig markiert. Existiert die Domain, hat aber keinen gültigen MX-Record, wird sie ebenfalls als ungültig markiert.
- Business and Personal Email addresses Segmentation - Bei Prospects aus Lead Magnets oder wenn Du Deine User Base segmentieren willst, ist die Unterscheidung zwischen Business- und privaten E-Mails oft relevant. Der Service liefert Dir diese Info zur Anreicherung Deiner Kontaktdaten.
👉 Schau Dir unseren Guide an, wie Du eine Email-Liste bereinigst.
Personen- oder Firmennamen aus gescrapten Texten extrahieren
Wenn Du Texte von Websites oder anderen Quellen scrapest, ist es oft super hilfreich, daraus die Namen von Personen oder Unternehmen zu extrahieren. Das kannst Du für Lead Generation, Competitive Research oder Data Enrichment nutzen. Der Haken: Namen aus unstrukturiertem Text zu ziehen ist nicht trivial — sie kommen in vielen Varianten vor und stecken häufig mitten in größeren Textblöcken.
Eine der größten Herausforderungen ist die Vielfalt an Namenskonventionen je nach Kultur und Sprache. Manche Kulturen schreiben den Familiennamen vor den Vornamen, andere umgekehrt. Manche Menschen haben mehrere Vornamen, andere gar keinen. Außerdem sind Namen oft falsch geschrieben, abgekürzt oder in unüblichen Formaten notiert. Das macht simples Pattern-Matching schnell unzuverlässig.
Ein gängiger Ansatz ist Named Entity Recognition (NER). Das ist eine NLP-Technik, die Entities in Text erkennt und klassifiziert, z. B. Personen, Organisationen oder Orte. NER-Modelle können auf verschiedene Entity-Typen trainiert werden und lassen sich an unterschiedliche Namenskonventionen anpassen.
Datablist enthält ein starkes „Named Entity Recognition“ (NER) Model, das Du direkt auf Deinen Texten laufen lassen kannst. Es ist trainiert für Arabisch, Deutsch, Englisch, Spanisch, Französisch, Italienisch, Lettisch, Niederländisch, Portugiesisch und Chinesisch.
Wähle „Entity name extraction“ im Menü „Enrichments“.
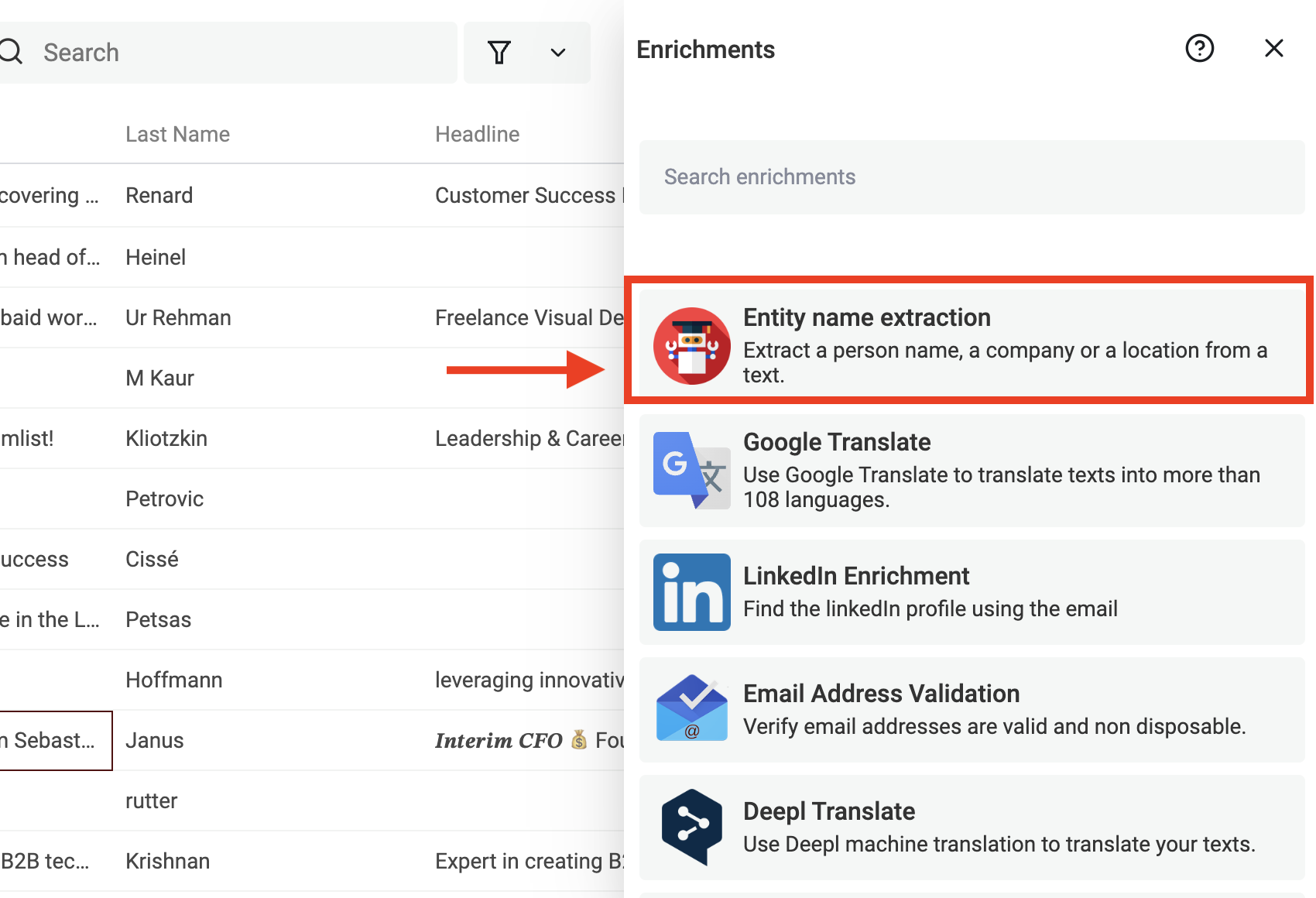
Wähle dann in den Input-Optionen die Property aus, aus deren Texten Du Namen extrahieren willst.
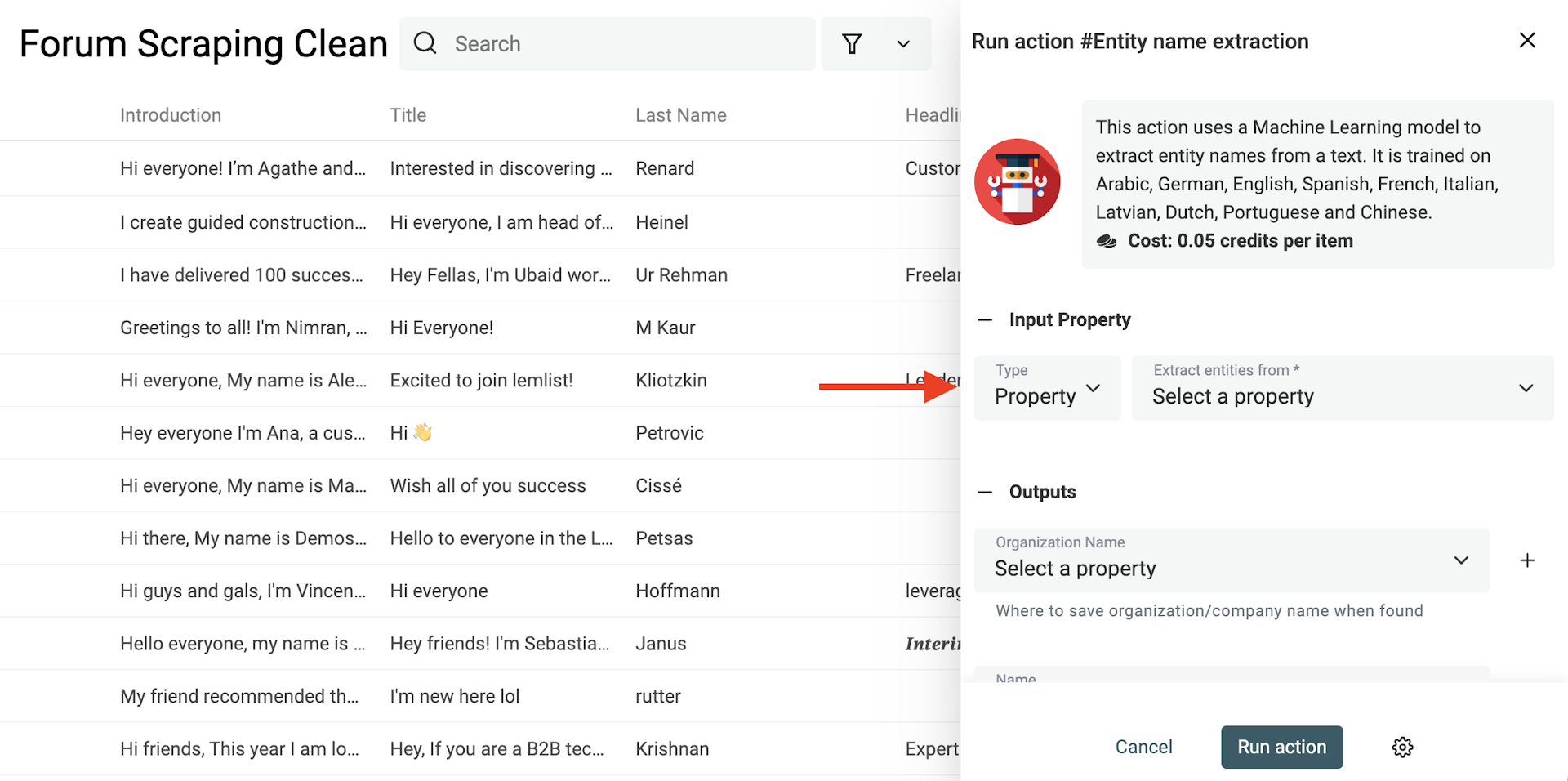
Bei den Outputs klickst Du für jede Art von Namen, die Du extrahieren willst, auf „Create a new property“.
Der Datablist Entity Name Extractor sucht nach:
- Organization Name: z. B. Unternehmen.
- Person Name: Full Name oder First Name/Last Name
- Location: Stadt, Land und Orte
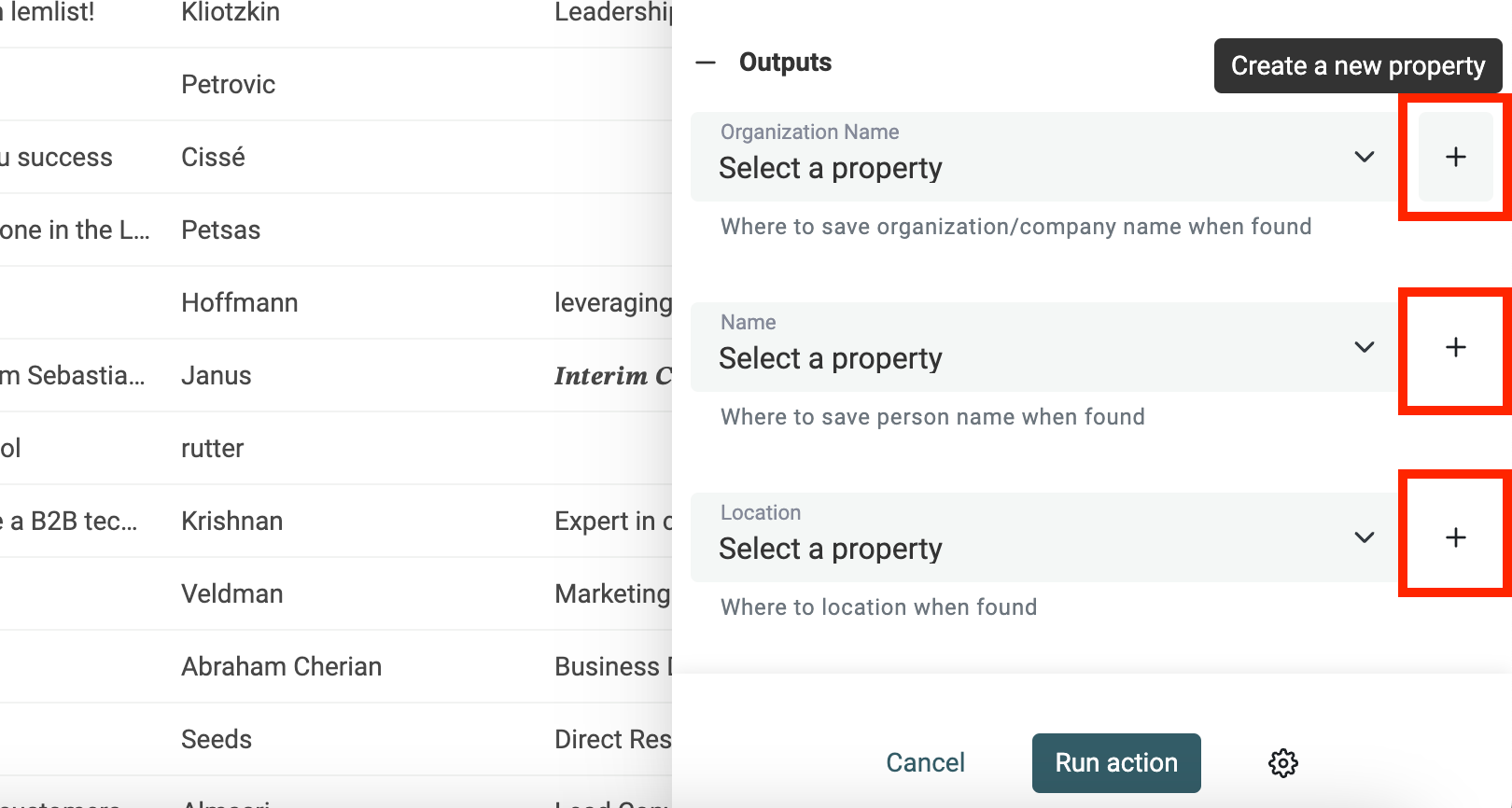
Dann startest Du das Enrichment.
Brauchst Du Hilfe beim Data Cleaning?
Ich bin immer auf der Suche nach Feedback und echten Data-Cleaning-Problemen, die wir besser lösen können. Bitte kontaktier mich und teile Deinen Use Case.