

La plupart des sites de retailers sont conçus pour vendre, pas pour partager leurs données. C’est pour cela que les scraper implique généralement de faire appel à un développeur ou de se battre avec du code.
Et contrairement au scraping de boutiques Shopify, où les sites suivent une structure assez similaire, scraper des sites de retailers est imprévisible, car chaque site est construit différemment. C’est là que le AI scraping fait la différence : il comprend le sens, pas seulement le code.
Dans ce guide, nous allons voir tout le processus : pourquoi les scrapers sur mesure ne valent pas l’effort, quels retailers nous avons réussi à scraper (et lesquels ont résisté), ainsi qu’un pas-à-pas complet pour extraire des données produits avec l’AI Scraping Agent de Datablist.
📌 Résumé pour les plus pressés
Cet article explique comment scraper des sites de retailers avec l’AI Scraping Agent de Datablist.
Problème : les sites de retailers ont tous une structure différente. Les scrapers traditionnels cassent donc en permanence, et les solutions développées sur mesure coûtent cher à maintenir.
Solution : utilisez l’AI Scraping Agent de Datablist.com pour extraire des données produits depuis des sites de retailers à l’aide de prompts en anglais simple.
Ce que vous allez apprendre :
- Pourquoi créer un scraper sur mesure pour des sites de retailers fait perdre du temps et de l’argent
- Quels sites de retailers nous avons testés et quelles données nous avons pu extraire
- Un tutoriel complet pour scraper n’importe quel site de retailer compatible en quelques minutes
Pourquoi Datablist :
- L’AI scraping lit la page comme un humain, donc il fonctionne malgré des structures de sites différentes
- Il gère automatiquement la pagination (jusqu’à 5 000 pages par exécution)
- Aucun code, aucune configuration d’API, juste une URL et un prompt
Ce que couvre ce guide
- Pourquoi créer un scraper sur mesure est une perte de ressources
- Comment fonctionne le scraping de sites de retailers
- Scraper un site de retailer : le guide étape par étape
- FAQ sur le scraping de sites de retailers
Pourquoi créer un scraper sur mesure est une perte de ressources
Si vous avez déjà envisagé de créer votre propre scraper pour extraire des données produits depuis des sites de retailers, voici trois bonnes raisons de reconsidérer cette idée.
C’est coûteux
Créer un scraper web sur mesure qui fonctionne correctement sur des sites de retailers n’est pas un petit projet du week-end. Ces sites utilisent du chargement dynamique de contenu, du rendu JavaScript et des protections anti-bot qui demandent de vraies compétences techniques.
Il existe quelques approches courantes pour scraper des sites de retailers, mais chacune a ses limites :
- Faire appel à un développeur freelance : à partir de 2 000 $+ par site de retailer, puis vous repayez à chaque fois que le scraper casse
- Utiliser un scraper prêt à l’emploi (Apify, GitHub) : cela fonctionne jusqu’au prochain changement du site, puis vous revenez au dépannage
- Coder rapidement un script “vibe-code” : CAPTCHA, blocages IP et grilles produits paginées auront vite raison du script
Si vous devez scraper des sites de retailers plus d’une fois, les coûts grimpent très vite. Chaque retailer a sa propre structure de site, ce qui signifie qu’il faut une logique de scraping spécifique à chaque cas.
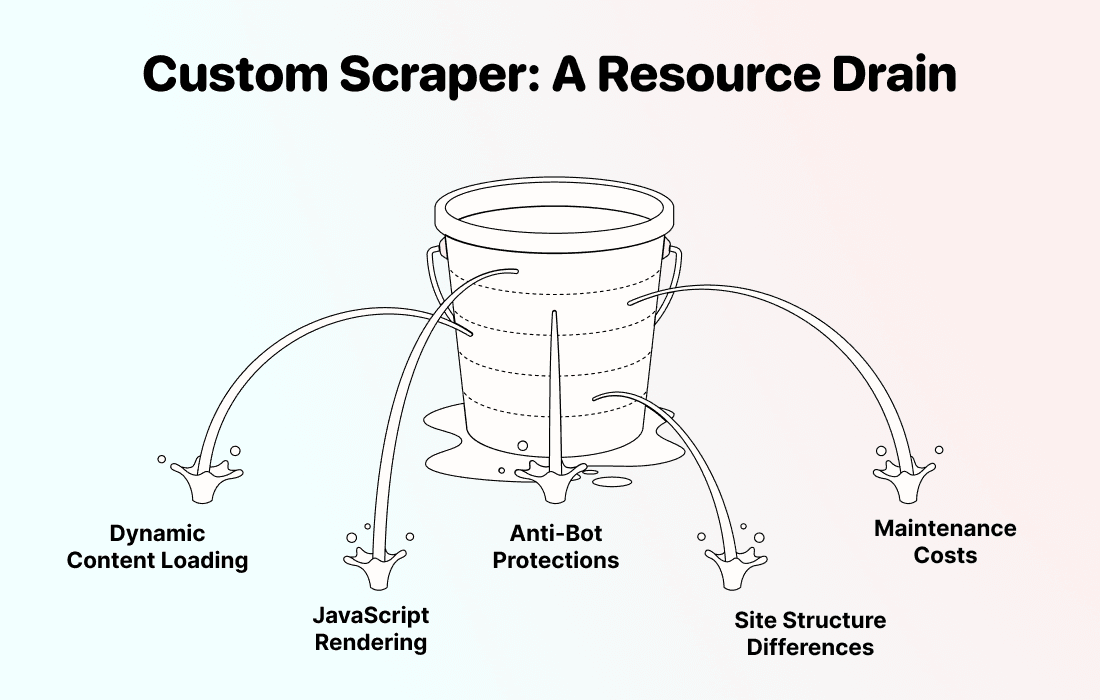
C’est long à mettre en place
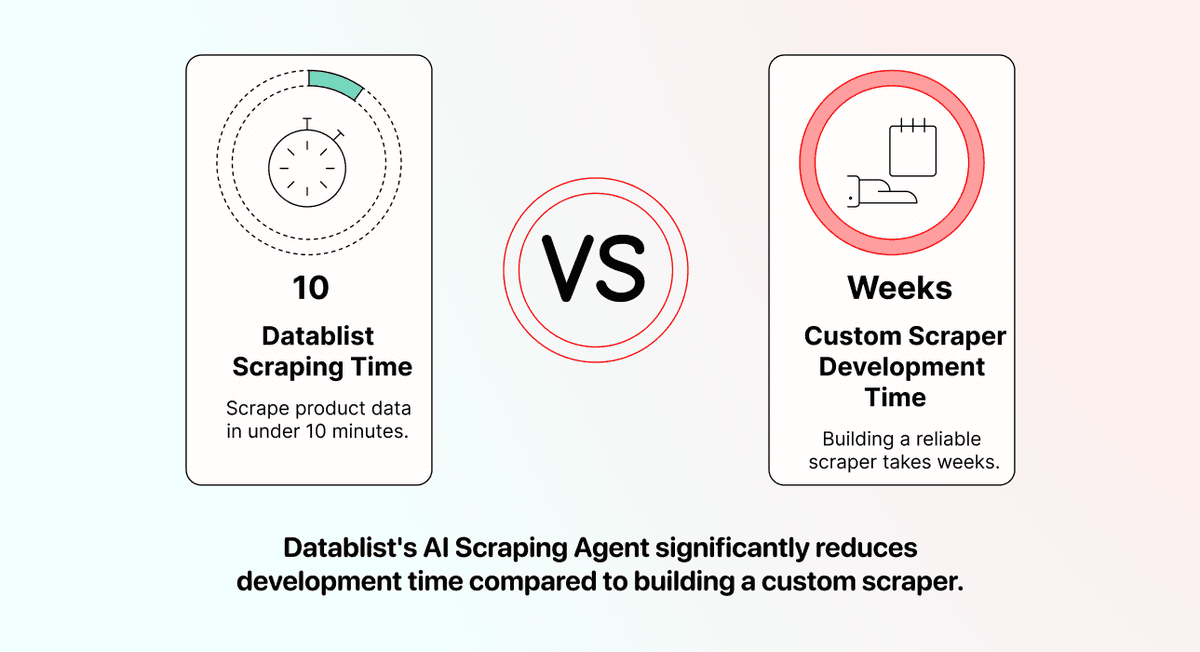
Même si vous trouvez un développeur, créer un scraper fiable prend souvent plusieurs semaines. Il faut analyser le fonctionnement de chaque site de retailer, gérer les cas particuliers, tester différentes catégories de produits et composer avec des formats de données incohérents.
Pendant ce temps, l’AI Scraping Agent de Datablist est déjà prêt, testé et conçu pour scraper des sites à grande échelle. Vous pouvez passer de zéro à des données produits exploitables en moins de 10 minutes. Pas besoin d’attendre une livraison de développeur ni de multiplier les allers-retours sur le cahier des charges.
Ça casse en permanence
C’est le vrai sujet. Les sites de retailers modifient régulièrement leur mise en page, parfois toutes les semaines. Dès que Tesco ou Aldi change une classe CSS, déplace un prix ou réorganise sa grille produits, votre scraper sur mesure cesse de fonctionner.
Résultat : vous payez un développeur pour faire de la maintenance en continu, ou vous passez votre propre temps à déboguer du code tous les quelques jours.
L’AI scraping n’a pas ce problème. Parce que l’AI agent lit le contenu de la page — et non sa structure HTML — il s’adapte automatiquement aux changements de mise en page. Un prix reste un prix, même si la classe CSS autour change.
💡 La vraie différence
Les scrapers traditionnels suivent des règles du type : « trouvez l’élément avec la classe .product-price et extrayez le texte ». Les scrapers IA suivent le sens : « trouvez le prix du produit sur cette page ».
C’est pour cela qu’ils fonctionnent sur différents sites de retailers sans configuration spécifique.
Comment fonctionne le scraping de sites de retailers
Avant de passer au tutoriel pas à pas, voici ce qu’il faut savoir : quels retailers fonctionnent, quelles données vous pouvez extraire et où se situent les limites.
Quelles données peut-on extraire d’un site de retailer ?
Quand vous scrapez des sites de retailers avec l’AI Agent de Datablist, vous pouvez extraire plusieurs types de données produits en une seule exécution. Voici ce que l’agent peut récupérer sur une page listing produits classique :
- Nom du produit - Le titre complet du produit tel qu’il apparaît sur la page
- URL du produit - Lien direct vers la fiche produit
- Marque - Le fabricant ou la marque du produit
- Prix - Le prix de vente actuel dans la devise affichée
- Prix promotionnel - Le prix remisé si une promotion est en cours (retourne « N/A » sinon)
- Catégorie produit - Le rayon ou la catégorie à laquelle le produit appartient
- Disponibilité - Si le produit est en stock, en rupture ou disponible en précommande
- Note - La note client ou le score d’avis, lorsqu’il est disponible
- URL de l’image - Lien direct vers l’image principale du produit
- SKU - L’identifiant du produit
Cela couvre les données essentielles dont la plupart des équipes ont besoin lorsqu’elles veulent récupérer des informations produits depuis des sites retail. Que vous fassiez du suivi de prix, de l’analyse concurrentielle ou du data enrichment pour enrichir une base existante, ces champs vous donnent une vue complète de chaque fiche produit.
Vous choisissez les champs de sortie souhaités avant de lancer le scraper. Vous ne récupérez donc que les données utiles à votre cas d’usage, sans bruit inutile.
Les sites de retailers que nous avons testés
Nous avons testé l’AI Scraping Agent de Datablist sur 8 sites de retailers en Allemagne, au Royaume-Uni et aux États-Unis. 5 sur 8 ont fonctionné dès le premier essai, sans configuration spécifique au site.
Scraping réussi (5/8)
✅ Tesco (tesco.com) - Noms de produits, prix, catégories et disponibilité extraits proprement
✅ Morrisons (morrisons.com) - Grille produits et pagination gérées sans problème
✅ Waitrose (waitrose.com) - Prix promotionnels et catégories produits extraits avec succès
✅ Netto Marken-Discount (netto-online.de) - Retailer allemand avec une structure de site différente, mais fonctionnement du premier coup
✅ Aldi (aldi-nord.de) - Listings produits, prix et SKU bien récupérés
Tous ces sites ont des structures très différentes, et pourtant l’AI agent a pu extraire les produits de chacun avec le même prompt, la même configuration et les mêmes outputs.
Bloqués par des protections anti-bot (3/8)
❌ Walmart (walmart.com) - Protections anti-bot avancées et chargement dynamique qui empêchent un scraping fiable
❌ Costco (costco.com) - Même type de protections, rendant l’extraction de données difficile de façon consistante
❌ Edeka (edeka.de) - Structure du site et méthode de diffusion du contenu qui bloquent des résultats fiables
Ces 3 sites investissent fortement dans des technologies anti-scraping. Pour la majorité des sites de retailers, notamment les chaînes alimentaires et les enseignes régionales, l’AI agent fonctionne bien.

Scraper un site de retailer : le guide étape par étape
Quand je disais plus haut que Datablist est simple à utiliser, ce n’était pas une formule. Le processus tient en 5 étapes, autrement dit en quelques clics. Avant de commencer, assurez-vous simplement de :
- Disposer de l’URL de la page retailer à scraper (une page catégorie, une page marque ou une page « tous les produits » fonctionne le mieux)
- Avoir une idée claire des informations produits que vous souhaitez extraire
Tutoriel pas à pas pour scraper un site de retailer
La section suivante vous guide sur tout le processus de scraping. Vous avez très peu à faire, car nous fournissons un template prêt à l’emploi.
Étape 1 : créer un compte et une collection
Commencez par créer un compte sur Datablist.com

Ensuite, créez une New Collection
Étape 2 : ouvrir AI Agent - Site Scraper
- Cliquez sur See all sources
- Faites défiler la page puis sélectionnez AI Agent - Site Scraper
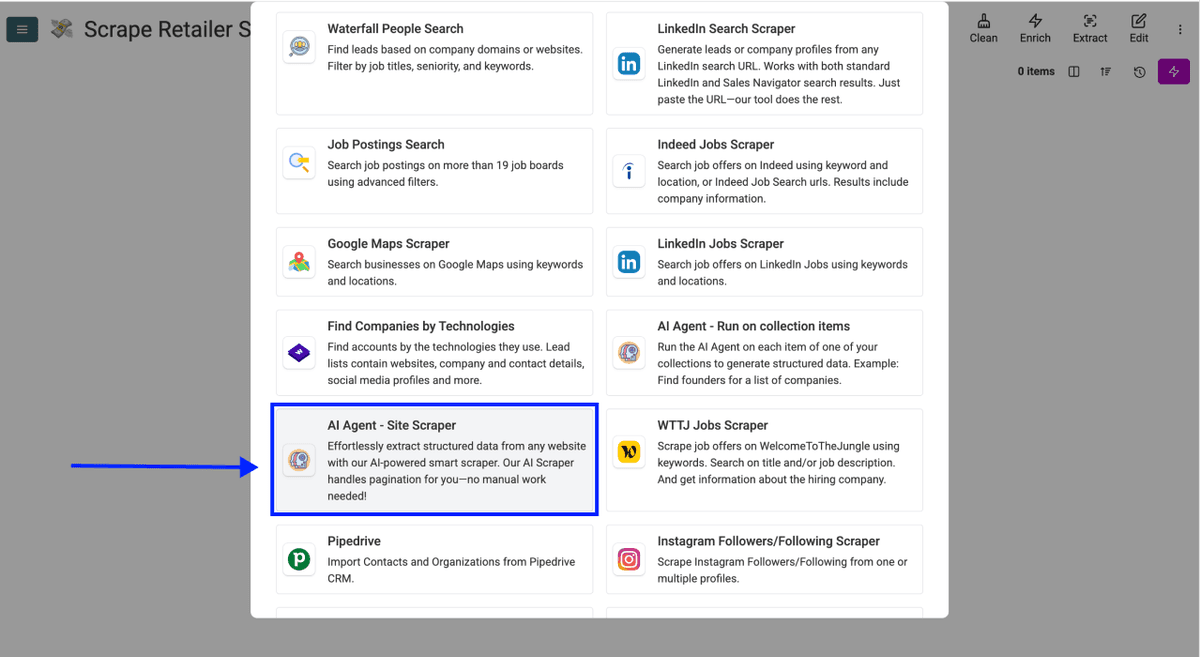
Vous devriez maintenant voir une interface différente, similaire à celle-ci :
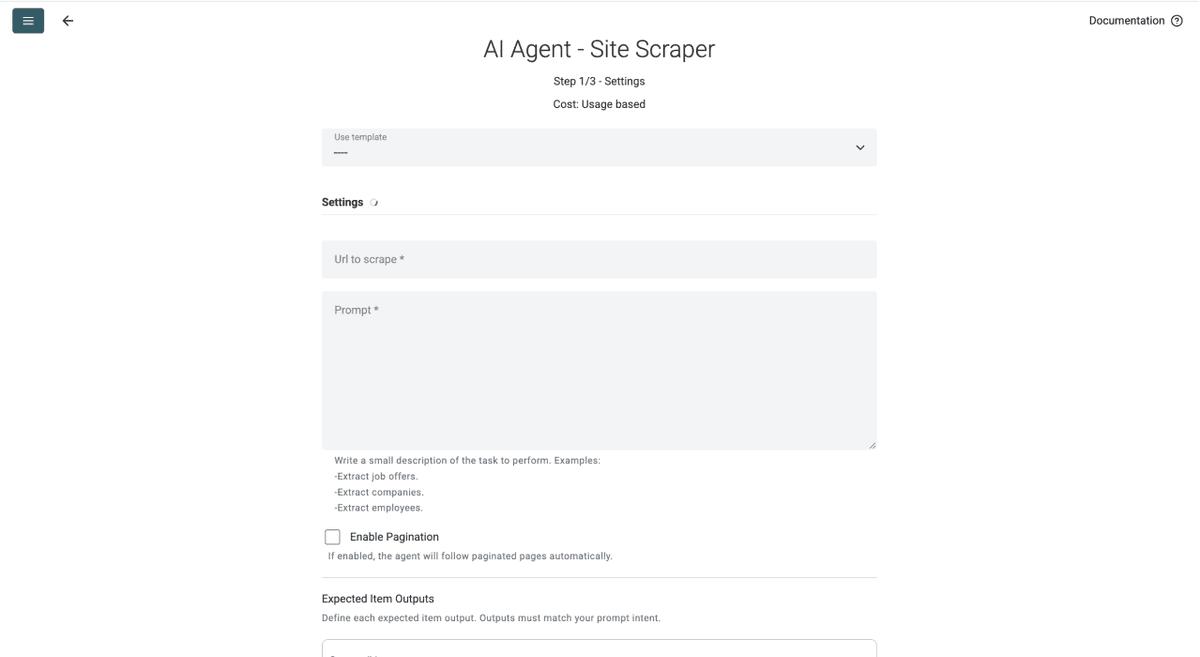
Étape 3 : choisir le template et configurer la tâche
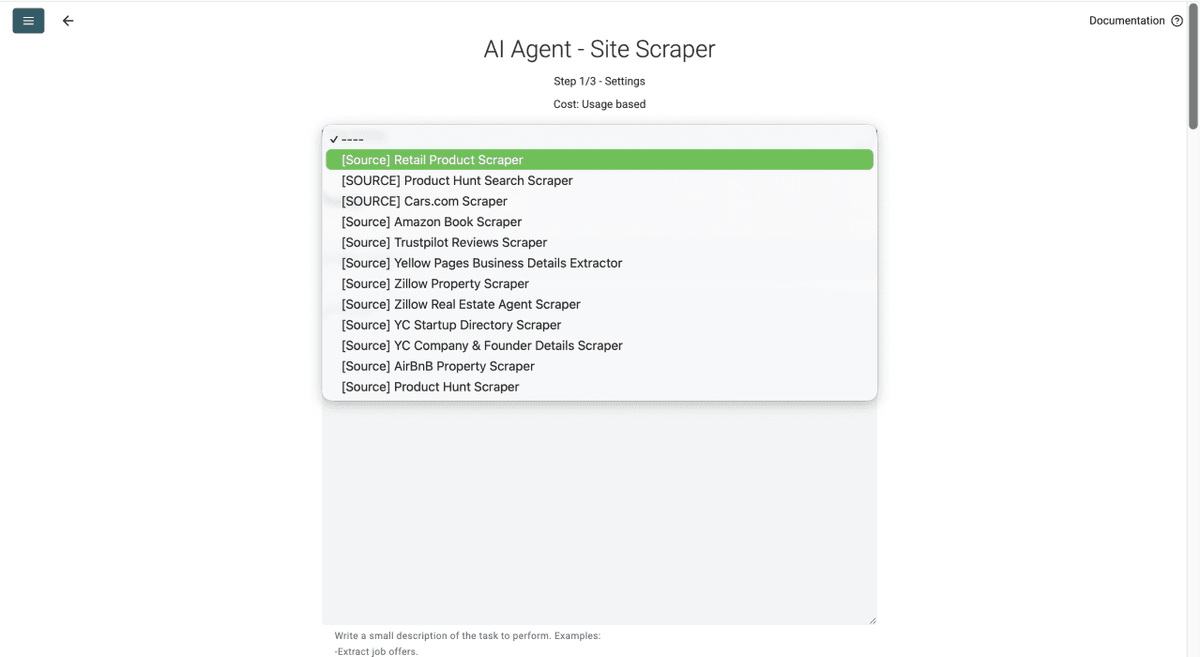
- Cliquez sur le Template Drop-Down et sélectionnez « Retail Product Scraper »
- Collez l’URL de votre page produit retailer dans le premier champ
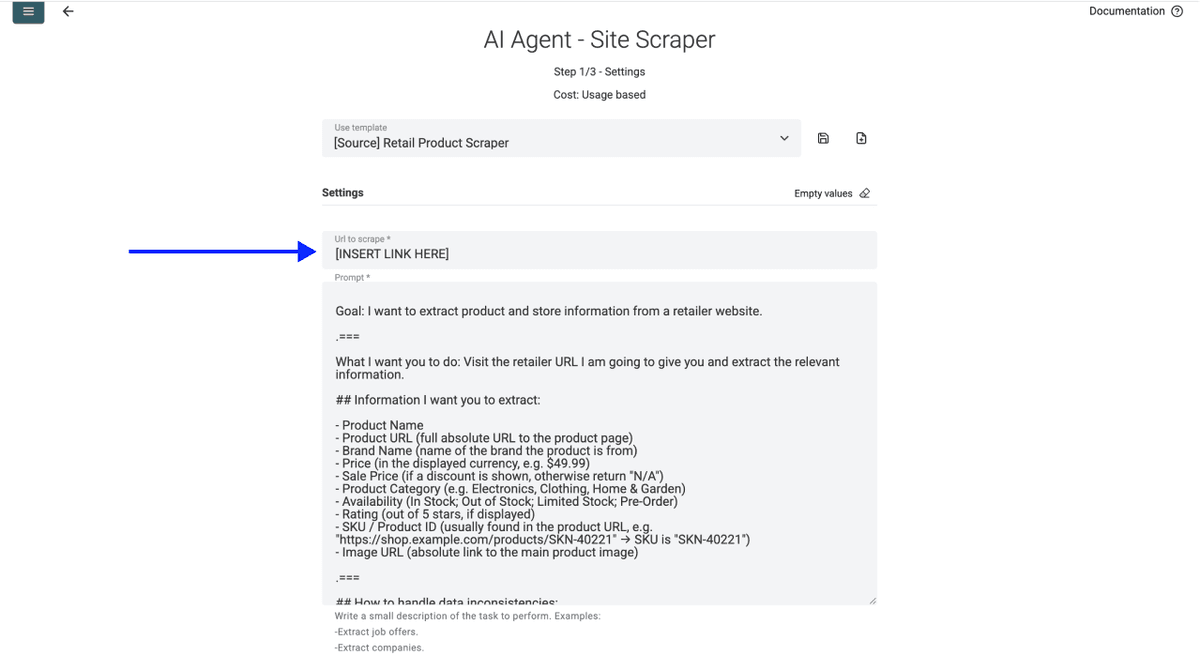
- Sélectionnez le nombre de pages que vous souhaitez scraper
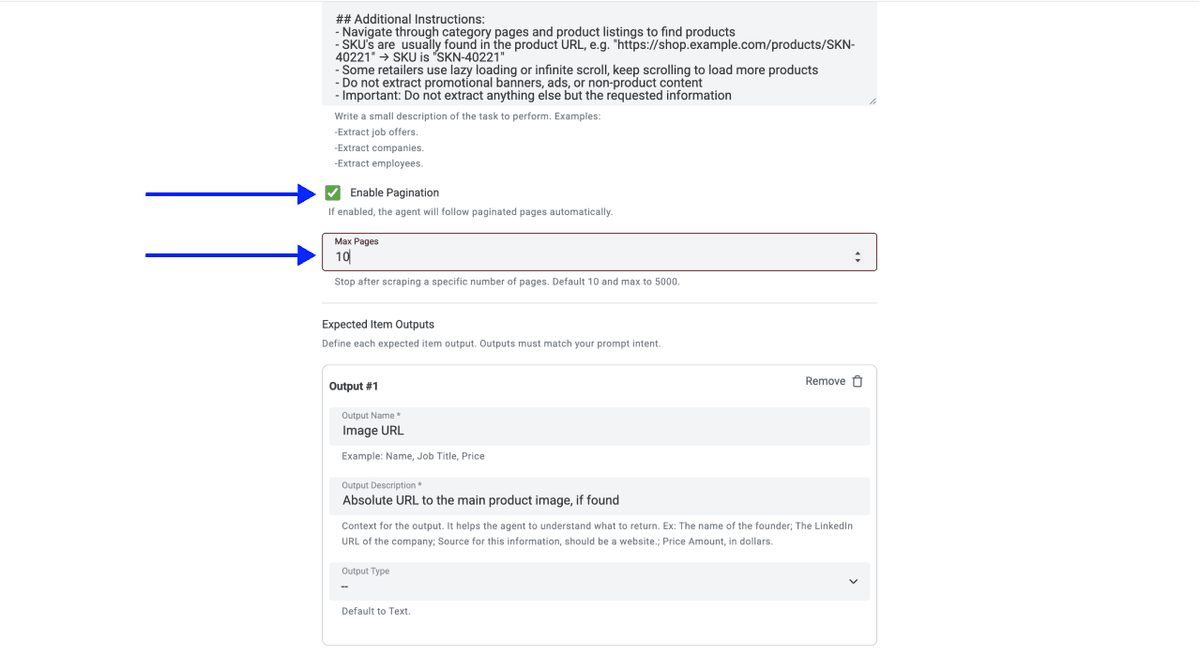
📘 À propos de la pagination sur les sites de retailers
La plupart des sites de retailers affichent entre 20 et 50 produits par page. Si une catégorie contient 500 produits, il faudra donc scraper 10 à 25 pages. L’AI Scraping Agent de Datablist gère la pagination automatiquement et peut traiter jusqu’à 5 000 pages sur une seule exécution.
Si le sujet de l’AI scraping vous intéresse, nous avons aussi publié un article sur les règles pour rédiger de bons prompts pour les AI agents 👈🏽
- Descendez puis cliquez sur Continue
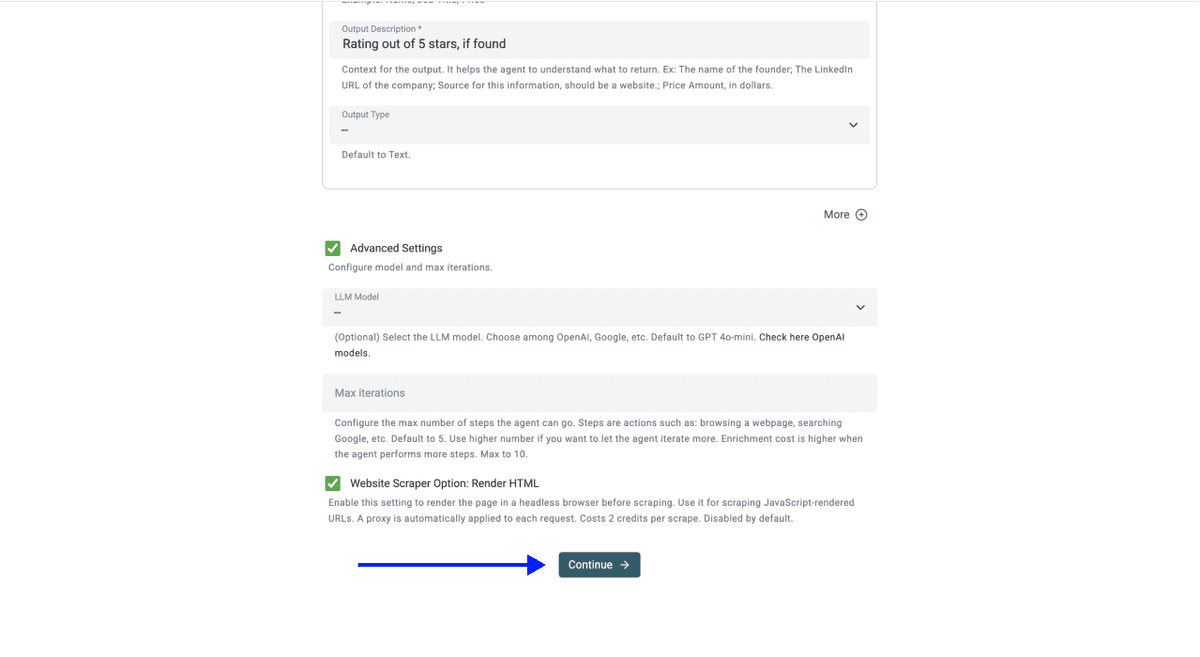
💡 Vérifiez les paramètres avancés avant de cliquer sur Continue
Assurez-vous que les réglages suivants sont activés :
- LLM: OpenAI: GPT 4.1 mini (meilleur rapport performance/prix)
- Max iterations: 10
- Website Scraper Option: Render HTML (c’est essentiel pour scraper des sites de retailers, car la plupart chargent les produits dynamiquement via JavaScript)
Étape 4 : sélectionner les outputs
Datablist créera automatiquement les propriétés de sortie.
Cliquez sur les icônes X pour supprimer les outputs que vous ne souhaitez pas conserver dans votre collection.
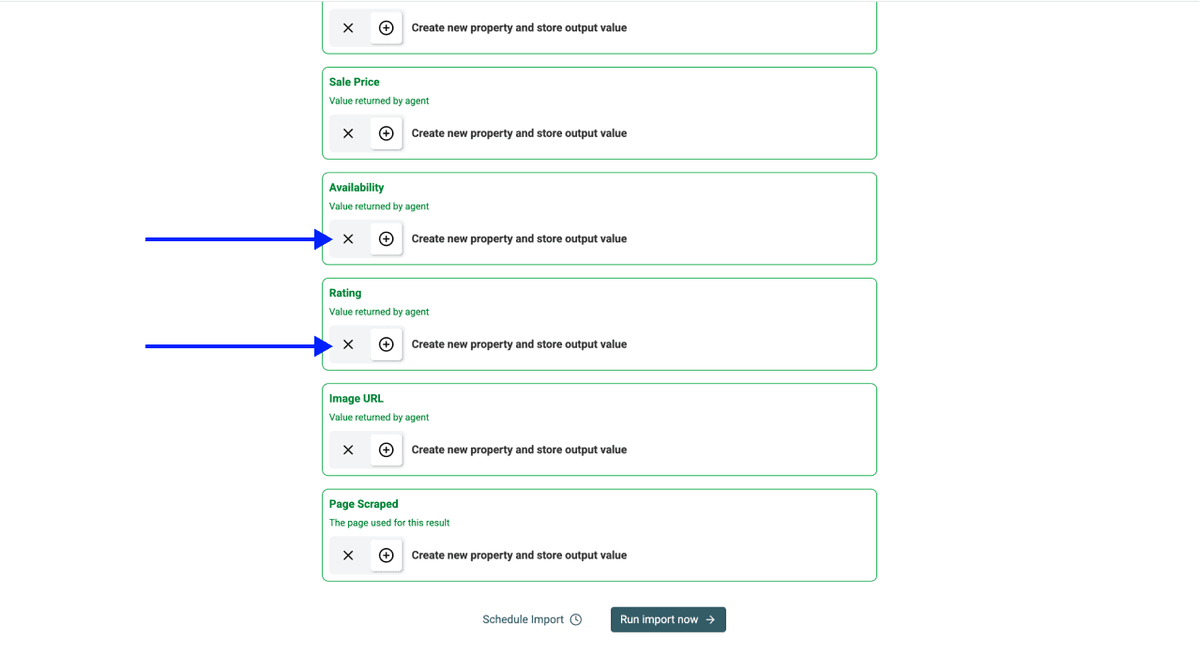
Étape 5 : lancer le scraping
Une fois tout cela en place, cliquez sur Run Import Now pour démarrer le scraping.
Après quelques minutes, vos résultats ressembleront à ceci. À partir de là, vous pouvez utiliser les fonctionnalités d’automatisation de workflow de Datablist pour nettoyer, enrichir et exporter les données.
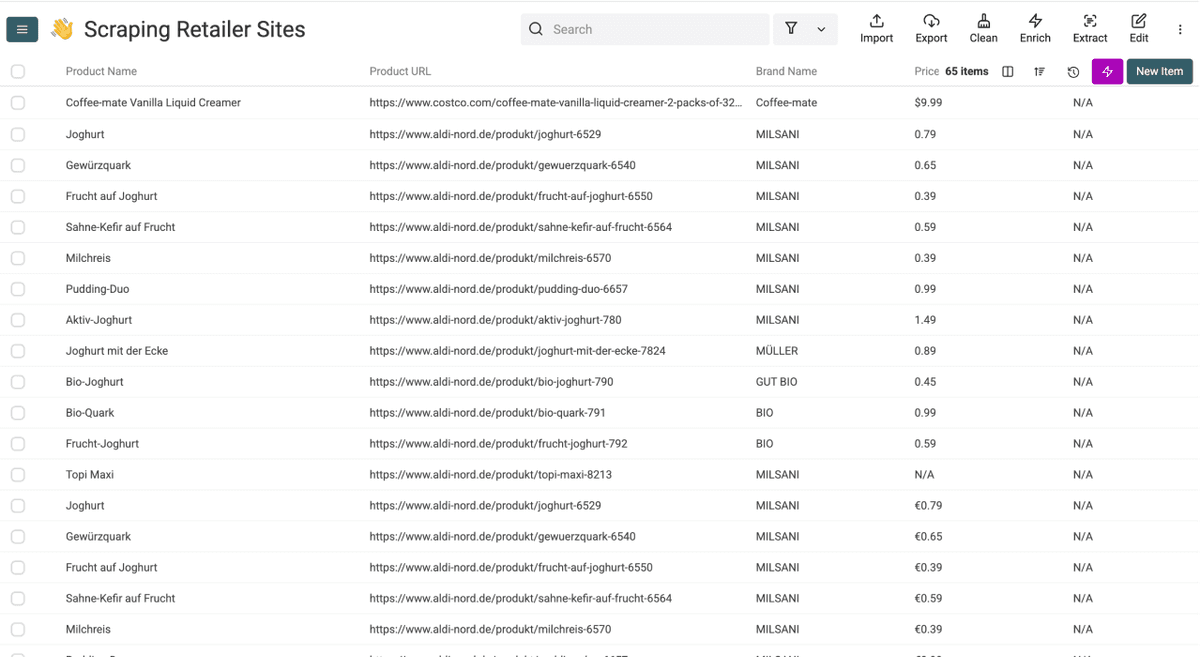
💡 Évitez les doublons lors des exécutions répétées
Si vous prévoyez de scraper à nouveau le même retailer plus tard (suivi de prix, suivi de stock, etc.) :
- Choisissez une colonne avec un identifiant unique (l’URL produit est généralement le meilleur choix)
- Cliquez sur l’en-tête de colonne et sélectionnez : Rename - Settings - Delete
- Cochez : Do not allow duplicate values
- Cliquez sur : Save Property
Ainsi, à chaque nouvelle exécution, le scraper n’ajoutera que les nouveaux produits au lieu de dupliquer ceux qui existent déjà. Combiné aux fonctionnalités d’automatisation de workflow de Datablist, vous pouvez planifier des exécutions régulières sans rien faire manuellement.
Et si vous scrapez plusieurs retailers dans un même fichier, nous avons aussi publié un guide sur la suppression des doublons dans un fichier CSV 👈🏽
À retenir
Voici l’essentiel à garder en tête la prochaine fois que vous devrez scraper un site de retailer :
- Les scrapers sur mesure sont un gouffre financier dans le retail. Structures de sites différentes, cassures à chaque changement de layout, absence d’automatisation native : l’investissement n’en vaut généralement pas la peine.
- L’AI scraping comprend le sens, pas le HTML. C’est pour cela qu’il fonctionne sur Tesco, Aldi, Morrisons et d’autres retailers sans configuration spécifique au site.
- Le processus complet prend moins de 10 minutes. URL, prompt, outputs, lancement. C’est tout.
- Tous les retailers ne sont pas scrapables. Walmart, Costco et Edeka disposent de protections anti-bot solides. Il faut donc rester réaliste sur ce qui est faisable.
FAQ sur le scraping de sites de retailers
Combien coûte le scraping d’un site de retailer ?
L’AI Agent de Datablist.com fonctionne avec un système de crédits basé sur l’usage. Le coût par page retailer dépend du volume de données extrait par l’agent et du nombre d’itérations nécessaires. Les offres Datablist démarrent à 25 $/mois avec 5 000 crédits inclus. Si vous avez besoin de plus, des packs de recharge commencent à 20 $ pour 20 000 crédits, avec des remises pouvant aller jusqu’à 35 % sur les plus gros volumes.
Combien de temps faut-il pour scraper les produits d’un site de retailer ?
La plupart des pages catégories de retailers contenant 50 à 200 produits sont scrapées en 5 à 10 minutes. Les extractions plus volumineuses avec pagination activée (500+ produits sur plusieurs pages) peuvent prendre 10 à 20 minutes. La configuration initiale prend encore 3 à 5 minutes lors du premier essai, puis seulement quelques secondes pour les exécutions suivantes sur le même retailer.
Y a-t-il une limite au nombre de produits que je peux scraper ?
Datablist.com prend en charge jusqu’à 100 000 lignes par collection et l’AI Agent peut scraper jusqu’à 5 000 pages en une seule exécution. Pour la plupart des sites de retailers, c’est largement suffisant pour récupérer un catalogue complet.
Faut-il savoir coder pour scraper des sites de retailers ?
Pas du tout. Avec Datablist.com, tout le processus est no-code. Vous collez une URL, vous rédigez un prompt décrivant les produits à extraire du site du retailer, vous choisissez vos outputs, puis vous lancez l’exécution. Si vous savez écrire, vous savez scraper un site de retailer avec Datablist.com.
L’IA peut-elle scraper n’importe quel site de retailer ?
La plupart des sites de retailers fonctionnent bien avec l’AI scraping, notamment les chaînes de supermarchés et les enseignes régionales. En revanche, certains grands retailers comme Walmart, Costco et Edeka disposent de protections anti-bot avancées qui empêchent une extraction automatisée fiable. Nous recommandons de commencer par un petit test pour vérifier que le retailer ciblé est bien compatible.
Quelle est la différence entre l’AI scraping et le web scraping traditionnel ?
Les scrapers traditionnels reposent sur des règles fixes comme des éléments HTML, des classes CSS ou des sélecteurs XPath. Dès qu’un site change sa structure, le scraper casse. L’AI scraping fonctionne différemment. Il lit la page comme un humain et peut déduire qu’un nombre placé à côté d’un nom de produit correspond probablement à un prix, même si le HTML change. C’est ce qui rend les scrapers IA plus robustes et plus faciles à utiliser sur différents sites sans configuration sur mesure.
Peut-on scraper des sites de retailers qui bloquent les bots ?
Cela dépend du niveau de protection. Certains sites de retailers utilisent une détection basique que l’option Render HTML de Datablist peut gérer. D’autres, comme Walmart et Costco, utilisent des systèmes anti-bot avancés qui bloquent la majorité des accès automatisés. Si vous avez un doute, lancez d’abord un test sur 10 produits pour vérifier si notre agent peut scraper ce site.
L’IA peut-elle scraper un site web ?
Oui. Les outils de scraping basés sur l’IA, comme l’AI Scraping Agent de Datablist, peuvent visiter une page web, lire son contenu et extraire des données structurées à partir d’instructions en langage naturel. L’IA gère automatiquement le rendu JavaScript, la pagination et les variations de structure des pages.
Quelle est la méthode la plus rapide pour scraper un site web ?
Pour scraper des sites de retailers en particulier, la méthode no-code la plus rapide est l’AI scraping. Vous fournissez l’URL, décrivez en anglais simple les données souhaitées, et l’agent les extrait automatiquement. Avec Datablist.com, l’ensemble du processus, de la configuration aux résultats, prend moins de 10 minutes.
Qu’est-ce que l’AI scraping ?
L’AI scraping est une méthode d’extraction de données depuis des sites web qui s’appuie sur l’intelligence artificielle plutôt que sur des scrapers traditionnels basés sur des règles. Au lieu de dépendre de sélecteurs HTML fixes, l’AI scraping utilise des modèles de langage pour comprendre le contenu d’une page et en extraire les informations demandées. Cette approche est plus souple, plus simple à utiliser et plus résistante aux changements de site. Des plateformes comme Datablist proposent cette approche via leurs AI Scraping Agents.
Quels sont les plus grands retailers du monde ?
Les plus grands retailers mondiaux par chiffre d’affaires sont :
- 🇺🇸 Walmart - 648 Md$
- 🇺🇸 Amazon - 620 Md$
- 🇺🇸 Costco - 254 Md$
- 🇩🇪 Schwarz Group (Lidl + Kaufland) - 175,4 Md€
- 🇺🇸 Home Depot - 157,6 Md$
- 🇺🇸 Kroger - 150,8 Md$
- 🇩🇪 Aldi (Nord + Süd) - 112 Md€
- 🇫🇷 Carrefour - 94,1 Md€
- 🇬🇧 Tesco - 63,6 Md£
- 🇪🇸 Mercadona - 38,8 Md€
Quels sont les plus grands retailers en Europe ?
Les plus grands retailers européens varient selon les pays. Voici quelques acteurs majeurs par chiffre d’affaires :
- 🇩🇪 Allemagne : Schwarz Group/175,4 Md€, Aldi/~117,6 Md€, REWE Group/96,0 Md€, Edeka/75,3 Md€, Netto Marken-Discount/17,6 Md€
- 🇬🇧 Royaume-Uni : Tesco/63,6 Md£, Sainsbury's/33,3 Md£, Asda/21,7 Md£, Morrisons/15,8 Md£
- 🇫🇷 France : Carrefour/94,1 Md€ (monde), E.Leclerc/50 Md€+, Auchan/32,3 Md€, Système U/25,9 Md€
- 🇪🇸 Espagne : Mercadona/38,8 Md€, Carrefour Espagne/11,7 Md€
Sources
[1] Ajoutez ici les sources après relecture finale. Référencez les pages produits, la documentation tarifaire et les éventuelles sources externes utilisées lors de la recherche.
[2] Tarifs Datablist.com : formule Growth à 50 $/mois avec 20 000 crédits. Packs de recharge à partir de 20 $ pour 20 000 crédits. Détails complets sur datablist.com/pricing