
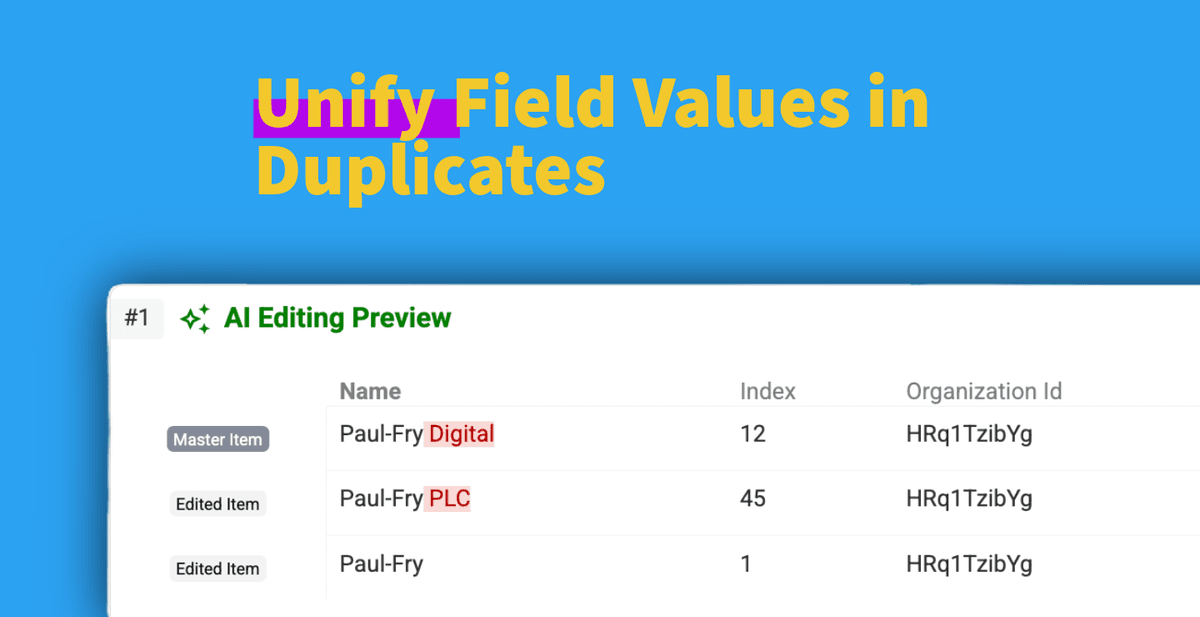
Lidiar con registros duplicados en sus datasets es un dolor habitual. Detectarlos es el primer paso, pero limpiarlos suele ser otro reto distinto.
A veces, no quiere fusionar los duplicados todavía.
Quizá tenga la misma empresa repetida con nombres ligeramente distintos ("Innovate Corp", "Innovate Corporation", "Innovate Corp.") en varios registros duplicados.
¿Y si pudiera estandarizar un campo concreto, como el nombre de la empresa o el cargo, en todos los registros de un grupo de duplicados sin fusionar los registros?
En esta guía aprenderá a normalizar valores de campos específicos en grupos de duplicados manteniendo intactos los registros individuales:
- Qué es la normalización de datos
- AI Processing en Duplicates Finder
- Cómo normalizar datos en duplicados (paso a paso)
Qué es la normalización de datos
En este contexto, normalizar datos significa llevarlos a un formato coherente. Al trabajar con duplicados, las incoherencias suelen estar en campos concretos. Por ejemplo:
- Nombres de empresa: "Tech Solutions Inc.", "Tech Solutions, LLC", "Tech Solutions"
- Cargos: "Software Engineer", "Software Dev.", "Eng., Software"
- Direcciones: "123 Main St", "123 Main Street", "123 main st"
- Países: "USA", "United States", "U.S.A."
La normalización busca elegir un único valor estándar (como "Tech Solutions" o "United States") y aplicarlo al campo correspondiente en todos los registros identificados como duplicados.
Esto deja sus datos más limpios, fáciles de analizar y fiables para filtrar o reportar, incluso si los registros duplicados siguen separados. Es un paso clave dentro del data cleaning.
AI Processing en Duplicates Finder
Duplicates Finder de Datablist ya es una herramienta potente para identificar registros similares. Además de sus opciones para fusionar duplicados de forma automática o manual, el modo AI Processing añade una capa extra de flexibilidad.
En lugar de reglas de fusión predefinidas, AI Processing le permite definir la lógica con un prompt en lenguaje natural. Usted le indica a la IA exactamente cómo tratar los duplicados. Incluye tareas como:
- Seleccionar un registro maestro con criterios concretos (p. ej., el más actualizado).
- Fusionar campos específicos manteniendo otros separados.
- Realizar cálculos durante la fusión (como sumar valores).
- 👉 Y, clave para esta guía: Actualizar un campo específico en todos los duplicados con un único valor normalizado sin fusionar los registros.
Convierte la complejidad de programar transformaciones de datos en una simple conversación con nuestra IA.
Cómo normalizar datos en duplicados (paso a paso)
Veamos el proceso para usar AI Processing y normalizar un campo (por ejemplo, Company Name) en registros duplicados.
Paso 1: Prepare sus datos
Primero, cargue sus datos en Datablist.
- Crear una Collection: Haga clic en el botón '+' de la barra lateral para crear una nueva collection.
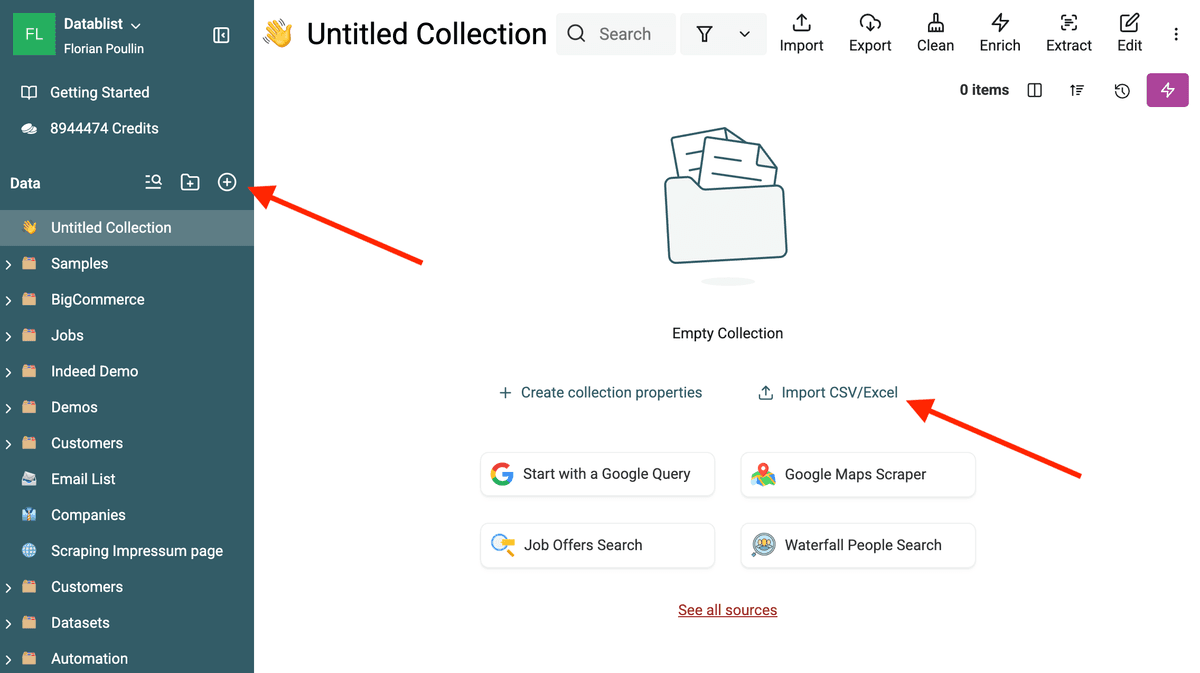
- Importar datos: Importe sus datos desde un archivo CSV o Excel. Si su información viene de varios archivos, impórtelos en la misma collection. Datablist le guiará para mapear columnas a propiedades. Asegúrese de importar correctamente el campo que desea normalizar (p. ej., Company Name) y los campos que usará para identificar duplicados (p. ej., Email, Website).

En este dataset de ejemplo ya se ven algunos nombres de empresa duplicados que conviene normalizar.
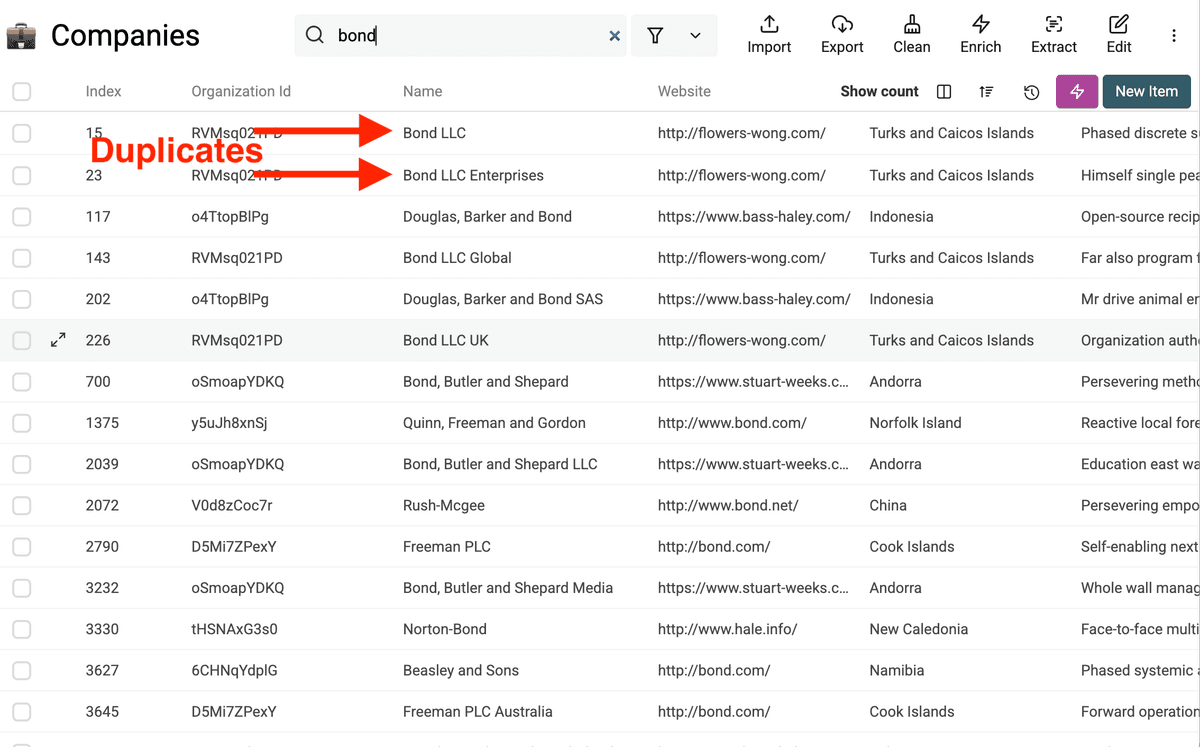
Paso 2: Encontrar duplicados
Ahora, identifique los registros duplicados.
2.a. Abrir Duplicates Finder
Haga clic en "Clean" en el menú superior y seleccione "Duplicates Finder".
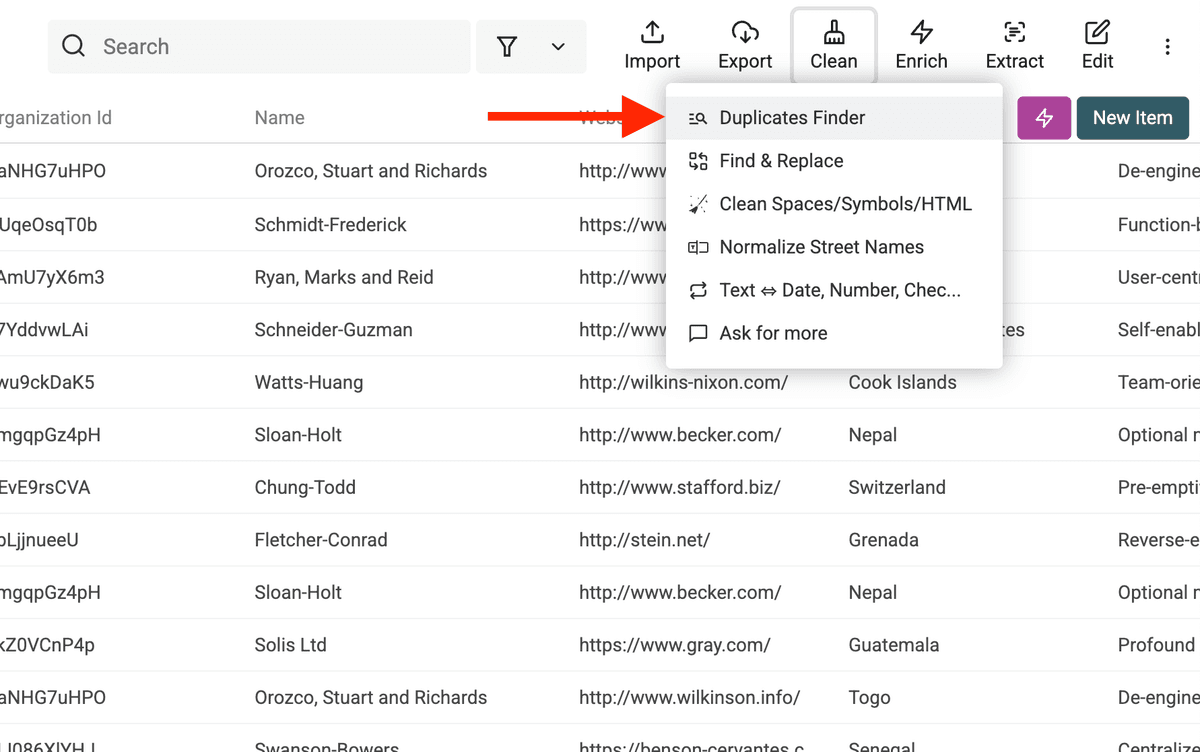
2.b Elegir identificadores de deduplicación
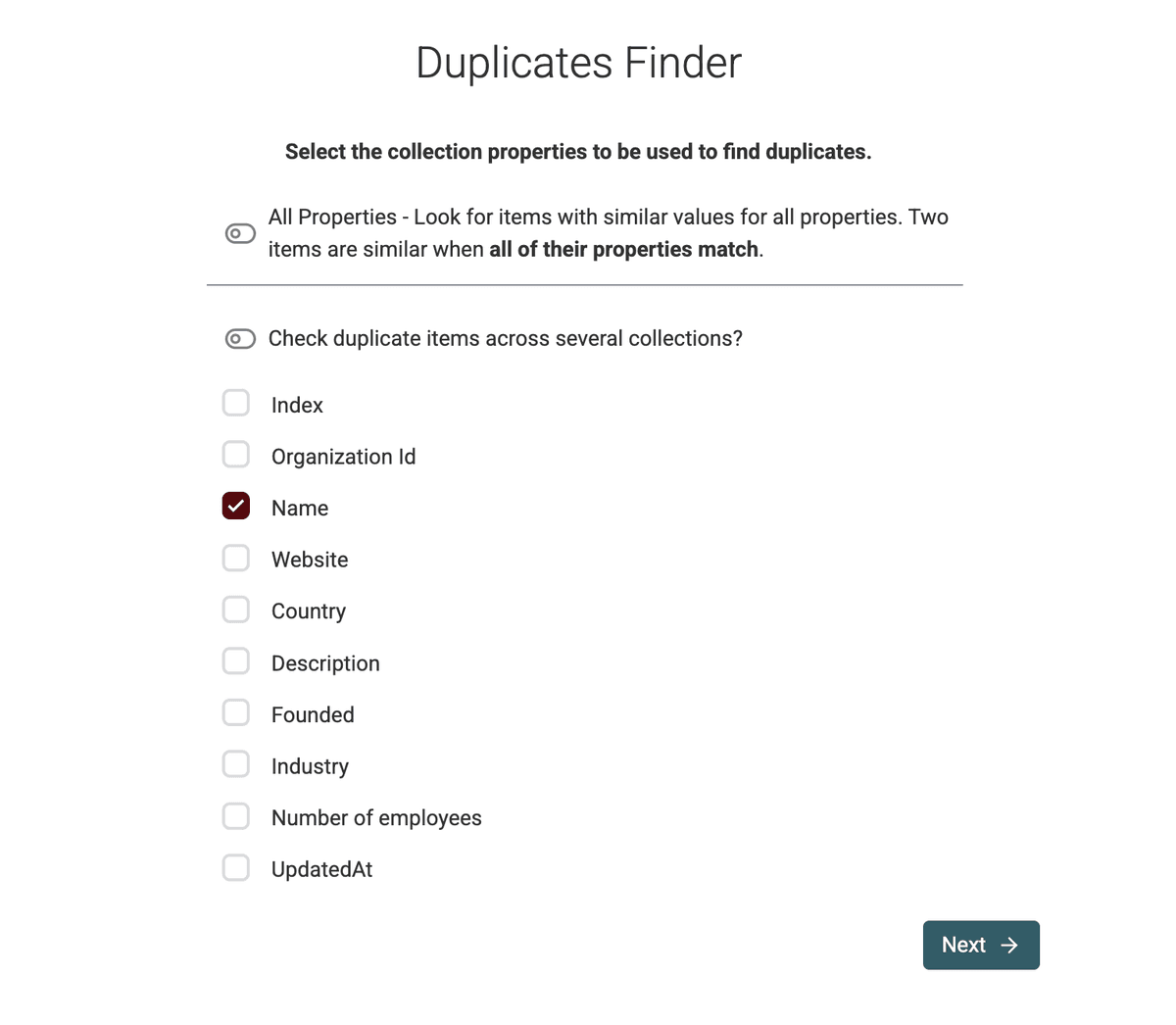
Seleccione la propiedad (o propiedades) que identifican un duplicado de forma única.
En nuestro ejemplo, queremos dedupe company names. Así que seleccionamos el campo del nombre.
Para empresas, también puede usar
Website URLoLinkedIn Company Page URL.Para contactos,
Phone Numberson opciones habituales.
2.c Configurar algoritmo
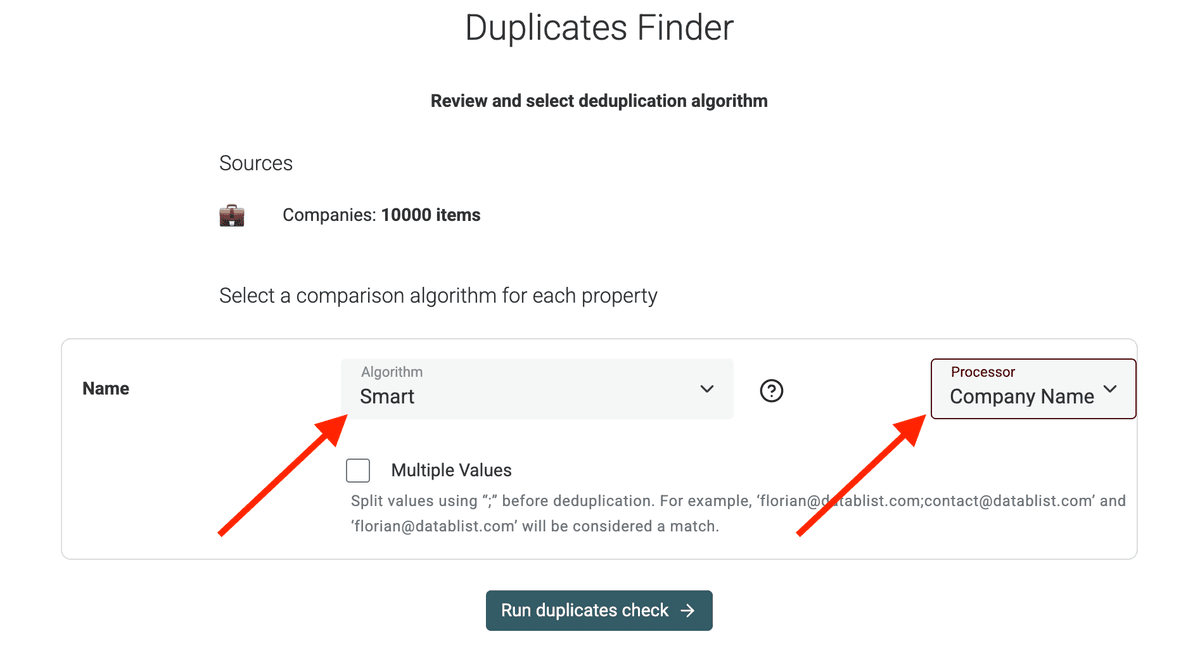
En el siguiente paso, elija el algoritmo de coincidencia.
"Smart" suele funcionar bien para URLs o emails, tolerando pequeñas variaciones. "Exact" es más estricto. También puede usar coincidencia fonética o difusa para nombres.
Seleccione también el Processor que mejor se ajuste a sus datos.
Aquí selecciono el Company Name processor para tratar variaciones específicas de nombres de empresa (sufijos legales, términos geográficos, etc.).
2.c Ejecutar comprobación
Haga clic en "Run duplicates check".
Datablist analizará sus datos y presentará grupos de posibles duplicados.
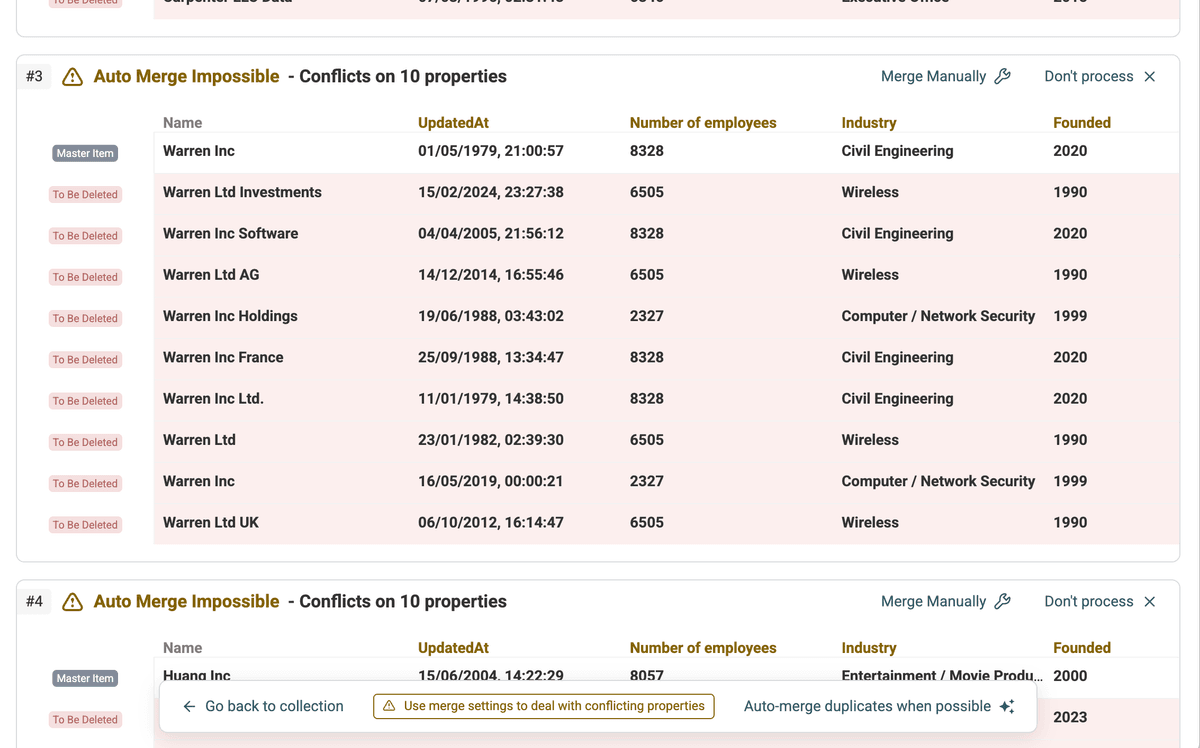
Paso 3: Seleccionar modo AI Processing
En lugar de usar "Auto Merge" o la fusión manual, haga clic en el botón AI Editing en la página de resultados de duplicados. Esto activa el modo de procesamiento asistido por IA.
Paso 4: Escribir el prompt de normalización
Aquí le dirá a la IA qué hacer. Debe indicarle que:
- Identifique el valor más común para la propiedad objetivo dentro de cada grupo de duplicados.
- Actualice todos los registros del grupo para usar ese valor común en ese campo específico.
- Especifique de forma explícita que no se borre ningún registro.
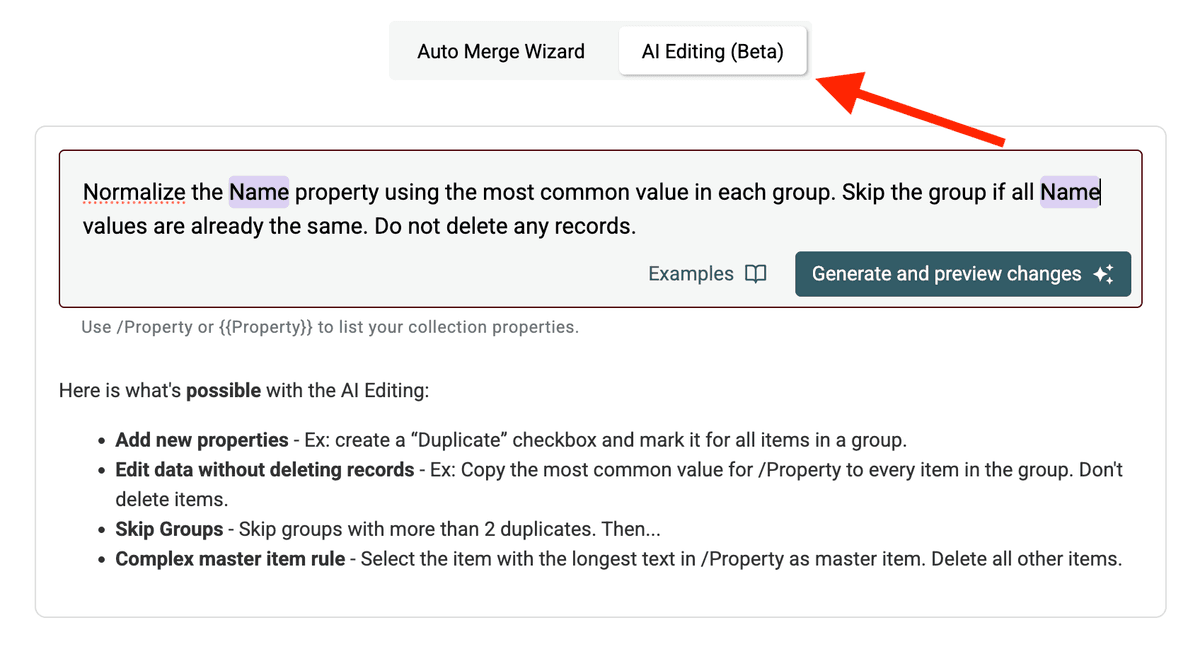
Aquí tiene un prompt de ejemplo para normalizar la propiedad /CompanyName:
Desglose del prompt:
Normalize the /CompanyName property...: especifica el campo objetivo. Use/PropertyNameo{{PropertyName}}para referenciar sus columnas....using the most common value in each group.: define la lógica para elegir el valor estándar. También podría usar otros criterios como "longest value", "shortest value" o referenciar otro campo (p. ej., "use the value from the record with the latest /UpdatedAt date").Skip the group if all /CompanyName values are already the same.: instrucción de eficiencia para evitar procesado innecesario.Do not delete any records.: crucial para asegurar que solo se actualizan campos y no se fusiona ni elimina ningún registro.
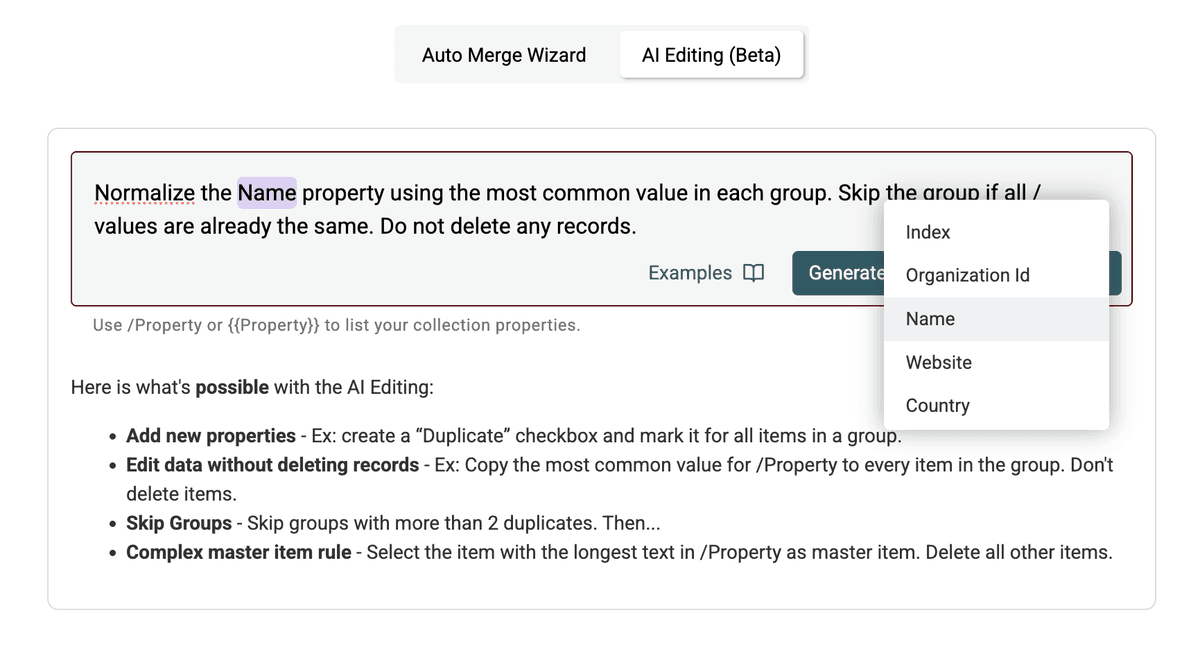
Paso 5: Generar y previsualizar el script
Haga clic en Generate and preview changes. La IA de Datablist interpretará su prompt y generará un script para ejecutar la acción.
No se preocupe, no tiene que escribir ni editar ningún script.
- Explicación del script: Un resumen en texto claro de lo que hará el script. Verifique que coincide con su intención.
- Vista previa de resultados: Una tabla que muestra con precisión cómo modificará el script una muestra de sus grupos de duplicados, antes de aplicar cambios. Revise el campo objetivo (p. ej.,
/Company Name) en la vista previa para confirmar que refleja el valor normalizado previsto en los duplicados de la muestra.
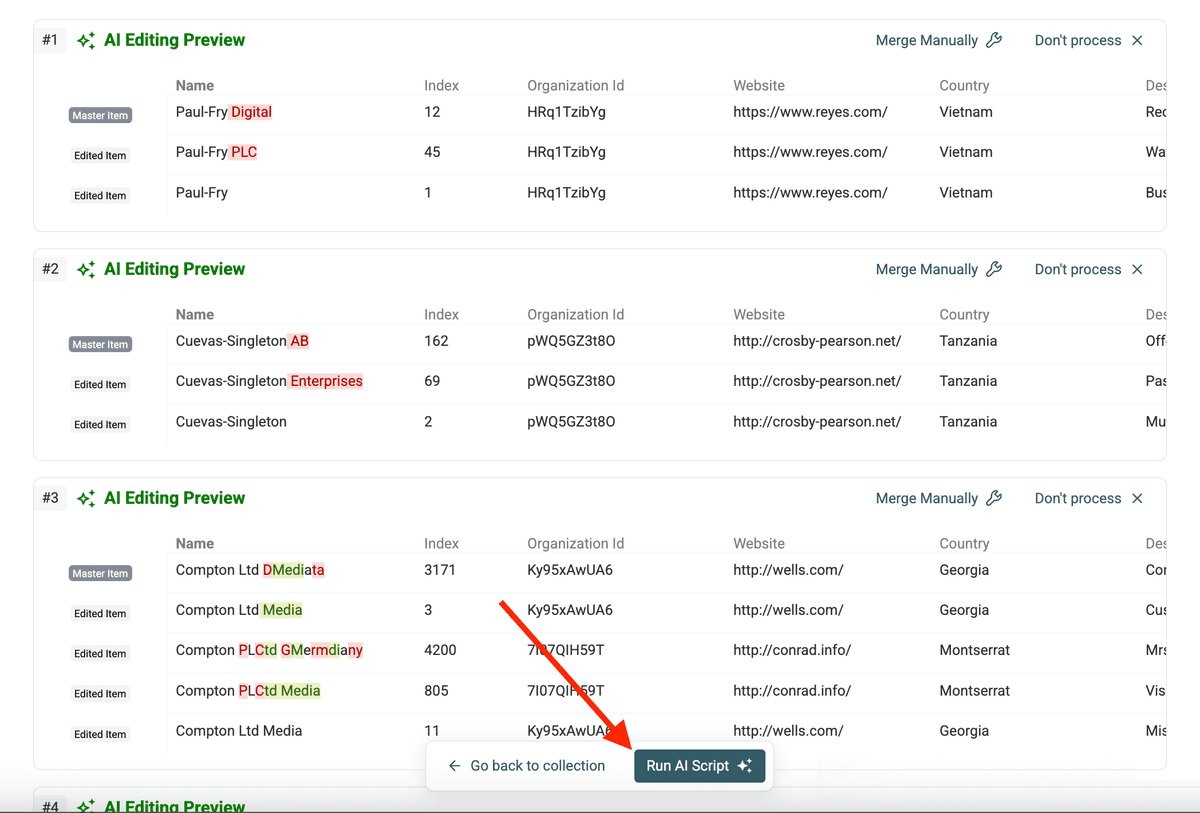
Paso 6: Ejecutar el script
Si la explicación y la vista previa son correctas, haga clic en Run AI Script. Datablist ejecutará el script generado en todos los grupos de duplicados identificados.
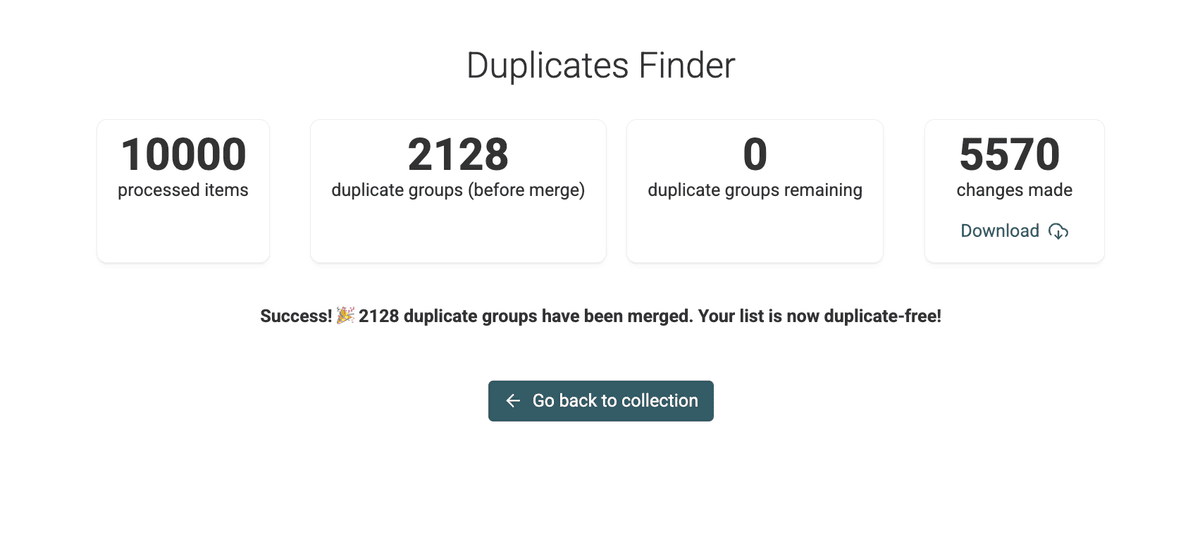
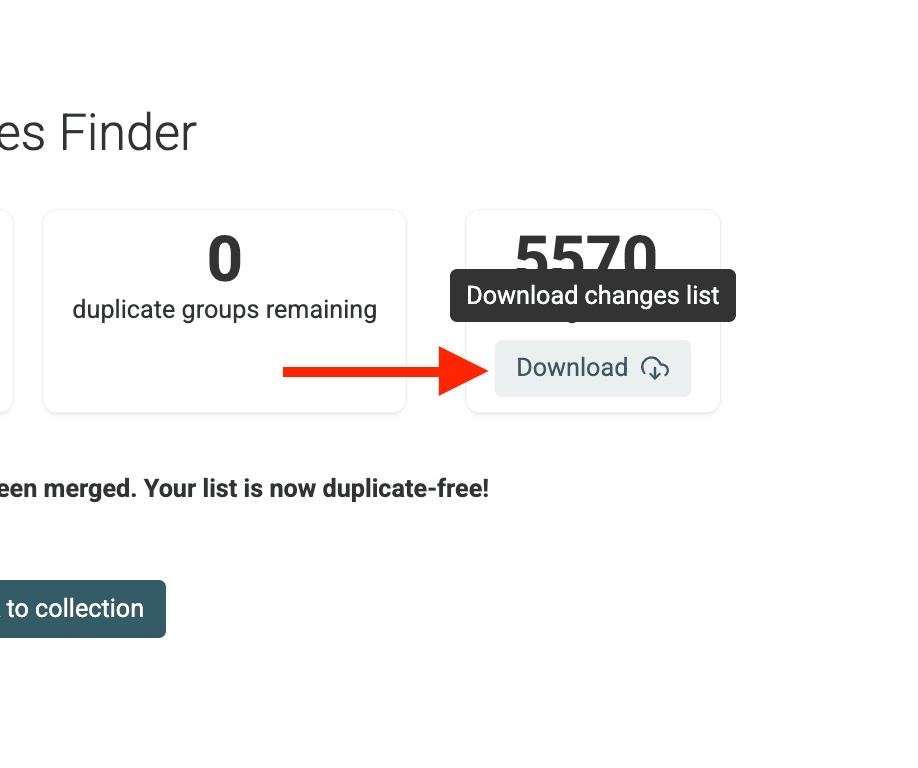
Paso 7: Revisar cambios
Cuando termine el script, Datablist le mostrará un resumen y un Changes List descargable.
Es útil cuando necesita reproducir los cambios en un sistema externo (por ejemplo, para editar leads en su CRM, etc.)
Vuelva a la vista principal de su collection. Verá que el campo objetivo (p. ej., /CompanyName) ahora es consistente en los registros dentro de los grupos de duplicados, mientras los registros siguen separados.
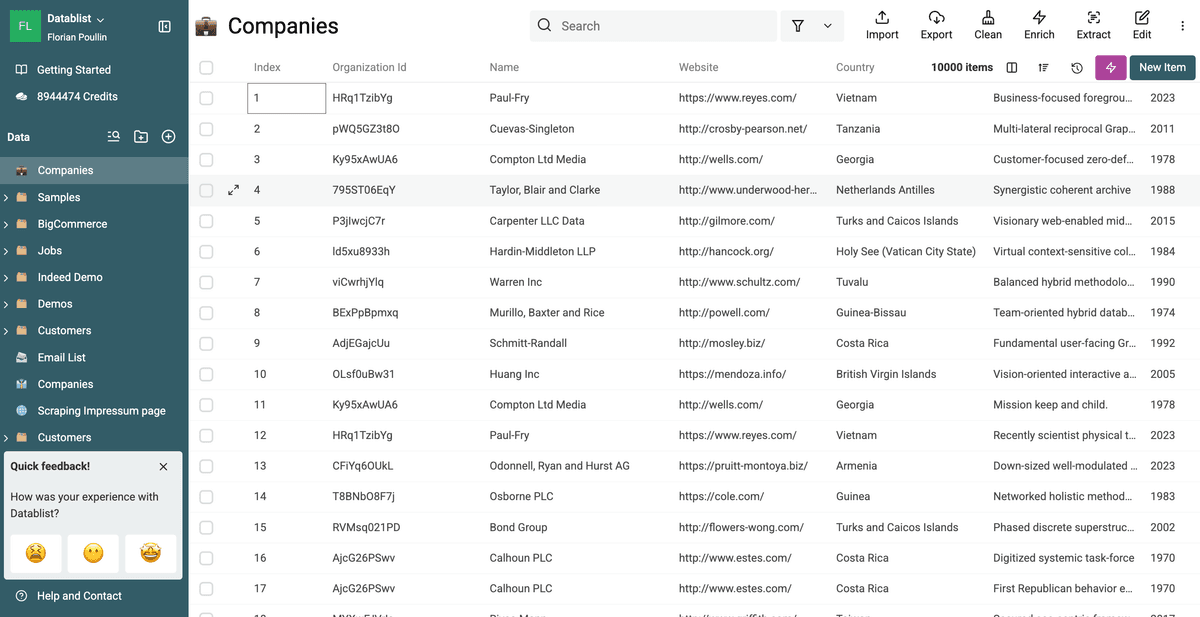
¡Ha normalizado un campo en duplicados sin fusionar! 🚀
Casos de uso para normalizar sin fusionar
¿Cuándo conviene normalizar un campo en lugar de hacer una fusión completa?
- Estandarizar nombres de empresa o contacto: Limpie variaciones como "Example Ltd", "Example Limited" o "Jon Doe", "Jonathan Doe" en duplicados antes de decidir su estrategia final de fusión.
- Limpiar cargos: Unifique títulos como "VP Marketing", "Vice President Marketing", "Marketing VP" para reportes o análisis consistentes.
- Normalizar ubicaciones: Asegure nombres de país coherentes ("UK", "United Kingdom") o abreviaturas de estado ("CA", "California") en registros de dirección duplicados.
- Preparación para importar/actualizar en el CRM: Estandarice campos clave antes de importar datos a un CRM con reglas de validación estrictas, incluso si mantiene los duplicados temporalmente.
- Auditoría de datos: Conserve los registros duplicados originales para auditoría o histórico, pero estandarice identificadores clave para facilitar el análisis.
- Limpieza incremental: Normalice un campo cada vez como parte de un flujo de data cleaning más amplio antes de comprometerse con una fusión o eliminación definitiva.
Por qué normalizar en lugar de fusionar
- Preserva la granularidad de los registros: Mantiene intactos los duplicados individuales, algo útil para rastrear orígenes, interacciones específicas o datos históricos ligados a cada registro.
- Gestiona la incertidumbre: Útil cuando los duplicados no son coincidencias perfectas. Normalizar un campo clave aporta consistencia sin forzar una fusión potencialmente incorrecta de registros con otros datos diferentes.
- Enfoque por etapas: Permite un proceso de data cleaning más controlado. Primero normalice, luego revise y decida si conviene fusionar o eliminar.
- Simplicidad: Es una acción enfocada. Apunta a la consistencia de un solo campo sin afectar el resto de datos en los registros duplicados.
Conclusión
La función AI Processing de Duplicates Finder ofrece una forma flexible y potente de gestionar datos duplicados. Al permitir normalizar campos concretos en grupos de duplicados sin fusionar registros, es un paso intermedio clave en muchos flujos de data cleaning. Con prompts en lenguaje natural, logrará consistencia de datos de forma rápida y eficiente, ahorrando horas de trabajo manual y reduciendo errores. Ya sea para estandarizar nombres de empresa, cargos o ubicaciones, esta función le da el control de la calidad de sus datos.
FAQ
-
¿AI Processing está incluido en mi plan de Datablist? AI Processing, incluido generar y ejecutar scripts para normalización, está disponible en los planes de pago de Datablist. Consulte nuestra Pricing Page para más detalles.
-
¿Puedo normalizar varios campos con un solo prompt? Sí. Puede escribir un prompt para normalizar varios campos a la vez. Por ejemplo: "Normalize the /Company Name property using the most common value in each group. Normalize the /Country property using the most common value in each group. Do not delete any records."
-
¿Y si la IA no interpreta bien mi prompt? Revise siempre con atención la explicación del script y la vista previa antes de ejecutarlo. Si la vista previa no es correcta, refine el prompt para que sea más claro y específico y vuelva a generar el script.
-
¿Puedo deshacer los cambios del script de IA? Una vez ejecutado el script, los cambios se aplican directamente. Aunque Datablist tiene una función de deshacer para acciones recientes dentro de la sesión, es buena práctica clonar su collection antes de realizar transformaciones importantes, así podrá revertir si lo necesita.
-
¿En qué se diferencia de la opción estándar "Combine conflicting properties" al fusionar? La opción "Combine" estándar fusiona los duplicados en un único registro maestro y concatena los valores de texto en conflicto en un solo campo. Con AI Processing, y el prompt adecuado, se actualiza el campo en todos los registros duplicados con un valor elegido y se mantienen separados los registros. No fusiona ni concatena valores salvo que se le indique expresamente.