
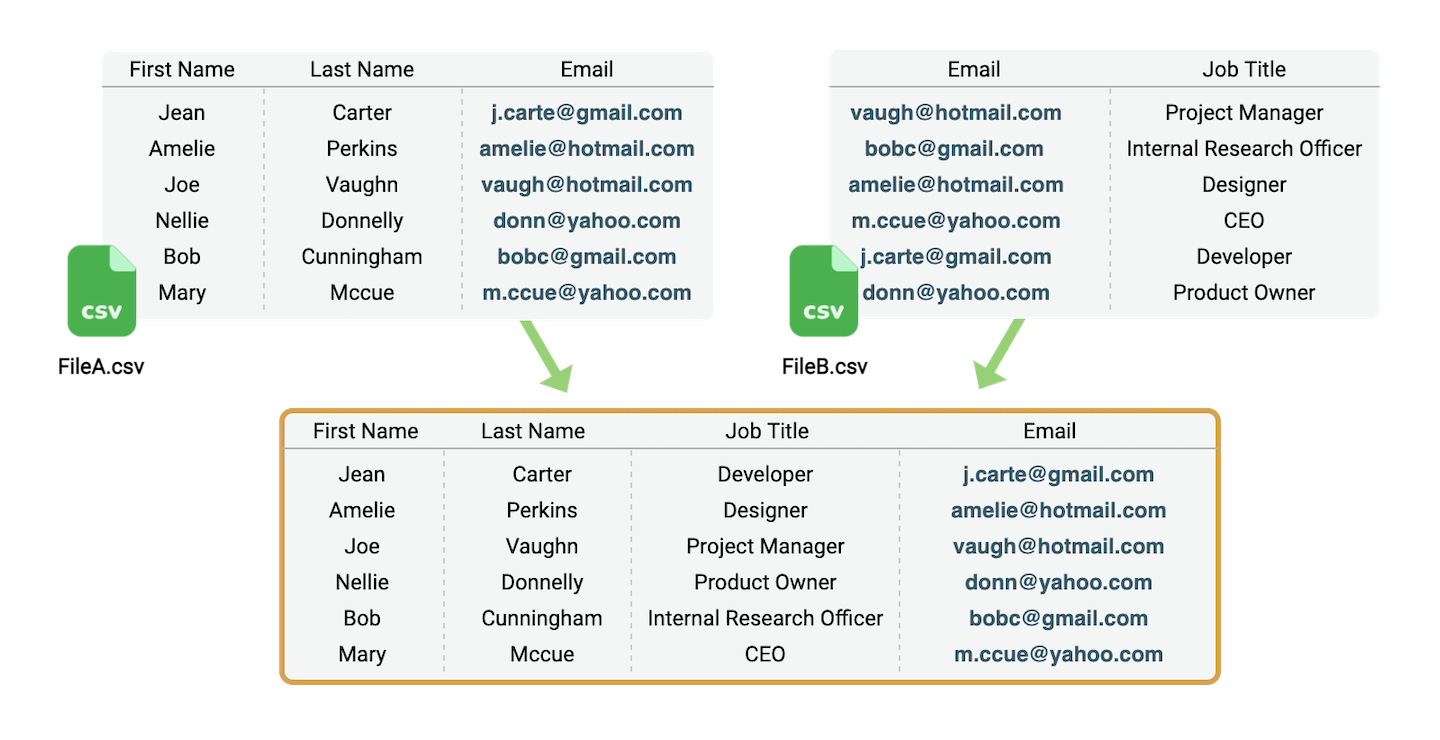
Das CSV-Format ist ein Standard, um strukturierte Daten zwischen Unternehmen oder unterschiedlichen Software-Tools auszutauschen. Es ist textbasiert und trennt Spalten über Trennzeichen wie Kommas.
Hier ein Beispiel für CSV-Daten:
firstName, lastName, email
Joe, Vaughn, vaugh@hotmail.com
Bob, Cunnighan, bobc@gmail.com
CSV-Dateien kannst Du aus den meisten datengetriebenen Tools exportieren – z. B. aus CRMs, Order-Management-Systemen, Spreadsheets (Google Sheets oder Microsoft Excel) oder Finance-Tools. Perspektivisch könnte es häufiger unified data models geben, um strukturierte Daten sauber zwischen Anwendungen zu übertragen. Bis dahin bleiben CSV-Dateien in der Praxis oft die einfachste gemeinsame Basis.
Wenn es ums Bearbeiten von CSVs geht, greifen viele zuerst zu Spreadsheets. Eine CSV in Google Sheets oder Microsoft Excel zu laden, ist schnell erledigt. Aber bei zwei eigentlich simplen Aufgaben stoßen diese Tools an Grenzen:
- CSV-Dateien über eine eindeutige Spalte zusammenführen (Join)
- CSV-Einträge anhand einer eindeutigen Spalte deduplizieren und zusammenführen
Wenn Du einen Join durchführst, nutzt Du eine gemeinsame Spalte, um Daten aus mehreren Quellen zusammenzubringen. Spreadsheets können aber keine echte Unique-Constraint auf einer Spalte definieren – deshalb ist der Support für CSV-Joins oder Deduplication nur eingeschränkt.
Dieser Guide hat 2 Teile:
- CSV-Dateien über eine gemeinsame Spalte mit Datablist joinen
- CSV-Dateien mit Google Sheets (oder Microsoft Excel) joinen
In diesem Tutorial nutzen wir zwei Demo-CSV-Dateien:
Lösung 1: CSV-Dateien über eine gemeinsame Spalte mit Datablist joinen
Mit Datablist wird Datenbearbeitung deutlich einfacher. Schauen wir uns an, wie Du CSV-Dateien über einen eindeutigen Identifier joinst. Open Datablist (No signup required) und los geht’s.
Step1: Deine erste CSV-Datei laden
Als Erstes erstellst Du eine Collection, in die Du Deine CSV-Daten importierst. Klicke in der Sidebar auf +, um eine neue Collection anzulegen.
Sobald die Collection steht, geh in den Bereich „Import CSV“.
Hinweis: Die erste Zeile Deiner CSV muss die Spaltennamen enthalten.
Zieh Deine CSV per Drag & Drop rein oder klicke, um eine Datei von Deinem Computer auszuwählen. Wenn die Datei geladen ist, prüfe kurz in der Vorschau, ob Anzahl der Zeilen und Spalten stimmt, bevor Du weitermachst.
Ordne Deine CSV-Spalten den Properties der Collection zu oder lege neue Properties an.
Zum Schluss klickst Du auf „Import“, um den Import zu starten. Deine erste CSV ist drin!
Step2: Festlegen, welche Spalte der Unique Identifier ist
Jetzt, wo Deine erste CSV importiert ist, kannst Du für eine Property eine „unique values“-Constraint definieren. Mit dieser Info kann Datablist neue CSV-Imports so mergen, dass die Eindeutigkeit eingehalten wird. Geh in die Spalten-Konfiguration und bearbeite die Property, die Dein Unique Identifier sein soll. Aktiviere das Attribut „Unique Values“ und speichere.
Step3: Eine oder mehrere weitere CSV-Dateien laden
Sobald Du eine Unique-Constraint auf einer Property gesetzt hast, importierst Du Deine weiteren CSV-Dateien nacheinander in dieselbe Collection. Falls nötig, legst Du beim Mapping neue Properties an.
Wenn Deine Collection bereits Items hat und eine Unique-Constraint aktiv ist, kannst Du beim CSV-Import einen Merging-Modus auswählen.
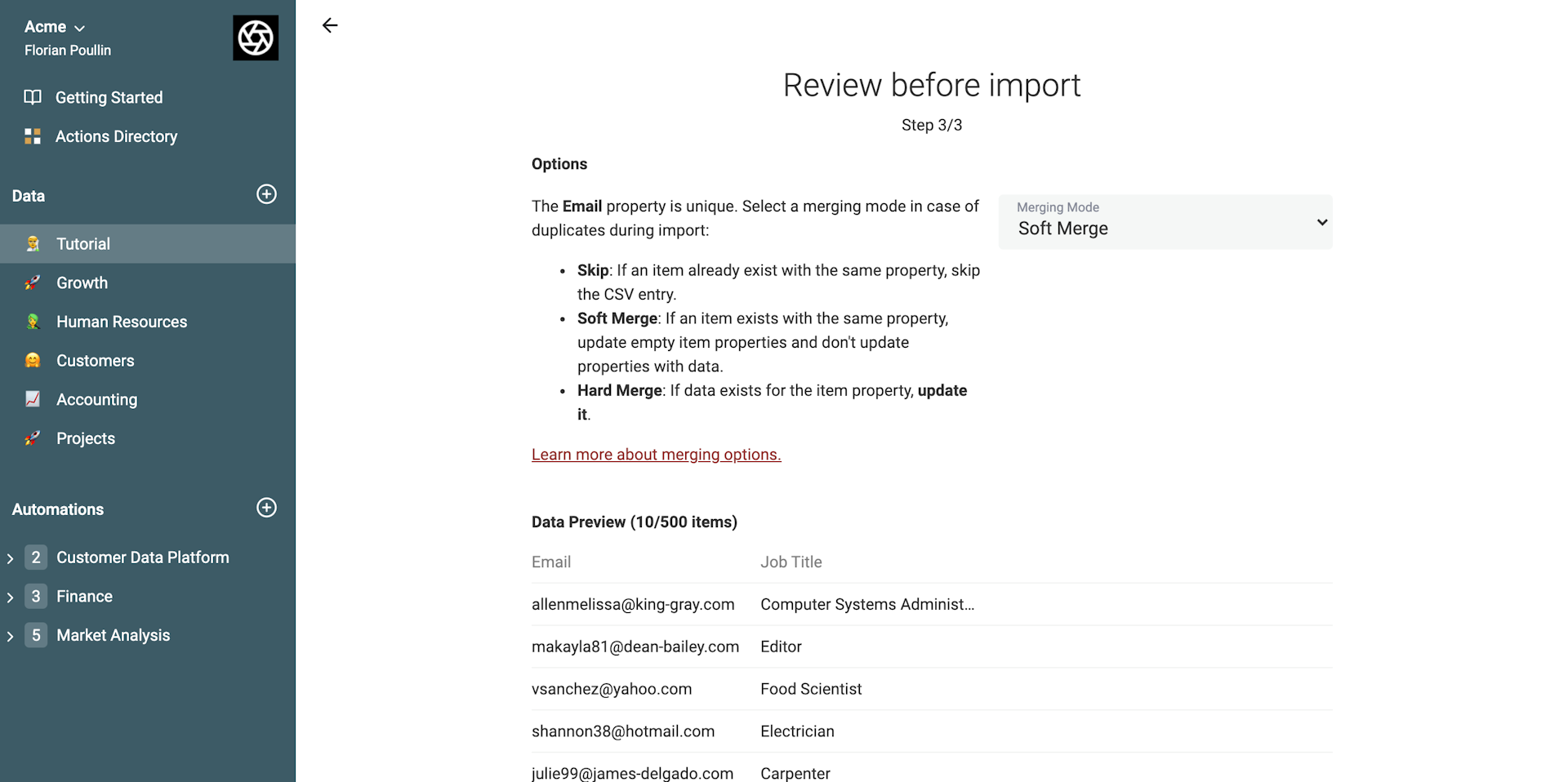
Wähle aus, wie die Daten in die Collection gemergt werden sollen:
- Soft Merge: Wenn für eine Property bereits Daten existieren, nicht überschreiben. (Default)
- Hard Merge: Wenn für eine Property bereits Daten existieren, überschreiben
Die Option „Skip item“ überspringt die Zeile, wenn ein Eintrag mit demselben Identifier-Wert schon in der Collection existiert. Um CSV-Dateien wirklich zu joinen, darf diese Option nicht ausgewählt werden.
Step 4: Bei Bedarf wieder als CSV exportieren
Glückwunsch! 🎉 Du hast CSV-Dateien erfolgreich über eine gemeinsame Spalte kombiniert. Wenn Du das Ergebnis in einem anderen Tool weiterverwenden willst, klicke auf „Export“, um die Collection wieder als CSV-Datei zu exportieren.
Komplettes Step-by-Step-Video: CSV-Dateien mit Datablist joinen
Im Video unten wird die „unique values“-Einstellung direkt beim Anlegen der Property gesetzt.
Lösung 2: CSV-Dateien mit Google Sheets (oder Microsoft Excel) joinen
Spreadsheet-Tools bieten nur begrenzte Möglichkeiten, CSV-Dateien über eine gemeinsame Spalte zusammenzuführen. Eine Zell-Formel kann aber in einer anderen Tabelle nach einer passenden Zeile suchen. Wenn Du das auf jede Zeile anwendest, kannst Du in einer zweiten Tabelle suchen und aus der gefundenen Zeile Werte aus beliebigen Spalten zurückgeben.
Die Formel heißt VLOOKUP und ist sowohl in Microsoft Excel als auch in Google Sheet verfügbar.
Einschränkungen
- In Spreadsheets ist eine CSV die Master-Tabelle und muss alle möglichen Werte für die Join-Spalte enthalten.
- In allen Secondary-Tabellen muss die Join-Spalte die erste Spalte sein.
Step 1: Deine CSV-Dateien laden
In diesem Tutorial nutzen wir Google Sheets (die Formel
VLOOKUPfunktioniert in Microsoft Excel sehr ähnlich).
Wähle unter Deinen CSVs die Datei mit den meisten Werten als Master-Tabelle aus. Die anderen sind Deine Secondary-CSV-Dateien.
Lade zuerst die Master-CSV über File -> Import und wähle Deine CSV aus (im Tab Upload, wenn Du die Datei von Deinem Computer hochladen willst).
Bei Import Location wählst Du Insert new sheet(s).
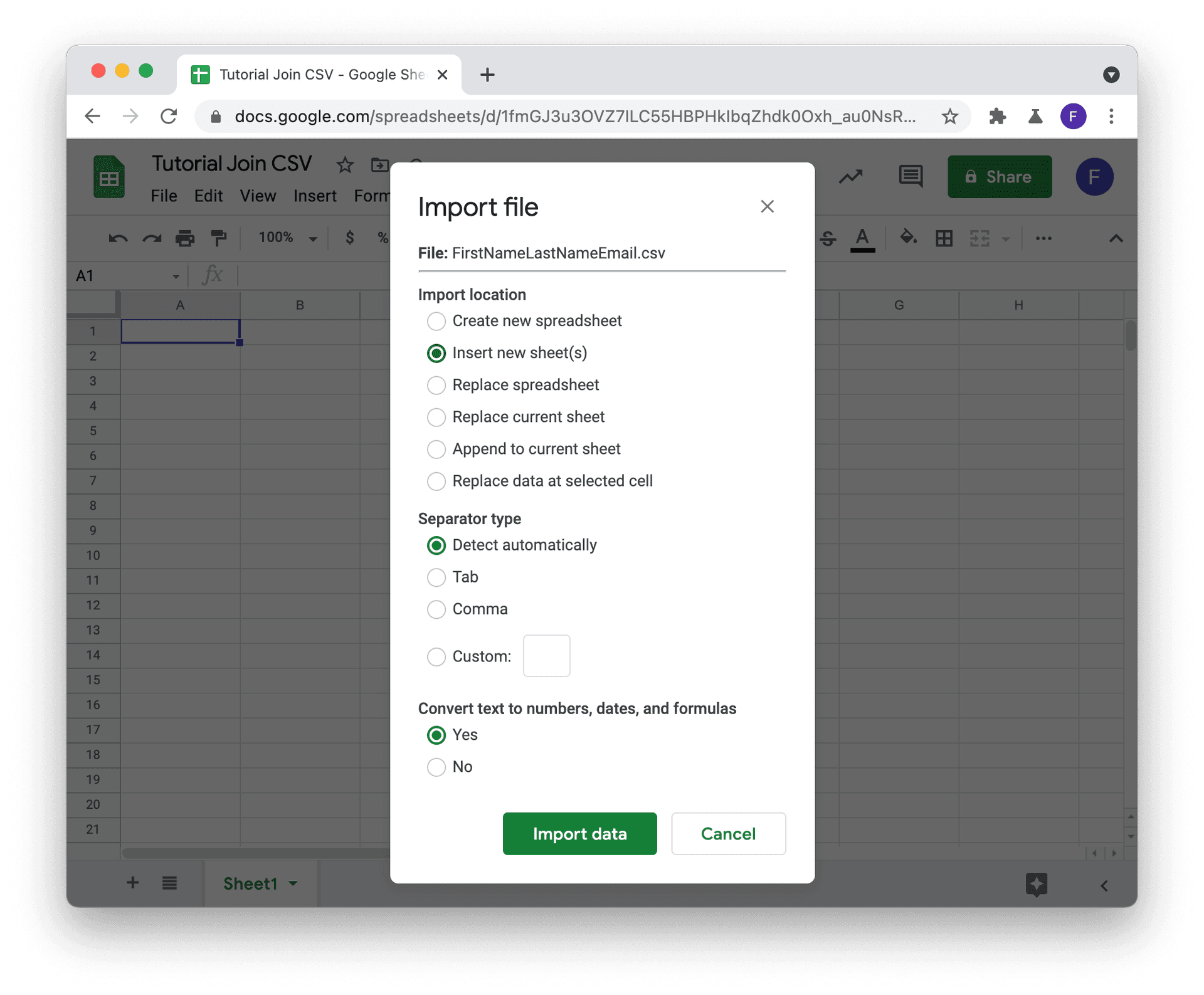
Wiederhole das für Deine Secondary-CSV-Datei(en). Jede CSV muss in ein eigenes Sheet innerhalb des Spreadsheets importiert werden.

Step 2: Neue Spalten im Master-Sheet anlegen
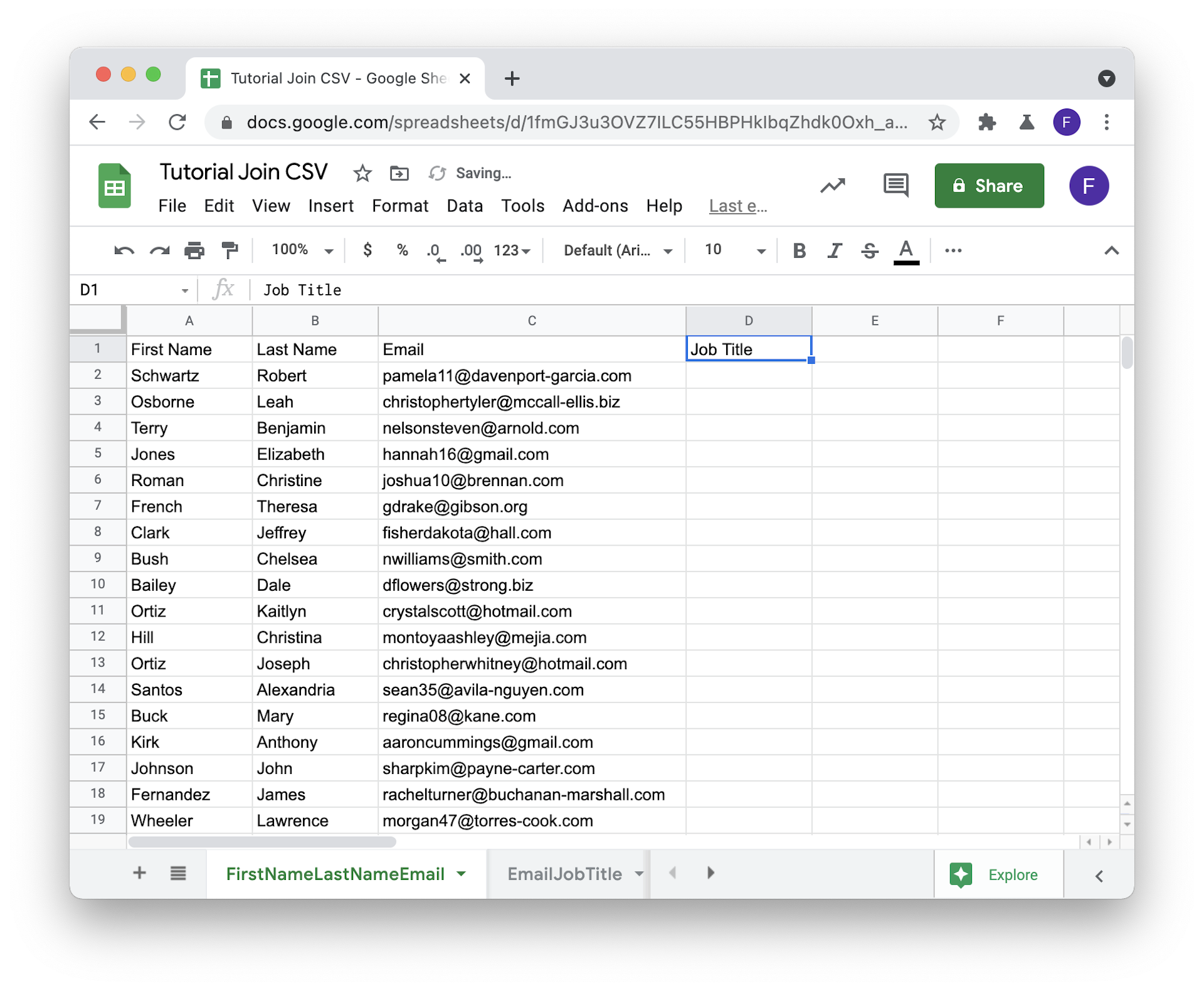
Das Sheet mit Deiner Master-CSV ist die Master-Tabelle – dort landen am Ende die Werte aus den anderen Tabellen. Lege in der Master-Tabelle neue Spalten an, um Daten aus den Secondary-Tabellen aufzunehmen.
In diesem Tutorial wollen wir die Job Title-Daten aus der Secondary-Tabelle in die Master-Tabelle holen – also fügen wir eine leere Spalte Job Title hinzu.
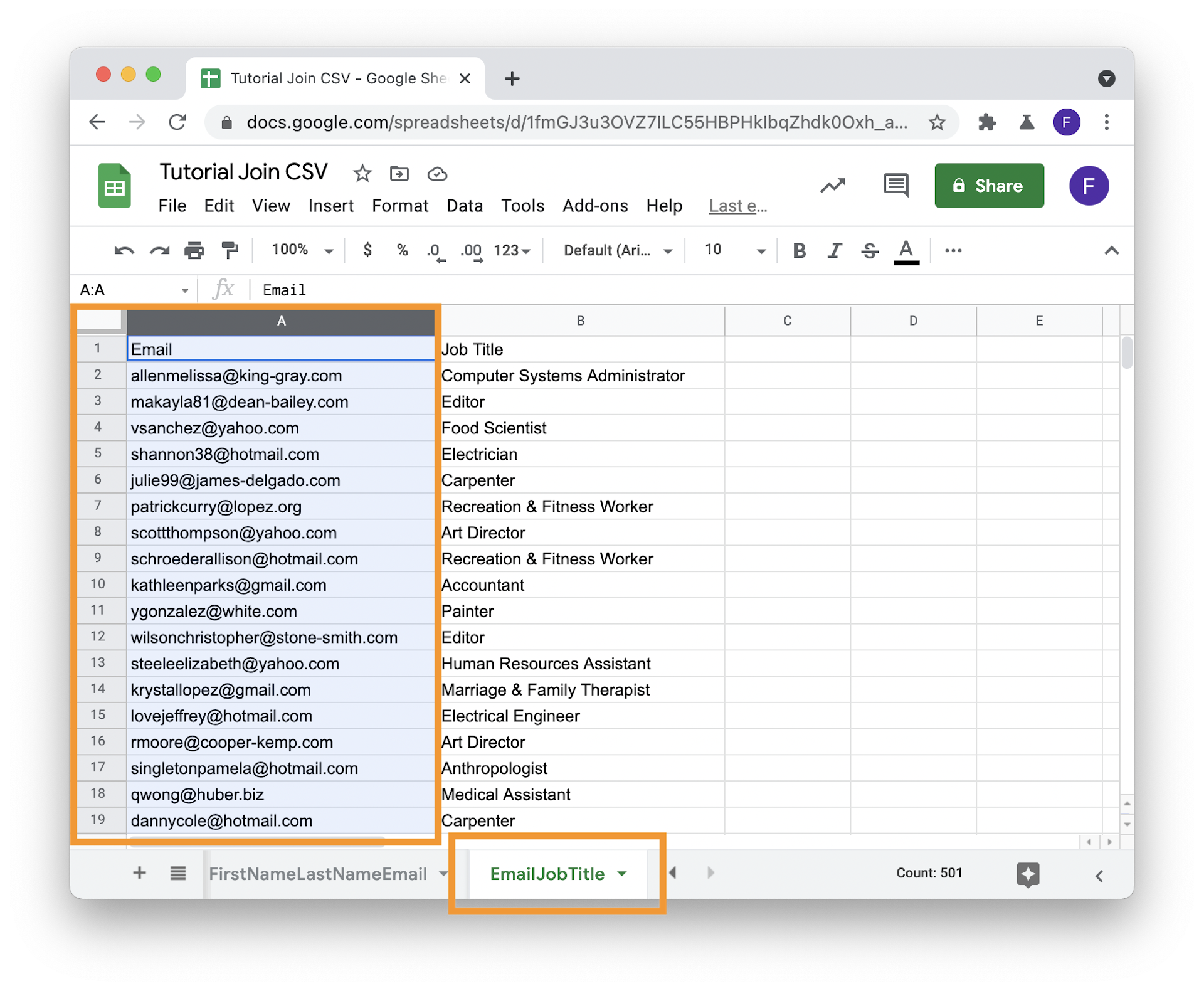
Step 3: In Secondary-Tabellen die Unique-Spalte nach vorne ziehen
VLOOKUP sucht immer in der ersten Spalte des Bereichs, in dem gesucht wird. Schiebe deshalb in all Deinen Secondary-Tabellen (in der Master-Tabelle musst Du das nicht machen) die Join-Spalte ganz nach vorne.
Step 3: Die VLOOKUP-Formel anwenden
Zum Schluss nutzt Du VLOOKUP, um in den anderen Tabellen passende Zeilen zu finden und aus der gefundenen Zeile eine Spalte zurückzugeben.
Die Formel hat 3 Argumente (plus ein optionales):
- search_key – Der Wert, nach dem gesucht wird. Das ist der Wert aus der Unique-Identifier-Spalte.
- range – Der Suchbereich. In der ersten Spalte dieses Bereichs wird nach dem search_key gesucht. Nimm als range am besten die komplette Secondary-Tabelle (siehe Video).
- index – Der Spaltenindex, der zurückgegeben werden soll. Die erste Spalte im range hat den Index 1.
- is_sorted – [Standardmäßig TRUE] – Gibt an, ob die Suchspalte (erste Spalte des Bereichs) sortiert ist. In den meisten Fällen ist FALSE die bessere Wahl. Wenn Du TRUE setzt und Deine Daten nicht sortiert sind, bekommst Du falsche Ergebnisse.
VLOOKUP(search_key, range, index, [is_sorted])
Im Video siehst Du, wie Du VLOOKUP nutzt, um Daten über eine eindeutige Spalte zu joinen:
Mehr zur VLOOKUP-Formel in der Google-Sheets-Dokumentation.
Wiederhole das für jede weitere Spalte, die Du aus Deinen Secondary-Tabellen übernehmen willst 💪.