
Chaque scraper basé sur du code est conçu pour la structure d’un site web précis. Dès que vous utilisez ce même script sur un autre site, les sélecteurs ne correspondent plus, la page revient vide et le script casse.
Un prompt ne casse pas de cette façon. Vous décrivez simplement ce que vous voulez avec des mots clairs, et un agent IA relit chaque page à neuf, au lieu de s’appuyer sur des règles codées en dur pour une seule mise en page.
C’est ce changement qui permet aujourd’hui de scraper n’importe quel site sans code, et d’extraire des données propres depuis presque n’importe quelle page en quelques minutes au lieu de plusieurs heures.
📌 Résumé pour celles et ceux qui vont à l’essentiel
L’idée clé : vous n’avez pas besoin d’un scraper différent pour chaque site. Les scrapers basés sur du code sont liés à la structure d’un seul site, alors qu’un agent d’AI scraping s’adapte à plusieurs sites à partir d’un unique prompt en langage naturel.
Cet article explique comment un seul outil peut désormais scraper presque n’importe quel site web, puis vous montre comment le faire avec l’AI Scraping Agent de Datablist.
Ce que vous allez retenir :
- Pourquoi les scrapers en code et les modèles prédéfinis cassent d’un site à l’autre
- Comment l’AI scraping se compare aux anciennes méthodes no-code
- Une méthode pas à pas pour scraper n’importe quel site web
Ce que ce guide couvre
- Ce que veut vraiment dire “scraper n’importe quel site” sans code
- AI scraping vs anciennes méthodes no-code et code
- Ce qu’il faut rechercher dans un outil capable de fonctionner sur tous les sites
- Le pas à pas avec l’AI Scraping Agent de Datablist
- Questions fréquentes
Ce que “scraper n’importe quel site” veut vraiment dire
Il y a encore deux ans, scraper un site sans code signifiait généralement utiliser un template prêt à l’emploi derrière un site populaire. Depuis que l’IA est devenue accessible à tous, la réalité a changé.
Aujourd’hui, cela signifie exactement ce que cela dit : pointer un outil vers presque n’importe quelle page publique et récupérer des données propres et structurées, sans écrire le moindre script.
Pourquoi le scraping de sites web nécessitait du code auparavant
Les scrapers classiques sont des scripts mappés sur le HTML d’un site précis. Ils ciblent des sélecteurs, des noms de classes et des logiques de pagination spécifiques à cette page-là.
Cela fonctionne… jusqu’au moment où la cible change. Si vous utilisez le même script sur un autre site, rien ne correspond plus, et vous obtenez soit des lignes vides, soit une erreur.
Ce qu’un web scraper no-code fait différemment
Un web scraper no-code supprime tout simplement l’étape du script. Au lieu d’écrire du code, vous configurez ce que vous voulez via une interface visuelle ou des instructions écrites.
C’est la catégorie que la plupart des gens connaissent déjà, même si tous les outils de cette famille sont loin de se valoir. C’est pourquoi nous allons les diviser en deux sous-catégories :
- Les outils en point-and-click et à templates : vous sélectionnez des champs sur une page ou vous chargez un modèle prêt à l’emploi pour un site populaire.
- Les agents d’AI scraping : vous décrivez les données attendues en langage naturel, et l’agent détermine comment les extraire.
Les deux suppriment le code, mais un seul supprime vraiment la dépendance à un site populaire ou prévisible.
Pourquoi vous pouvez désormais scraper n’importe quel site sans code
Le vrai changement vient de la manière dont l’IA lit une page. Un AI scraping agent analyse le contenu de la page ainsi que votre prompt, puis décide quoi extraire.
Cette approche supprime la dépendance aux sélecteurs codés en dur, et c’est précisément ce qui la rend si puissante : il n’y a plus de règle fixe qui casse quand la mise en page change, puisque l’agent relit la page à chaque exécution.
AI scraping vs anciennes méthodes pour scraper sans code
Le no-code ne désigne pas une seule méthode, et les différences deviennent évidentes dès qu’un site est de niche ou qu’une page populaire change de structure.
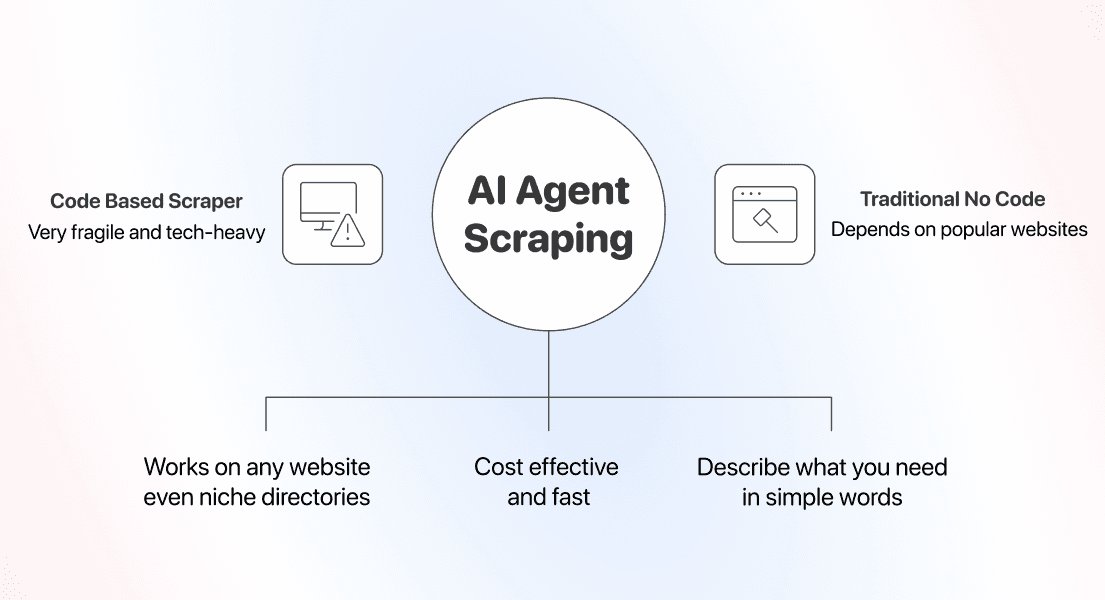
Scrapers basés sur du code : puissants, mais liés à un seul site
Écrire votre propre scraper en Python ou JavaScript vous donne un contrôle total. Vous décidez de chaque sélecteur, de chaque règle de pagination, de chaque retry et de chaque timeout.
Mais chaque script est conçu pour un site unique, nécessite un développeur pour être créé, et casse dès que ce site modifie sa mise en page. Oui, les scrapers basés sur du code sont peu coûteux à exécuter, mais ils impliquent un autre type de coût : un script par site, un développeur disponible à la demande, et de la maintenance à chaque mise à jour du site ciblé.
Pour une équipe qui scrape de nombreux sites différents, le coût grimpe très vite. Cinq cibles peuvent signifier cinq scripts et cinq problèmes distincts à corriger chaque semaine.
Outils en point-and-click et à templates : simples, jusqu’à ce que le site soit trop spécifique
Les outils à templates et en point-and-click ont été les premiers vrais scrapers no-code. Ils fonctionnent bien sur les sites populaires, parce que quelqu’un a déjà construit le template, ou parce que la page est assez simple pour être configurée à la main.
Les vraies limites apparaissent dès que vous voulez scraper des pages moins connues, comme des annuaires de niche, des boutiques régionales ou des mises en page inhabituelles, qui n’ont souvent aucun template prêt à l’emploi.
Et comme les scrapers en code, ils dépendent encore d’une structure de page relativement stable. Dès que le site change, les sélections enregistrées cassent, les données cessent de remonter et il faut repartir en maintenance.
AI scraping : un seul prompt qui s’adapte à n’importe quel site
L’AI scraping résout deux problèmes :
- Les configurations sans fin
- Les scrapers qui cassent quand le site cible change de structure
Vous décrivez simplement les données que vous voulez, vous indiquez une URL à l’agent, et il renvoie des lignes structurées.
Comme l’agent lit chaque page au moment du scraping, le même prompt peut fonctionner sur différents sites. Une fiche produit, un annuaire, une page de listings : le workflow, lui, ne change pas.
C’est exactement là que s’inscrit l’AI Scraping Agent de Datablist. Il prend une URL cible et un prompt en langage naturel, pour vous permettre de scraper n’importe quel site sans code et en quelques minutes, plutôt qu’en plusieurs heures. Il facilite aussi beaucoup le data cleaning, car les données extraites arrivent directement dans une feuille où vous pouvez dédupliquer et enrich instantanément.
Nous avons comparé les méthodes de scraping no-code selon les critères les plus importants 👈🏽
Comment choisir un outil pour scraper n’importe quel site sans code
Une fois que vous avez compris qu’un AI Scraper est plus intéressant qu’un scraper conçu site par site, la vraie question devient : quel outil choisir ? Pour moi, tout se joue sur trois critères : la couverture, la fiabilité dans le temps et la simplicité d’utilisation.
Couverture : peut-il gérer les sites de niche et longue traîne ?
La couverture est le premier test. Beaucoup d’outils affirment pouvoir scraper n’importe quel site, alors qu’en réalité ils dépendent surtout d’une bibliothèque de templates préconstruits pour des sites populaires.
La question la plus importante est simple : l’outil peut-il scraper un site qu’il n’a jamais vu ?
Les agents pilotés par prompt réussissent ce test, car ils ne reposent pas du tout sur des templates. Si vos cibles incluent des annuaires de niche ou des sites régionaux, c’est probablement le critère le plus important.
Un moyen rapide de vérifier : testez l’outil sur le site le plus atypique de votre liste, et voyez s’il arrive à le scraper.
Maintenance : casse-t-il à chaque changement de structure ?
La maintenance d’un scraper est souvent le coût dont personne ne parle. Les sélecteurs, les règles de pagination et les proxies cassent dès qu’un site modifie sa structure, et quelqu’un doit passer derrière pour réparer.
Un outil dépendant de règles fixes vous transfère ce travail. Chaque changement de layout devient un mini-chantier de maintenance, et cela ne s’arrête jamais vraiment.
Un agent de scraping piloté par prompt contourne en grande partie ce problème, parce qu’il relit la page à chaque exécution au lieu de faire confiance aux sélecteurs d’hier. Le prompt, lui, reste le même, même si la page évolue.
Simplicité d’utilisation : ce qu’un web scraper no-code devrait vraiment offrir
Le dernier test consiste à voir si vous pouvez réellement l’utiliser sans développeur. Un outil universel n’aide personne dans une équipe de recrutement, d’opérations ou de marketing s’il faut un ingénieur pour le faire tourner.
Jugez-le depuis votre propre contexte. Pouvez-vous écrire un prompt simple, mapper quelques champs, puis exporter le résultat par vous-même ?
C’est exactement pour cela que l’AI Scraping Agent de Datablist a été conçu : écrire un prompt, configurer les champs, puis exporter les données. Pas de code, pas de développeur, pas de configuration spécifique à chaque site.
Si vous hésitez encore sur l’outil le plus adapté à vos cibles, nous avons comparé les meilleurs outils de scraping no-code en détail 👈🏽
Guide étape par étape pour scraper n’importe quel site
Passons maintenant à la partie pratique. Tout ce qui suit se fait directement dans Datablist, la plateforme d’automatisation pensée pour l’AI scraping et le data enrichment.
Vous lui fournissez une URL cible et un prompt simple, et il vous renvoie des données structurées depuis presque n’importe quel site, sans code, en quelques minutes au lieu de plusieurs heures. Sans développeur, sans configuration spécifique à chaque site.
Dans ce tutoriel, nous allons faire deux choses :
- Configurer le scraping et le lancer
- Mettre en place une propriété unique pour éviter d’importer deux fois la même ligne lors des exécutions répétées
Comment scraper n’importe quel site avec l’AI Scraping Agent de Datablist
Pour vérifier cette promesse sur un cas réel, nous allons utiliser l’AI Scraping Agent sur une page catégorie de GymShark, mais chaque étape fonctionne exactement de la même manière sur n’importe quel site web.
Avant de commencer, assurez-vous d’avoir :
- Un compte Datablist
- L’URL de la page que vous voulez scraper
- Une liste claire des champs à extraire
- Des exemples pour les champs qui peuvent prêter à confusion
- Une estimation du nombre de pages à traiter
Étape 1 : créer un compte et une Collection
Commencez par créer un compte sur Datablist.com.
Ensuite, créez une New Collection pour stocker les données que vous allez scraper.
Étape 2 : ouvrir AI Agent - Site Scraper
Dans votre nouvelle collection, cliquez sur See all sources.
Faites défiler la page puis sélectionnez AI Agent - Site Scraper
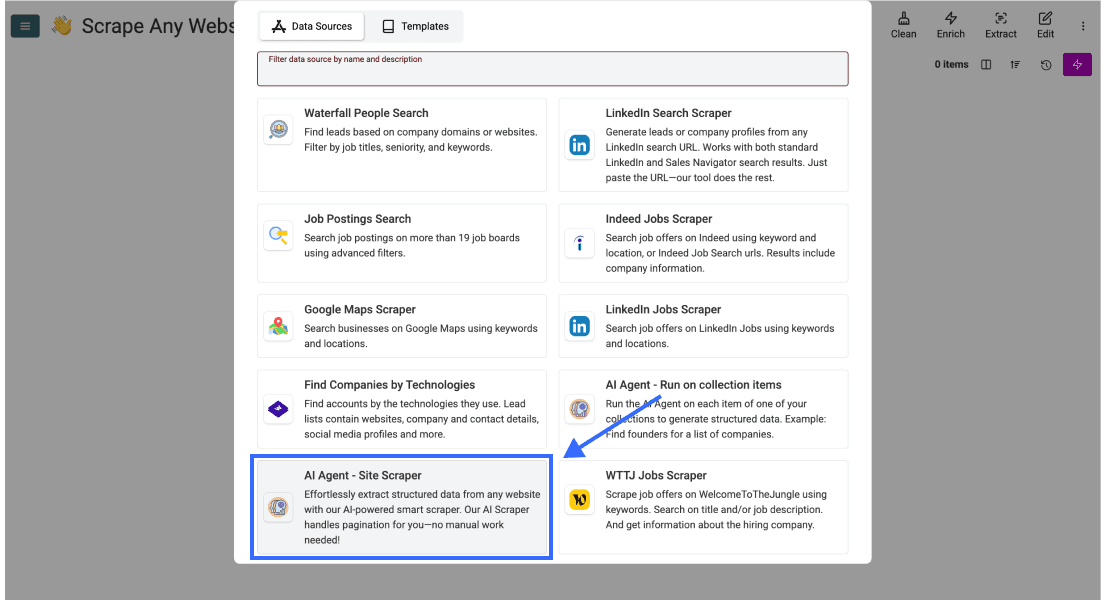
Étape 3 : rédiger votre prompt et configurer la tâche
Collez l’URL cible dans le premier champ. Pour cet exemple, il s’agit d’une page catégorie GymShark, mais vous pouvez scraper le site de votre choix.
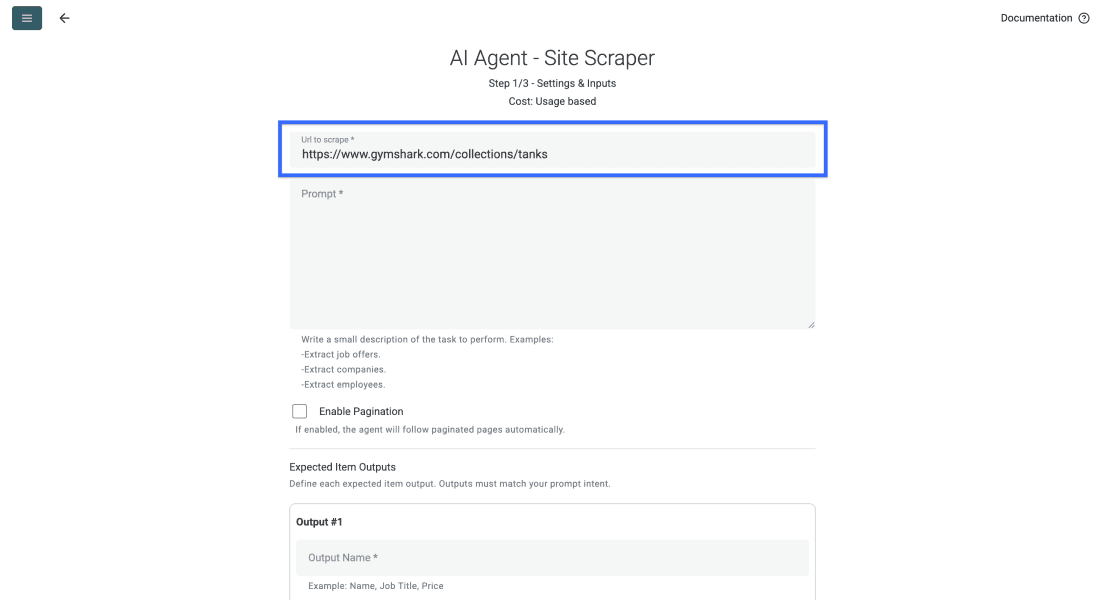
Faites ensuite défiler jusqu’au champ du prompt et décrivez ce que l’agent doit récupérer sur chaque page. Vous trouverez aussi un exemple de prompt ci-dessous.
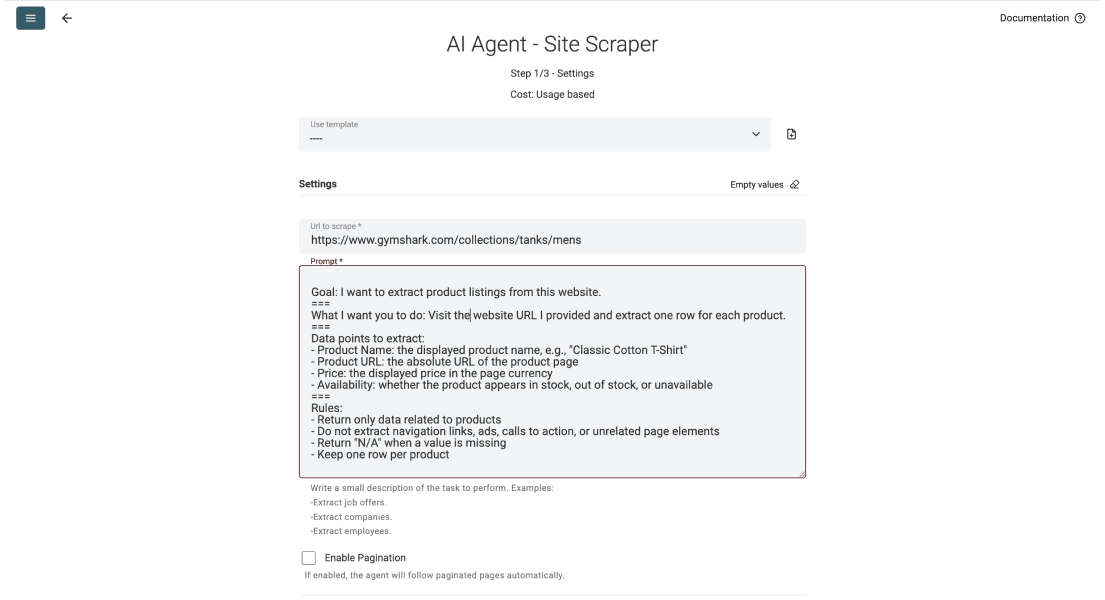
Un bon prompt indique à l’agent quoi extraire, quoi ignorer, et à quoi chaque ligne doit ressembler. Vous pouvez reprendre la structure ci-dessous puis remplacer les champs par les vôtres.
Goal: I want to extract product listings from this website.
.===
What I want you to do: Visit the URL I provide and return one row per product.
.===
Data points to extract:
- Product Name (example: "Classic Cotton T-Shirt")
- Product URL: the absolute link to the product page
- Price: the displayed price in the page currency
- Availability: in stock, out of stock, or unavailable
.===
Mistakes to avoid:
- Return only product data; ignore navigation, ads, and call to actions
- Return "N/A" when a value is missing
- Keep one row per product
L’agent suit beaucoup mieux les consignes lorsque le prompt nomme clairement chaque champ et donne un exemple. Les prompts vagues sont la première raison pour laquelle un scraping revient avec des données brouillonnes.
Suivez ces règles de rédaction de prompts pour agents IA pour obtenir des résultats plus propres 👈🏽
Définissez ensuite le nombre de pages que l’agent doit parcourir.
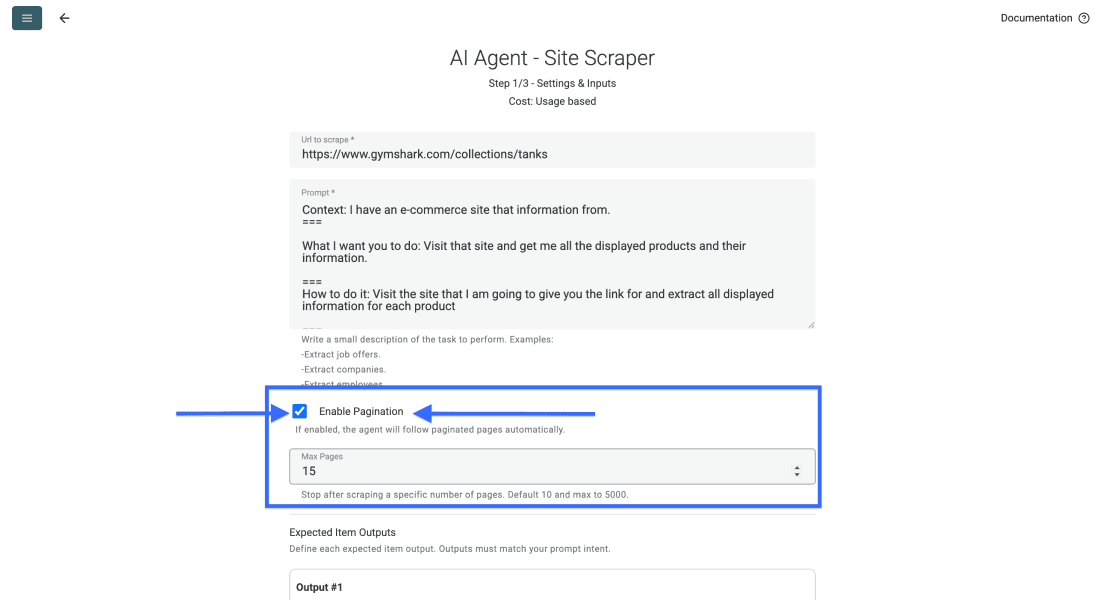
📘 À propos de la pagination sur les pages de listings
La plupart des pages de listings répartissent les résultats sur plusieurs pages. Définissez la limite selon la portion du site que vous souhaitez récupérer. Datablist prend en charge jusqu’à 5 000 pages par exécution.
Une fois le prompt et la limite de pages définis, faites défiler l’écran pour configurer vos champs de sortie.
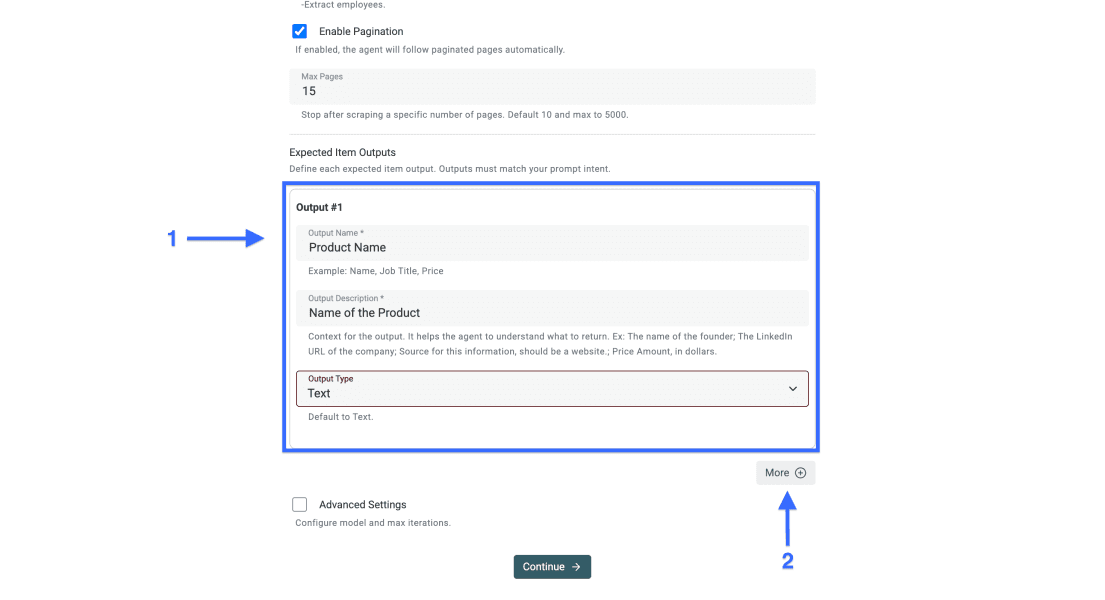
Étape 4 : définir les champs de sortie
Si vous rédigez le prompt vous-même, les champs de sortie doivent refléter exactement les données demandées. Une colonne par champ permet de garder des données propres.
Pour chaque sortie :
- Utilisez le nom du data point comme Output Name
- Ajoutez une Output Description claire, avec un exemple si nécessaire
- Choisissez le bon Output Type, comme texte, nombre, URL ou email
- Cliquez sur More pour ajouter d’autres champs de sortie
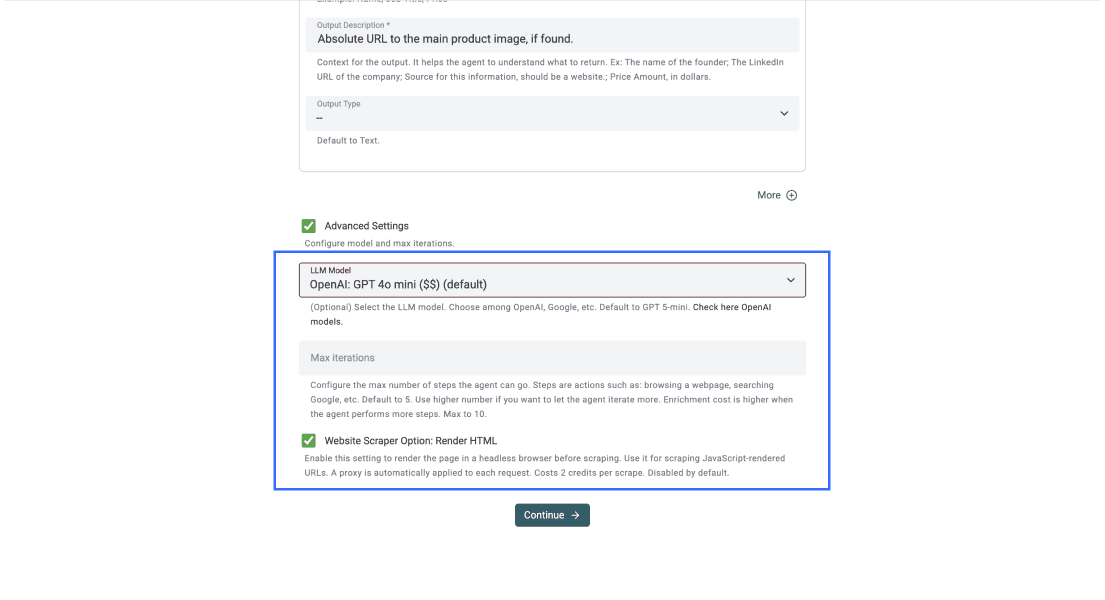
Étape 5 : configurer les paramètres avancés
Une fois vos sorties définies, cochez la case Advanced Settings puis appliquez les paramètres suivants :
- LLM: OpenAI GPT-4o mini, pour le meilleur équilibre entre performance et coût
- Max iterations: 10
- Render HTML: activé, ce qui est essentiel pour les sites qui chargent leur contenu en JavaScript
Avec ces réglages, votre panneau Advanced Settings devrait ressembler à ceci.
Étape 6 : lancer le scraping
Une fois le prompt, les sorties et les paramètres correctement configurés, cliquez sur Continue
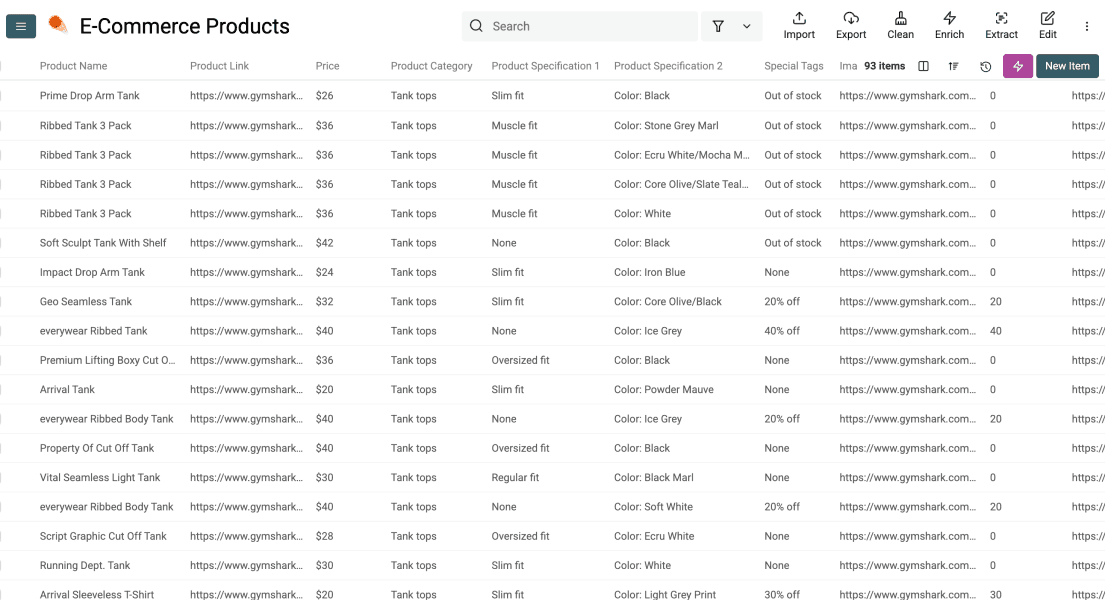
Datablist va créer une propriété pour chaque sortie que vous avez configurée. Vous pouvez alors vérifier que rien ne manque, puis cliquer sur Run Import Now lorsque vous êtes prêt à lancer le scraping.

Après quelques minutes, les lignes arrivent dans votre collection, prêtes à être nettoyées, enrichies, dédupliquées ou exportées.
Si vous prévoyez de relancer ce scraping plus tard, suivez la section ci-dessous pour définir d’abord une colonne unique afin de ne pas importer deux fois la même ligne.
Éviter les doublons lors de scrapes répétés
Je vais maintenant vous montrer comment éviter les doublons dans Datablist en définissant un identifiant unique avant de répéter une tâche de scraping.
Étape 1 : choisir un identifiant unique
Commencez par choisir la colonne que Datablist devra utiliser pour détecter les doublons.
Par exemple, si vous scrapez des produits, utilisez une valeur stable comme Product URL ou Item URL. Si vous travaillez sur des entreprises, utilisez plutôt Company Domain ou Business Name.
💡 Choisissez un identifiant stable
Sélectionnez une valeur propre à une seule ligne. Les URL produit, URL fiche, domaines d’entreprise et adresses email fonctionnent généralement mieux que les noms, car les noms peuvent se répéter.
Étape 2 : ouvrir les paramètres de la colonne
Cliquez sur l’en-tête de colonne correspondant à votre identifiant unique.
Puis sélectionnez Rename - Settings - Delete.

Étape 3 : empêcher les valeurs en doublon
Cochez maintenant la case Do not allow duplicate values.
Puis cliquez sur Save Property.

Étape 4 : vérifier l’icône en forme de clé
Une fois la colonne enregistrée, Datablist affiche une icône de clé à côté du nom de la colonne.
Cette icône confirme que la colonne est désormais utilisée comme identifiant unique.
Désormais, lorsque vous relancez le même scrape, la même source ou le même import, Datablist n’ajoute que les lignes comportant de nouvelles valeurs uniques. C’est la meilleure façon de garder une collection propre lorsque vous répétez le même processus plus tard.
Conclusion : arrêtez de configurer des scrapers, commencez à les piloter par prompt
Le vrai changement n’est pas seulement un nouvel outil. C’est le fait qu’une page web + un prompt en langage naturel remplacent désormais le modèle « un script par site », qui rendait le web scraping si fragile. C’est pour cela qu’un même workflow peut aujourd’hui scraper presque n’importe quel site, qu’il s’agisse d’un annuaire, d’une marketplace ou d’une boutique de niche.
FAQ sur le scraping de sites web sans code
L’AI Scraping Agent de Datablist peut-il scraper n’importe quel site ?
Il fonctionne sur presque tous les sites publics. Comme il lit chaque page à partir d’un prompt plutôt qu’à partir d’un template fixe, il s’adapte à des sites qu’il n’a jamais vus.
Existe-t-il un essai gratuit pour le web scraper no-code de Datablist ?
Oui. Vous pouvez commencer gratuitement, créer une collection et tester l’AI Scraping Agent sans frais.
Faut-il écrire du code pour utiliser l’AI Scraping Agent de Datablist ?
Non. Vous décrivez ce que vous voulez en langage naturel, vous mappez quelques champs de sortie, puis vous lancez l’exécution. Il n’y a aucun script à écrire, ni à réécrire quand un site change de structure. C’est précisément ce qui permet à Datablist de vous aider à scraper n’importe quel site sans code.
Quel type de données l’AI Scraping Agent peut-il extraire depuis un site web ?
Tout ce qui est affiché sur la page et que vous demandez : noms de produits, prix, URL, disponibilité, coordonnées, listings, et bien plus encore. Vous définissez les champs dans le prompt et dans les sorties. À noter : l’AI Scraper de Datablist ne peut pas récupérer des informations backend, comme un stock non affiché publiquement sur le site.
Combien coûte le scraping de sites web avec Datablist ?
Le scraping fonctionne avec des crédits basés sur l’usage, donc vous payez en fonction de ce que vous traitez. Le moyen le plus économique de valider un cas reste de faire un petit test avant de lancer un scraping complet.
Peut-on exporter les données scrapées en CSV ou Excel ?
Oui. Une fois les lignes importées dans votre collection, vous pouvez les nettoyer, les dédupliquer, les enrichir et les exporter, y compris en CSV et en Excel, directement depuis Datablist.
Que signifie scraper un site web sans code ?
Cela signifie extraire des données structurées depuis une page sans écrire ni maintenir de script. Au lieu de programmer des sélecteurs, vous configurez un outil ou décrivez les données à récupérer en langage naturel à l’aide d’un prompt.
Peut-on vraiment scraper n’importe quel site sans code ?
Vous pouvez scraper presque n’importe quel site public sans code si vous utilisez un AI Scraping Agent, car les agents IA s’adaptent à des structures différentes à partir d’un seul prompt. En revanche, les connexions obligatoires et les protections anti-bot avancées restent des freins sur certains sites.
Quelle est la différence entre l’AI scraping et le web scraping traditionnel ?
Le scraping traditionnel repose sur un script codé en dur pour la structure d’un seul site. L’AI scraping relit la page avec un prompt à chaque exécution, ce qui permet à une même configuration de s’adapter à de nombreux sites différents.
Pourquoi les scrapers cassent-ils quand un site change de mise en page ?
Un scraper cible des sélecteurs précis et des schémas de page spécifiques. Quand le site les modifie, le script ne trouve plus les données et renvoie des résultats vides ou des erreurs, jusqu’à ce que quelqu’un le réécrive.
Qu’est-ce qu’un web scraper no-code et comment fonctionne-t-il ?
Un web scraper no-code extrait des données sans programmation. Les outils en point-and-click permettent de sélectionner visuellement des champs, tandis que les agents d’AI scraping utilisent un prompt en langage naturel pour récupérer les données à votre place.
Combien de temps faut-il pour scraper un site sans code ?
Cela dépend de l’outil utilisé, mais si l’on prend Datablist.com comme exemple, cela ne prend généralement que quelques minutes : création du compte, rédaction du prompt, mapping des champs, puis lancement. Le scraping lui-même se termine souvent en 5 à 10 minutes, selon le nombre de pages à traiter.