

Sainsbury's hat keine öffentliche Produkt-API. Genau deshalb landen die meisten Teams, die Sainsbury's Produkte scrapen wollen, entweder bei einem Freelancer für £2000+ oder bei einem Apify-Scraper, der nach ein paar Tagen wieder kaputt ist.
Was viele aber nicht wissen: Es gibt einen dritten Weg – AI scraping. Dabei wird die Seite wie von einem Menschen gelesen. Deshalb funktioniert dasselbe Setup auf einer Sainsbury's-Kategorieseite, einer Brand-Übersicht oder einer Angebotsseite – und übersteht Layout-Änderungen, an denen klassische Scraper scheitern.
In diesem Guide zeige ich dir den kompletten Ablauf: warum sich ein eigener Sainsbury's-Produkt-Scraper finanziell meist nicht lohnt, welche Sainsbury's-Seiten die saubersten Daten liefern und wie du mit dem Datablist AI Scraping Agent Schritt für Schritt ans Ziel kommst.
📌 Kurzfassung für Eilige
Dieser Artikel zeigt dir, wie du Produktdaten von Sainsbury's mit dem Datablist AI Scraping Agent extrahierst.
Problem: Sainsbury's bietet keine öffentliche Produkt-API, Standard-Scraper brechen nach fast jedem Layout-Update innerhalb weniger Wochen, und ein Custom Build kostet £2000+ plus laufende Wartung.
Lösung: Nutze den Datablist AI Scraping Agent, um Sainsbury's Produkte mit einem einfachen Prompt in normalem Englisch und nur einer URL zu scrapen.
Was du lernst:
- Warum ein eigener Sainsbury's-Scraper ein Geldgrab ist
- Welche Sainsbury's-Seiten die saubersten Daten liefern
- Einen 5-Schritte-Prozess, mit dem du jede Sainsbury's-Kategorie in unter 10 Minuten scrapest
Warum Datablist:
- AI scraping versteht Inhalte statt HTML – deshalb brechen Sainsbury's-Layout-Updates den Prozess nicht
- Pagination läuft automatisch (bis zu 5.000 Seiten pro Run)
- Kein Code, keine API-Keys – nur eine Sainsbury's-URL und ein Prompt
Was dieser Guide abdeckt
- Warum sich ein eigener Sainsbury's-Scraper nicht lohnt
- So scrapest du Sainsbury's Produkte mit dem Datablist AI Agent
- Sainsbury's scrapen: die komplette Schritt-für-Schritt-Anleitung
- Häufige Fragen zum Scraping von Sainsbury's
Warum sich ein eigener Sainsbury's-Scraper nicht lohnt
Falls du schon mal darüber nachgedacht hast, einen eigenen Sainsbury's-Scraper zu bauen, gibt es drei gute Gründe, das nochmal zu überdenken, bevor du Geld investierst.
Es ist teuer
Ein stabiler Sainsbury's-Scraper ist kein Wochenendprojekt. sainsburys.co.uk lädt sein Produkt-Grid dynamisch mit JavaScript, verteilt Kategorien über hunderte paginierte Seiten und ändert das Layout oft genug, dass jeder regelbasierte Scraper ständig nachgebessert werden muss.
Das probieren die meisten Teams – und genau hier scheitern die einzelnen Ansätze:
- Einen Freelance-Entwickler beauftragen: £2000+ für den ersten Build, dazu laufende Kosten bei jedem Grid-Update von Sainsbury's
- Einen fertigen Sainsbury's-Produkt-Scraper von Apify oder GitHub kaufen: funktioniert am ersten Tag, bricht aber meist nach wenigen Wochen beim nächsten Layout-Update
- Ein Puppeteer- oder Playwright-Script zusammenbauen: Pagination, JavaScript-Rendering und uneinheitliche Produktkarten bringen das Setup schnell an seine Grenzen
Wenn du nur einmalig eine Datenaufnahme brauchst, kann ein Freelancer okay sein. Wenn du aber regelmäßig frische Sainsbury's-Daten brauchst (z. B. für Preisbeobachtung, FMCG-Analysen oder Retail Arbitrage), steigen die Wartungskosten Monat für Monat weiter an.

Es dauert lange, bis es steht
Selbst mit einem starken Entwickler dauert ein sauberer Sainsbury's-Scraper mehrere Wochen. Es müssen alle Kategorieseiten gemappt, das gerenderte HTML verarbeitet, Logik für paginierte Grids gebaut und Sonderfälle berücksichtigt werden – etwa wenn Sainsbury's bei Angebotspreisen „N/A“ zurückgibt oder Produkte hinter Altersabfragen versteckt.
Der Datablist AI Scraping Agent überspringt diese komplette Build-Phase. Du fügst einfach eine Sainsbury's-URL ein und ziehst dir in unter 10 Minuten strukturierte Produktdaten. Keine Spezifikationsdokumente, kein Hin und Her bei Edge Cases, kein Warten auf Version 2.

Es geht ständig kaputt
Das ist der eigentliche Kostenfaktor: Sainsbury's aktualisiert sein Produkt-Grid regelmäßig. Jedes Mal, wenn das Team ein neues Kategorie-Template ausrollt oder das Preiselement verschiebt, funktioniert dein eigener Sainsbury's-Scraper nicht mehr.
Dann bleiben dir nur zwei Optionen: den Entwickler nochmal bezahlen oder selbst einen Nachmittag lang debuggen.
AI scraping umgeht genau dieses Problem. Weil der AI Agent die Bedeutung einer Seite statt ihrer HTML-Struktur liest, bleibt ein Preis ein Preis – auch wenn Sainsbury's die CSS-Klasse darum herum ändert.
💡 Der entscheidende Unterschied
Klassische Scraper folgen Regeln: „Finde das Element mit der Klasse .product-price und extrahiere den Text.“ AI Scraper folgen der Bedeutung: „Finde den Produktpreis auf dieser Sainsbury's-Seite.“
Deshalb funktioniert dasselbe Setup, das heute auf Sainsbury's läuft, auch noch nach der nächsten Umstrukturierung des Grids – und lässt sich genauso auf Tesco, Morrisons und Asda übertragen, ohne pro Website eigenen Code zu schreiben.
So scrapest du Sainsbury's Produkte mit dem Datablist AI Agent
Bevor wir zur Schritt-für-Schritt-Anleitung kommen, kurz das Wichtigste: was der AI Scraping Agent überhaupt ist, welche Sainsbury's-Seiten saubere Ergebnisse liefern, welche Daten du extrahieren kannst und wo die Grenzen liegen.
Was ist der Datablist AI Scraping Agent?
Datablist ist eine Plattform für Workflow-Automation, mit der du Lead-Listen aufbauen, Daten anreichern und Scraping-Workflows ausführen kannst. In Datablist gibt es über 60 verschiedene Sources und Enrichments, und der AI Scraping Agent ist die passende Option, wenn du Produktdaten von einer Retail-Website extrahieren willst.
Der Agent kombiniert dafür drei Dinge: eine Ziel-URL, einen Prompt mit der Beschreibung der gewünschten Daten und ein Sprachmodell, das die Seite so liest, wie du es selbst tun würdest.
Für Sainsbury's musst du den Prompt nicht einmal selbst schreiben. Datablist bringt ein Retail Product Scraper Template mit, das Prompt und Output-Spalten bereits vorgeladen hat. Du fügst einfach eine Sainsbury's-URL ein, den Rest übernimmt das Template.
Drei Punkte sind für Sainsbury's besonders wichtig:
- OpenAI GPT 4.1 mini als Standard – das beste Preis-Leistungs-Verhältnis unter den LLMs für AI scraping
- Render HTML als Option, zwingend nötig für Sainsbury's, weil das Produkt-Grid per JavaScript geladen wird
- Automatische Pagination über bis zu 5.000 Seiten pro Run
Genau deshalb lässt sich das Setup auch ohne Änderungen auf andere britische Supermärkte übertragen. Derselbe Agent, dasselbe Template und dieselben Einstellungen funktionieren auch bei Tesco, Morrisons, Asda, Waitrose und Aldi. Nur die URL ändert sich.
Die wichtigste Regel: Nur Brand- und Kategorieseiten
Scrape immer Sainsbury's Kategorie- oder Brand-Seiten, niemals die Startseite oder eine „All Products“-Ansicht. Sehr große Listen sprengen das Context Window des AI Agent, der Run bricht mittendrin ab und deine Credits sind verschwendet.
Diese Seitentypen verarbeitet der AI Agent bei Sainsbury's sauber:
- ✅ Kategorieseiten auf sainsburys.co.uk/gol-ui/groceries/...
- ✅ Brand-Seiten (Listings eines bestimmten Herstellers)
- ✅ Angebots- oder Deals-Seiten
Das solltest du vermeiden:
- ❌ Die Sainsbury's-Startseite
- ❌ „All products“ oder Suchergebnisse über die ganze Website
- ❌ Alles, was tausende Produkte in einem einzigen Infinite Scroll lädt
Welche Daten du von Sainsbury's extrahieren kannst
Ein einzelner Sainsbury's-Run kann alle Produktdatenpunkte extrahieren, die du für Preisbeobachtung, Wettbewerbsanalysen oder data enrichment in einem bestehenden Katalog brauchst:
- Product Name: kompletter Produkttitel, wie er auf der Sainsbury's-Website angezeigt wird
- Product URL: direkter Link zur Produktseite auf sainsburys.co.uk
- Brand Name: der Hersteller des Produkts
- Price: aktueller Preis in GBP inklusive £-Symbol
- Sale Price: rabattierter Preis, wenn gerade eine Sainsbury's-Aktion aktiv ist, sonst „N/A“
- Product Category: Regal, Kategorie oder Abteilung, in der das Produkt einsortiert ist
- Availability: verfügbar, nicht verfügbar oder limitiert
- Rating: Kundenbewertung, sofern Sainsbury's sie anzeigt
- Image URL: direkter Link zum Hauptbild des Produkts
- SKU: die interne Sainsbury's-Produkt-ID
Wähle vor dem Run nur die Outputs aus, die du wirklich brauchst, damit dein Export nur die Spalten enthält, mit denen du später auch arbeitest.
Sainsbury's scrapen: die komplette Schritt-für-Schritt-Anleitung
Das komplette Setup für Sainsbury's besteht aus 5 Schritten. Bevor du startest, solltest du Folgendes parat haben:
- Eine Sainsbury's-Kategorie- oder Brand-URL (nicht die Startseite)
- Eine grobe Vorstellung davon, welche Produktfelder du wirklich brauchst
Schritt 1: Registrieren und eine Collection anlegen
Registriere dich zuerst auf Datablist.com.

Erstelle dann eine New Collection.

Schritt 2: Zum AI Scraping Agent navigieren
- Klicke auf See all sources

- Scrolle nach unten und wähle AI Scraping Agent (Site Scraper) aus.

Jetzt solltest du das Interface für die Source-Konfiguration sehen. Es sieht so aus:

Schritt 3: Das Retail Product Scraper Template auswählen und eine Sainsbury's-URL einfügen
- Klicke auf das Template Drop-Down und wähle „Retail Product Scraper“

- Füge deine Sainsbury's-Kategorie-URL in das URL-Feld ein, z. B.
https://www.sainsburys.co.uk/gol-ui/groceries/frozen/fish-and-seafood/c:1019924/opt/page:2

❗️ Nur Brand- und Kategorieseiten (zur Erinnerung)
Füge niemals die Sainsbury's-Startseite oder eine „All Products“-URL ein. Große Listen sprengen das Context Window des AI Agent. Scrape Sainsbury's immer Kategorie für Kategorie.
- Stelle die Anzahl der zu scrapenden Seiten ein (Sainsbury's zeigt typischerweise rund 60 Produkte pro Seite an, daher braucht eine Kategorie mit 200 Produkten ungefähr 3 bis 4 Seiten)
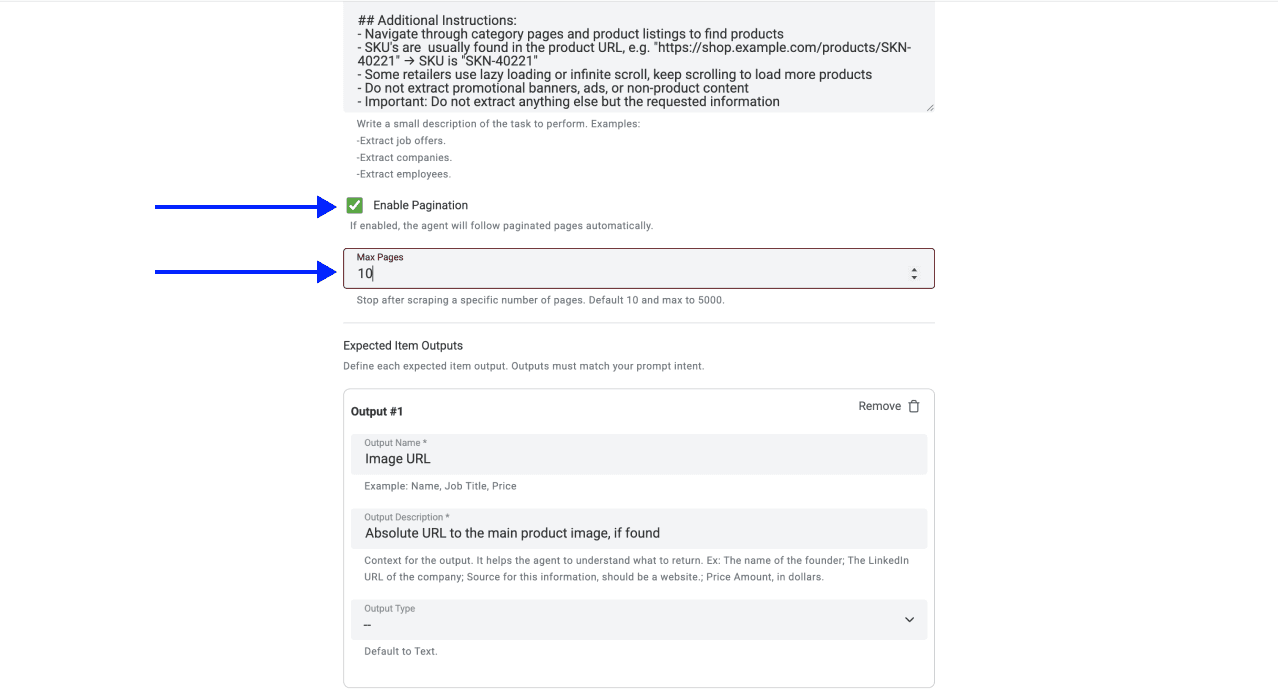
- Scrolle nach unten und klicke auf Continue

💡 Prüfe deine Advanced Settings, bevor du auf Continue klickst
Achte darauf, dass diese Optionen aktiv sind:
- LLM: OpenAI GPT 4.1 mini (bestes Performance-Preis-Verhältnis)
- Max Iterations: 10
- Website Scraper Option: Render HTML (entscheidend für Sainsbury's, weil die Website ihr Produkt-Grid dynamisch per JavaScript lädt)
Schritt 4: Outputs konfigurieren
Datablist erstellt die Output-Properties automatisch.
Klicke auf die X-Icons, um Outputs zu entfernen, die du nicht brauchst (zum Beispiel Rating, wenn du nur Sainsbury's-Preise monitoren willst).

Schritt 5: Run starten
Sobald deine Outputs festgelegt sind, klicke auf Run Import Now, um den Sainsbury's-Scrape zu starten.

Nach ein paar Minuten sehen deine Sainsbury's-Ergebnisse ungefähr so aus. Von hier aus kannst du mit den Workflow-Automation-Features von Datablist die Daten bereinigen, deduplizieren und exportieren.

💡 So vermeidest du Duplikate bei wiederholten Sainsbury's-Runs
Wenn du dieselbe Sainsbury's-Kategorie später nochmal scrapen willst:
- Wähle eine eindeutige Identifier-Spalte (am besten Product URL)
- Klicke auf den Spaltenkopf → Rename - Settings - Delete
- Aktiviere: Do not allow duplicate values
- Save Property
Wenn du zusätzlich Daten von Tesco, Morrisons und Asda in dieselbe Datei ziehst, zeigt dir unser Guide zum Entfernen von Duplikaten aus CSV-Dateien, wie Cross-Retailer-Dedupe funktioniert.
Der Datablist AI Agent scrapet auch andere Retail-Websites
Das Sainsbury's-Setup ist nicht speziell nur für Sainsbury's gedacht. Derselbe AI Scraping Agent und dasselbe Retail Product Scraper Template funktionieren bei jedem britischen Supermarkt, den wir getestet haben. Nur die URL ändert sich.
Wenn du auch Produktdaten von ähnlichen Retailern extrahierst, schau dir diese Schritt-für-Schritt-Guides an:
Das Wichtigste auf einen Blick
- Ein eigener Sainsbury's-Produkt-Scraper ist ein Geldgrab. Die Entwicklung kostet schnell £2000+, laufende Wartung kommt noch dazu, und Layout-Updates von Sainsbury's sorgen regelmäßig für Ausfälle.
- AI scraping versteht Bedeutung statt HTML. Deshalb funktioniert dasselbe Setup auch dann weiter, wenn sich das Grid ändert – und lässt sich ohne Extra-Code auf Tesco, Morrisons und Asda übertragen.
- Scrape immer Brand- oder Kategorieseiten, nie die Startseite. Große Listen sprengen das Context Window des Agent und verschwenden deinen Run.
- Das komplette Setup dauert weniger als 5 Minuten. Template auswählen, URL einfügen, Outputs festlegen, Run starten.
Häufige Fragen zum Scraping von Sainsbury's
Was kostet es, Sainsbury's Produkte zu scrapen?
Der Datablist AI Agent arbeitet mit einem nutzungsbasierten Credit-System. Die Kosten pro Sainsbury's-Run hängen davon ab, wie viele Produkte und Seiten der Agent verarbeitet. Die Datablist-Pläne starten bei 25 $/Monat inklusive 5.000 kostenloser Credits, und Top-up-Pakete starten bei 20 $ für 20.000 Credits – mit Mengenrabatten von bis zu 35 % bei größeren Paketen.
Wie lange dauert es, den kompletten Sainsbury's-Katalog zu scrapen?
Die meisten Sainsbury's-Kategorieseiten mit 50 bis 200 Produkten sind in 5 bis 10 Minuten gescraped. Größere Runs über mehrere paginierte Kategorien hinweg (500+ Produkte) dauern eher 10 bis 20 Minuten. Für das erste Setup kommen nochmal 2 bis 3 Minuten dazu.
Warum sollte ich eine Sainsbury's-Kategorieseite statt „All Products“ scrapen?
Eine Sainsbury's-„All Products“-Ansicht lädt tausende Artikel in eine einzige gerenderte Seite. Das sprengt das Context Window des AI Agent, der Agent stoppt mitten im Run und es gibt keine Resume-Option – der teilweise Run ist also verloren. Kategorie- und Brand-Seiten bleiben in einem sicheren Bereich, lassen sich sauber scrapen und bei Bedarf später in einer Collection zusammenführen.
Kann ich Sainsbury's-Angebotspreise und Promotions scrapen?
Ja. Das Retail Product Scraper Template enthält einen Sale Price-Output. Wenn bei Sainsbury's gerade eine Promotion läuft, wird der rabattierte Preis übernommen. Wenn kein Angebot aktiv ist, gibt die Spalte „N/A“ zurück – was für Filter nach Promotionsstatus über mehrere Kategorien hinweg sogar praktisch ist.
Ist das Scraping von Sainsbury's in Großbritannien legal?
Das Scraping öffentlich sichtbarer Sainsbury's-Produktdaten (Namen, Preise, Verfügbarkeit) ist in Großbritannien grundsätzlich unter ähnlichen Prinzipien zulässig wie andere öffentlich zugängliche Webdaten. Trotzdem solltest du die Nutzungsbedingungen von Sainsbury's prüfen, keine personenbezogenen Daten scrapen und in einem angemessenen Request-Volumen bleiben. Für kommerzielle Nutzung solltest du das zusätzlich mit deinem Legal-Team abstimmen.
Blockiert Sainsbury's Scraper?
Die Anti-Bot-Maßnahmen von Sainsbury's sind relativ moderat im Vergleich zu Walmart oder Costco. Die meisten Sainsbury's-Runs in Datablist funktionieren direkt beim ersten Versuch, vor allem wenn Render HTML aktiviert ist. Wenn eine Kategorieseite keine Daten zurückgibt, reduziere die Seitenzahl und versuche es erneut – oder teile den Scrape in spezifischere Unterkategorien auf.
Kann ich wiederkehrende Scrapes für Sainsbury's-Preisbeobachtung planen?
Ja. Mit den Workflow-Automation-Features von Datablist kannst du wiederkehrende Runs einrichten. Kombiniere das mit einer eindeutigen Identifier-Spalte (Product URL funktioniert am besten) und der Einstellung zur Duplikatvermeidung, damit jeder wiederholte Sainsbury's-Run nur neue Produkte ergänzt, statt bestehende zu duplizieren.
Kann ich Sainsbury's ohne Coding-Kenntnisse scrapen?
Ja, du brauchst keinerlei Coding-Skills. Der gesamte Ablauf ist no-code: Retail Product Scraper Template auswählen, Sainsbury's-URL einfügen, Outputs festlegen und den Run starten. Wenn du einen Satz schreiben kannst, kannst du mit Datablist auch Sainsbury's scrapen.
Welche Sainsbury's-Kategorien eignen sich am besten zum Scrapen?
Standard-Lebensmittelkategorien unter https://www.sainsburys.co.uk/gol-ui/groceries](https://www.sainsburys.co.uk/gol-ui/groceries liefern die saubersten Daten: Frischeprodukte, Tiefkühlkost, Backwaren, Getränke, Haushalt. Brand-Seiten funktionieren ebenfalls sehr gut. Promo- oder „Last chance“-Seiten können etwas unruhiger sein, weil Produktkarten unterschiedliche Formate mischen, aber der AI Agent zieht trotzdem brauchbare Daten daraus.
Kann der AI Agent die Pagination bei Sainsbury's automatisch verarbeiten?
Ja. Mit aktivierter Option Enable Pagination arbeitet sich der AI Agent durch jede Seite einer Sainsbury's-Kategorie bis zu deinem konfigurierten Limit (Standard 10, Maximum 5.000). Für eine Sainsbury's-Kategorie mit 240 Produkten und 24 Artikeln pro Seite stellst du Pagination auf 10 – und der Agent nimmt die komplette Liste mit.
Was ist AI scraping?
AI scraping ist eine Methode, strukturierte Daten mit Hilfe eines Sprachmodells aus Websites zu extrahieren, statt mit festen HTML-Regeln zu arbeiten. Der Agent besucht eine Seite, liest den Inhalt und gibt die Felder zurück, die du in normalem Englisch angefordert hast. Genau das macht den Ansatz so robust auf Websites wie Sainsbury's, die ihr Layout regelmäßig ändern.
Was ist der Unterschied zwischen AI scraping und klassischem Web Scraping?
Klassische Scraper folgen festen Regeln (CSS-Selektoren, XPath). Wenn sich die Website ändert, brechen diese Regeln. AI scraping liest die Bedeutung einer Seite – deshalb bleibt ein Sainsbury's-Preis auch nach geändertem Markup weiterhin ein Sainsbury's-Preis. Genau deswegen funktioniert dasselbe Datablist-Setup auf Tesco, Sainsbury's, Morrisons und Asda, ohne pro Website eigenen Code zu brauchen.