
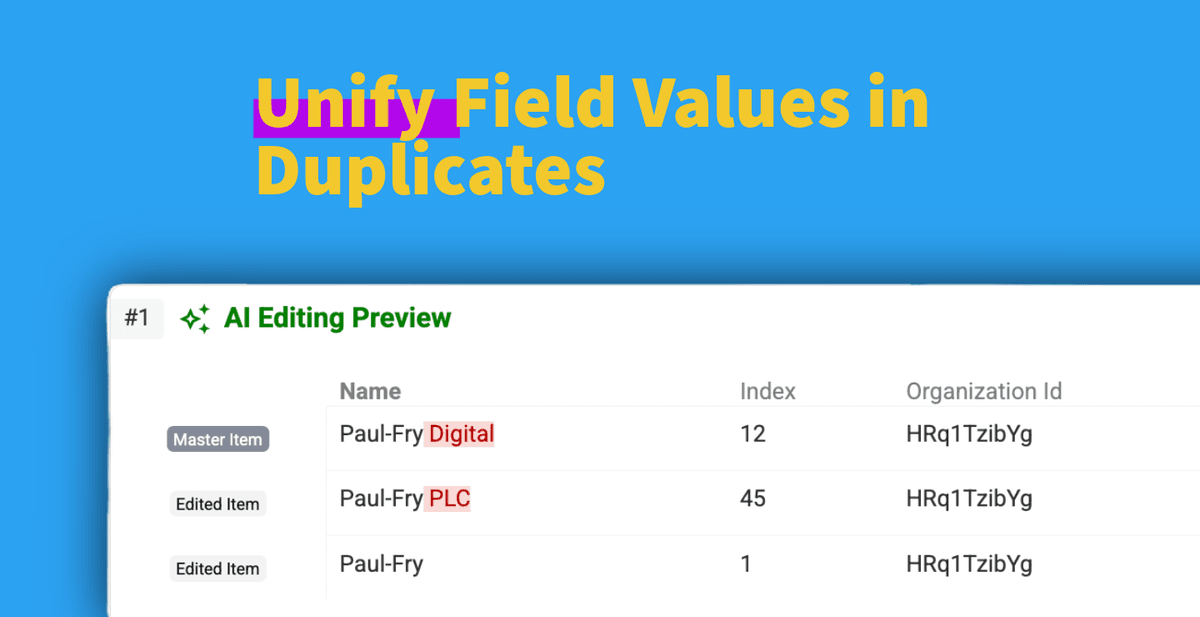
处理数据集里的重复记录,几乎是所有做数据的人都会遇到的“老大难”。找到重复只是第一步,真正麻烦的是后续怎么清理。
有时候,你并不想立刻把重复记录彻底 merge。
比如同一家公司可能在不同重复记录里出现了略有差异的名字(“Innovate Corp”“Innovate Corporation”“Innovate Corp.”)。
如果你能在不 merge 记录的前提下,把某个字段(比如公司名或职位)在同一个重复组里统一成一个标准值,会怎么样?
这篇指南会带你学会:如何在保留每条记录不动的情况下,对重复组内某个字段做 normalization(标准化/统一格式):
什么是数据标准化(Data Normalization)?
这里说的 data normalization,指的是把数据统一到一致的格式。处理 duplicates 时,往往是某些字段出现不一致,比如:
- 公司名(Company Names): "Tech Solutions Inc.", "Tech Solutions, LLC", "Tech Solutions"
- 职位(Job Titles): "Software Engineer", "Software Dev.", "Eng., Software"
- 地址(Addresses): "123 Main St", "123 Main Street", "123 main st"
- 国家(Countries): "USA", "United States", "U.S.A."
Normalization 的目标,是为某个字段选出一个标准值(例如 "Tech Solutions" 或 "United States"),并把它应用到所有被识别为同一组 duplicates 的记录上。
这样一来,即使重复记录仍然分开存在,你的数据也会更干净、更好分析,做筛选或报表也更可靠。这是 data cleaning 里非常关键的一步。
Duplicates Finder 里的 AI Processing 介绍
Datablist 的 Duplicates Finder 本身就很擅长识别相似记录。它不仅支持强大的 自动或手动 merge duplicates 方案,AI Processing 模式还提供了更灵活的一层能力。
和预设 merge 规则不同,AI Processing 允许你用自然语言 prompt 来定义逻辑。你可以直接告诉 AI:这些 duplicates 应该怎么处理。它可以做的事情包括:
- 按特定条件选择 master record(例如:最近更新的一条)。
- 只 merge 某些字段,同时保留其他字段不动。
- merge 过程中做计算(比如 对重复值求和)。
- 👉 也是本篇的重点:不 merge 记录,只把某个字段在所有 duplicates 内统一成一个标准值。
它把原本需要写脚本才能完成的数据处理,变成你和 AI 的一次对话。
如何在重复记录间做字段标准化(步骤详解)
下面我们一步步演示:如何用 AI Processing 把某个字段(例如 Company Name)在重复记录组内统一。
Step 1: 准备数据
首先,你需要把数据放进 Datablist。
- 创建 Collection: 点击侧边栏的“+”按钮,新建一个 collection。
- 导入数据: 从 CSV 或 Excel 文件 导入数据。如果你的数据来自多个文件,把它们导入到同一个 collection。Datablist 会引导你把列映射到属性(properties)。请确认你要标准化的字段(如 Company Name)以及用来识别 duplicates 的字段(如 Email、Website)都正确导入。

在这个示例数据里,我们已经能看到一些重复的公司名,需要做标准化处理。
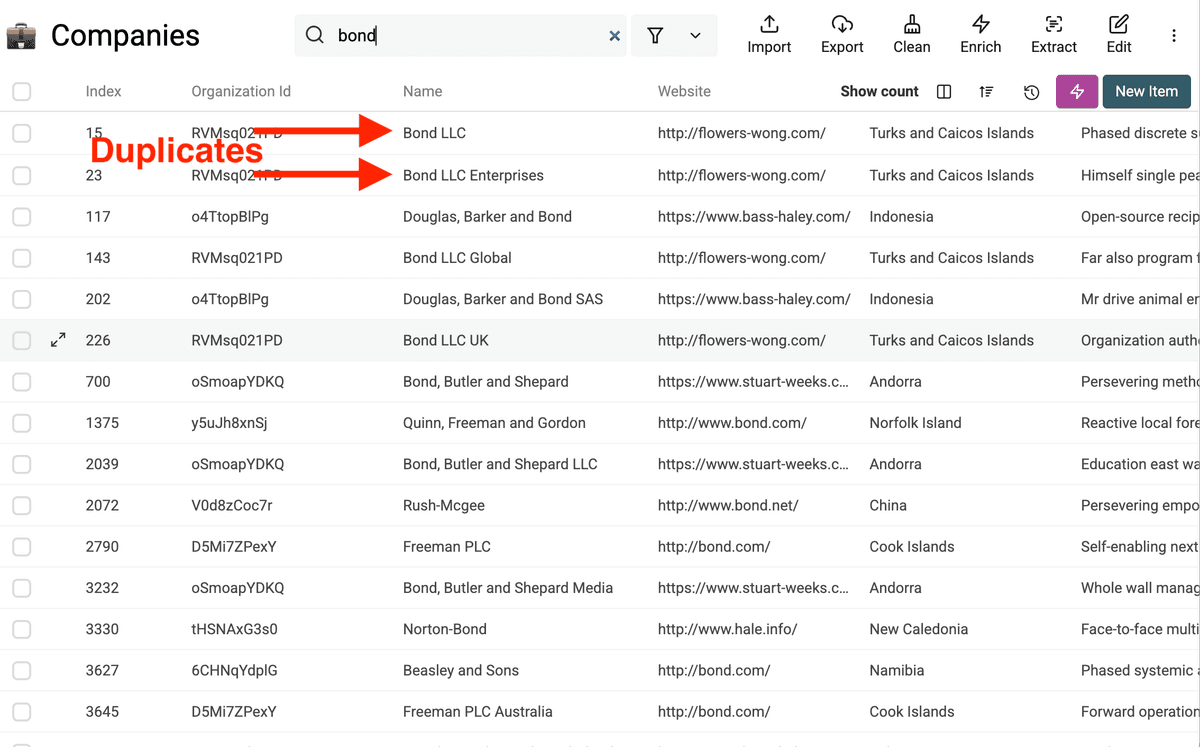
Step 2: 查找重复记录
接下来,识别重复记录。
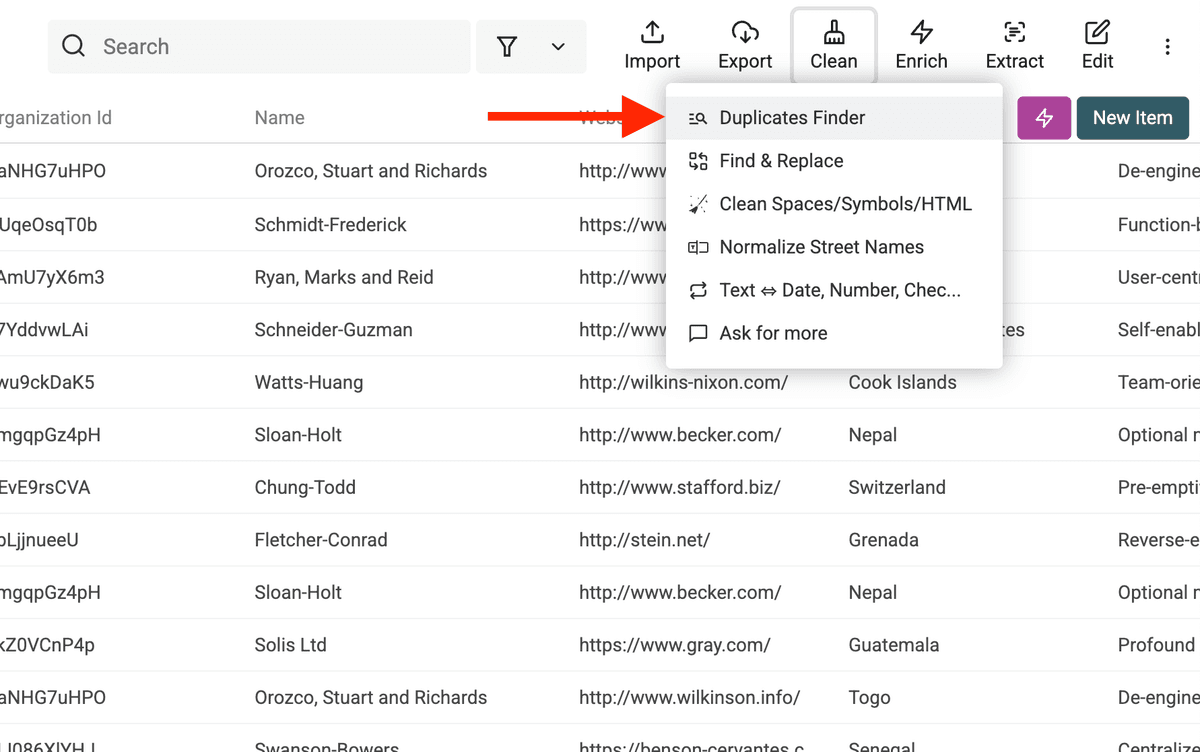
2.a. 打开 Duplicates Finder
点击顶部菜单里的 “Clean”,然后选择 “Duplicates Finder”。
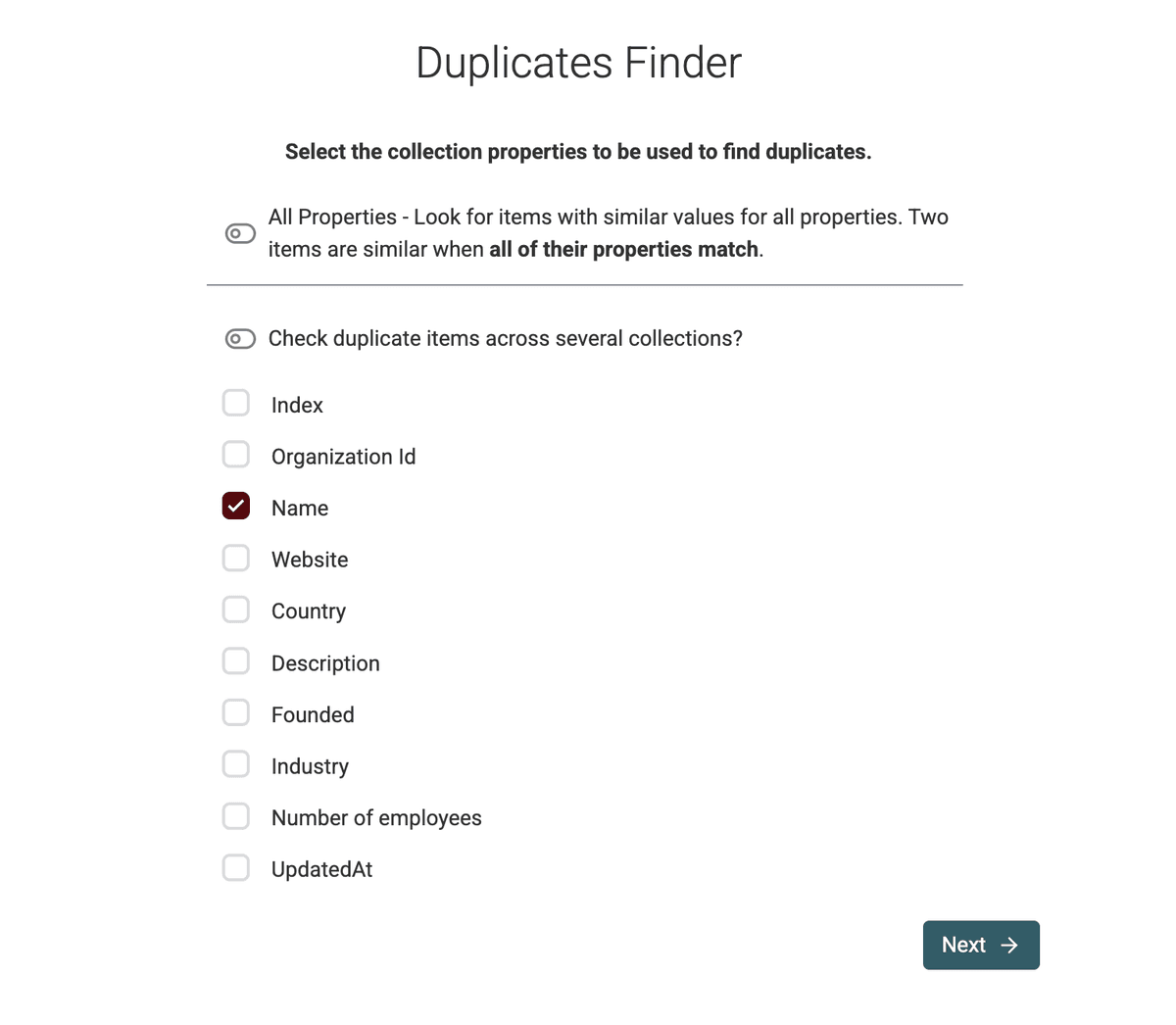
2.b 选择去重标识字段(Deduplication Identifier)
选择一个(或多个)能唯一识别 duplicates 的属性。
在我们的例子里,我们想 dedupe company names,所以选择 name 字段。
对公司来说,你也可以用
Website URL或LinkedIn Company Page URL。对联系人(contacts)来说,常见选择是
Phone Number。
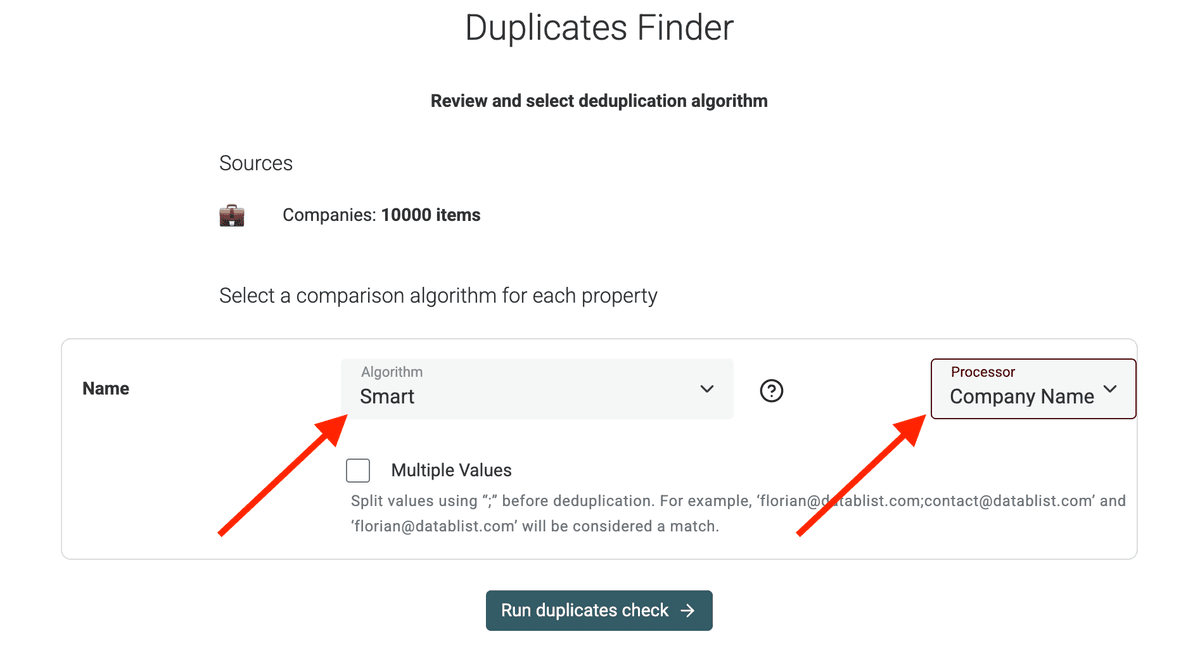
2.c 配置算法
下一步,选择匹配算法(matching algorithm)。
' Smart ' 通常适用于 URL 或 email,能处理一些细微差异;' Exact ' 更严格。对于名字类字段,你也可以用 phonetic 或 fuzzy matching。
同时选择适合你数据的 Processor。
这里我选择 Company Name processor,用来处理常见的 公司名差异(公司后缀、地理词等)。
2.c 运行检查
点击 “Run duplicates check”。
Datablist 会分析你的数据,并展示可能的重复组。
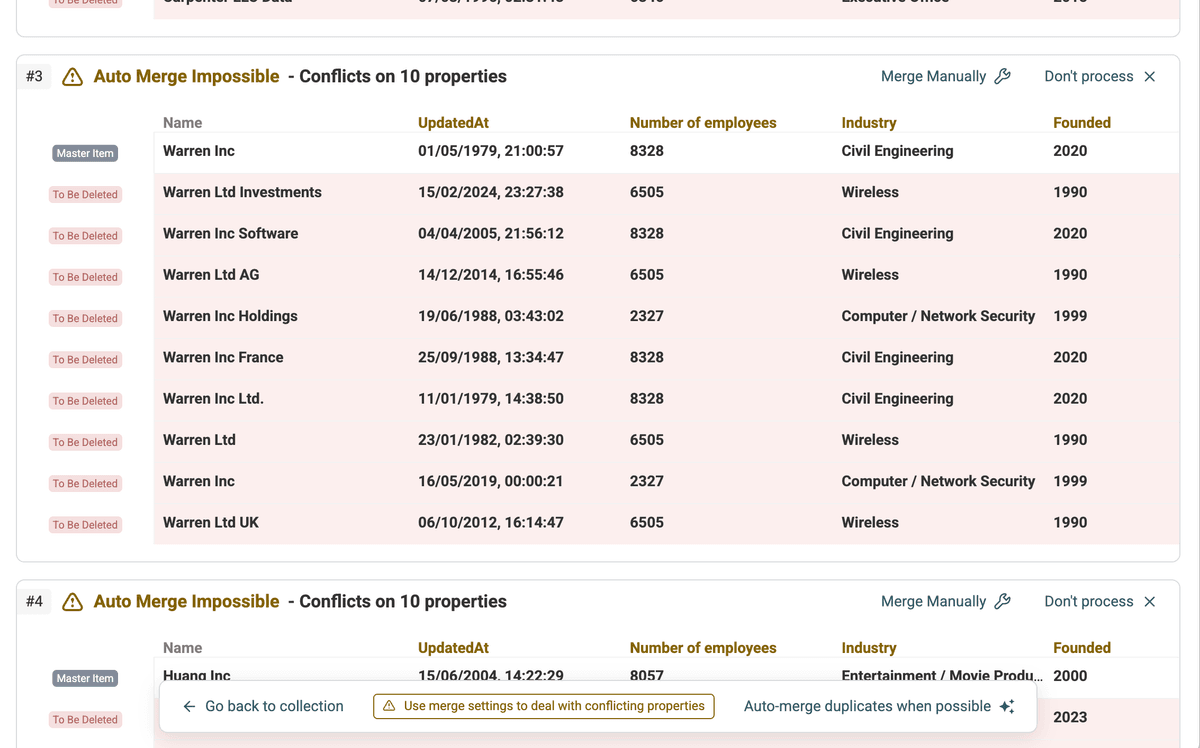
Step 3: 选择 AI Processing 模式
不要用标准的 “Auto Merge” 或手动 merge,而是在结果页点击 AI Editing 按钮,进入 AI 驱动的处理模式。
Step 4: 编写标准化 Prompt
这一步是关键:告诉 AI 你希望它怎么做。你需要让它:
- 在每个 duplicate group 内找出目标字段的“最常见值”。
- 把该组里的所有记录都更新为这个常见值。
- 明确说明不要删除任何记录。
下面是一个用来标准化 /Company Name 的 prompt 示例:
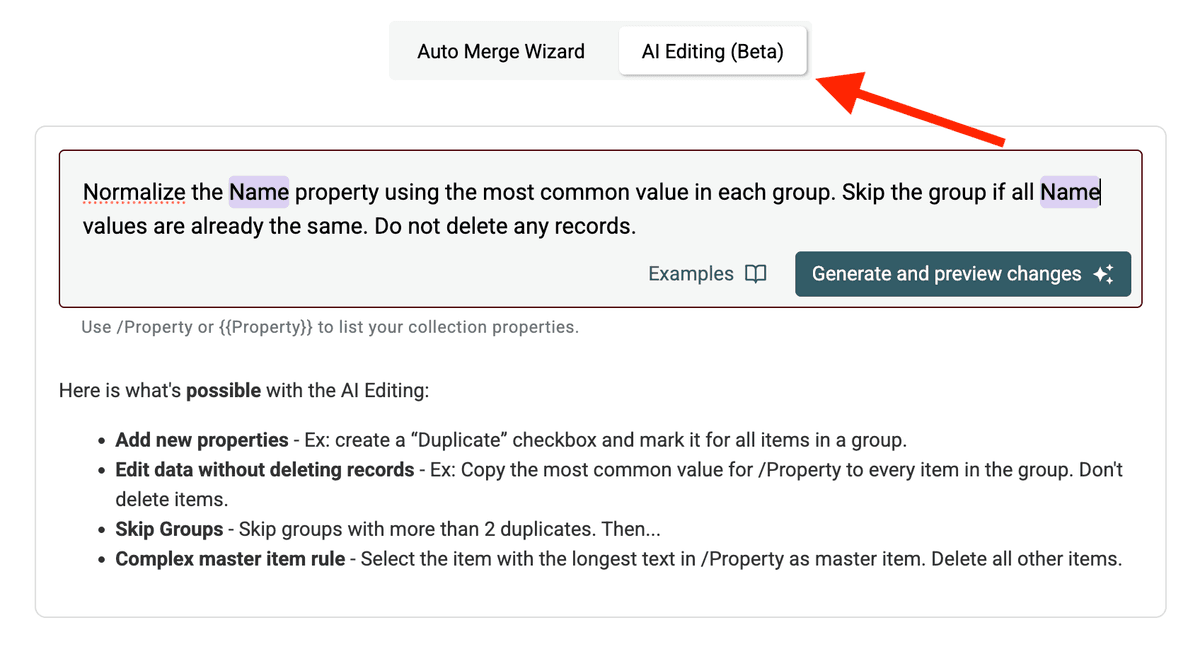
拆解一下这个 prompt:
Normalize the /CompanyName property...:指定目标字段。你可以用/PropertyName或{{PropertyName}}引用列。...using the most common value in each group.:定义选“标准值”的规则。你也可以换成其他标准,比如 “longest value”“shortest value”,或引用另一列(例如:“使用 /UpdatedAt 最新那条记录里的值”)。Skip the group if all /CompanyName values are already the same.:提升效率,已经一致的组就跳过。Do not delete any records.:非常重要,确保只是更新字段,不会 merge 或移除记录。
Step 5: 生成并预览脚本
点击 Generate and preview changes。Datablist 的 AI 会理解你的 prompt,并生成一个执行动作的脚本。
不用担心,你不需要写或修改任何脚本。
- Script Explanation: 用通俗语言解释脚本会做什么,确认它和你的意图一致。
- Result Preview: 预览表格会展示脚本将如何修改一部分 duplicate groups(在真正执行之前)。重点检查预览里的目标字段(例如
/Company Name)是否在样本 duplicates 中被统一成了你预期的标准值。
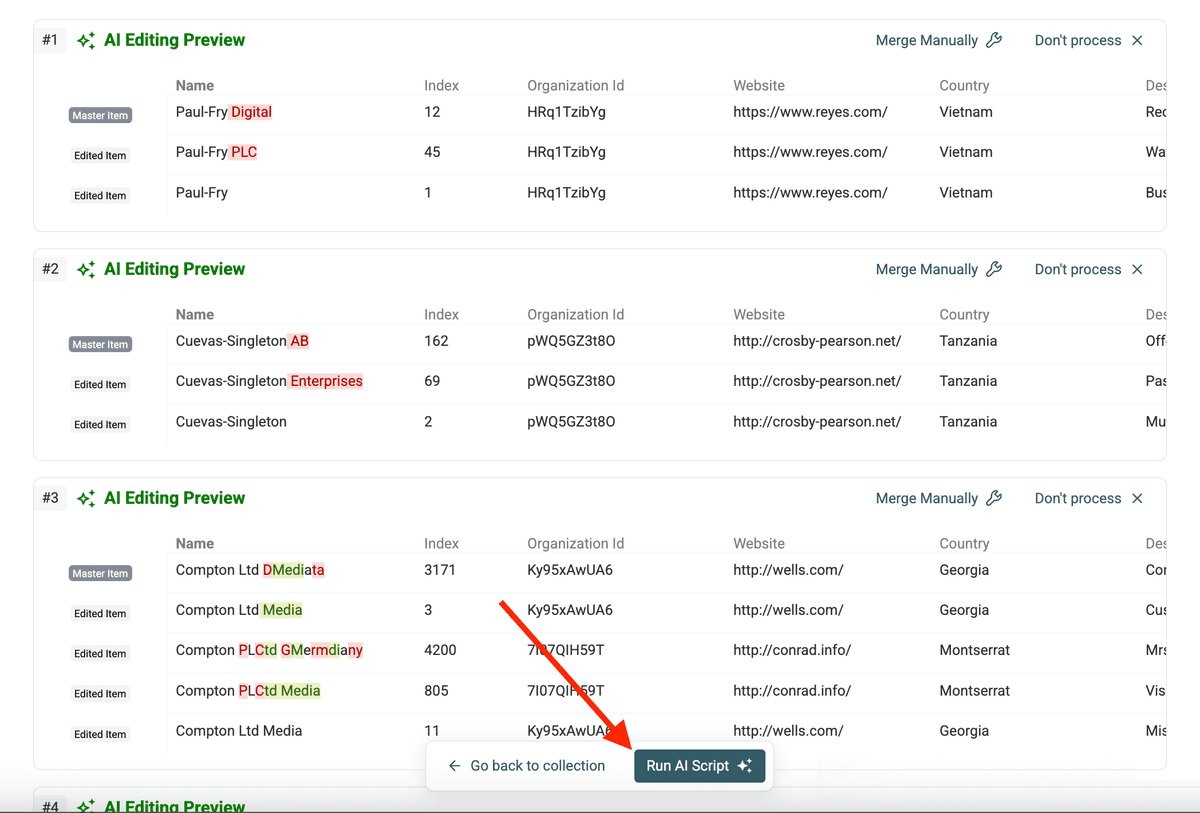
Step 6: 运行脚本
如果解释和预览都没问题,点击 Run AI Script。Datablist 会对所有识别到的 duplicate groups 执行该脚本。
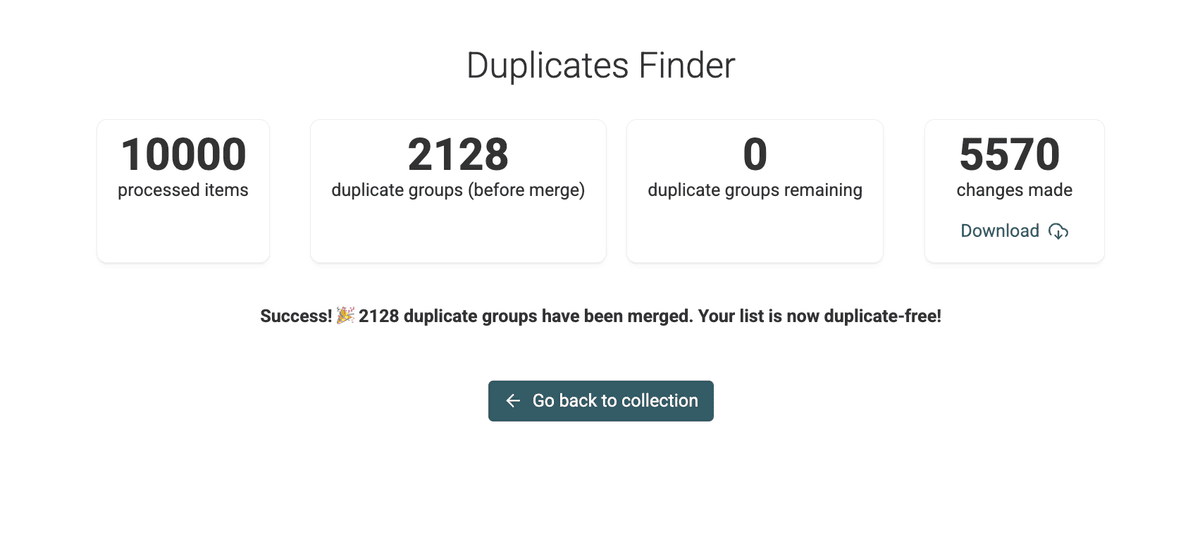
Step 7: 检查修改结果
脚本运行完成后,Datablist 会给出汇总,并提供可下载的 Changes List。
当你需要把这些修改同步/重放到外部系统时(比如去 批量编辑 CRM leads 等),这个列表会非常好用。
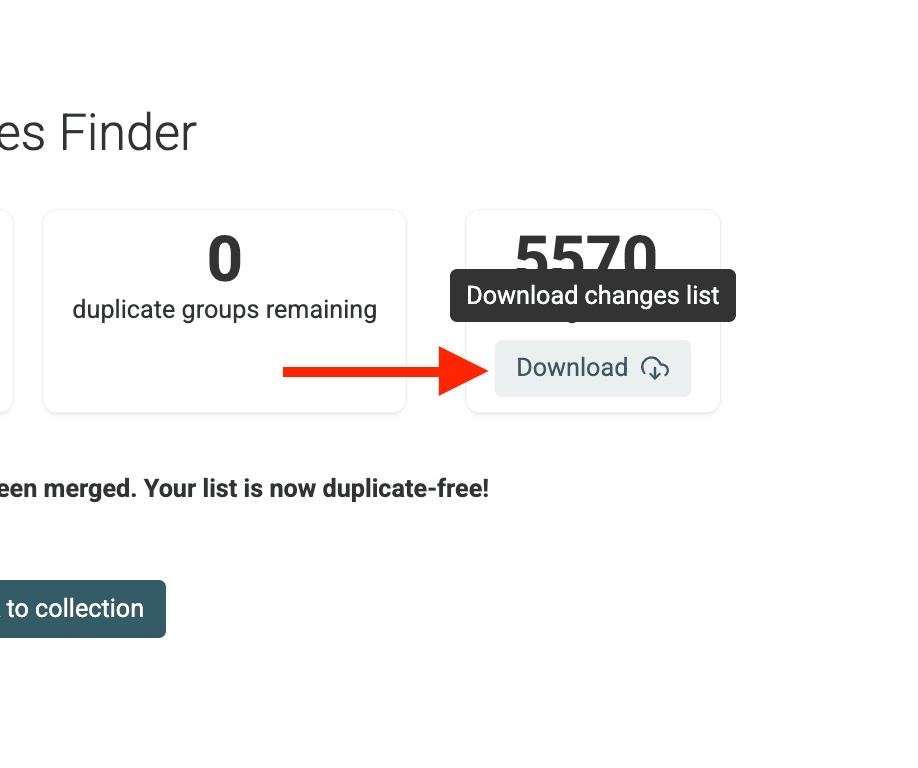
回到 collection 主视图,你会看到目标字段(例如 /CompanyName)已经在每个 duplicate group 内保持一致,而记录本身仍然是分开的。
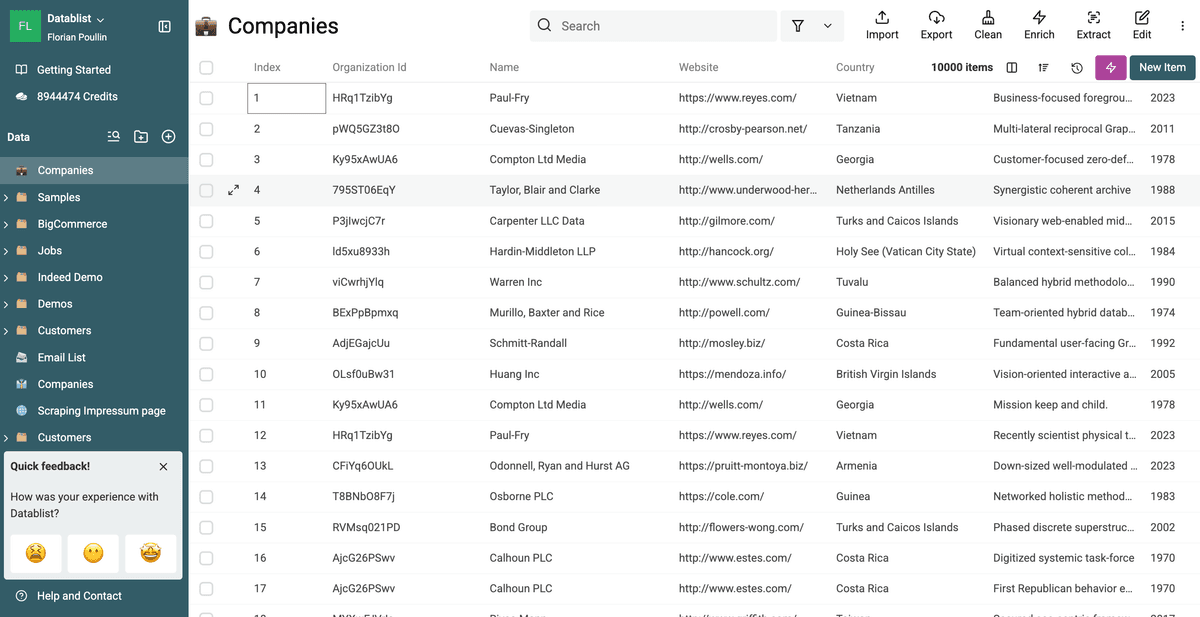
你已经成功在不 merge 的情况下,完成了 duplicates 内字段标准化! 🚀
不 merge 也做标准化的典型场景
什么时候你会选择“只标准化字段”,而不是直接 full merge?
- 统一公司名或联系人姓名: 在决定最终 merge 策略前,先清理类似 “Example Ltd”“Example Limited”,或 “Jon Doe”“Jonathan Doe” 这类命名差异。
- 清洗职位字段: 把 “VP Marketing”“Vice President Marketing”“Marketing VP” 统一成一个写法,便于统计与分析。
- 标准化地理位置: 统一国家名(“UK”“United Kingdom”)或州/省缩写(“CA”“California”),避免地址字段口径不一致。
- 为 CRM 导入/更新做准备: 先把关键字段统一,再导入到校验严格的 CRM;duplicates 可以暂时保留。
- 数据审计(Audit): 需要保留原始重复记录用于审计或历史追踪,但又希望关键标识字段一致,便于分析。
- 渐进式清洗: 把它作为更大 data cleaning workflow 的一环,一次先统一一个字段,之后再决定是否 merge 或删除。
为什么先标准化,而不是直接 merge?
- 保留记录粒度: 不破坏每条重复记录,适合需要追踪来源、互动记录或历史状态的场景。
- 应对不确定性: duplicates 未必是完美匹配。先统一关键字段,先让数据口径一致,但不强行把其他可能不一致的数据点 merge 在一起。
- 分阶段推进: 标准化先行,后面再 review 决定 merge 或 delete,会更可控。
- 更简单聚焦: 只对一个字段下手,不影响其他字段,风险更低、执行更快。
总结
Datablist 的 Duplicates Finder 里,AI Processing 提供了一种非常灵活且强力的 duplicates 管理方式:你可以在不 merge 记录的情况下,把重复组内的某些字段统一成标准值。这一步在很多数据清洗流程里都属于关键“中间层”。通过简单的自然语言 prompt,你就能快速实现一致性,省下大量人工对齐的时间,同时降低误操作风险。无论你要统一公司名、职位还是地理位置,这个能力都能让你更可控地提升数据质量。
FAQ
-
AI Processing 是否包含在我的 Datablist 套餐里? AI Processing(包括生成并运行用于标准化的脚本)在 Datablist 的付费套餐中提供。具体请查看我们的 Pricing Page。
-
能否用一个 prompt 同时标准化多个字段? 可以。你可以在同一个 prompt 里同时要求标准化多个字段。例如:"Normalize the /Company Name property using the most common value in each group. Normalize the /Country property using the most common value in each group. Do not delete any records."
-
如果 AI 误解了我的 prompt 怎么办? 在运行脚本之前,一定要仔细查看 script explanation 和 preview 结果。如果预览不符合预期,就把 prompt 写得更清晰、更具体,然后重新生成脚本。
-
我能撤销 AI 脚本带来的修改吗? 脚本一旦运行,修改会直接写入数据。Datablist 提供 undo 功能,可撤销当前 session 内的近期操作;但最佳实践仍然是:在做这种较大规模的数据变换之前,先 clone 一份 collection,以便需要时回滚。
-
这和标准 merge 里的 “Combine conflicting properties” 有什么不同? 标准 “Combine” 会把 duplicates merge 成一条 master record,并把冲突的文本值拼接到同一个字段里。AI Processing 在写对 prompt 的前提下,是把某个字段在所有重复记录里统一更新为一个选定值,并且保留所有记录分开存在。除非你在 prompt 里明确要求,否则它不会 merge 记录,也不会把值拼接起来。