

¿Tiene una lista llena de duplicados? Ya sea en contactos de clientes, suscriptores de email o inventario de productos, los registros repetidos deben eliminarse o le harán perder tiempo y dinero. Imagine enviar el mismo email dos veces a un cliente: además de molesto, puede dañar la reputación de su marca.
¿La buena noticia? Puede deduplicar su lista online gratis con Datablist. Es una herramienta online simple y potente que le ayuda a eliminar duplicados y limpiar sus datos en minutos. Sin código y sin dolores de cabeza.
En esta guía, le mostramos cómo deduplicar una lista en tres pasos sencillos:
Parte 1: Importe su lista con duplicados
El primer paso para deduplicar su lista online con Datablist es muy simple: cargar sus datos en la plataforma.
Datablist funciona con varios formatos (CSV, Excel) y también puede cargar datos desde fuentes externas como Pipedrive.
Paso 1: Cree una nueva Collection
Piense en una collection en Datablist como una hoja de cálculo. Para empezar, cree una collection nueva para la lista que desea deduplicar.
Haga clic en el botón "+" de la barra lateral para crear una nueva collection.
En su nueva collection, haga clic en el enlace "Import CSV/Excel". O haga clic en "Sources" para integraciones más avanzadas.
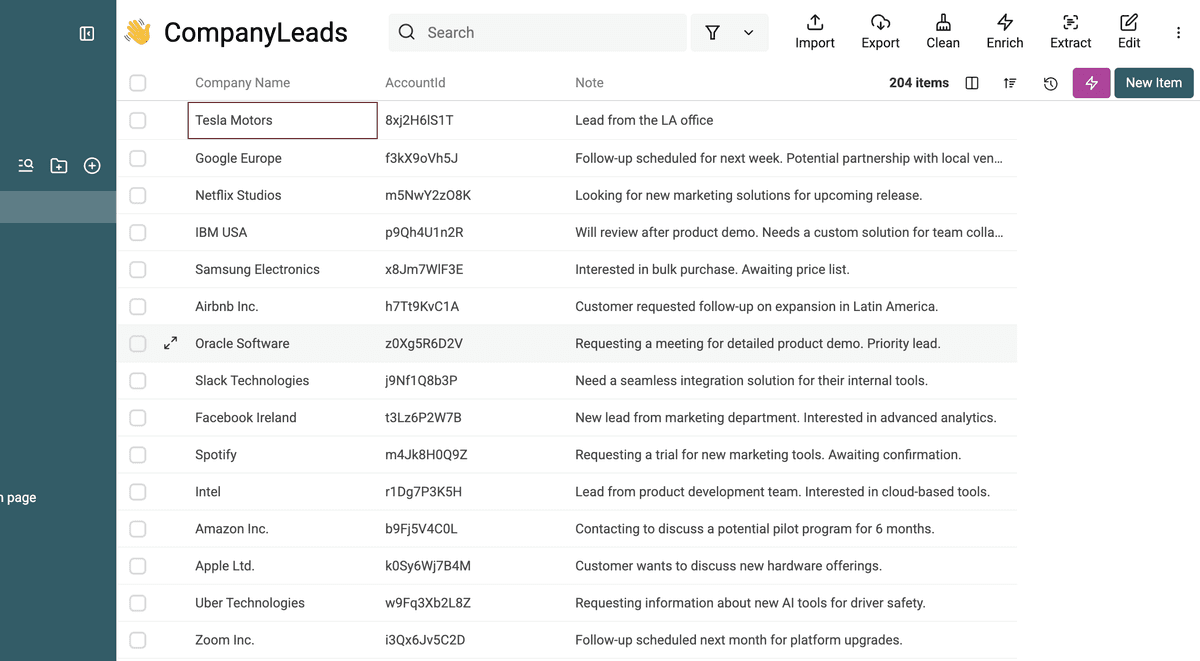
Una vez cargado, Datablist le mostrará una vista previa de sus datos, con columnas (llamadas propiedades) y algunas filas. Revísela rápidamente para asegurarse de que todo se vea correcto.
Parte 2: Encontrar duplicados en la lista
Su lista está lista. Ahora, vamos a cazar esos duplicados.
Datablist utiliza algoritmos avanzados para detectar registros que probablemente sean duplicados, incluso si no son exactamente iguales.
Paso 1: Abra el Duplicates Finder
Para iniciar la búsqueda de duplicados, vaya al menú "Clean" en su collection de Datablist y haga clic en "Duplicates Finder".
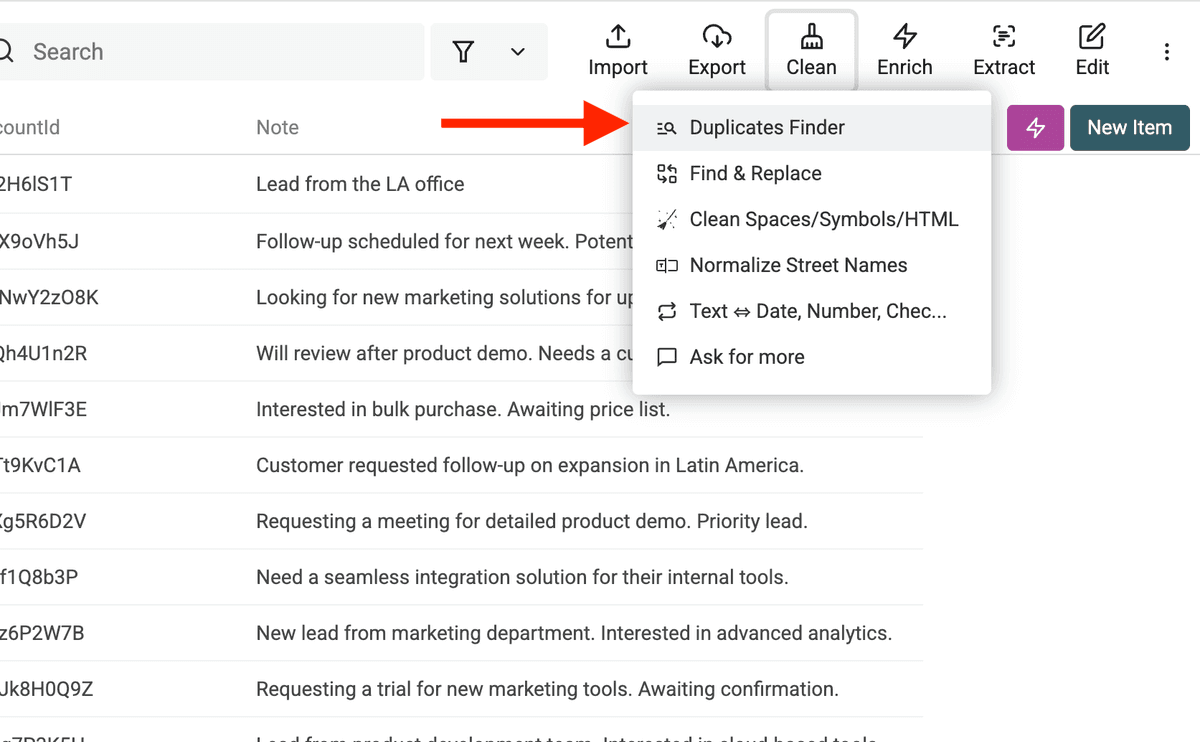
Se abrirá el Duplicates Finder, donde puede indicar a Datablist cómo buscar duplicados en su lista.
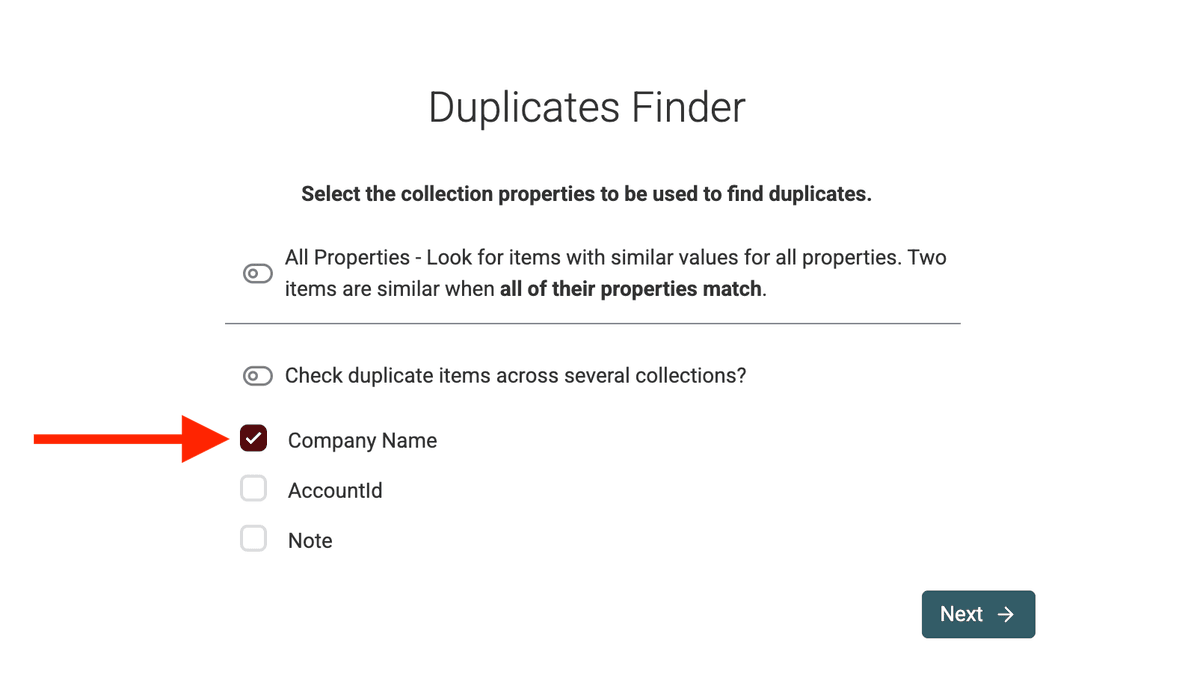
Paso 2: Elija qué comparar: propiedades de deduplicación
Una "propiedad de deduplicación" es, básicamente, la columna (o campo) de su lista que Datablist usará para comparar registros y ver si son duplicados.
Elija la adecuada según el tipo de lista:
Por ejemplo:
- Listas de contactos: En una lista de personas, el email suele ser el atributo más fiable, ya que la mayoría de personas tiene un email único. Si no tiene email para todos, también puede usar el nombre o nombre y apellido juntos.
- Listas de productos: En una lista de productos, puede usar el nombre del producto o un ID único (EAN, GTIN, SKU).
- Listas de empresas: En una lista de empresas, el company name o su URL del sitio web son buenas opciones.
En Duplicates Finder, se le pedirá seleccionar una o varias propiedades para hacer el matching.
Paso 3: Seleccione algoritmo de coincidencia y procesador
Datablist le ofrece varias formas de comparar sus datos, según el nivel de rigor que necesite:
- Exact: Solo encuentra registros donde la propiedad elegida es exactamente igual. Ideal para detectar entradas idénticas.
- Smart: Un poco más flexible. Puede detectar, por ejemplo, URLs iguales con inicios distintos (http vs. https) o textos con pequeñas diferencias de puntuación.
- Phonetic (Double Metaphone): ¡Muy útil! Hace matching por cómo suenan las palabras, no solo por su ortografía. Perfecto para nombres con variaciones de escritura que suenan igual.
- Fuzzy Matching (Jaro-Winkler & Levenshtein): Calcula la similitud entre dos textos. Puede definir un nivel de similitud para marcar como duplicados aunque haya typos, abreviaturas o ligeras diferencias.
Nota: El algoritmo Exact está disponible para usuarios anónimos. El algoritmo Smart requiere una cuenta free. Y los algoritmos Metaphone y Fuzzy Matching solo están disponibles en los paid plans.
Elija el algoritmo que más sentido tenga para cada una de sus propiedades de deduplicación.
También necesita definir el processor adecuado para normalizar sus datos antes de la deduplicación. Así, valores similares coinciden aunque tengan pequeñas variaciones.
Processors frecuentes en Datablist:
- URLs - Elimina protocolos (http, https), parámetros de consulta y códigos de tracking para hacer coincidir enlaces equivalentes.
- Ejemplo: https://example.com?utm_source=newsletter → example.com
- Emails - Ignora alias como +filter en direcciones de Gmail, para que las variaciones coincidan.
- Ejemplo: john+work@gmail.com → john@gmail.com
- Company Names - Quita sufijos legales (Inc., LLC), términos de negocio (Partners, Group) y términos geográficos (Europe, USA).
- Ejemplo: Acme Inc. → Acme
Nota: El processor Company Names solo está disponible en los paid plans.
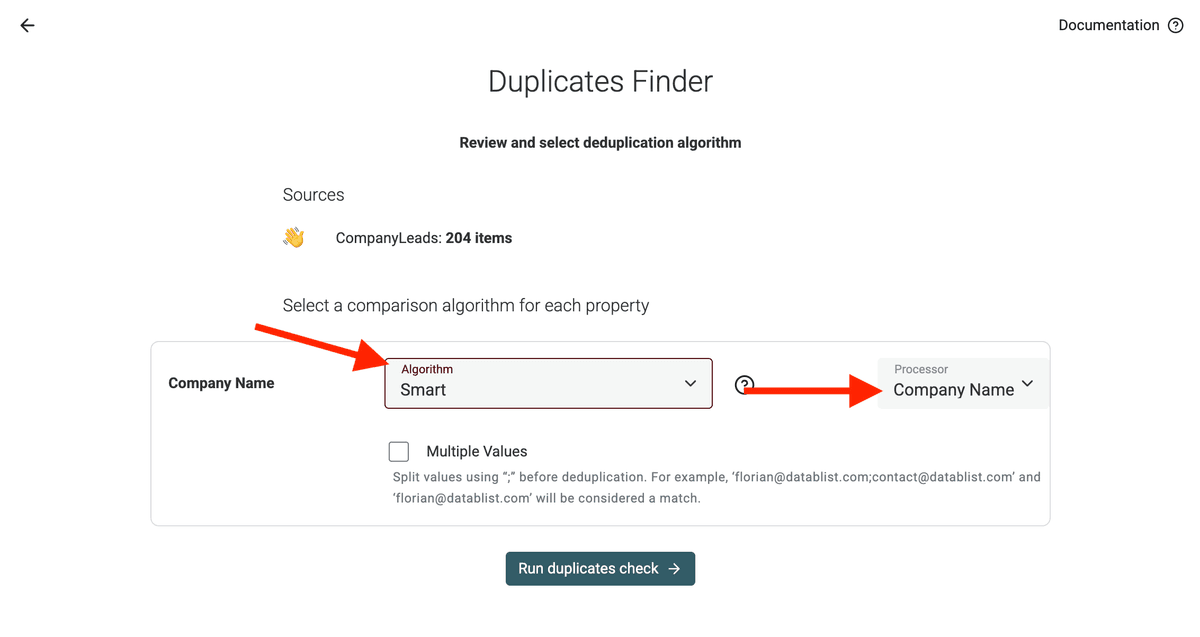
Deduplicar campos con varios valores - Si su propiedad de deduplicación contiene varios valores, active la opción "Multiple Values".
Importante: Dedupique en varias pasadas
Para la mayoría de listas, se recomienda empezar con el matching "Smart" y después hacer otra pasada con "Fuzzy Matching" sobre la misma propiedad o una diferente (por ejemplo, nombre si primero usó email).
Los duplicados encontrados con el algoritmo "Smart" suelen ser duplicados reales. Puede fusionarlos sin validaciones muy extensas.
Pero con los algoritmos de distancia pueden aparecer "falsos positivos". Dos nombres con una letra distinta pueden o no pueden ser la misma entidad. Sea especialmente cuidadoso al revisar esos grupos de duplicados (ver más adelante).
✅ Consejo experto: Empiece con Smart Matching y luego refine con Distance (Fuzzy) Matching.
Paso 4: Ejecute la verificación de duplicados
Cuando haya elegido sus propiedades y algoritmos de matching, haga clic en el botón "Run duplicates check" para iniciar el proceso.
Datablist analiza su lista y agrupa los registros que considera potenciales duplicados según sus criterios.
Paso 5: Revise los grupos de duplicados detectados
Tras el análisis, Datablist le mostrará una lista de "Duplicate Groups".
Cada grupo contiene dos o más registros que se consideran duplicados.
En cada grupo puede ver por qué coinciden y si tienen valores en conflicto.
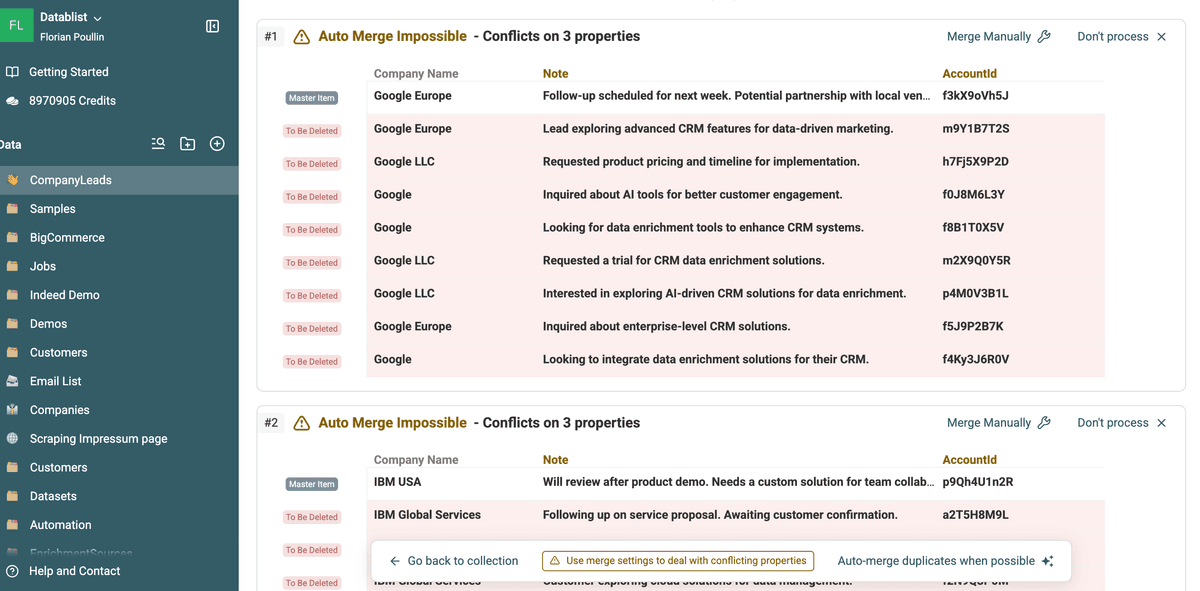
Este paso es importante para verificar que el matching sea correcto y evitar agrupar registros válidos por error.
Nota: Si solo necesita la lista de duplicados, puede descargar un archivo CSV/Excel con los grupos de duplicados. Cada grupo tiene un identificador único. También obtiene el número de duplicados en su archivo si solo requiere estadísticas.
Parte 3: Resolver y fusionar duplicados
Perfecto, ¡ya encontró los duplicados! Ahora toca deduplicar su lista fusionándolos.
Esto implica decidir qué hacer con la información en conflicto y luego fusionar los registros duplicados en una única entrada limpia.
Paso 1: Comprender los grupos y conflictos
Al ver un grupo de duplicados, puede notar que cierta información difiere ligeramente entre registros. A esto lo llamamos "valores en conflicto".
Por ejemplo, dos registros duplicados de un contacto pueden tener el mismo email pero diferentes teléfonos o cargos.
Paso 2: Definir reglas de fusión para valores en conflicto
Datablist le permite decidir cómo manejar estos valores en conflicto al fusionar duplicados. Puede definir reglas para indicar qué valor conservar o cómo combinarlos.
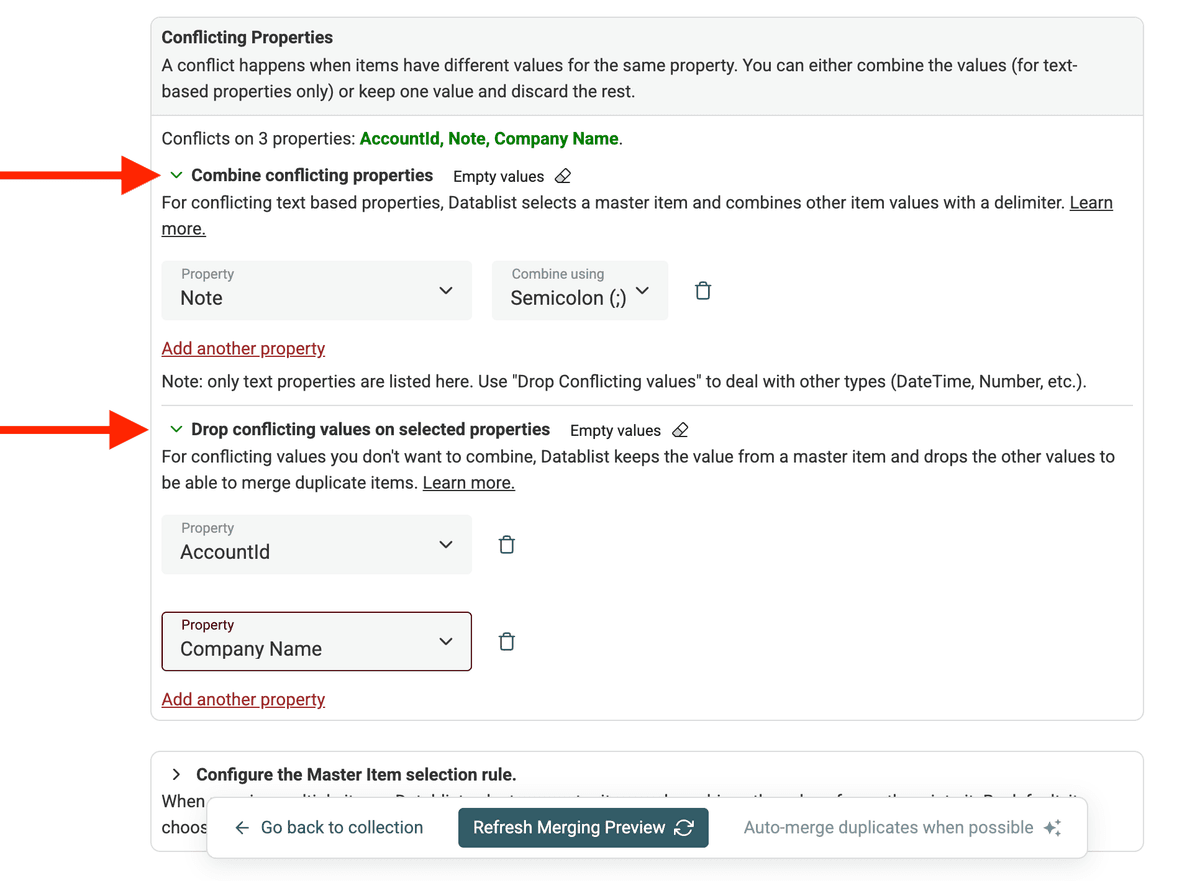
Tiene dos opciones para tratar los conflictos:
- Combine Conflicting Values: Si los valores son complementarios (p. ej., varios teléfonos, notas), combínelos.
- Drop Conflicting Values: Si solo necesita el valor de un registro y desea descartar el otro, seleccione "Drop conflicting values...".
Para las opciones Combine conflicting values y Drop conflicting values, dispone de un acceso directo para seleccionar automáticamente todas las propiedades en conflicto.
Ejemplo de combinación de múltiples valores:
Supongamos que tiene dos entradas duplicadas de un contacto:
Registro 1: Email: john.doe@example.com, Tel.: 555-1234
Registro 2: Email: john.doe@example.com, Tel.: 555-5678
Si define la regla de fusión para la propiedad "Phone" como "Combine values", el registro resultante quedará así:
Registro fusionado: Email: john.doe@example.com, Tel.: 555-1234;555-5678
Paso 3: Configure la regla de Master Item
Al fusionar duplicados, Datablist elige un registro como principal y la información de los demás se combina en él.
Puede controlar cómo selecciona Datablist ese Master Record eligiendo entre varias reglas:
- Most Complete: Elige el registro con más campos completos.
- Last Updated: Elige el registro modificado más recientemente.
- First Created: Elige el registro más antiguo según la fecha de creación.
- Highest Value: Elige el registro con el valor más alto en una propiedad seleccionada. Si varios registros tienen el mismo valor, selecciona el más reciente.
- Lowest Value: Elige el registro con el valor más bajo en una propiedad seleccionada. Si varios registros tienen el mismo valor, selecciona el más reciente.
- Matching Value: Elige el registro que contiene un valor específico en una propiedad seleccionada. Si ningún registro coincide, no se fusionarán.
Paso 4: Fusión automática de duplicados (cuando sea posible)
Cada vez que cambie sus ajustes de fusión, haga clic en "Refresh Preview" para ver cómo se aplicarán los cambios.
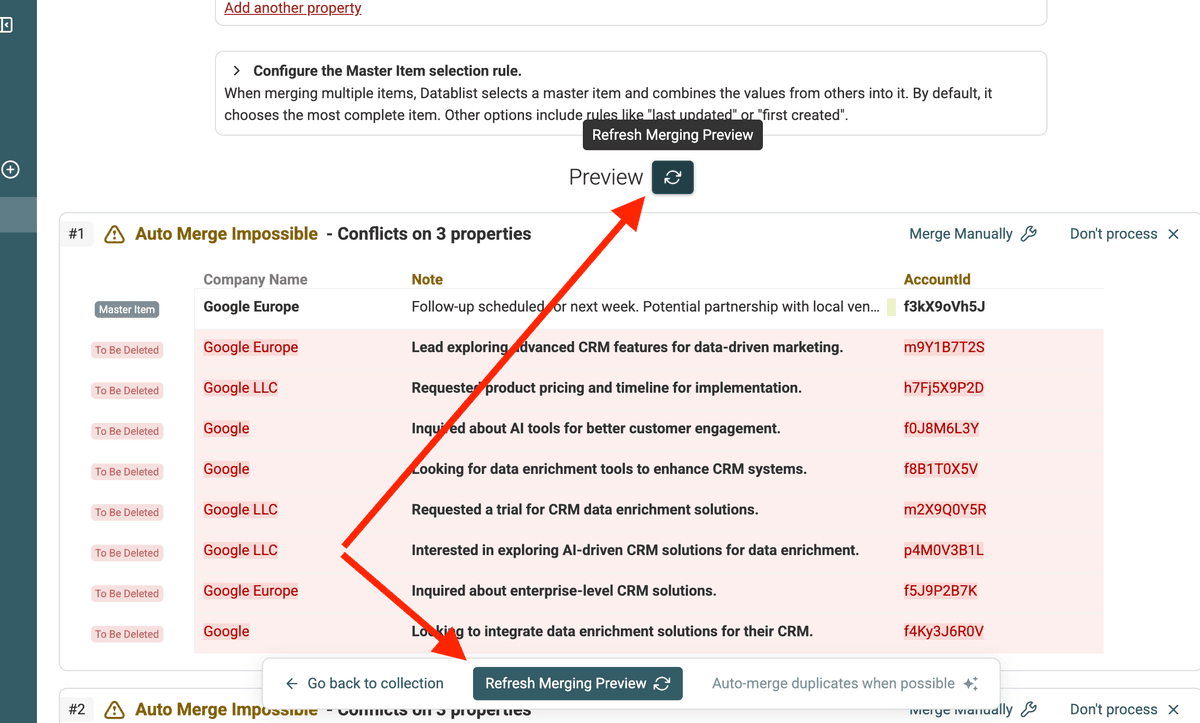
Una vez que haya configurado sus reglas, Datablist podrá fusionar automáticamente los grupos de duplicados cuando ya no existan valores en conflicto.

Busque la opción "Auto-merge when possible" para fusionarlos.
Paso 5: Fusione manualmente los duplicados restantes
Para los grupos con valores en conflicto que necesiten su revisión, tendrá que fusionarlos manualmente.
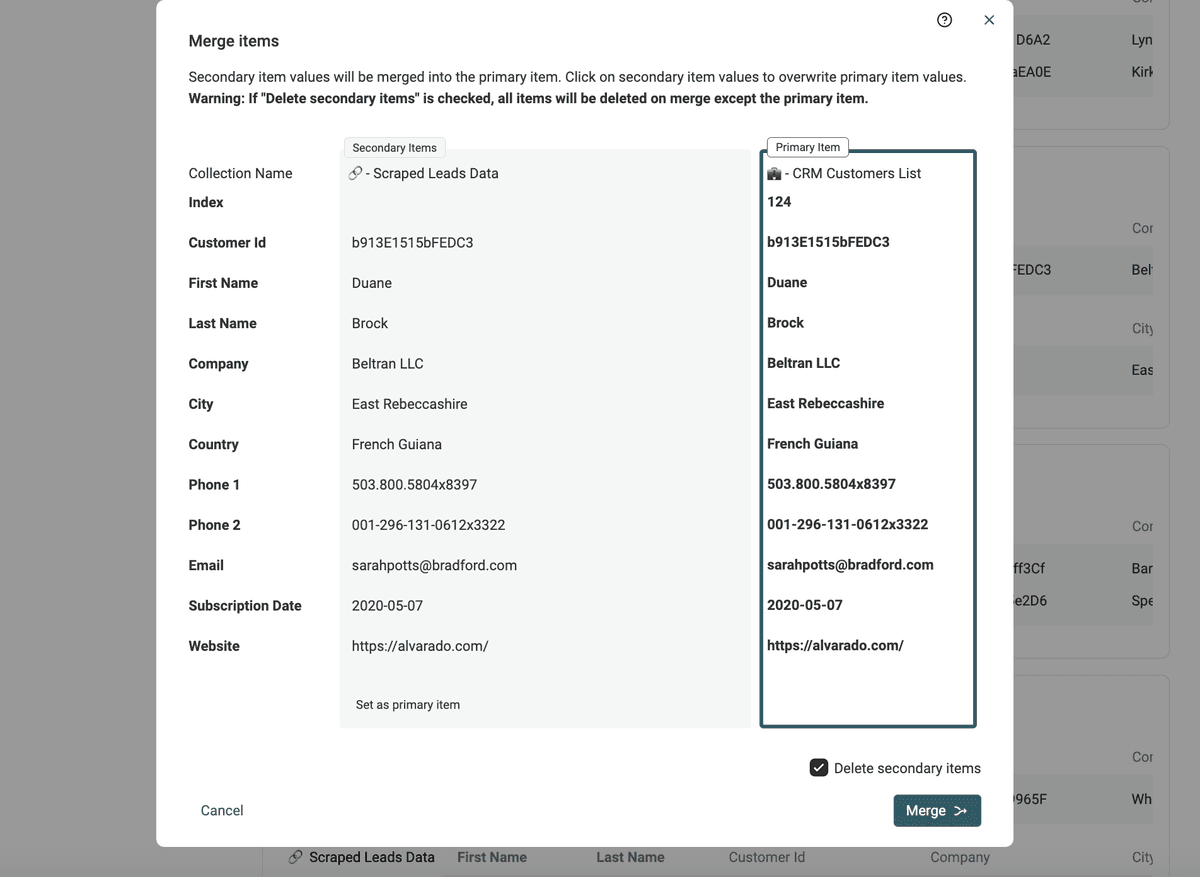
Datablist ofrece un "Manual Merging Assistant" que le muestra los valores en conflicto lado a lado para que elija cuáles conservar en el registro final.
Para usar el Manual Merging Assistant, haga clic en el botón del grupo de duplicados correspondiente.
Verá los datos de todos los registros del grupo y podrá seleccionar los valores a conservar antes de pulsar "Merge".
Paso 6: ¡Listo! Revise y finalice
Cuando haya fusionado todos los grupos de duplicados, tómese un momento para revisar su lista ya limpia.
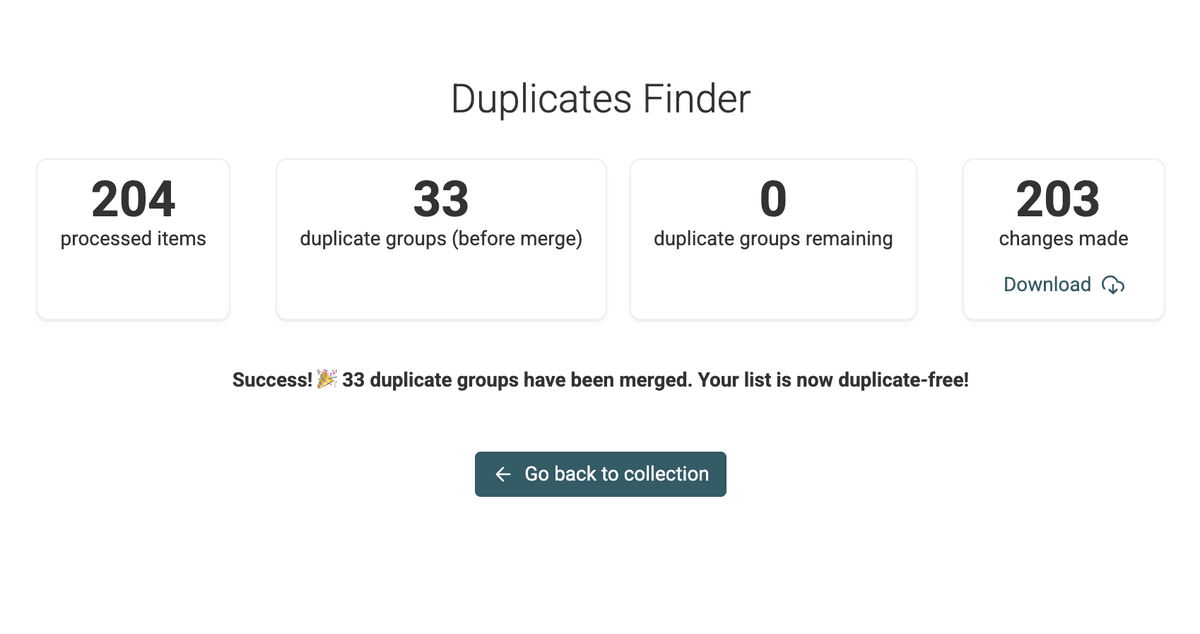
Asegúrese de que la deduplicación funcionó como esperaba y que sus datos estén ahora precisos y libres de duplicados.
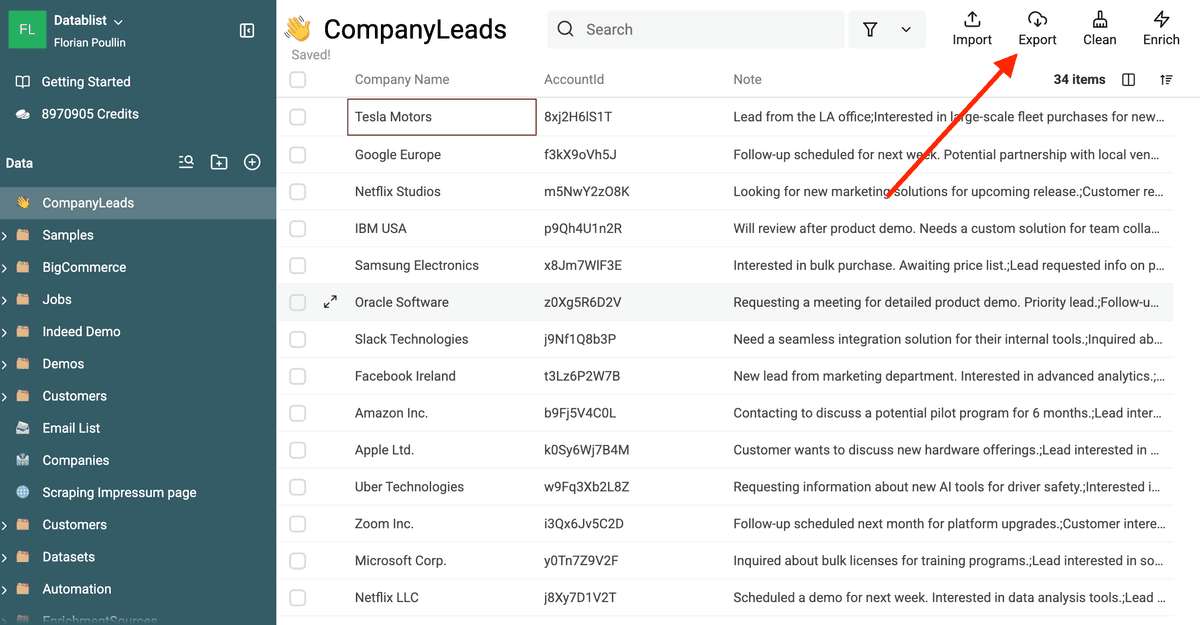
Luego, vuelva a su collection y haga clic en "Export" para descargar el CSV o Excel con los datos limpios.
Pruebe Datablist para la limpieza continua de datos.
Preguntas frecuentes (FAQ)
¿Datablist es realmente gratis para deduplicación?
¡Sí! Puede eliminar duplicados de su lista online gratis 💰, sin registrarse.
Solo cargue su archivo y empiece a limpiar. Para algoritmos avanzados de matching, puede crear una cuenta free.
Los únicos algoritmos de pago son el fuzzy matching y la deduplicación fonética.
¿Puede Datablist manejar listas grandes con miles de registros?
¡Por supuesto! Datablist está diseñado para procesar listas grandes con eficiencia.
Tenga 10.000 o 500.000+ registros, el buscador de duplicados analizará y agrupará rápidamente. No necesita dividir sus datos: ¡solo cargue y limpie!
¿Datablist admite fuzzy matching para detectar casi duplicados?
¡Sí! Datablist incluye algoritmos de fuzzy matching 🔍 como Levenshtein y Jaro-Winkler para detectar typos y pequeñas diferencias. Por ejemplo, puede emparejar:
- "Jon Smith" con "John Smith"
- "Acme Ltd." con "Acme Inc"
Usted controla el nivel de similitud para ajustar el umbral y mejorar la precisión.
¿Puedo deduplicar mis contactos de CRM, Leads o datos de clientes?
¡Sí! Exporte sus datos de CRM (de HubSpot, Salesforce u otra herramienta) como archivo CSV, súbalo a Datablist y elimine duplicados en minutos. Tras limpiar, puede usar los Change Files generados para aplicar los cambios en su CRM, sin teclear nada manualmente.
Si usa Pipedrive, ofrecemos una integración directa para deduplicación masiva.