무료 중복 제거 도구

데이터 중복 제거란 무엇인가요?
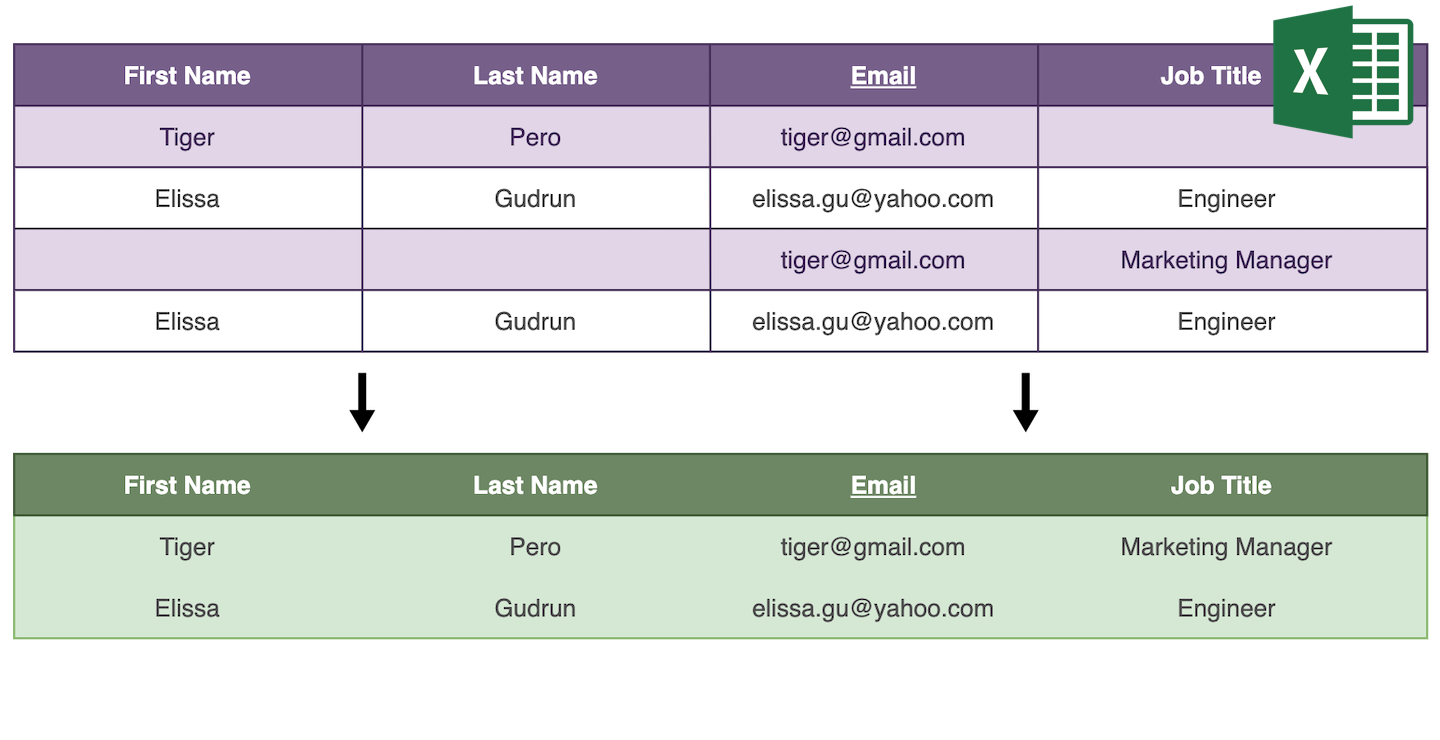
데이터 중복 제거, 또는 deduping은 데이터셋에서 중복 레코드를 제거하는 과정입니다.
고유한 엔트리 목록을 만들려면 deduping이 필요합니다. 메일링 리스트를 사용하는 마케팅, lead generation, 고객 관리에서, 또는 전자상거래의 상품 카탈로그 관리에서요. 두 엔트리가 동일한 개체를 참조할 때 중복입니다. 같은 email 주소를 가진 두 leads, 또는 동일한 바코드를 가진 두 상품 등입니다.
중복은 데이터 품질을 떨어뜨리고 생산성을 저하시킵니다. 중복을 없애는 방법은 두 가지입니다: 삭제하거나, 유사한 엔트리를 하나로 병합하는 것입니다.
중복 삭제는 간단합니다. 중복 제거 알고리즘이 중복 엔트리를 찾아 하나를 남기고 나머지를 삭제합니다. 중복 병합은 중복 엔트리를 분석해 하나의 마스터 레코드로 결합해야 합니다.


















단일 또는 여러 컬렉션에서 전체 혹은 일부 항목 분석
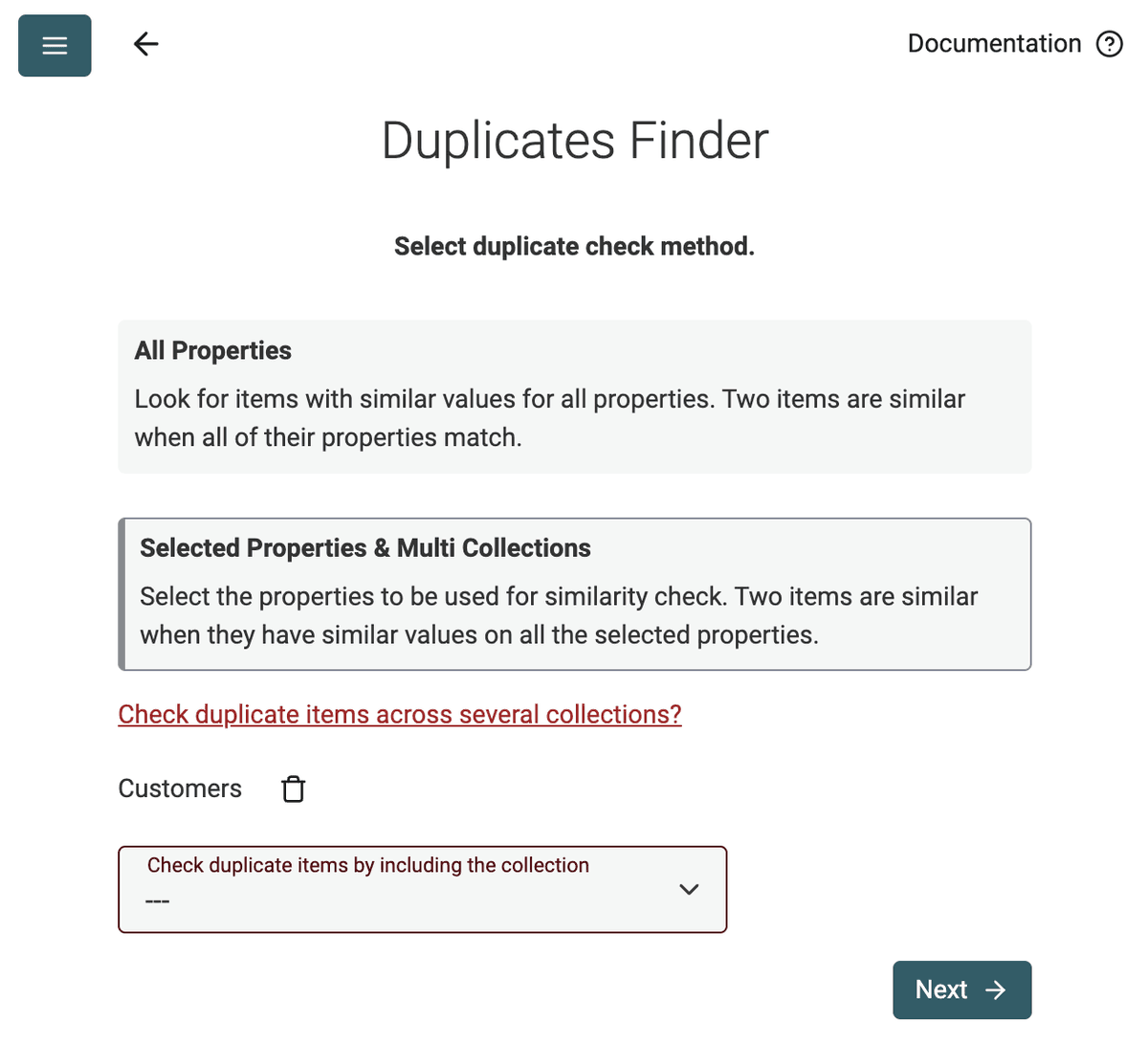
Datablist Duplicates Finder는 항목 전체 비교 또는 선택한 속성 비교로 동작합니다.
Selected Properties 모드를 사용해 email 주소 기반으로 중복 연락처를 찾거나, 회사 리스트에서 웹사이트 URL을 사용해 중복을 감지하세요.
중복 삭제 또는 통합

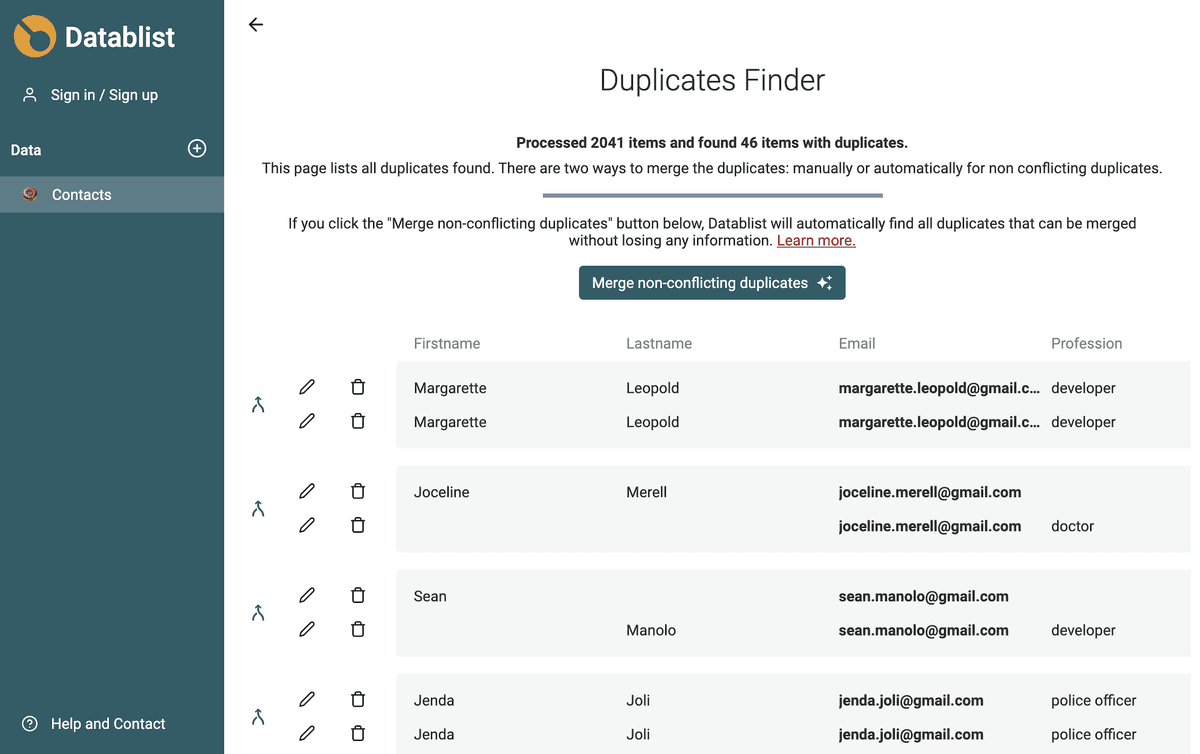
충돌 없는 중복 항목 자동 병합
Datablist는 정보 손실 없이 병합 가능한 모든 중복 값을 자동으로 찾습니다.
- 모든 중복 항목의 속성 값이 동일한 경우 하나의 항목만 유지되고 나머지는 삭제됩니다.
- 중복 항목이 상호 보완적일 경우, 정보가 가장 많은 항목을 기본 항목으로 선택하고 다른 항목의 속성 값으로 비어 있는 값을 채웁니다. 이후 기본 항목을 제외한 모든 항목이 삭제됩니다.
- 중복 항목 간 속성 값이 충돌하면 해당 항목은 자동 병합을 건너뛰고 수동 병합 대상으로 표시됩니다.
중복을 통합해 단일 레코드로 유지
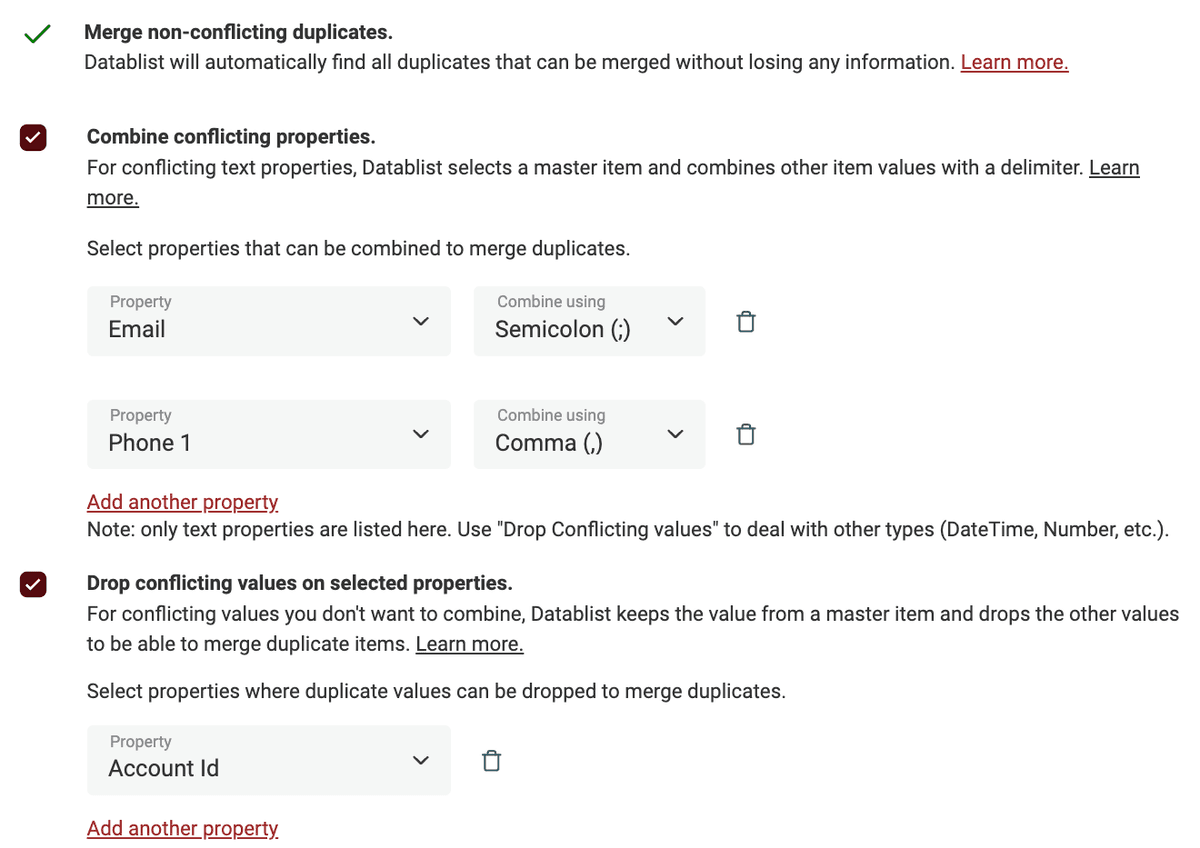
단순 병합만으로 충분하지 않을 때는 고급 기능을 사용하세요. 중복 레코드를 결합하거나 불필요한 값을 제거해 통합할 수 있습니다.
Datablist가 충돌하는 필드를 나열하고 처리 방법을 선택하게 해줍니다. 데이터 연결(Concatenation)에는 Combine values를, 하나의 마스터 레코드 값만 유지하려면 Drop values를 사용하세요.
또는 병합 도우미로 충돌 값을 수동으로 확인
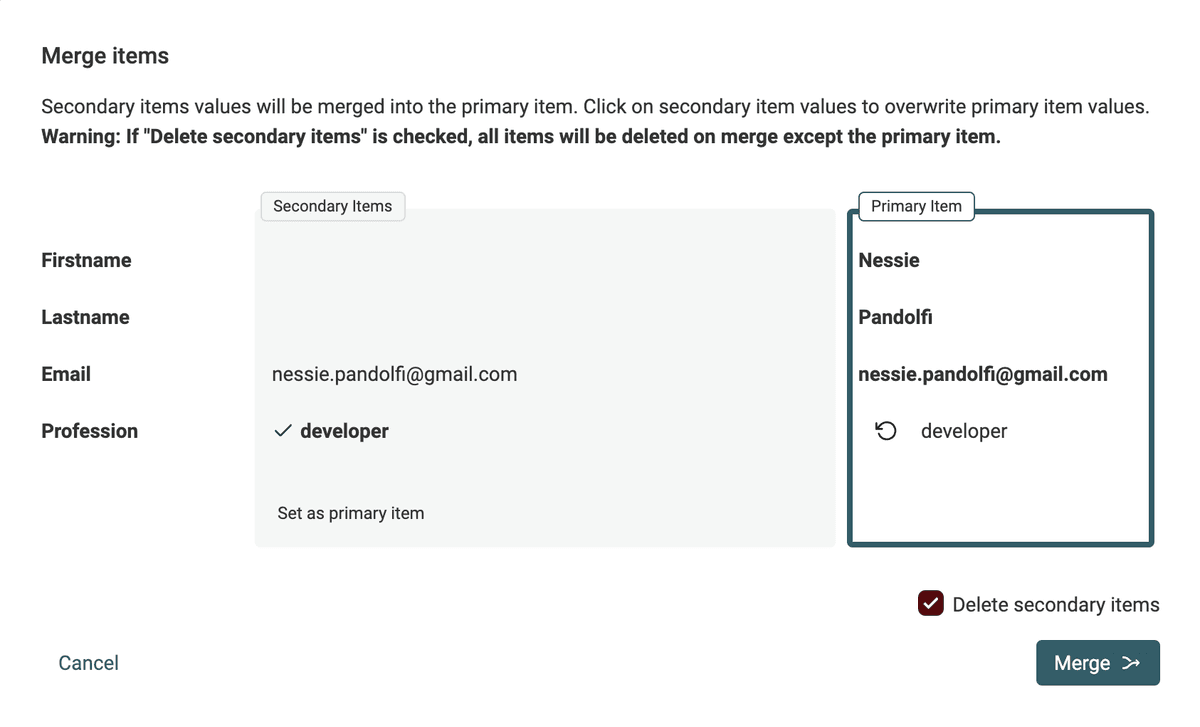
자동 병합이 불가능할 때는 Datablist 병합 도우미로 유지할 값을 선택해 항목을 통합하세요.
정보가 가장 많은 항목이 마스터 항목으로 선택되며, 보조 항목의 보완 값들을 전달받습니다.
AI 기반 중복 처리
데이터 중복 제거는 언제 사용하나요?
- 메일링 리스트 중복 제거
시간이 지나면 웨비나 참가자, 구매자, freemium 사용자 등 여러 출처의 데이터가 메일링 리스트로 유입됩니다. 하나의 email 주소가 메일링 리스트에 여러 번 등장할 수 있습니다.
중복 email 주소는 추가 비용을 유발하고 스팸성 동작으로 보일 수 있으며, 수신 거부 후에도 메일을 계속 받게 되면 사용자 불만을 초래할 수 있습니다.- 메일링 리스트 클린업 방법
- Microsoft Excel 중복 제거
Google Sheets, Microsoft Excel 등 스프레드시트 도구는 기본 중복 제거 기능을 제공합니다. 컬럼의 중복 값을 하이라이트하거나 삭제합니다. 복잡한 중복 레코드는 Datablist의 자동 병합과 수동 병합 도우미로 처리하세요.
Datablist는 CSV와 Excel 파일을 모두 열 수 있습니다.- Excel 파일 중복 제거 방법
- Lead 및 잠재고객 중복 제거 도구
B2B 마케팅에서 잠재고객 데이터베이스의 품질은 캠페인 성과에 직접적인 영향을 줍니다. 중복 leads가 포함된 지저분한 리스트는 저장 비용을 증가시키고, lead 추적 효율을 떨어뜨리며, 영업팀에 좌절감을 줍니다.
Datablist로 lead generation 프로세스를 관리하세요. 또는 CRM 데이터나 lead 리스트를 Datablist로 가져와 정리하세요.- lead 리스트 중복 제거 방법
- CSV 파일 중복 제거
CSV 데이터 클린업은 시간이 많이 듭니다. 데이터 엔지니어는 보통 Python 같은 프로그래밍 언어로 CSV를 파싱하고 정리합니다. Datablist는 비기술 사용자를 위한 No-Code 도구를 제공해 CSV 파일로 데이터 클린업을 수행할 수 있게 합니다. 수십만 행의 CSV 파일을 열어 빠르게 중복 레코드를 제거하세요.
- CSV 파일 중복 제거 방법
자주 묻는 질문
예. 온라인에서 무료로 중복을 찾고 병합할 수 있습니다. Exact 및 smart matching 같은 기본 기능은 계정 없이도 사용 가능합니다. Fuzzy나 phonetic matching 같은 고급 알고리즘은 유료 요금제가 필요합니다.
Excel은 중복 행을 영구적으로 삭제하여 잠재적으로 가치 있는 데이터를 잃을 수 있습니다. Datablist는 레코드를 병합해 모든 중복에서 보완 정보를 지능적으로 결합하여 하나의 완전한 마스터 레코드로 만듭니다. 어떤 데이터도 잃지 않습니다.
Datablist는 대용량 파일 처리를 위해 설계되었습니다. 무료 요금제에서는 최대 100만 행, 유료 요금제에서는 최대 150만 행까지 처리할 수 있어, 전통적인 스프레드시트 도구의 한계를 훨씬 뛰어넘습니다.
물론입니다. Levenshtein, Jaro-Winkler 거리와 같은 고급 fuzzy matching 알고리즘을 사용해 철자 오류, 오타, 경미한 포맷 차이가 있어도 유사한 레코드를 식별합니다.
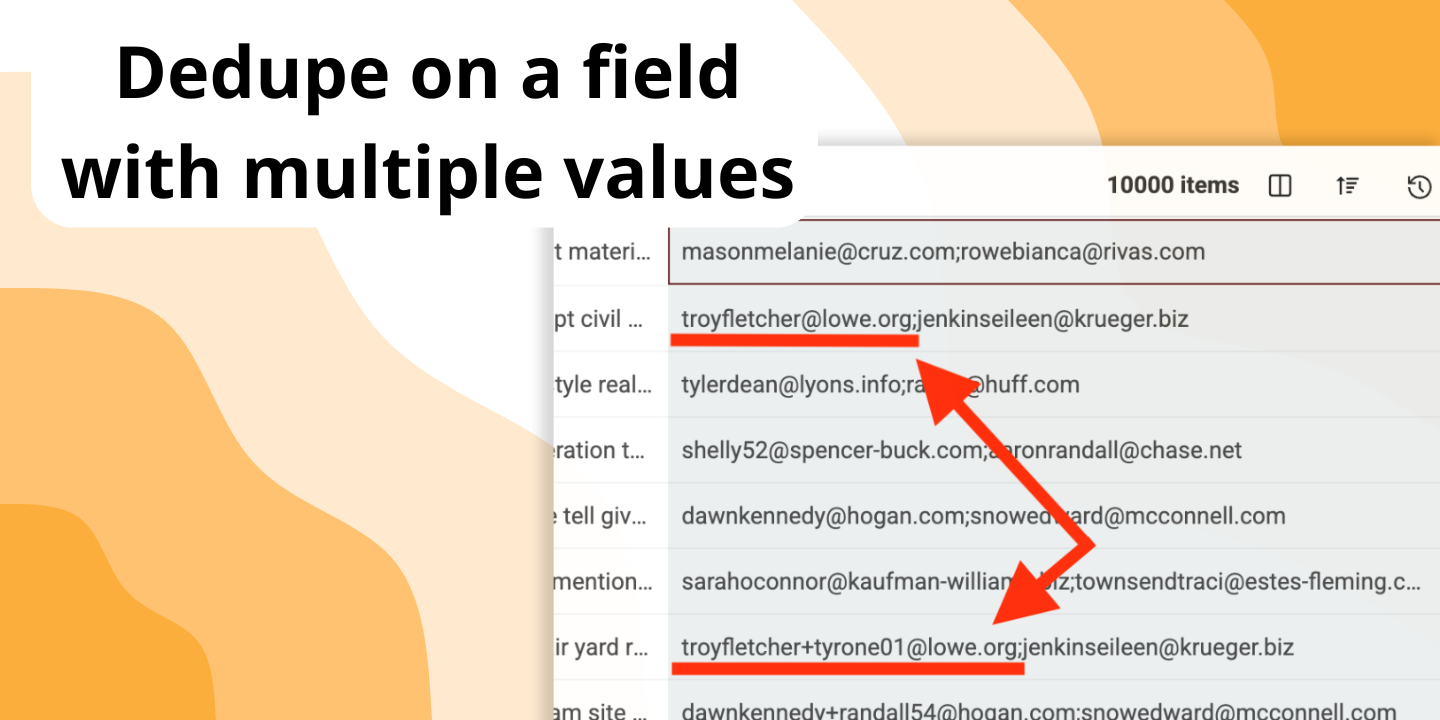
그런 경우를 위해 설계되었습니다. "Multiple Value Matching"을 활성화하면 셀 내 각 값을(세미콜론으로 구분) 별도의 엔트리로 간주해 비교합니다. 값 중 하나만 중복이어도 일치로 판단합니다.
예. 여러 파일을 Datablist로 가져온 뒤, 전부를 대상으로 Duplicates Finder를 실행할 수 있습니다. 파일의 컬럼이나 구조가 달라도 공통 식별자를 기준으로 레코드를 매칭할 수 있습니다.
전혀 아닙니다. Datablist는 완전한 no-code 솔루션입니다. Duplicates Finder가 단계별로 안내하며, 사용자 친화적 인터페이스에서 컬럼과 매칭 규칙을 선택하기만 하면 됩니다.
우리의 AI Editing 기능은 무제한의 유연성을 제공합니다. 표준 병합 규칙 대신 평이한 영어로 지시문을 작성할 수 있습니다. 예를 들어, 중복 항목의 매출 수치를 합산하거나 최신 날짜를 기준으로 마스터 레코드를 선택하라고 요청할 수 있습니다. 복잡한 로직을 단순한 요청으로 바꿔줍니다.
Datablist는 데이터를 하나의 마스터 레코드로 통합합니다. 다른 중복에서 누락된 정보를 자동으로 채워주고, 충돌 데이터에 대한 옵션도 제공합니다. 서로 다른 행의 텍스트를 결합하거나 유지할 값을 선택할 수 있습니다. 중복된 레코드는 제거됩니다.
용도에 따라 여러 알고리즘을 제공합니다. 동일 일치에는 'Exact', 단어 순서나 URL 프로토콜 차이 등 변형에는 'Smart', 발음이 비슷한 이름에는 'Phonetic', 오타와 철자 오류에는 'Fuzzy Matching'이 적합합니다.
예. Datablist가 모든 중복 그룹을 식별한 뒤, 변경을 적용하기 전에 CSV 또는 Excel 파일로 내보낼 수 있습니다. 이 파일은 각 중복 그룹을 연속으로 나열해 외부에서 검토하거나 다른 도구로 처리하기 쉽게 합니다.
병합을 완료하면 Datablist가 다운로드 가능한 'Changes List'를 제공합니다. 이 파일은 처리 중 업데이트되거나 삭제된 모든 레코드를 기록한 로그 역할을 합니다. 이 파일을 사용해 CRM 같은 외부 시스템에서도 변경을 손쉽게 반영하여 데이터 동기화를 유지할 수 있습니다.
See Also