
Sainsbury's ne propose pas d’API publique pour ses produits. C’est pour cela que la plupart des équipes qui essaient de scraper les produits Sainsbury's finissent soit par payer plus de 2 000 £ à un freelance, soit par brancher un scraper Apify qui casse au bout de quelques jours.
Ce que beaucoup ignorent, c’est qu’il existe une troisième voie : le AI scraping. Cette approche lit la page comme le ferait un humain. Résultat : la même configuration fonctionne sur une catégorie Sainsbury's, une page de marque ou une page de promotions, et résiste bien mieux aux changements de layout qui mettent hors service les scrapers classiques.
Dans ce guide, nous allons voir l’ensemble du processus : pourquoi créer un scraper produit Sainsbury's sur mesure n’est pas un bon investissement, quelles pages Sainsbury's donnent les données les plus propres, et un pas-à-pas complet avec Datablist's AI Scraping Agent.
📌 Résumé pour les plus pressés
Cet article explique comment scraper les données produit de Sainsbury's avec Datablist's AI Scraping Agent.
Problème : Sainsbury's n’a pas d’API publique pour ses produits, les scrapers prêts à l’emploi cassent quelques semaines après chaque mise à jour du site, et un développement sur mesure coûte plus de 2 000 £, sans compter la maintenance.
Solution : Utiliser Datablist's AI Scraping Agent pour scraper les produits Sainsbury's avec un prompt en langage naturel et une seule URL.
Ce que vous allez apprendre :
- Pourquoi un scraper Sainsbury's sur mesure devient vite un gouffre financier
- Quelles pages Sainsbury's renvoient les données les plus propres
- Une méthode en 5 étapes pour scraper n’importe quelle catégorie Sainsbury's en moins de 10 minutes
Pourquoi Datablist :
- L’AI scraping comprend le sens de la page, pas seulement le HTML, donc les mises à jour de layout de Sainsbury's ne cassent pas l’extraction
- La pagination est gérée automatiquement (jusqu’à 5 000 pages par run)
- Pas de code, pas de clé API, juste une URL Sainsbury's et un prompt
Ce que couvre ce guide
- Pourquoi créer un scraper Sainsbury's sur mesure n’en vaut pas la peine
- Comment scraper les produits Sainsbury's avec l’AI Agent de Datablist
- Scraper Sainsbury's : le guide étape par étape
- FAQ sur le scraping de Sainsbury's
Créer un scraper Sainsbury's sur mesure est un gouffre financier
Si vous avez déjà envisagé de développer votre propre scraper Sainsbury's, voici trois bonnes raisons de reconsidérer la question avant de dépenser le moindre centime.
C’est coûteux
Un scraper Sainsbury's stable ne se monte pas en un week-end. sainsburys.co.uk charge sa grille de produits dynamiquement via JavaScript, pagine sur des centaines de pages catégorie et met son layout à jour assez souvent pour qu’un scraper basé sur des règles doive être corrigé en permanence.
Voici ce que la plupart des équipes essaient, et pourquoi chaque option finit par montrer ses limites :
- Faire appel à un développeur freelance : plus de 2 000 £ pour la première version, puis des frais récurrents à chaque fois que Sainsbury's modifie sa grille
- Acheter un scraper produit Sainsbury's préconstruit sur Apify ou GitHub : il fonctionne le premier jour, puis casse quelques semaines plus tard au prochain changement de layout
- Coder rapidement un script Puppeteer ou Playwright : la pagination Sainsbury's, le rendu JavaScript et les fiches produit parfois incohérentes le mettent vite en défaut
Si vous avez simplement besoin d’un snapshot ponctuel, un freelance peut suffire. Mais si vous avez besoin de données Sainsbury's fraîches de manière récurrente (suivi de prix, analyse FMCG, retail arbitrage), le coût de maintenance s’accumule mois après mois.
C’est long à mettre en place
Même avec un bon développeur, mettre en place un scraper Sainsbury's propre prend des semaines. Il faut cartographier chaque page catégorie, gérer le HTML rendu, écrire la logique de pagination pour les grilles produits et prévoir les cas où Sainsbury's renvoie "N/A" pour les prix promotionnels ou masque certains produits derrière des restrictions d’âge.
Datablist's AI Scraping Agent élimine toute cette phase de développement. Vous pouvez coller une URL Sainsbury's et récupérer des données produit structurées en moins de 10 minutes. Pas de cahier des charges, pas d’allers-retours sur les edge cases, pas d’attente pour une v2.
Ça casse en permanence
C’est là que se cache le vrai coût : Sainsbury's met souvent à jour sa grille produit. À chaque fois que l’équipe déploie un nouveau template de catégorie ou déplace l’élément du prix, votre scraper Sainsbury's sur mesure cesse de fonctionner.
Vous n’avez alors que deux options : repayer le développeur ou passer votre après-midi à déboguer.
L’AI scraping contourne ce problème. Comme l’AI Agent comprend le sens de la page plutôt que sa structure HTML, un prix reste un prix même si Sainsbury's change la classe CSS qui l’entoure.
💡 La différence fondamentale
Les scrapers traditionnels suivent des règles : « trouver l’élément avec la classe .product-price et extraire le texte ». Les scrapers IA suivent l’intention : « trouver le prix du produit sur cette page Sainsbury's ».
C’est pour cela que la même configuration qui fonctionne sur Sainsbury's aujourd’hui continue de fonctionner après une réorganisation de la grille le mois prochain, et qu’elle se transfère facilement à Tesco, Morrisons et Asda sans code spécifique par site.
Comment scraper les produits Sainsbury's avec l’AI Agent de Datablist
Avant de passer au tutoriel, voyons rapidement ce qu’est réellement l’AI Scraping Agent, quelles pages Sainsbury's donnent les meilleurs résultats, quelles données vous pouvez extraire et où se situent les limites.
Qu’est-ce que Datablist's AI Scraping Agent ?
Datablist est une plateforme d’automatisation de workflows conçue pour créer des listes de leads, enrichir des données et exécuter des workflows de scraping. Dans Datablist, vous trouverez plus de 60 sources et enrichissements différents, et l’AI Scraping Agent est celui à utiliser pour extraire des données produit depuis le site d’un retailer.
L’agent repose sur trois éléments : une URL cible, un prompt qui décrit ce qu’il faut extraire, et un modèle de langage qui lit la page comme vous le feriez.
Pour scraper Sainsbury's, vous n’avez même pas besoin d’écrire le prompt vous-même. Datablist propose un template Retail Product Scraper qui précharge le prompt et les colonnes de sortie. Vous collez une URL Sainsbury's, et le template s’occupe du reste.
Trois points importants sur la manière dont l’agent gère Sainsbury's :
- OpenAI GPT 4.1 mini par défaut, le meilleur LLM en rapport qualité-prix pour l’AI scraping
- Render HTML activable, indispensable pour Sainsbury's puisque la grille produit est chargée en JavaScript
- Pagination automatique jusqu’à 5 000 pages par run
C’est aussi ce qui permet à la configuration de fonctionner telle quelle sur d’autres supermarchés britanniques. Le même agent, le même template et les mêmes réglages marchent sur Tesco, Morrisons, Asda, Waitrose et Aldi. Seule l’URL change.
La règle la plus importante : uniquement les pages de marque et de catégorie
Scrapez toujours des pages catégorie ou des pages de marque Sainsbury's, jamais la homepage ni une vue « all products ». Les listes trop volumineuses dépassent la fenêtre de contexte de l’AI Agent, le run s’interrompt en plein milieu sans possibilité de reprise, et vos crédits sont gaspillés.
Ce que l’AI Agent gère proprement sur Sainsbury's :
- ✅ Les pages catégorie sur sainsburys.co.uk/gol-ui/groceries/...
- ✅ Les pages marque (listings d’un fabricant spécifique)
- ✅ Les pages de promotions ou d’offres
Ce qu’il vaut mieux éviter :
- ❌ La homepage Sainsbury's
- ❌ Les vues « all products » ou les résultats de recherche sur tout le site
- ❌ Tout ce qui charge des milliers de produits dans un seul infinite scroll
Quelles données peut-on extraire de Sainsbury's ?
Un seul run Sainsbury's peut extraire toutes les données produit dont vous avez besoin pour le suivi de prix, la veille concurrentielle ou le data enrichment d’un catalogue existant :
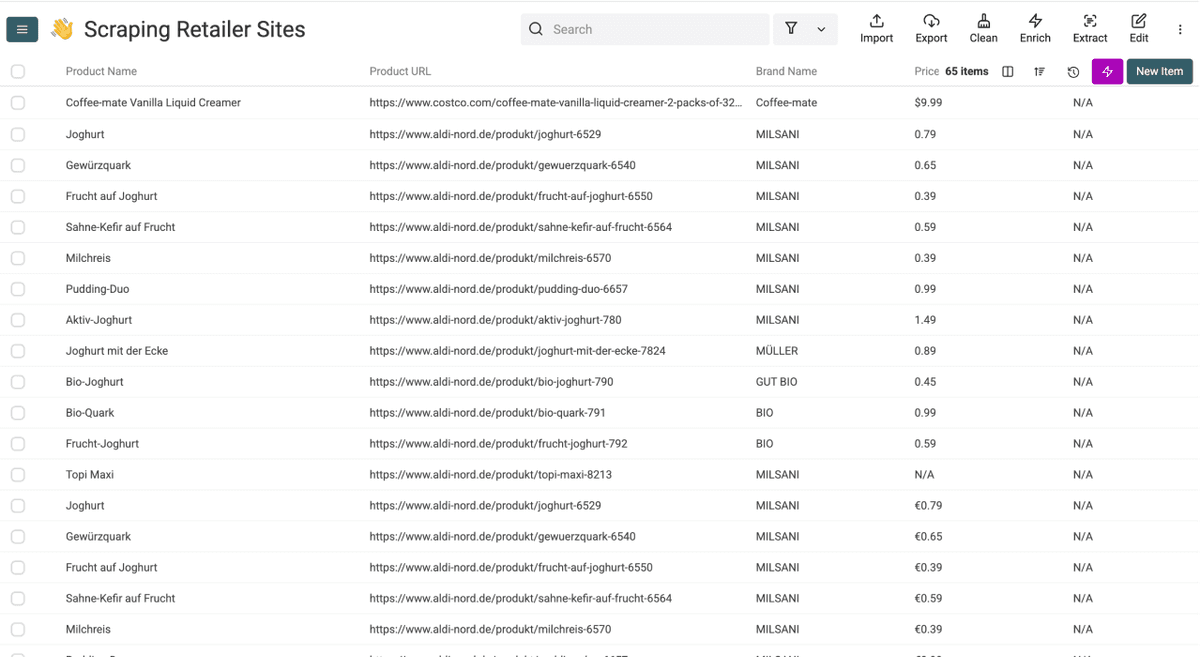
- Product Name : nom complet du produit tel qu’affiché sur le site Sainsbury's
- Product URL : lien direct vers la fiche produit sur sainsburys.co.uk
- Brand Name : marque ou fabricant du produit
- Price : prix actuel en GBP, symbole £ inclus
- Sale Price : prix promotionnel si une offre Sainsbury's est active, "N/A" sinon
- Product Category : rayon ou catégorie du produit
- Availability : en stock, en rupture ou disponibilité limitée
- Rating : note client lorsque Sainsbury's l’affiche
- Image URL : lien direct vers l’image principale du produit
- SKU : identifiant produit interne de Sainsbury's
Choisissez les champs dont vous avez réellement besoin avant de lancer le run, afin que l’export ne contienne que les colonnes utiles.
Scraper Sainsbury's : le guide étape par étape
La configuration complète pour scraper Sainsbury's tient en 5 étapes. Avant de commencer, assurez-vous d’avoir :
- Une URL Sainsbury's de catégorie ou de marque (pas la homepage)
- Une idée claire des champs produit dont vous avez réellement besoin
Étape 1 : inscrivez-vous et créez une Collection
Commencez par créer un compte sur Datablist.com.

Ensuite, créez une New Collection.
Étape 2 : ouvrez l’AI Scraping Agent
- Cliquez sur See all sources
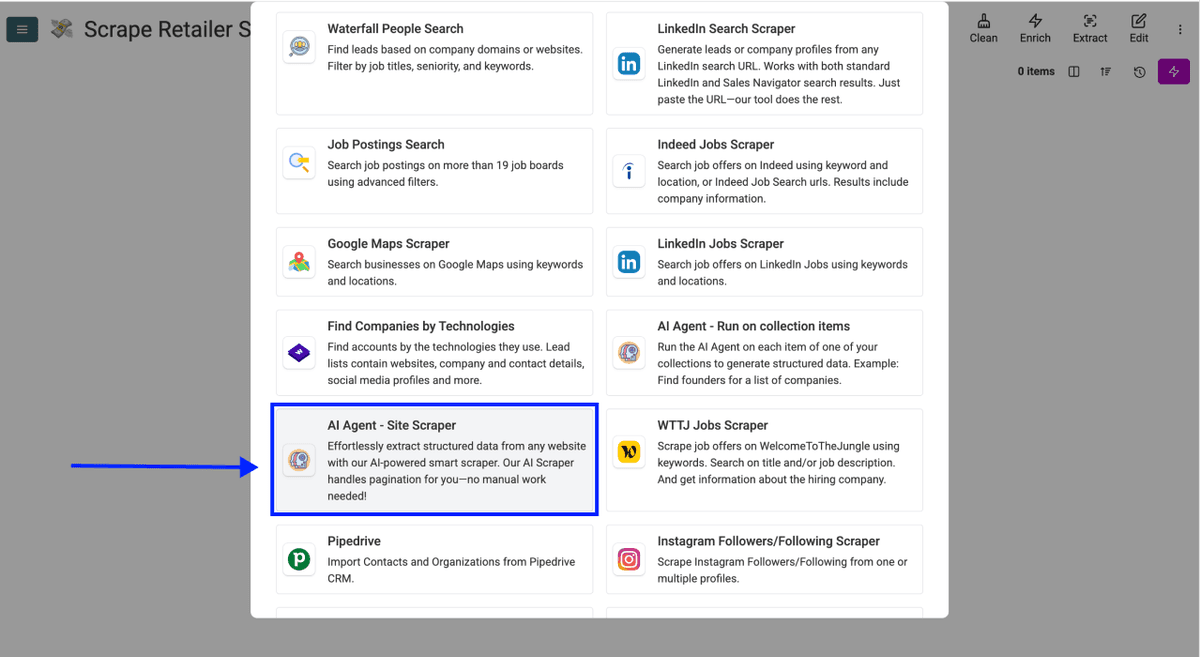
- Descendez dans la liste, puis sélectionnez AI Scraping Agent (Site Scraper).
Vous devriez maintenant voir l’interface de configuration de la source, qui ressemble à ceci :
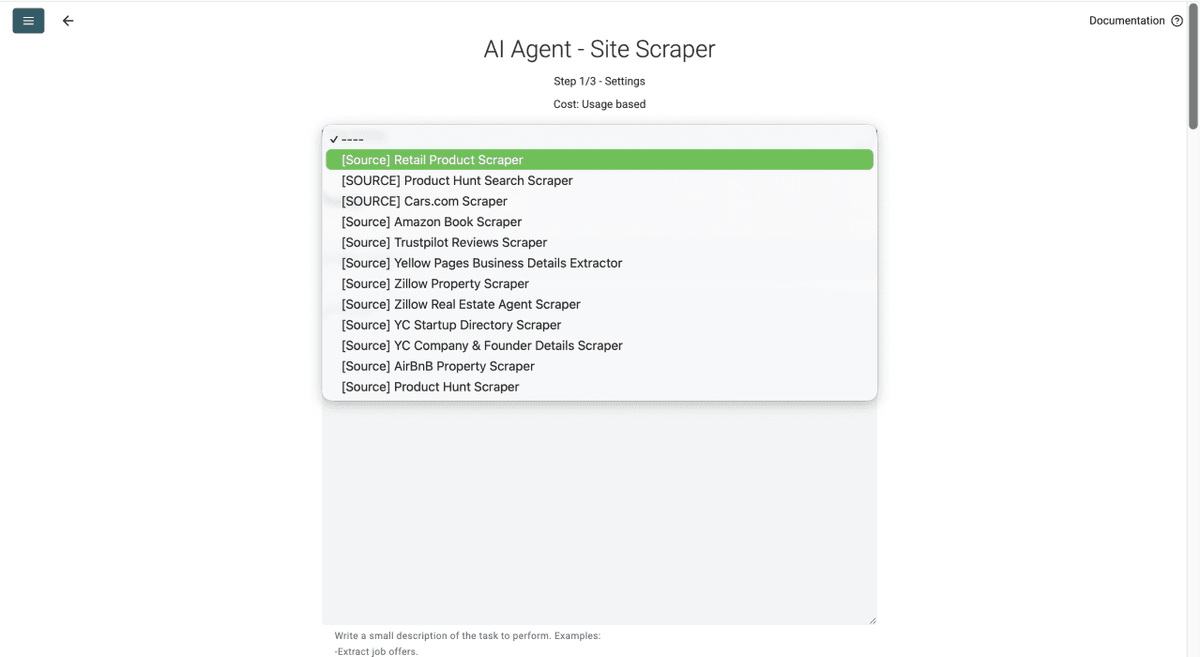
Étape 3 : sélectionnez le template Retail Product Scraper et collez une URL Sainsbury's
- Cliquez sur le Template Drop-Down et choisissez « Retail Product Scraper »
- Collez votre URL de catégorie Sainsbury's dans le champ URL, par exemple :
https://www.sainsburys.co.uk/gol-ui/groceries/frozen/fish-and-seafood/c:1019924/opt/page:2
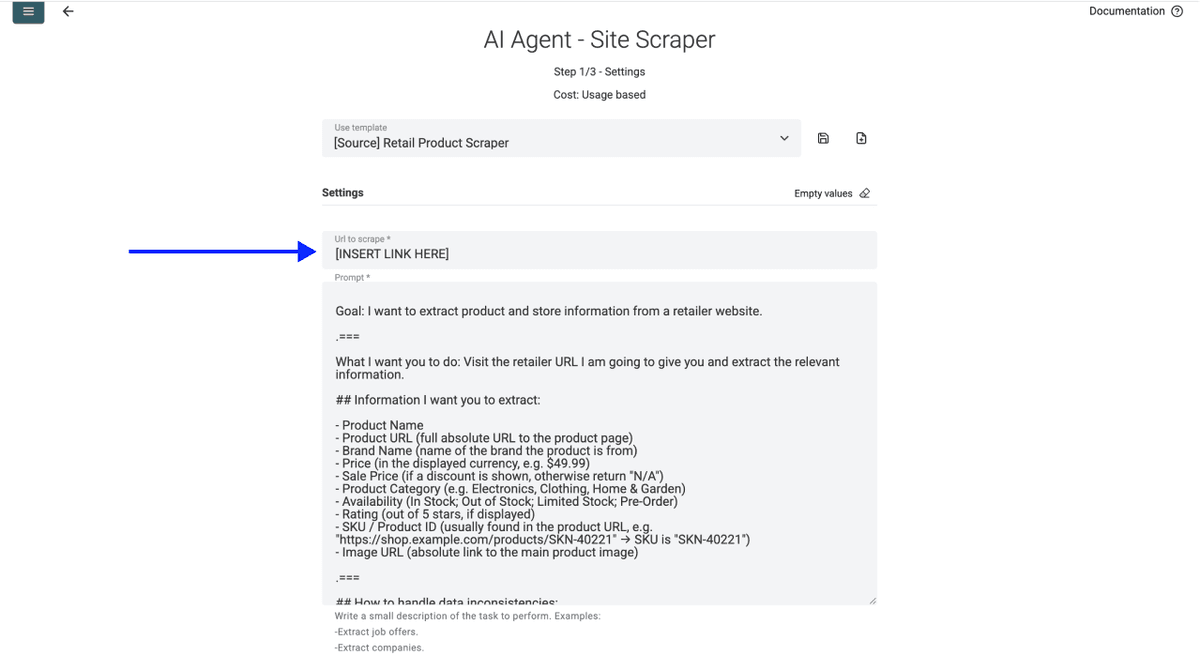
❗️ Uniquement les pages de marque et de catégorie (rappel)
Ne collez jamais la homepage Sainsbury's ni une URL « all products ». Les grosses listes dépassent la fenêtre de contexte de l’AI Agent. Scrapez Sainsbury's catégorie par catégorie.
- Définissez le nombre de pages à scraper (Sainsbury's affiche généralement autour de 60 produits par page, donc une catégorie de 200 produits nécessite environ 3 à 4 pages)
- Descendez puis cliquez sur Continue
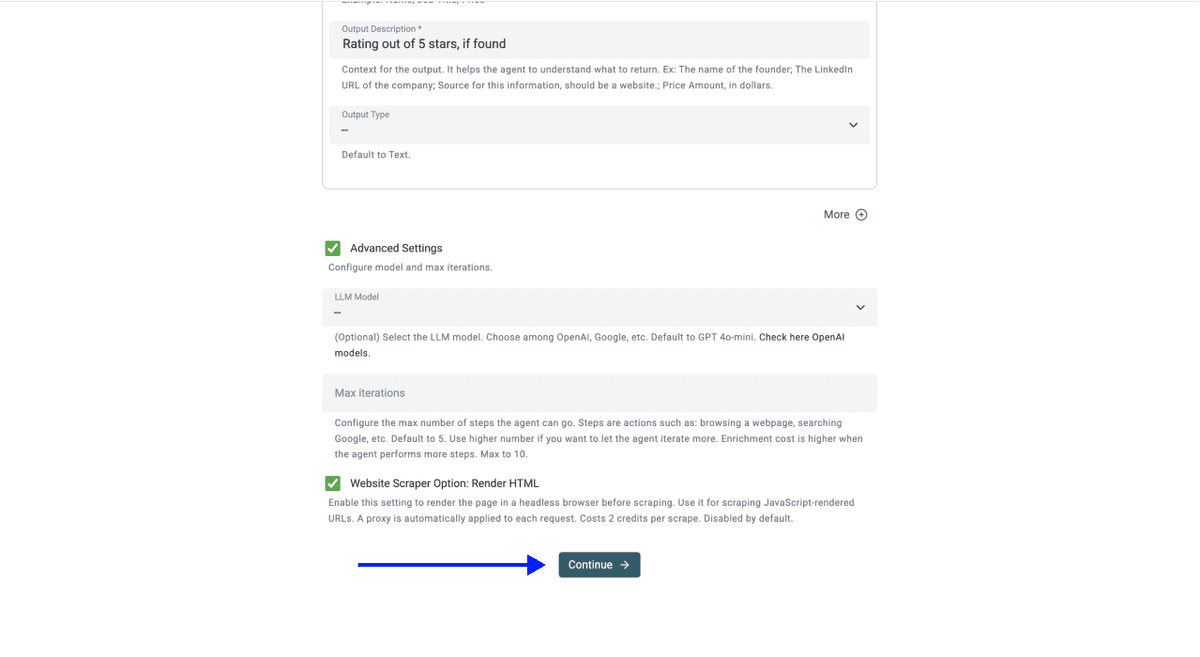
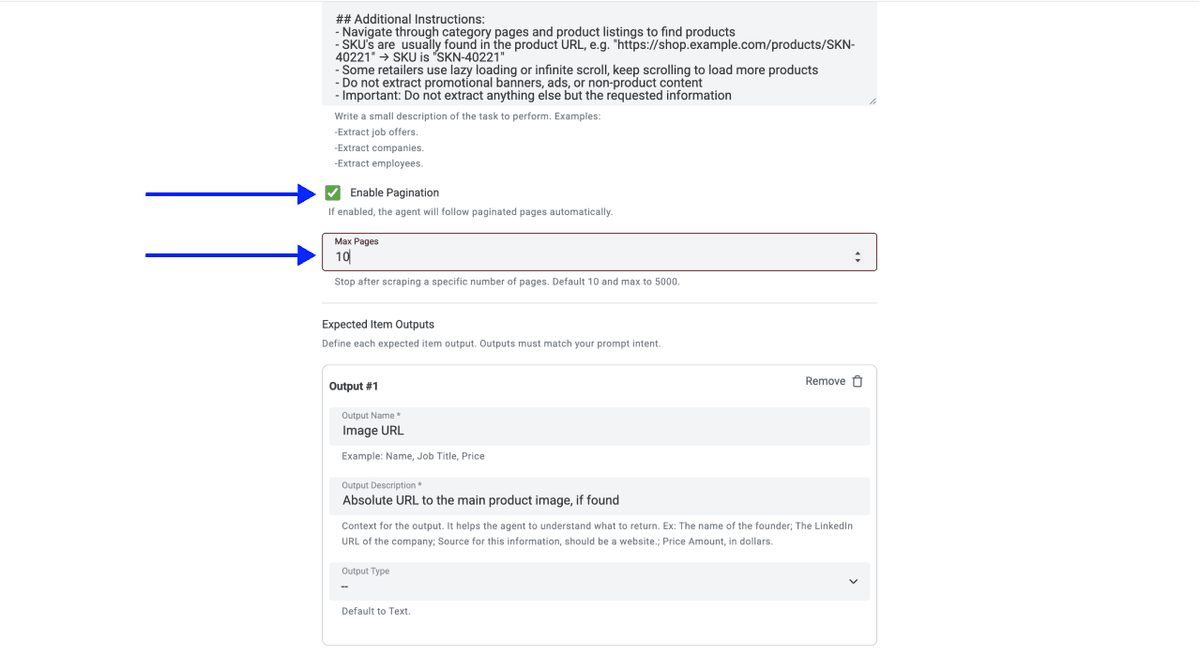
💡 Vérifiez vos Advanced Settings avant de cliquer sur Continue
Assurez-vous que ces options sont bien activées :
- LLM : OpenAI GPT 4.1 mini (meilleur ratio performance/prix)
- Max Iterations : 10
- Website Scraper Option: Render HTML (essentiel pour Sainsbury's, car le site charge sa grille produit dynamiquement via JavaScript)
Étape 4 : configurez les outputs
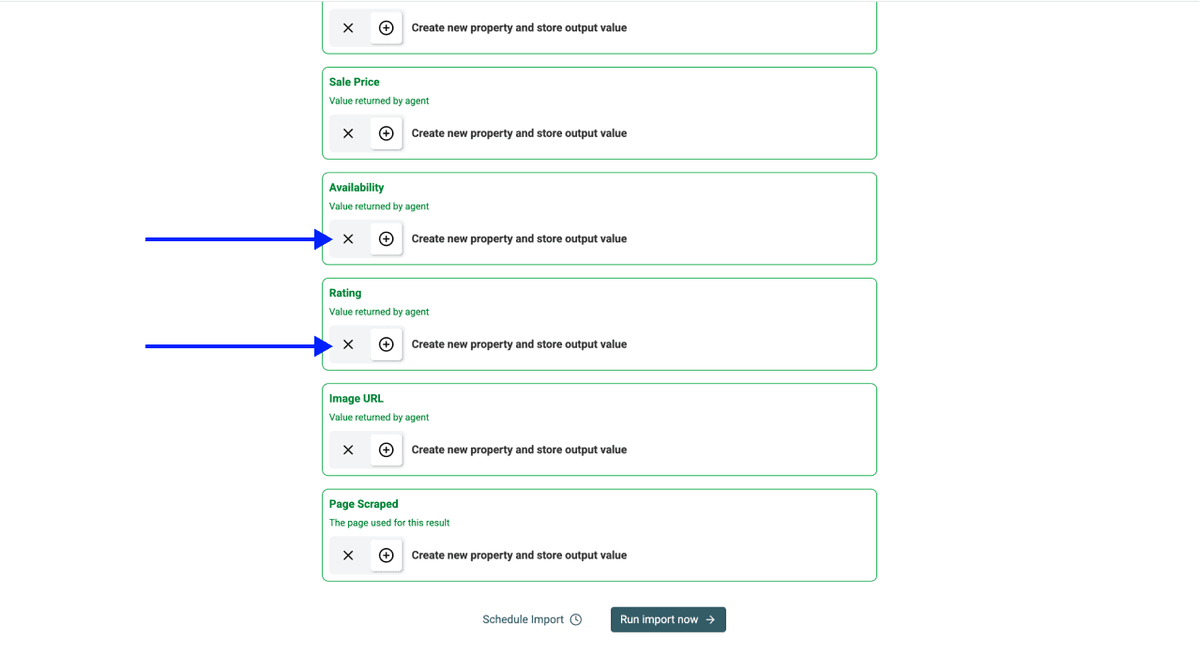
Datablist crée automatiquement les propriétés de sortie.
Cliquez sur les icônes X pour retirer les outputs dont vous n’avez pas besoin (par exemple, supprimez Rating si votre objectif est uniquement le suivi des prix Sainsbury's).
Étape 5 : lancez le run
Une fois vos outputs définis, cliquez sur Run Import Now pour démarrer le scraping Sainsbury's.
Après quelques minutes, vos résultats Sainsbury's ressembleront à ceci. À partir de là, les fonctionnalités d’automatisation de workflow de Datablist peuvent nettoyer, dédupliquer et exporter les données.
💡 Évitez les doublons lors de runs Sainsbury's répétés
Si vous prévoyez de scraper à nouveau la même catégorie Sainsbury's plus tard :
- Choisissez une colonne avec identifiant unique (Product URL fonctionne le mieux)
- Cliquez sur l’en-tête de colonne → Rename - Settings - Delete
- Cochez : Do not allow duplicate values
- Save Property
Si vous récupérez aussi des données depuis Tesco, Morrisons et Asda dans le même fichier, notre guide sur la suppression des doublons dans un fichier CSV explique comment gérer la déduplication multi-retailers.
Datablist’s AI Agent scrape aussi d’autres sites de retailers
La configuration Sainsbury's n’est pas spécifique à Sainsbury's. Le même AI Scraping Agent et le même template Retail Product Scraper fonctionnent sur tous les supermarchés britanniques que nous avons testés. Seule l’URL change.
Si vous récupérez aussi des données produit depuis un retailer comparable, consultez les guides pas à pas ci-dessous :
L’essentiel à retenir
- Un scraper produit Sainsbury's sur mesure est un gouffre financier. Le coût de départ dépasse 2 000 £, la maintenance vient s’ajouter, et les mises à jour de layout de Sainsbury's finiront par le casser régulièrement.
- L’AI scraping comprend le sens, pas le HTML. C’est pour cela que la même configuration continue de scraper les produits Sainsbury's même après un changement de grille, et qu’elle se transfère à Tesco, Morrisons et Asda sans code spécifique.
- Scrapez toujours des pages de marque ou de catégorie, jamais la homepage. Les listes trop volumineuses dépassent la fenêtre de contexte de l’agent et gaspillent le run.
- La configuration complète prend moins de 5 minutes. Template, URL, outputs, run.
FAQ sur le scraping de Sainsbury's
Combien coûte le scraping des produits Sainsbury's ?
Datablist's AI Agent fonctionne avec un système de crédits basé sur l’usage. Le coût d’un run Sainsbury's dépend du nombre de produits et de pages traités par l’agent. Les offres Datablist démarrent à 25 $/mois avec 5 000 crédits inclus, et les packs de recharge commencent à 20 $ pour 20 000 crédits, avec des remises allant jusqu’à 35 % sur les plus gros volumes.
Combien de temps faut-il pour scraper tout le catalogue Sainsbury's ?
La plupart des pages catégorie Sainsbury's contenant 50 à 200 produits sont scrapées en 5 à 10 minutes. Les runs plus volumineux sur plusieurs catégories paginées (500+ produits) peuvent prendre 10 à 20 minutes. La configuration initiale ajoute généralement 2 à 3 minutes.
Pourquoi scraper une page catégorie Sainsbury's plutôt qu’une page « all products » ?
Une vue Sainsbury's « all products » charge des milliers d’articles dans une seule page rendue. Cela dépasse la fenêtre de contexte de l’AI Agent, l’agent s’arrête en cours de route, et il n’existe pas d’option de reprise : le run partiel est donc perdu. Les pages catégorie et marque restent dans une plage sûre, s’exécutent proprement et peuvent ensuite être fusionnées dans une même Collection si vous voulez une couverture complète.
Peut-on récupérer les prix promotionnels et les offres Sainsbury's ?
Oui. Le template Retail Product Scraper inclut un output Sale Price. Lorsqu’une promotion Sainsbury's est active, le prix remisé remonte correctement. Lorsqu’aucune offre n’est en cours, la colonne renvoie "N/A", ce qui est d’ailleurs pratique pour filtrer les produits en promotion ou non à travers différentes catégories.
Le scraping de Sainsbury's est-il légal au Royaume-Uni ?
Le scraping de données produit Sainsbury's visibles publiquement (noms, prix, disponibilité) est généralement considéré comme légal au Royaume-Uni, selon les mêmes principes que pour les autres données web publiques. Vous devriez tout de même consulter les conditions d’utilisation de Sainsbury's, éviter de scraper des données personnelles et rester dans des volumes de requêtes raisonnables. En usage commercial, mieux vaut faire valider cela par votre équipe juridique.
Sainsbury's bloque-t-il les scrapers ?
Les protections anti-bot de Sainsbury's restent modérées comparées à celles de Walmart ou Costco. La plupart des runs Sainsbury's via Datablist réussissent dès la première tentative, surtout lorsque Render HTML est activé. Si une page catégorie ne renvoie pas de données, réduisez le nombre de pages et relancez, ou découpez l’extraction en sous-catégories plus précises.
Peut-on planifier des runs récurrents pour le suivi des prix Sainsbury's ?
Oui. Les fonctionnalités d’automatisation de workflow de Datablist permettent de configurer des runs récurrents. Associez cela à une colonne d’identifiant unique (Product URL est le meilleur choix) et au paramètre de prévention des doublons, afin que chaque nouveau run Sainsbury's n’ajoute que les nouveaux produits au lieu de dupliquer les existants.
Peut-on scraper Sainsbury's sans savoir coder ?
Oui, aucune compétence technique n’est nécessaire. Tout le process est no-code : sélectionnez le template Retail Product Scraper, collez une URL Sainsbury's, choisissez vos outputs, puis lancez le run. Si vous savez écrire une phrase, vous pouvez scraper Sainsbury's avec Datablist.
Quelles catégories Sainsbury's sont les plus adaptées au scraping ?
Les catégories alimentaires standard sur https://www.sainsburys.co.uk/gol-ui/groceries](https://www.sainsburys.co.uk/gol-ui/groceries renvoient les données les plus propres : produits frais, surgelés, boulangerie, boissons, entretien de la maison. Les pages marque fonctionnent également très bien. Les pages promo ou « Last chance » peuvent être un peu plus bruitées parce que les fiches produit mélangent plusieurs formats, mais l’AI Agent en extrait quand même des données exploitables.
L’AI Agent gère-t-il automatiquement la pagination sur Sainsbury's ?
Oui. Avec Enable Pagination activé, l’AI Agent parcourt chaque page de la catégorie Sainsbury's jusqu’à la limite configurée (10 par défaut, 5 000 maximum). Pour une catégorie Sainsbury's de 240 produits affichant 24 articles par page, réglez la pagination sur 10 et l’agent récupérera la liste complète.
Qu’est-ce que l’AI scraping ?
L’AI scraping est une méthode d’extraction de données structurées depuis des sites web à l’aide d’un modèle de langage, plutôt qu’avec des règles HTML fixes. L’agent visite une page, lit son contenu et renvoie les champs demandés en langage naturel. C’est précisément ce qui le rend robuste sur des sites comme Sainsbury's, qui mettent souvent leur layout à jour.
Quelle différence entre AI scraping et web scraping traditionnel ?
Les scrapers traditionnels suivent des règles fixes (sélecteurs CSS, XPath). Quand le site change, ces règles cassent. L’AI scraping comprend le sens de la page : un prix Sainsbury's reste donc un prix Sainsbury's même si le balisage change. C’est pourquoi la même configuration Datablist fonctionne sur Tesco, Sainsbury's, Morrisons et Asda, sans code spécifique pour chaque site.