

Hast Du eine chaotische Liste voller Duplikate? Egal ob Kundenkontakte, E-Mail-Abonnenten oder Produktbestände: Doppelte Einträge solltest Du rauswerfen – sonst kosten sie Dich Zeit und Geld. Stell Dir vor, Du schickst einem Kunden dieselbe E-Mail zweimal: nicht nur nervig, sondern schlecht für Dein Markenimage.
Die gute Nachricht: Du kannst Deine Liste online kostenlos deduplizieren – mit Datablist. Das Tool ist simpel, aber richtig leistungsstark: Du entfernst Duplikate, bereinigst Deine Daten und bringst Ordnung rein. Ohne Code, ohne Stress.
In dieser Anleitung zeigen wir Dir in drei einfachen Schritten, wie Du eine Liste deduplizierst:
- Liste importieren und vorbereiten
- Duplikate finden und matchen
- Duplikate zusammenführen und Liste bereinigen
Teil 1: Liste mit Duplikaten importieren
Der erste Schritt, um Deine Liste online zu deduplizieren – mit Datablist – ist super einfach: Du bringst Deine Daten in die Plattform.
Datablist kommt mit den gängigen Listenformaten klar (CSV, Excel). Du kannst Daten auch aus externen Quellen laden, zum Beispiel aus Pipedrive.
Step 1: Create a New Collection
Stell Dir eine Collection in Datablist wie eine Tabelle (Spreadsheet) vor. Zum Start legst Du eine neue Collection für die Liste an, die Du deduplizieren willst.
Klicke in der Sidebar auf den „+“-Button, um eine neue Collection zu erstellen.
Klicke in Deiner neuen Collection auf „Import CSV/Excel“. Oder auf „Sources“, wenn Du eine fortgeschrittene Integration nutzen willst.
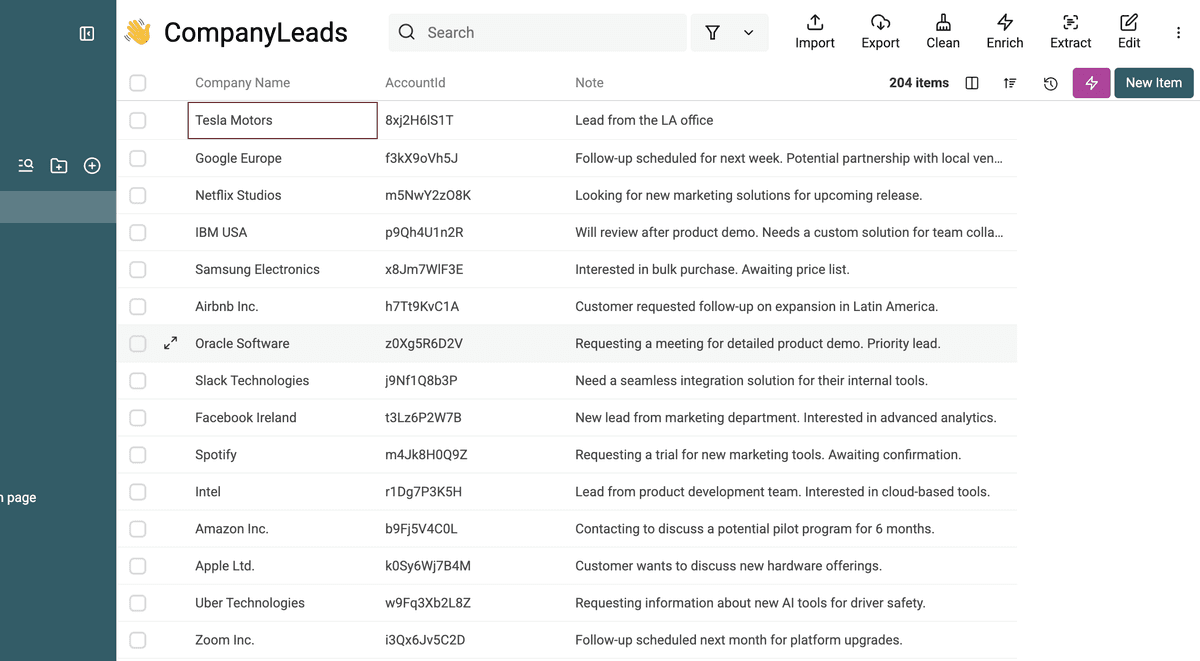
Nach dem Upload zeigt Dir Datablist eine Vorschau Deiner Daten: Spalten (Properties) und ein paar Zeilen. Schau kurz drüber, ob alles korrekt aussieht.
Teil 2: Duplikate in der Liste finden
Deine Liste ist bereit. Jetzt geht’s an die Duplikate.
Datablist nutzt fortgeschrittene Algorithmen, um Datensätze zu erkennen, die sehr wahrscheinlich Duplikate sind – auch wenn sie nicht zu 100% identisch sind.
Step 1: Open the Duplicates Finder
Um die Suche zu starten, geh in Deiner Datablist-Collection ins Menü „Clean“ und klicke auf „Duplicates Finder“.
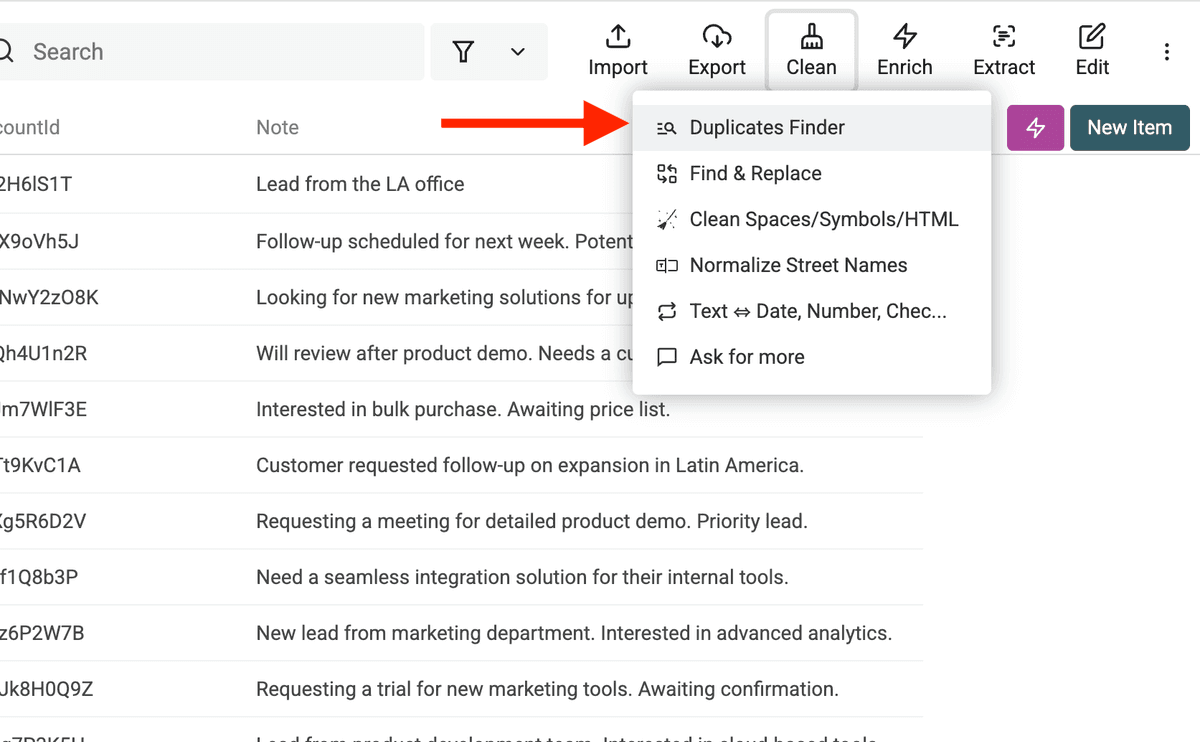
Damit öffnest Du den Duplicates Finder. Hier legst Du fest, wie Datablist Duplikate in Deiner Liste finden soll.
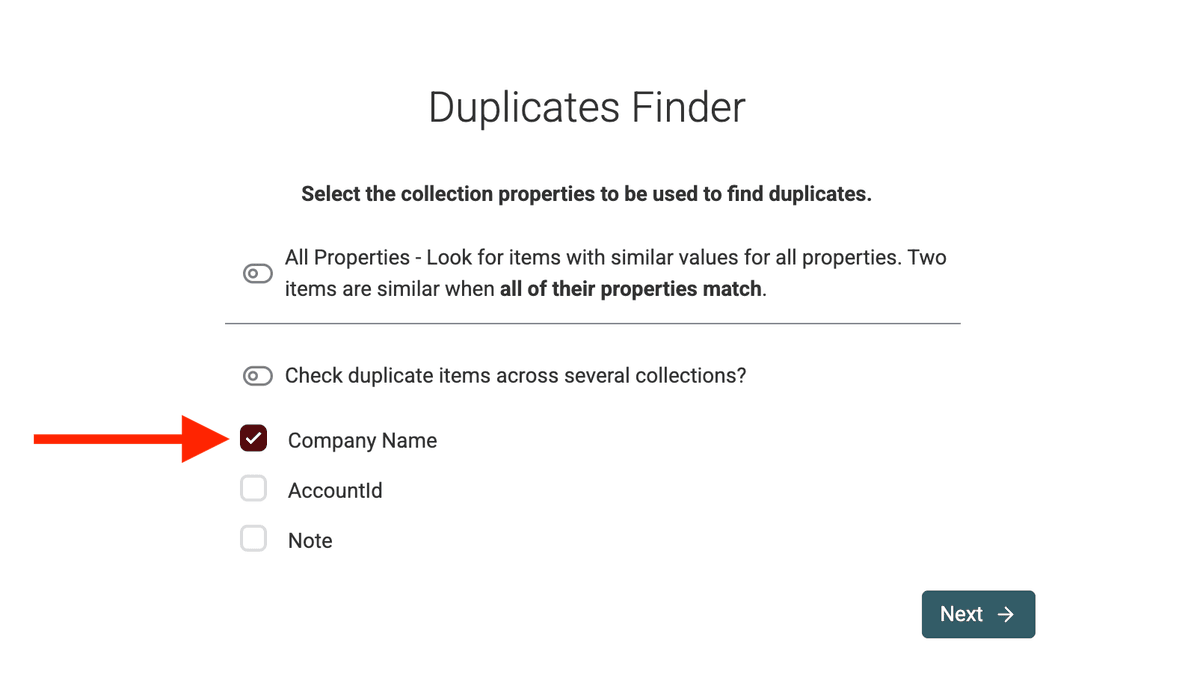
Step 2: Pick What to Compare: Deduplication Properties
Eine „Deduplication Property“ ist einfach die Spalte (oder das Feld) in Deiner Liste, die Datablist nutzt, um Datensätze zu vergleichen und Duplikate zu erkennen.
Wähle die passende Property je nach Listentyp:
Zum Beispiel:
- Contact Lists: Bei Personen ist die E-Mail-Adresse oft am zuverlässigsten, weil sie in der Regel eindeutig ist. Wenn nicht überall E-Mails vorhanden sind, kannst Du auch Name oder Vorname und Nachname kombinieren.
- Product Lists: Bei Produkten bieten sich Produktname oder eine eindeutige Produkt-ID (EAN, GTIN, SKU) an.
- Company Lists: Bei Unternehmen sind Company Name oder die Website-URL gute Optionen.
Im Duplicates Finder wählst Du eine oder mehrere Properties aus, die fürs Matching genutzt werden sollen.
Step 3: Select Matching Algorithm & Processor
Datablist bietet Dir mehrere Möglichkeiten, Daten zu vergleichen – je nachdem, wie streng Du sein willst:
- Exact: Findet nur Datensätze, bei denen die gewählte Property exakt identisch ist. Perfekt für wirklich identische Einträge.
- Smart: Der Smart-Algorithmus ist toleranter. Er erkennt z. B. URLs, die eigentlich gleich sind, aber unterschiedlich beginnen (http vs. https), oder kleine Unterschiede bei Zeichen und Interpunktion.
- Phonetic (Double Metaphone): Ziemlich praktisch: Matcht Datensätze nach Klang statt nach Schreibweise. Ideal bei Namen, die unterschiedlich geschrieben werden können, aber gleich klingen.
- Fuzzy Matching (Jaro-Winkler & Levenshtein): Sehr „intelligent“: Berechnet, wie ähnlich sich zwei Texte sind. Du stellst einen Ähnlichkeitswert ein, sodass auch Tippfehler, Abkürzungen oder leichte Abweichungen als Duplikate markiert werden.
Note: The Exact algorithm is available for anonymouse users. The Smart algorithm requires a free account. And the Metaphone and Fuzzy Matching algorithms are only available for the paid plans.
Wähle den Algorithmus, der für Deine Deduplication Properties am meisten Sinn ergibt.
Außerdem solltest Du den passenden processor festlegen, um Deine Daten vor der Deduplication zu normalisieren. So matchen ähnliche Werte auch dann, wenn sie leicht unterschiedlich formatiert sind.
Häufige Processor in Datablist:
- URLs - Entfernt Protokolle (http, https), Query-Parameter und Tracking-Codes, damit identische Links gematcht werden.
- Beispiel: https://example.com?utm_source=newsletter → example.com
- Emails - Ignoriert Aliase wie +filter bei Gmail-Adressen, damit Varianten gematcht werden.
- Beispiel: john+work@gmail.com → john@gmail.com
- Company Names - Entfernt Rechtsformen (Inc., LLC), Business-Zusätze (Partners, Group) und geografische Begriffe (Europe, USA).
- Beispiel: Acme Inc. → Acme
Note: The Company Names processor is only available for the paid plans.
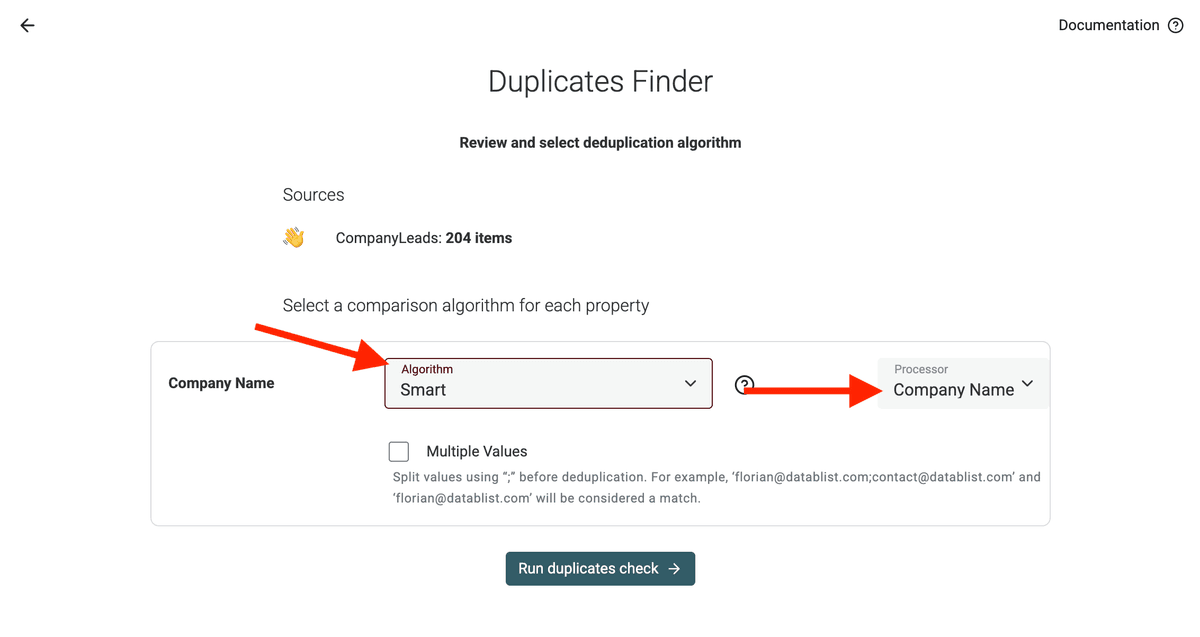
Dedupe fields with several values - If your deduplication property contains multiple values, check the "Multiple Values" settings.
👉 Wichtig: In mehreren Durchläufen deduplizieren
Für die meisten Listen empfiehlt es sich, zuerst mit „Smart“ zu starten und danach noch einen zweiten Durchlauf mit „Fuzzy matching“ zu machen – entweder auf derselben Property oder auf einer anderen (z. B. Name, wenn Du zuerst auf E-Mail gematcht hast).
Duplikate, die „Smart“ findet, sind in der Praxis sehr oft echte Duplikate. Die kannst Du meistens ohne großen Prüfaufwand zusammenführen.
Bei Distance-Algorithmen kann es aber „false positives“ geben: Zwei Namen mit einem anderen Buchstaben können dieselbe Person/Firma sein – oder auch nicht. Deshalb solltest Du solche Duplicate Groups besonders sorgfältig prüfen (siehe weiter unten).
✅ Pro Tip: Erst Smart Matching, dann mit Distance (Fuzzy) Matching verfeinern.
Step 4: Run the Deduplication Check
Wenn Du Properties und Algorithmus/Algorithmen ausgewählt hast, klick einfach auf „Run duplicates check“, um den Deduplication-Prozess zu starten.
Datablist scannt Deine Liste und gruppiert Datensätze, die auf Basis Deiner Einstellungen potenzielle Duplikate sind.
Step 5: Review the Detected Duplicate Groups
Nach dem Scan zeigt Dir Datablist eine Liste mit „Duplicate Groups“.
Jede Gruppe enthält zwei oder mehr Datensätze, die sehr wahrscheinlich Duplikate sind.
In jeder Duplicate Group siehst Du, wie die Datensätze gematcht wurden – und ob es widersprüchliche Werte gibt.
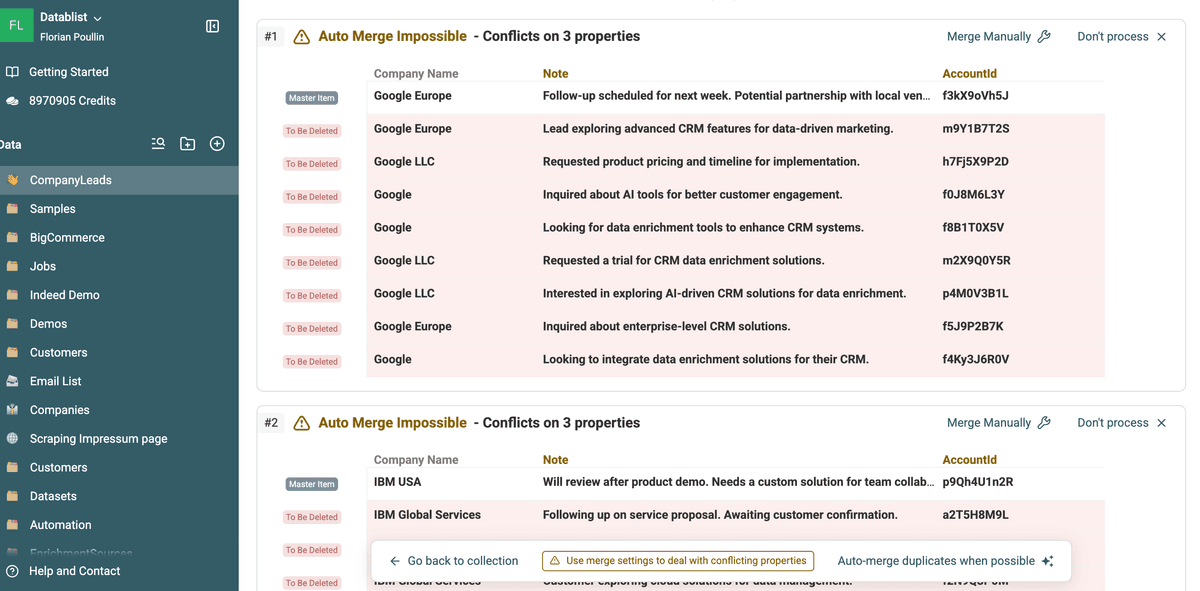
Dieser Schritt ist wichtig, damit Du sicherstellen kannst, dass das Matching korrekt ist und Du nicht aus Versehen legitime Datensätze zusammenfasst.
Note: If you only need to have the list of duplicates, you can download a CSV/Excel file with the duplicate groups. Each duplicate group has an unique identifier. You also have the number of duplicates in your file if you only need statistics.
Teil 3: Duplikate auflösen und zusammenführen
Okay, Du hast die Duplikate gefunden – jetzt geht’s ans Deduplizieren, also ans Zusammenführen.
Dabei entscheidest Du, wie Du mit widersprüchlichen Informationen umgehst, und merge-st die Duplikat-Datensätze zu einem sauberen Eintrag.
Step 1: Understanding Duplicate Groups and Conflicts
Wenn Du Dir eine Duplicate Group anschaust, wirst Du oft sehen, dass einzelne Informationen leicht voneinander abweichen. Das sind „conflicting values“.
Beispiel: Zwei Kontakt-Datensätze haben dieselbe E-Mail-Adresse, aber unterschiedliche Telefonnummern oder Jobtitel.
Step 2: Setting merging rules for Conflicting Values
In Datablist legst Du fest, wie Du mit diesen conflicting values beim Merge umgehen willst. Dafür definierst Du Regeln: welche Werte behalten werden sollen oder wie sie kombiniert werden.
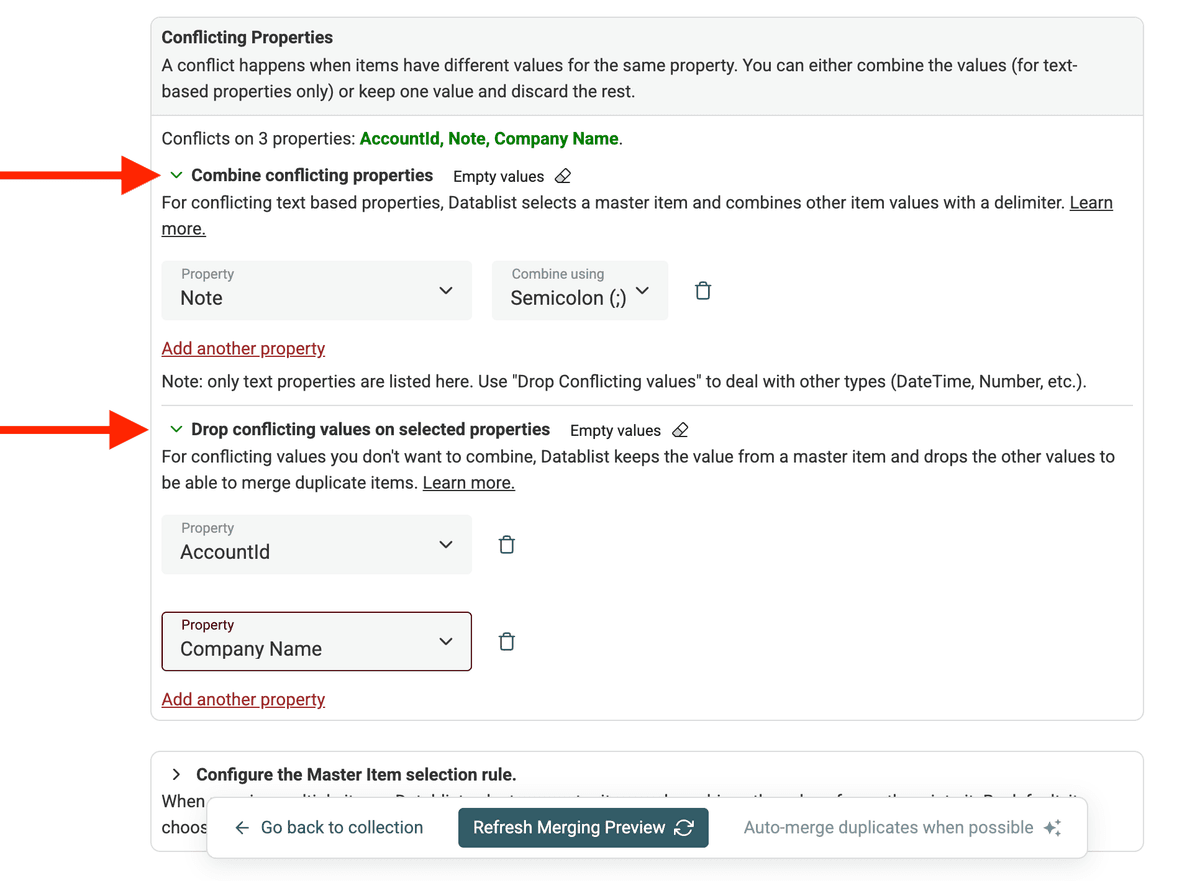
Du hast zwei Optionen, um Konflikte zu lösen:
- Combine Conflicting Values: Wenn sich Werte sinnvoll ergänzen (z. B. mehrere Telefonnummern, Notizen), werden sie zusammengeführt.
- Drop Conflicting Values: Wenn Du nur den Wert aus einem Datensatz behalten und den anderen verwerfen willst, wähl „Drop conflicting values...“.
Für die Einstellungen Combine conflicting values und Drop conflicting values gibt es einen Shortcut-Link, der automatisch alle conflicting properties auswählt.
Beispiel: Mehrere Werte kombinieren
Angenommen, Du hast zwei doppelte Kontakt-Einträge:
Record 1: Email: john.doe@example.com, Phone: 555-1234
Record 2: Email: john.doe@example.com, Phone: 555-5678
Wenn Du für die Property „Phone“ die Regel „Combine values“ setzt, sieht der gemergte Datensatz so aus:
Merged Record: Email: john.doe@example.com, Phone: 555-1234;555-5678
Step 3: Configure the Master Item rule
Beim Merge wählt Datablist einen Datensatz als „Hauptdatensatz“ aus. Die Infos der anderen Duplikate werden dort hinein zusammengeführt.
Du steuerst über Regeln, wie Datablist diesen Master Record auswählt:
- Most Complete: Nimmt den Datensatz mit den meisten ausgefüllten Feldern.
- Last Updated: Nimmt den zuletzt aktualisierten Datensatz.
- First Created: Nimmt den ältesten Datensatz basierend auf dem Erstellungsdatum.
- Highest Value: Nimmt den Datensatz mit dem höchsten Wert in einer ausgewählten Property. Wenn mehrere Datensätze denselben Wert haben, wird der aktuellste gewählt.
- Lowest Value: Nimmt den Datensatz mit dem niedrigsten Wert in einer ausgewählten Property. Wenn mehrere Datensätze denselben Wert haben, wird der aktuellste gewählt.
- Matching Value: Nimmt den Datensatz, der einen bestimmten Wert in einer ausgewählten Property enthält. Falls keiner matcht, werden sie nicht gemergt.
Step 4: Auto-Merge Duplicates (When Possible)
Jedes Mal, wenn Du Deine Merge-Einstellungen änderst, klick auf „Refresh Preview“, um zu sehen, wie die Änderungen angewendet werden.
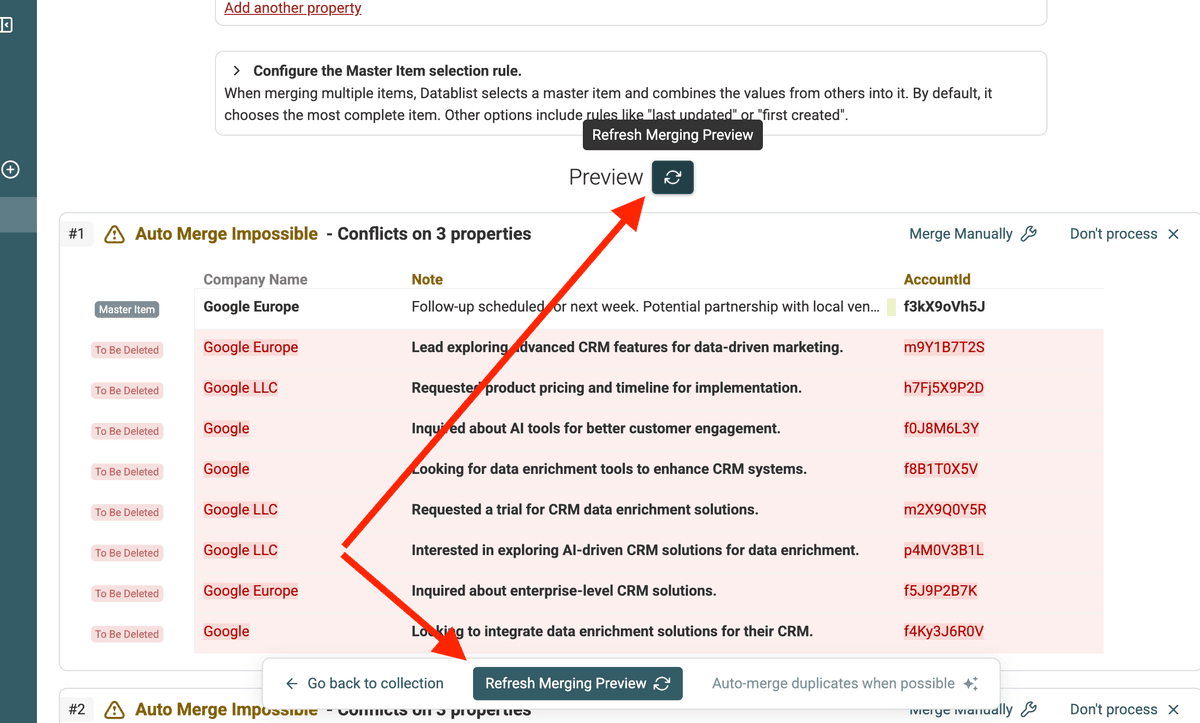
Wenn Deine Merge-Regeln stehen, kann Datablist Duplicate Groups automatisch zusammenführen – sobald es keine conflicting values mehr gibt.

Aktiviere dafür „Auto-merge when possible“.
Step 5: Manually Merge Remaining Duplicates
Bei Duplicate Groups, in denen Du die conflicting values manuell prüfen musst, merge-st Du selbst.
Dafür gibt’s in Datablist einen „Manual Merging Assistant“. Er zeigt Dir die conflicting values nebeneinander, sodass Du gezielt auswählen kannst, was im gemergten Datensatz bleiben soll.
Um den Manual Merging Assistant zu nutzen, klickst Du einfach auf den Button der jeweiligen Duplicate Group.
Dann siehst Du alle Datensätze aus der Gruppe und wählst die Werte aus, die Du behalten willst, bevor Du auf „Merge“ klickst.
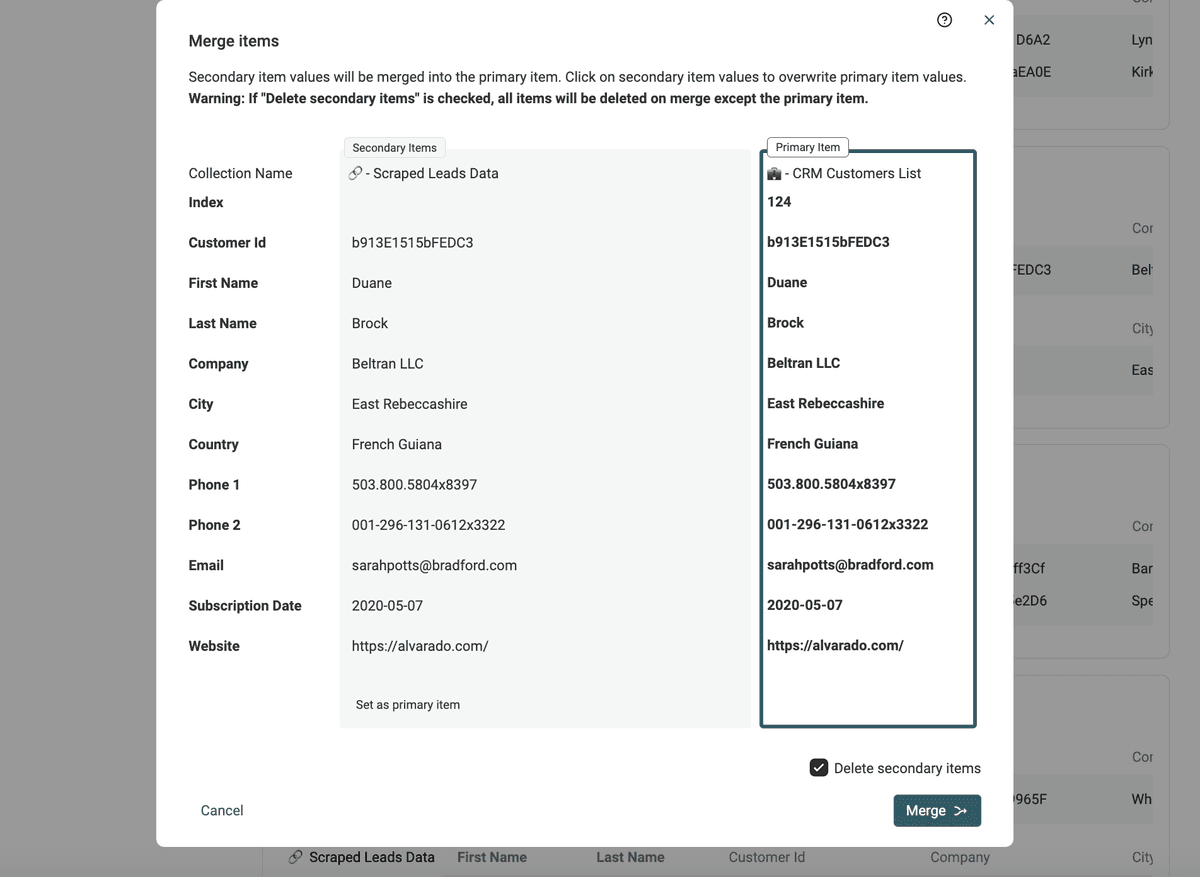
Step 6: All Done! Review and Finalize
Nachdem Du alle Duplicate Groups gemergt hast, schau Dir Deine bereinigte Liste kurz an.
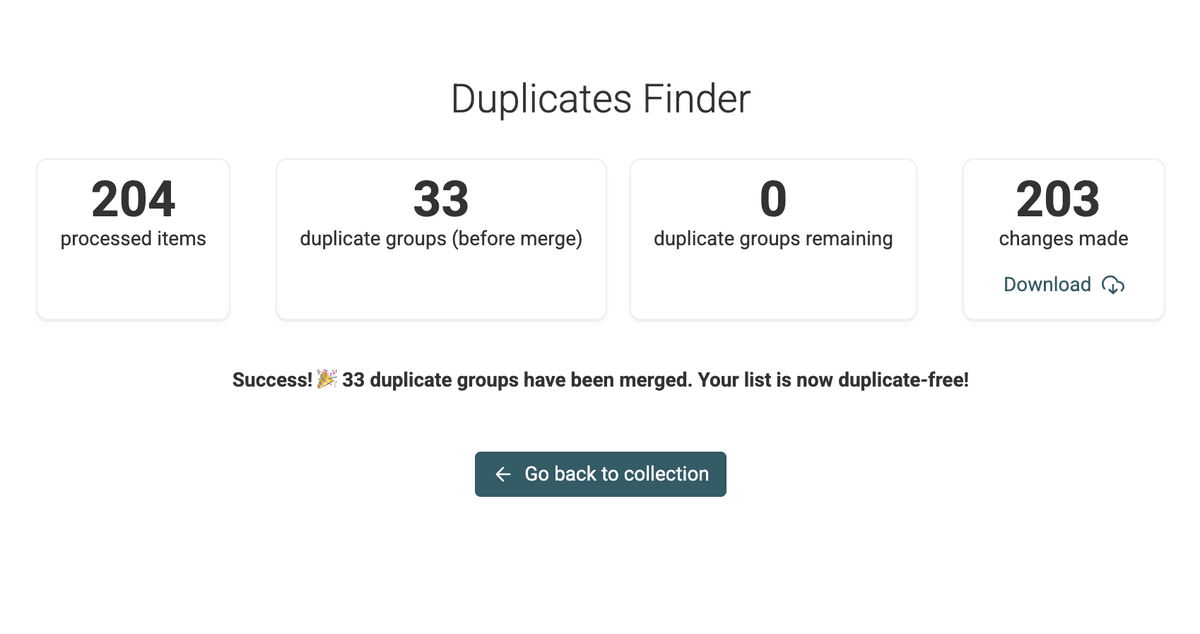
Stell sicher, dass der Deduplication-Prozess so gelaufen ist, wie Du ihn brauchst – und dass Deine Daten jetzt korrekt und frei von Duplikaten sind.
Danach geh zurück in Deine Collection und klick auf „Export“, um die sauberen Daten als CSV- oder Excel-Datei herunterzuladen.
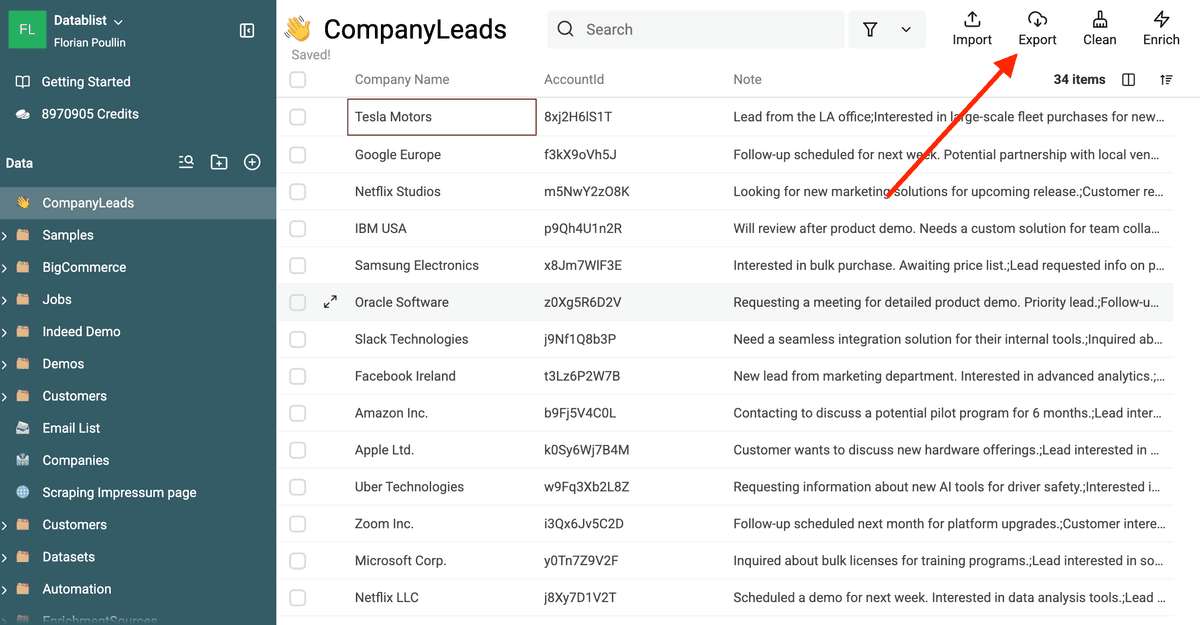
Teste Datablist für kontinuierliche Data Cleaning Workflows.
Häufig gestellte Fragen (FAQ)
Ist Datablist fürs Deduplizieren wirklich kostenlos?
Ja. Du kannst Duplikate online kostenlos entfernen, ganz ohne Signup.
Lade einfach Deine Datei hoch und leg los. Für advanced matching algorithms kannst Du ein kostenloses Konto anlegen.
Kostenpflichtig sind nur Fuzzy Matching und Phonetic Deduplication.
Kommt Datablist mit großen Listen mit tausenden Datensätzen klar?
Ja – absolut. Datablist ist dafür gebaut, große Listen effizient zu verarbeiten.
Egal ob 10.000 oder 500.000+ Datensätze: Der Duplicate Finder scannt und gruppiert Duplikate schnell. Du musst Deine Daten nicht aufteilen – einfach hochladen und bereinigen.
Unterstützt Datablist Fuzzy Matching, um Near-Duplicates zu finden?
Ja. Datablist bietet fuzzy matching algorithms wie Levenshtein und Jaro-Winkler, um Tippfehler und kleine Unterschiede zu erkennen. Zum Beispiel matcht es:
- "Jon Smith" mit "John Smith"
- "Acme Ltd." mit "Acme Inc"
Du bestimmst den Similarity-Level selbst und kannst den Threshold feinjustieren, um die Genauigkeit zu optimieren.
Kann ich CRM-Kontakte, Leads oder Kundendaten deduplizieren?
Ja. Exportiere Deine CRM data (aus HubSpot, Salesforce oder jedem anderen Tool) als CSV file, lade sie in Datablist hoch und entferne Duplikate in wenigen Minuten. Danach kannst Du die erzeugten Change Files nutzen, um Updates wieder in Dein CRM zurückzuspielen – ohne manuelles Copy-Paste.
Wenn Du Pipedrive nutzt, bieten wir eine direkte Integration für Bulk Deduplication.