
评估一款 no-code scraper,不该只看点选界面做得多干净。但很多“最佳 no-code scraper”榜单,偏偏就是这么排的。
这份排名换了一个标准。**我们用固定的 10 分基准,测试了 8 款 no-code web scraping 工具:**Datablist、Browse AI、Octoparse、Apify、Phantombuster、Outscraper、Instant Data Scraper 和 ParseHub。
我们的测试围绕几个核心问题:它能抓取任意网站吗?它的 AI 能理解自然语言字段描述,还是只能自动识别表格?它能帮你 enrich 抓取结果,还是只给你一堆原始数据?还有更多。
📌 赶时间先看这里
**首选:**如果你想在不写代码的情况下获得最强 scraping 能力,Datablist 是最佳 no-code scraper。
如果你需要抓取任意网站、用自然语言做 AI extraction,并且在同一个 spreadsheet 里完成数据 enrichment,Datablist 最适合,因为它在 power-first 基准中拿到 9.5/10 的最高分。
两个 AI agents 可用于抓取任意网站。预置 scrapers 可抓取 LinkedIn 数据、Sales Navigator leads、职位信息、Instagram 和 Google Maps。60+ enrichments 可直接补全 emails、phones 和 firmographics,不用离开当前页面。
**同场评测工具:**Browse AI、Octoparse、Phantombuster、Outscraper、Apify、Instant Data Scraper 和 ParseHub。每款工具的取舍会在下文展开。
**结论:**想要最强能力和最低使用摩擦,选 Datablist;只有需求非常窄时,才考虑专门工具。
本文会讲什么
- No-code scraping 到底是什么,以及该看哪些能力
- 我们使用的 10 分 power-first 评分基准
- 2026 年 8 款最佳 no-code scrapers 排名与评分
- 为什么纯 API 和开发者工具不参与排名
- 如何根据你的场景选择合适的 scraper
- 常见问题
什么才算 No-Code Scraper
“No-code”这个词,不同人理解不同。对开发者来说,它意味着不用写自定义脚本。对非技术用户来说,它还意味着不用配置 API、不用处理 authentication tokens,也不用改配置文件。
大多数人误解了 No-Code Scraper 的定义
很多人把 no-code scraping 定义成“不写脚本”。这个定义太窄了。
对非技术用户来说,配置 API 依然像是在写代码。你要写 requests、传 keys、处理 responses。摩擦并没有消失,只是换了个样子。
真正的 no-code scraper 不需要这些东西。不用 selectors,不用 scripts,不用 API configuration。你只需要输入网站,描述你想要的数据,它就返回结构化结果。
如何挑选 No-Code Scraper
有 5 个点,决定一款工具是你下个月还会继续用,还是一周后就放弃:
- **任意网站覆盖能力:**你能输入任意 URL,还是只能使用支持的 templates?
- **AI extraction 深度:**你能用自然语言描述字段,还是只能自动识别表格?
- **内置 enrichment:**它能清洗和 enrich 数据,还是只导出原始数据让你去别处处理?
- **设置摩擦:**是基于 Web、打开即用,还是需要安装桌面端和操作技术控制台?
- **价格可预测性:**按结果付费,还是按执行分钟计费,卡住和成功一样收费?
这些取舍很快就会影响实际使用。任意网站覆盖有限,会挡住小众页面;enrichment 太浅,会让你在三款工具之间来回拼接。
📘 本排名不包含什么
纯 API 和开发者专用服务(ScraperAPI、Bright Data、Zyte)会在结尾部分提到,但不参与排名,因为它们不符合零代码标准。
专门的 AI-only scrapers 会另写一篇文章;Clay 也不包含在内,因为它更像 licensed-data enricher,而不是 live scraper。
我们如何打分:10 分 Power-First 基准
前面提到过,我们定义了一套固定基准,用来衡量“零代码前提下的最大 scraping 能力”,然后用它测试 8 款 no-code scrapers。
每款工具从 0 分开始。原始 scraping 能力最多 6 分,再根据使用摩擦和成本可预测性最多加 4 分。总分最高者胜出。
Scraping 能力基准(6 分)
能力权重最高,因为这才是工具之间真正拉开差距的地方。其中 AI extraction 的权重最高。
- **AI / Natural-Language Extraction(2):**用自然语言描述字段,让工具自动查找并结构化数据。完整 agentic extraction 得 2 分;AI assist 或自动识别得 1 分。
- **Any-Site Flexibility(1):**可以输入任意 URL,而不只是使用支持的 templates。
- **Pre-Built Coverage(1):**无需搭建即可运行的 ready-made scrapers 覆盖范围。
- **JS / Dynamic / Pagination(1):**能处理现代、脚本较重、分页的网站。
- **Enrichment + Automation(1):**内置 cleaning 或 enrichment,并支持 scheduling 和 recurring runs。
使用摩擦和成本加分项(4 分)
这 4 分奖励那些既有能力,又不会让你花太多精力配置或猜账单的工具。
- **Setup Friction(1):**基于 Web、打开即用,优于桌面安装或技术控制台。
- **Output & Learning Curve(1):**输出干净、学习曲线低,优于需要大量清洗的工具。
- **Entry Price(1):**有免费层,或低门槛价格(约 $30/mo 或更低)即可解锁核心 scraping。
- **Pricing Predictability(1):**透明、固定或按结果付费,优于按 usage 计费且卡顿和重试都收费的模式。
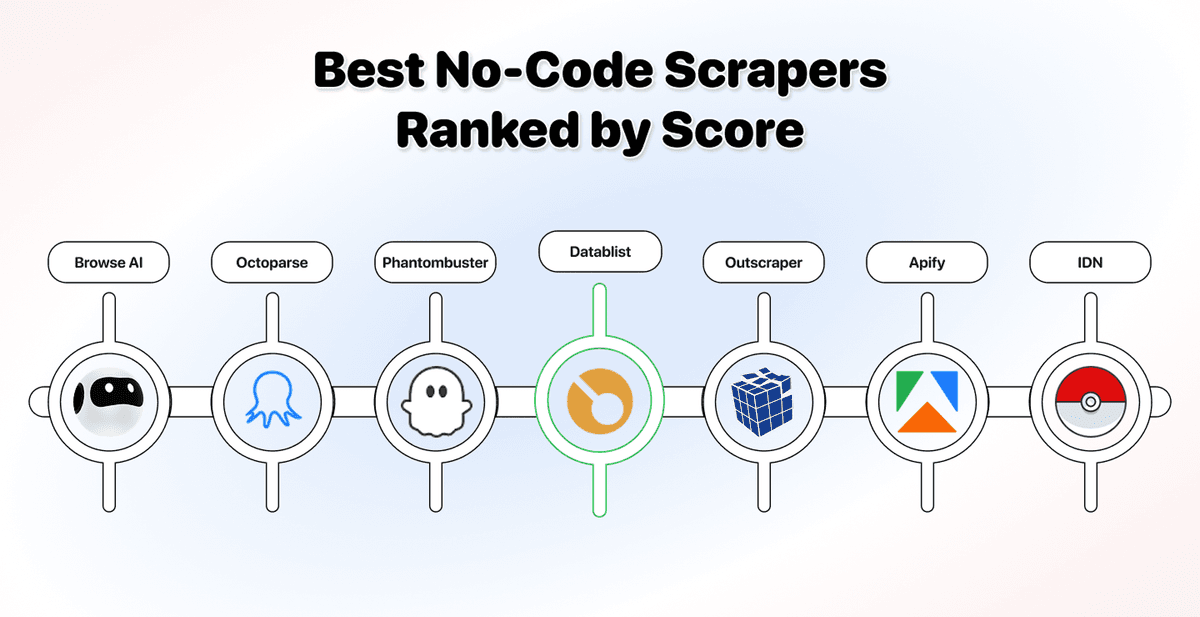
8 款最佳 No-Code Scrapers 一览
下面是详细分析前的完整排名。可以看到,按能力优先评分后,常见的“最简单工具获胜”排序被重新洗牌了:
| 工具 | AI Extract | 任意网站 | 预置工具 | JS / Dynamic | Enrich + Auto | 易用性 | 入门价 | 评分 |
|---|---|---|---|---|---|---|---|---|
| Datablist | ✅ ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | $25/mo | 9.5 |
| Browse AI | ✅ | ✅ | ✅ | ✅ | ⚠️ | ✅ | $19/mo | 7.5 |
| Octoparse | ⚠️ | ✅ | ✅ | ✅ | ⚠️ | ⚠️ | $83/mo | 7.0 |
| Phantombuster | ⚠️ | ❌ | ✅ | ✅ | ✅ | ✅ | $69/mo | 6.0 |
| Outscraper | ⚠️ | ❌ | ✅ | ⚠️ | ✅ | ✅ | PAYG | 6.0 |
| Apify | ⚠️ | ✅ | ✅ | ✅ | ✅ | ❌ | $29/mo | 5.5 |
| Instant Data Scraper | ⚠️ | ✅ | ❌ | ⚠️ | ❌ | ✅ | Free | 5.5 |
| ParseHub | ❌ | ✅ | ❌ | ✅ | ⚠️ | ❌ | Free / $189 | 4.5 |
2026 年 8 款最佳 No-Code Scrapers 排名与评分
下面的排名从最完整的 no-code scraper 到最垂直的专门工具。每个评分、价格和功能结论都来自逐一测试。
Datablist:无需写代码的最强 Scraping 能力(9.5/10)
Datablist.com 不只是一个 scraper。它是一个 AI-powered spreadsheet,你可以在同一个页面里 scrape leads、抓取网站数据、enrich、clean 和 dedupe。
为什么 Datablist 是突出的 No-Code Scraper
回到 no-code scraper 的定义:不写代码、不配 API、不处理 authentication。按这个标准,你很快就会明白为什么 Datablist 排第一。
这个平台提供多种 scraping 方法,实际可以覆盖几乎任何公开网站:
- Smart Scraper 可以快速抓取网站数据
- 两个 AI agents 可用自然语言处理更精确的抓取任务
- 另外 10+ scrapers 可提取 emails、LinkedIn 数据、Sales Navigator leads、Instagram followers、job postings 等。
除此之外,Datablist 还可以设置 automated workflows,并把 scraping 和 enrichments 串起来,让数据更容易直接使用。
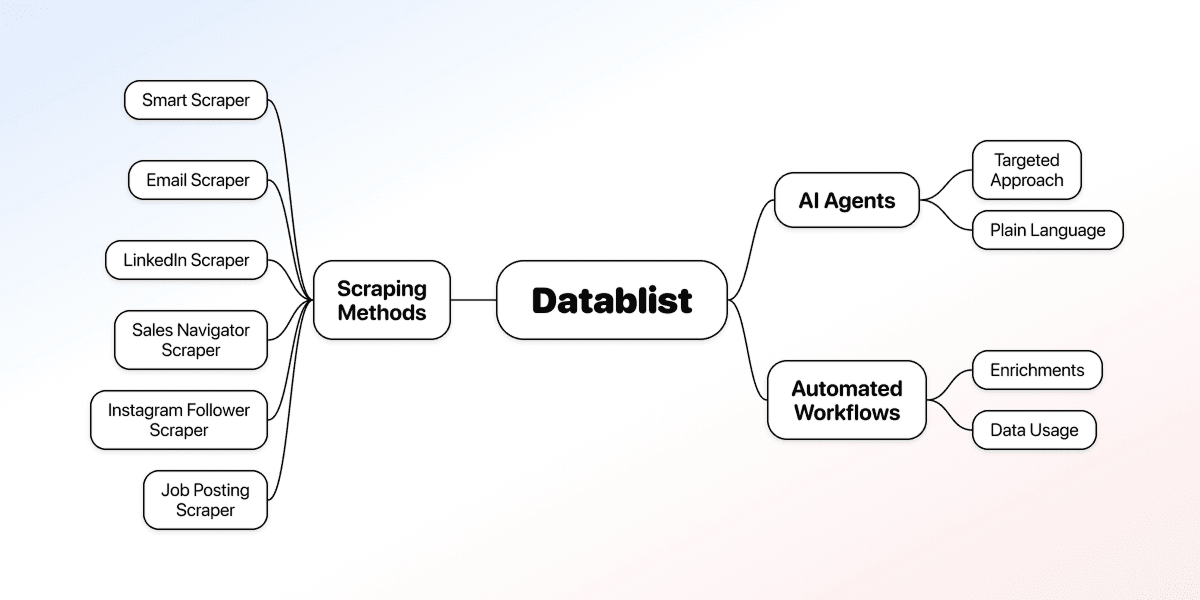
Datablist 的 No-Code Web Scraping 工具
- **Smart Scraper:**从任意页面提取 emails、links 和 website texts。非常适合后续交给 AI 做 account qualification
- **AI Scraping Agent:**用自然语言从页面中抓取完整列表,例如电商网站产品、目录条目、网站案例研究等。
- **AI Research Agent:**从一批网站中提取指定字段,帮助你在数千行数据上规模化 AI search。
除了 AI agents,Datablist.com 还提供一组现成的 scrapers 和 enrichments,用零配置处理最常见的 lead-gen 任务。
Datablist 的预置 Scrapers
这些预置 scrapers 覆盖 growth 和 recruiting 团队最常用的平台:
- **Sales Navigator Scraper:**在降低常见账号风险的情况下,从 Sales Navigator 导出 leads。
- **LinkedIn Jobs Scraper:**直接从 LinkedIn Jobs 抓取实时职位信息、职位名称和招聘公司。
- **Job Board Scraper:**一次运行即可收集多个 job boards 上的职位。
- **Instagram and Google Maps:**抓取社交资料和本地商家列表,用于 prospecting。

Datablist 的 Enrichments
Datablist 的 enrichments 可以把抓取到的数据变成完整 lead list:
- **Domain Finder:**批量匹配公司名称和官网。
- **Email and Personal Email Finder:**查找工作邮箱或个人邮箱。
- **Waterfall Phone Finder:**串联多个 providers,提高电话号码命中率。
- **LinkedIn Profile Finder:**只用姓名定位正确的 LinkedIn profile。
- **Company and Technology Enrichment:**补充 firmographics,并识别网站的 tech stack。
接下来是多数 scrapers 跳过的部分:60+ enrichments、deduplication 和 cleaning,以及高阶套餐上的 recurring runs。你可以在一个地方完成整个流程,而不是导出到三款工具。
**使用 Datablist 的优势:**你能在不写代码的前提下获得最强 scraping 能力,覆盖任意网站,支持自然语言 AI extraction 和 enrichment;同时有免费层,预置 scrapers 采用可预测的按任务计价。[1]
🆚 Datablist 的 No-Code Scraper 评分
- **评分:**9.5/10
- **价格:**Starter $25/mo,每月 5,000 credits;Growth $50/mo,20,000 credits(top-up credits 永不过期)
- **访问方式:**基于浏览器的 spreadsheet,另外也提供 API 给需要的人。
- **最适合:**想在一个地方完成任意网站抓取、自然语言 AI extraction 和 enrichment 的用户
- **不适合:**如果你在找一款好用的 no-code scraper,确实很难跳过它
Browse AI:最适合定时监控(7.5/10)
Browse AI 通过云端 point-and-click “robots”工作。你可以在几乎任何网站上录制一次 extraction,然后让它按计划监控变化。
你只需要录制一次 robot,它之后会自动重新运行。AI-assisted extraction 和 prebuilt robots 对页面结构识别不错,也可以用 prompt 指定字段,不过它更接近辅助录制,而不是完整的 agentic extraction。
它能处理动态页面、滚动和分页,也提供 prebuilt robots 库以及数千个 integrations。[2] 变化监控是它真正突出的地方。
差距在 enrichment 和 cleaning:它没有内置 email、phone 或 firmographic 层,而这些通常是让数据可用所必需的。输出在使用前也需要清洗。
🆚 Browse AI 的 No-Code Scraper 评分
- **评分:**7.5/10
- **价格:**免费 50 credits/mo;Personal 年付约 $19/mo(月付 $48);Professional 约 $69/mo 起
- **访问方式:**Web app、API 和 integrations
- **最适合:**定时监控和从特定页面做 recurring extraction。
- **不适合:**你需要内置 enrichment 或无需清洗的输出
Octoparse:最佳 No-Code 桌面 Scraper(7.0/10)
Octoparse 是一款适用于桌面端和云端的 no-code visual scraper,具备 AI auto-detect、大型 template library、scheduling、IP rotation 和 CAPTCHA solving。[3]
它的 point-and-click builder 基本可以覆盖任何公开网站,AI auto-detect 能扫描页面并一键生成 extraction template。**这是 AI assist,不是自然语言 extraction;**你不能用文字描述任意字段并让它理解。
它在 JavaScript、infinite scroll、pagination、dropdowns 和 forms 上表现很强,也有面向热门网站的大型 template library。Cloud scheduling 和并发能力也扎实。
Octoparse 和许多 no-code web scraping tools 有相同问题:没有 enrichment,输出是原始数据,需要后续清洗;云端 extraction 也需要桌面安装,并且要中档价位套餐才能解锁。
🆚 Octoparse 的 No-Code Scraper 评分
- **评分:**7.0/10
- **价格:**免费本地版;Standard 约 $83/mo
- **访问方式:**Desktop app、cloud 和 API
- **最适合:**目录、地图和通用网页上的模板化、定时 extraction
- **不适合:**你想要纯浏览器工具或内置 enrichment
Phantombuster:不太推荐(6.0/10)
Phantombuster 是一个预置 “Phantoms” 库。这些 Phantoms 是固定 workflow,运行在支持的平台列表上:LinkedIn、Instagram、Twitter、Google Maps 以及少数其他平台。
它针对特定资源有 catalog。Scheduling、通过 Flows 串联 workflow,以及 AI-assisted data cleaning 都能正常工作,前提是你的目标在它支持的列表里。
在 catalog 内,它还不错。一旦跳出 catalog,三个取舍会立刻出现:
- **不能抓任意网站:**Phantombuster 只能运行预置 Phantoms,所以你不能输入任意 URL。它也没有自然语言 extraction,只有一些固定 workflows。
- **账号风险:**它通过把 session cookies 连接到 Phantoms 来访问社交平台,这会增加检测风险(过去有用户被封过)
- **计费不可预测:**按执行时间计费意味着卡住和顺利运行一样收费,实际花费很难预估。
Phantombuster 有 free trial,但更适合快速看一眼:导出上限为 10 行,并包含一次性的 2 小时执行时间,不会每月刷新。[4]
🆚 Phantombuster 的 No-Code Scraper 评分
- **评分:**6.0/10
- **价格:**仅免费试用(导出上限 10 行,2 小时一次性执行时间,不每月刷新);付费 Start 约 $69/mo 起(年付 $56/mo)
- **访问方式:**Web app、API 和 integrations(Make、Zapier、n8n)
- **最适合:**不太推荐。它能做的事,Datablist 和其他工具通常能以更低价格、更少限制覆盖
- **不适合:**你需要抓取任意通用网站
Outscraper:适合低价获取 Google Maps 数据(6.0/10)
Outscraper 是一个 scrapers catalog(Google Maps、business data、reviews 等),提供 enrichment add-ons、pay-as-you-go 定价和 API。[5]
你选择一个 service,然后直接运行,无需安装。Universal AI Scraper service 增加了 AI-driven extraction,但平台主体仍是固定的预置 services,而不是自由形式的 extraction。
它的覆盖范围够用,输出也干净、结构化,并带有一些 contact enrichment、scheduling 和 API automation。不过它的重心明显在 Google Maps。
🆚 Outscraper 的 No-Code Scraper 评分
- **评分:**6.0/10
- **价格:**免费层;pay-as-you-go 基础记录约 $3/1,000 条起(带完整联系方式约 $9 到 $14)
- **访问方式:**UI、API 和 MCP server
- **最适合:**预算很低、只需要基础数据的团队
- **不适合:**你需要抓取某个具体的任意网站
Apify:最适合多样性和规模化(5.5/10)
Apify 是一个包含 43,000+ pre-built actors[6] 的 marketplace,同时有完整的 headless-browser engine,面向大规模抓取几乎任何网站。
论原始灵活性,这里没有其他工具超过它。SDK 和 custom actors 可以覆盖任意网站,pre-built catalog 是本榜单中最大的,JS rendering、infinite scroll 和 proxy rotation 都是一等能力。
问题在于零代码门槛。它的 console 偏技术,自定义工作需要写代码,社区维护的 actors 在质量和稳定性上差异较大。它也没有 first-party 自然语言 extraction 层。
计费也是另一个问题:compute-unit pricing 意味着卡住或被拦截的运行,和顺利完成的运行一样收费。因此不经过测试,很难估算每条 lead 的成本。[7]
🆚 Apify 的 No-Code Scraper 评分
- **评分:**5.5/10
- **价格:**免费 $5 credits/mo;Starter $29/mo,之后基于 compute-unit 计费
- **访问方式:**Task runner UI、API 和 SDK(JS/Python)
- **最适合:**技术用户,需要最大灵活性和最广 pre-built 覆盖
- **不适合:**你想要真正 no-code、适合初学者且成本可预测的 scraping
Instant Data Scraper:最佳免费一次性工具(5.5/10)
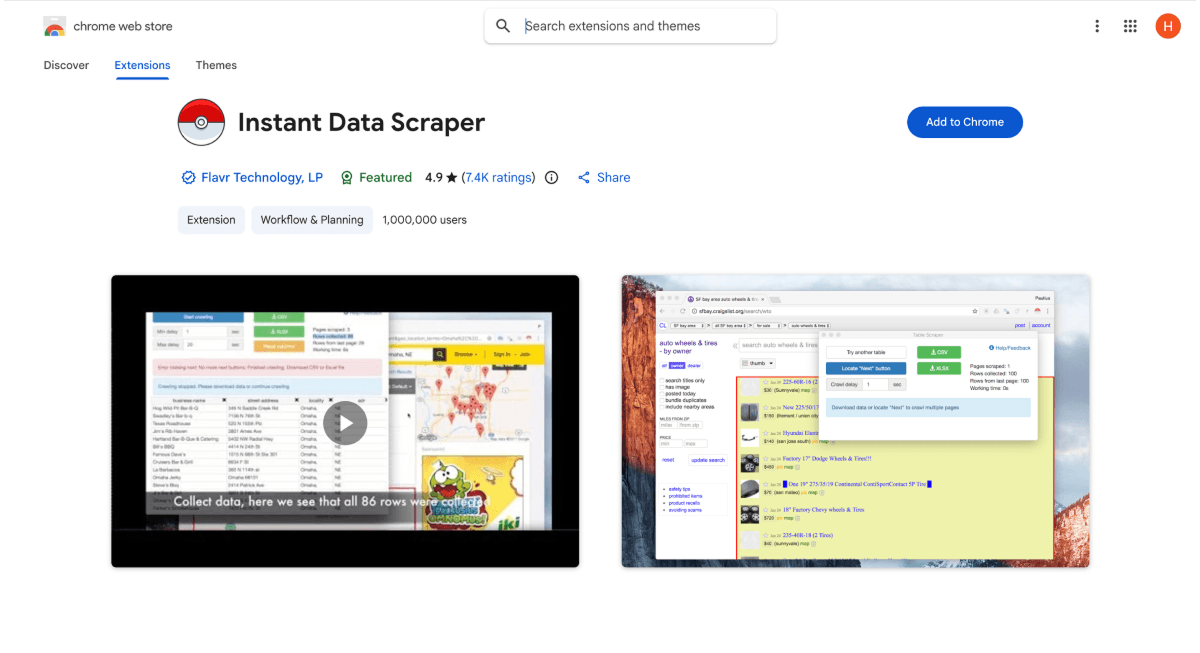
Instant Data Scraper 是一个免费的 Chrome extension,可用 heuristic 方法识别页面表格并导出,不需要账号。[8]
如果只是快速抓一次,它很难被超越:一键、即时、完全免费。它对列表页和表格页的覆盖很广,也能处理 infinite scroll 和基础 pagination。
但超过基础场景后,它很快就到顶了。没有 template library,没有 scheduling,也没有 enrichment,在复杂动态网站上表现不稳定。输出通常还需要清洗一遍。
🆚 Instant Data Scraper 的 No-Code Scraper 评分
- **评分:**5.5/10
- **价格:**100% 免费,无账号、无套餐层级
- **访问方式:**仅 Chrome extension
- **最适合:**快速、免费、一次性抓取表格
- **不适合:**你需要 recurring jobs、enrichment 或干净的结构化输出。
ParseHub:不太推荐(4.5/10)
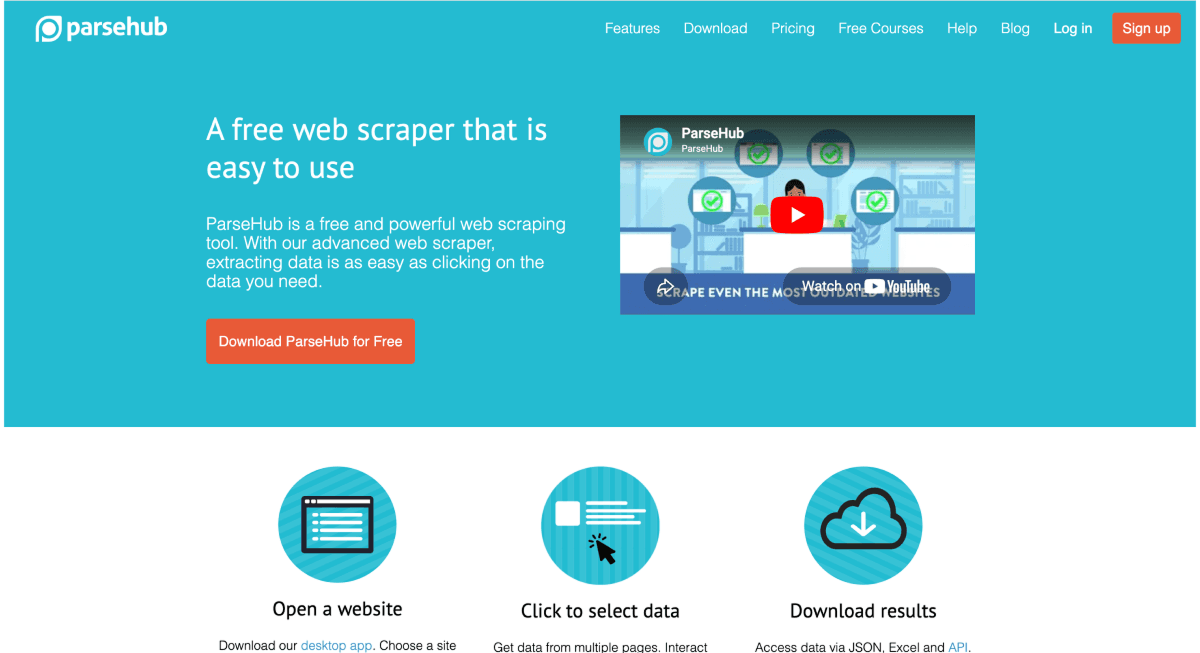
ParseHub 是一款 desktop visual scraper,可处理 JavaScript、AJAX 和 pagination,付费套餐支持 scheduling。
Visual selection 在多数公开网站上可用,对 dropdowns、AJAX 和 pagination 的处理也不错。免费层(每次运行 200 pages)[9] 让低预算测试更容易。
但缺点也很明显:没有 AI 或自然语言 extraction,没有真正的 template library,没有 enrichment,UI 像停留在 2012 年,学习曲线也陡。
付费套餐从 $189/mo[9] 起,和榜单里其他工具相比非常高。
🆚 ParseHub 的 No-Code Scraper 评分
- **评分:**4.5/10
- **价格:**免费层(200 pages/run);Standard 约 $189/mo
- **访问方式:**Desktop app 和 API
- **最适合:**不太推荐。
- **不适合:**你想要 AI extraction 或现代、低摩擦的工具
如何根据你的场景选择 No-Code Scraper
最好的 no-code scraper 取决于你的具体情况。可以这样选:
- **一个网站,还是多个网站?**任意网站任务更适合 Datablist、Apify 或 Octoparse;固定数据源更适合 Outscraper。
- **通用网页,还是社交平台?**Social 和 lead-gen scraping 更适合 Datablist。
- **一次性任务,还是 recurring?**快速抓一次适合 Instant Data Scraper;定时监控适合 Browse AI;重复任务可用 Datablist 完成。
- **原始数据,还是 enriched 数据?**如果你需要在同一个地方拿到 emails、phones 和 firmographics,Datablist 是唯一完整的 full-stack 选择。
- **预算多少?**免费测试适合 Instant Data Scraper 或各家的 free tiers;如果你希望支出可预测并能规模化,优先选择按结果计费的平台,而不是 compute-unit 或执行时间计费。
结论:Datablist 提供最强无代码抓取能力
如果你想在不写代码的情况下获得最强 scraping 能力,Datablist.com 明显胜出。它是唯一在 power-first 基准中达到 9.5/10 的 no-code scraper,把任意网站覆盖、自然语言 AI extraction,以及其他工具没有的 enrichment 放在一起。
在 social media 和 lead scraping 场景中,差距更大。你可以在不冒账号风险的情况下导出 Sales Navigator leads,抓取 LinkedIn job posts、Instagram profiles 和 Google Maps listings,并让 AI Research Agent 在数千行数据中补齐任意自定义字段。
Datablist 的 email、phone 和 company enrichments 会进一步把抓取数据变成可直接联系的 lead list,而且都在同一个 spreadsheet 里完成。对范围最广、摩擦最低的任务来说,没有其他工具接近它。
No-Code Scraper 常见问题
2026 年最佳 No-Code Web Scraper 是什么?
Datablist 在本基准中排名第一,得分 9.5/10。它结合了任意网站抓取、两个 AI agents 提供的自然语言 AI extraction,以及内置 enrichment 和 cleaning,覆盖了大多数 no-code scraper 应该完成的工作。
哪款 No-Code Scraper 最适合非技术用户?
Datablist 是非技术用户最强的选择,因为它基于熟悉的 spreadsheet 工作,并允许你用自然语言描述字段。Browse AI 和 Octoparse 也比较友好,但它们更依赖 point-and-click recording,而不是 AI extraction。
No-Code Scraper 能抓取任意网站吗?
有些可以。Datablist、Apify、Octoparse 和 ParseHub 实际上可以覆盖任意公开 URL。其他工具如 Outscraper 和 Phantombuster,只能针对固定数据源运行预置 scrapers,不能随便输入任意网站。
哪款 No-Code Scraping 工具价格最可预测?
按结果计费和固定价格在这里更占优。Datablist 的预置 scrapers 按任务固定收费,Octoparse 使用固定套餐。Apify 和 Phantombuster 更依赖 usage 或时间计费,卡住和重试也会产生费用。
No-Code Web Scraper 能用自然语言提取数据吗?
可以,最好的工具已经支持。Datablist 的 AI Scraping Agent 允许你用自然语言描述想要的字段。多数其他工具提供的是 AI assist 或 auto-detect,可以读取页面结构,但不能理解自由形式指令。
最便宜的 No-Code Web Scraper 是什么?
Instant Data Scraper 免费,Datablist、ParseHub 和 Browse AI 也有适合轻量使用的 free tiers。对于持续付费使用,Datablist 从 $25/mo 起,credits 可同时用于 enrichment[1],比单独购买 scraping、cleaning 和 enrichment 工具更划算。
什么是 No-Code Scraper?
No-code scraper 是一种无需脚本或 API 就能从网站提取数据的工具。你使用 visual builder、pre-built scraper 或 AI agent,而不是自己写 selectors,所以没有编程技能的人也能提取网页数据。
No-Code Web Scraping 工具如何工作?
Point-and-click 工具会记录你选择的页面元素,pre-built scrapers 面向已知数据源,AI scrapers 则像人一样阅读页面,并返回你描述的字段,全程不需要写代码。
不写代码可以抓取网站吗?
可以。No-code scrapers 会处理从访问页面到结构化数据的完整流程。使用 Datablist 这类 AI scraper 时,你只需粘贴 URL,用自然语言描述想要的数据,工具就会为你提取并结构化。
No-Code Scrapers 能处理 JavaScript 很重的网站吗?
多数现代工具可以。Datablist、Apify、Octoparse、Browse AI 和 ParseHub 都能渲染 JavaScript,并处理动态、分页页面。Instant Data Scraper 这类轻量 extension 在复杂动态网站上可能会失败。
No-Code Scraper 和 API Scraper 有什么区别?
No-code scraper 通过 UI 运行,不需要编程。API scraper,例如 ScraperAPI 或 Zyte,通过你写的代码返回数据。API 工具很强,但不符合零代码标准,所以本榜单没有把它们纳入排名。
No-Code Scrapers 对需要账号的平台安全吗?
像 Datablist 这样在自有基础设施上抓取的工具,不会把你的账号卷入流程。把 login cookie 放进 shared-IP cloud automation 的工具,例如 Phantombuster,会带来更高的检测风险。
社交媒体抓取最佳 No Code Scraper 是什么?
Datablist 可以抓取 LinkedIn 数据、Sales Navigator leads、Instagram followers 和 Instagram profiles,而且不用连接你的社交媒体账号。它也能抓取 Google Maps、LinkedIn Jobs、Indeed 等更多来源。
引用来源
-
[2] Browse AI 宣称提供 250+ prebuilt robots 和 7,000+ integrations,可将抓取数据路由到其他工具。
-
[5] Outscraper 的 pricing page 确认其有免费层,并提供约 $3/1,000 基础记录起的 pay-as-you-go 定价。
-
[6] Apify Store 列出 43,000+ web scraping 和 automation tools(actors)。
-
[7] Apify 的 pricing page 确认其免费计划包含每月 $5 usage credit,Starter plan 为 $29/mo,并按 compute units 计费。
-
[9] ParseHub 的 pricing page 确认其免费计划每次运行上限为 200 pages,Standard plan 价格为每月 $189。