

几个月前,我们上线了一个功能——当时完全没想到它会这么强。
结果现在,它正在把整个 no-code web scraping 行业搅得天翻地覆。
我说的这个功能,就是我们的 “AI Agent - Site Scraper” source。 这个 AI scraping agent 可以去任何网站,帮你找到、处理并提取你需要的数据。
而在几个月后的今天,我发现了 3 件事:
- 整个 no-code scraping 行业,本质上是一场大型“营销骗局”
- 我们在不知不觉中,做出了最好的 no-code scraper
- AI scraping agents 比任何过去的 no-code scraping tool 都更强大、更好用、更快
📌 赶时间的人速读版总结
这篇文章会讲清楚“真正的 no-code scraping”到底是什么,并证明它根本不需要 API、CSS selectors 或技术背景。如果你很赶,这里是核心摘要:
问题: 很多号称“no-code”的 scraping 工具,仍然要求你具备技术知识:要理解网站结构、看教程、花几小时配置;而网站只要小改一下,整个流程就会崩。
为什么这是个问题: 你不该为了从网页里提取点数据,就去学 API、CSS selectors,或者看几小时教程——这完全背离了 “no-code” 的初衷。
解决方案: Datablist 用 AI 驱动的 scraping:你用 plain English 描述需求,AI 负责剩下的一切。
你会学到什么: 这份指南会拆穿 no-code scraping 行业常见套路,展示“真正 no-code”的样子,并给出实用场景与 prompting 写法。
为什么用 Datablist 做 no-code scraping:3 个关键理由
- 真正 no-code:只要用 plain English 描述你想要什么
- 能处理复杂网站:JavaScript、分页、动态内容都不怕
- 网站改版也能适应:不像基于 CSS selector 的 scraper 那么脆弱
这篇文章会讲什么
No-Code Scraping 行业与它的“套路”
这一部分我们来拆穿 no-code scraping 行业里的各种“神话”和小把戏。事实是:大多数所谓的 “no-code” 工具,根本不是真的 no-code。 它们只是把技术复杂度换了个包装、换了个界面。
代码从来不是问题
你仔细想想:代码本身从来都不是问题。 如果你真的会写代码,你会直接用代码去 scrape——根本不会去搜索什么 no-code solution。
你会找 no-code,是因为你不想为了 scrape 一个网站就去学编程。但**市场很聪明,于是有人卖给你一个“半可用”的方案:**看起来不需要写 Python/JavaScript,但你仍然要面对:
- 很陡的学习曲线
- 看一堆教程
- 理解网站结构
有时候还要接触类似代码的概念,比如 CSS selectors。
真正的问题从来不是“code vs no-code”。
真正的问题一直都是:学习成本、复杂度、以及各种技术心智负担。
他们到底想卖给你什么
no-code scraping 行业主流有三种路线,但没有一种真正解决“复杂度”这个核心问题。
基于 API 的 Scrapers
这类工具会说自己是 “no-code”,因为你不需要写 Python 或 JavaScript。但他们通常不会主动告诉你:
你还是得处理:
- 网站 DOM 结构
- CSS selectors
- HTML tags
严格意义上你确实没在“写代码”,但你做的事情一样技术化:把人的需求翻译成机器可读的 selectors——说白了,就是“换个形式在编程”,而且步骤更多。

Click and Point 工具
这种方式更直观,但仍然要求你理解网站是怎么搭出来的。它只是让你“点一下元素”来配置,麻烦少一点,但绝不是无痛。
最大的问题是:只要网站结构一变,你往往就得从头再来一遍。 也就意味着:
- 教程再看一遍
- selectors 全部重配
- 祈祷这次能跑通
浏览器扩展(Browser Extensions)
本质上就是运行在浏览器里的 click-and-point 工具,而不是独立的 app。很多是免费的,比如 Instant Data Scraper。
这类工具的主要痛点:
- 网站改一下,就得全部重做
- 功能和规模有限,很难跑大批量
- 容易触发风控,导致 IP 被封
📘 你应该注意到的共同模式
这三种路线都强迫你去理解网站的技术结构。它们只是把技术复杂度“搬家”到不同的界面里。这不是在解决问题,只是在换个地方让你头疼。
你真正想要的是什么
坦白说,你真正想要的是:不折腾、无负担的 scraping,而不是什么“no-code scraping”这个标签。
所谓“无负担的 scraping”,应该长这样:
不头疼
- 别逼我学 CSS selectors
- 别让我看 3 小时教程
- 网站改版别把流程搞崩
无学习曲线
- 我应该立刻就能上手
- 不应该为了一个任务学一门新技术
本质上,你只想用自然语言描述目标,然后直接拿到结果。其它所有步骤,都是行业习以为常但完全没必要的摩擦。
解决方案:用 AI 替代 No-Code Scraping
no-code scraping 的解法,不是把 click-and-point 做得更漂亮,也不是给你一个更“干净”的 API。真正的解法,是把技术层彻底拿掉,改用自然语言。
AI Scraping 如何让 no-code 真的变成 no-code
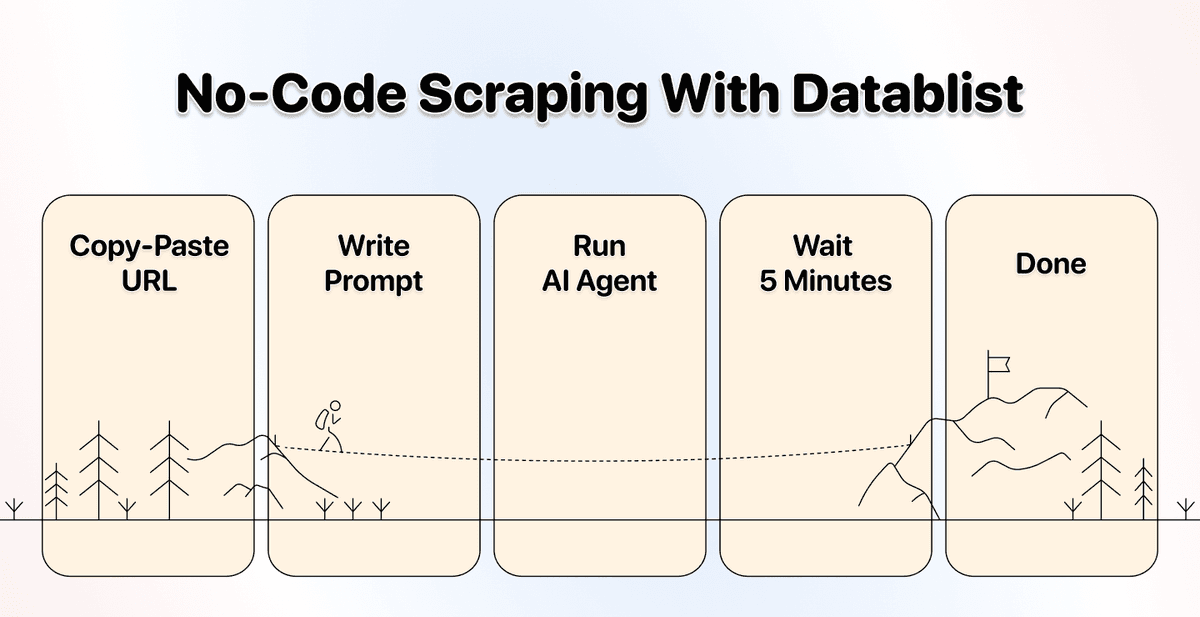
顾名思义,AI scraping 是让 AI 去 scrape,而不是你。
在 AI 驱动的 no-code scraping 里,你只需要告诉系统:要做什么、怎么做、什么时候做。技术细节全部由 AI 在后台处理。
你不需要懂:
- CSS selectors 或 HTML 结构
- 网站 DOM 架构
- API endpoints 或技术文档
你只要给出 plain English 指令,AI scraping agent 会把剩下的都搞定。这才是 no-code scraping 从一开始就该有的体验。
提供这个解法的公司: Datablist.com
就像开头说的,我们并没有计划“干掉”整个 no-code 行业;我们是阴差阳错做到的——因为有个用户需要 scrape 一个网站,我们就给他做了个解决方案。
我们给他做了一个 AI Agent,可以:
- 理解 plain English 指令
- 自动在复杂网站里导航
- 处理 JavaScript 很重的页面
- 处理分页内容
- 更智能地提取数据
- ….
突破点不在于“又做了一个更强的 scraper”。
而在于:我们把“需要技术能力”这件事直接消掉了。
你告诉 AI 你要什么,它会自己想办法拿到。
不需要 CSS selectors,不需要 DOM inspection,也不需要教程。
Datablist 是什么
Datablist 是一个面向非技术用户(sales、marketing、recruiting 等)的平台,用来做 automation lead generation、data enrichment 和 data cleaning workflows。
你可以用它来查找、清洗并 enrich 数据,平台提供超过 60 个工具,从 AI Agents 到 Email Finders、AI processors、Technology enrichments 等等。

另外,Datablist 还支持你搭建自动化 workflow:可以定时跑,也可以按需触发。 一些非常典型、也很受用户欢迎的用法包括:
- Building lead lists
- Personalizing emails with AI
- Cleaning and deduplicating CRMs
- Scraping job postings from 19 boards at once
- Scrape thousands of Business from Yellow Pages
- Scraping LinkedIn Sales Navigator searches without risking your account
重点很明确:如果你需要获取、清洗、enrich 数据,或者把围绕数据的流程自动化,并且希望它简单、快速、稳定,那 Datablist 就是你该去的地方。
更关键的是:Datablist 还“顺手”把 no-code web scraping 这个难题解决了。
💡 用 35 个词总结 Datablist
Datablist 是一个用于自动化 lead generation workflow 的平台,提供超过 60 个工具,包括 AI Agents、用于找邮箱和电话的 Waterfall Enrichment、用于去重的 data cleaning 工具等。
为什么选择 Datablist
Datablist 的 no-code scraping 路线跟市场上其他产品不一样,因为**我们不卖“包装得很漂亮的技术头疼”;**我们直接用 AI scraping。
对你来说意味着:
真正的 No-Code
- 零技术门槛
- 不用懂 HTML 或 CSS
- 网站每次更新,你的 automation 也不容易崩
你只需要会 Prompt
- 用 plain English 写清楚你要什么
- AI 能理解上下文和意图
多种 scraper 模板
- 常见场景的预置 prompts
- 目录站(directory)scraping 模板
- 电商网站 scraping 模板
- Case study 提取模板
抓目录网站最省心
- 适用于 Yellow Pages、Yelp、TripAdvisor、Alibaba
- 自动处理分页
不需要在 10 个工具间来回导入导出
- 数据直接进 spreadsheet 式界面
- Edit、筛选、enrich 一站完成
- 直接接入完整的 lead-generation 生态
AI Scraping 的使用场景与实战技巧
用 Datablist 去 scrape 网站、目录站,甚至把 AI search 规模化,其实都很简单;方法始终一致:把你想要的东西描述得越具体越好。
Prompting 速成入门
在展开所有可用场景之前,我先用最短的方式告诉你:该怎么给这个 AI scraping agent 下指令。
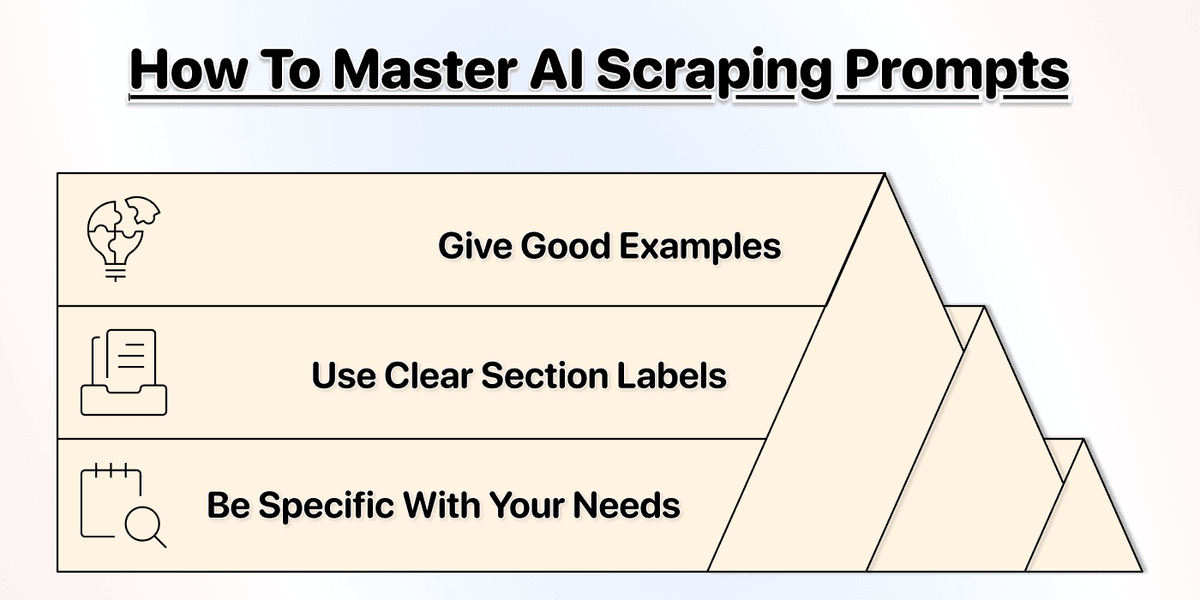
Prompting 规则:
好的 prompting 很简单。 你不需要是什么专家,只需要把需求说清楚。下面几条能明显提升效果:
具体一点(Be Specific)
- 别说 “get product info”
- 要说 “get product name, price, and availability status”
- 可能的话,给几个例子
这样你更容易拿到你真正想要的数据,也能避免 AI agent 自己“猜错”。
用分段标签(Use Section Labels)
- 用清晰的章节来组织 prompt
- Goal:你要达成什么
- Data Points:你要哪些字段
- Format:你想要的数据结构
- Constraints:要排除什么/必须包含什么
分段能让 AI agent 更快理解你的需求。不是硬性要求,但我们发现它能显著提高准确率。
给例子(Give Examples)
AI agent 也不是全知全能,有些网站结构非常复杂。给例子可以减少误判(false positives)、提高准确率,并降低成本。
这里有一份更详细的教程: detailed guide on how write a prompt for an AI agent 👈🏽
💡 Pro Tip:分页怎么处理
Datablist 的 AI Agent 可以自动处理分页内容。你只要在 settings 里开启 pagination,并设置最大页数。agent 会自动翻页并逐页提取数据。
===
Data Points I Need:- Product Name (example: "Classic T-Shirt")
- Price (example: "$29.99")
- Product URL (full link)
- Availability (In Stock / Out of Stock)
===
Format:- Return one row per product
- Use "N/A" if data is missing
===
Constraints:- Skip promotional banners
- Only get actual products, not category pages
No-Code Scraping 使用场景
no-code scraping 的可用场景几乎没有上限。下面是我们目前看到最常见、也最有效的 AI scraping use cases:
目录站(Directories)
- Scraping businesses from Yellow Pages
- 抓 Yelp 餐厅数据
- Scraping properties from AirBnB
- 抓 TripAdvisor 酒店信息
- 抓 Alibaba 供应商目录
- Scraping properties from Zillow
- Scraping Realtors from Zillow
电商网站(E-Commerce Websites)
其他(Other)
- Scrape all case studies from a website
- 从展会网站提取参展商名单
📘 如何同时 scrape 多个网站
如果你有一批相似的网站要抓取,你也可以用 Datablist's AI Research Agent 去 scrape 一个网站列表。这个 agent 还有额外能力,支持规模化的 AI search。
结论:No-Code Scraping 应该改名
no-code scraping 真应该改名叫 “No-tech-headache scraping(不折腾式抓取)”,因为这才是大家真正想要的。
你搜索 no-code scraping,不是因为你不会写代码;而是因为你不想为了提取点数据,就去学一堆技术。
所以如果 scraping 并不是你核心的赚钱活动,那你就不应该被迫浪费几个小时折腾它。 解法也不是更好的 API 或更精致的 click-and-point 界面。
**解法是把技术层彻底移除,**也就是 AI scraping。
用 Datablist,你可以做到这些,并且:
- 几分钟出结果,不用折腾几小时
- 从一个网站扩展到上千个网站
- 用 plain English 描述需求
- 网站变化也能自动适配
no-code scraping 的问题终于被解决了。 而我们是“无意间”做到的。

No-Code Scraping 常见问题 FAQ
Datablist 可以 scrape 各种目录站吗?
可以。Datablist 的 AI Scraping Agent 很适合抓取各种目录站,而且 agent 会自动处理分页(pagination),所以你不用手动配置,也能一次性提取成千上万条 listing。
例如,我们已经成功抓取过:
- TripAdvisor 的 reviews、酒店、餐厅等数据
- Yellow Pages 商家列表
- Airbnb 房源目录
- Alibaba 供应商数据库
- Yelp 商家信息
- ……以及更多
我可以自动 scrape 多页数据吗?
可以。Datablist 的 AI Scraping Agent 支持自动分页。你只需要在配置里设置最大页数,agent 就会自动逐页浏览,并把每一页的数据都提取出来,全程无需手动干预。
适用于:
- 电商产品目录
- 多页的目录站列表
- 带分页的搜索结果
- 博客归档页
- …
使用 Datablist 的 scraping agent 要多少钱?
Datablist 的 AI agents 采用 usage-based(按用量计费),具体会随任务复杂度变化。以 Yellow Pages 这种目录站为例,成本通常更低,抓取 1000 条 listing 大概在 800–1000 credits 之间。像 Shopify 这类 JavaScript 很重的网站,成本会更高。
什么是 no-code scraping?
no-code scraping 指的是:在不写代码、也不需要技术技能的前提下,从网站提取数据。真正的 no-code scraping 应该是:你用 plain English 描述你要什么,然后直接拿到结果;不需要懂 HTML、CSS selectors 或 API。
Datablist 能处理 JavaScript 很重的网站吗?
可以。Datablist 的 AI Agent 能 scrape JavaScript-heavy 网站。在 advanced settings 里开启 “Render HTML”,确保 agent 等 JavaScript 加载完成后再提取数据。
这对 React、Vue、Angular 这类会在首屏后动态加载内容的网站尤其关键。
no-code scraping 和传统 web scraping 有什么区别?
传统 web scraping 需要编码能力(Python、JavaScript)或技术技能(CSS selectors、XPath)。no-code scraping 则试图消除这些要求,通过可视化界面,或像 Datablist 这样通过自然语言理解来完成。
AI scraping 和基于 CSS selector 的 scraping 有什么不同?
基于 CSS selector 的 scraper 依赖网站 HTML 的“精确结构”。网站只要改个布局,scraper 往往就会失效。
AI scraping 识别的是内容的含义,而不只是它在 HTML 里的位置。即使 class 名变了,它也能判断“这是价格”“这是产品名”。因此更抗变化,几乎不需要维护。
no-code scraping 合法吗?
web scraping 是否合法,取决于你抓什么、怎么用。抓取公开数据通常是合法的,但你应该:
- 尊重 robots.txt
- 避免抓取需要登录的内容
- 合理使用数据,并遵守隐私与合规要求
- 不要用过量请求压垮对方服务器