

Data Matching, auch bekannt als Record Linkage oder Deduplication, bedeutet, zusammengehörige Datensätze über mehrere Datasets hinweg zu erkennen und miteinander zu verknüpfen. Genau das ist der Hebel, der aus rohen, chaotischen Daten eine verwertbare Basis für Marketing, Sales oder Data Analysis macht.
Viele Tools am Markt sind entweder unnötig kompliziert oder schlicht teuer. Datablist ist eine Online-Anwendung, kompatibel mit Mac OS, Microsoft Windows und Linux, mit der Du Data Matching schnell umsetzen kannst. Sie unterstützt Exact Match, Phonetic und fortgeschrittene Fuzzy-Matching-Algorithmen.
In diesem Guide räumen wir mit dem „Black Box“-Gefühl rund um Data Matching auf. Egal, ob Du gerade erst anfängst oder schon professionell mit Daten arbeitest und Deinen Prozess optimieren willst: Hier bekommst Du einen klaren, praxisnahen Ablauf.
Hier ist eine kurze Übersicht über die Data-Matching-Themen in diesem Artikel:
- Datasets laden
- Daten vorbereiten: Cleaning und Normalisierung
- Records innerhalb oder über mehrere Collections matchen
- Deduplicate: Matching-Gruppen entfernen oder mergen
Starte in Sekunden mit unserem Online Data Matching Tool. Keine Sales Calls, keine PowerPoint-Features.
Schritt 1: Datasets laden
Der erste Schritt: Lade Deine Datasets in Datablist. Datablist ist ein Online-Tool für Listenmanagement. Du kannst CSV-Dateien ansehen und bearbeiten sowie Excel-Dateien. Ideal, um Deine Leads list zu managen, Customer Data zu bereinigen oder Scraped Data zu säubern.
Lege zuerst eine Collection an, um Dein erstes Dataset zu importieren.
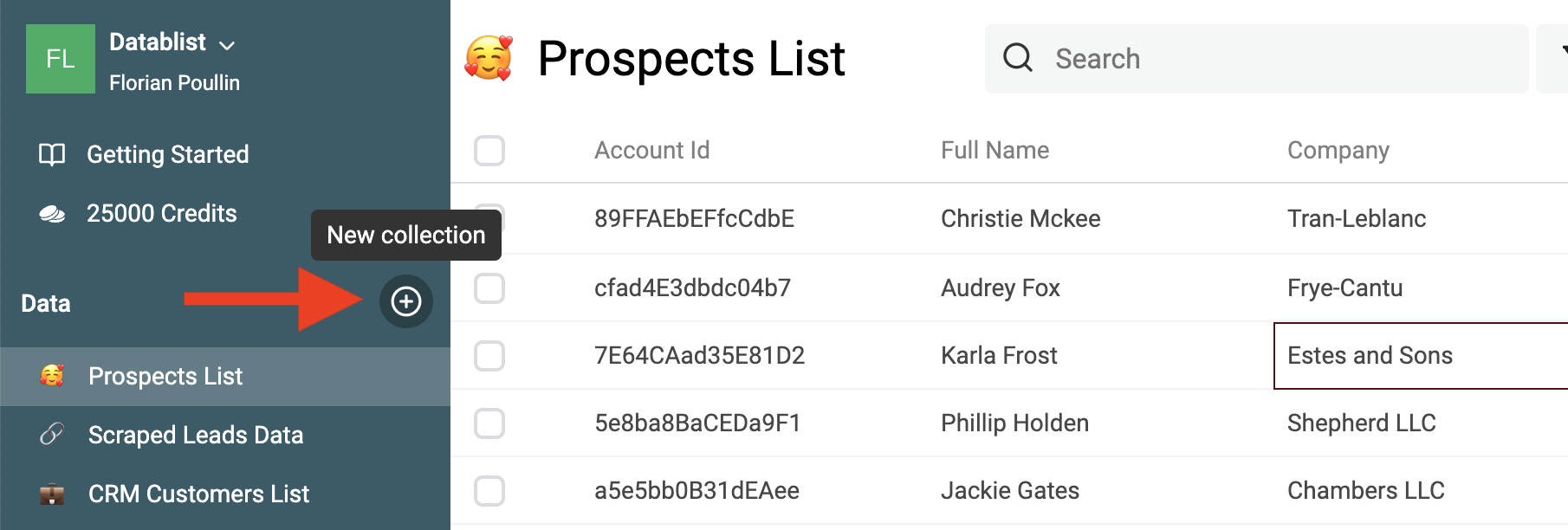
Klicke dann auf den Button Import.
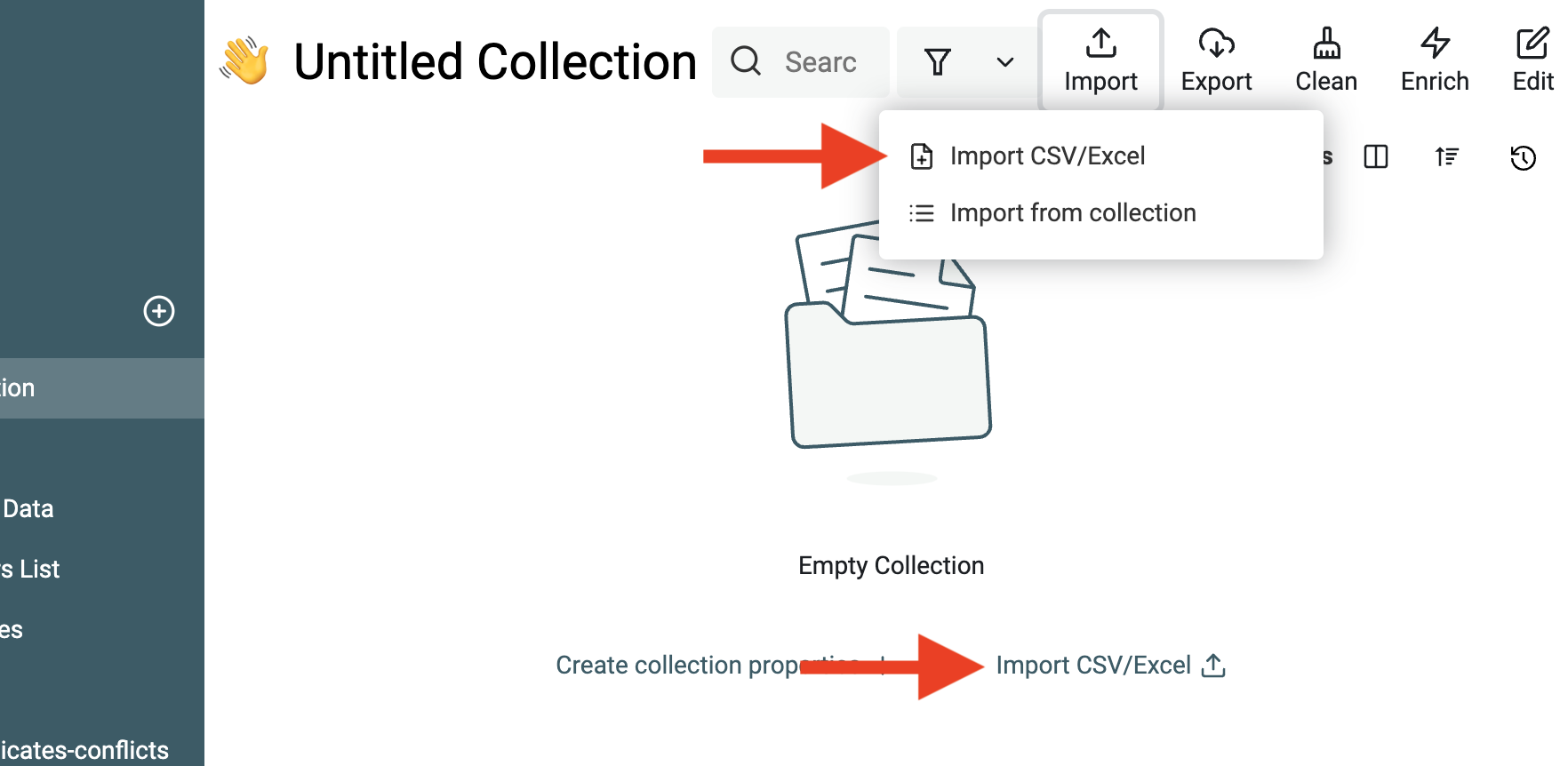
Sobald Dein erstes Dataset importiert ist, hast Du zwei Optionen:
- Importiere weitere Datasets mit ähnlicher Struktur in dieselbe Collection.
- Importiere Datasets mit anderer Struktur in neue Collections.
Der Datablist Duplicates Finder findet passende Records innerhalb einer einzelnen Collection oder auch collection-übergreifend bei unterschiedlichen Datenstrukturen.
Schritt 2: Daten bereinigen (wenn nötig)
Der zweite Schritt ist Data Cleansing. Data Cleaning ist die wichtigste Voraussetzung für sauberes Data Matching: Es sorgt dafür, dass Deine Treffer präzise und reproduzierbar sind. Unbereinigte Daten führen schnell zu False Positives, verpassten Matches und insgesamt unzuverlässigen Ergebnissen. Kurz gesagt: Data Cleaning ebnet den Weg für erfolgreiches Data Matching.
Wenn solche „Störsignale“ in Namen (Personen- oder Firmennamen) auftauchen, bringen sie inhaltlich nichts – können aber verhindern, dass der Deduplication-Algorithmus echte Duplikate erkennt.
Datablist bringt eine ganze Reihe integrierter Data-Cleaning-Tools mit:
- Remove symbols and punctuation – Scraped Texte enthalten oft Smileys oder ASCII-Symbole, oder Namen mit Satzzeichen. Für das Matching ignoriert Datablist diese Zeichen zwar, aber sie können das automatische Zusammenführen während des Deduplication-Prozesses blockieren.
- Remove extra spaces – Ein einzelnes zusätzliches Leerzeichen reicht, damit zwei Strings unterschiedlich sind. Datablist preprocessed Textwerte zwar (u.a. extra Spaces entfernen), aber auch hier gilt: Beim automatischen Mergen im Deduplication-Prozess können sie stören.
- Extract email addresses, URLs, etc. from texts – Wenn Du unstrukturierten Text hast, der E-Mail-Adressen, URLs, Mentions, Tags etc. enthält, nutze unseren Data Extractor, um diese Entities sauber zu extrahieren und zu strukturieren. Data Matching ist deutlich einfacher, wenn Du strukturierte Felder vergleichen kannst.
- Remove HTML tags – Du kannst Strings mit HTML-Tags in Plain Text umwandeln. Damit lassen sich auch gescrapte Listen mit HTML sauber mit anderen Datasets matchen.
- Convert text to DateTime, Number, Boolean, etc. – Datablist unterstützt echte Datentypen wie DateTime, Number, Boolean usw. Ein wichtiger Cleaning-Schritt ist, Rohtext in native Formate umzuwandeln. Das ist entscheidend für fortgeschrittene Merge-Regeln, wenn Du z.B. anhand eines Value-Vergleichs entscheiden willst (etwa: „neuester Timestamp gewinnt“).
- Change text case to get consistent formatting – Einheitliche Groß-/Kleinschreibung ist simpel, aber wichtig. Datablist hat mehrere Case-Transformation-Algorithmen).
- Split oder merge properties – Perfekt für Multi-Value-Daten. Wenn ein Feld mehrere E-Mail-Adressen enthält (getrennt durch Komma/Semikolon/Spaces), erzeugt das Split-Tool mehrere Felder mit jeweils einer Adresse.
- Empty Values entfernen oder ersetzen – Nutze die Datablist Filtering features, um leere Werte oder ganze leere Zeilen zu filtern.
Mehr Beispiele und konkrete Schritte findest Du in unserem Guide zu Data Cleaning.
Personennamen normalisieren
Mit People-Datasets zu arbeiten ist bei Data Deduplication absolut Standard. Customer-, Leads- und Prospects-Datasets sind typische Beispiele. Optimalerweise basiert Data Matching in People-Daten auf eindeutigen Identifiers wie E-Mail-Adresse oder ID-Nummern. Wenn Du diese nicht hast (oder Personen über mehrere Datasets hinweg matchen willst), kommst Du meistens über den Namen.
Durch Pre-processing stellst Du sicher, dass Namen einheitlich formatiert sind – und reduzierst so Fehler bei der Deduplication.
Noise aus Namen entfernen
Personennamen sind oft extrem variabel: Nicknames, Abkürzungen, alternative Schreibweisen und Sonderzeichen kommen ständig vor.
Nutze das starke Find & Replace tool, um Prefixes, Suffixes, Stop-Words, regionale Zusätze und andere überflüssige Wörter zu entfernen.
Wenn Du z.B. Titel am Anfang entfernen willst, kannst Du diesen Regular Expression nutzen:
^\s*(mr|mrs|dr|miss|ms|sir|madam|m).?\s
und durch einen leeren String ersetzen.
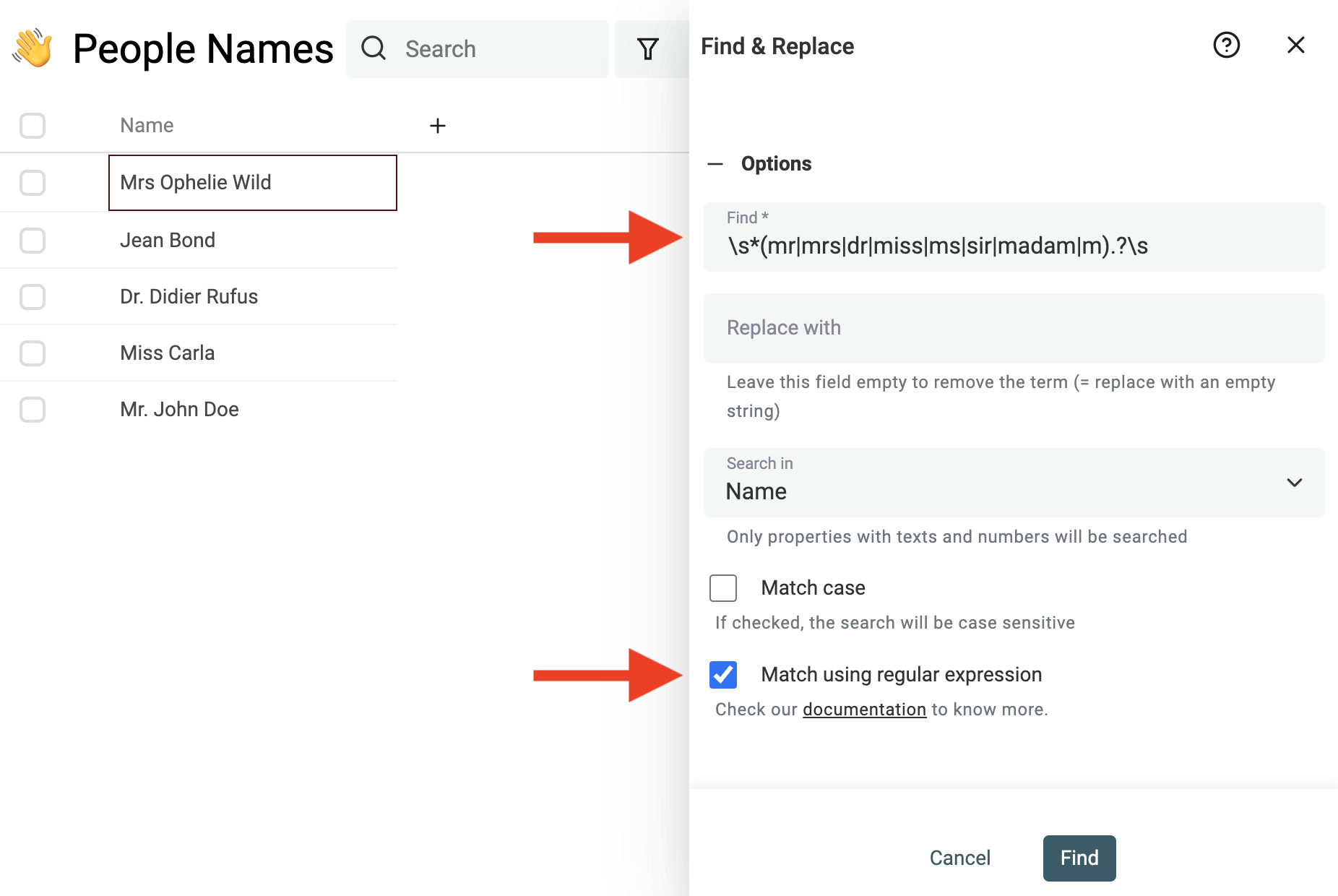
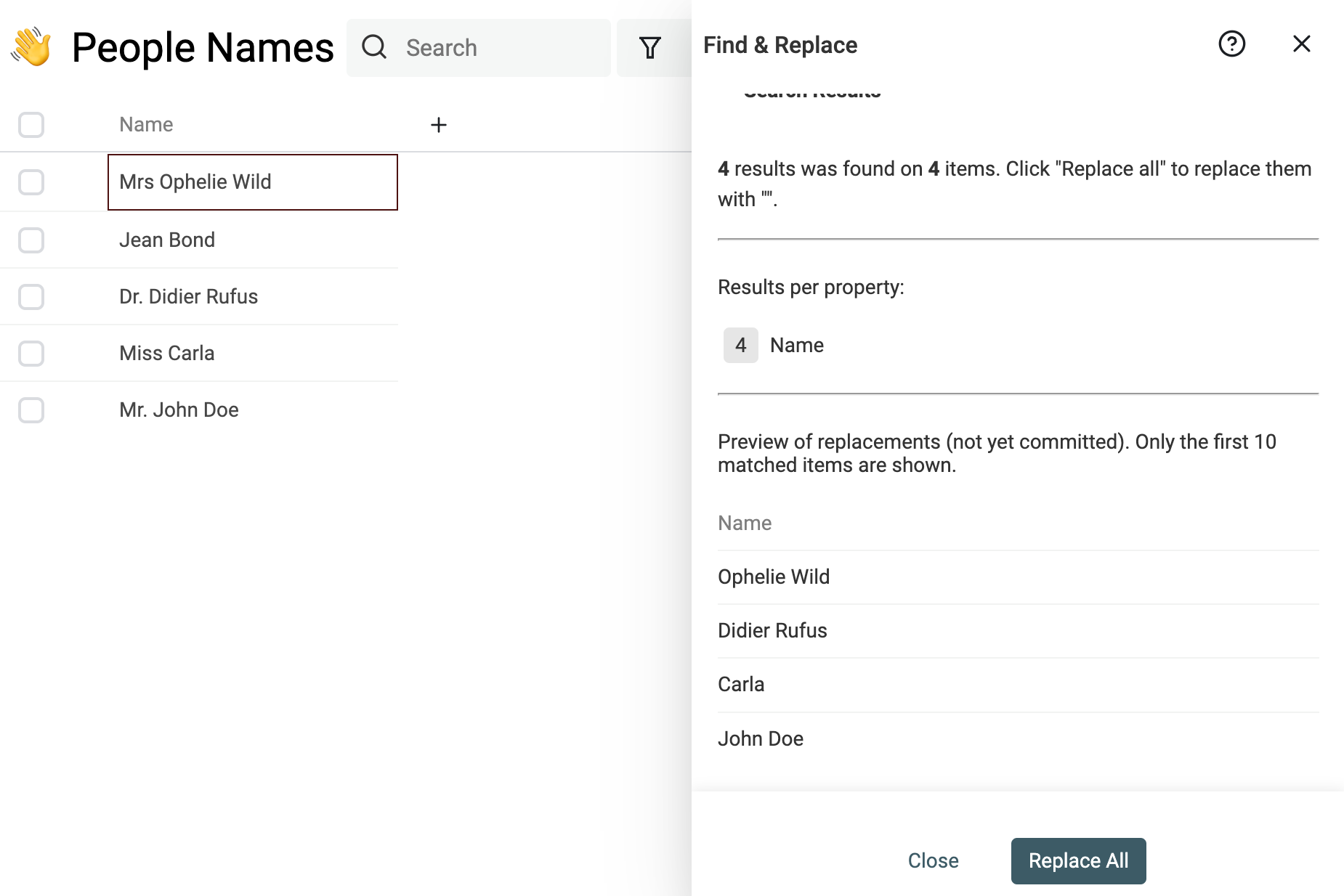
Hinweis Wenn Du mit Regular Expressions nicht vertraut bist, kontaktiere uns einfach – wir helfen Dir beim Cleaning.
Full Name in Bestandteile parsen
Datablist ist mehr als ein Data-Cleaning-Tool und bietet auch Data Enrichment. Beispiele dafür sind Lead Enrichments oder CSV-Übersetzungen via Deepl.
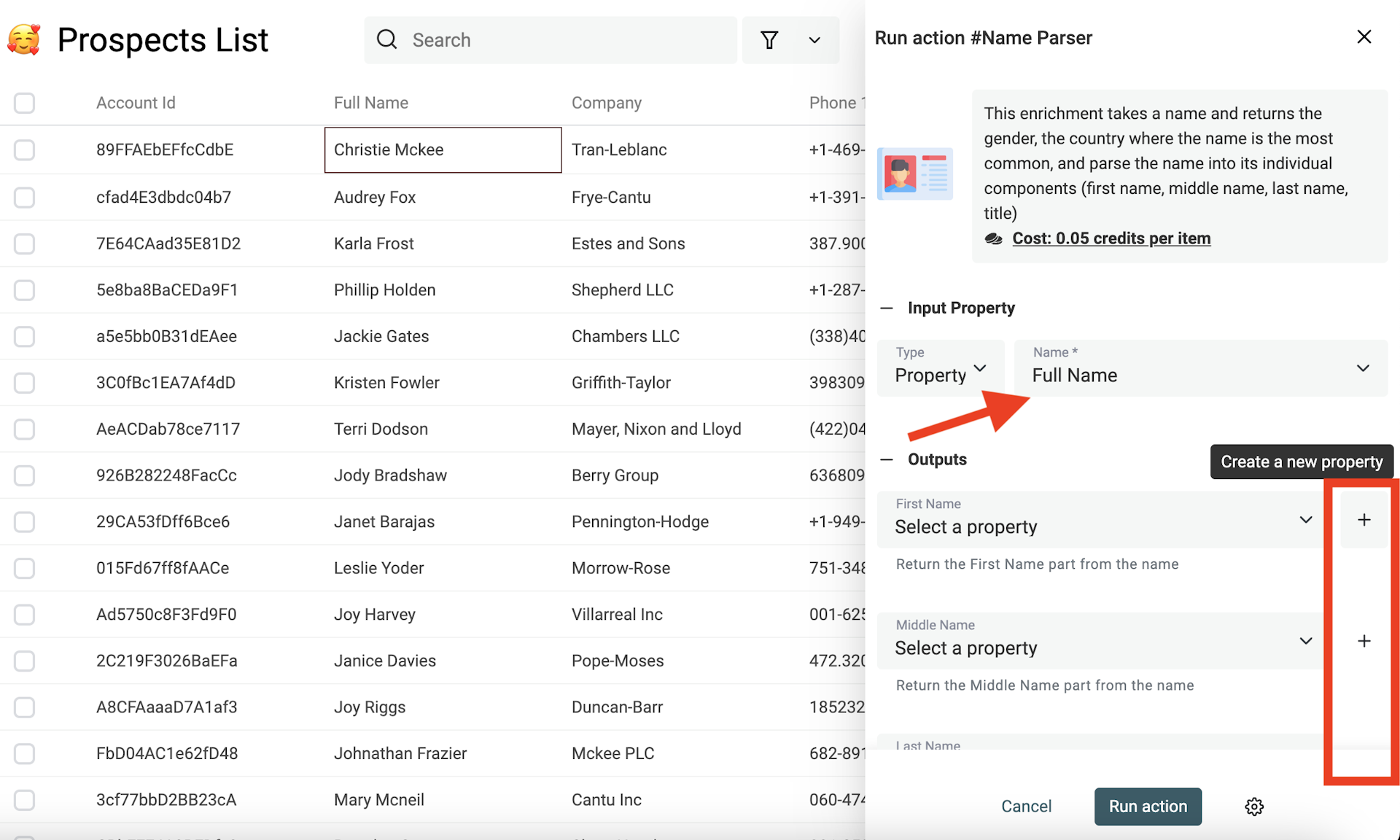
Der Name Parser ist ein perfektes Enrichment, um Personennamen zu bereinigen. Er nimmt einen vollständigen Namen und gibt die Bestandteile zurück: Vorname, zweiter Vorname, Nachname. Zusätzlich liefert er das wahrscheinlichste Geschlecht und das häufigste Land für den Namen.
Dazu nutzt er statistische Daten, um Full Names zu splitten.
Öffne dazu das "Enrich Menu" über die Buttons oben.
Wähle anschließend "Name Parser".

Wähle dann die Property mit den Namen aus und mappe (oder erstelle) neue Properties für das Ergebnis. Die Full-Name-Property selbst wird nicht geändert – nur die Output-Properties werden mit den Parsing-Ergebnissen befüllt.
Firmennamen normalisieren
Auch bei Firmennamen kannst Du „Noise“ entfernen – also Prefixes, Suffixes, Stop-Words, regionale Zusätze usw., die gutes Matching verhindern.
Ein klassisches Beispiel: Suffixes wie "Inc." oder "GmbH" entfernen.
Nutze dafür diesen Regular Expression im Find & Replace tool:
,?\s(llc|inc|incorporated|corporation|corp|co|gmbh|ltd).?$
und ersetze ihn durch einen leeren String.

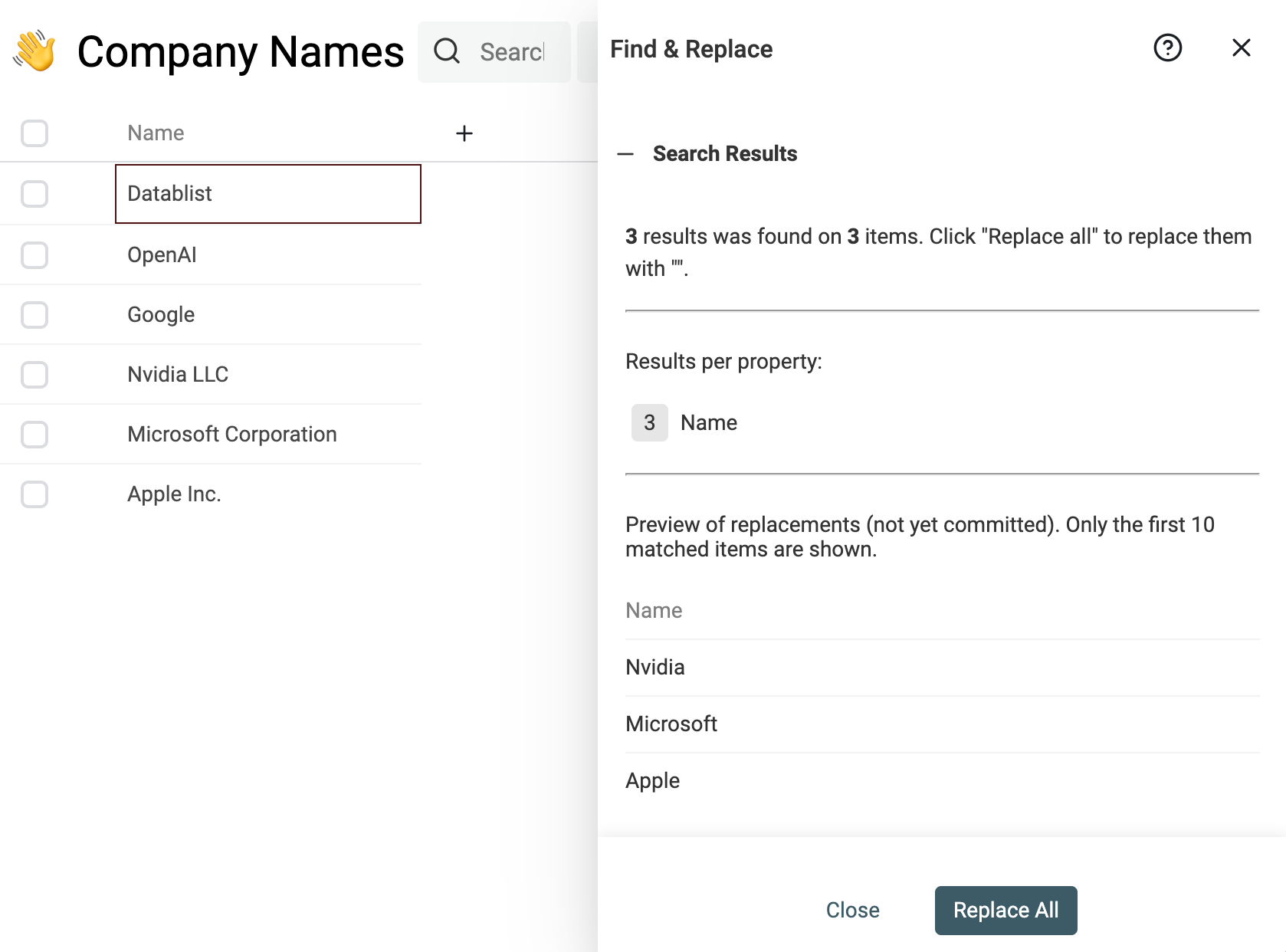
Firmennamen (und auch Adressen) über alle Datasets hinweg zu normalisieren ist wichtig, damit alles in einem Standardformat vorliegt.
Straßennamen normalisieren
Wenn Du Data Matching auf Postadressen machst, ist Street-Name-Normalisierung zentral. Adressen werden mit Abkürzungen, Richtungszusätzen oder Zahlen-Suffixes geschrieben. Ohne Normalisierung taucht dieselbe Straße plötzlich in mehreren Varianten auf – und Matching wird unnötig schwer.
Beispiel: Main 9 St, Main 9TH St., und Main 9th Street sind dieselbe Straße. Oder Washington Blvd und Washington Boulevard.
Das allein über Fuzzy-Algorithmen zu lösen, ist ineffizient: Zwischen Washington Blvd und Washington Boulevard sind viele Zeichen unterschiedlich. Die Similarity Distance (z.B. mit Fuzzy-Matching-Algorithmen) wäre entsprechend hoch.
Besser ist es, Straßennamen vorher zu normalisieren. Ein konsistentes Format sorgt für konsistente Matches.
Datablist bietet Street-Name-Normalisierung für englische Straßenformate (Abkürzungen, Hausnummern etc.).
Hinweis
Die Street-Name-Normalisierung funktioniert für gesplittete Adressen. Die Street-Info muss in einer eigenen Property stehen. Full-Address-Werte funktionieren nicht.
Klicke im "Clean" menu auf "Normalize Street Names".
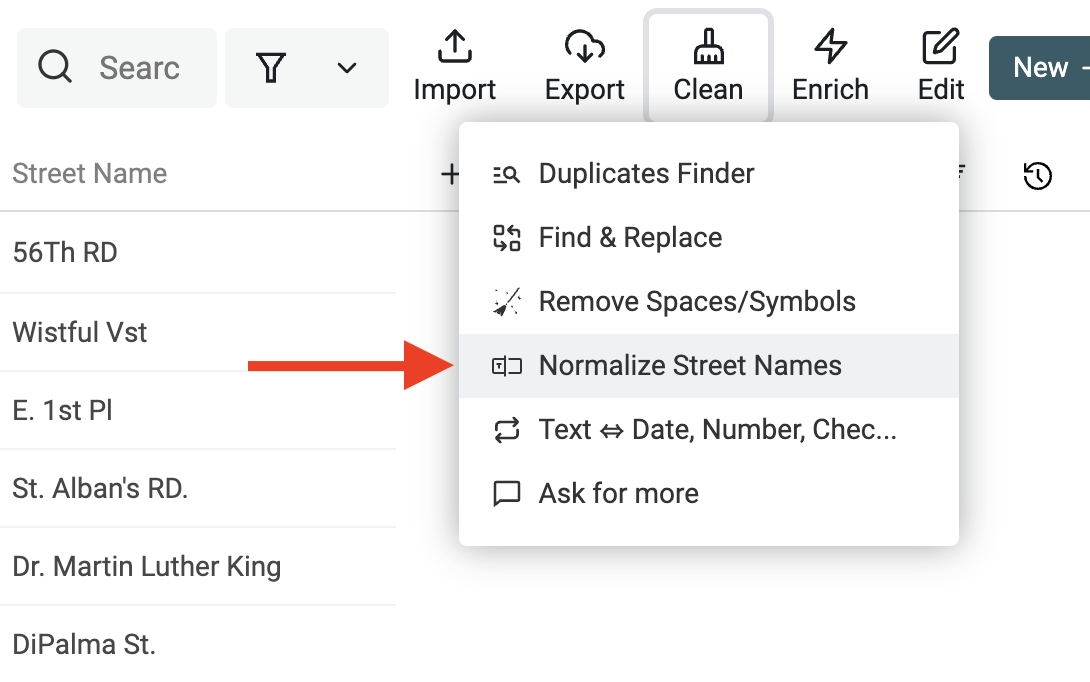
Wähle dann die Property mit den Straßennamen und "Normalize english street names".
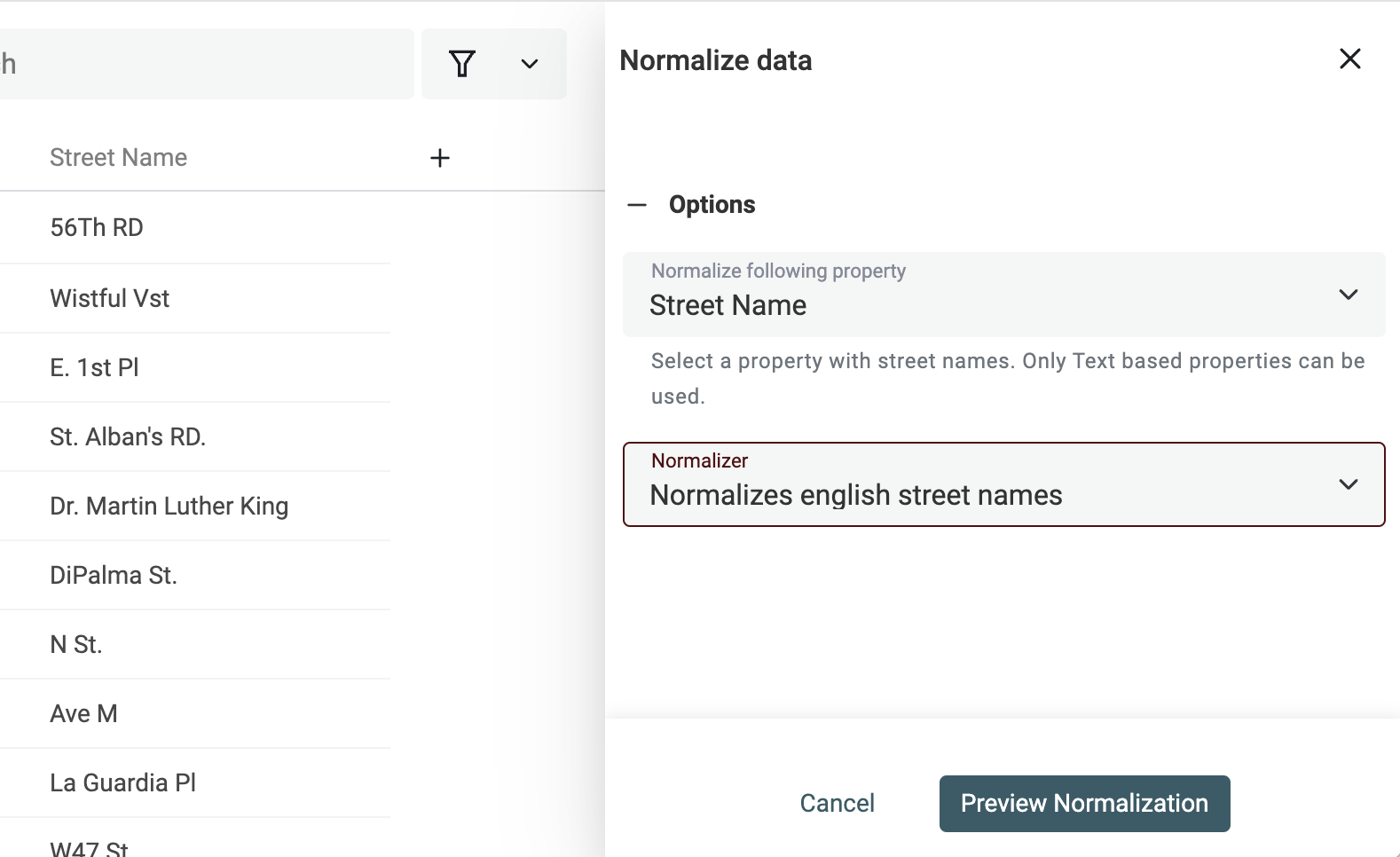
Prüfe die Preview und klicke auf "Run".
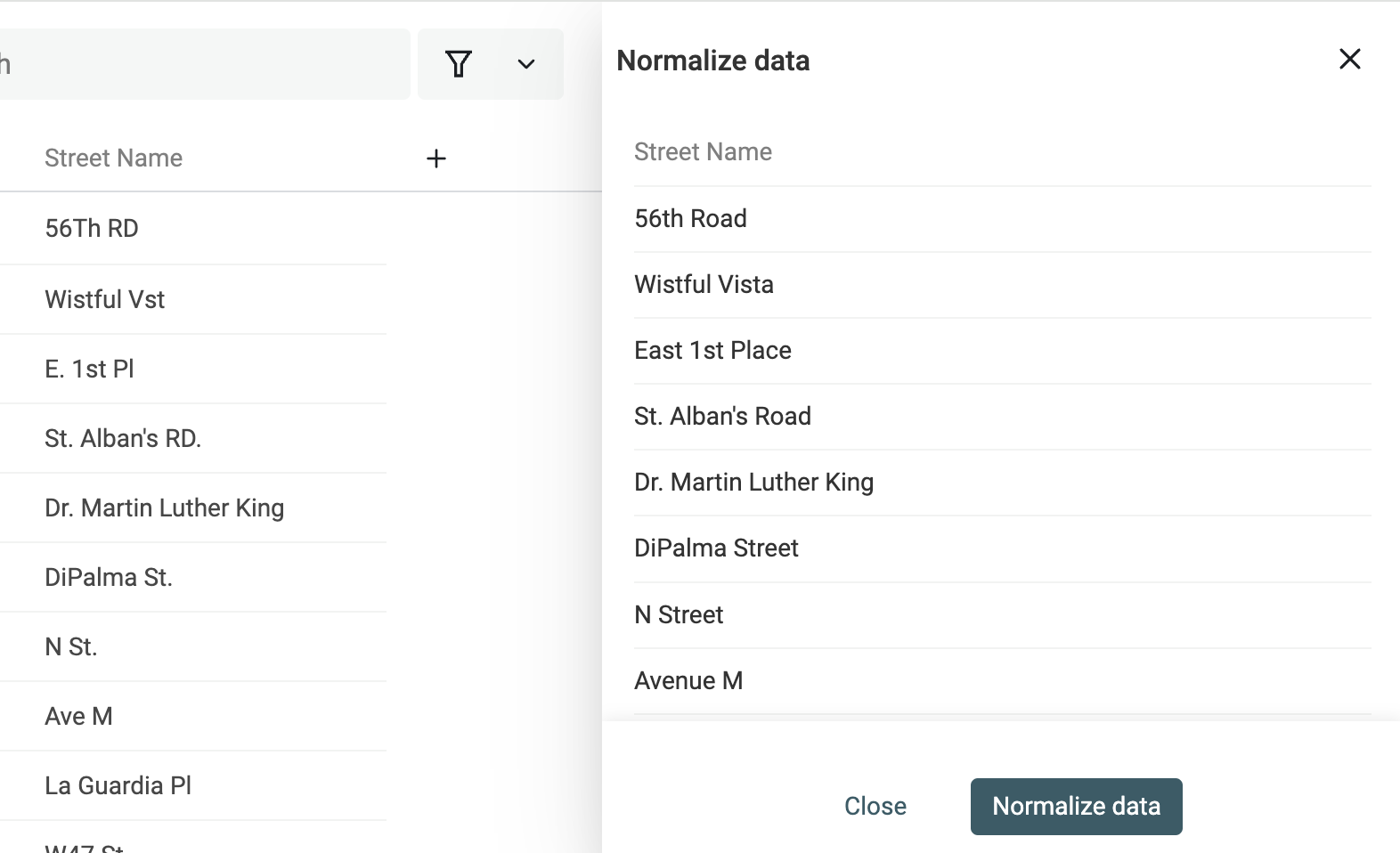
Schritt 3: Records innerhalb oder über mehrere Collections matchen
Jetzt, wo Deine Daten sauber und normalisiert sind, geht’s ans eigentliche Data Matching. Ziel in diesem Schritt: ähnliche Records zu Gruppen zusammenfassen.

Datablist bietet zwei Wege, Records zu vergleichen:
- Selected properties comparison – das ist der Standardfall. Du definierst, welche Properties verglichen werden sollen. Dieser Modus funktioniert auch collection-übergreifend.
- All Properties comparison – In diesem Modus identifiziert und entfernt der Datablist Duplicates Finder Records, die exakt identisch sind. Sie müssen für alle Properties die gleichen Werte haben. Wenn eine Property leer ist, werden Records nicht gematcht.
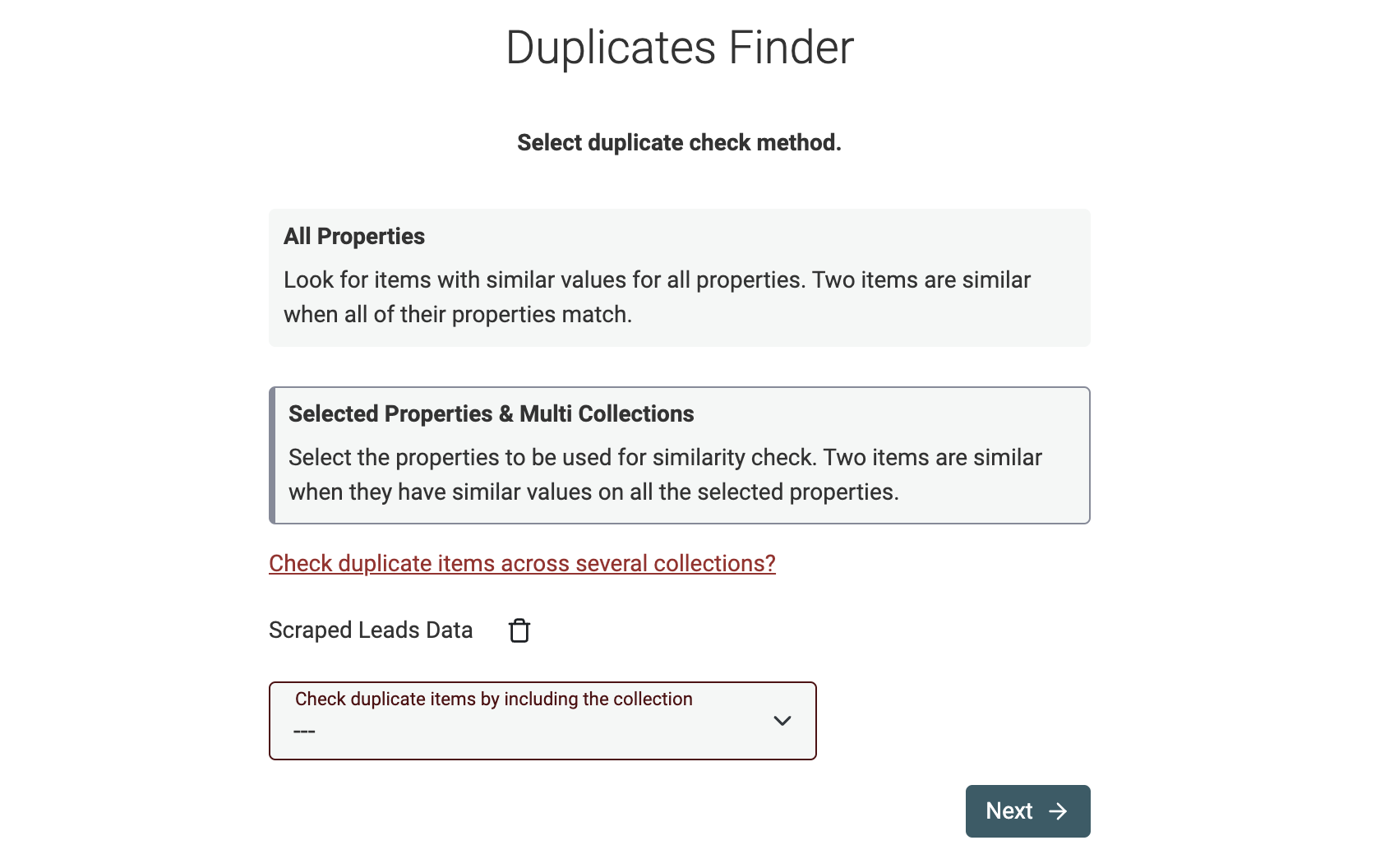
Properties fürs Matching auswählen
Für den Rest dieses Guides nutzen wir den Modus "Selected Properties & Multi Collections".
Als Nächstes wählst Du die Properties aus, die fürs Data Matching verwendet werden. Wenn Du im Schritt davor mehrere Collections ausgewählt hast, wirst Du gebeten, pro Collection ein Mapping festzulegen.
Hinweis
Datablist versucht, Properties über Collections hinweg automatisch anhand ihrer Namen zu mappen.
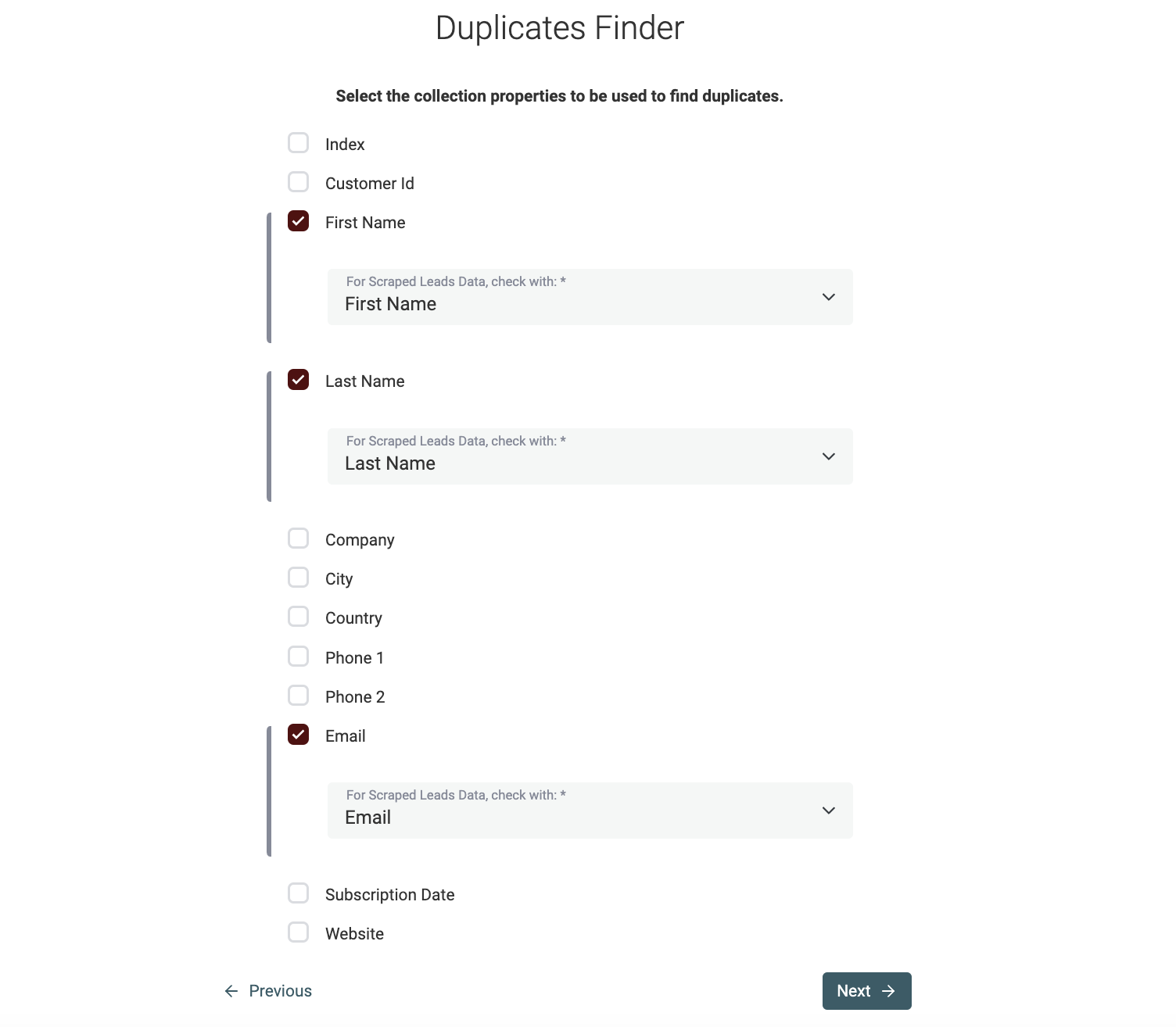
Matching-Algorithmus auswählen
Im nächsten Schritt werden die ausgewählten Properties gelistet, und Du konfigurierst die Vergleichsalgorithmen.
Datablist unterstützt folgende Matching-Algorithmen:
-
Exact – Empfohlen für Nicht-Text-Properties wie DateTime, Number, Boolean usw. Bei Text kannst Du zusätzlich entscheiden, ob der Vergleich case-sensitive sein soll. Der Exact-Algorithmus entfernt außerdem führende und trailing Spaces.
-
Smart – Preprocesses Deine Items, um leichte Variationen zu matchen. Matcht z.B. URLs mit unterschiedlichen Protokollen. Außerdem berücksichtigt er Wortreihenfolge und Satzzeichen. "John-Doe" und "Doe John" matchen.
-
Phonetic with Double Metaphone algorithm – Datablist implementiert den Double Metaphone Algorithmus für phonetic matching. Dabei werden Wörter in Codes umgewandelt, die ihre Aussprache repräsentieren. Zwei ähnlich klingende Wörter bekommen denselben Double-Metaphone-Code.
-
Fuzzy matching with distance algorithms – Datablist unterstützt Fuzzy Matching mit den Distanzen Jaro-Winkler und Levenshtein. Hier musst Du einen Similarity Threshold setzen: Je höher der Threshold, desto weniger Abweichung ist erlaubt.
Mehr Details zu den Algorithmen findest Du in unserer Doku.
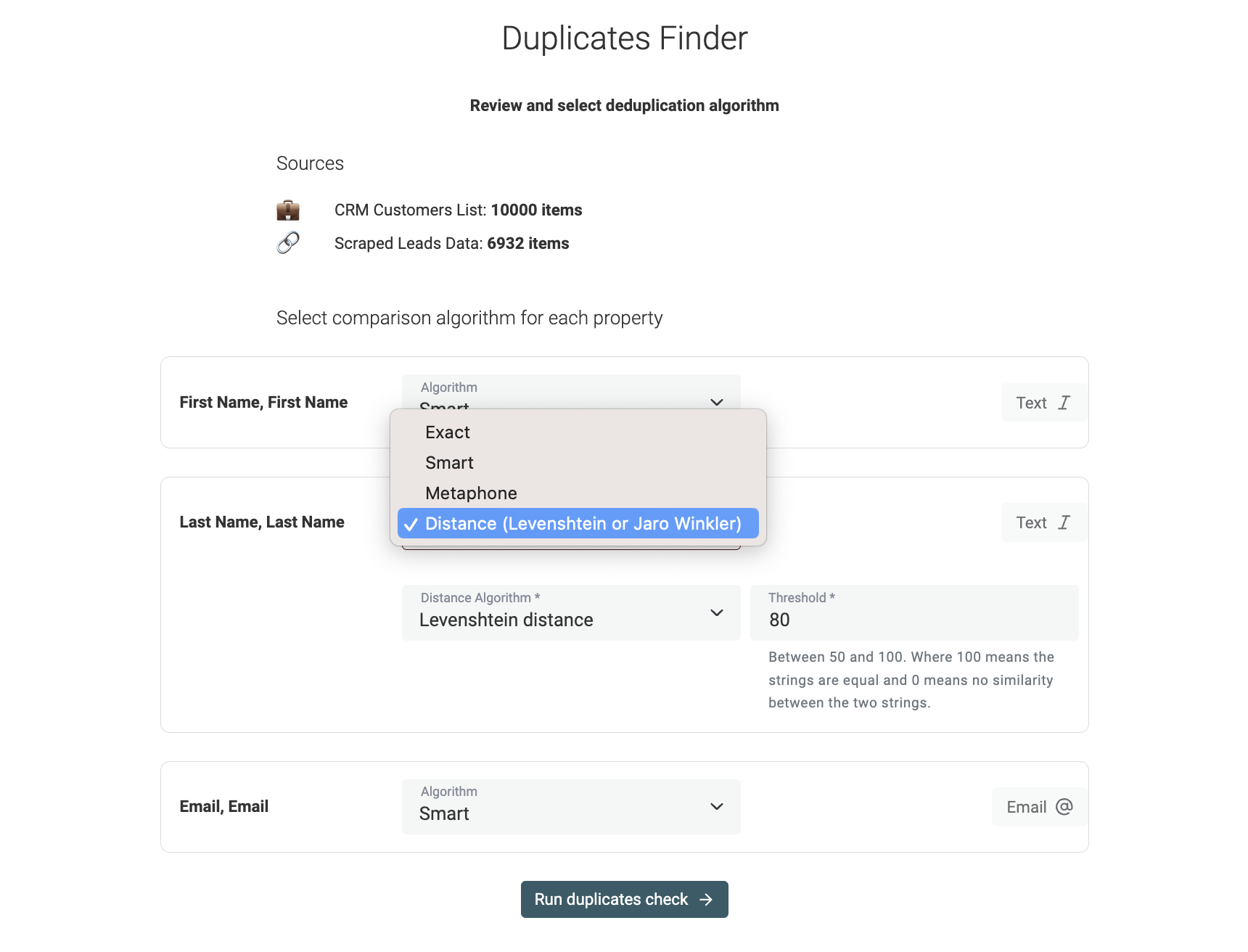
Hinweis
- Smart, Phonetic und Fuzzy gelten nur für textbasierte Properties (inkl. Email, Text, LongText.).
- URL-Properties sind nur mit Exact und Smart kompatibel.
Schritt 4: Matching-Gruppen entfernen oder mergen (Deduplication)
Der Datablist Duplicates Finder liefert Dir innerhalb weniger Sekunden eine Liste mit Matching-Gruppen.
Automatisches Mergen bei Deduplication in einer Collection
Das Datablist Data Matching tool bringt einen fortgeschrittenen Algorithmus mit, um Duplikate zu mergen. Es gibt zwei Modi:
- Non-conflicting items merging (siehe unten)
- Merge conflicting items using text concatenation or value dropping (siehe unten)
Hinweis:
Diese Funktion gibt es nur bei Deduplication innerhalb einer einzelnen Collection. Bei Multi-Collection-Deduplication können sich die Datenstrukturen zwischen den Collections unterscheiden.
Auto-Merging ohne Datenkonflikte
Datablist findet automatisch alle Duplikate, die sich mergen lassen, ohne dass Informationen verloren gehen.
So funktioniert’s:
- Wenn alle Duplicate Items in allen Properties identische Werte haben, bleibt nur ein Item übrig, die anderen werden gelöscht.
- Wenn Duplicate Items sich ergänzen, wird das Item mit den meisten Informationen als Primary Item gewählt und mit Werten aus den anderen Items aufgefüllt. Danach werden alle Items außer dem Primary Item gelöscht.
- Wenn Duplicate Items in Properties widersprüchliche Werte haben, werden diese Gruppen fürs manuelle Mergen übersprungen.
Auto-Merging mit Konfliktauflösung
Beim Auto-Merging erkennt der Datablist Duplicates Finder automatisch konfliktbehaftete Properties. Ein Konflikt liegt vor, wenn zwei Items für eine Property unterschiedliche Werte haben. Um trotzdem mergen zu können, hast Du zwei Optionen:
- Combine properties values – Werte werden per Delimiter zusammengefügt. Beispiel: Wenn zwei unterschiedliche "Phone"-Werte existieren, kannst Du beide mit Semikolon concatenaten. Perfekt für E-Mail-Adressen, Telefonnummern, Notes usw.
- Drop properties values – Bei Nicht-Text-Properties kannst Du nur einen Wert behalten und den konflikthaften Wert droppen. Beispiel: Zwei DateTime-Werte lassen sich nicht sinnvoll concatenaten – also musst Du einen behalten. Das ist auch hilfreich bei externen Identifiers: Wenn Du Daten fürs CRM bereinigst, muss die externe Account-ID eindeutig bleiben und darf keine concatenated String sein.
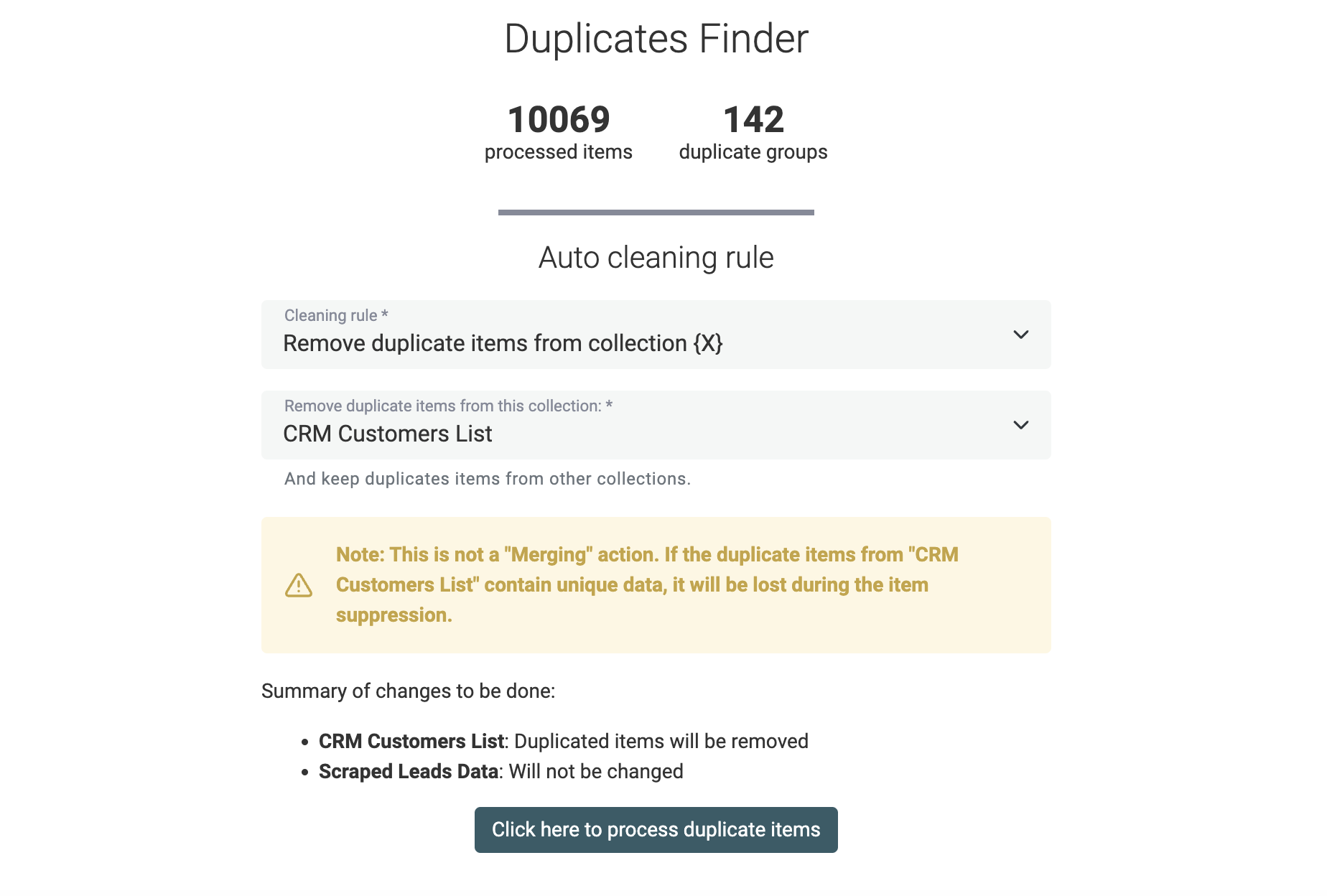
Cleaning Rules für Multi-Collection Data Matching
Wenn Du das Datablist Data Matching tool auf mehrere Datasets anwendest, ist Auto-Merging nicht verfügbar. Deine Collections können unterschiedliche Properties und Strukturen haben.
Stattdessen bietet Datablist eine Cleaning-Option, um Duplicate Items in allen bis auf einer Collection zu entfernen. So stellst Du Uniqueness über Deine Datasets hinweg sicher.
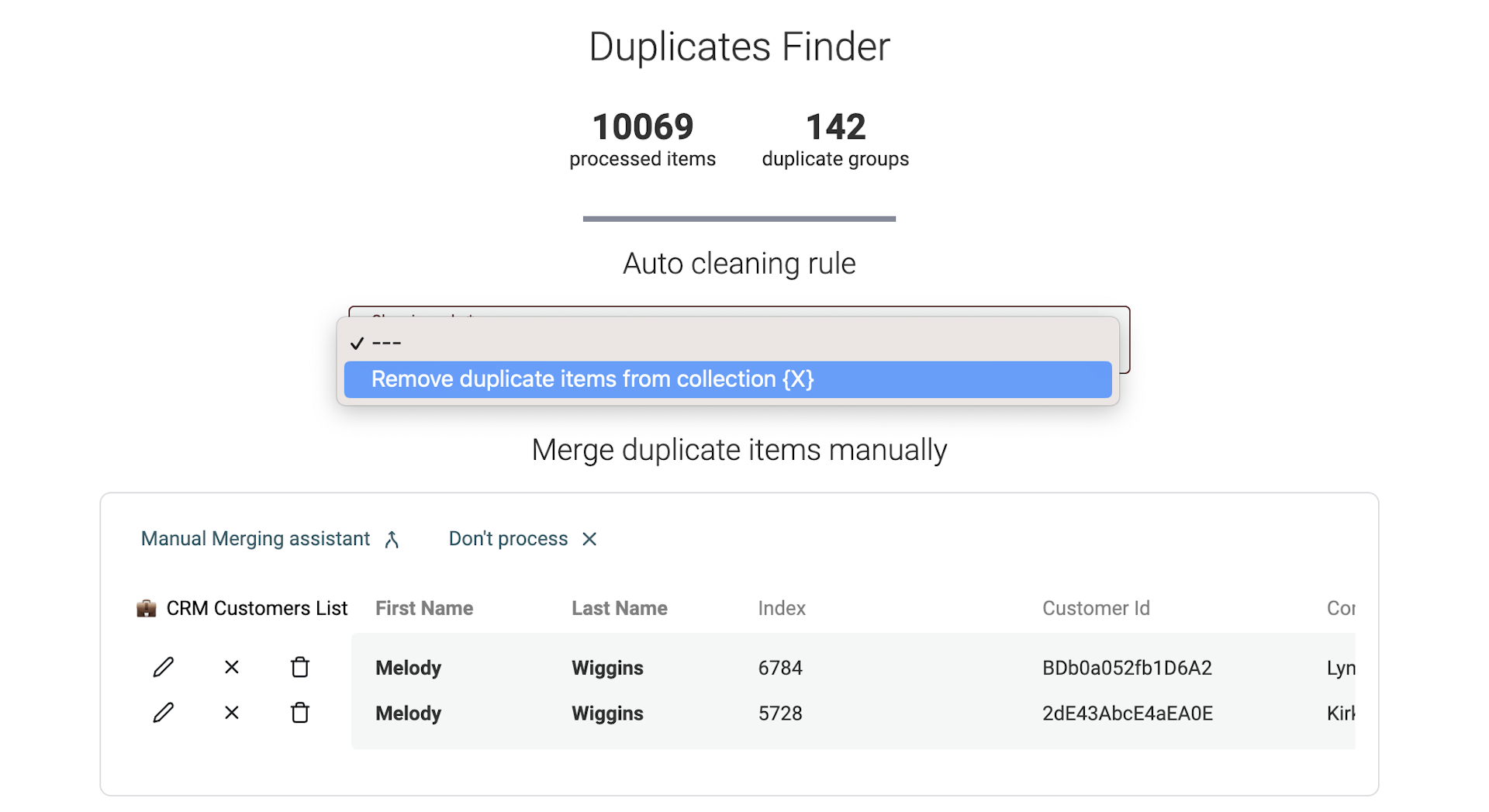
Vor dem Ausführen siehst Du eine Preview der Änderungen.
Manuelles Mergen mit dem Merging Assistant
Für die verbleibenden Duplicate Records gibt es einen manuellen Merging Assistant.
Klicke dazu bei jeder Duplicate Group links auf "Manual Merging Assistant".
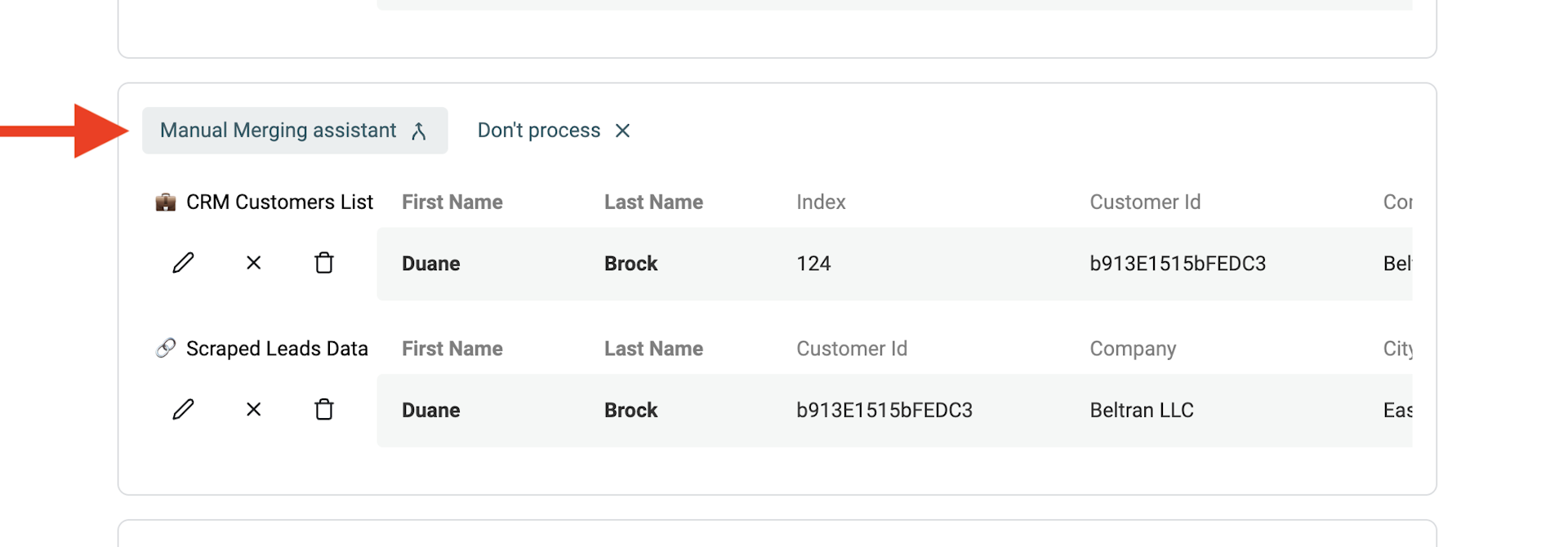
Es öffnet sich ein Merge-Tool: Rechts siehst Du das "Primary Item", links die übrigen Duplicate Items als "Secondary Items". Datablist wählt automatisch das Item mit den meisten Daten als "Primary item".
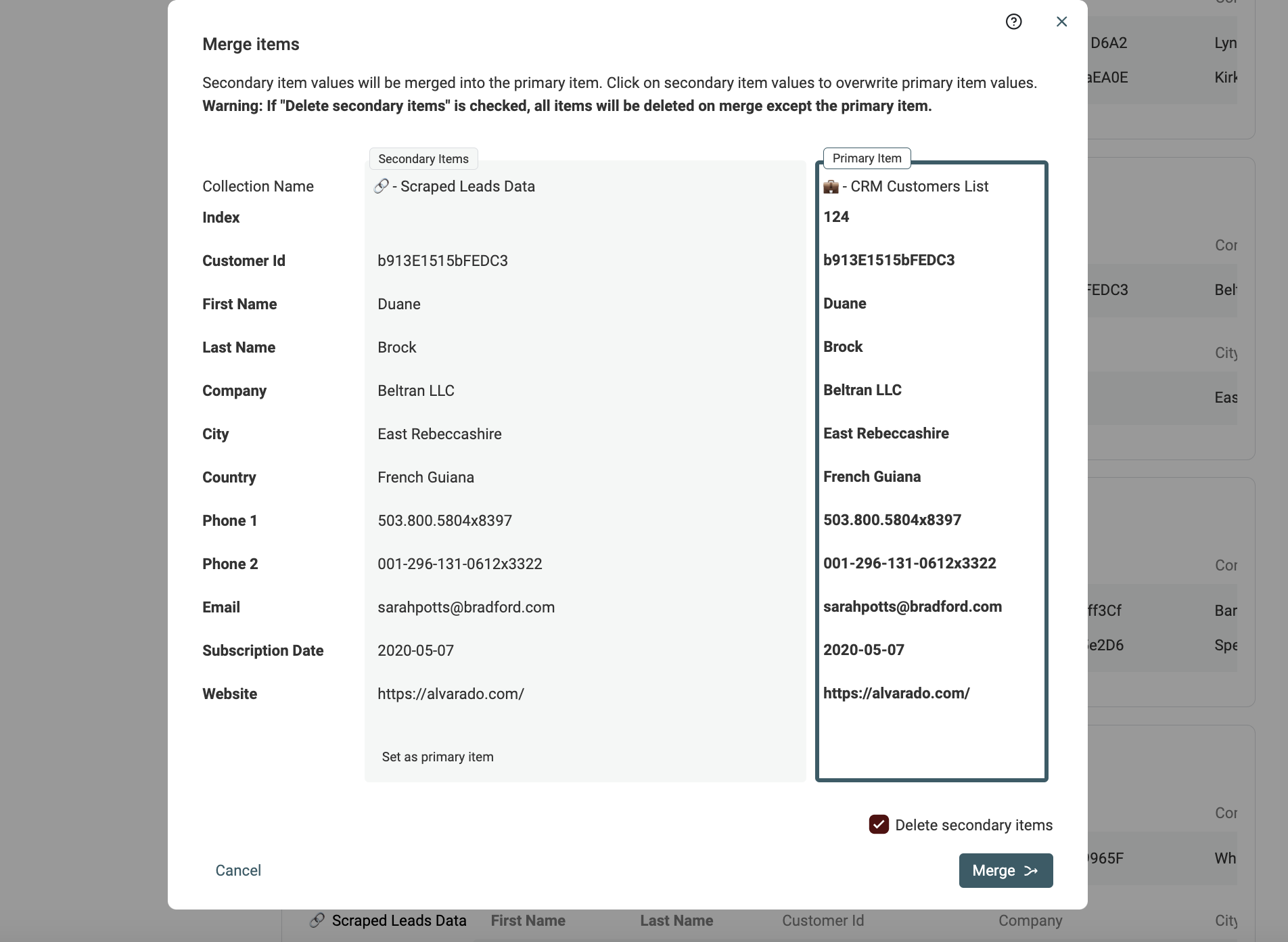
Wenn möglich, werden Property Values aus Secondary Items automatisch vorselektiert, um sie ins Primary Item zu mergen. Wenn mehrere Werte kollidieren, musst Du entscheiden, welcher Wert bleiben soll.
Wenn das Ergebnis passt, klicke auf den Button Merge, um den Merge zu bestätigen. Alle Secondary Items werden gelöscht, sodass nur ein kombiniertes Item übrig bleibt.
Hinweis Der manuelle Merging Assistant ist auch bei Multi-Collection-Deduplication verfügbar, wenn die Collections eine ähnliche Datenstruktur haben (gleiche Properties).
Duplicate Groups herunterladen und extern mergen
Zum Schluss bietet das Datablist Data Matching tool einen Export der erkannten Duplicate Groups. Du kannst eine CSV- oder Excel-Datei exportieren, in der alle Duplicate Items direkt hintereinander gelistet sind.
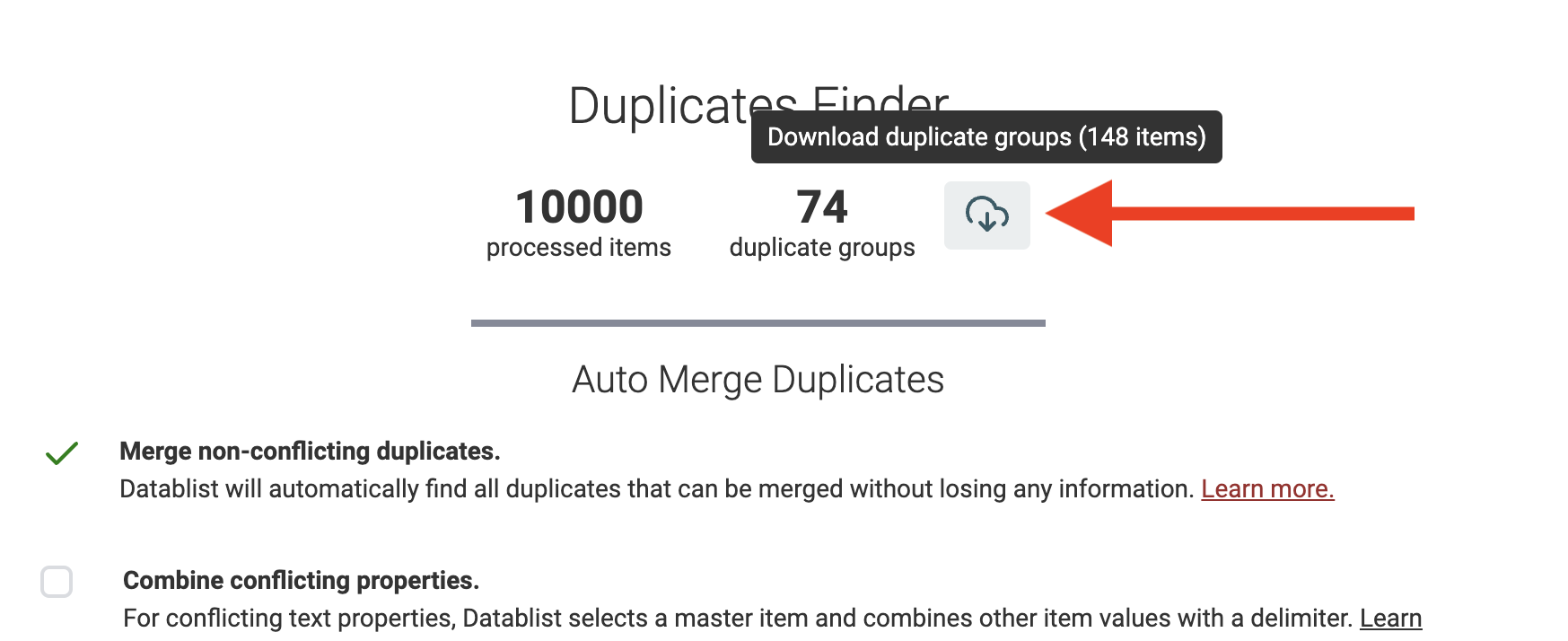
Nutze den Export, um Records mit einem anderen Tool (z.B. Spreadsheet) zu bereinigen oder tiefere Analysen zu machen.
FAQ
Was ist Data Matching?
Data Matching, auch bekannt als Record Linkage oder Deduplication, ist der Prozess, bei dem zusammengehörige Records innerhalb eines Datasets oder über mehrere Datasets hinweg identifiziert und verknüpft werden. Das Hauptziel ist bessere Datenqualität, mehr Accuracy und konsistente Daten, indem doppelte oder sehr ähnliche Einträge erkannt und zusammengeführt werden, die dieselben Entities/Personen/Objekte abbilden.
Das ist besonders hilfreich, wenn in Datasets über Zeit Duplikate entstehen – oder wenn Du mehrere Listen mit ähnlichen oder überlappenden Feldern zusammenführen willst.
Data Matching kann auf eindeutige Felder wie E-Mail-Adresse, Website-URL oder Identifikationsnummern setzen. Oder es nutzt eine Kombination nicht-eindeutiger Attribute (z.B. Name, Geburtsdatum, Firmenname oder Standort), um einen Similarity Score zwischen Records zu berechnen.
Wie schnell ist das Datablist Data Matching Tool?
Das Datablist Data Matching tool lädt Deine Datasets in den Arbeitsspeicher, um die Analyse durchzuführen. Es ist für Datasets unter 1 Million Records gedacht und führt die meisten Data-Matching-Analysen in wenigen Minuten durch.
Brauche ich technische Skills für Data Matching?
Nein. Datablist ist eine No-Code-Lösung, gemacht für alle – von Data Analysts bis zu Marketing- oder Sales-Teams.
Wann sollte man Data Matching einsetzen?
Data Matching wird in vielen Bereichen eingesetzt, z.B. Finance, Healthcare, Marketing und Customer Management – überall dort, wo verlässliche Daten für Entscheidungen oder für die Integration mit anderen Tools entscheidend sind.
Der Prozess unterstützt z.B. Fraud Detection, das Zusammenführen von User Profiles und Data Enrichment aus mehreren Quellen.
Was kommt als Nächstes?
Wenn Du Dich für Data Cleansing interessierst, könnten diese Guides als Nächstes spannend für Dich sein: