

Pipedrive ist super, um Leads und Sales zu managen. Aber wie in jedem CRM sammeln sich mit der Zeit doppelte Kontakte und Organizations an.
Das integrierte Pipedrive-Tool zum Duplikate-Mergen hat ein paar echte Schwachstellen (alle Pipedrive Merge Duplicate Limitations):
- Es erkennt nur exakte Treffer über Personen-/Organizations-Namen – kein Abgleich von Firmennamen mit Rechtsformen (Google LLC == Google), kein fuzzy matching und keine Deduplication über Website, E-Mail-Adresse etc.
- Es erlaubt kein Bulk Merge von Duplikaten.
Wenn Du in Pipedrive mit doppelten People oder Organizations kämpfst, brauchst Du eine bessere Lösung.
Genau hier kommt Datablist Duplicates Finder ins Spiel, um Deine Pipedrive-Daten sauber zu dedupen. In diesem Guide zeige ich Dir Schritt für Schritt, wie das geht:
- Importiere Deine Pipedrive People und/oder Organizations in Datablist
- Finde und merge Duplikate mit smarten Algorithmen
- Synce die Merges als Bulk zurück nach Pipedrive
- Limits der Pipedrive-eigenen Duplikat-Merge-Funktion
Schritt 1: Importiere Deine Pipedrive Kontakte
Der erste Schritt, um Pipedrive-Duplikate aufzuräumen: Importiere Deine Daten in Datablist. So kannst Du Deduplication-Tools nutzen, die Pipedrive so nicht anbietet. So importierst Du Kontakte und Organizations:
1. Erstelle eine neue Datablist Collection
Eine Collection in Datablist ist wie ein Spreadsheet, in dem Du Deine Daten speicherst und bereinigst. Jede Collection enthält entweder Deine Pipedrive-Kontakte (People) oder Deine Firmen (Organizations).
- Wenn Du People dedupen willst, erstelle eine Collection für People.
- Wenn Du Organizations dedupen willst, erstelle eine Collection für Organizations.
- Wenn Du beides bereinigen willst, erstelle zwei getrennte Collections: eine für People und eine für Organizations.
2. Wähle „Source → Pipedrive“
Datablist verbindet sich über die API direkt mit Deinem Pipedrive-Account.
In Deiner Datablist Collection gehst Du auf Import → Source auswählen → Pipedrive wählen. Oder direkt über den Link „See all sources“ auf dem Startscreen der Collection.
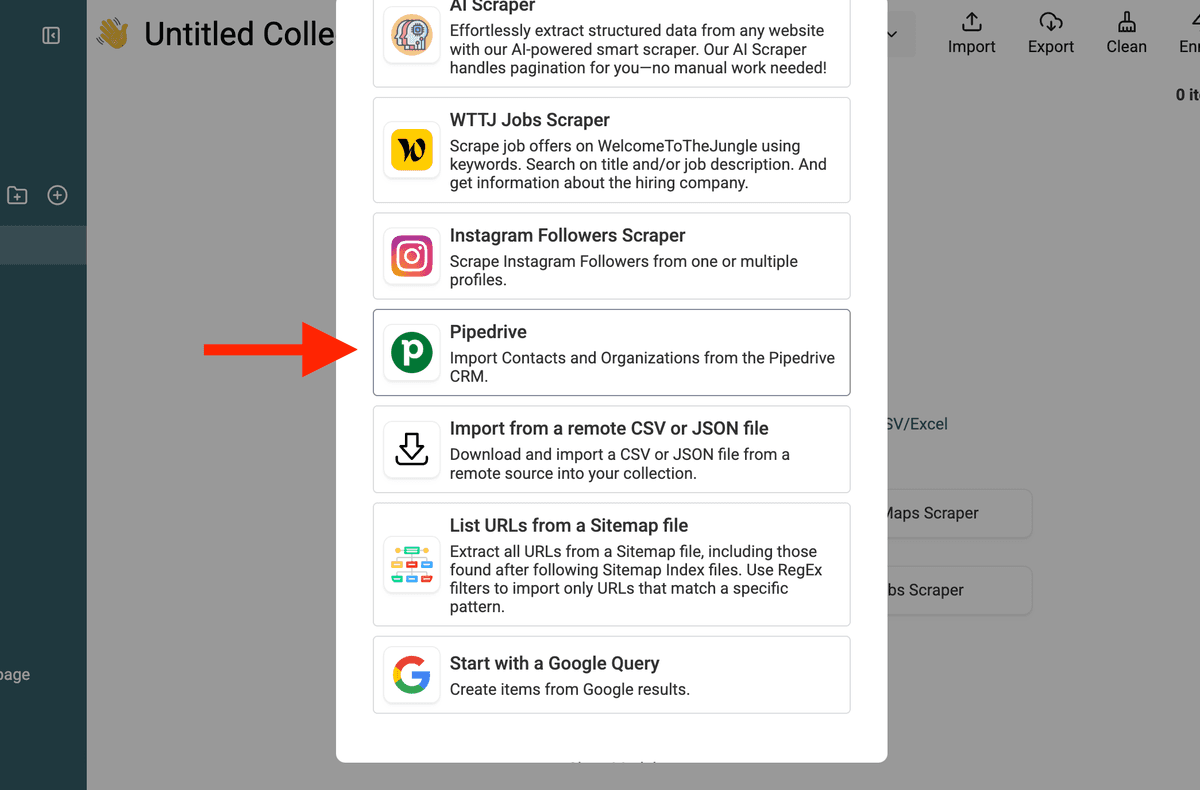
3. Finde Deinen Pipedrive API Key
Du wirst aufgefordert, Deinen Pipedrive API key einzugeben.
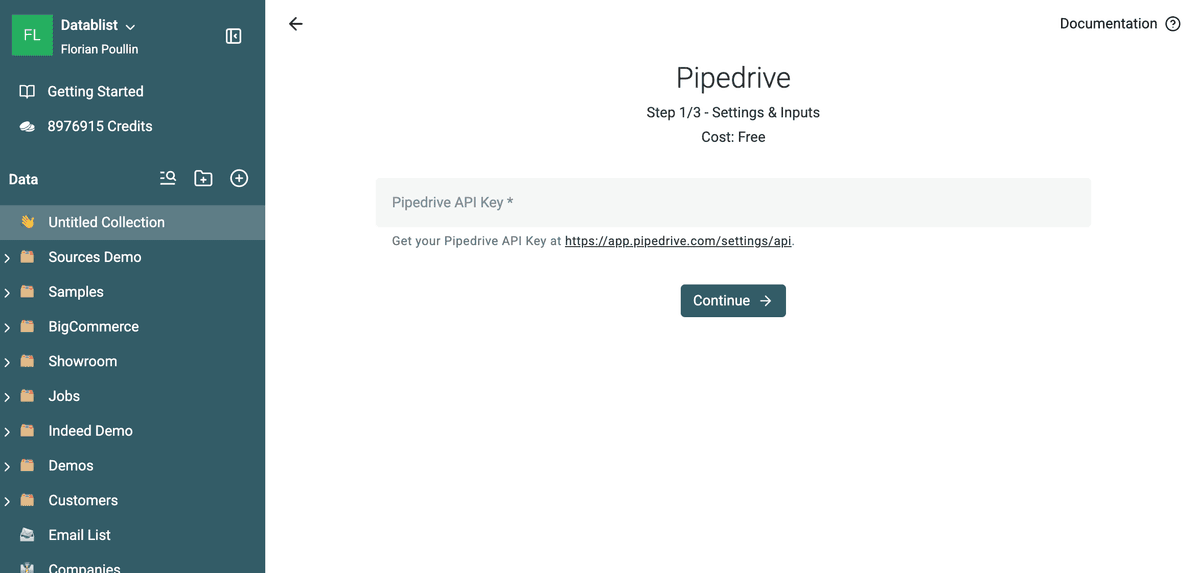
Dein Pipedrive API key ist notwendig, um Datablist mit Deinem Pipedrive-Account zu verbinden. Geh in die Pipedrive API Settings, kopiere Deinen persönlichen API key und füge ihn in Datablist ein.
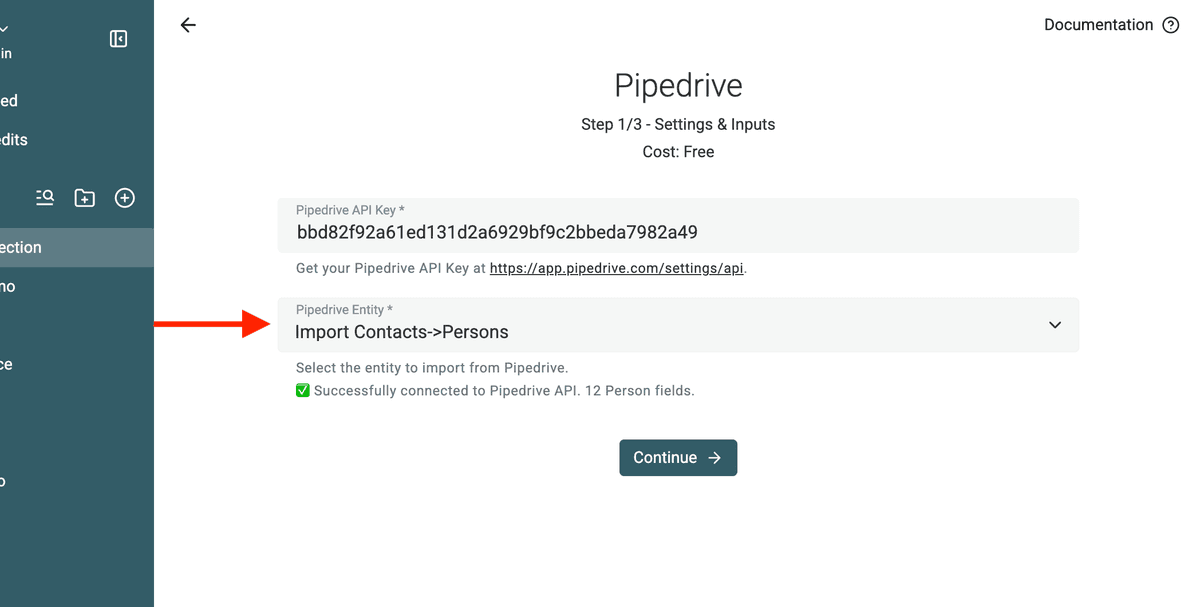
4. Wähle People oder Organizations
Sobald die Verbindung steht, entscheidest Du, was Du importieren willst:
- Wenn Du doppelte Kontakte bereinigst, wähle People.
- Wenn Du doppelte Firmen bereinigst, wähle Organizations.
Hinweis: Wenn Du beides brauchst, importiere es getrennt in zwei verschiedene Collections.
Warum getrennte Collections? – Pipedrive speichert People und Organizations unterschiedlich. Du kannst keinen Mix aus beidem gleichzeitig dedupen. Getrennt bekommst Du saubere, zuverlässige Treffer.
5. Datablist zieht alle Pipedrive-Felder
Sobald Du People oder Organizations auswählst, importiert Datablist:
- Standard-Pipedrive-Felder (Name, Email, Phone, Website usw.)
- Custom Fields, die Du in Pipedrive angelegt hast
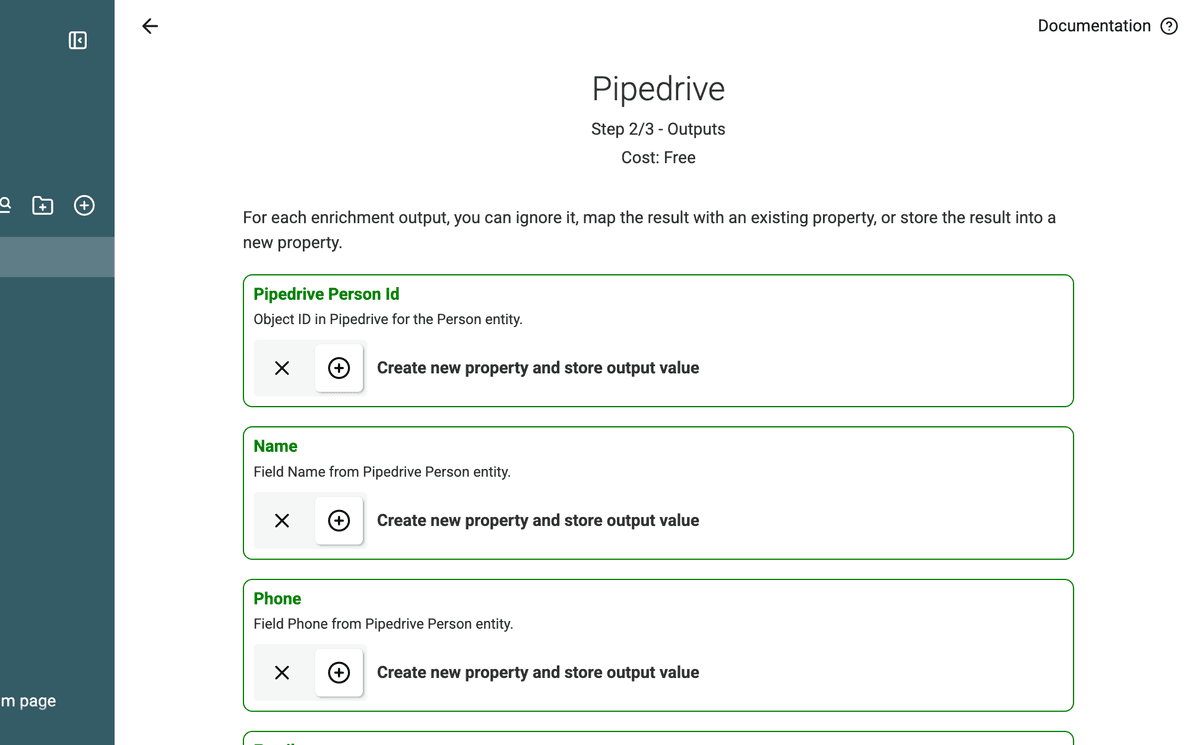
So ist alles Relevante für die Deduplication verfügbar.
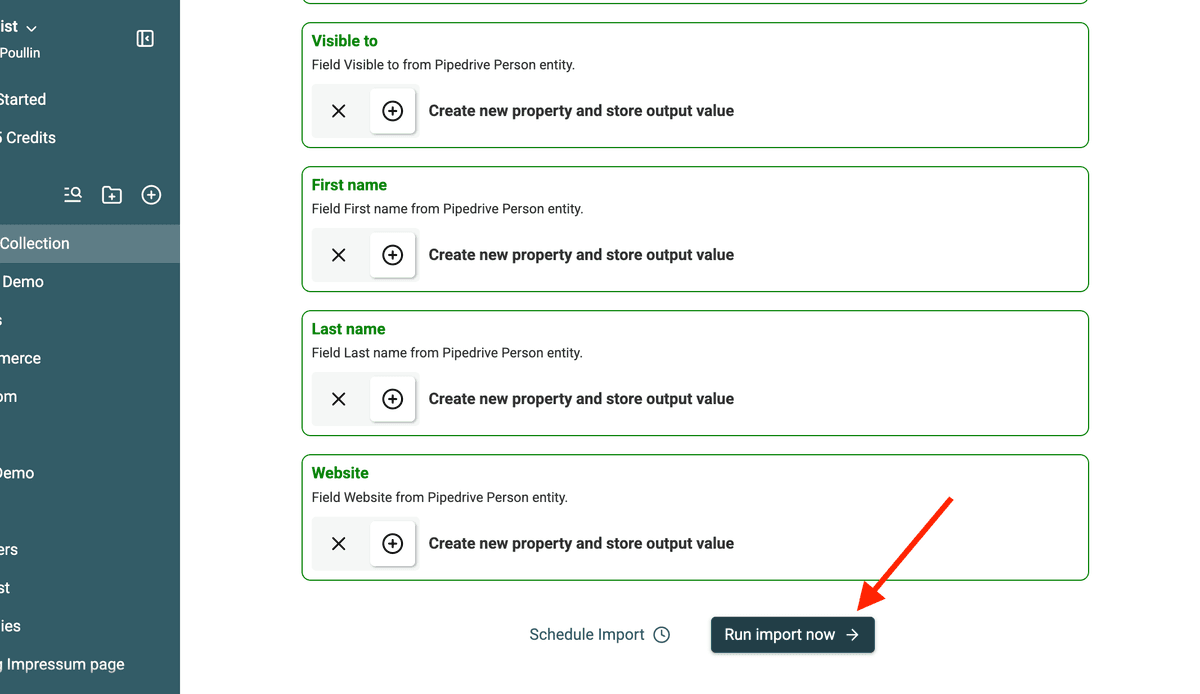
6. Starte den Import
Klicke auf Import, um Deine Daten zu laden. Wie lange es dauert, hängt von der Anzahl der Records ab.
Datablist verarbeitet Deine Kontakte und strukturiert sie für die Deduplication.
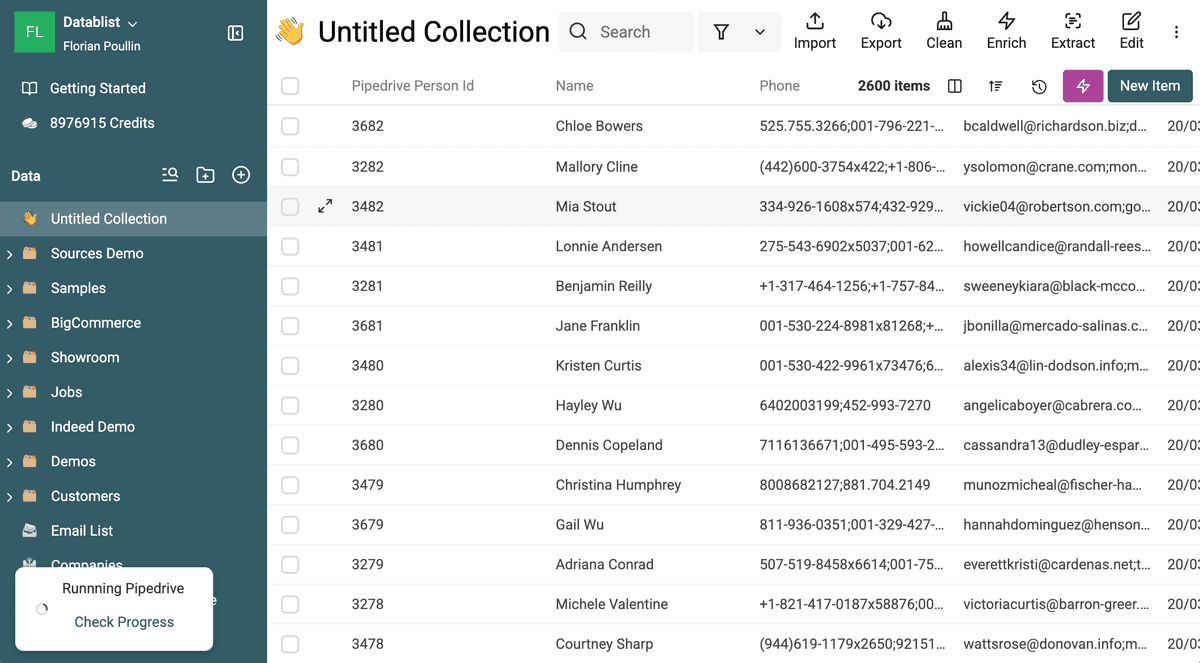
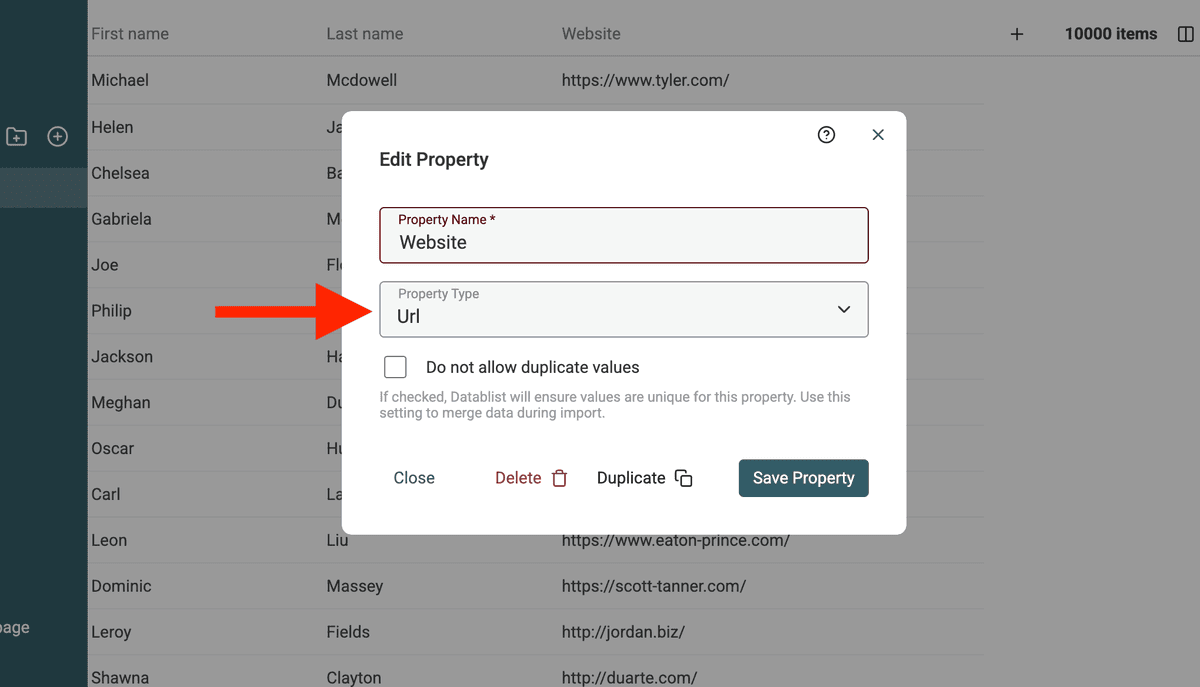
Datentypen für URLs anpassen
Der Datablist Duplicates Finder hat spezielle Processor für Emails, URLs usw. Wenn Deine Daten Websites enthalten, ändere den Property Type auf URL.
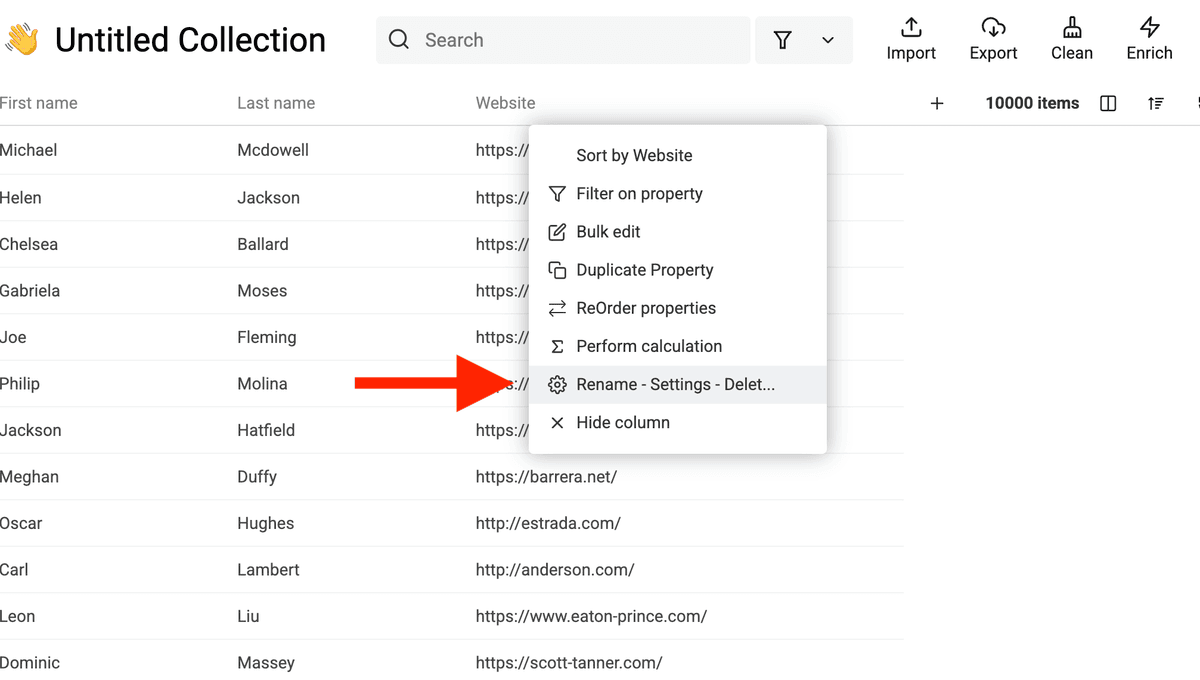
Mehrere E-Mail-Adressen & Telefonnummern
Wenn ein Kontakt in Pipedrive mehrere E-Mails oder Telefonnummern hat, werden sie in ein einzelnes Feld geschrieben – getrennt durch ein Semikolon ;.
Beispiel:
- John Doe hat in Pipedrive zwei E-Mails:
john@company.comundj.doe@gmail.com. - In Datablist steht dann: Email:
john@company.com;j.doe@gmail.com
So kann Datablist mehrere Werte bei der Deduplication korrekt berücksichtigen.
Sobald der Import fertig ist, sind Deine Daten bereit. Als Nächstes finden wir Duplikate mit erweiterten Matching-Methoden.
Schritt 2: Finde Duplikate in Pipedrive People und Organizations
Jetzt, wo Deine Pipedrive People oder Organizations in Datablist sind, geht’s ans Eingemachte: Duplikate finden. Anders als das Pipedrive-Tool nutzt Datablist fortgeschrittene Matching-Algorithmen und erkennt ähnliche Datensätze – auch wenn Namen leicht abweichen oder Kontaktdaten unvollständig sind.
So gehst Du vor:
1. Öffne den Duplicates Finder und wähle eine Deduplication Property
In Deiner Datablist Collection gehst Du auf Clean → Duplicates Finder.
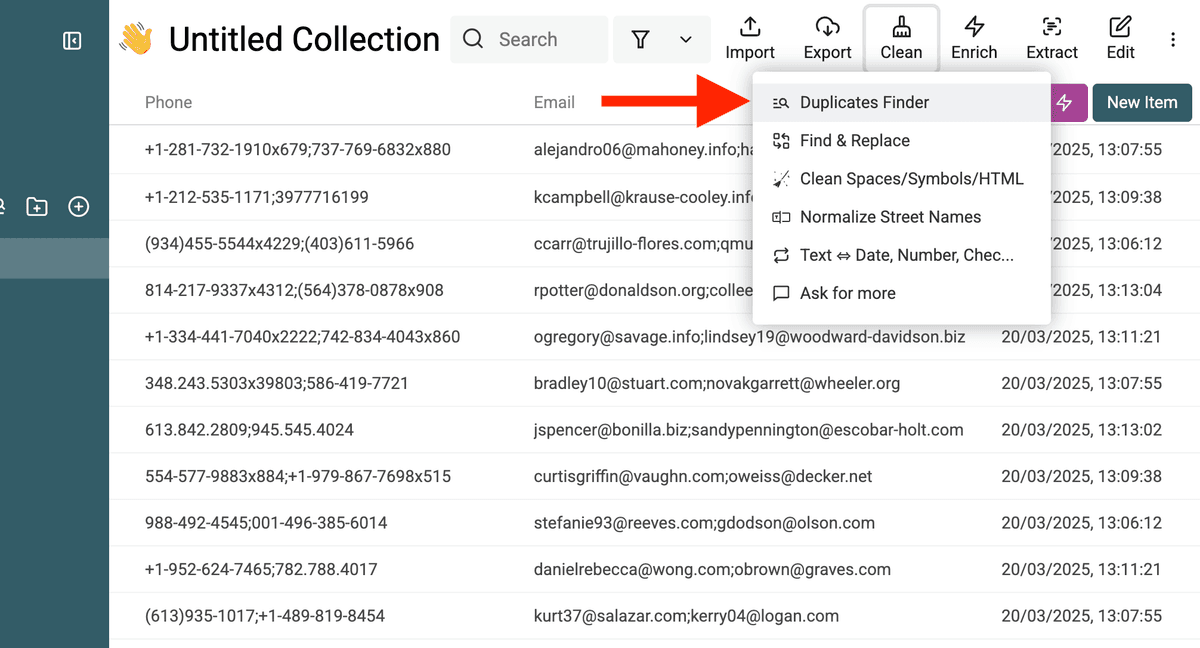
Eine deduplication property ist das Feld, über das Datablist Duplikate erkennt. Welche Property am besten passt, hängt von Deinen Daten ab:
- Für People: Email (am zuverlässigsten) oder Name (wenn E-Mails fehlen oder uneinheitlich sind).
- Für Organizations: Website (am besten) oder Name (wenn keine Website vorhanden ist).
💡 Beispiel:
- Wenn „Google“ zweimal existiert – einmal als
Google LLCund einmal alsGoogle– erkennt Datablist das als Duplikat, weil die Namen sehr ähnlich sind.
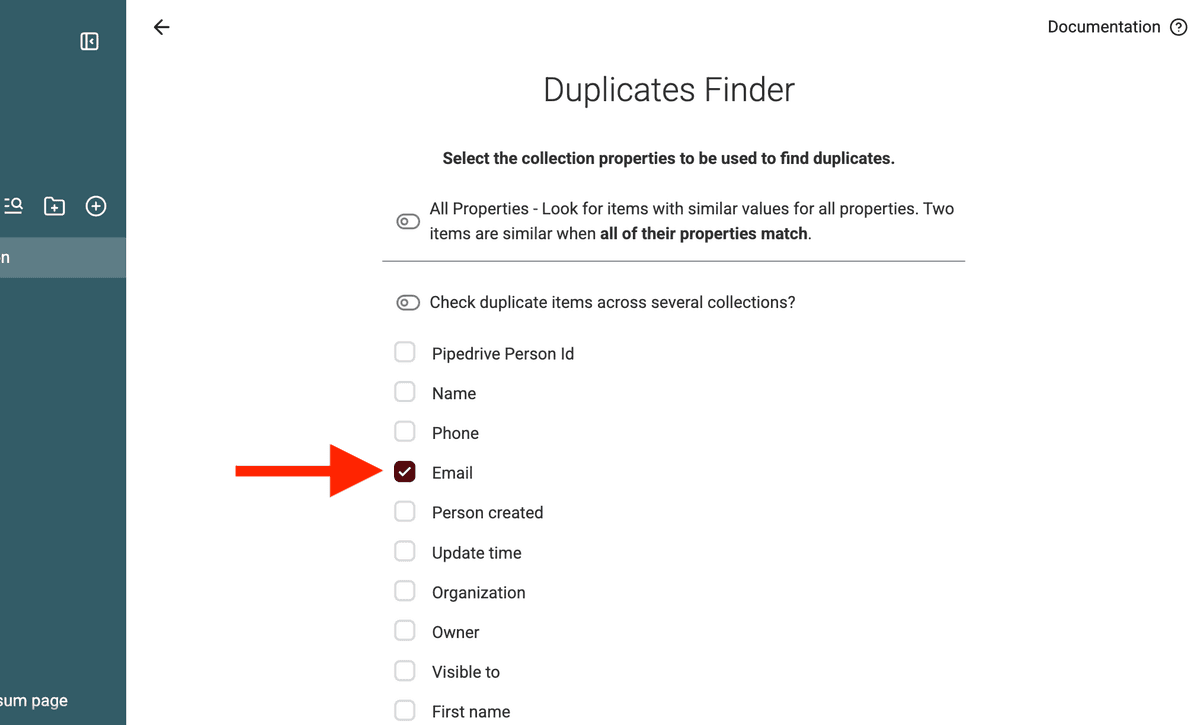
2. Deduplication laufen lassen
Für die besten Ergebnisse solltest Du nicht alles in einem Rutsch mergen. Mach Deduplication in Iterationen:
1️⃣ Erster Durchlauf: Match auf Email (bei People) oder Website (bei Organizations). Damit findest Du klare Duplikate. 2️⃣ Zweiter Durchlauf: Match auf Name (für People oder Organizations), um Duplikate zu finden, die unterschiedliche E-Mails haben, aber zur gleichen Person/Firma gehören.
🔹 Warum zwei Schritte?
- Wenn Du auf Email + Name gleichzeitig matchst, können kleine Namensunterschiede („John Doe“ vs. „Johnathan Doe“) einen Treffer verhindern.
- Ein Email-first Durchlauf räumt exakte Matches zuerst auf und reduziert Fehler.
Besondere Aufmerksamkeit bei mehreren E-Mails und Firmennamen
Manche Pipedrive-Felder enthalten mehrere Werte, z. B. Emails und Phones.
Wenn Du auf Feldern wie Emails oder Phones dedupst, die mehrere Werte enthalten (getrennt mit ;), aktiviere in Datablist den Modus "Multiple Values". So wird ein Record mit john@company.com; j.doe@gmail.com auch korrekt mit einem Record gematcht, der nur john@company.com enthält.
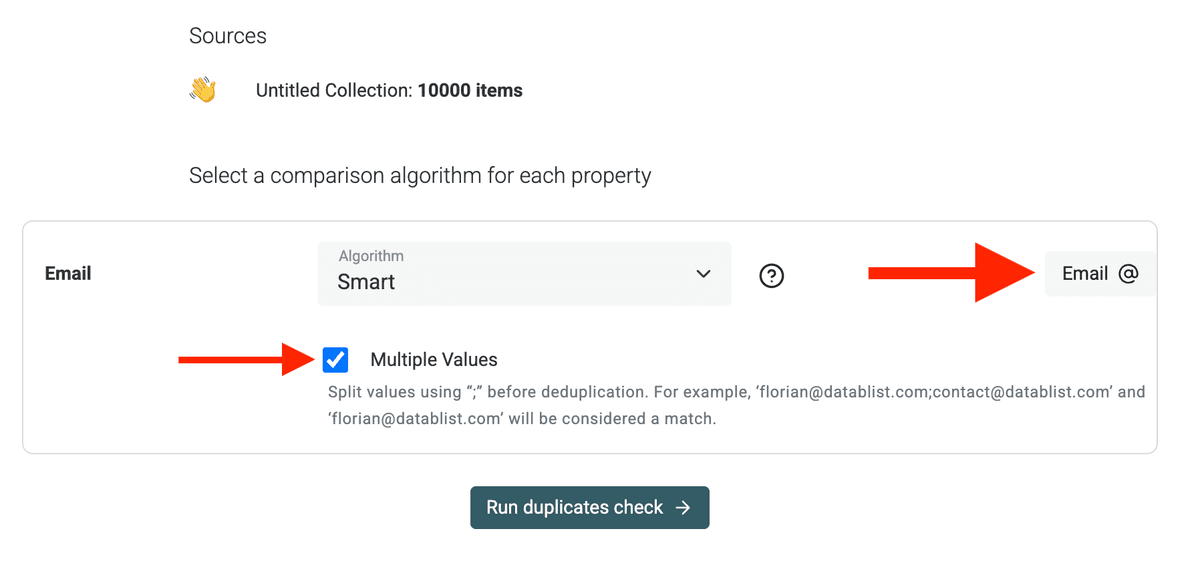
Wenn Du nach Company Names dedupst, hat der Datablist Duplicates Finder einen eigenen Processor für Rechtsformen und typische „Clutter Words“.
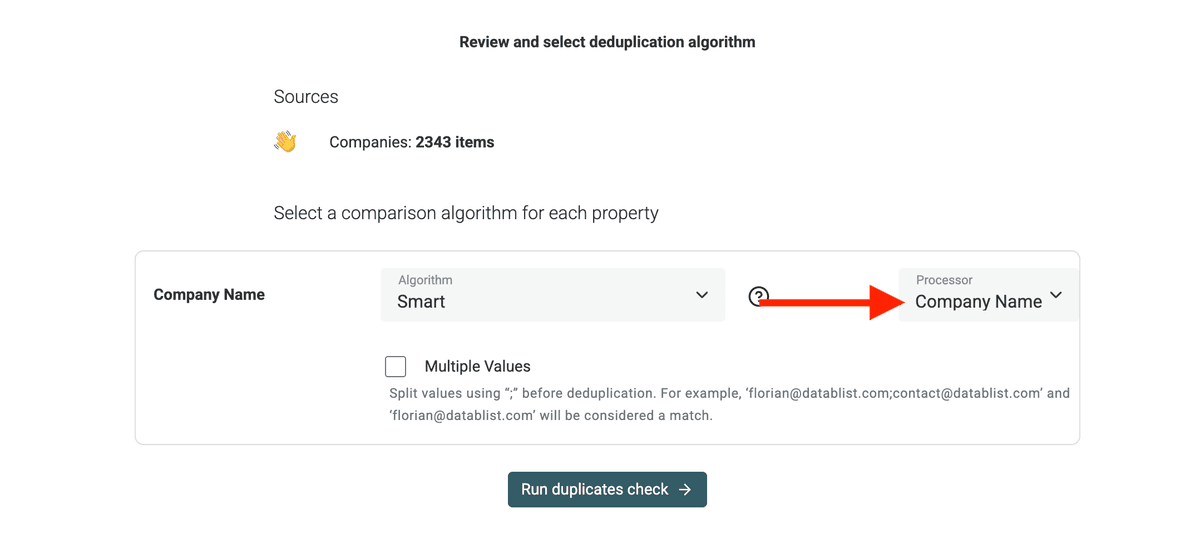
Wenn Du nach Websites dedupst, nutze den
URLprocessor.
3. Gefundene Duplikate und Konflikte prüfen
Sobald der Scan fertig ist, gruppiert Datablist die Duplikate.
- Du siehst Cluster ähnlicher People oder Organizations. Diese heißen bei uns „Duplicate Groups“.
- Pro Gruppe siehst Du, wodurch gematcht wurde (Email, Name oder Website) und ob es widersprüchliche Werte gibt.
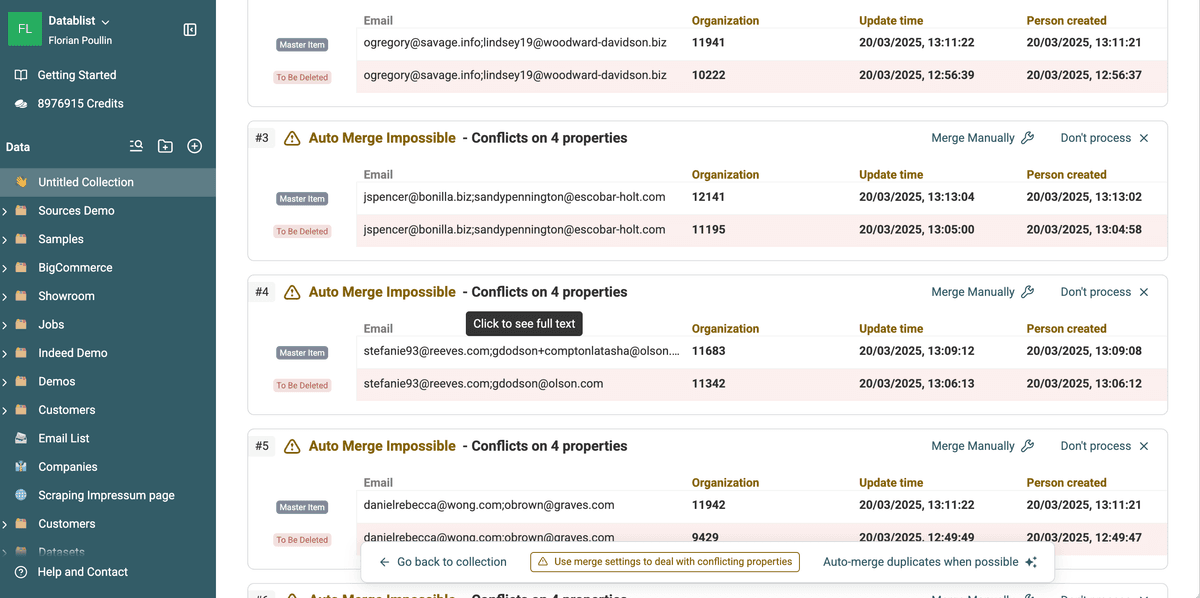
3.a. Duplicate Groups verstehen
Jede Duplicate Group enthält mehrere Records, die als dieselbe Entity bewertet werden.
- Manche Gruppen lassen sich automatisch mergen, weil die Daten identisch oder komplementär sind.
- Andere brauchen manuelle Prüfung, weil es Konflikte gibt.
💡 Beispiel:
- Wenn zwei „John Doe“-Records die gleiche E-Mail haben, aber unterschiedliche Telefonnummern, erkennt Datablist das Duplikat und markiert die Telefonnummer als conflicting field.
3.b. Merge-Regeln für conflicting values festlegen
Konflikte verstehen
Konflikte entstehen, wenn Duplikate für dasselbe Feld unterschiedliche Werte haben. Zum Beispiel unterschiedliche Jobtitel oder Telefonnummern. Datablist hebt diese Konflikte hervor, damit Du entscheiden kannst, was bleiben soll.
So gehst Du mit Konflikten um
Datablist bietet Dir ein übersichtliches Interface, um Konflikte schnell zu lösen – damit Deine Daten sauber und korrekt bleiben.
- Combine Values: Wenn sich Werte ergänzen (z. B. mehrere Telefonnummern oder Notizen), kombinierst Du sie.
- Keep One Value and delete the others: Wenn ein Record eindeutig besser ist und Du den anderen verwerfen willst, wähle „Drop conflicting values...“.
Für Combine conflicting values und Drop conflicting values gibt es einen Shortcut-Link, um automatisch alle conflicting properties auszuwählen.
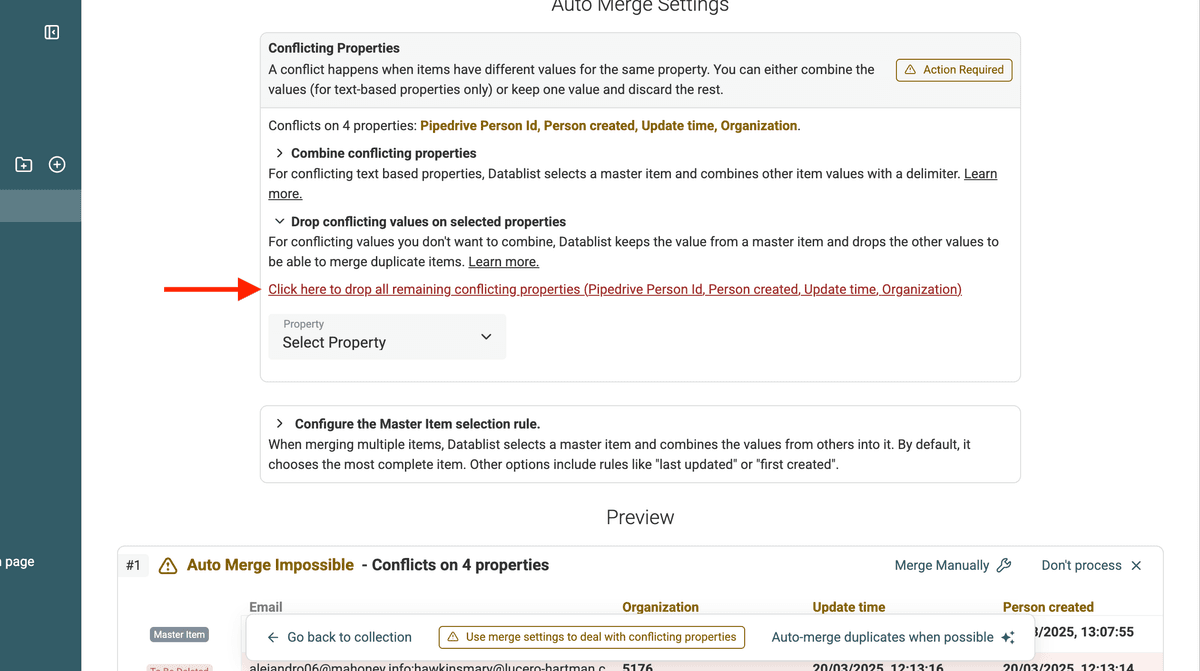
Master Record auswählen
Du kannst auch einstellen, wie Datablist den Master Record auswählt. Beim Mergen bleibt ein Record übrig (der Master), dessen Felder aktualisiert werden, während die anderen gelöscht werden.
Du steuerst die Auswahl des Master Records über verschiedene Regeln:
- Most Complete: Nimmt den Record mit den meisten ausgefüllten Feldern.
- Last Updated: Nimmt den zuletzt bearbeiteten Record.
- First Created: Nimmt den ältesten Record basierend auf dem Erstelldatum.
- Highest Value: Nimmt den Record mit dem höchsten Wert in einer ausgewählten Property. Bei Gleichstand wird der neueste genommen.
- Lowest Value: Nimmt den Record mit dem niedrigsten Wert in einer ausgewählten Property. Bei Gleichstand wird der neueste genommen.
- Matching Value: Nimmt den Record, der einen bestimmten Wert in einer ausgewählten Property enthält. Wenn keiner passt, wird nicht gemergt.
Datablist zeigt Dir eine Preview der geplanten Änderungen: welche Records gelöscht werden, welche Werte kombiniert werden usw.
Klicke auf „Refresh“ in der Preview, sobald Du mit den Merge-Settings fertig bist.
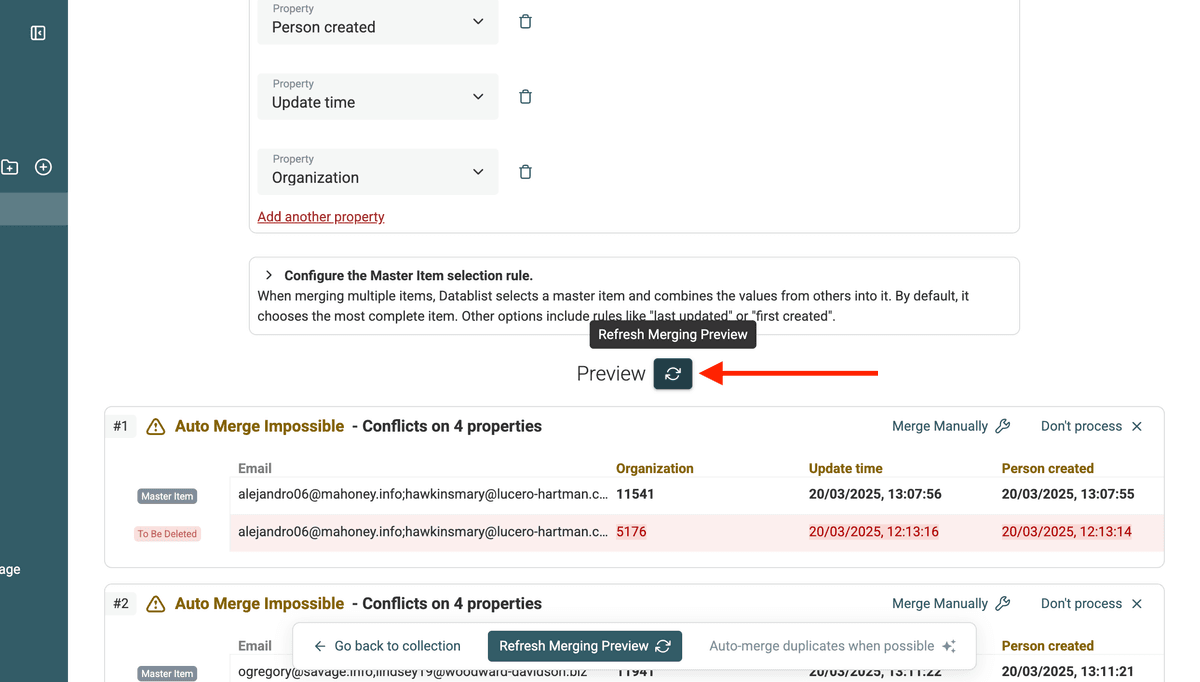
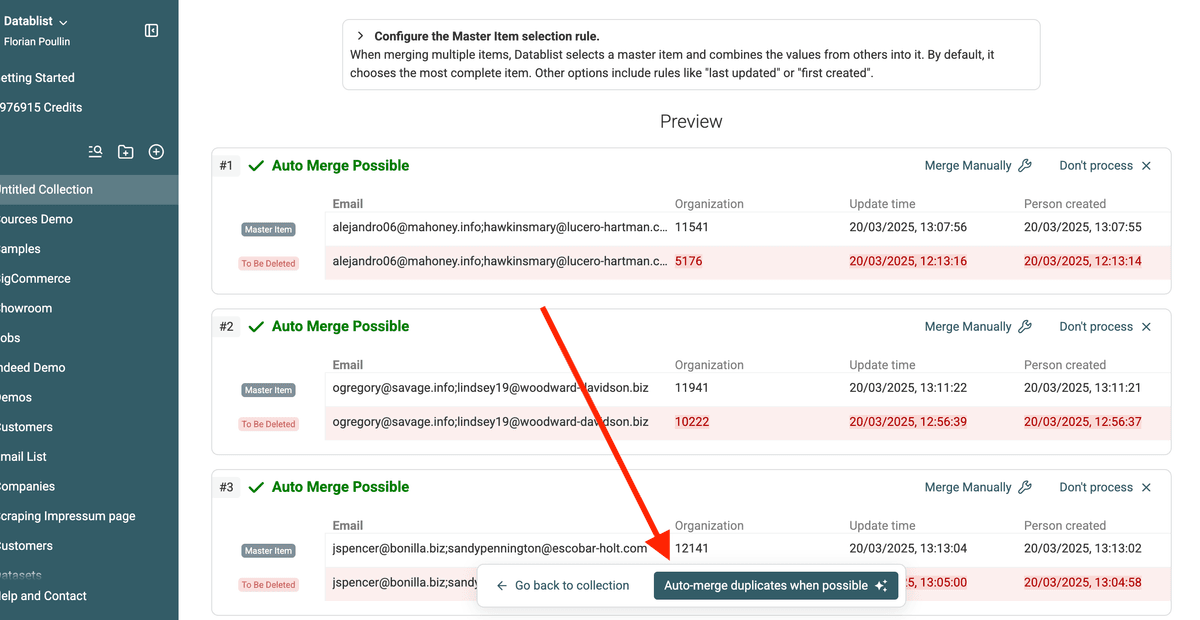
🔹 Beispiel: Zwei Kontakte mergen
Das folgende Beispiel zeigt das Ergebnis der Merge-Regeln:
- Drop Conflicting values für das Feld
Name. - Combine Conflicting values für das Feld
Phone.
| Field | Contact 1 | Contact 2 | Merged Result |
|---|---|---|---|
| Name | John Doe | Johnathan Doe | John Doe |
| john@company.com | john@company.com | john@company.com | |
| Phone | 555-1234 | 555-5678 | 555-1234; 555-5678 |
3.c. Duplikate automatisch mergen
Wenn Du mit der Preview zufrieden bist, klicke auf „Auto-merge duplicates when possible“. Dann wendet Datablist die Merge-Regeln auf alle Duplicate Groups an.
3.d. Changes File herunterladen
⚠️ Du BRAUCHST diese Changes File, um die Records in Deinem Pipedrive CRM zu mergen und zu updaten.
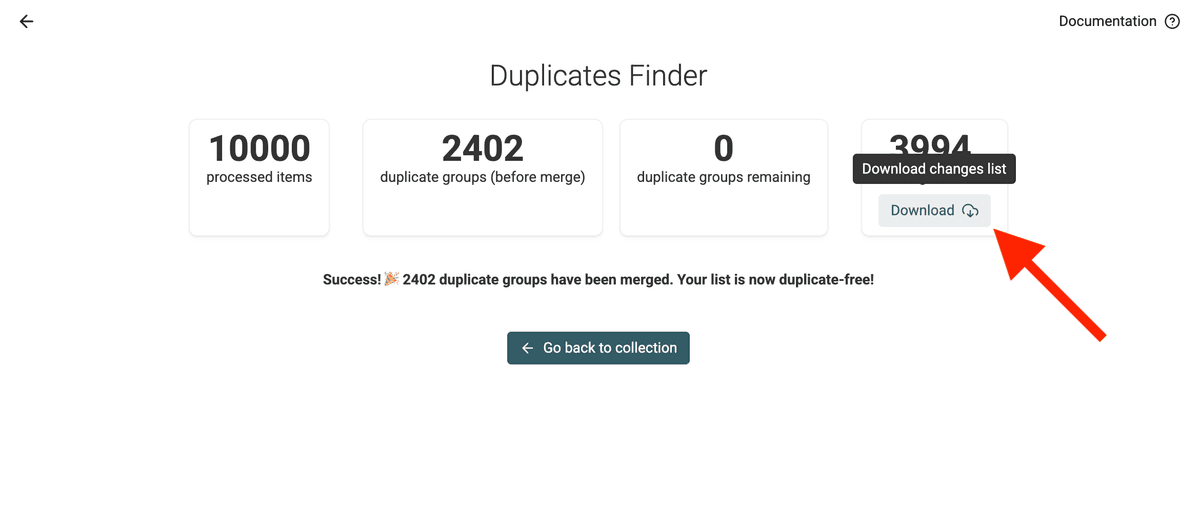
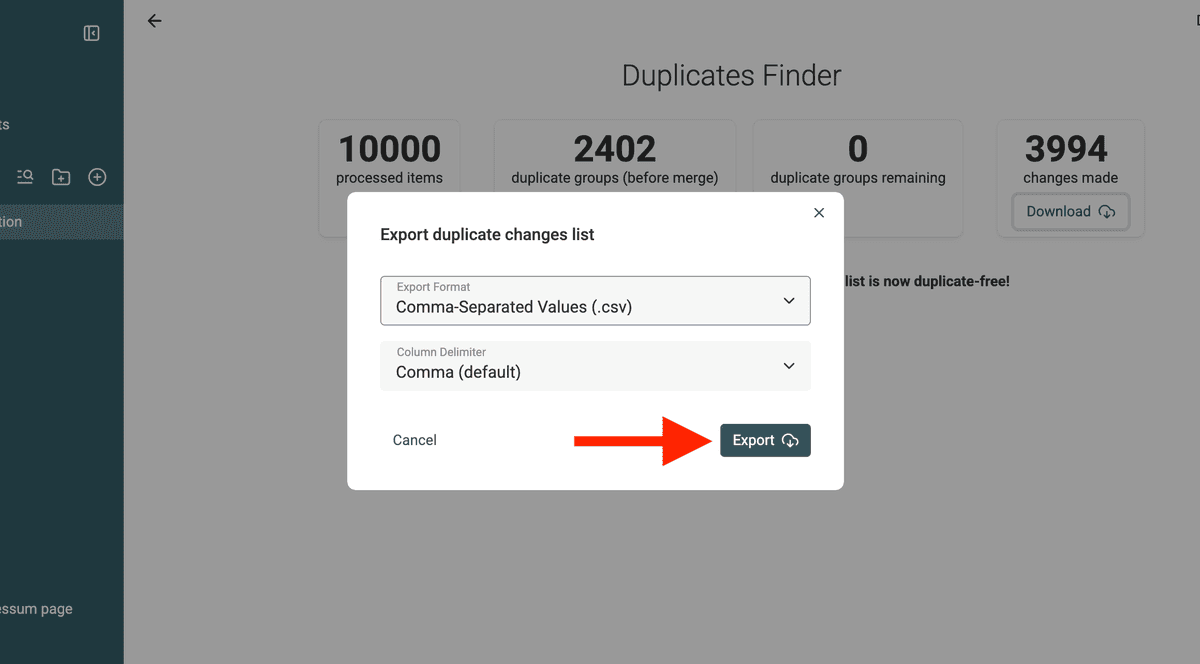
Schritt 3: Synce Bulk-Merges zurück nach Pipedrive
Deine Duplikate sind jetzt in Datablist gemergt. Der letzte Schritt: Synce die bereinigten Daten zurück nach Pipedrive, damit Dein CRM aktuell bleibt.
Dafür nutzen wir die Changes File, die Du im letzten Schritt heruntergeladen hast (siehe 3.d. Changes File herunterladen). Diese Datei enthält alle Merge-Aktionen, gelöschte Duplikate und aktualisierte Felder.
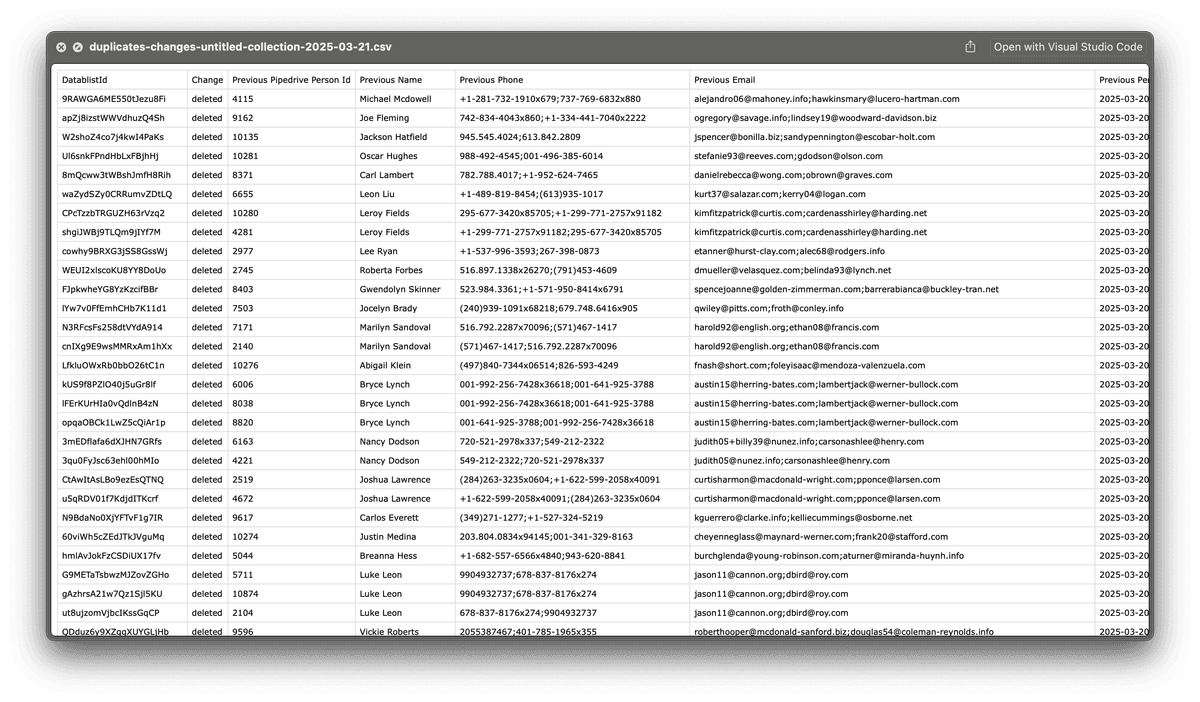
In diesem Changes Log siehst Du:
✅ Updated Records → Kontakte oder Organizations, die angepasst wurden (z. B. kombinierte Emails, Phones oder Namen) – inklusive vorheriger und neuer Werte.
✅ Deleted Records → Duplikate, die in einen Master Record gemergt wurden – mit der id des gelöschten Records und der id des Master Records, der ihn ersetzt. Diese Records müssen in Pipedrive gelöscht werden.
3.a Importiere die Duplicates Changes File in eine neue Collection
Um diese Änderungen in Pipedrive anzuwenden, erstellst Du eine neue Collection und lädst die Changes File hoch.
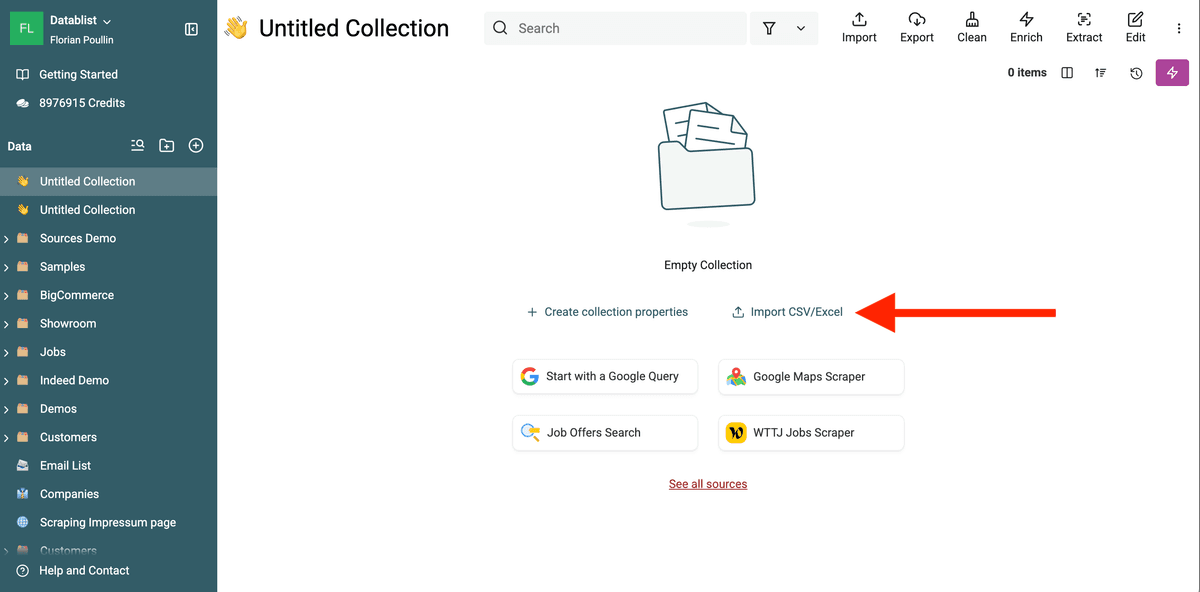
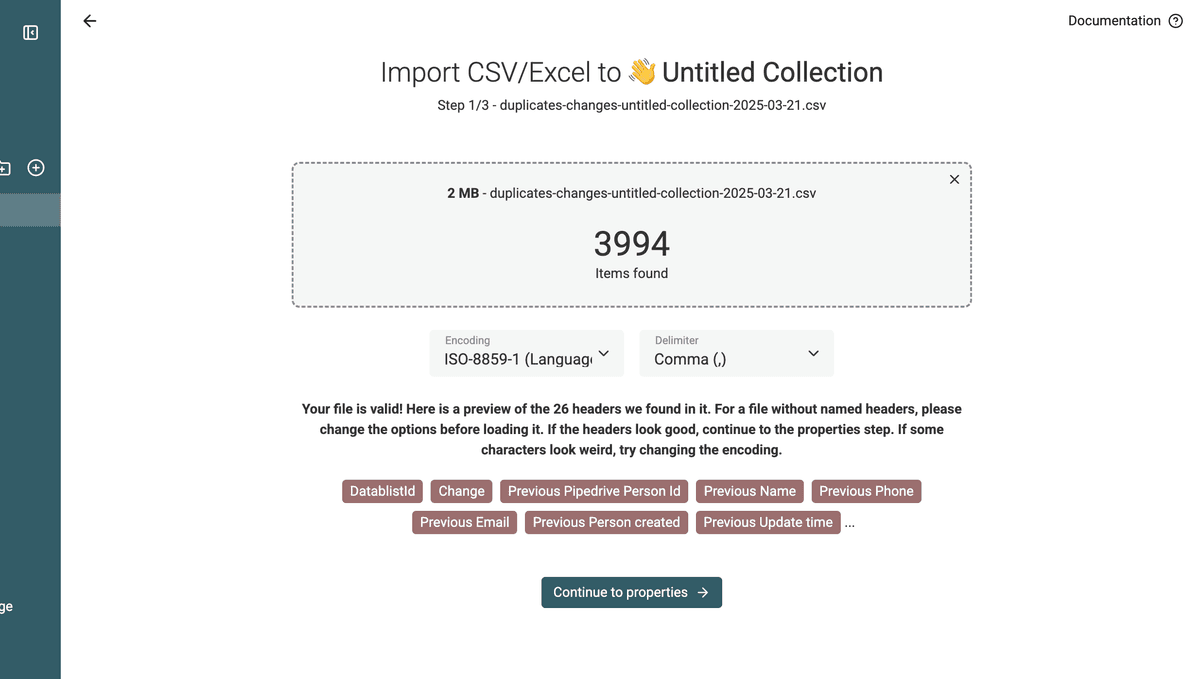
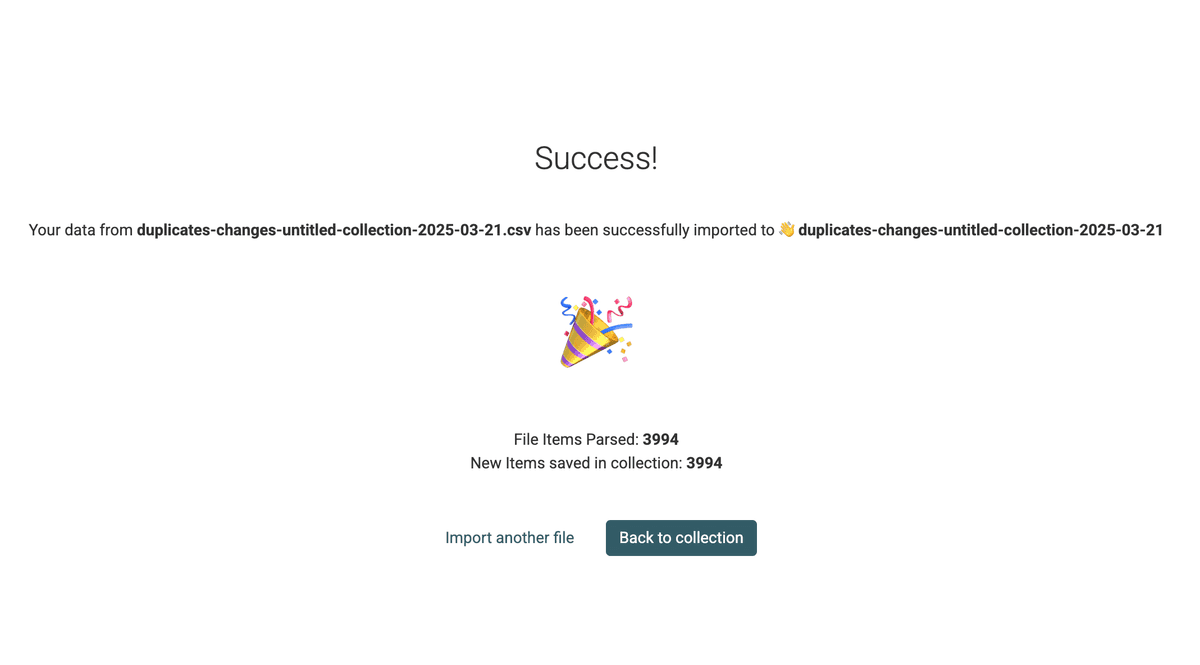
Du hast danach eine Collection mit den Merge-Operationen.
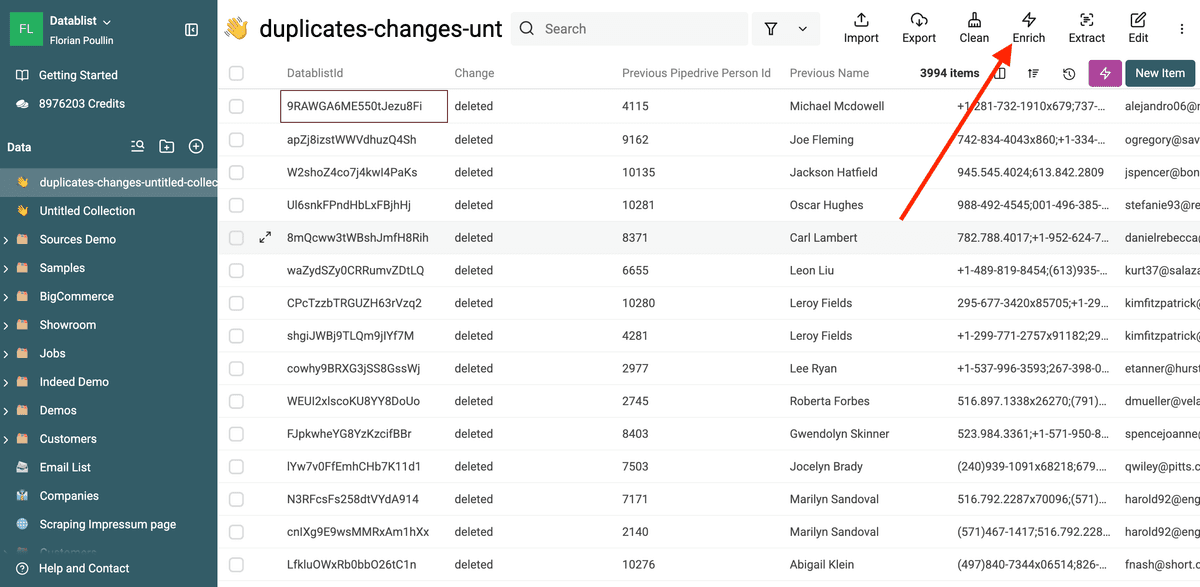
3.b. Duplicate Records mergen und löschen
Der erste Schritt, um die Änderungen in Pipedrive anzuwenden: Du sagst Pipedrive, dass es die „deleted“ Records in die „master“ Records mergen soll.
Pipedrive bietet dafür eine merge API, mit der Duplikate sauber zusammengeführt werden. Genau die nutzen wir.
Für die Techies: so funktioniert die Pipedrive API:
- Nutze den Endpoint
/organizations/:id/mergefür Organizations. - Nutze den Endpoint
/persons/:id/mergefür People. - Der Duplicate Record wird gelöscht, und die Daten werden in den Master Record übertragen.
💡 Example API Request:
PUT https://api.pipedrive.com/v1/persons/{duplicate_id}/merge?api_token=YOUR_API_KEY
{
"merge_with_id": "{master_record_id}"
}
🔹 Warum die Merge API nutzen?
- So bleiben alle verknüpften Deals, Activities und Notes am Master Record.
- Nicht-konfliktierende Daten (wie zusätzliche Phones oder Emails) werden automatisch behalten.
Keine Sorge – Datablist hat ein natives Enrichment, das diesen Pipedrive-Endpoint für Dich aufruft.
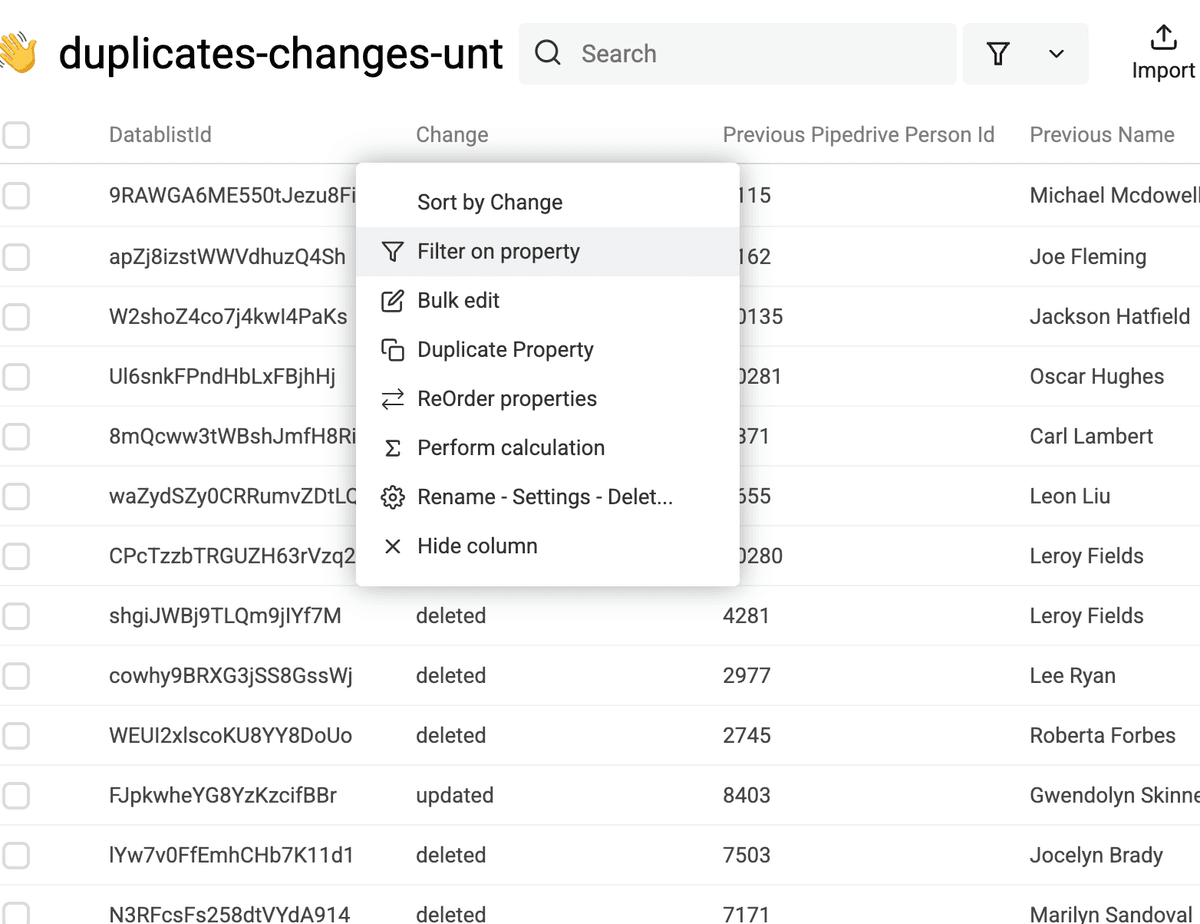
Als Erstes filterst Du nur die Zeilen, die in der change-Spalte deleted stehen.
Dann wählst Du im Enrich-Menü Pipedrive Merge Duplicates.
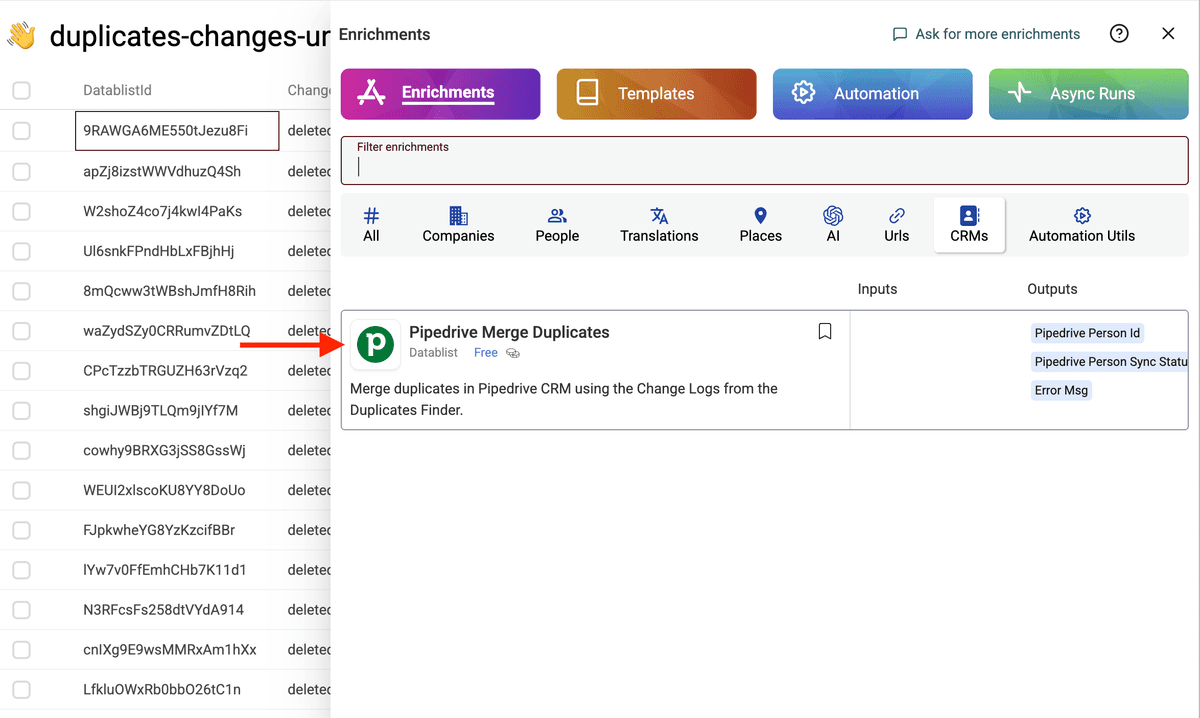
Stell sicher, dass Du wirklich nur „deleted“ in der Change-Spalte siehst, bevor Du das Enrichment Pipedrive Merge Duplicates startest.
Gib Deinen Pipedrive API key ein und wähle die Pipedrive Entity, die gemergt werden soll.
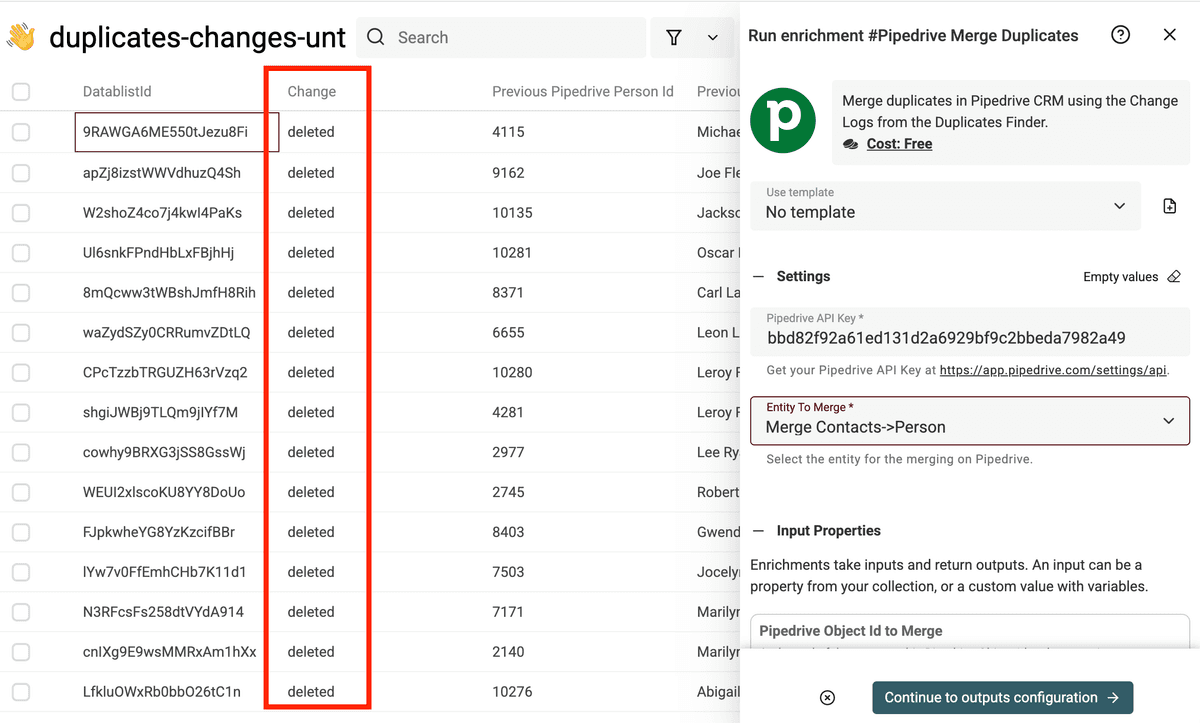
Dann mapst Du in den Inputs Pipedrive Object Id to Merge auf das Feld Previous Pipedrive Person Id.
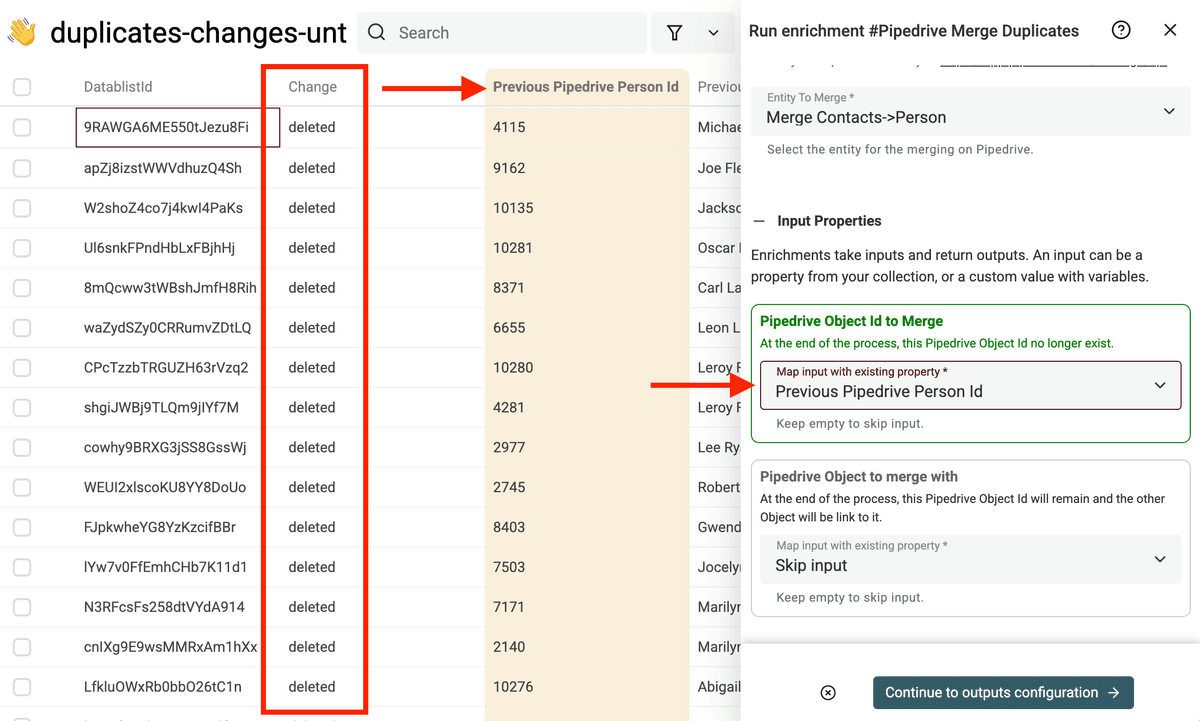
Für Pipedrive Object to merge with mapst Du auf Destination Pipedrive Person Id.
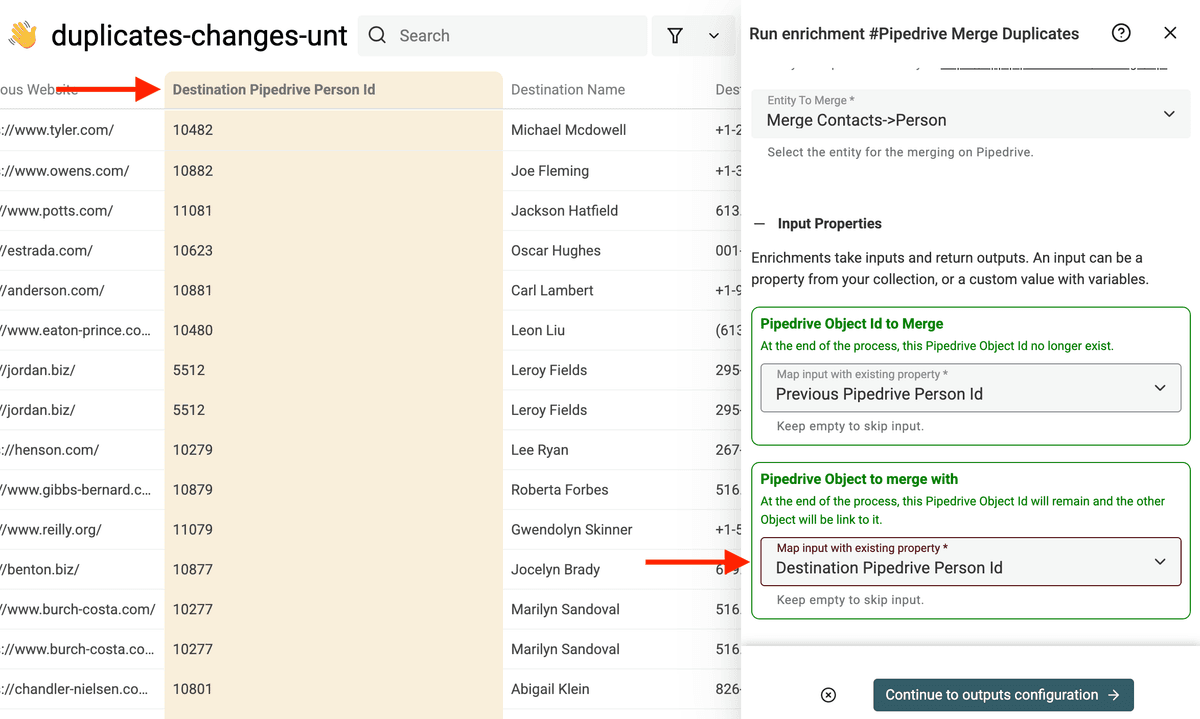
Dann startest Du den Merge-Prozess.
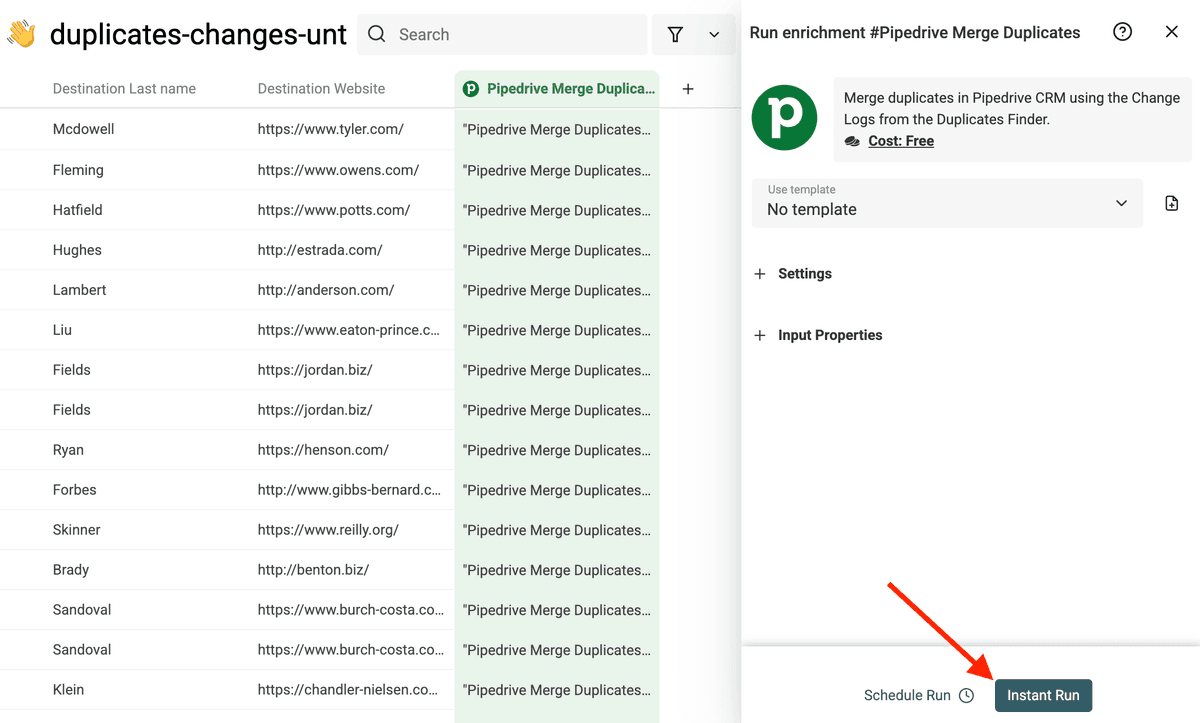
Den Fortschritt siehst Du direkt in Datablist.
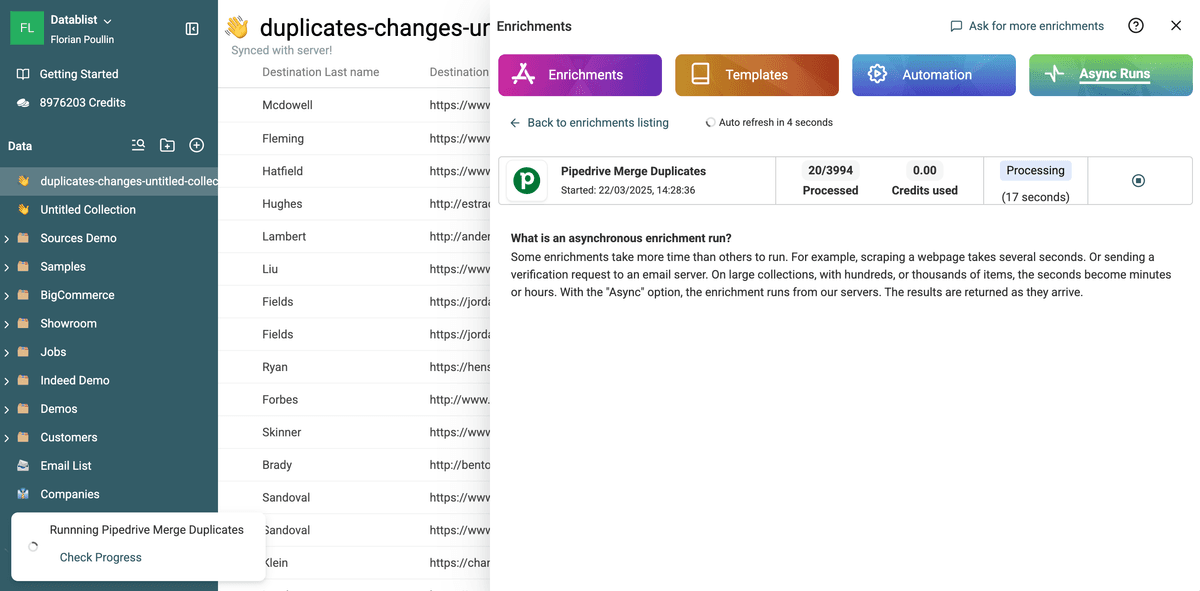
Für jede Zeile in der Collection bekommst Du einen Status zum Merge.
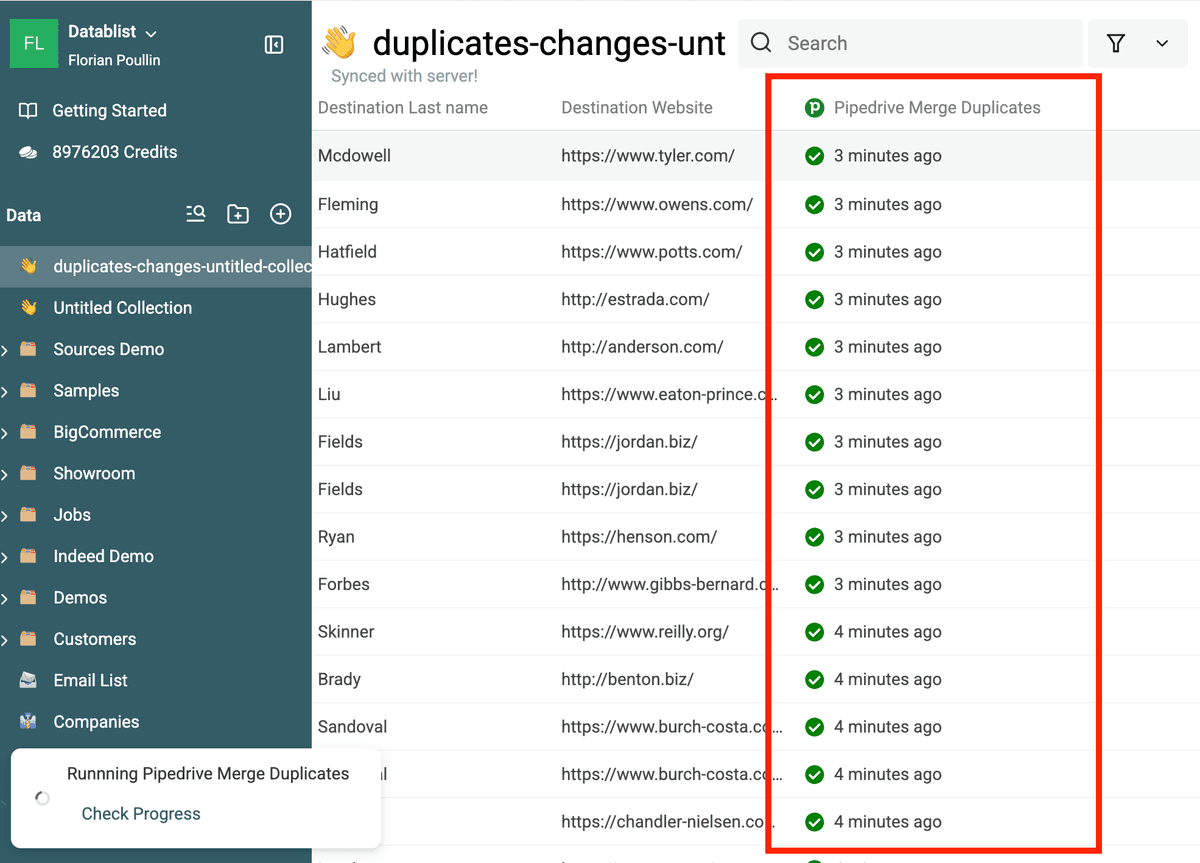
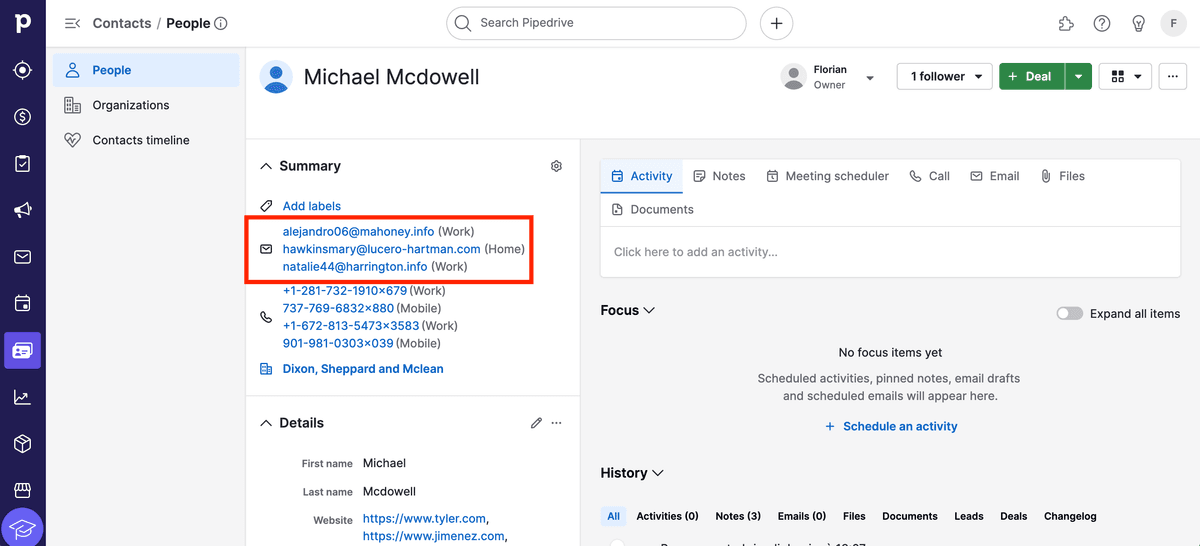
Du kannst den Pipedrive Record, der gelöscht wird, prüfen: Öffne den Record (bei People ist die URL https://app.pipedrive.com/person/:ID). Oben erscheint dann eine Meldung.
Im Master Record siehst Du anschließend ebenfalls die zusammengeführten Daten.
3.c. Updated Records in Pipedrive syncen
Im vorherigen Schritt haben wir über die Pipedrive Merge API die Duplicate Records in den Master Record gemergt.
Leider hängt Pipedrive dabei die Werte des Duplicate Records einfach an den Master Record dran. Das kann dazu führen, dass Du am Ende mehrere ähnliche Websites etc. im selben Record hast.
Darum updaten wir im nächsten Schritt die verbleibenden Master Records mit den sauberen Daten, die wir nach dem Merge in Datablist haben.
In derselben „Changes File“-Collection filterst Du in der change-Spalte auf updated.
Dann klickst Du Export -> Send to external tool.
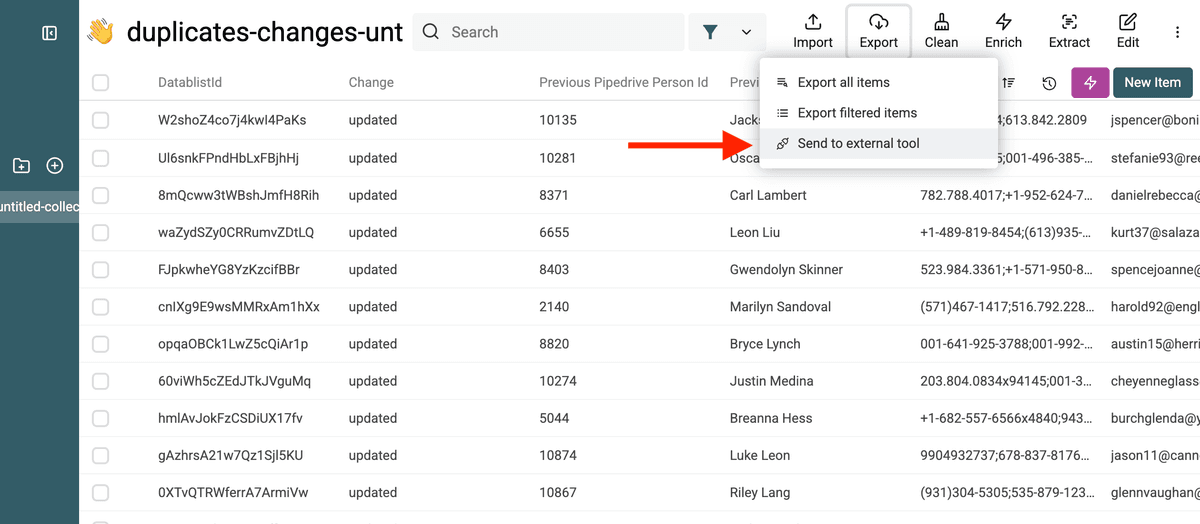
Und wählst Sync with Persons/Organizations in Pipedrive.
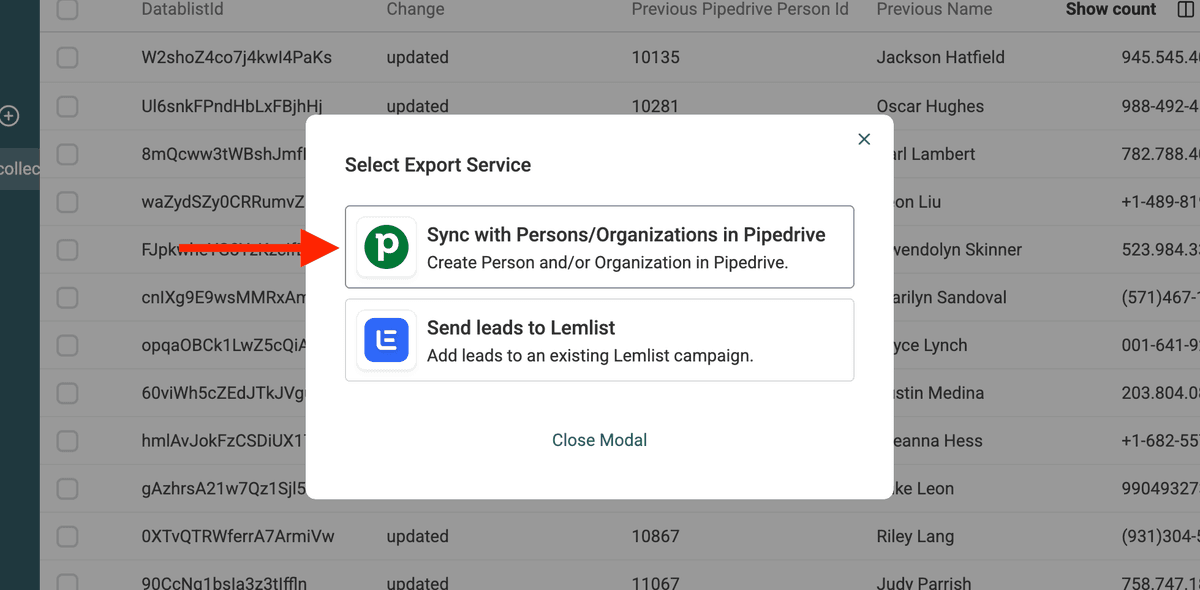
Gib Deinen Pipedrive API Key ein und wähle die Entity, die Du updatest (People oder Organizations).
Wähle das Feld ID und die Felder, die Du mit sauberen Werten updaten willst.
Wichtig – Du musst das Feld
IDauswählen, damit Datablist Records aktualisiert, statt neue anzulegen.
In diesem Beispiel update ich nur das Website-Feld. Also wähle ich ID und Website.
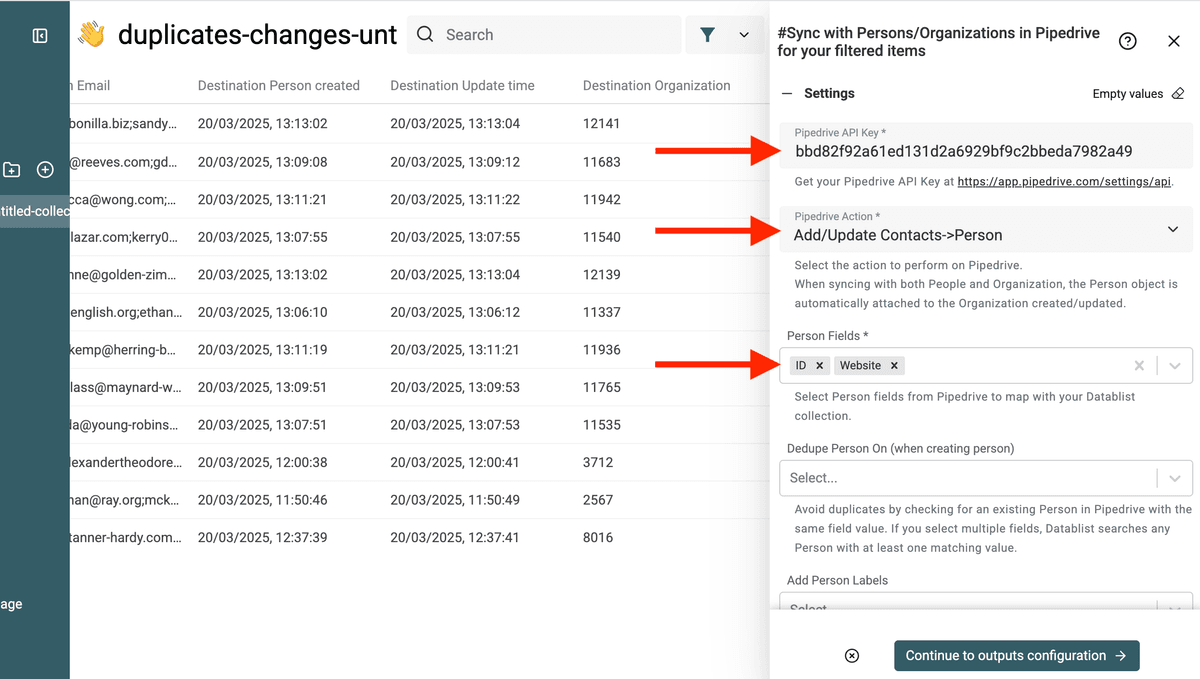
Im Inputs-Bereich mapst Du mit den Destination XX-Feldern.
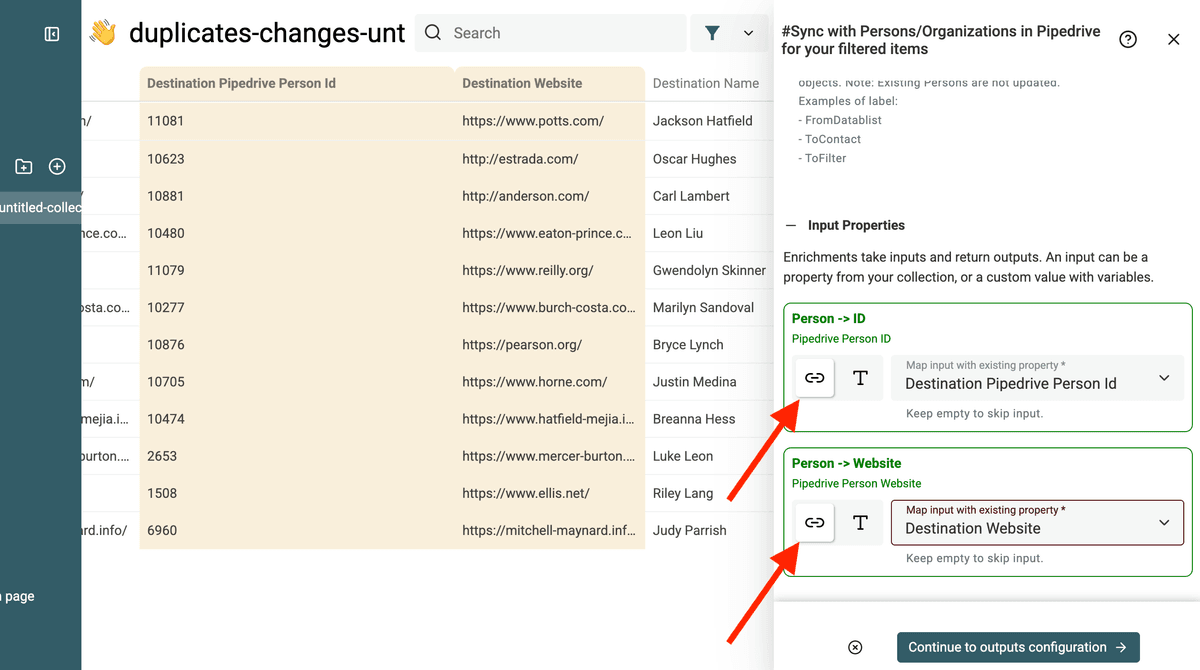
Konfiguriere die Outputs so, dass Du den Update-Status bekommst.
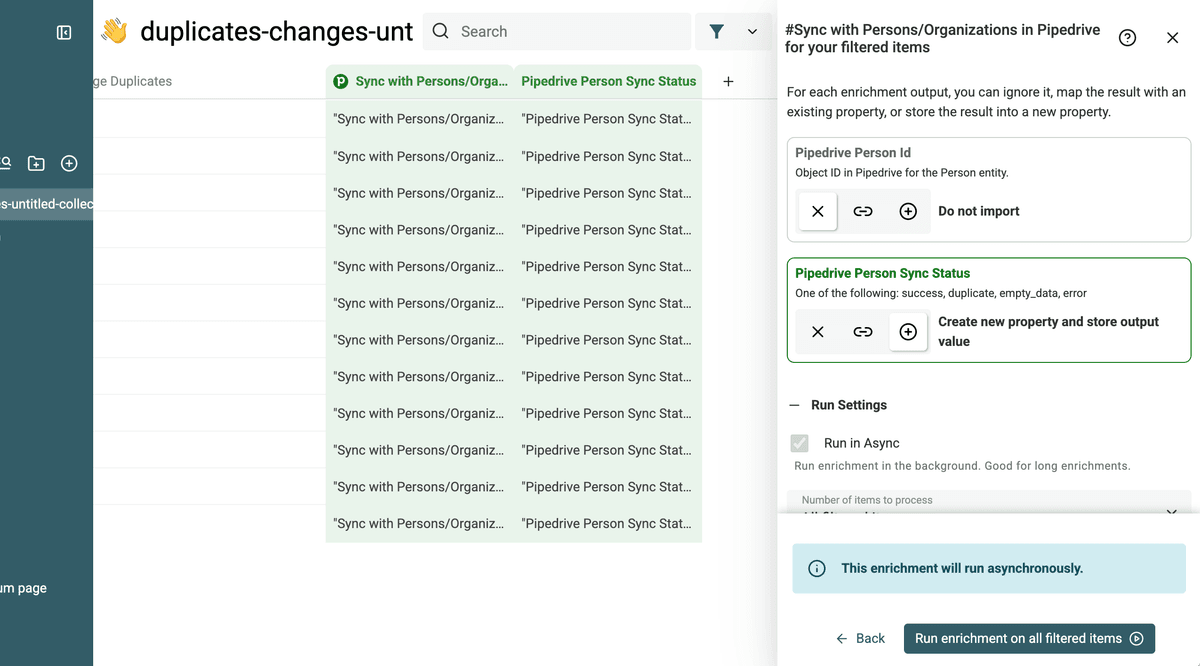
Dann startest Du den Prozess.
Du kannst das Ergebnis prüfen, indem Du im Pipedrive Record in die Changelog-Ansicht gehst.
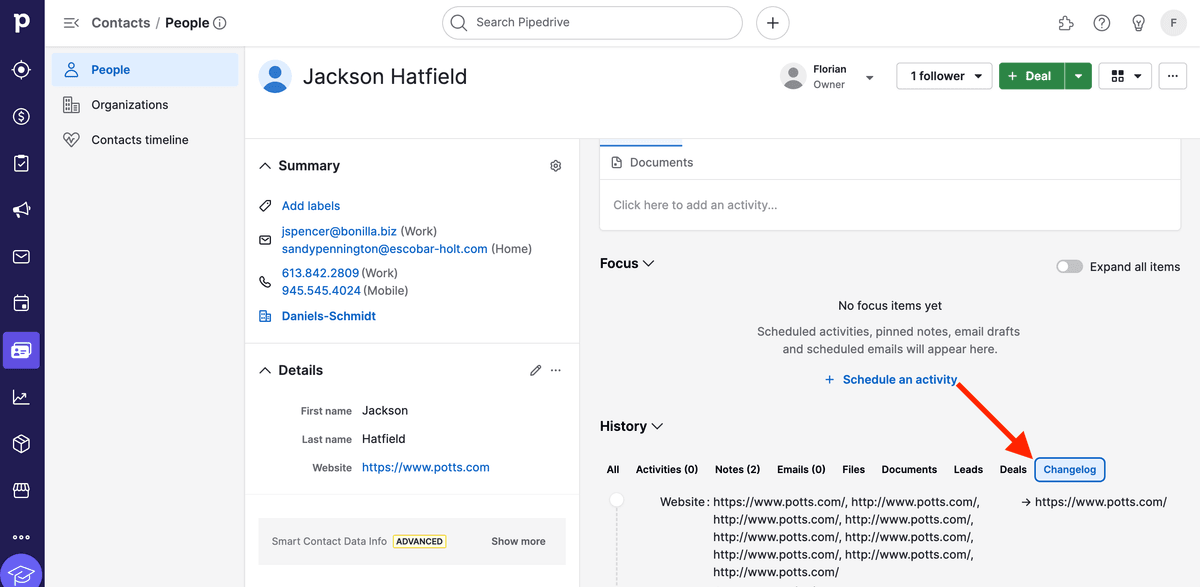
3.d. Fertig! Dein Pipedrive CRM ist jetzt sauber
Das war’s! Du hast erfolgreich: ✅ Daten in Datablist importiert. ✅ Duplikate mit smarten Algorithmen gefunden und gemergt. ✅ Die bereinigten Daten zurück nach Pipedrive gesynct.
Dein CRM ist jetzt deduped und aufgeräumt, und Du kannst Sales und Kontakte deutlich entspannter managen. 🚀
Limits der Pipedrive-eigenen Duplikat-Merge-Funktion
Pipedrive hat ein simples Deduplication-Tool – aber mit klaren Limits, die Dein CRM trotzdem mit Duplikaten voll laufen lassen können. Hier ist, warum Datablist die bessere Lösung ist:
1. Pipedrive findet nur exakte Matches
Die Duplicate Detection von Pipedrive ist zu streng. Es matcht nur Records mit identischen Namen. Das heißt:
- „Google LLC“ und „Google“ werden nicht als Duplikate erkannt.
- Emails, Phones oder Websites werden nicht für Deduplication berücksichtigt.
✅ Datablist-Vorteil: Nutzt fuzzy matching und findet Duplikate auch dann, wenn Name, Email oder Website leicht abweichen.
2. Kein Bulk Merge in Pipedrive
Pipedrive zwingt Dich, Duplikate einzeln zu mergen – das kostet Zeit, sobald Du Hunderte davon hast.
✅ Datablist-Vorteil: Bulk merging mit voller Kontrolle darüber, wie Felder kombiniert werden – für saubere, vollständige Daten.
3. Keine Kontrolle über Merge-Regeln
Beim Mergen in Pipedrive:
- Du kannst nicht auswählen, welche Felder behalten oder kombiniert werden.
- Manche Infos gehen verloren, wenn das System den falschen Master Record auswählt.
✅ Datablist-Vorteil: Du definierst eigene Merge-Regeln, kombinierst mehrere Werte und stellst sicher, dass keine wichtigen Daten verloren gehen.
4. Kein Merge-Verlauf oder Change Log
Pipedrive trackt nicht, was gemergt wurde oder welche Records gelöscht wurden. Wenn ein Fehler passiert, gibt’s kein echtes „Undo“.
✅ Datablist-Vorteil: Ein Change Log dokumentiert jeden Merge, sodass Du immer nachvollziehen kannst, was sich geändert hat.
Pipedrive ist top fürs Sales-Management – aber bei Deduplication ist Datablist die smartere Wahl. Probier’s aus und bring Dein CRM ohne Stress wieder in Ordnung! 🚀