無料の重複削除ツール

データの重複排除とは?
データの重複排除(デデュープ)は、データセットから重複レコードを取り除くプロセスです。
一意のリストを維持するにはデデュープが不可欠です。メーリングリストを使うマーケティング、リードジェネレーション、顧客管理、あるいは EC の商品カタログ管理など。2 つのエントリが同一の実体を指す場合、それらは重複です。同じ email アドレスを持つ 2 件のリード、同じバーコードを持つ 2 つの商品などが該当します。
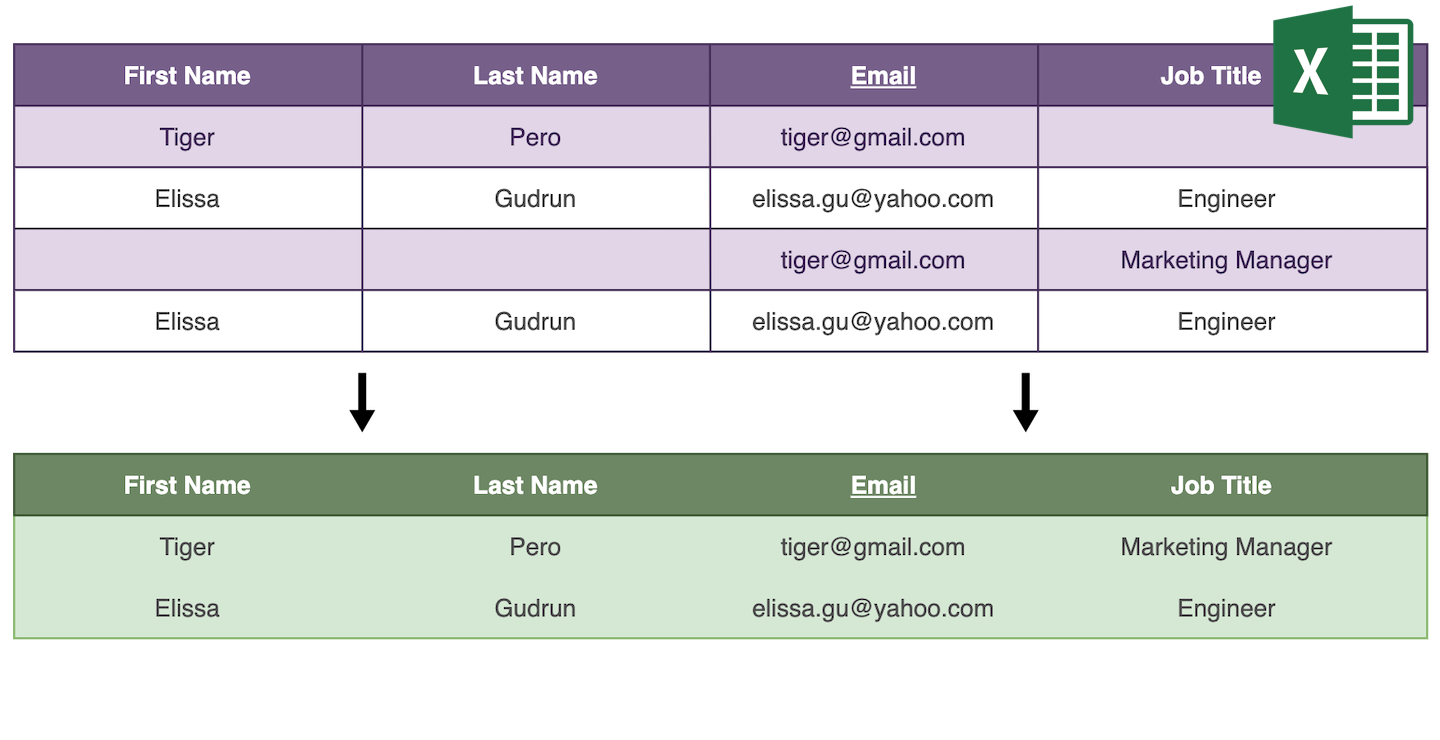
重複はデータ品質を損ない、生産性を低下させます。重複をなくす方法は 2 つあります。削除するか、類似エントリを 1 件にマージして統合するかです。
重複の削除は簡単で、アルゴリズムが重複エントリを見つけ、1 件を除いて削除します。重複のマージは、重複エントリを分析し統合して 1 つのマスターレコードにする必要があります。


















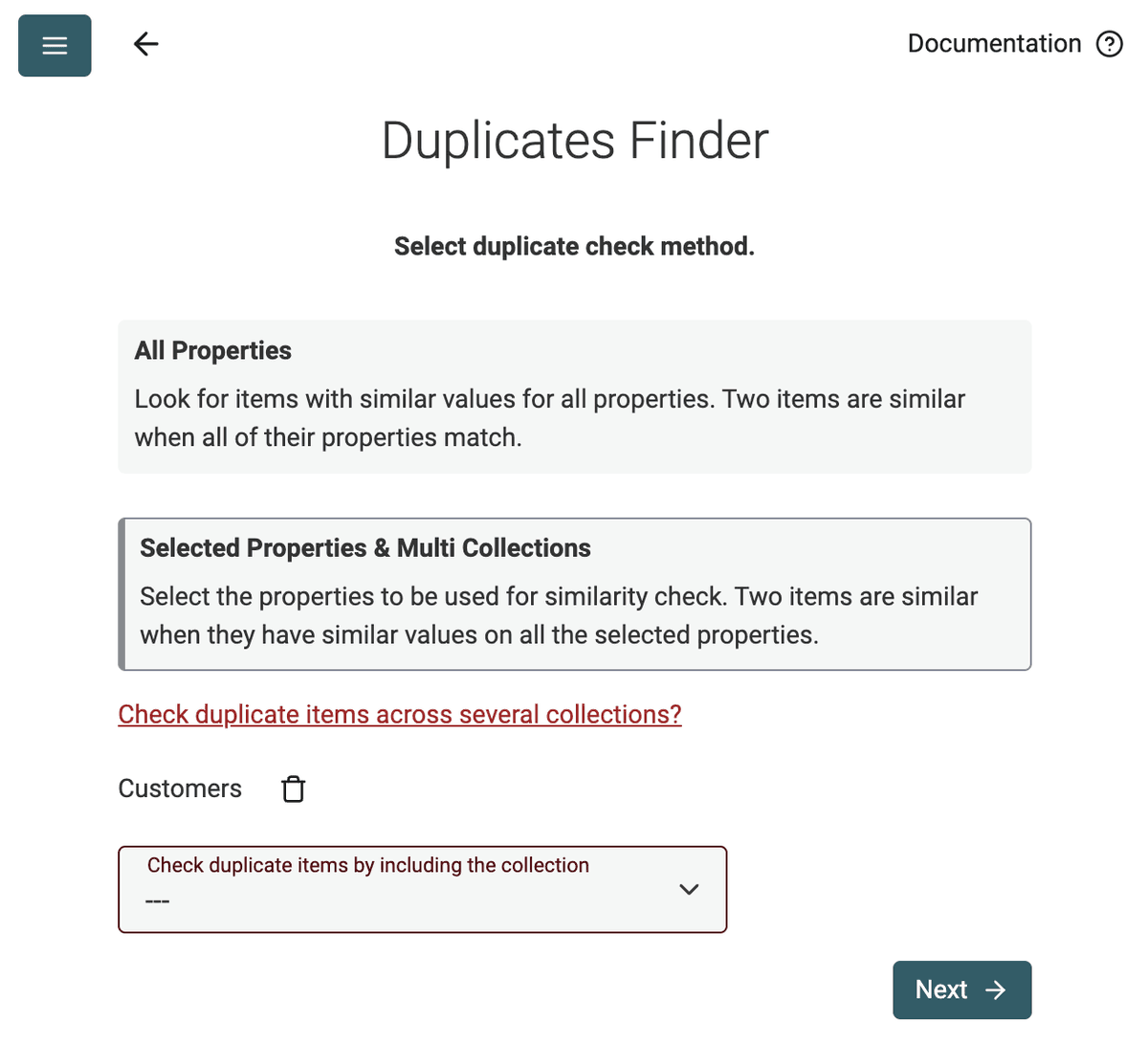
1 つまたは複数のデータコレクションで、全項目または選択項目を解析
Datablist Duplicates Finder は、全アイテム比較または選択したプロパティでの比較に対応します。
Selected Properties モードを使えば、email アドレスに基づいて重複コンタクトを検出したり、ウェブサイト URL によって企業リストの重複を見つけたりできます。
重複の削除または統合

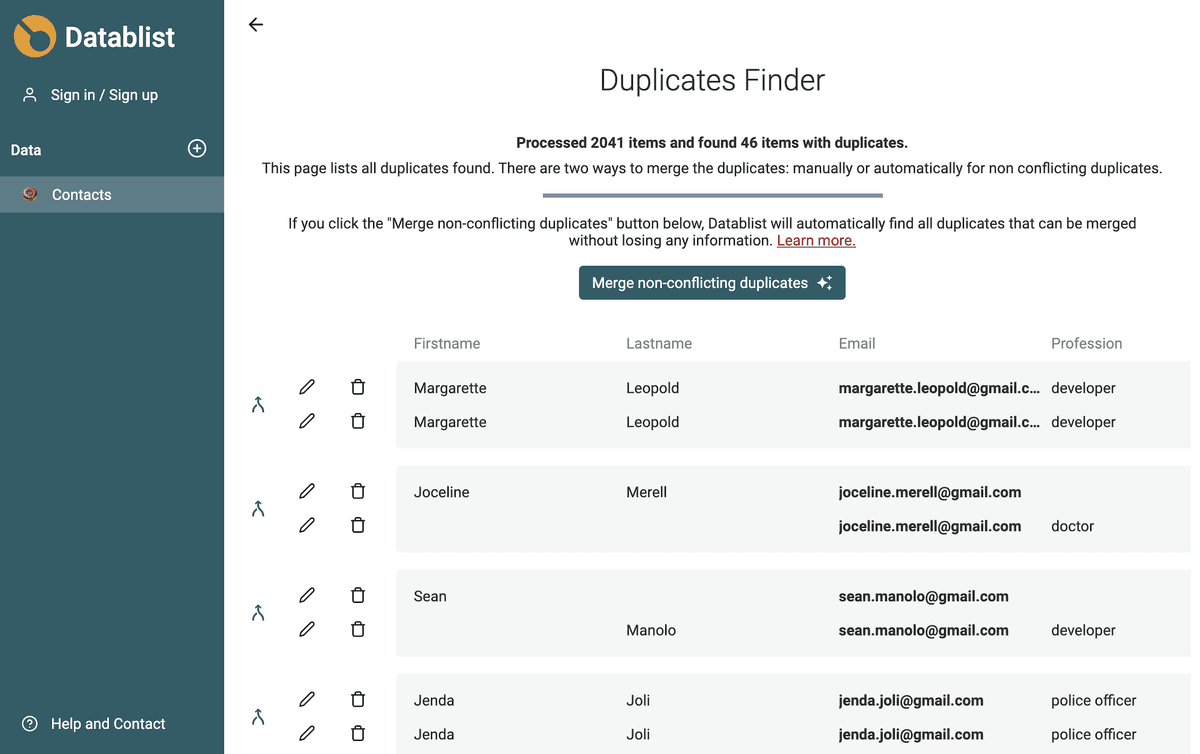
競合のない重複を自動マージ
Datablist は、情報を失うことなくマージできるすべての重複値を自動的に見つけます。
- 重複アイテムのプロパティ値がすべて同一の場合、1 件だけを残し、残りは削除します。
- 重複アイテムが相補的な場合は、情報量が最も多いアイテムをプライマリアイテムとして選択し、そのプロパティ値を他のアイテムの値で補完します。その後、プライマリ以外のアイテムはすべて削除します。
- 重複アイテムに競合するプロパティ値がある場合は、自動処理をスキップし手動マージに回します。
重複を統合して 1 件のレコードに集約
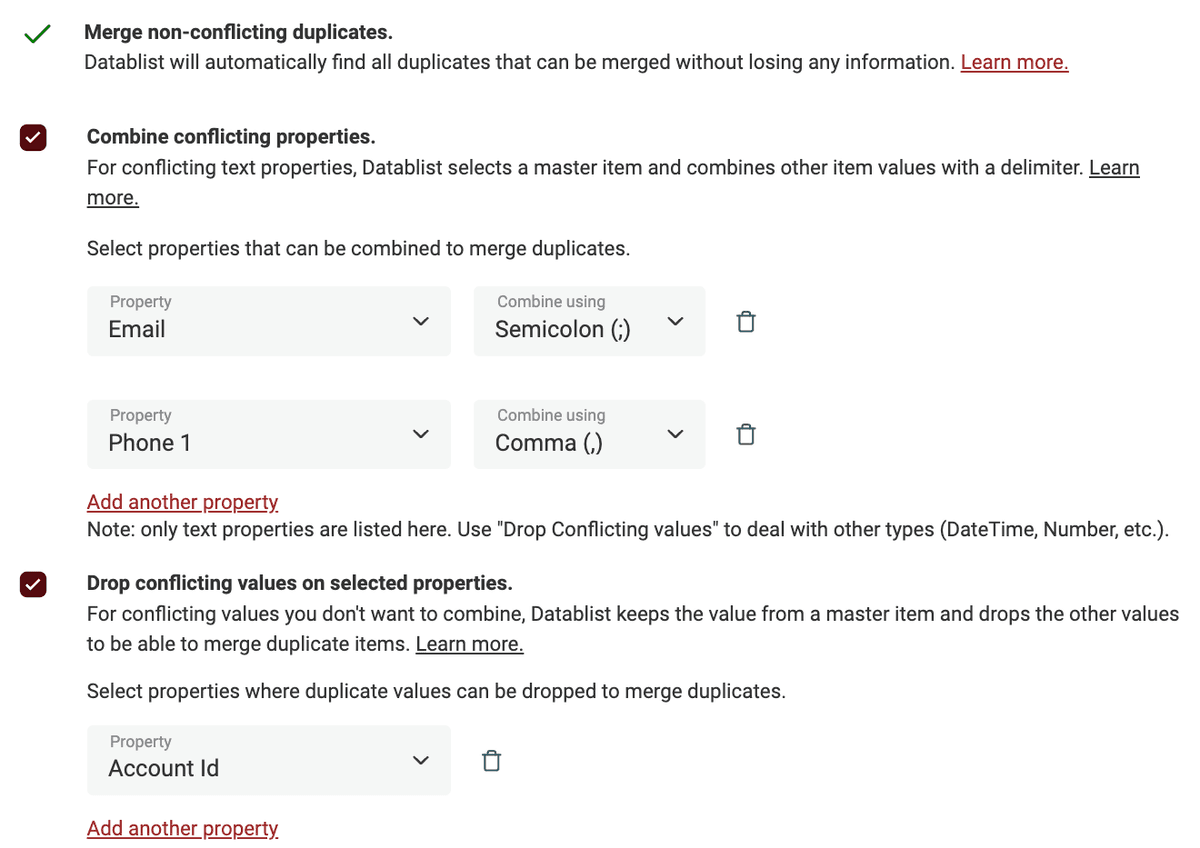
単純なマージだけでは足りない場合は、重複値の結合または破棄などの高度な機能で、重複レコードを統合しましょう。
Datablist は競合しているフィールドを一覧表示し、対応方法を選べます。データ連結には 値を結合、1 つのマスターレコードの値を残すには 値を破棄 を使います。
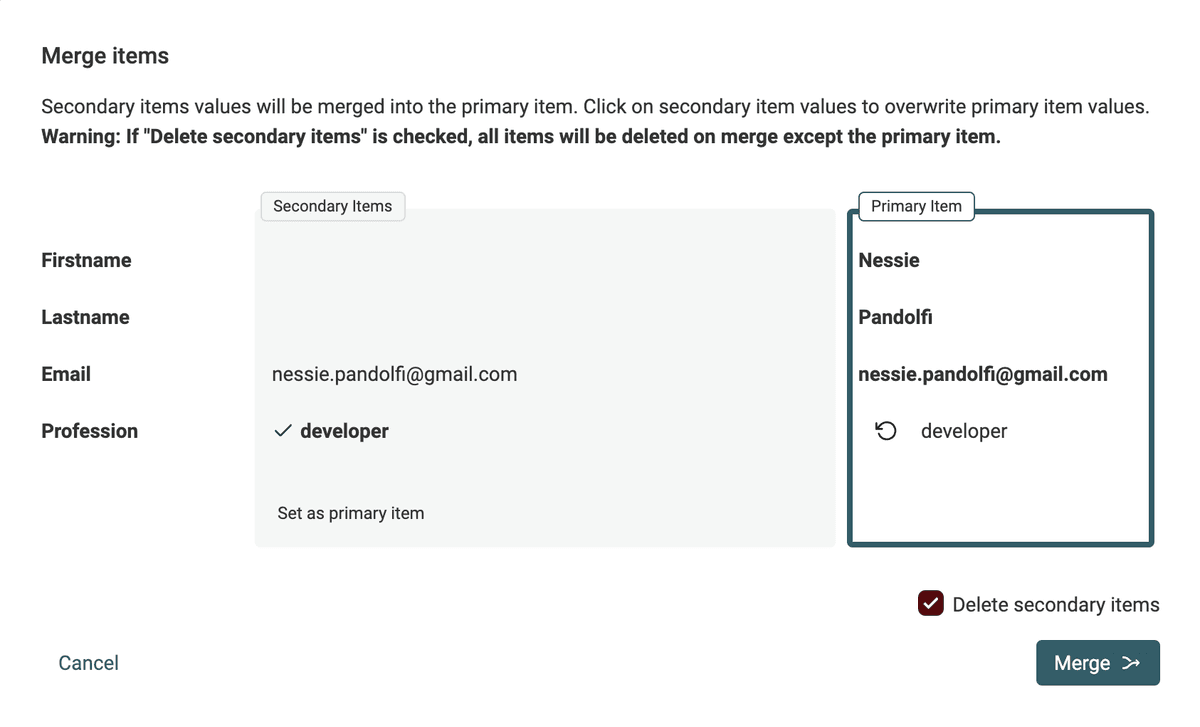
競合する値はマージアシスタントで手動確認
自動マージが難しい場合は、Datablist のマージアシスタントで保持する値を選び、アイテムを統合してください。
情報量が最も多いアイテムがマスターアイテムに選ばれ、セカンダリーアイテムから補完値を受け取ります。
AI による重複処理
データ重複排除はいつ使うべき?
- メーリングリストのデデュープ
時間の経過とともに、ウェビナー参加者、購入者、フリーミアムユーザーなど、複数のソースがメーリングリストに流入します。1 つの email アドレスが複数回登録されることがあります。
重複した email アドレスは、余分なコストやスパム的な挙動、配信停止後もメールを受け取り続けることによるユーザーの不満など、マーケティング施策に悪影響を与えます。- メーリングリストをクリーンアップする方法
- Microsoft Excel の重複排除
Google Sheets や Microsoft Excel などのスプレッドシートには基本的な重複排除機能があります。列内の重複をハイライトしたり削除したりできます。Datablist の自動マージと手動のマージアシスタントで、複雑な重複レコードにも対応できます。
Datablist は CSV と Excel ファイルをどちらも開けます。- Excel ファイルをデデュープする方法
- リード/見込み客の重複排除ツール
B2B マーケティングでは、見込み客データベースの品質がキャンペーン成果に直結します。重複リードを含む汚れたデータリストは、ストレージコストを増やし、リードトラッキングの効率を下げ、営業チームにフラストレーションをもたらします。
Datablist で リードジェネレーションのプロセスを管理しましょう。あるいは CRM データやリードリストを Datablist にインポートしてクリーンアップできます。- リードリストを重複排除する方法
よくあるご質問
はい。オンラインで重複の検出とマージを無料で行えます。厳密一致やスマートマッチングなどの基本機能はアカウント不要で利用可能です。あいまい一致や Phonetic などの高度なアルゴリズムには有料プランが必要です。
Excel は重複行を完全に削除するため、そこに含まれていた有益な情報を失う可能性があります。Datablist はレコードをマージし、重複間の相補情報を賢く 1 つの完全なマスターレコードに統合します。データを失うことはありません。
Datablist は大容量ファイルの処理を前提に設計されています。無料プランで最大 100 万行、有料プランでは最大 150 万行まで処理でき、従来のスプレッドシートの制限を大きく超えています。
もちろんです。Levenshtein や Jaro-Winkler 距離などの高度なあいまいマッチングにより、スペルミスやタイプミス、軽微な書式差があっても類似レコードを特定します。
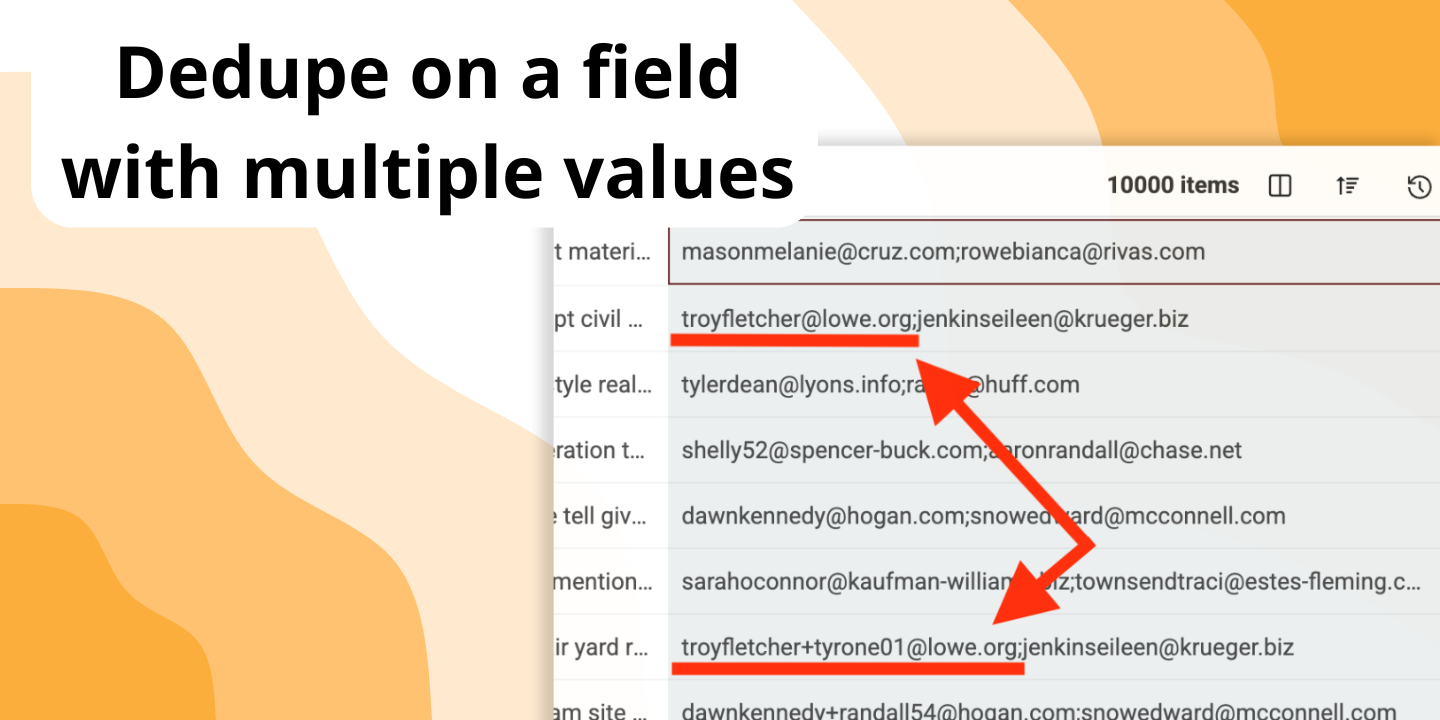
そのために設計されています。"Multiple Value Matching" を有効にすると、(セミコロン区切りの)セル内の各値を個別のエントリとして比較できます。いずれか 1 つでも重複があれば一致とみなします。
はい。複数のファイルを Datablist にインポートし、それら全体に対して Duplicates Finder を実行できます。列や構造が異なっていても、共通の識別子に基づいてレコードを照合できます。
いいえ、不要です。Datablist は完全なノーコードソリューションです。Duplicates Finder が、ユーザーフレンドリーな UI で列とマッチングルールを選ぶだけのステップバイステップでご案内します。
AI 編集機能で柔軟に対応できます。標準のマージルールの代わりに、平易な英語で指示を書くことができます。たとえば、重複エントリの売上数値を合計する、最新日付に基づいてマスターレコードを選ぶ、など。複雑なロジックをシンプルなリクエストに変換します。
Datablist はデータを 1 つのマスターレコードに統合します。他の重複から不足情報を自動補完し、競合データへの対応も選べます。異なる行のテキストを結合することも、保持する値を選ぶことも可能です。不要になったレコードは削除されます。
用途に応じて複数のアルゴリズムをご用意しています。完全一致の 'Exact'、語順や URL プロトコルなどの違いに強い 'Smart'、読みが近い名前に効く 'Phonetic'、タイプミスに強い 'Fuzzy Matching' です。
はい。Datablist がすべての重複グループを特定した後、変更前に CSV または Excel にエクスポートできます。このファイルは、各グループの重複アイテムが連続して並ぶ形で出力されるため、外部でのレビューや他ツールでの処理が容易です。
マージ完了後、Datablist はダウンロード可能な 'Changes List' を提供します。このファイルはプロセス中に更新・削除された各レコードを詳細に記録するログとして機能します。CRM など外部システムでも、このファイルを使えば変更を容易に反映でき、データの完全な同期を維持できます。
See Also