

E-Mail-Listen sind die Basis für jede E-Mail-Kampagne und fürs Newsletter-Management. Mit der Zeit wird so eine Liste aber schnell chaotisch – zum Beispiel durch mehrfaches Zusammenführen verschiedener Exporte oder durch „spammy“ User-Verhalten.
Die Vorteile, wenn Du Deine E-Mail-Liste regelmäßig bereinigst:
- Bessere Zustellbarkeit – Jeder E-Mail-Provider nutzt Deinen Sender Score, um zu entscheiden, ob Deine Mails im Posteingang landen oder irgendwo im SPAM. Der wichtigste erste Schritt: Schick keine Mails an Adressen, die es gar nicht gibt. Ein schlechter Sender Score lässt sich nur schwer wieder geradebiegen – also lieber früh sauber arbeiten und nicht zustellbare Adressen rauswerfen.
- Geld sparen – In den meisten Tools zahlst Du indirekt pro Kontakt bzw. pro Versandvolumen. Wenn Du Duplikate und ungültige Adressen entfernst, sinken Deine Kosten sofort. Zusätzlich solltest Du Disposable Email Addresses entfernen – die werden ohnehin nie gelesen.
- Typos finden und korrigieren – Nach dem Cleaning werden fehlerhafte Adressen markiert. Dann kannst Du typische Tippfehler in Namen oder Domains oft schnell manuell fixen.
E-Mail-Listen zu bereinigen gehört zu jedem digitalen Business – und sollte regelmäßig passieren. Datablist ist ein ideales Data-Tool, um diesen Prozess sauber durchzuziehen. In dieser Schritt-für-Schritt-Anleitung lernst Du:
- Wie Du doppelte E-Mails entfernst
- Wie Du die Syntax von E-Mail-Adressen prüfst
- Wie Du Disposable Provider erkennst
- Wie Du erkennst, ob eine Adresse eine Business Email ist
- Wie Du sicherstellst, dass E-Mail-Domains existieren
- Wie Du den E-Mail-Provider erkennst
- Wie Du E-Mail-Aliase entfernst
Datablist kannst Du ohne Registrierung nutzen, um CSV-Dateien anzusehen und zu bearbeiten. Der E-Mail-Verification-Service, den wir gleich verwenden, braucht allerdings einen Account.
👉 Erstelle Deinen Account kostenlos 👈.
Wie schlägt sich das im Vergleich zu bezahlten E-Mail-Cleaning-Services?
Wenn Du bei Google nach E-Mail-Verification-Services suchst, findest Du hunderte (tausende?) Anbieter. Fast alle rechnen pro E-Mail-Adresse ab. Datablist enthält einen E-Mail-Verification-Service – und der ist kostenlos. Für einfache Checks ist das super und völlig ausreichend. Wenn Du allerdings tiefergehende Analysen brauchst oder Hunderttausende E-Mails verifizieren musst, lohnt sich ein bezahlter E-Mail-Cleaning-Service.
Schritt 1: E-Mail-Adressen importieren
Collection erstellen
Der erste Schritt beim E-Mail-Cleaning: Erstelle in Datablist eine Collection, in die Du Deine E-Mail-Adressen „kippst“.
In Datablist klickst Du auf +, um eine neue Collection anzulegen. Gib ihr einen Namen (und ein Icon 😍).
Deine E-Mail-Listen importieren
Jetzt hast Du eine Collection – als Nächstes importierst Du Deine Listen. Egal, ob Du nur eine Liste hast oder mehrere, die Du zusammenführen willst.
Datablist bietet zwei Import-Optionen:
- Über CSV-Dateien
- Per Copy/Paste aus einem Spreadsheet
Option 1: Import aus CSV-Dateien
Das CSV-Format ist ein einfacher Standard, um tabellarische Daten zwischen Tools zu übertragen. Jedes Newsletter-Tool und jede Digital-Marketing-Lösung kann Kontakte als CSV exportieren. CSV-Dateien sind in Datablist „first-class citizens“.
Siehe auch: How to join CSV files by a unique identifier und How to remove CSV duplicates.
In diesem Beispiel nutzen wir eine Demo-CSV mit drei Spalten: First Name, Last Name, Email. Lade die Demo-Datei hier herunter.
Um Deine CSV zu importieren, klick auf „Import CSV“ und wähle die Datei aus.
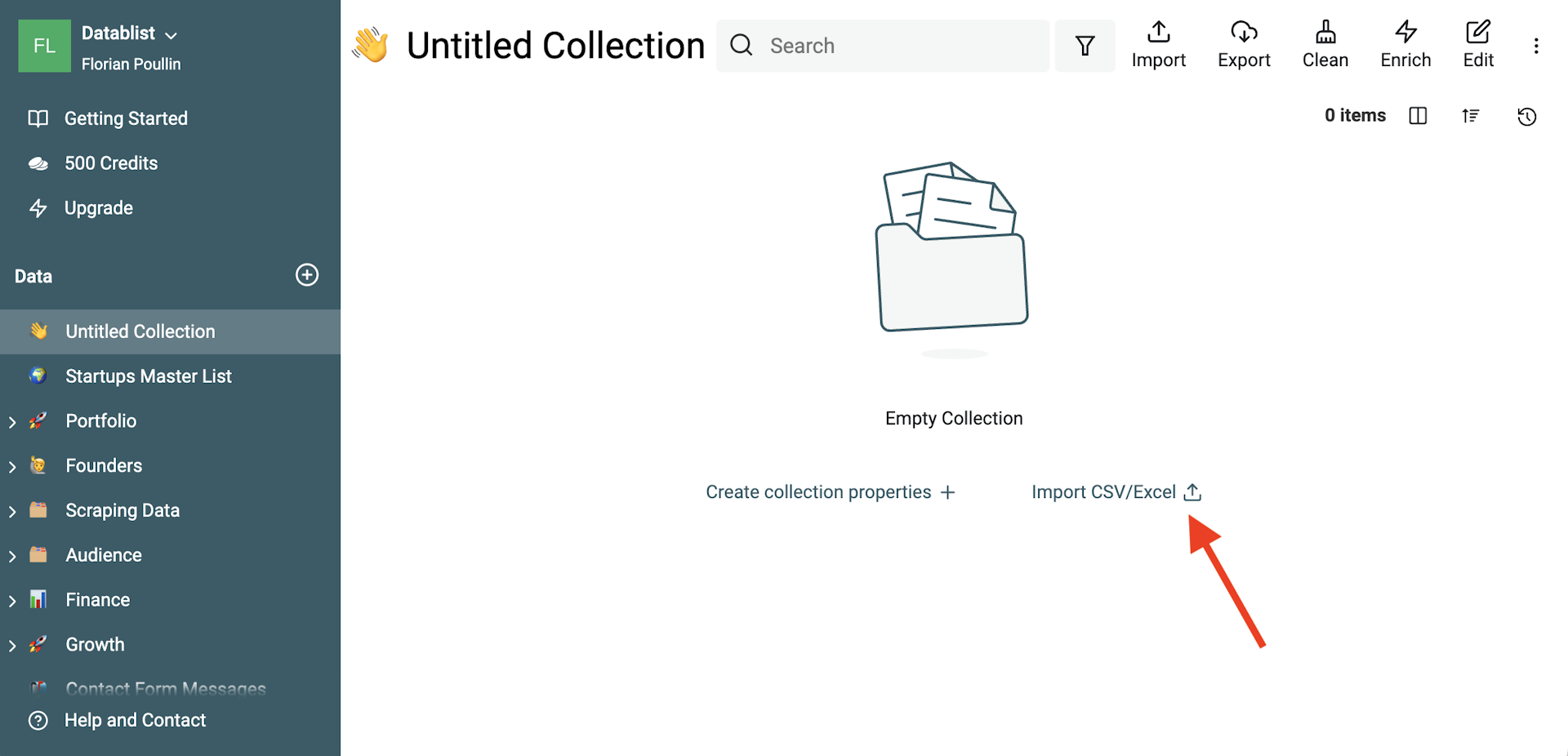
Datablist liest CSV-Dateien und Excel-Dateien. Die ersten Zeilen werden genutzt, um das Encoding zu erkennen. Wenn Du in den Headern oder später beim Import komische Zeichen siehst, leg am besten eine neue Collection an und importiere die CSV mit einem anderen Encoding.
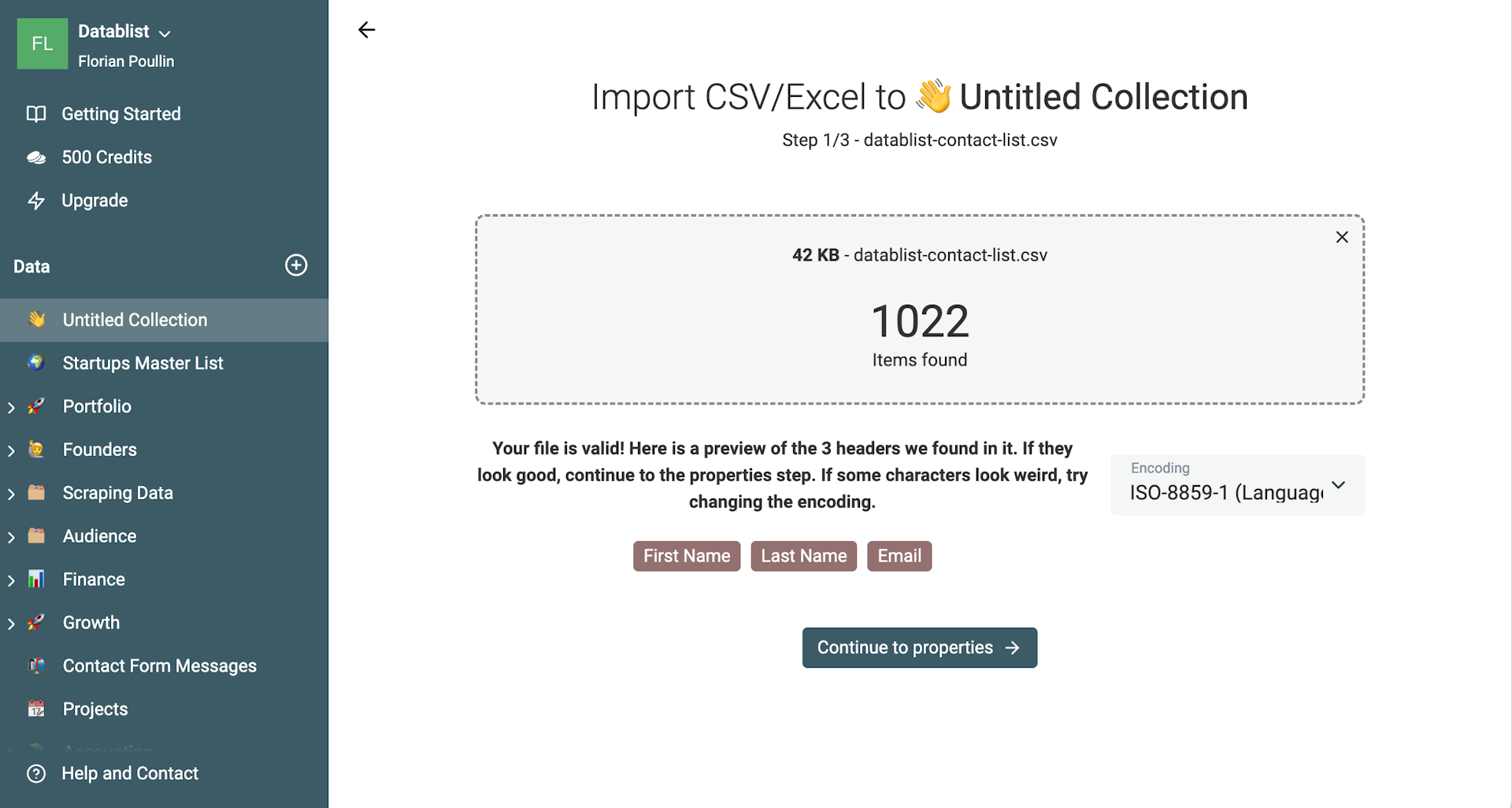
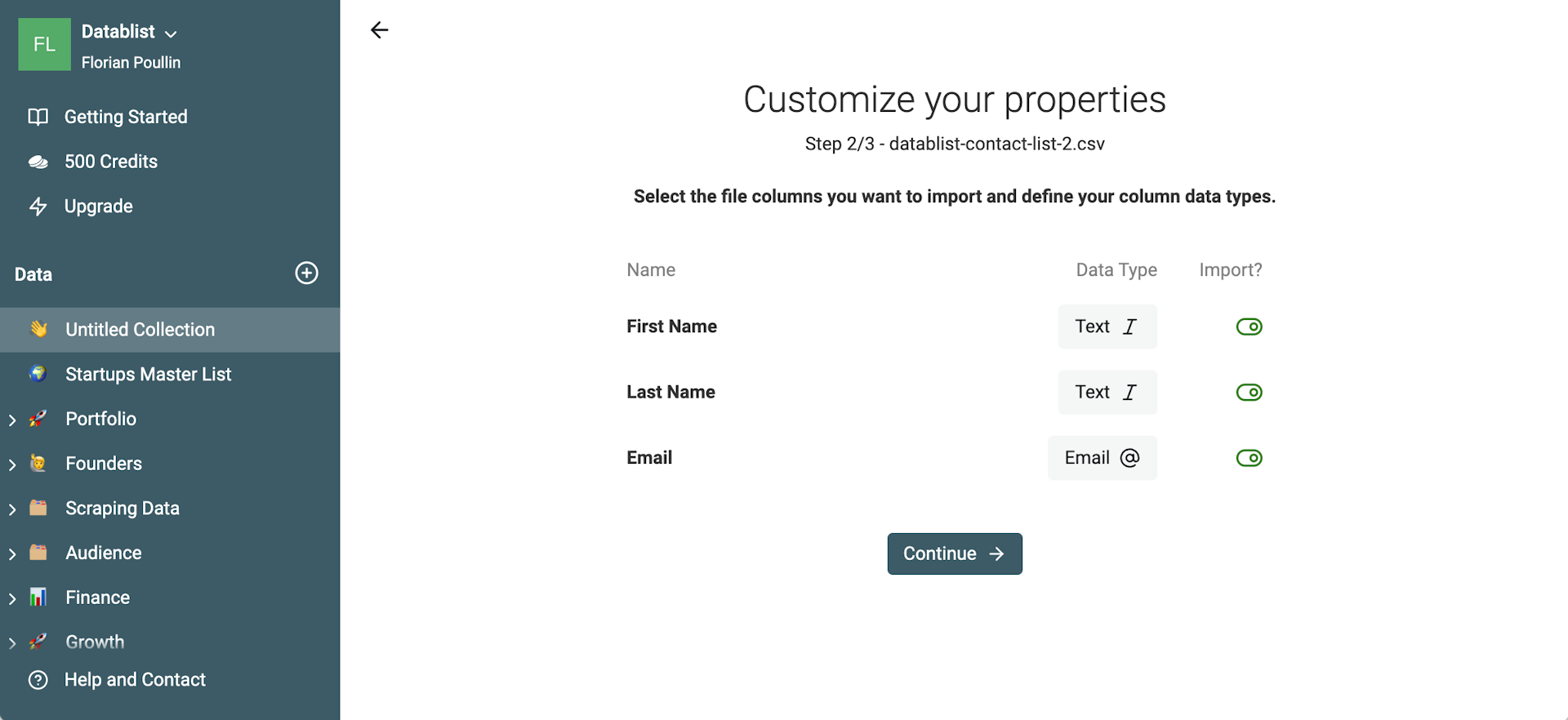
Datablist liest die Spalten und zeigt Dir eine Mapping-Seite. Wenn Deine E-Mail-Adressen valide sind, wird der Datentyp als Email erkannt. Das sorgt später in Datablist beim Bearbeiten für zusätzliche Validierung.
Hier ist ein Video vom kompletten Prozess:
Option 2: Import per Copy/Paste
Datablist ist kompatibel mit Copy/Paste aus jedem Spreadsheet. Markiere einfach die Zellen in Deinem Spreadsheet, geh in Deine Datablist-Collection und nutze Edit -> Paste im Browser oder direkt Ctrl + v.
Beim Einfügen zeigt Datablist Dir, welche Spalten und Zeilen erkannt wurden. Um eine Spalte zu importieren, mappe sie auf eine bestehende Property oder erstelle eine neue.
Warnung: Nur gemappte Spalten werden importiert!
Weitere Kontaktlisten importieren (falls nötig)
Wenn Du Dir eine E-Mail-Collection aus mehreren Quellen zusammenbaust, importiere einfach alle Listen in dieselbe Collection.
Beim Import einer weiteren Datei erscheint wieder ein Mapping-Schritt. Dort verknüpfst Du die Properties Deiner Collection mit den Spalten aus der CSV. Dadurch werden die neuen Daten in die bestehenden Properties übernommen.
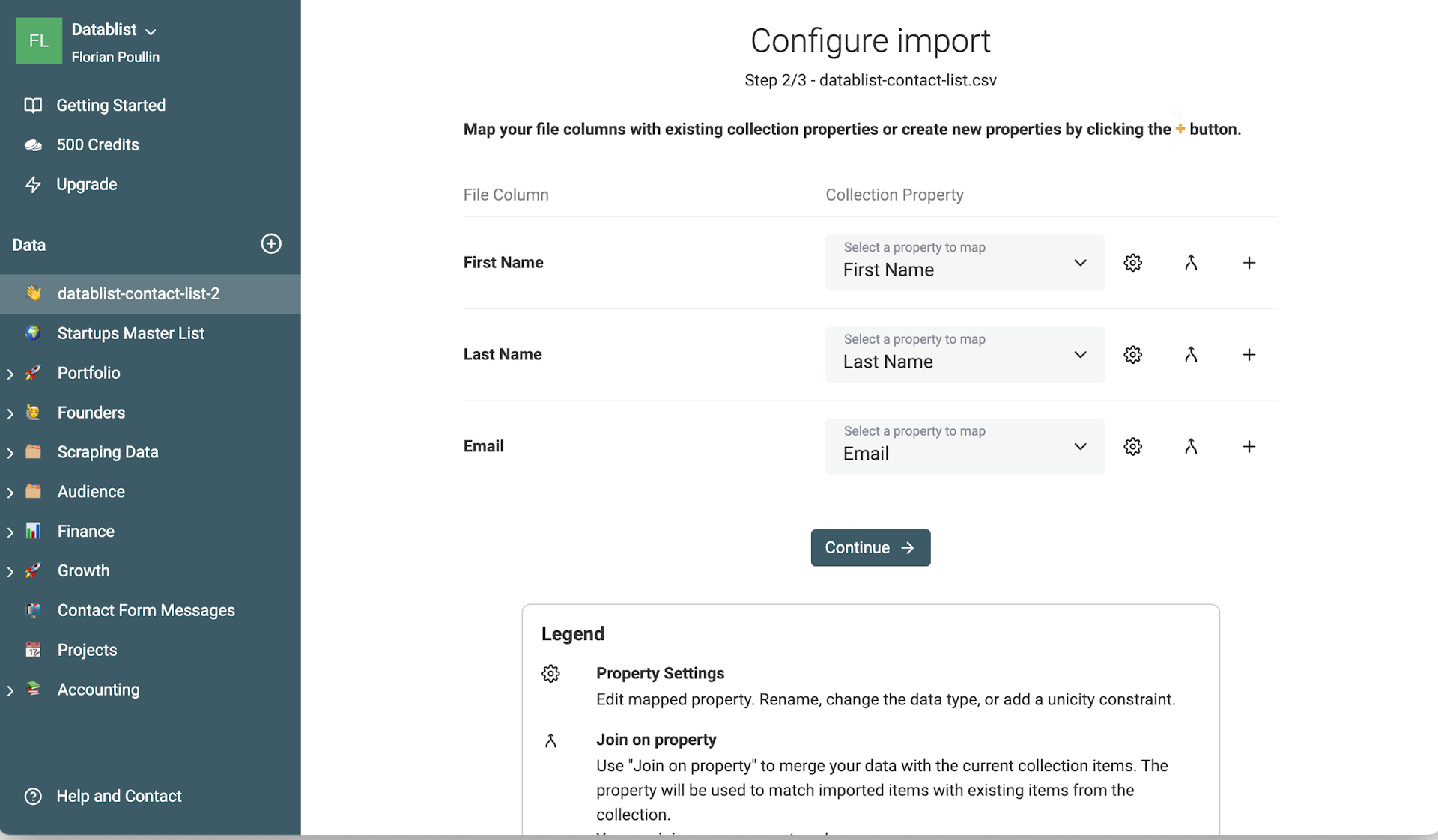
Schritt 2: Duplikate finden und zusammenführen
Es ist total normal, dass eine E-Mail-Liste über Zeit wächst. Oft werden mehrere Exporte in eine Liste zusammengeführt. Und zack: Duplikate. Wenn Deine Liste zusätzlich Kontaktinfos wie First Name, Last Name etc. enthält, liegen diese Infos dann häufig verteilt über mehrere doppelte Zeilen.
Wenn alle E-Mail-Adressen an einem Ort sind, ist Schritt 2: doppelte Einträge entfernen oder zusammenführen.
Nutze dafür die Datablist-Funktion „Duplicates Finder“: Klick im Menü „Clean“ auf „Duplicates Finder“.
Im Config-Screen legst Du fest, wie Duplikate erkannt werden sollen:
- All Properties – Sucht nach kompletter Ähnlichkeit: Zwei Items gelten als Duplikate, wenn alle Properties übereinstimmen.
- Selected properties – Zwei Items gelten als Duplikate, wenn die ausgewählten Properties übereinstimmen.
In unserem Beispiel sind zwei Kontakte Duplikate, wenn sie dieselbe E-Mail-Adresse haben. Wähle also Selected Properties und markiere die Property Email.
Starte den Duplikat-Check, um eine Vorschau aller gefundenen Duplikate zu sehen.
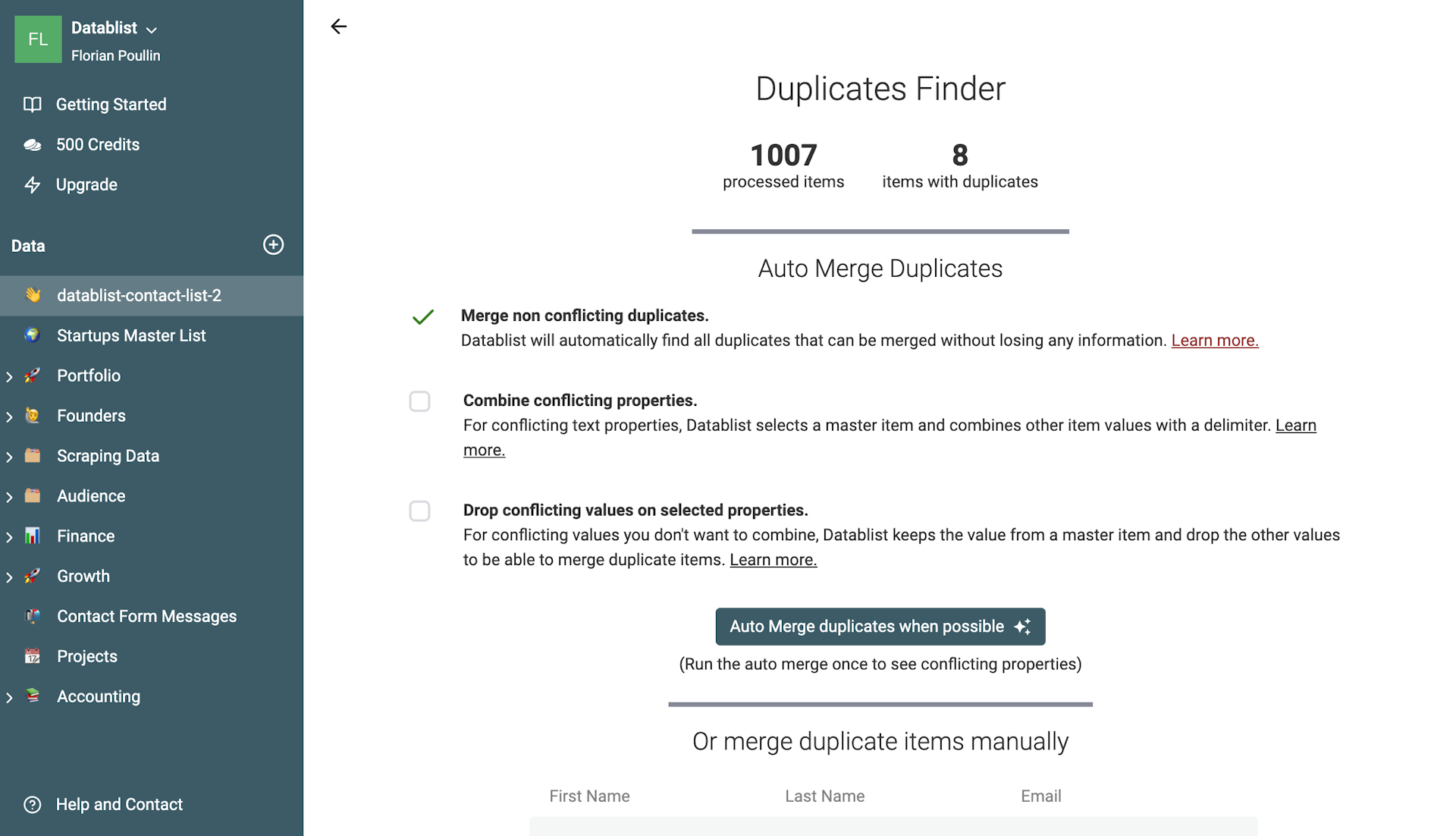
Wenn Duplikate gefunden werden, hast Du mehrere Optionen:
- Duplicate Items zusammenführen/konsolidieren
- Duplicate Items löschen
- Manuell bearbeiten
Datablist hat einen automatischen Algorithmus zum Dedupe Deiner Daten. Schau in unsere Doku, um mehr über Deduplication zu erfahren.
Nach dem Auto-Merge kannst Du mit dem manuellen Merge-Assistenten den Feinschliff machen. Um Duplikate zusammenzuführen, klick links in jeder Duplikat-Gruppe auf „Merge Items“.
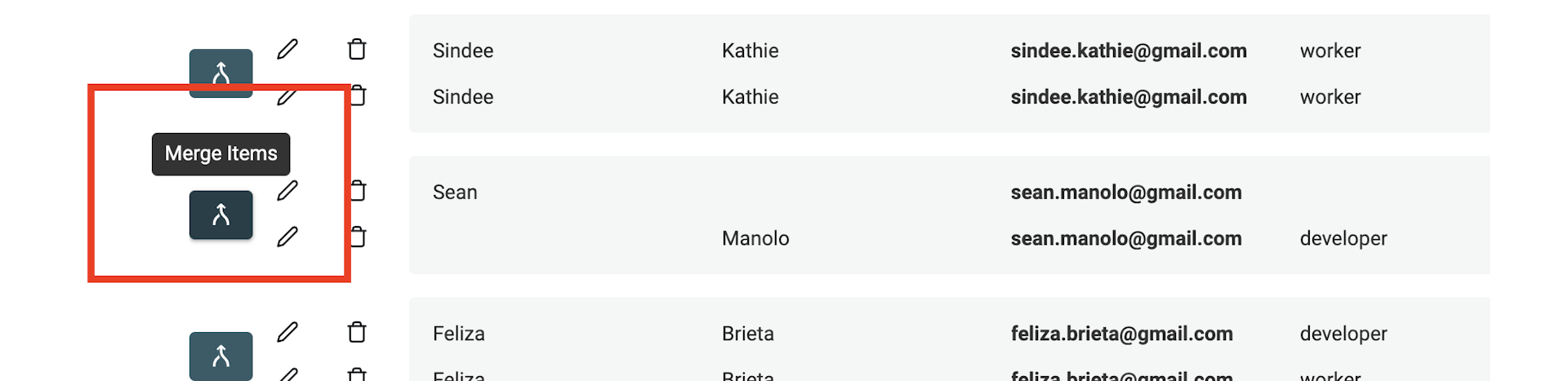
Datablist zeigt Dir rechts das „Primary Item“ und links die übrigen Duplikate als „Secondary Items“. Datablist wählt automatisch den Kontakt mit den meisten Daten als „Primary Item“.
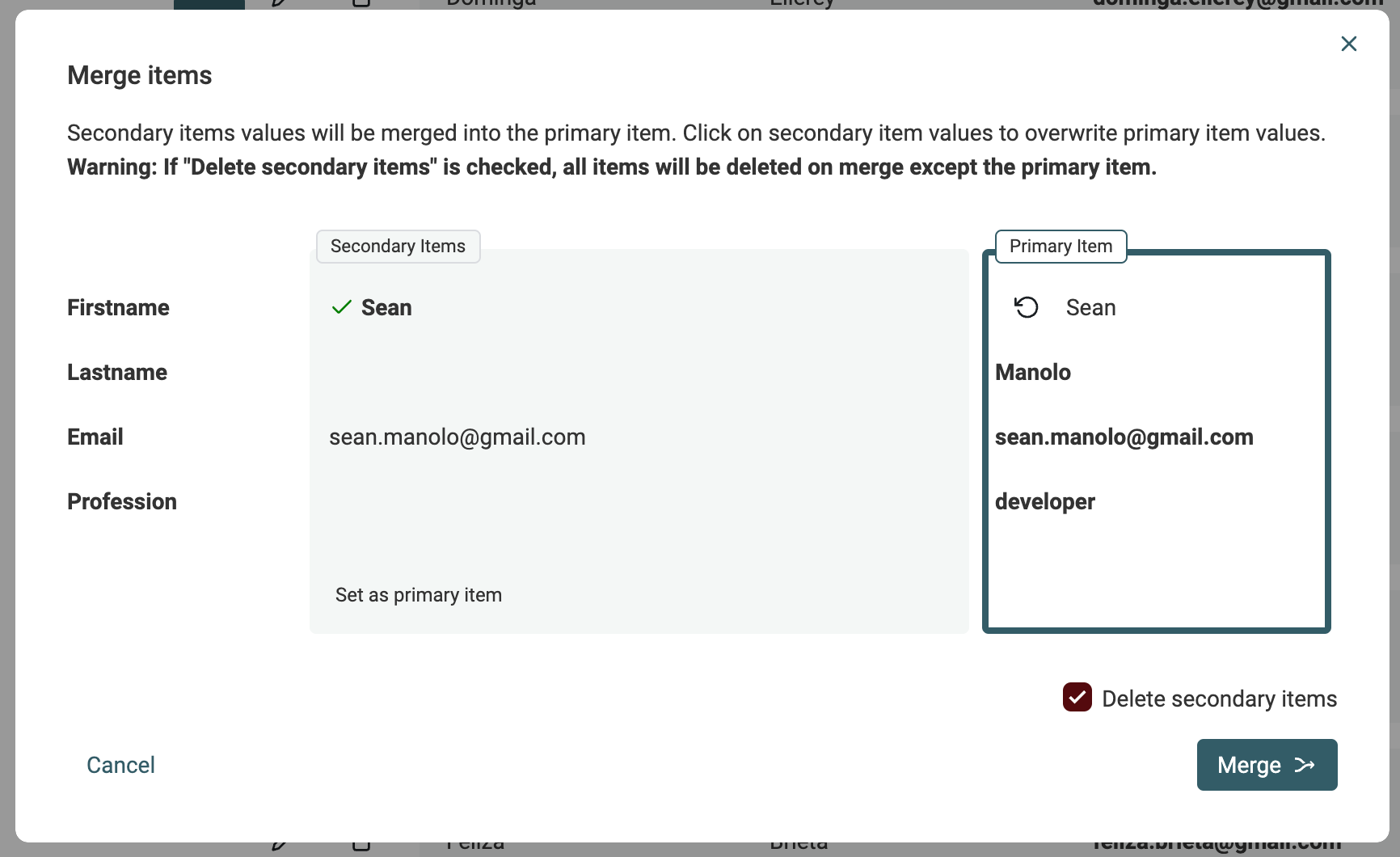
Wenn möglich, werden Property Values aus Secondary Items automatisch zum Merge ins Primary Item vorgeschlagen. Wenn mehrere Werte kollidieren, musst Du entscheiden, welcher Wert bleiben soll.
Wenn das Ergebnis im „Primary Item“ passt, klick auf Merge, um den Merge zu bestätigen. Alle Secondary Items werden gelöscht – übrig bleibt ein konsolidiertes Item.
Sobald alle Duplikate verarbeitet sind, geh zurück in die Collection.
Hier ein Video zum kompletten Ablauf:
Schritt 3: E-Mail-Liste kostenlos bereinigen
Jetzt hast Du in Datablist eine Collection mit allen E-Mail-Adressen – ohne Duplikate. Zeit fürs eigentliche Cleaning.
Hinweis
Für den E-Mail-Verification-Service musst Du registriert sein. Sign up (kostenlos). Wenn Du schon eine anonyme Collection hast, importiere sie in Deinen Workspace.
Was wird geprüft?
Datablist hat einen integrierten kostenlosen E-Mail-Verification-Service. Dieser Free-Service macht 5 Checks:
- E-Mail-Syntax-Analyse
- Domain-MX-Records-Check
- Disposable-Provider-Check
- Name des E-Mail-Providers zurückgeben
- Ist die Adresse eine Business Email oder von einem generischen Provider (Gmail, Yahoo etc.)
Email-Syntax-Analyse
Der erste Check stellt sicher, dass die E-Mail der IETF-Spezifikation entspricht und führt eine vollständige syntaktische Analyse durch.
Dabei werden z. B. Adressen ohne @, mit ungültigen Domains usw. markiert.
Domain MX Records prüfen
Der zweite Check erkennt, ob die Domain überhaupt E-Mails empfangen kann. Eine valide E-Mail-Adresse braucht eine existierende Domain mit korrekt gesetzten MX Records. Diese MX Records geben an, welcher Mailserver für die Domain E-Mails annimmt. Fehlen MX Records, ist die E-Mail-Adresse praktisch ungültig.
Für jede Domain prüft der Service die DNS-Records und sucht nach MX. Wenn die Domain nicht existiert, wird die E-Mail als ungültig markiert. Wenn die Domain existiert, aber keinen gültigen MX Record hat, wird sie ebenfalls als ungültig markiert.
Disposable Provider prüfen
Der dritte Check erkennt temporäre E-Mails. Der Service sucht nach Domains, die zu Disposable Email Address (DEA) Providern gehören – z. B. Mailinator, Temp-Mail, YopMail usw.
Die aktuelle Datenbank enthält etwa 3000 Disposable-Provider-Domains und wird regelmäßig aktualisiert, basierend auf dieser Disposable-Domain-Liste.
Namen des E-Mail-Providers ausgeben
Wenn Du das Enrichment „Free Email Validator“ laufen lässt, ist eines der wichtigsten Ergebnisse das Feld „MX Provider“. Dieses Feld zeigt Dir, welcher E-Mail-Service die Zustellung für die Domain übernimmt – basierend auf den MX Records.
Ein E-Mail-Provider kann z. B. sein: google, microsoft, amazon usw.
Mehr Details findest Du in der Enrichment-Doku: Free Email Validator.
Prüfen, ob die E-Mail-Adresse eine Business Email ist
Eine weitere Info aus dem Datablist-Enrichment „Email Address Validation“: ob die E-Mail-Adressen Business Emails oder generische Adressen sind.
Eine Business Email nutzt eine Unternehmensdomain (z. B. elon@tesla.com). Wenn Du Deine Kontakte segmentierst, um Lead-Listen aufzubauen, hilft Dir das beim Lead Scoring.
Datablist pflegt eine Liste aller generischen E-Mail-Provider und vergleicht jede Domain damit. Die Adresse wird als „Business Email“ gelabelt, wenn die Domain nicht zu den generischen Providern gehört.
Cleaning in Deiner Collection durchführen
Ein E-Mail-List-Cleaning in Datablist ist unkompliziert: Klick auf das Menü „Enrich“ und wähle das Enrichment „Email Address Validation“.

Sobald Du „Email Address Validation“ ausgewählt hast, öffnet sich rechts ein Drawer, in dem Du das Enrichment konfigurierst.
Die Konfiguration hat 2 Schritte:
- Konfiguration von
SettingsundInput Properties - Konfiguration der
Output Properties, um festzulegen, wo die Ergebnisse gespeichert werden

Settings und Input Properties
Settings
Aktiviere in den Settings „Check for MX-records in email domain“, um die MX Records zu analysieren.
Input Properties
Wähle die Property aus Deiner Collection, die die E-Mail-Adresse enthält. In diesem Beispiel ist das die Property „Email“.
👉 Klick auf „Continue to outputs configuration“, um zu Schritt 2 zu gehen.
Output Properties und Run Settings

Das Enrichment „Email Address Validation“ liefert 4 Werte:
- Valid Email – Eine Checkbox (
trueoderfalse), ob die E-Mail-Adresse gültig ist. - Error status – Ein Text, der erklärt, warum die Adresse ungültig ist, wenn „Valid Email“
falseist. - Business Email – Eine Checkbox, ob die Adresse eine Business Email ist oder von einem generischen Provider kommt
- Domain – Gibt den Domain-Teil nach dem @ zurück. Beispiel: gmail.com
- MX Provider – Gibt den E-Mail-Provider zurück. Beispiele: google, microsoft, ovh etc.
- Processed – Eine Checkbox, um zu markieren, ob ein Item bereits verarbeitet wurde. Das ist praktisch, um zu filtern und das Enrichment nicht versehentlich zweimal auf dieselben Adressen laufen zu lassen.
⚠️ Du musst die Output Properties konfigurieren, um neue Properties in Deiner Collection anzulegen – oder sie auf bestehende Properties zu mappen.
Wenn Du das Enrichment zum ersten Mal ausführst, klick bei jeder Output Property auf +, um die Ergebnis-Properties in der Collection anzulegen.
Die Properties, die erstellt werden, werden rechts neben Deinen Spalten angezeigt.

Wenn die Outputs gemappt sind, klick auf „Run on first 10 items“. Bevor Du alles durchjagst, verarbeitet Datablist erst die ersten zehn Items. Damit erkennst Du Fehler und falsche Konfigurationen schneller.

Wenn die Ergebnisse passen, klick auf „Run the enrichment on all items“, um den Prozess fortzusetzen.

Hier ist ein Video vom Prozess (das ist eine ältere Datablist-Version – das Email-Verification-Enrichment ist inzwischen über den „Enrich“-Button erreichbar):
Wenn der Service fertig ist, schau Dir alle ungültigen E-Mails an – oft findest Du schnell Tippfehler, die man einfach korrigieren kann.
Email-Aliase finden und entfernen
Google Gmail und Microsoft Outlook (unter anderem) erlauben Alias-Adressen, indem Nutzer +irgendwas an den Username hängen.
Beispiel: Die Gmail-Adressen john@gmail.com und john+saas@gmail.com landen im gleichen Postfach.
Diese Aliase sind valide und bestehen die Prüfung – können aber trotzdem Kosten und Zustellbarkeit negativ beeinflussen.
So entfernst Du zusätzliche Alias-Adressen aus Deiner Kontaktliste.
Filtere zuerst alle E-Mail-Adressen, die ein + enthalten.
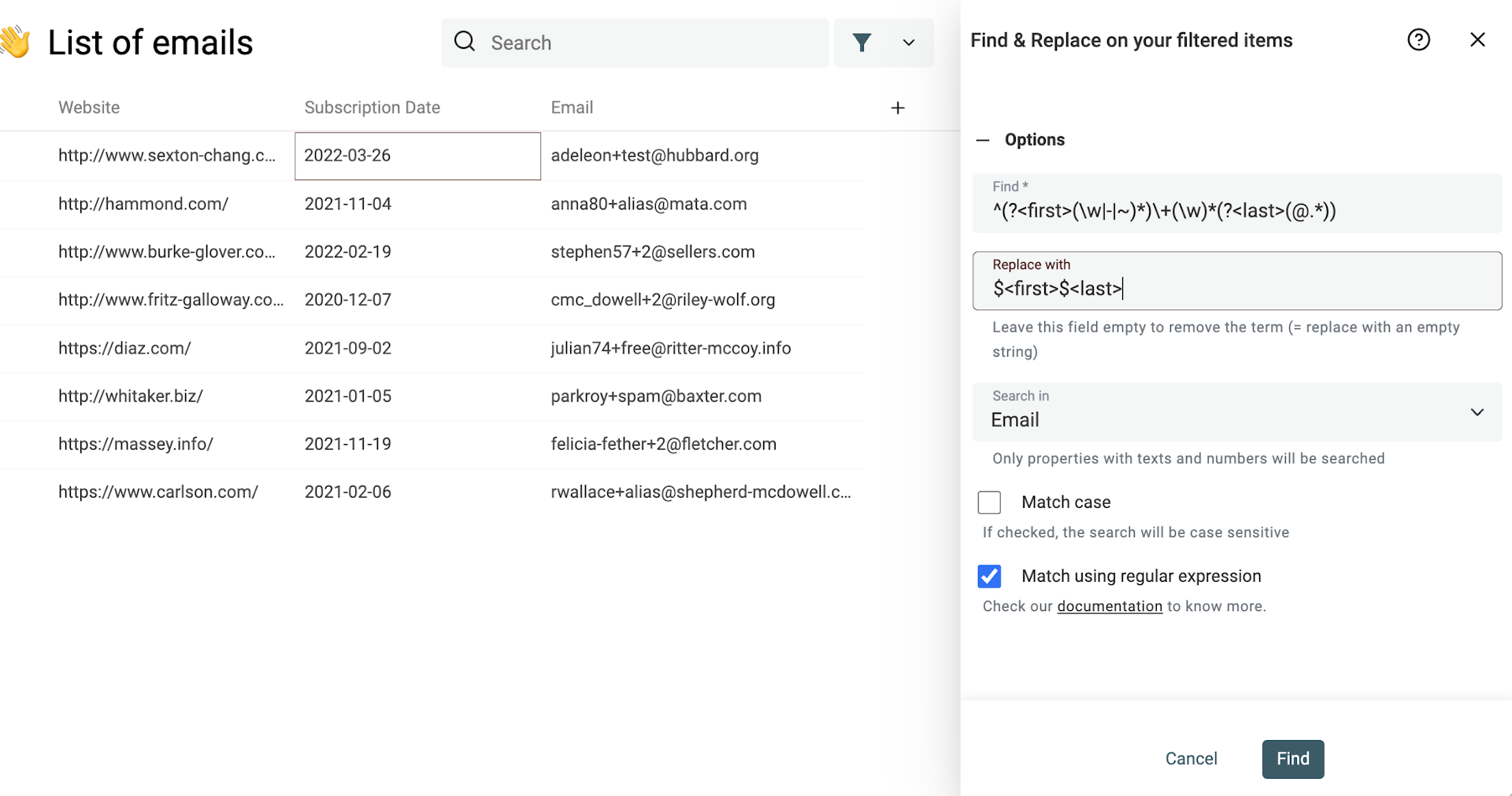
Öffne dann das Find & Replace Tool im Menü „Clean“.
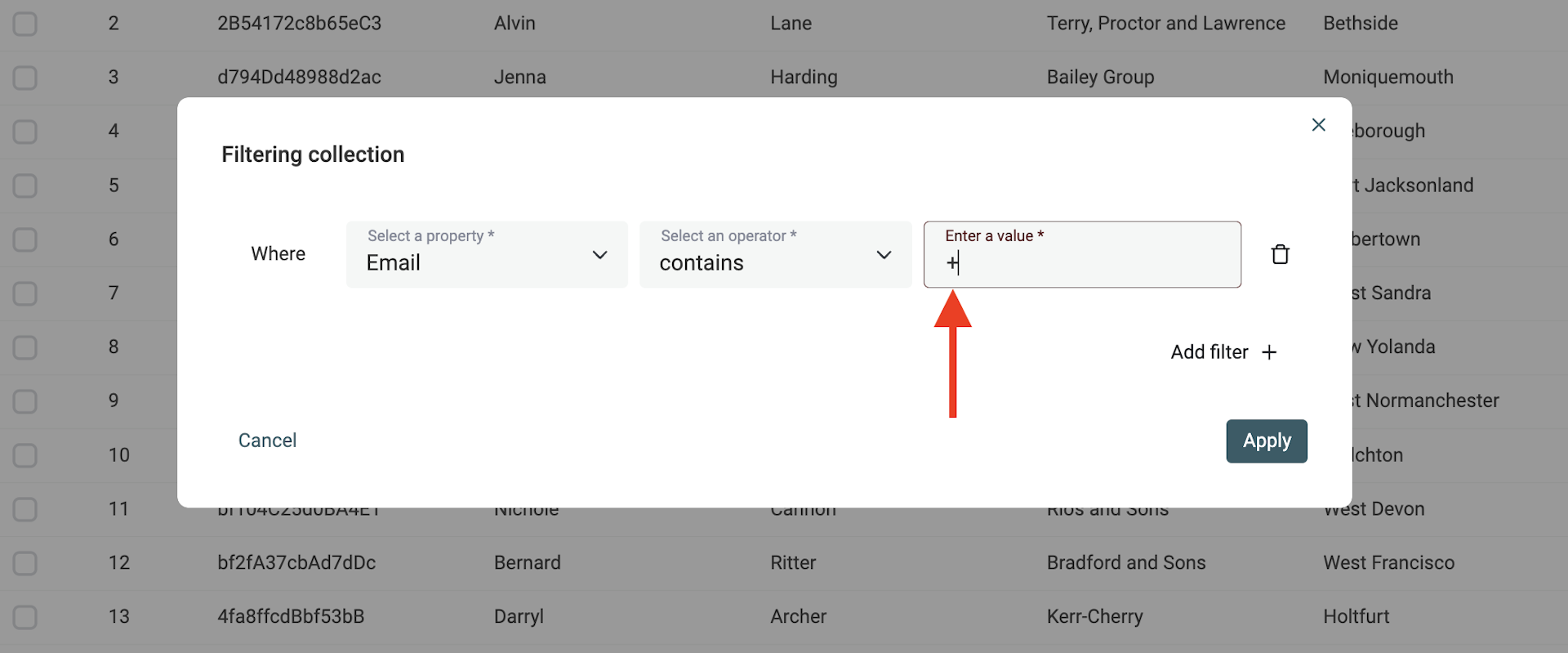
Wähle die Option Match using regular expression, suche in Deiner Property Email und nutze dieses Suchpattern:
^(?<first>(\w|-|~)*)\+(\w)*(?<last>(@.*))
Und trage bei „Replace with“ diesen String ein:
$<first>$<last>
Diese Regular Expression entfernt den +string aus E-Mail-Adressen.
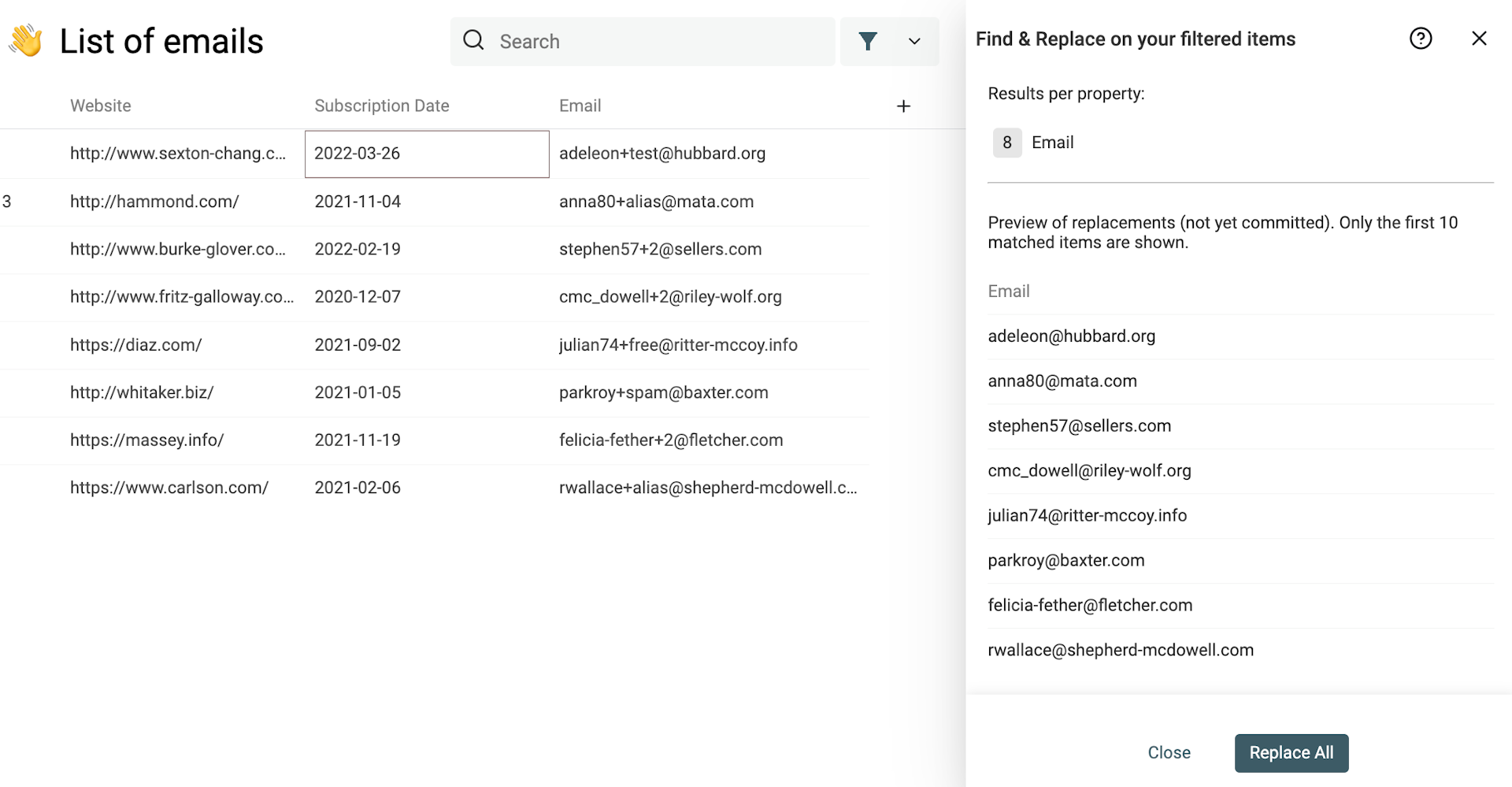
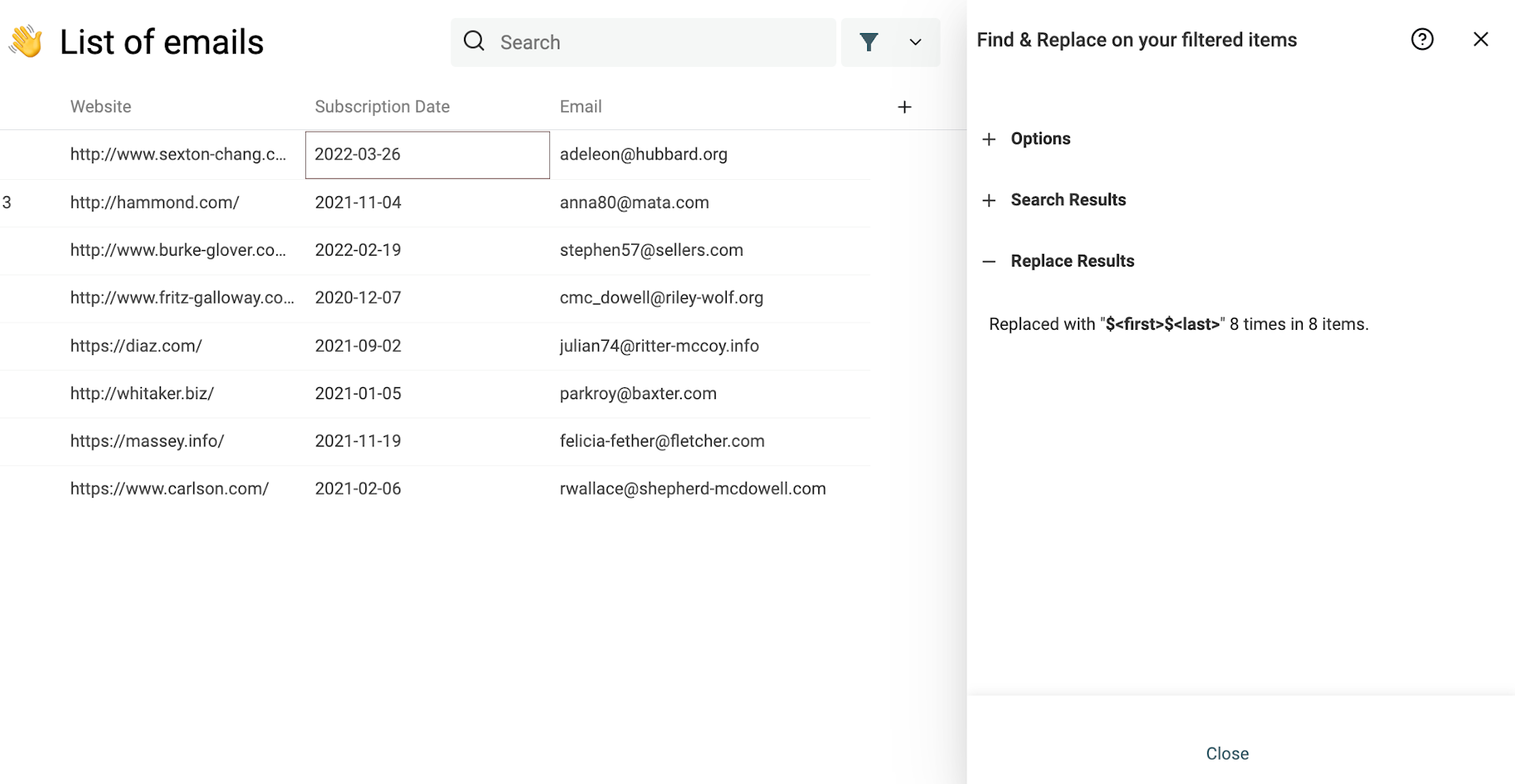
Danach kannst Du den Filter entfernen und den Deduplication Algorithm erneut auf Deine E-Mail-Datenbank anwenden. Wie Du Deine Kontaktliste deduplizierst, steht oben.
Der Deduplication-Schritt entfernt dann zusätzliche E-Mail-Adressen, wenn es eine Version ohne Alias gibt – und behält die Adresse, wenn sie die einzige ist.
Schritt 4: Abgemeldete E-Mails entfernen
Dieser letzte Schritt ist optional. Vielleicht hast Du eine separate Liste mit allen abgemeldeten E-Mails, die Du aus Deiner Hauptliste entfernen willst. Wenn Deine Unsubscribed-Liste z. B. eine Spalte wie diese hat:
email | Unsubscribed
xxx@xxx.com | yes
xxx@xxx.com | yes
xxx@xxx.com | yes
Dann kannst Du einen Join machen und die Info Unsubscribed zu Deiner Kontaktliste hinzufügen.
Dazu importierst Du die zweite Datei und machst eine CSV-Datei-Import + Join-Operation in dieselbe Collection.
Die gemeinsame Property ist Email. Du führst also die „join operation“ über die Property Email aus.
Beim Import der CSV mit den Unsubscribed-Adressen erstellst Du eine neue Property, um die Spalte „Unsubscribed“ zu speichern (klick im Mapping auf „+“).
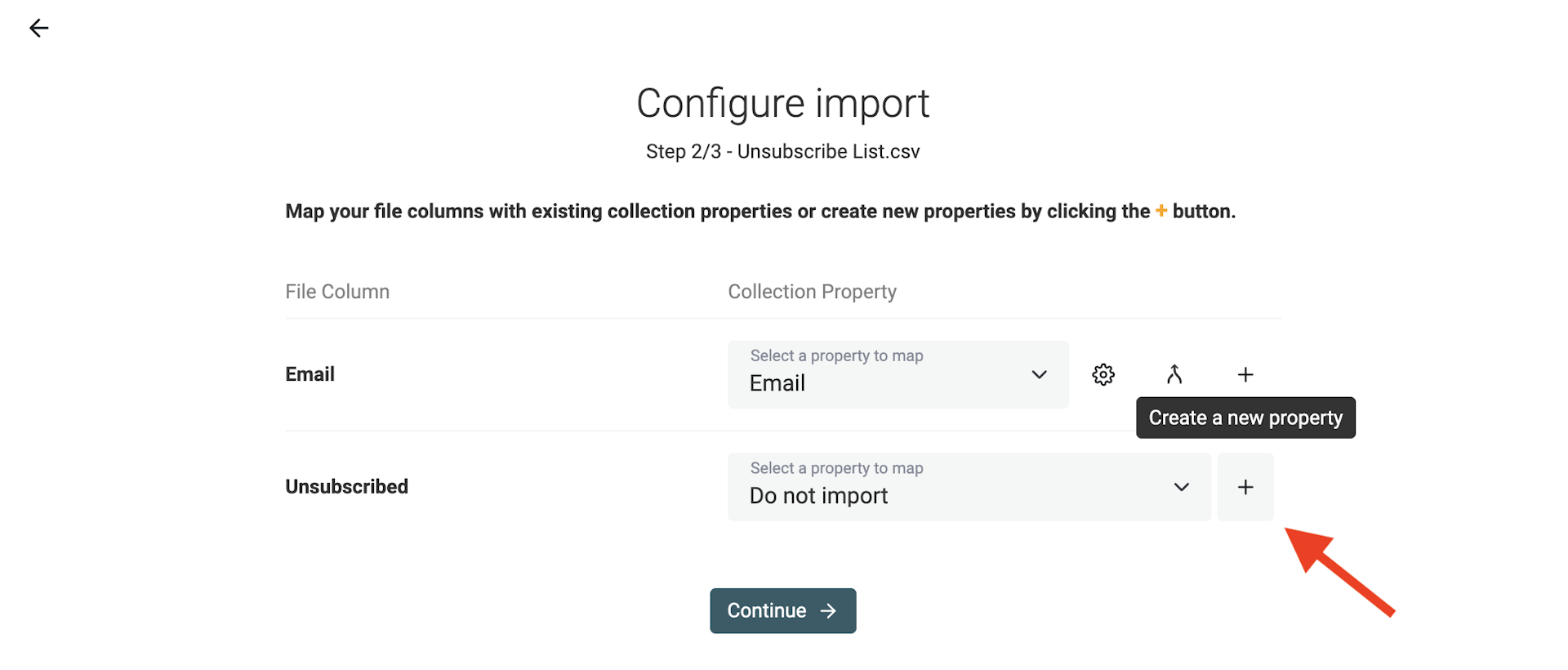
Mappe die Spalte „Email“ auf die Property „Email“, falls das noch nicht passiert ist. Aktiviere dann „Join on property“.

Im nächsten Schritt konfigurierst Du, wie Datablist die Join-Operation auf der CSV-Datei ausführen soll.
- Import all rows and match when possible – Wenn eine E-Mail aus der Unsubscribed-Datei nicht in Deiner Collection existiert, wird ein neues Item angelegt.
- Import only matching rows – Das ist hier die empfohlene Option. Wenn eine E-Mail aus der Unsubscribed-Datei nicht in Deiner Collection existiert, wird sie beim Import übersprungen.
Der „Merging Mode“ legt fest, wie Konflikte zusammengeführt werden. Das ist nützlich, wenn Du Deine Collection aktualisierst und bereits eine „Unsubscribed“-Property hast, die Du updaten willst.
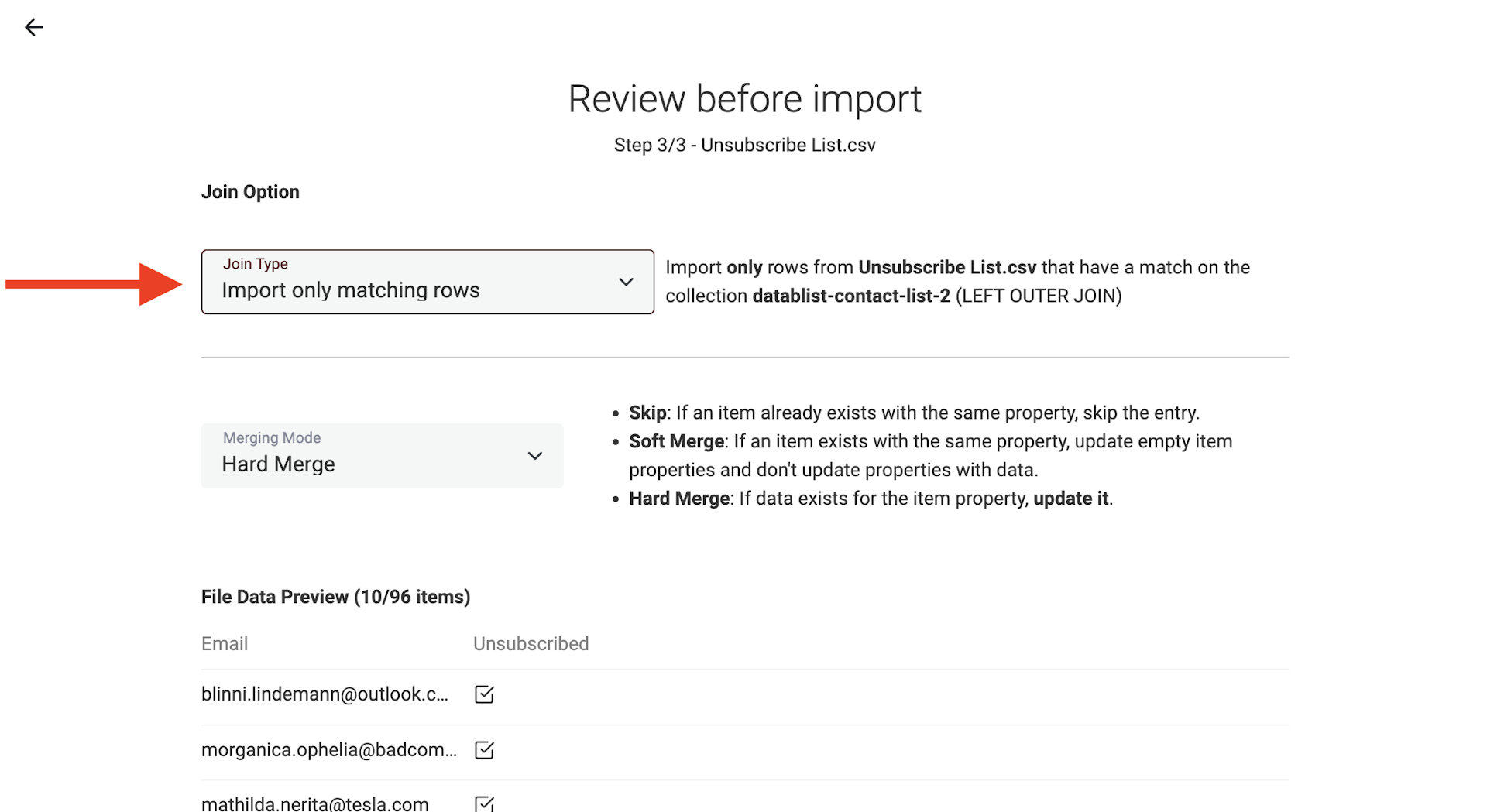
Nach dem Import taucht die neue Property „Unsubscribed“ auf. Jetzt kannst Du nach dieser Property filtern und die entsprechenden Kontakte löschen.

Extra Schritt: Duplikate beim Import automatisch zusammenführen
Damit Duplikate gar nicht erst entstehen (oder direkt beim Import gemerged werden), aktiviere bei der Property „Email“ die Option „do not allow duplicate values“. Damit dedupliziert und merged Datablist Deine Kontakte automatisch beim Import.
Während des Import-Steppers siehst Du dann eine Merging-Option, mit der Du einstellst, wie Datablist mit Duplikaten umgehen soll.
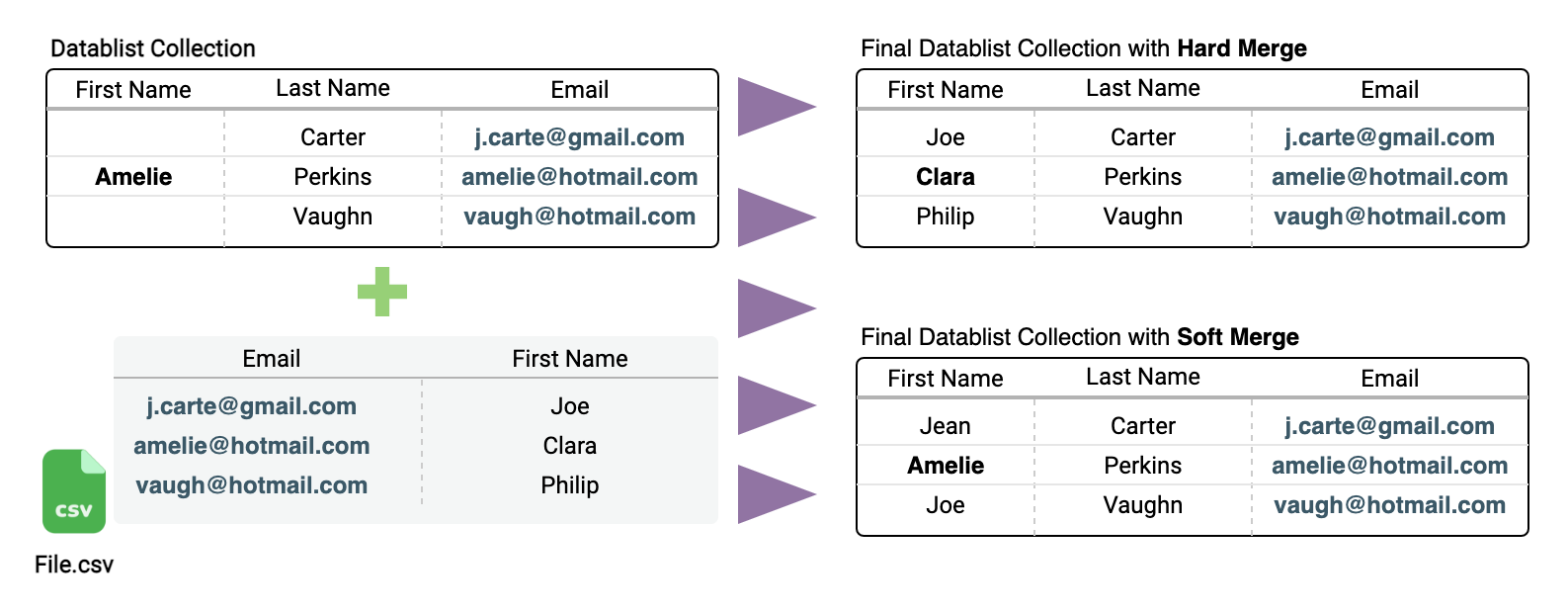
Diese Merging-Option ist besonders wichtig, wenn Deine Liste neben E-Mail-Adressen auch weitere Kontaktinfos enthält.
- Mit
Soft Mergewird bei einem bestehenden Kontakt mit derselben E-Mail nichts überschrieben (Kontakte, die schon in der Collection sind oder der erste Kontakt in der CSV). Das ist die Default-Einstellung. - Mit
Hard Mergewerden bestehende Daten bei gleicher E-Mail aktualisiert.
Wenn Du Feedback zu dieser Anleitung hast oder Fragen auftauchen, schreib uns gern: contact us.