
Todo scraper basado en código está diseñado para la estructura de un solo sitio web. En cuanto apunta ese mismo script a otra web, los selectores dejan de coincidir, la página vuelve vacía y el script falla.
Un prompt no se rompe así. Usted describe lo que quiere con palabras sencillas, y un agente de IA interpreta cada página desde cero, en lugar de depender de reglas codificadas para un único diseño.
Ese cambio lo transforma todo: ahora puede scrapear casi cualquier sitio web sin código y extraer datos limpios de casi cualquier página en minutos, no en horas.
📌 Resumen para quienes van con prisa
La idea clave: ya no necesita un scraper distinto para cada web. Los scrapers basados en código dependen de la estructura de un sitio concreto, mientras que un AI scraping agent se adapta a distintas páginas a partir de un solo prompt en lenguaje natural.
En este artículo verá cómo una sola herramienta puede scrapear prácticamente cualquier sitio web y cómo hacerlo paso a paso con el AI Scraping Agent de Datablist.
Qué se llevará de esta guía:
- Una visión clara de por qué los scrapers con código y los basados en plantillas fallan entre sitios
- Cómo se compara el AI scraping con los métodos no-code más antiguos
- Un paso a paso para scrapear cualquier sitio web
Qué cubre esta guía
- Qué significa realmente scrapear cualquier sitio web sin código
- Cómo se compara el AI scraping con los métodos no-code y con código
- Qué buscar en una herramienta que funcione en cualquier sitio
- Guía paso a paso con el AI Scraping Agent de Datablist
- Preguntas frecuentes
Qué significa realmente “scrapear cualquier sitio web”
Hace dos años, scrapear una web sin código solía significar usar una plantilla ya preparada para un sitio popular. Eso cambió desde que la IA se volvió accesible para todo el mundo.
Ahora significa exactamente eso: apuntar una herramienta a casi cualquier página pública y recibir datos limpios y estructurados, sin escribir scripts.
Por qué antes hacer web scraping exigía código
Los scrapers clásicos son scripts mapeados al HTML de un único sitio. Apuntan a selectores específicos, nombres de clase y patrones de paginación que existen en esa página concreta.
Eso funciona... hasta que cambia el objetivo. Si apunta el mismo script a otra web y nada coincide, devuelve filas vacías o muestra un error.
Qué hace diferente un web scraper no-code
Un web scraper no-code elimina el script por completo. En vez de escribir código, usted configura lo que quiere mediante una interfaz visual o instrucciones escritas.
Esta es la categoría que la mayoría ya conoce, aunque las herramientas dentro de ella están lejos de ser iguales. Por eso aquí las vamos a dividir en dos subcategorías:
- Herramientas de point-and-click y plantillas: usted selecciona campos en una página o carga una plantilla ya preparada para un sitio popular.
- AI scraping agents: usted describe los datos en lenguaje natural y el agente decide cómo extraerlos.
Ambas eliminan el código, pero solo una elimina la dependencia de que el sitio sea popular o predecible.
Por qué ahora puede scrapear cualquier sitio web sin código
El cambio viene de la forma en que la IA interpreta una página. Un AI scraping agent analiza el contenido de la página junto con su prompt y decide qué extraer.
Este enfoque de AI scraping elimina la dependencia de selectores fijos. Por eso resulta tan potente: no hay una regla rígida que se rompa cuando cambia el diseño, porque el agente vuelve a leer la página en cada ejecución.
AI scraping vs métodos antiguos para scrapear sitios web sin código
No-code no es una sola cosa, y las diferencias entre métodos se notan en cuanto el sitio es de nicho o una página popular cambia su diseño.
Scrapers basados en código: potentes, pero atados a un solo sitio
Escribir su propio scraper en Python o JavaScript le da control total. Usted decide cada selector, cada regla de paginación, cada reintento y cada timeout.
Pero cada script se construye para un solo sitio, necesita un desarrollador que lo cree y se rompe cada vez que esa web cambia su estructura. Sí, ejecutar scrapers con código puede salir barato, pero arrastran otro coste: un script por sitio, un desarrollador disponible y mantenimiento cada vez que el objetivo actualiza sus páginas.
Para un equipo que scrapea muchas webs distintas, ese coste crece muy rápido. Cinco objetivos pueden significar cinco scripts y cinco cosas distintas que arreglar cada semana.
Scrapers de point-and-click y plantillas: fáciles hasta que el sitio es de nicho
Las herramientas de plantillas y point-and-click fueron los primeros scrapers no-code realmente útiles. Funcionan bien en sitios populares porque alguien ya creó la plantilla o porque la página es lo bastante simple como para seleccionarla manualmente.
Los problemas reales aparecen cuando quiere scrapear páginas menos conocidas, como directorios de nicho, tiendas regionales o diseños poco habituales, que a menudo no tienen una plantilla ya preparada.
Y, al igual que los scrapers con código, siguen dependiendo de que la página se mantenga igual. Cuando el sitio cambia su estructura, las selecciones guardadas dejan de funcionar, los datos dejan de fluir y toca ponerse a corregir.
AI scraping: un solo prompt que se adapta a cualquier sitio web
El AI scraping resuelve dos problemas:
- Configuración interminable
- Scrapers que dejan de funcionar cuando la web objetivo cambia su estructura
Usted solo tiene que describir los datos que quiere, indicar la URL al agente y este devuelve filas estructuradas.
Como el agente interpreta cada página en el momento en que la scrapea, el mismo prompt puede ejecutarse en distintos sitios. Una página de producto, un directorio o una página de listados: el flujo de trabajo no cambia.
Aquí es donde encaja el AI Scraping Agent de Datablist. Toma una URL objetivo y un prompt en lenguaje natural para que usted pueda scrapear cualquier sitio web sin código y hacerlo en minutos, no en horas. Además, facilita mucho el data cleaning, porque los datos scrapeados llegan a una hoja donde puede deduplicar y enriquecer al instante.
Comparamos los métodos no-code de scraping según las métricas más importantes 👈🏽
Qué buscar en una herramienta para scrapear cualquier sitio web sin código
Una vez que entiende por qué un AI Scraper es mejor que un scraper por sitio, la pregunta pasa a ser en qué herramienta confiar. Para mí, todo se reduce a tres factores: cobertura, frecuencia con la que falla y facilidad de uso.
Cobertura: ¿puede manejar sitios de nicho y long-tail?
La cobertura es la primera prueba. Muchas herramientas de scraping afirman que pueden scrapear cualquier sitio web, pero en realidad dependen de una biblioteca de plantillas preconfiguradas para sitios populares.
La pregunta más importante es esta: ¿puede la herramienta scrapear un sitio que nunca ha visto?
Los agentes guiados por prompt superan esta prueba porque no dependen de plantillas. Si entre sus objetivos hay directorios de nicho o sitios regionales, este es el criterio que más importa.
Una forma rápida de comprobarlo: pruebe la herramienta en el sitio más raro de su lista y vea si puede scrapearlo.
Mantenimiento: ¿se rompe cada vez que un sitio cambia?
El mantenimiento de scrapers suele ser la variable de coste de la que nadie habla. Los selectores, las reglas de paginación y los proxies dejan de funcionar cuando el sitio objetivo cambia su diseño, y alguien tiene que arreglarlo.
Una herramienta atada a reglas fijas le pasa ese trabajo a usted. Cada cambio de diseño se convierte en una pequeña reparación, y esas reparaciones nunca terminan del todo.
Un scraping agent guiado por prompt evita la mayor parte de esto porque vuelve a interpretar la página en cada ejecución, en lugar de confiar en los selectores de ayer. El prompt sigue siendo el mismo aunque la página cambie.
Facilidad de uso: cómo debería sentirse un web scraper no-code
La última prueba es muy simple: ¿de verdad puede usarlo sin depender de un desarrollador?
Una herramienta universal no ayuda a nadie en un equipo de recruiting, operaciones o marketing si hace falta un ingeniero para manejarla.
Júzguelo desde su propia posición. ¿Puede escribir un prompt sencillo, mapear algunos campos y exportar el resultado por su cuenta?
Eso es exactamente para lo que está pensado el AI Scraping Agent de Datablist: escribir un prompt, configurar los campos y exportar los datos. Sin código, sin desarrollador y sin configuración específica por sitio.
Si no tiene claro qué herramienta encaja mejor con su lista de objetivos, comparamos las mejores herramientas de scraping no-code cara a cara 👈🏽
Guía paso a paso para scrapear cualquier sitio web
Pasemos ahora a la parte práctica. Todo lo que sigue se hace dentro de Datablist, la plataforma de automatización de workflows creada para AI scraping y data enrichment.
Usted le da una URL objetivo y un prompt sencillo, y Datablist devuelve datos estructurados de casi cualquier sitio sin código, en minutos en lugar de horas. Sin desarrollador y sin configuración por sitio.
Para llevarlo a la práctica, en este tutorial haremos dos cosas:
- Configurar el scraping y ejecutarlo
- Definir una propiedad única para que las ejecuciones repetidas no importen la misma fila dos veces
Cómo scrapear cualquier sitio web con el AI Scraping Agent de Datablist
Para demostrar esta capacidad en un caso real, vamos a ejecutar el AI Scraping Agent sobre una página de categoría de GymShark, pero todos los pasos funcionan igual en cualquier sitio web al que lo apunte.
Antes de empezar, asegúrese de tener esto preparado:
- Una cuenta de Datablist
- La URL de la página que quiere scrapear
- Una lista clara de los campos que quiere extraer
- Ejemplos para cualquier campo que pueda prestarse a confusión
- Un límite aproximado de páginas para la ejecución
Paso 1: regístrese y cree una Collection
Primero, regístrese en Datablist.com.
Después, cree una New Collection para guardar los datos que está a punto de scrapear.
Paso 2: abra AI Agent - Site Scraper
Dentro de su nueva collection, haga clic en See all sources.
Desplácese hacia abajo y seleccione AI Agent - Site Scraper
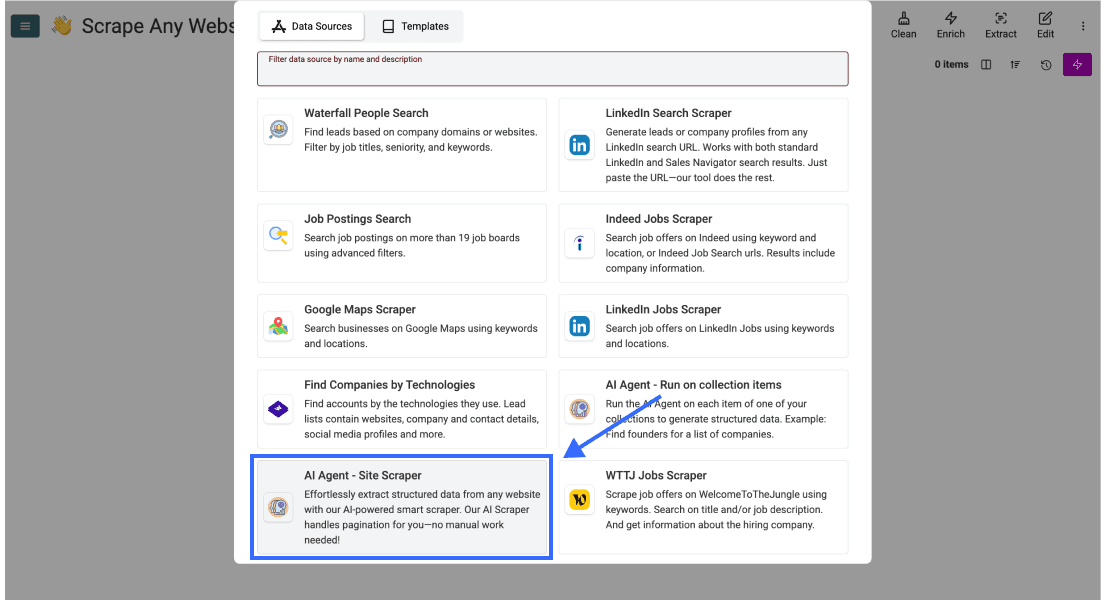
Paso 3: escriba su prompt y configure la tarea
Pegue la URL objetivo en el primer campo. En este ejemplo usaremos una página de categoría de GymShark, pero usted puede scrapear el sitio que quiera.
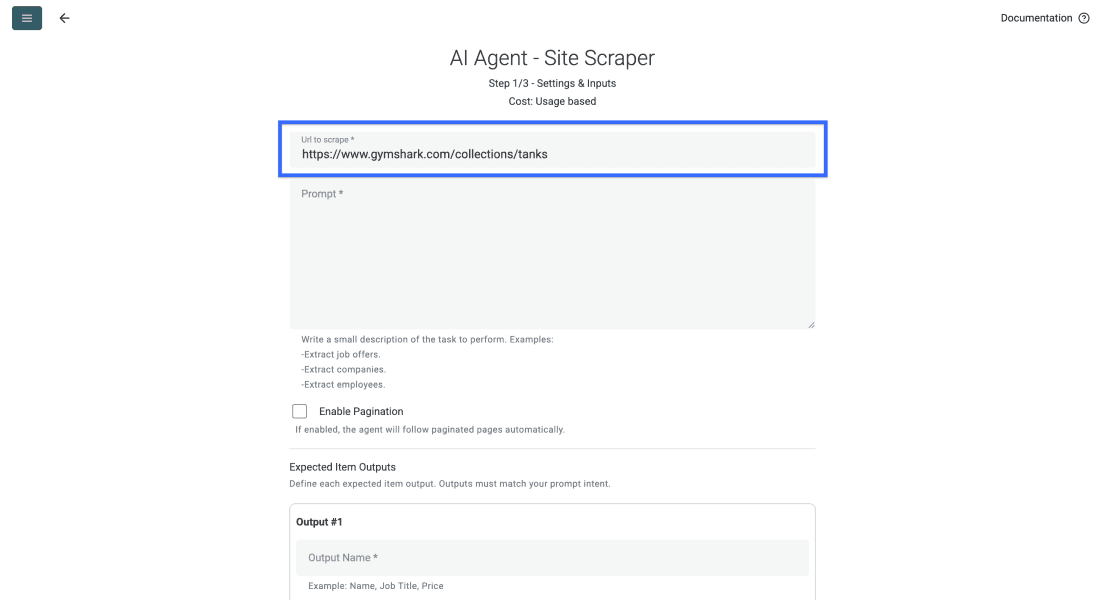
Después, baje hasta el campo del prompt y describa qué debe extraer el agente de cada página. También puede ver un prompt de ejemplo más abajo.
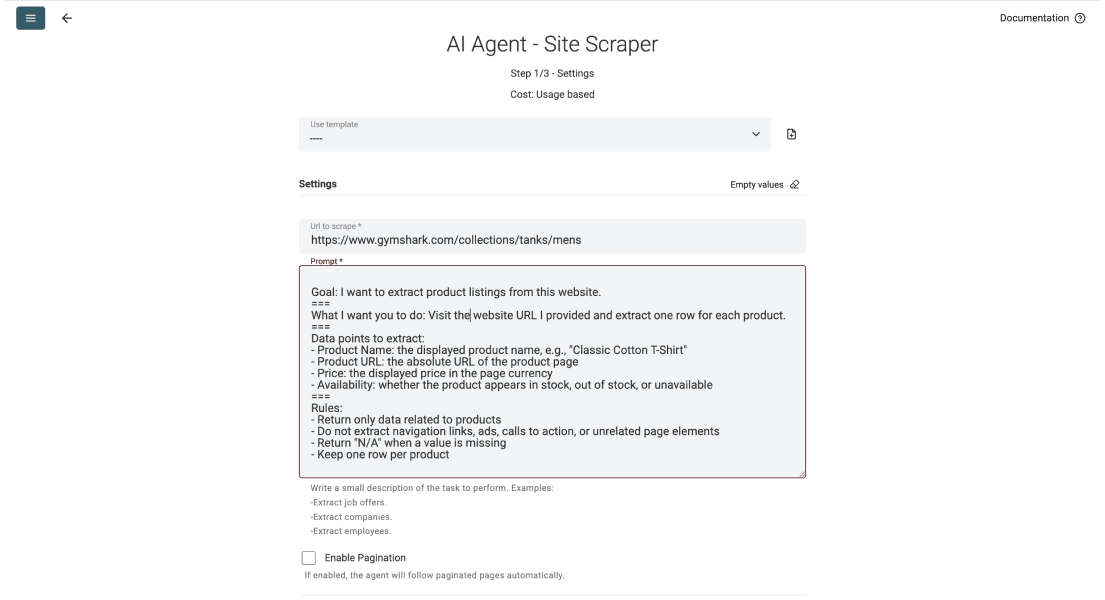
Un buen prompt le dice al agente qué debe extraer, qué debe ignorar y cómo debe verse cada fila. Puede copiar la estructura siguiente y sustituirla por sus propios campos.
Goal: I want to extract product listings from this website.
.===
What I want you to do: Visit the URL I provide and return one row per product.
.===
Data points to extract:
- Product Name (example: "Classic Cotton T-Shirt")
- Product URL: the absolute link to the product page
- Price: the displayed price in the page currency
- Availability: in stock, out of stock, or unavailable
.===
Mistakes to avoid:
- Return only product data; ignore navigation, ads, and call to actions
- Return "N/A" when a value is missing
- Keep one row per product
El agente sigue mucho mejor las instrucciones cuando el prompt nombra cada campo y añade un ejemplo. Los prompts vagos son la principal razón por la que una ejecución devuelve resultados desordenados.
Siga estas reglas para escribir prompts para AI agents y obtendrá resultados más limpios 👈🏽
Defina cuántas páginas quiere que recorra el agente una vez haya terminado de escribir el prompt.
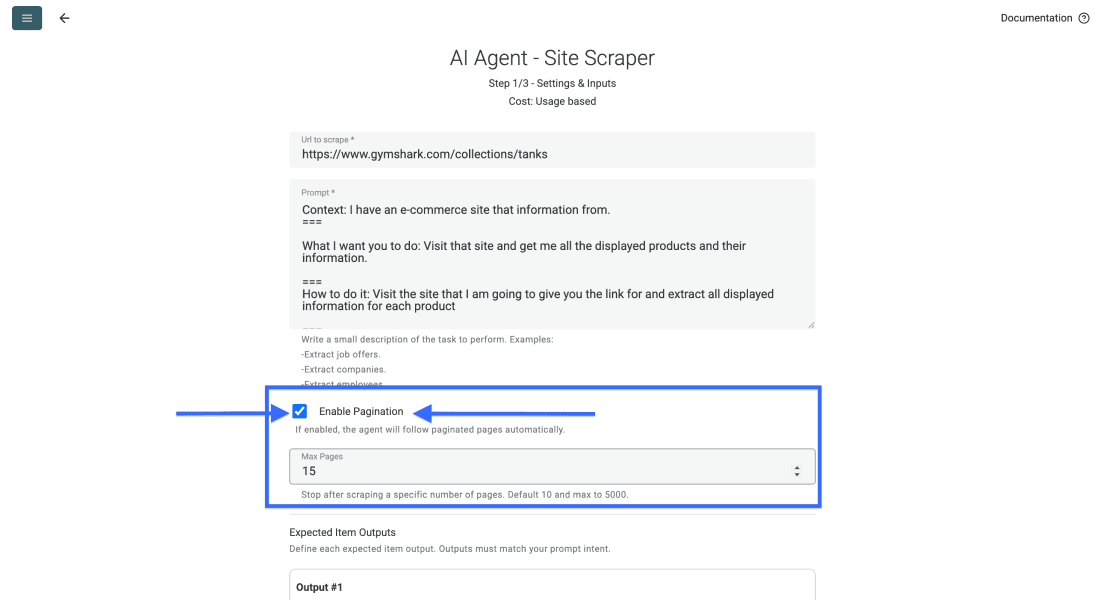
📘 Sobre la paginación en páginas de listados
La mayoría de las páginas de listados reparten los resultados en varias páginas. Ajuste el límite según cuánto contenido quiera extraer del sitio. Datablist permite hasta 5.000 páginas por ejecución.
Una vez configurados el prompt y el límite de páginas, desplácese hacia abajo para definir los campos de salida.
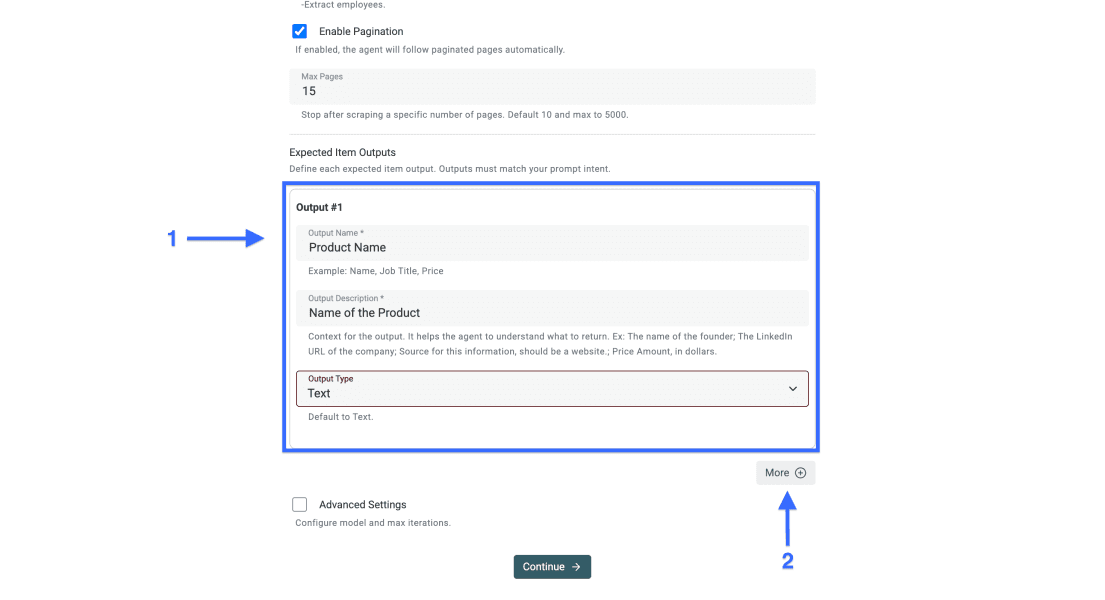
Paso 4: defina los campos de salida
Si usted mismo redacta el prompt, los campos de salida deberían reflejar los datos que pidió. Una columna por campo mantiene los datos limpios.
Para cada output:
- Defina el nombre del dato como Output Name
- Añada una Output Description clara, con un ejemplo si hace falta
- Elija el Output Type correcto, como texto, número, URL o email
- Haga clic en More para añadir campos de salida adicionales
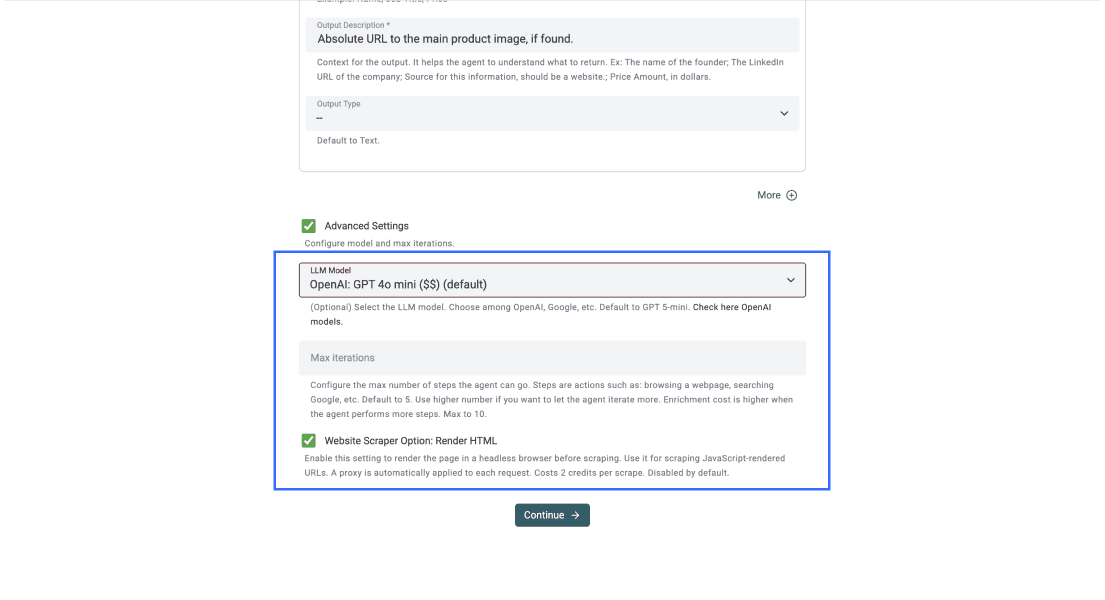
Paso 5: configure los ajustes avanzados
Con los outputs ya definidos, marque la casilla junto a Advanced Settings y aplique lo siguiente:
- LLM: OpenAI GPT-4o mini, por su mejor equilibrio entre rendimiento y precio
- Max iterations: 10
- Render HTML: activado, algo clave para sitios que cargan contenido con JavaScript
Una vez hecho esto, su panel de Advanced Settings debería verse así.
Paso 6: ejecute el scraping
Cuando ya tenga listos el prompt, los outputs y la configuración, haga clic en Continue
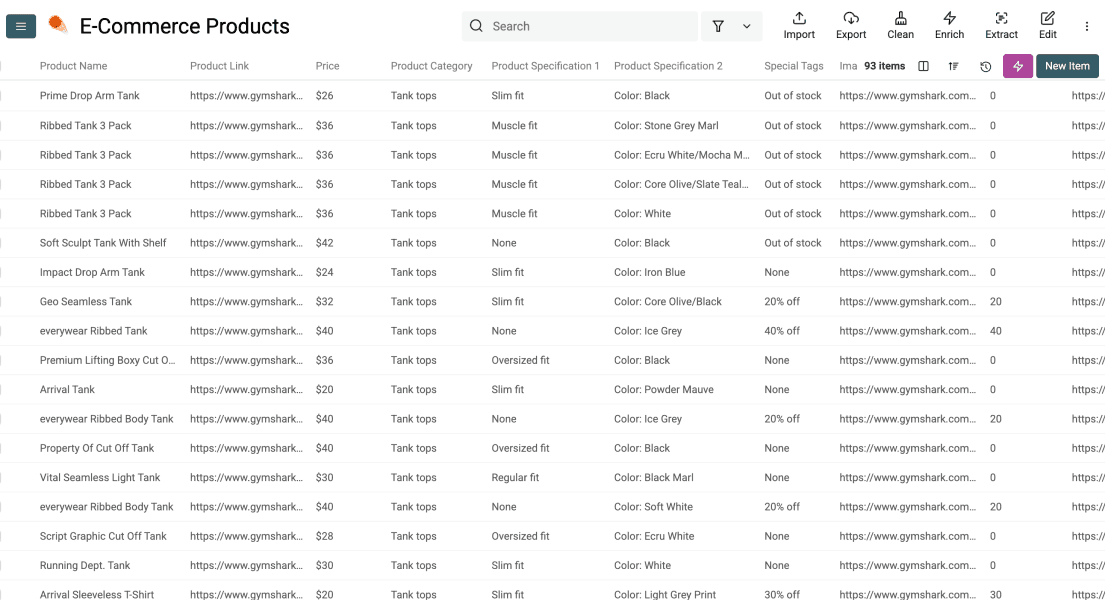
Datablist creará una propiedad para cada output que haya configurado. En ese momento podrá revisar que no se le haya olvidado nada y hacer clic en Run Import Now cuando esté listo para empezar a scrapear.

Tras unos minutos, las filas aparecerán en su collection, listas para limpiar, enriquecer, deduplicar o exportar.
Si va a repetir este scraping más adelante, siga la sección siguiente para definir antes una columna única y así no importar la misma fila dos veces.
Cómo evitar duplicados en scraping recurrente
Ahora le voy a mostrar cómo evitar duplicados en Datablist configurando un identificador único antes de repetir una tarea de scraping.
Paso 1: elija un identificador único
Primero, elija la columna que Datablist debe usar para detectar duplicados.
Por ejemplo, si está scrapeando productos, use un valor estable como Product URL o Item URL. Si trabaja con empresas, use Company Domain o Business Name.
💡 Elija un identificador estable
Escoja un valor que pertenezca solo a una fila. Las URL de producto, las URL de ítem, los dominios de empresa y las direcciones de email suelen funcionar mejor que los nombres, porque los nombres pueden repetirse.
Paso 2: abra la configuración de la columna
Haga clic en el encabezado de la columna de su identificador único.
Después, seleccione Rename - Settings - Delete.

Paso 3: bloquee los valores duplicados
Ahora marque la casilla Do not allow duplicate values.
Después, haga clic en Save Property.

Paso 4: compruebe el icono de llave
Una vez guardada la columna, Datablist mostrará un icono de llave junto al nombre de la columna.
Ese icono confirma que la columna ya es un identificador único.
A partir de ese momento, cuando ejecute de nuevo el mismo scraping, source o import, Datablist solo añadirá filas con nuevos valores únicos. Así mantendrá su collection limpia cuando repita el proceso más adelante.
En resumen: deje de configurar scrapers y empiece a usar prompts
El gran cambio aquí no es una sola herramienta. Es que una página más un prompt en lenguaje natural ha sustituido al antiguo modelo de un script por sitio, que hacía que el web scraping fuera tan frágil. Por eso el mismo workflow puede scrapear cualquier sitio web, ya sea un directorio, un marketplace o una tienda de nicho.
Preguntas frecuentes sobre cómo scrapear cualquier sitio web sin código
¿El AI Scraping Agent de Datablist puede scrapear cualquier sitio web?
Funciona en casi cualquier sitio web público. Como interpreta cada página a partir de un prompt en lugar de una plantilla fija, se adapta a sitios que nunca ha visto.
¿Datablist ofrece una prueba gratis para su web scraper no-code?
Sí. Puede empezar gratis, crear una collection y probar el AI Scraping Agent sin coste.
¿Necesito escribir código para usar el AI Scraping Agent de Datablist?
No. Usted describe lo que quiere en lenguaje natural, define algunos output fields y lo ejecuta. No hay scripts que escribir ni nada que rehacer cuando un sitio cambia su diseño. Esa es precisamente una de las razones por las que Datablist le permite scrapear cualquier sitio web sin código.
¿Qué tipo de datos puede extraer el AI Scraping Agent de un sitio web?
Todo lo que la página muestre y usted pida: nombres de producto, precios, URL, disponibilidad, datos de contacto, listados y más. Usted define los campos en el prompt y en los outputs. Nota: el AI Scraper de Datablist no puede extraer información del backend, como stock disponible, si no aparece en el sitio web público.
¿Cuánto cuesta scrapear sitios web con Datablist?
El scraping funciona con créditos basados en uso, así que usted paga por lo que procesa. La forma más barata de confirmar que todo funciona es hacer primero una prueba pequeña antes de lanzar un scraping completo.
¿Puedo exportar los datos scrapeados a CSV o Excel?
Sí. Una vez que las filas llegan a su collection, puede limpiarlas, deduplicarlas, enriquecerlas y exportarlas, incluyendo CSV y Excel, directamente desde Datablist.
¿Qué significa scrapear un sitio web sin código?
Significa extraer datos estructurados de una página sin escribir ni mantener un script. En lugar de programar selectores, usted configura una herramienta o describe los datos que quiere extraer mediante prompting en lenguaje natural.
¿De verdad se puede scrapear cualquier sitio web sin código?
Se puede scrapear casi cualquier sitio público sin código si usa un AI Scraping Agent, porque estos agentes se adaptan a distintos diseños a partir de un único prompt. Aun así, los logins y las protecciones anti-bot más agresivas pueden seguir generando fricción en algunos sitios.
¿Cuál es la diferencia entre AI scraping y web scraping tradicional?
El scraping tradicional ejecuta un script codificado para la estructura de un solo sitio. El AI scraping interpreta la página con un prompt en cada ejecución, de modo que la misma configuración se adapta a muchos sitios diferentes.
¿Por qué los scrapers dejan de funcionar cuando un sitio cambia su diseño?
Porque un scraper apunta a selectores y patrones de página concretos. Cuando el sitio cambia esos elementos, el script deja de encontrar los datos y devuelve resultados vacíos o errores hasta que alguien lo reescribe.
¿Qué es un web scraper no-code y cómo funciona?
Un web scraper no-code extrae datos sin programar. Las herramientas de point-and-click permiten seleccionar campos visualmente, mientras que los AI scraping agents funcionan a partir de un prompt en lenguaje natural y extraen los datos por usted.
¿Cuánto tarda scrapear un sitio web sin código?
Depende de la herramienta que use, pero si tomamos Datablist.com como ejemplo, no debería llevarle más de unos minutos: registrarse, escribir un prompt, mapear los campos y ejecutar. El scraping en sí suele completarse también en 5 a 10 minutos, según cuántas páginas procese.