

很多工具都号称可以“no-code”抓取 Y Combinator 的创业公司目录。但实际用起来,你很容易被 API、复杂的 point-and-click 界面、CSS selector 这些东西困住。说是无代码,本质上只是把技术细节包了一层不太好用的 UI。
问题在于: 它们都在卖“简单”,最后却变成了一堂编程课。
这篇指南不一样: 我会展示一种真正 no-code 的方法,从 Y Combinator 目录里抓取 startup 数据。我们说 no-code,就是字面意思。
用 Datablist 抓取 YC startup directory 时,我们甚至可以直接承诺:
↳ 你不需要配置 API,也不需要检查网页元素。
↳ ↳ 你只需要用自然语言告诉 AI 你想要什么,也就是 prompting。
↳ ↳ ↳ 就连这一步,我们也已经准备好了可直接使用的模板
📌 给赶时间的人看的摘要
这篇文章会教你如何在没有技术负担的情况下,从 Y Combinator directory 抓取 startup 数据。如果你时间有限,先看这个摘要:
问题: 大多数 web scraping 工具都声称自己是“no-code”,但仍然要求你处理 API 或理解网页元素。本质上只是换了一种形式制造技术麻烦。
为什么这是问题: 如果你想要一个真正简单的方案来抓取 YC startups,就不应该需要技术背景,也不应该花几个小时看教程。
解决方案: 使用 Datablist 的 AI Agent 和现成的 YC directory scraper 模板。你只需要粘贴 URL,然后点击开始。
你会学到什么: 本指南会介绍抓取 YC directory 的 2 个阶段,解释为什么 Datablist 是更合适的选择,并回答关于 no-code 抓取 YC companies 的常见问题。
为什么用 Datablist: 3 个简单理由
- 真正 no-code,直接使用模板,无需 set-up
- 价格友好,套餐从 $25/month 起,还支持灵活购买额外 credits
- 一个平台里可以使用 60+ lead generation tools
这篇指南会讲什么
- 用 YC Directory 找到最相关 Startup 的方法
- 阶段 1:从 YC Directory 抓取 Startup 列表
- 阶段 2:抓取公司与创始人详情
- 为什么 Datablist 是抓取 YC Companies 的最佳工具
- 关于无代码抓取 YC Startup Directory 的 FAQ
Datablist 是什么?
Datablist 是一个用于自动化 lead generation 工作流的平台。你可以用它通过 60 多种工具来查找、清洗和 enrich 数据,包括 AI Agents、Email Finders、AI processors、Technology enrichments 等。
此外,Datablist 还可以帮你搭建按计划或按需运行的自动化工作流。下面是一些 Datablist 用户常用的实际场景:
我的意思很简单:如果你的工作涉及数据获取、数据清洗,或数据相关流程自动化,并且你希望它简单、快速、可靠,Datablist 就是合适的工具。
💡 用 35 个词概括 Datablist
Datablist 是一个用于自动化 lead generation 工作流的平台,提供 60+ 工具,包括 AI Agents、用于查找邮箱和电话的 Waterfall Enrichment、去重等数据清洗工具。
抓取 YC Startup Directory 的两步流程
前面我说 Datablist 很容易上手,不是随便说说。整个流程非常简单,每个阶段只需要点击几次。不过在开始之前,我先给你看一个关键点。
如何找到最相关的 YC Startups
Y Combinator directory 里有数千家 startups,分布在不同 batch、行业和细分市场。下面是更高效筛选目标 startup 的方法:
-
使用左侧边栏的筛选项:
Batch: 选择特定 YC batch(例如 Winter 2025),用于定位最新的 startups 或更成熟的公司
Industry: 选择 B2B、Consumer、Healthcare、Fintech 等大类
Region: 如果你关注特定市场,可以按地理位置筛选
Company Size: 选择团队规模区间,让列表更接近你的 ideal customer profile
-
使用搜索框按关键词查找 startups。需要精确匹配时,用引号,例如 “AI”
-
组合多个筛选条件,进一步缩小结果范围
-
设置好筛选条件后,复制浏览器里的 URL
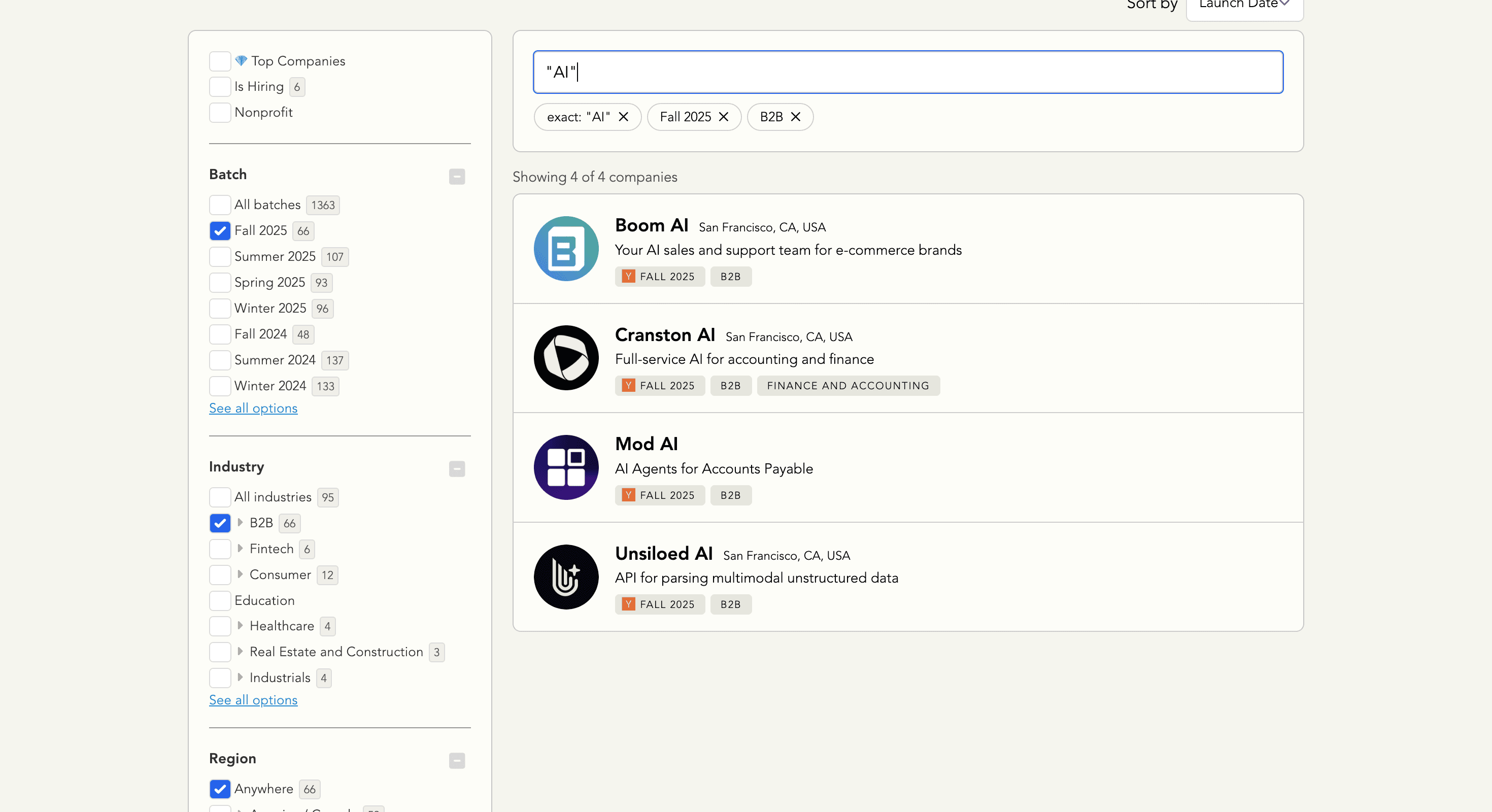
Pro tip: 筛选越具体,结果越精准。比如你卖 dev tools,可以筛选 B2B + recent batches + 2-10 team size,找到正处在增长期、也更可能有采购需求的 startups。
💡 为什么筛选很重要
YC directory 里有 5,000 多家公司。
但关键在这里:每个列表最多只展示 1,000 家 startups。如果你不加筛选直接抓取,会漏掉大部分数据。
这就是为什么筛选很重要。一个符合你 ICP 的 100 家 startup 精准列表,永远比 1,000 家随机公司更有价值。
阶段 1:从 YC Directory 抓取 Startup 列表
第一阶段是从 YC directory 的搜索结果中提取基础信息。这会给你一个后续可继续处理的公司基础列表。
阶段 1 - 步骤 1:注册并创建 Collection
首先,注册 Datablist.com
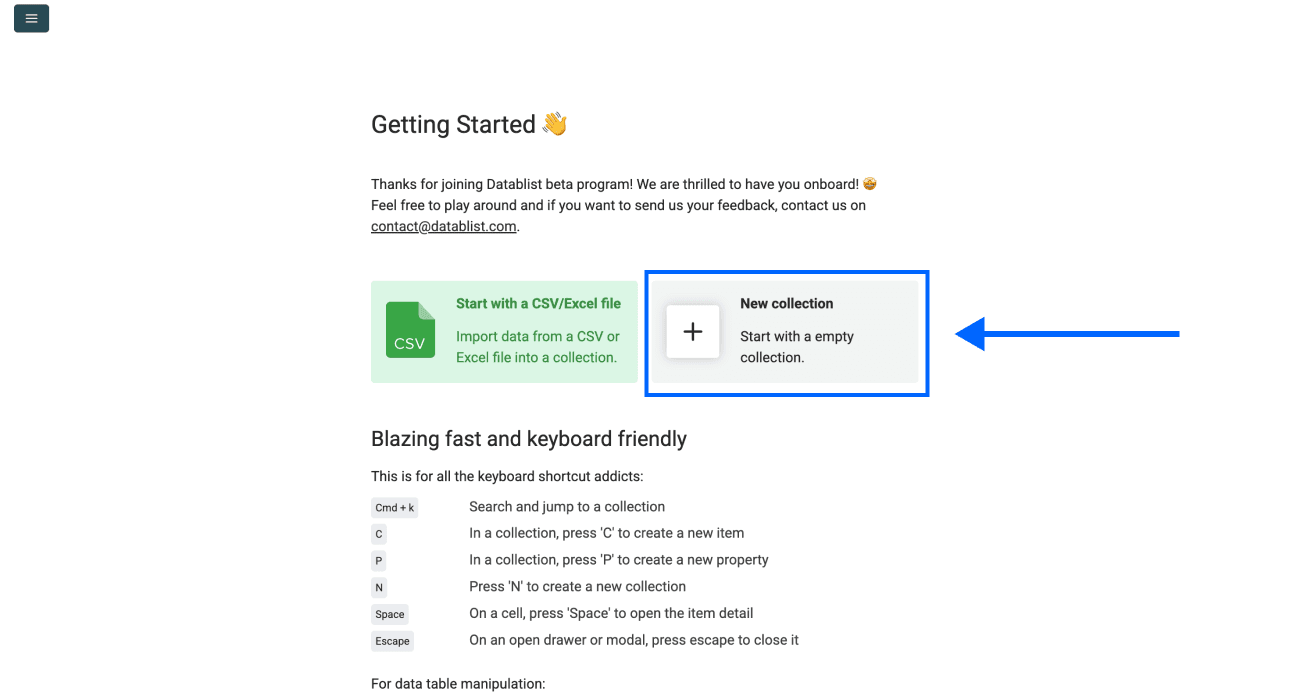
然后,创建一个 New Collection
阶段 1 - 步骤 2:创建第一个 Property,避免重复数据
Y Combinator directory 里有些 startups 可能会在搜索结果中出现不止一次。如果你不想在 collection 里看到同一家公司出现多次,可以这样做:
- 创建一个 New Property,命名为 "YC Company URL"
- 点击 Column Header,选择 Rename - Settings - Delete
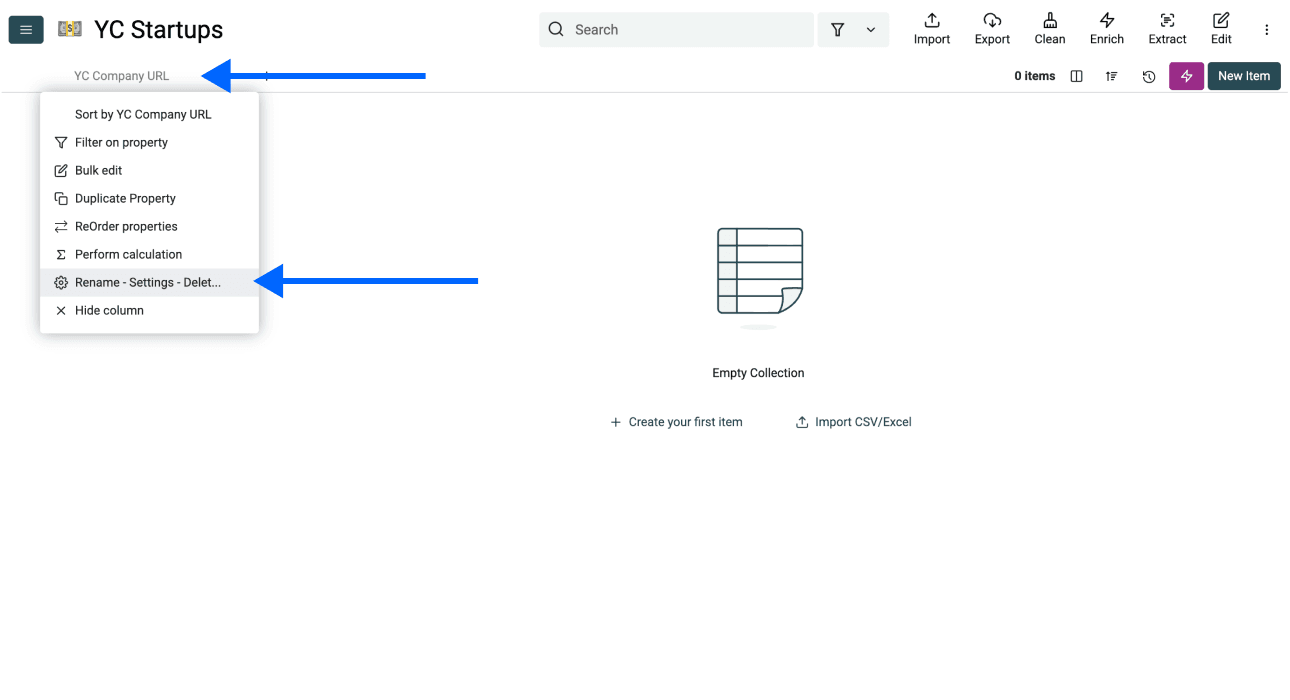
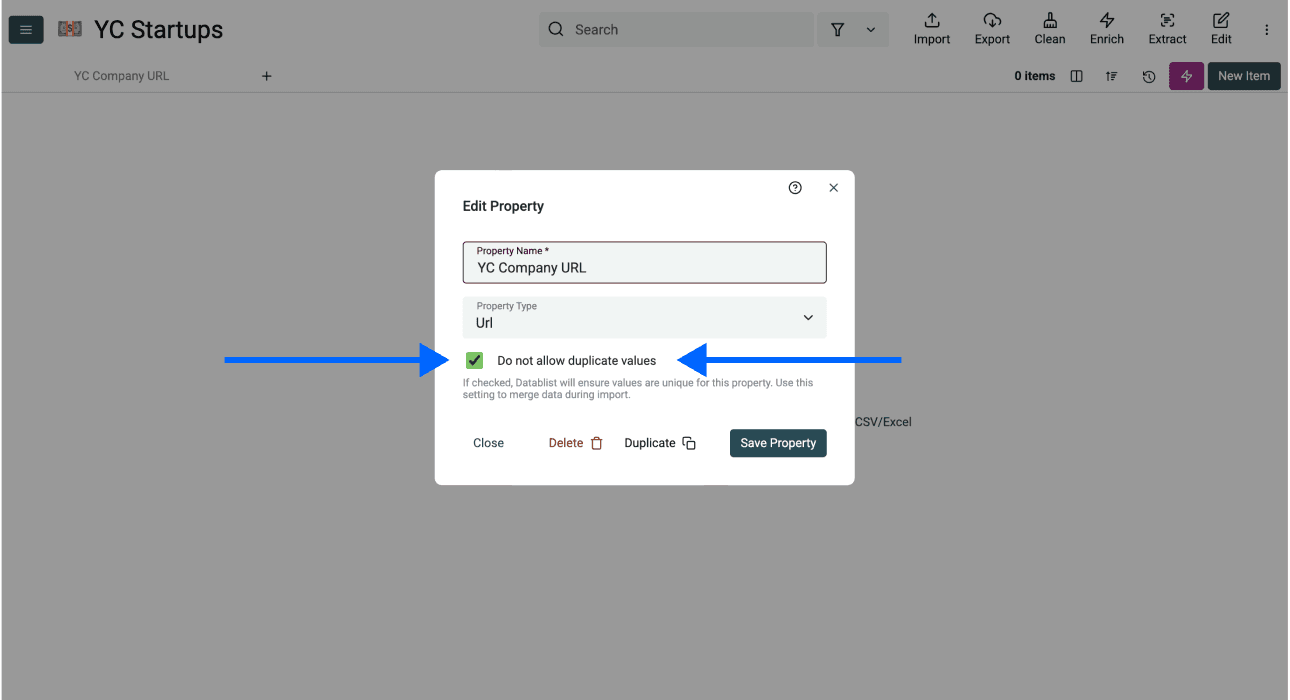
- 勾选 "Do not allow duplicate values" 旁边的复选框,然后点击 Save Property
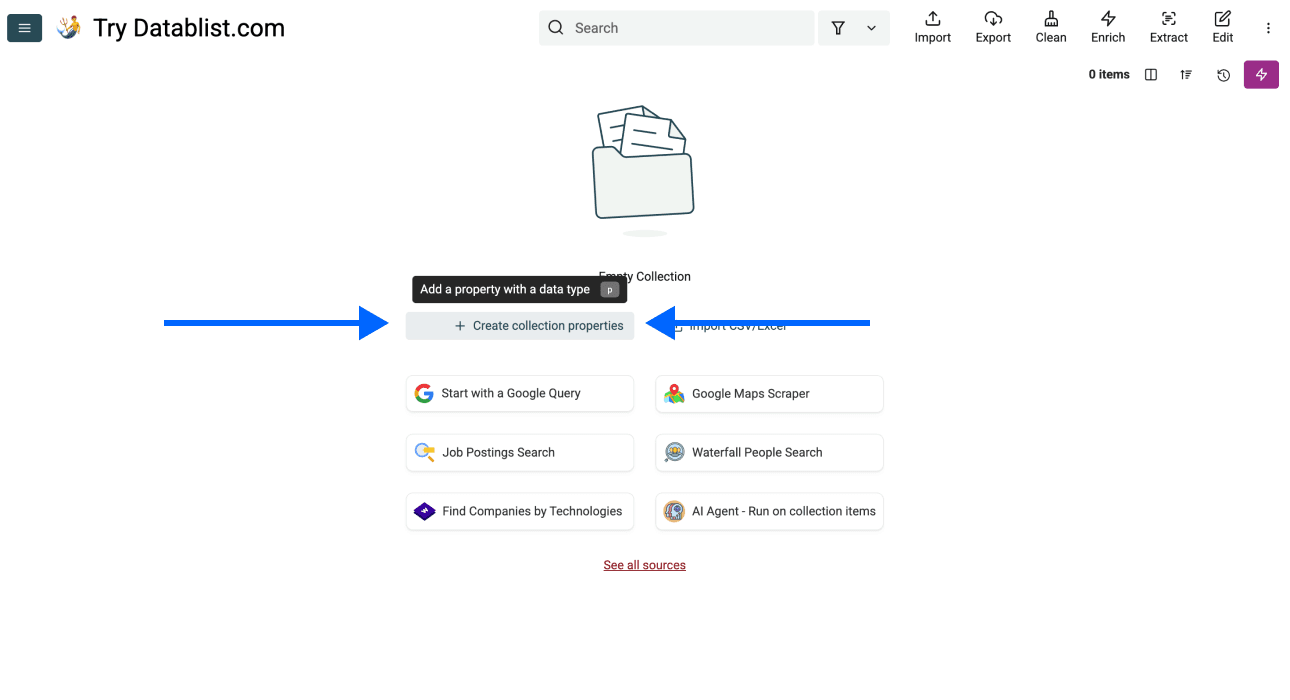
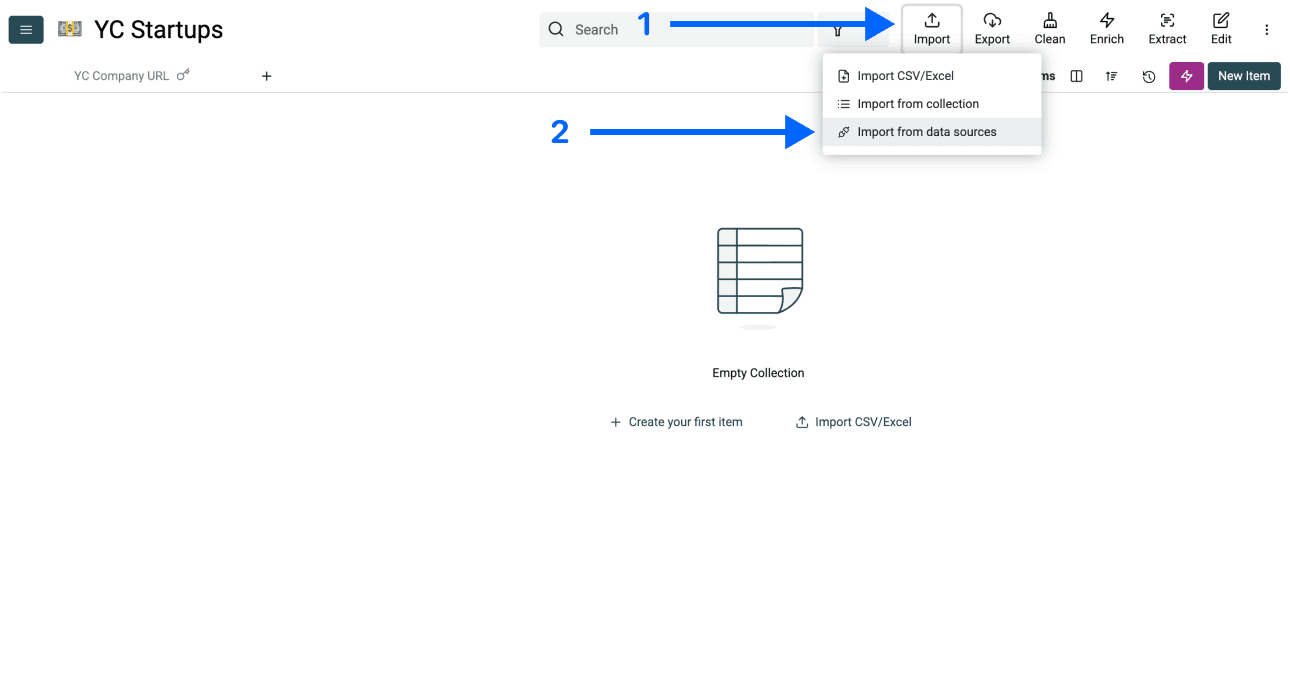
阶段 1 - 步骤 3:进入 AI Scraping Agent
- 点击应用顶部菜单里的 Import,然后选择 Import From Data Sources
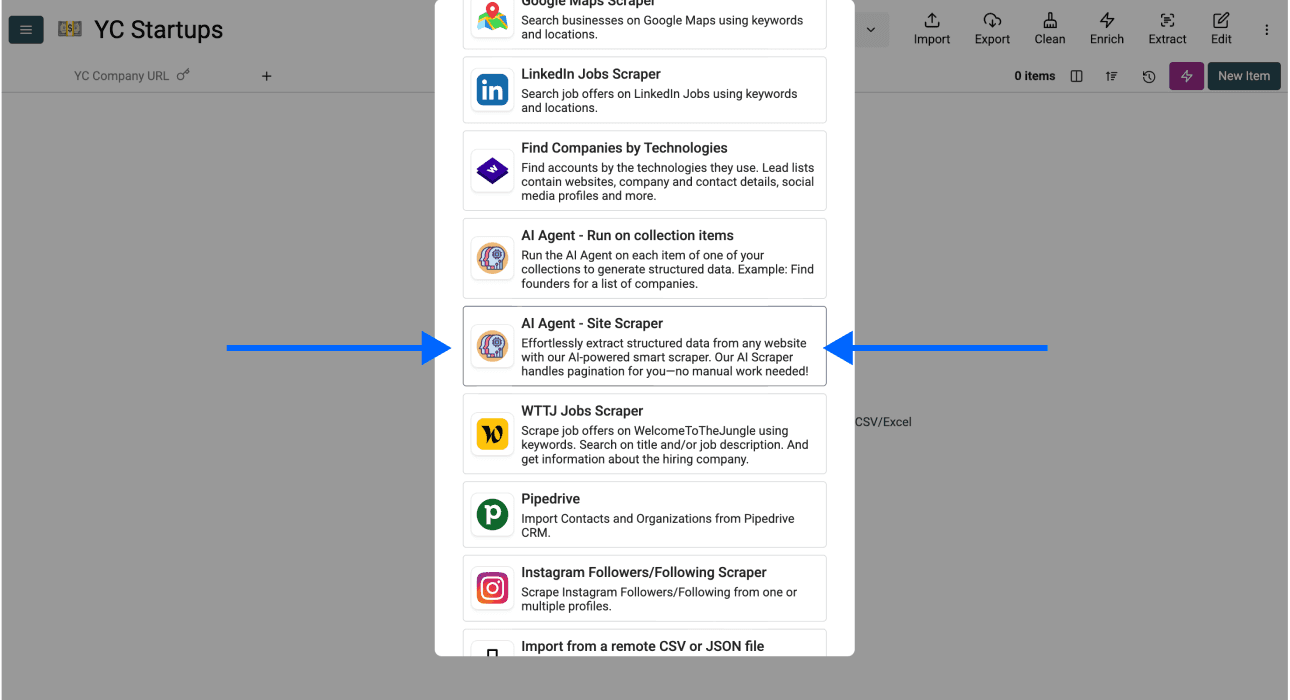
- 向下滚动,选择 AI Agent - Site Scraper
现在,你会看到一个新的界面,大概是这样:
阶段 1 - 步骤 4:选择模板
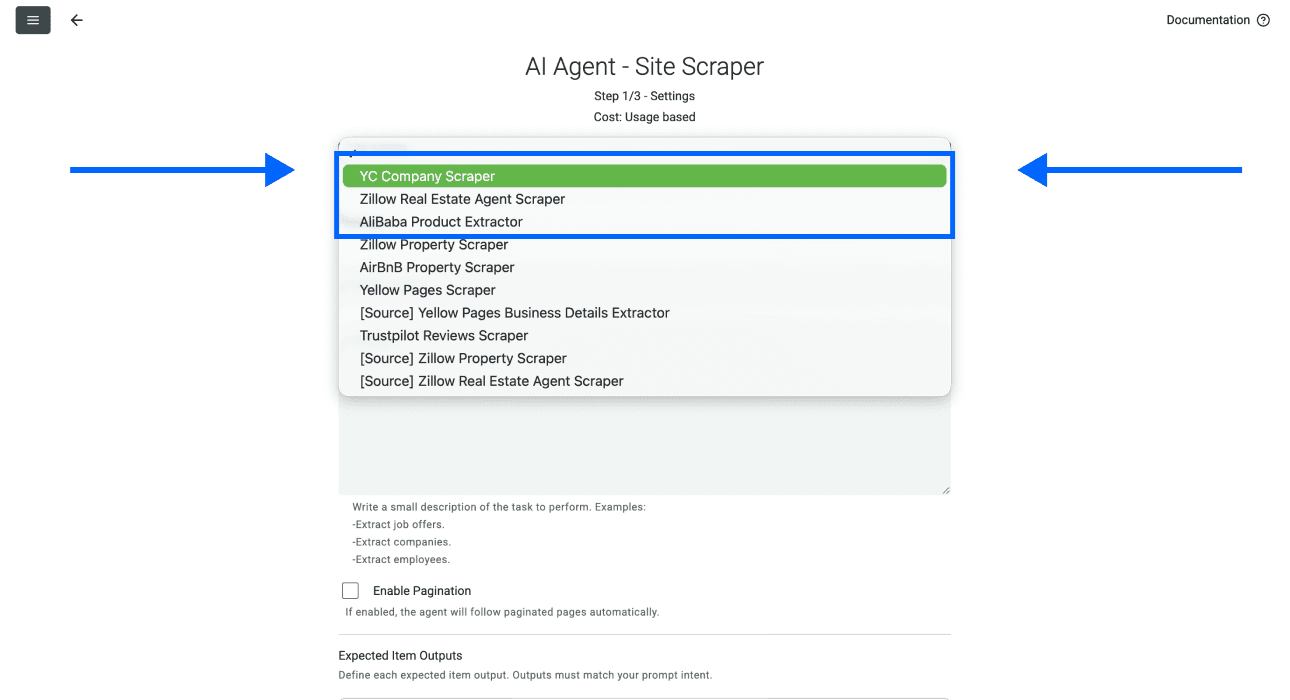
- 点击 Template Drop-Down,选择 "YC Startup Directory Scraper"
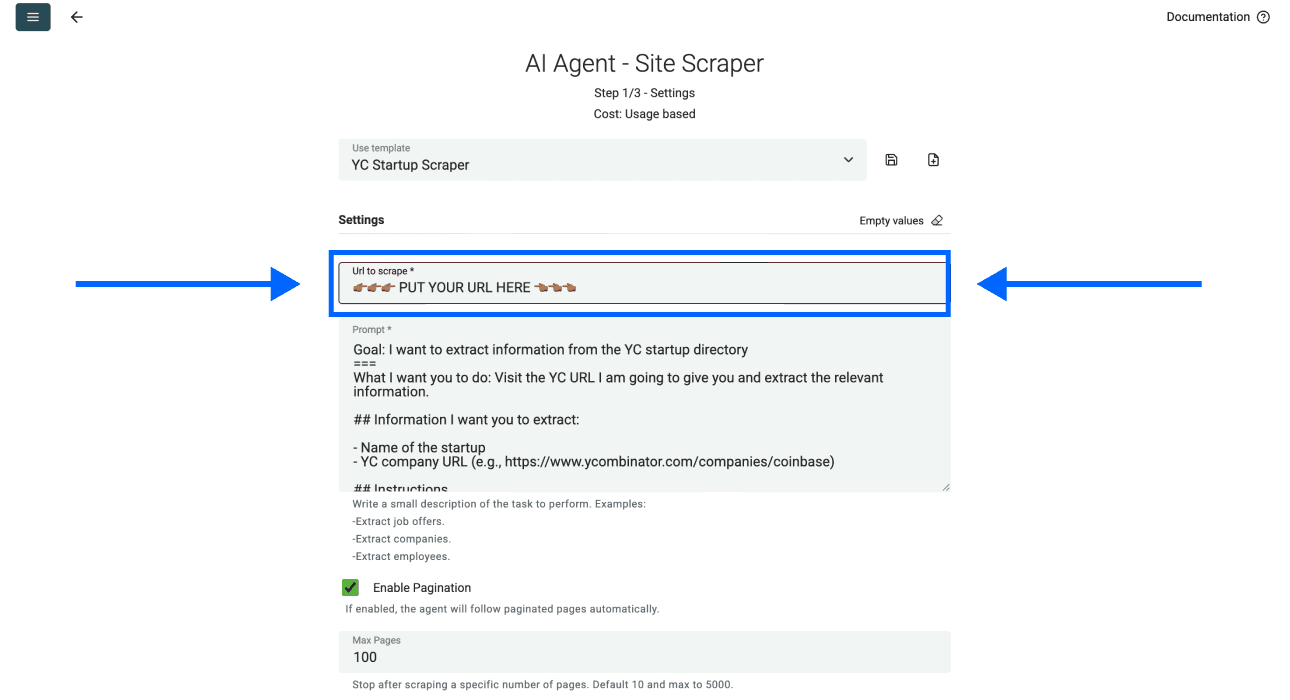
- 在第一个字段里粘贴你的 YC directory URL
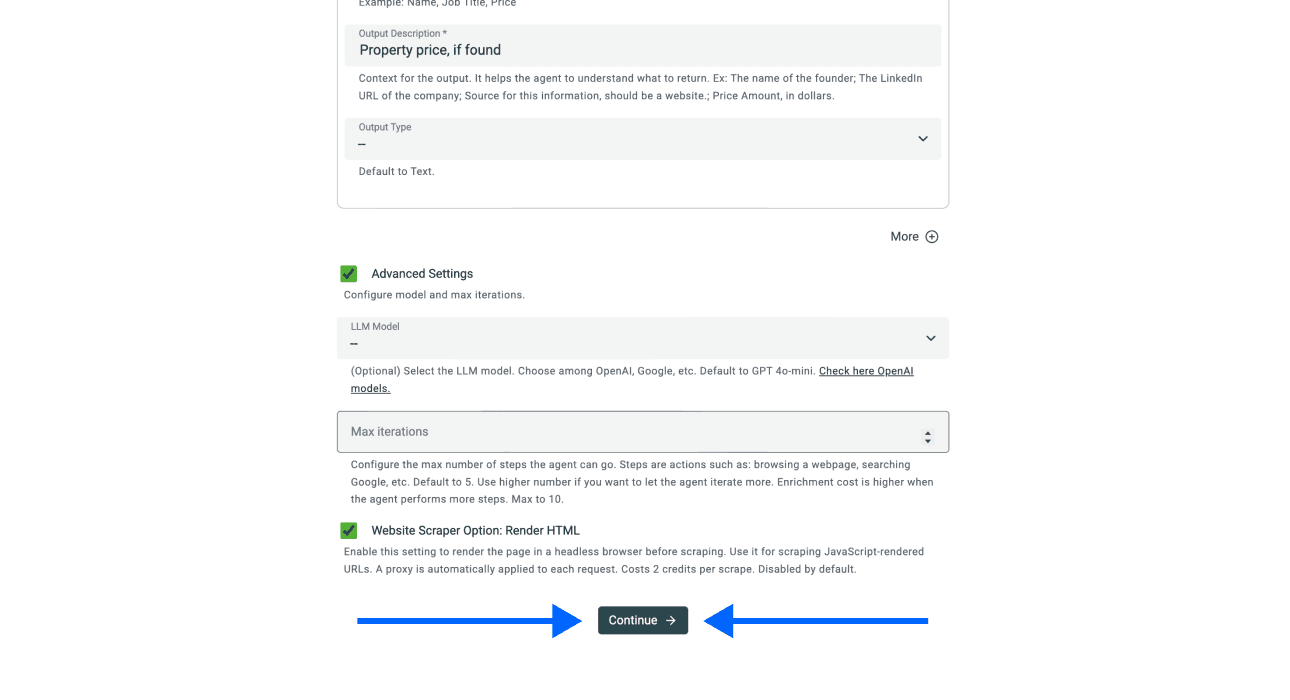
- 向下滚动,点击 Continue
阶段 1 - 步骤 5:选择输入并开始 Scrape
因为名称相同,Datablist 会自动映射第一个 property。
对于其他 properties,点击 ⊕ Icon 将它们添加到你的 collection 中。
完成后,点击 Run Import Now 开始 scraping。

几分钟后,你的结果会像这样:
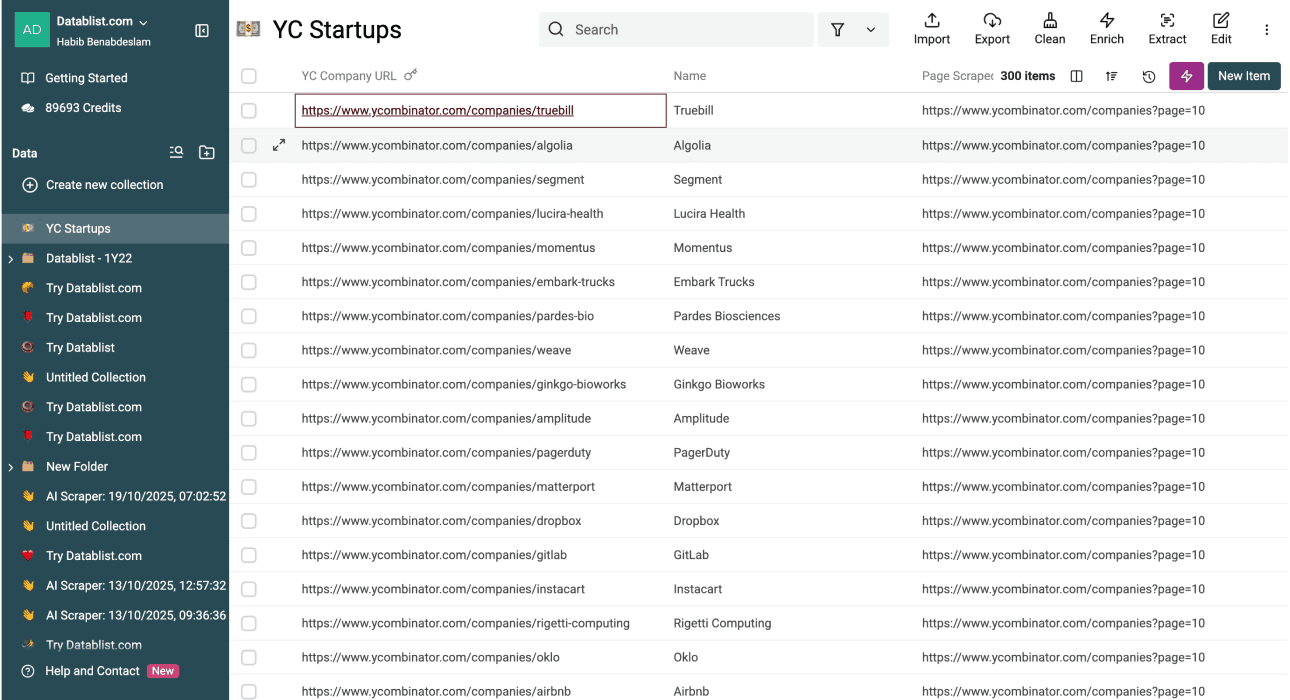
现在你应该已经有了:
- Startup Name
- YC Company URL
- ……以及很多其他字段
你可以到这里就停下,也可以继续进入阶段 2,获取 founders 的信息。
阶段 2:抓取公司与创始人详情
在这个阶段,我们会访问每家 startup 的 Y Combinator profile page,并提取更详细的公司和 founder 信息,包括:
Company Information:
- Startup Name
- Startup Description
- Founded Date
- Batch
- Team Size
- Status(Active、Public、Acquired)
- Location
- Primary Partner
- Website URL
- LinkedIn Company Page URL
- X (Twitter) Company Page URL
Founder Information(每家公司最多 3 位 founders):
- Founder Names
- Founder LinkedIn URLs
- Founder X (Twitter) Accounts
这里还有一篇指南,讲的是如何通过 LinkedIn URL 查找邮箱 👈🏽
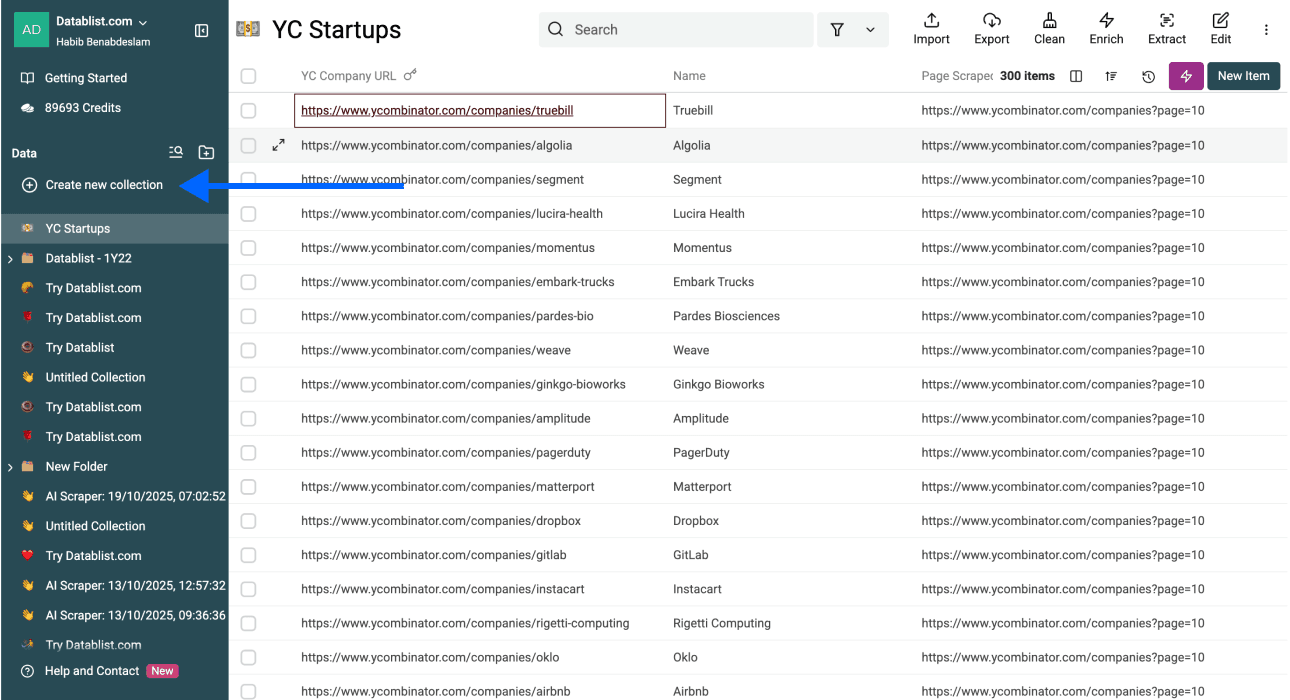
阶段 2 - 步骤 1:创建新的 Collection
创建一个 New Collection
Pro tip: 使用快捷键 N 可以快速创建 new collections
阶段 2 - 步骤 2:选择模板
- 选择 AI Agent - Run on Collection Items
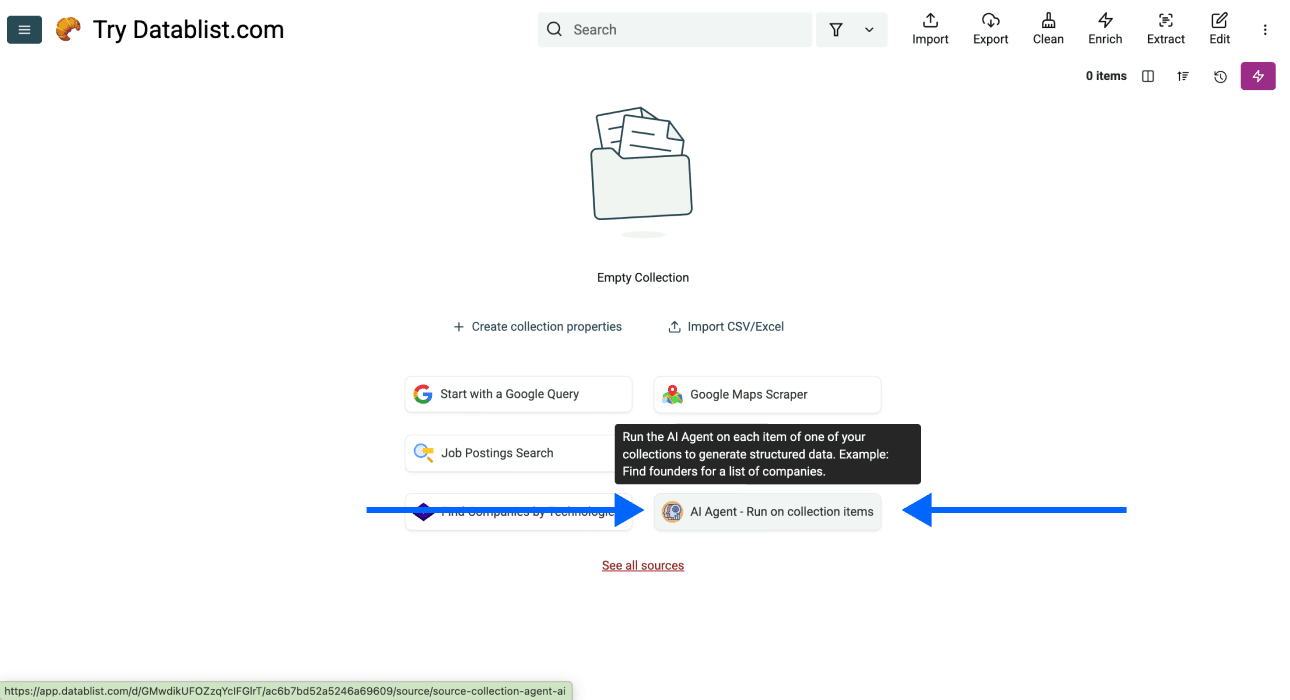
现在,你会看到这个界面:
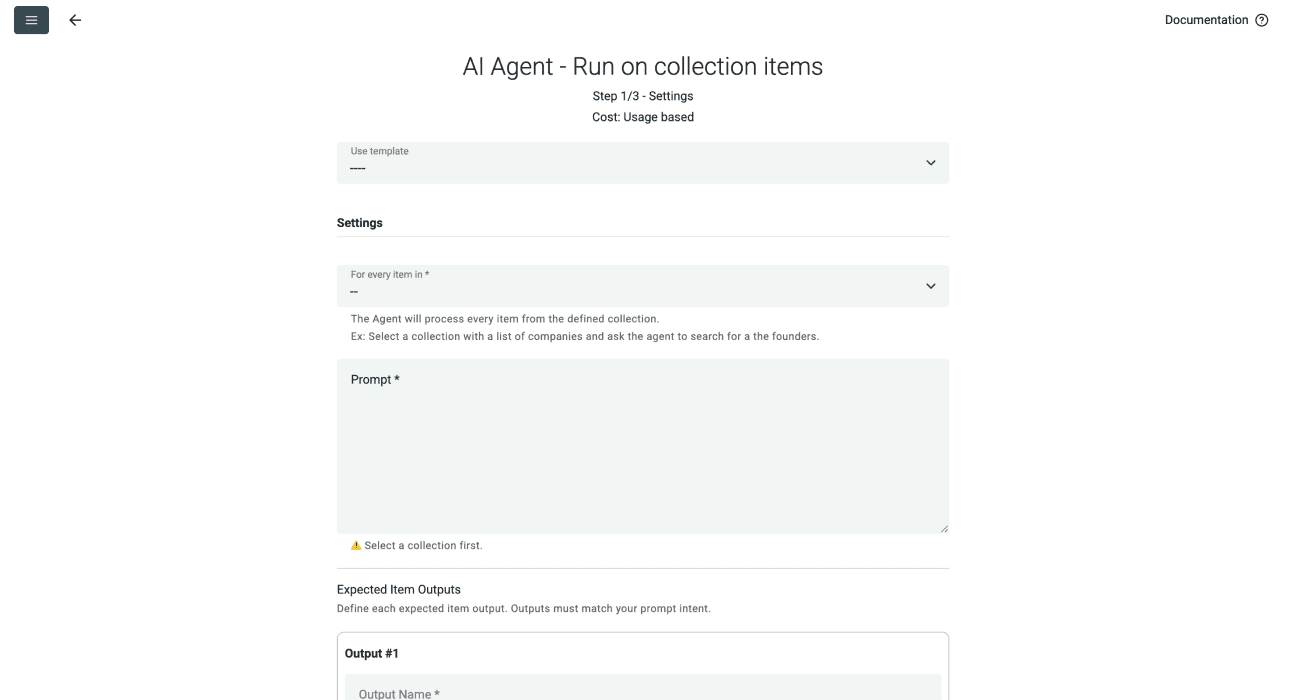
- 点击 Template Drop-Down,选择 "YC Company & Founder Details Scraper"。
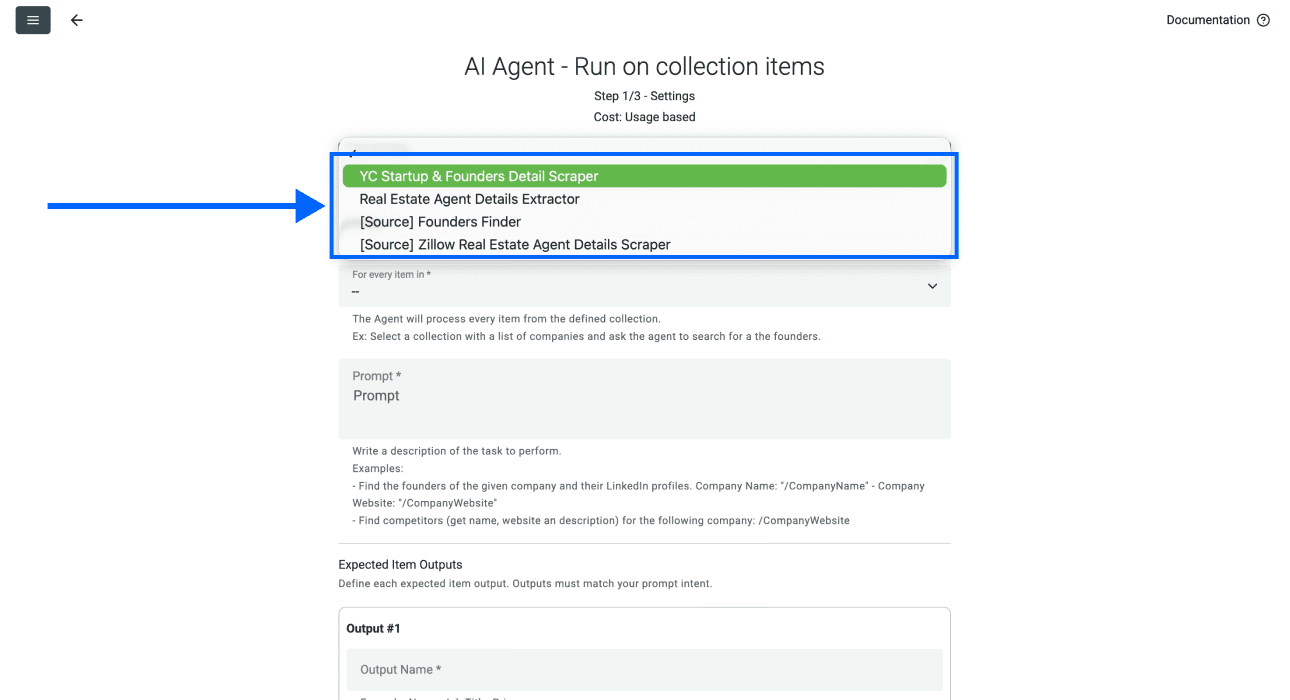
阶段 2 - 步骤 3:映射 Collection 和 Input Property
- 点击第二个下拉菜单,选择你在阶段 1 刚刚创建的 collection
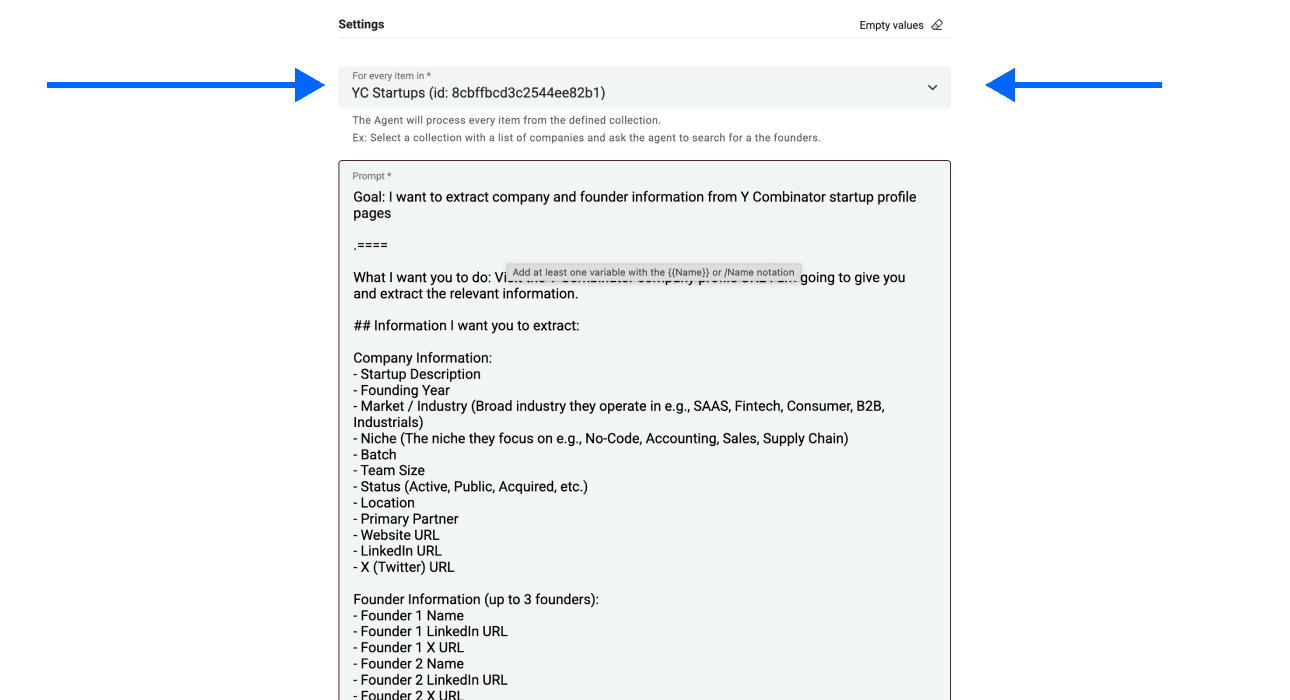
-
现在,向下滚动到 prompt 末尾,把 YC company URL 插入为 Input Property
你可以输入 /,然后选择 YC Company URL

- 完成上面的步骤后,向下滚动并点击 Continue
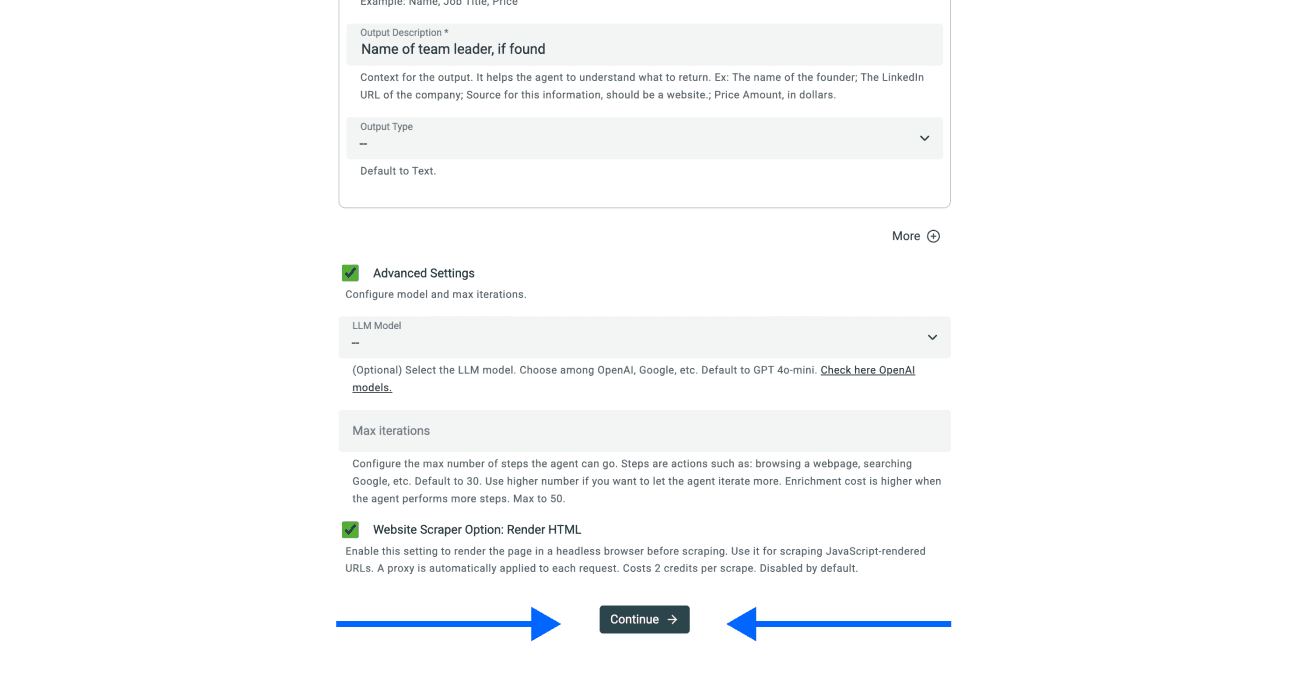
阶段 2 - 步骤 4:选择 Outputs
Datablist 会自动创建所有 properties。
如果有些数据点你不需要,点击 ✕ Icons 将它们从 collection 中移除。
完成后,向下滚动并点击 Run Import Now 开始 scraping。
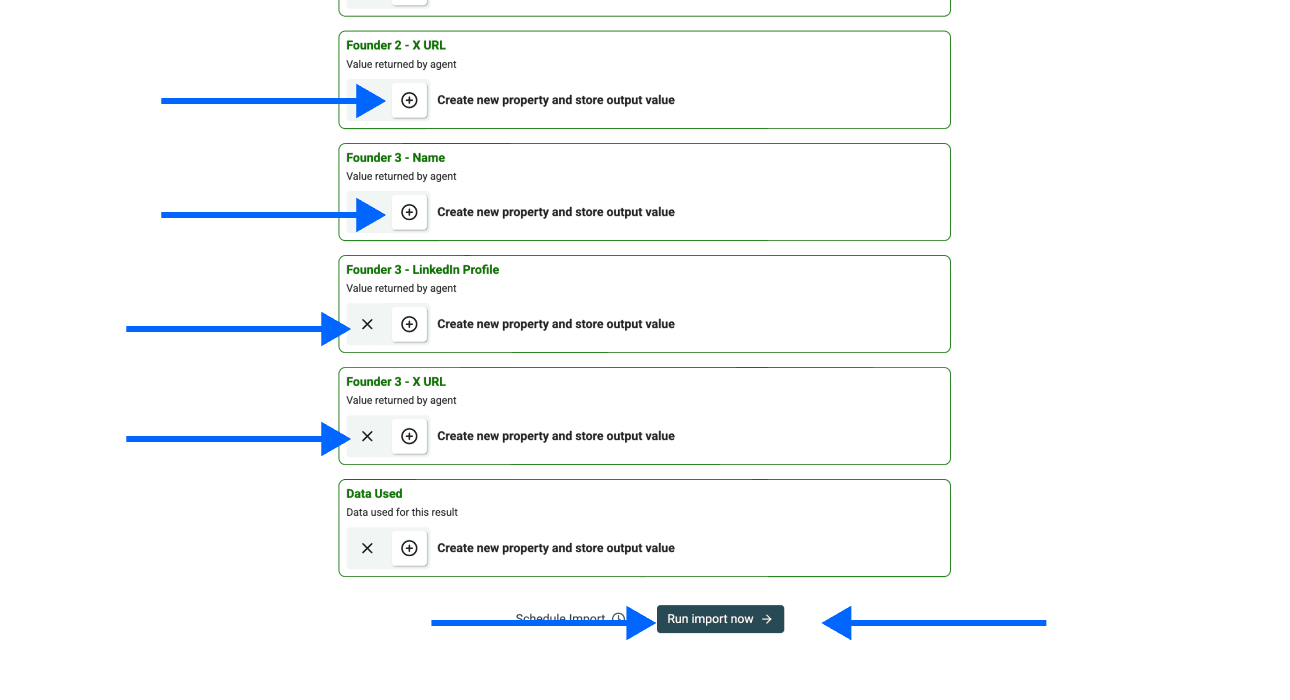
几分钟后,你的结果会像这样:
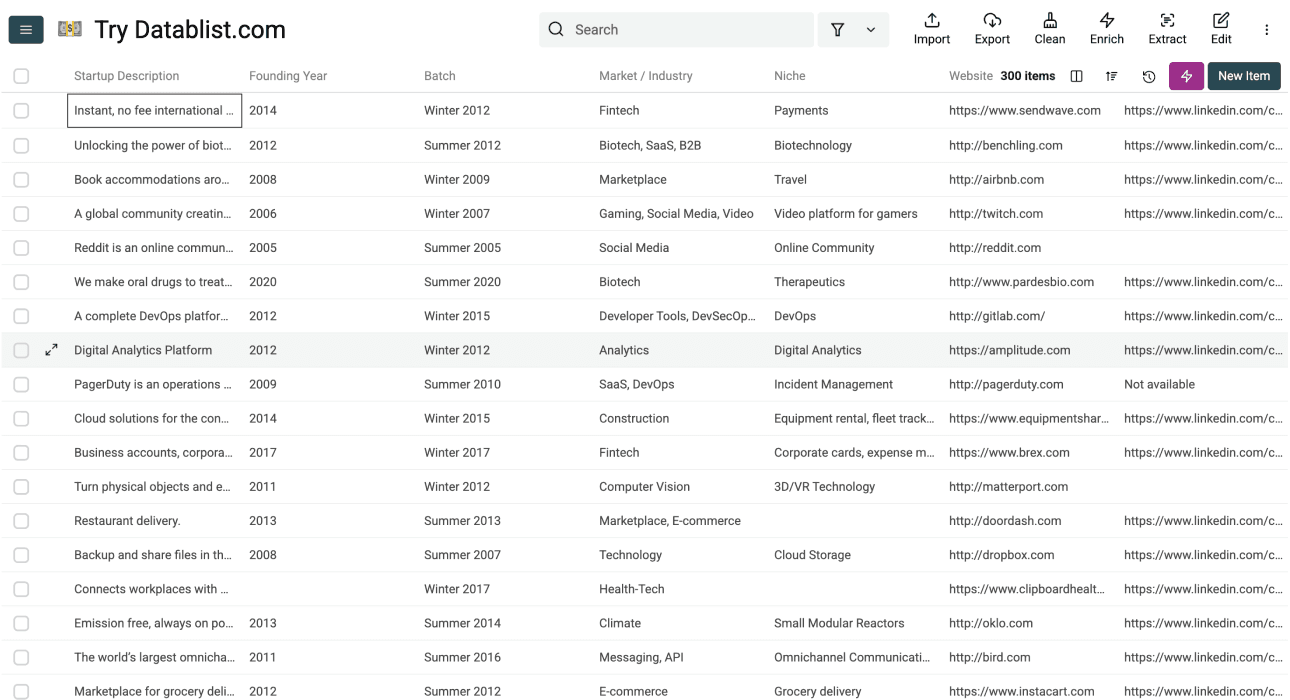
现在你已经拿到了完整数据: 公司详情、社交资料和 founder 信息,都集中在一个地方。
为什么 Datablist 是抓取 YC Directory 的最佳选择
当你比较不同的 Y Combinator startup scraping 方案时,会很快发现:并不是所有“no-code”工具都一样。Datablist 从一开始就是为了消除其他平台仍然存在的技术摩擦而设计的。 证据很直接:
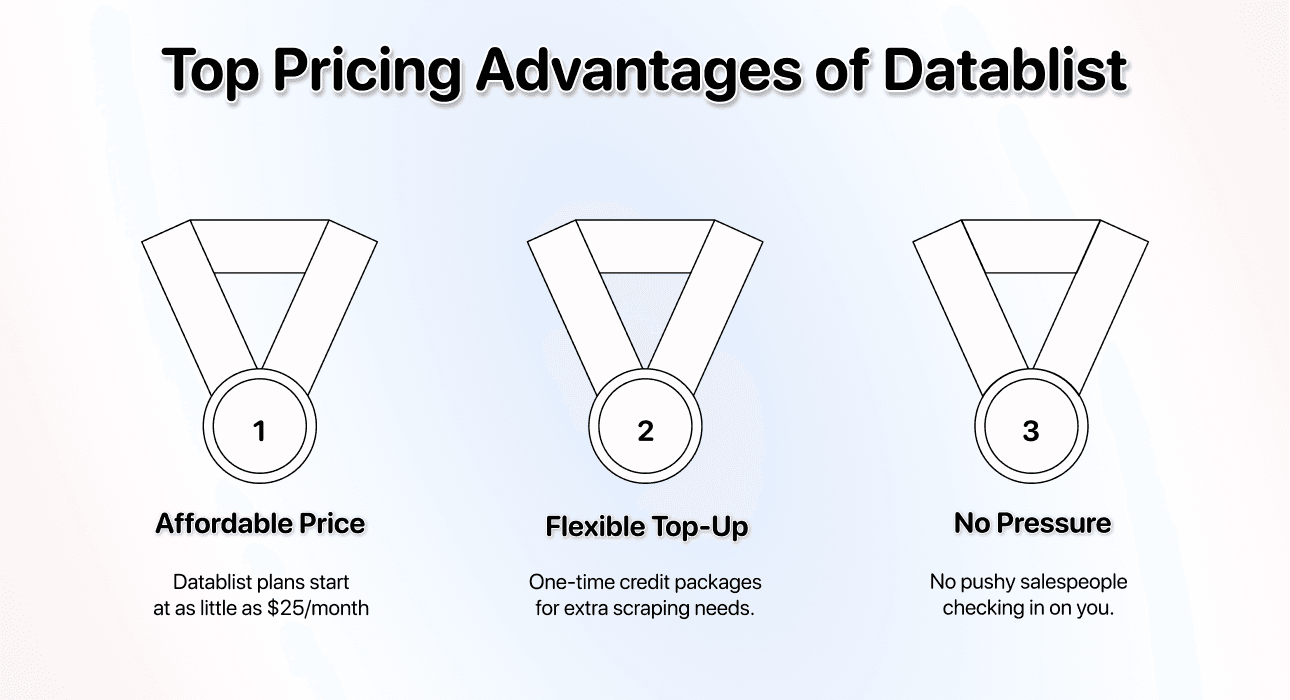
价格优势
- 起价仅 $25/month; 在市场上属于入门门槛很低、但能力很强的 scraping 方案
- 灵活的 credit system: 每月免费 credits 用完了?你可以直接购买一次性的 credit package,而不必升级整个套餐。
另外, 使用 Datablist,你不会遇到那些不断“跟进”的强推销售。
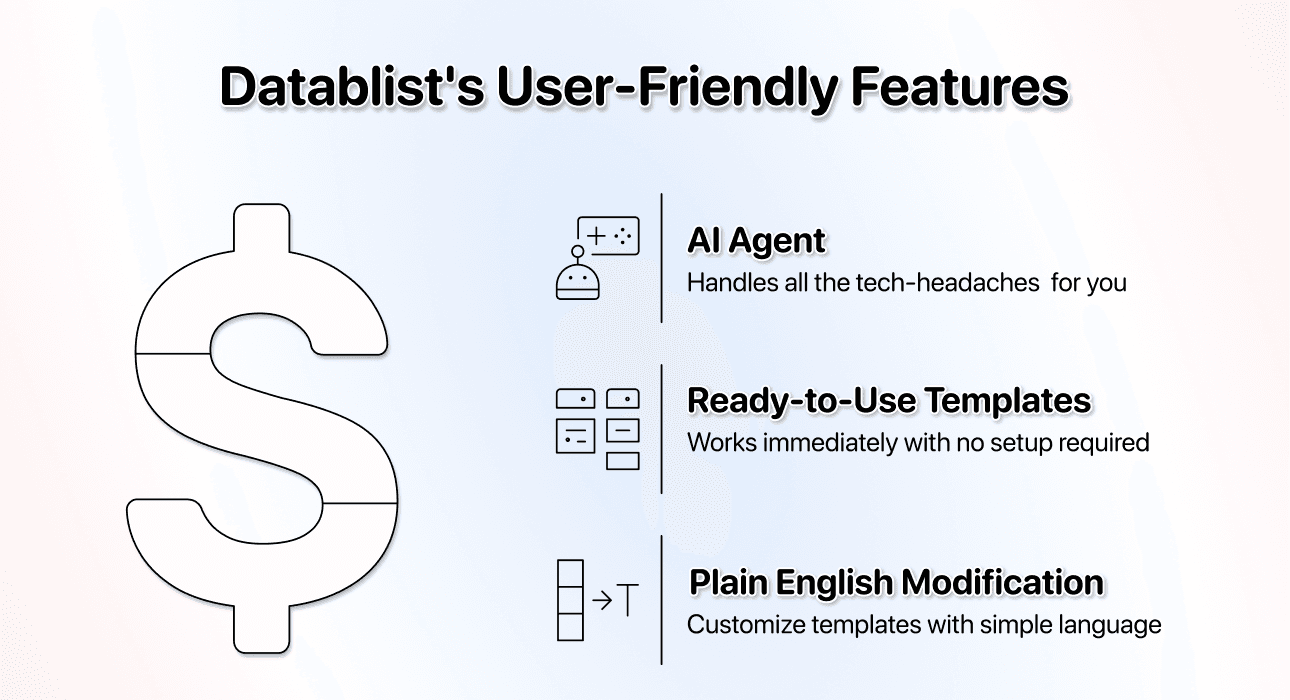
易用性
用户友好非常重要,这也很可能是 Datablist 做得最好的地方。
使用我们的 AI Agent,你不需要:
- 阅读文档
- 理解 API
- 在令人困惑的网页元素上 point-and-click
只要粘贴 Y Combinator directory URL,scraping 模板就可以立即使用。 没有复杂配置。即使你想修改模板、抓取不同的数据,也可以直接用自然语言完成。告诉 AI 你想要什么,剩下的交给它处理。
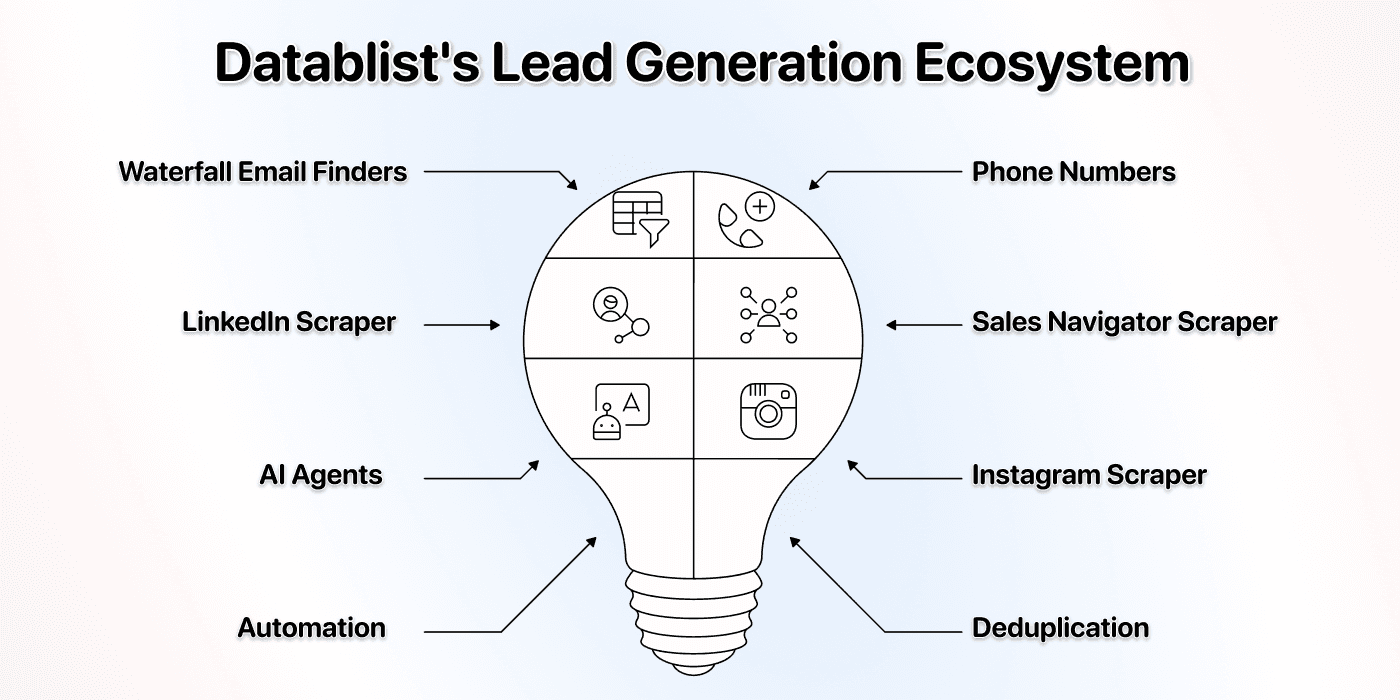
Lead Generation 生态
Scraping data 通常只是第一步。更重要的是你接下来如何使用这些数据。使用 Datablist,你得到的不只是一个 YC scraper,而是一个包含 60+ 工具的完整生态,用来支持你的 lead generation 工作。
拿到 YC startups 和 founders 列表后,你可以马上使用 Datablist 的其他工具,例如:
- Waterfall Email Finders: 为 founders 和团队成员查找已验证的 email addresses。
- Mobile Phone Number Enrichments: 获取可用于 cold calling campaigns 的直接手机号。
- LinkedIn Scraper: 从 LinkedIn profiles 收集专业信息。
- Sales Navigator Scraper: 在不影响账号安全的情况下从 Sales Navigator 提取 leads
- AI Agents: 规模化 AI search,并自动化从任意网站收集数据。
结论:抓取 YC 本来就应该很简单
从 Y Combinator directory 抓取 startups,不应该变成一个需要你“配置”和“研究”的项目。它应该是一项简单、快速的任务,直接给你业务增长所需的数据。
和那些仍然需要大量配置的“templates”不同,使用 Datablist 的 AI Agent,你唯一需要做的就是选择 YC template,粘贴 URL,然后启动流程。
你会在几分钟内得到一份干净、结构化的 leads 列表,而不是花几个小时折腾设置。这样你就可以把精力放在真正重要的事情上:联系潜在客户并创造收入。
P.S. 用 Datablist,真的比系鞋带还简单。
关于抓取 YC Startup Directory 的常见问题 FAQ
抓取 YC Directory 需要多少钱?
费用取决于你使用的工具。订阅 Datablist 后,每个月都会获得 5,000 个 free credits,所以你最低可以从 $25/month 开始 scraping。AI Agent 和 Datablist 里的其他工具一样,按 credits 计费,也就是 usage-based。例如,要抓取 500 家 YC startups,并获取完整公司和 founder details,大约需要 1000-1500 credits。
如何从 YC Directory 抓取 Startups?
最简单的方法是使用像 Datablist 这样的 no-code 工具。你可以直接使用 YC directory 的预构建 AI Agent templates。只要提供带有目标筛选条件的 directory URL,agent 就会通过简单的两阶段流程,自动提取 startup names、descriptions、founder information、social profiles 等数据。
抓取 YC Directory 合法吗?
抓取公开可访问的数据,例如 Y Combinator directory 里的 startup listings,通常被认为是合法的。不过,你仍然需要尊重网站的 terms of service,并以合规、负责任的方式使用数据,尤其是在 lead generation 场景中。
我可以从 YC Directory 获取哪些数据?
通常,你可以抓取 startup profiles 上展示的所有关键信息,包括:
Startup Info:
- Startup Name
- Startup Description
- Founded Date
- Batch
- Team Size
- Status
- Location
- Primary Partner
- Website URL
- LinkedIn URL
- X URL
Founders Info:
- Founder Names(最多 3 位)
- Founder LinkedIn URLs
- Founder X Accounts
为什么要抓取 YC Startups?
YC startups 是高潜力 leads,因为它们通常融资情况更好、增长更快,也正在积极搭建团队和技术栈。无论你销售软件、服务,还是做人才招聘,YC companies 往往都处在更强的采购或合作窗口期。在竞争对手之前拿到它们的联系信息,会带来非常明显的优势。
我可以自定义抓取哪些数据吗?
可以。Datablist 提供 ready-to-use templates,但你也可以用自然语言进行自定义。只要告诉 AI 你还想提取哪些信息,它就会相应调整 scraping process。不需要写代码。