
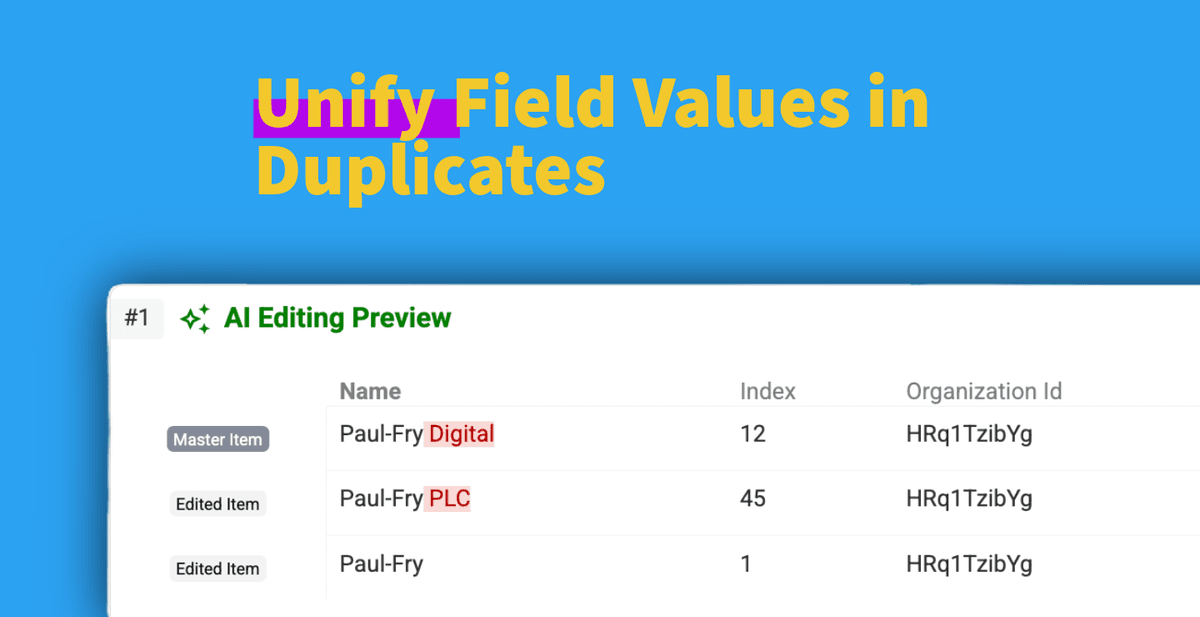
Doppelte Datensätze in einem Dataset sind ein echter Klassiker – und meistens nervig. Duplicates zu finden ist der erste Schritt. Sie wirklich sauber zu bereinigen, ist dann oft die nächste Baustelle.
Manchmal willst Du Duplikate aber (noch) nicht komplett zusammenführen.
Vielleicht taucht dieselbe Firma in mehreren doppelten Einträgen mit leicht unterschiedlichen Namen auf ("Innovate Corp", "Innovate Corporation", "Innovate Corp.").
Was wäre, wenn Du ein bestimmtes Feld – z. B. Firmenname oder Jobtitel – innerhalb jeder Duplicate-Gruppe vereinheitlichen könntest, ohne die Datensätze selbst zu mergen?
In dieser Anleitung lernst Du, wie Du bestimmte Feldwerte über Duplicate-Gruppen hinweg normalisierst, während die einzelnen Records erhalten bleiben:
- Was ist Daten-Normalisierung?
- AI Processing im Duplicates Finder: So funktioniert’s
- Duplikate normalisieren: Schritt-für-Schritt-Anleitung
Was ist Daten-Normalisierung?
Daten-Normalisierung bedeutet in diesem Kontext: Daten in ein einheitliches, konsistentes Format bringen. Gerade bei Duplikaten entstehen Inkonsistenzen oft nur in einzelnen Feldern. Zum Beispiel:
- Firmennamen: "Tech Solutions Inc.", "Tech Solutions, LLC", "Tech Solutions"
- Jobtitel: "Software Engineer", "Software Dev.", "Eng., Software"
- Adressen: "123 Main St", "123 Main Street", "123 main st"
- Länder: "USA", "United States", "U.S.A."
Ziel der Normalisierung ist es, einen Standardwert (z. B. "Tech Solutions" oder "United States") festzulegen und ihn im entsprechenden Feld über alle als Duplikate erkannten Datensätze hinweg zu setzen.
Damit werden Deine Daten sauberer, leichter auszuwerten und zuverlässiger beim Filtern oder Reporting – selbst wenn die Duplicate-Records weiterhin getrennt bleiben. Das ist ein wichtiger Baustein für data cleaning.
AI Processing im Duplicates Finder: So funktioniert’s
Der Duplicates Finder von Datablist ist ohnehin schon ein starkes Tool, um ähnliche Datensätze zu identifizieren. Zusätzlich zu Optionen für automatisches oder manuelles Mergen von Duplikaten bringt der Modus AI Processing nochmal deutlich mehr Flexibilität.
Statt festen Merge-Regeln definierst Du die Logik per Prompt in natürlicher Sprache. Du sagst der AI konkret, was sie mit den Duplikaten machen soll. Dazu gehören z. B.:
- Einen Master Record nach klaren Kriterien auswählen (z. B. der zuletzt aktualisierte).
- Bestimmte Felder mergen, andere aber getrennt lassen.
- Berechnungen während des Merge durchführen (z. B. Werte aufsummieren).
- 👉 Und – besonders wichtig für diese Anleitung: Ein bestimmtes Feld in allen Duplikaten auf einen einzigen normalisierten Wert setzen, ohne die Datensätze zu mergen.
So wird aus einer komplexen Daten-Manipulation per Skript im Prinzip ein einfaches Gespräch mit unserer AI.
Duplikate normalisieren: Schritt-für-Schritt-Anleitung
Schauen wir uns an, wie Du mit AI Processing ein Feld (z. B. Company Name) über Duplicate-Records hinweg normalisierst.
Step 1: Prepare Your Data
Zuerst brauchst Du Deine Daten in Datablist.
- Create a Collection: Klicke in der Sidebar auf den „+“-Button, um eine neue Collection zu erstellen.
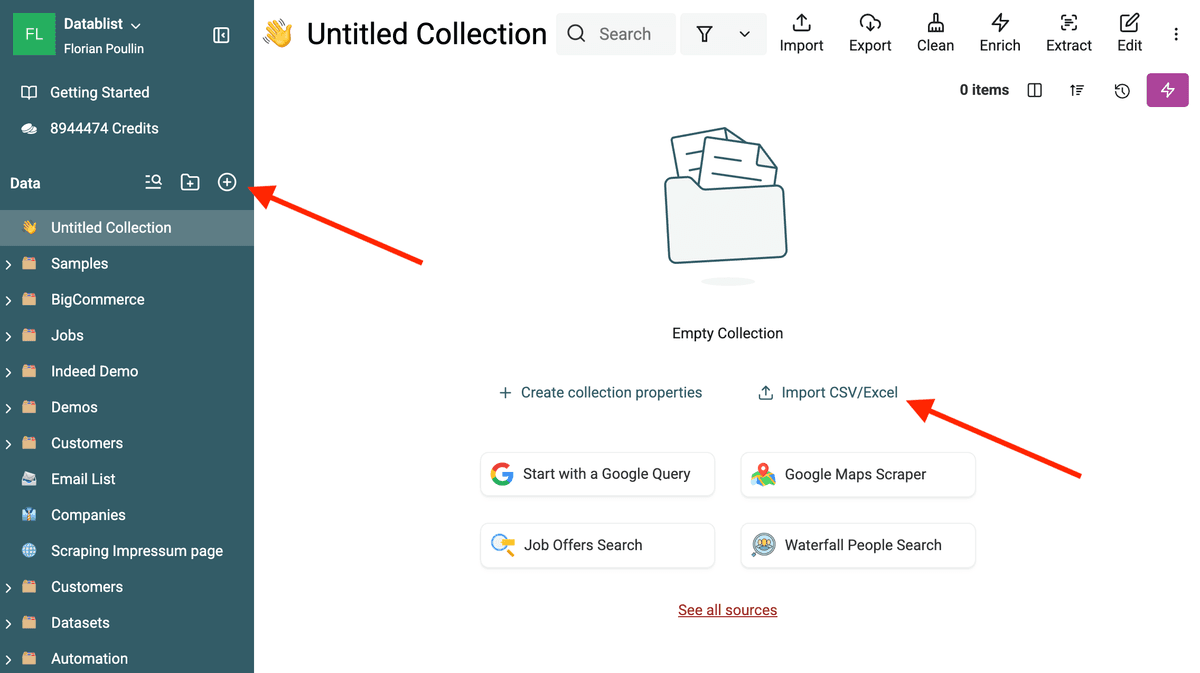
- Import Data: Importiere Deine Daten aus einer CSV- oder Excel-Datei. Wenn Deine Daten aus mehreren Dateien stammen, importiere alles in dieselbe Collection. Datablist führt Dich durch das Mapping der Spalten auf Properties. Achte darauf, dass das Feld, das Du normalisieren willst (z. B. Company Name), und die Felder, mit denen Du Duplikate identifizierst (z. B. Email, Website), korrekt importiert werden.

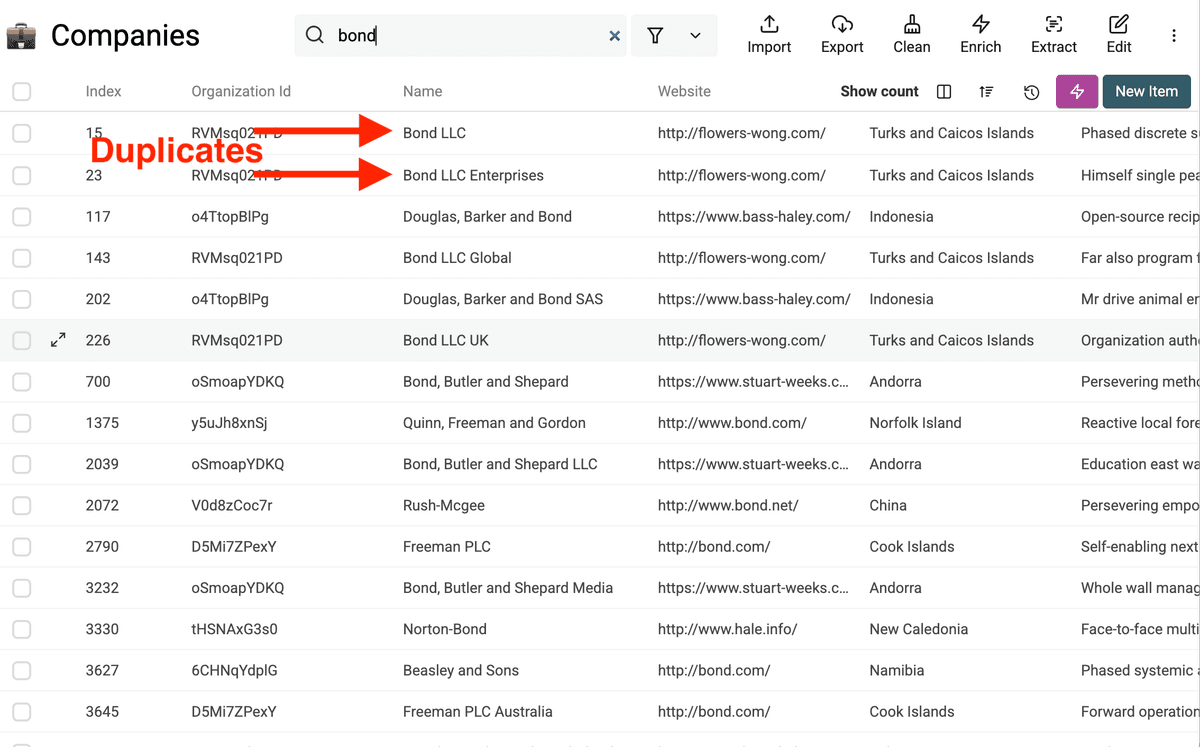
In diesen Beispieldaten sehen wir schon ein paar doppelte Firmennamen, die vereinheitlicht werden sollten.
Step 2: Find Duplicates
Als Nächstes identifizierst Du die Duplicate-Records.
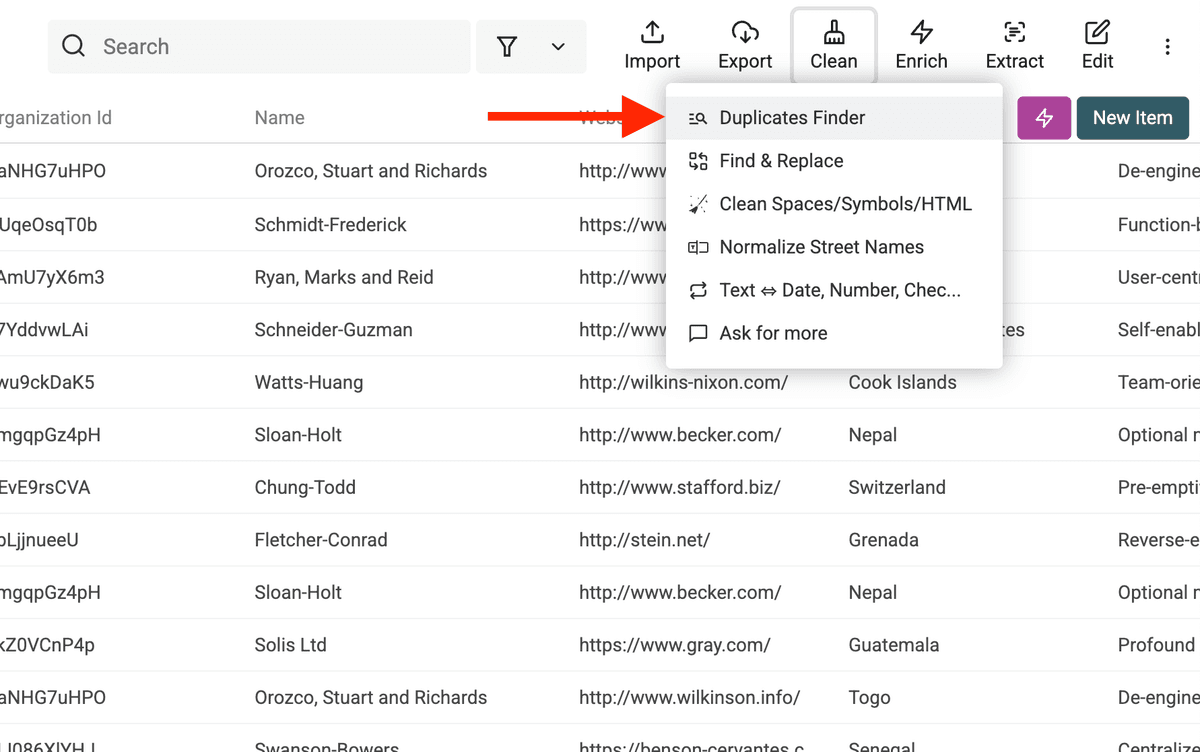
2.a. Open Duplicates Finder
Klicke im Header-Menü auf „Clean“ und wähle dann „Duplicates Finder“.
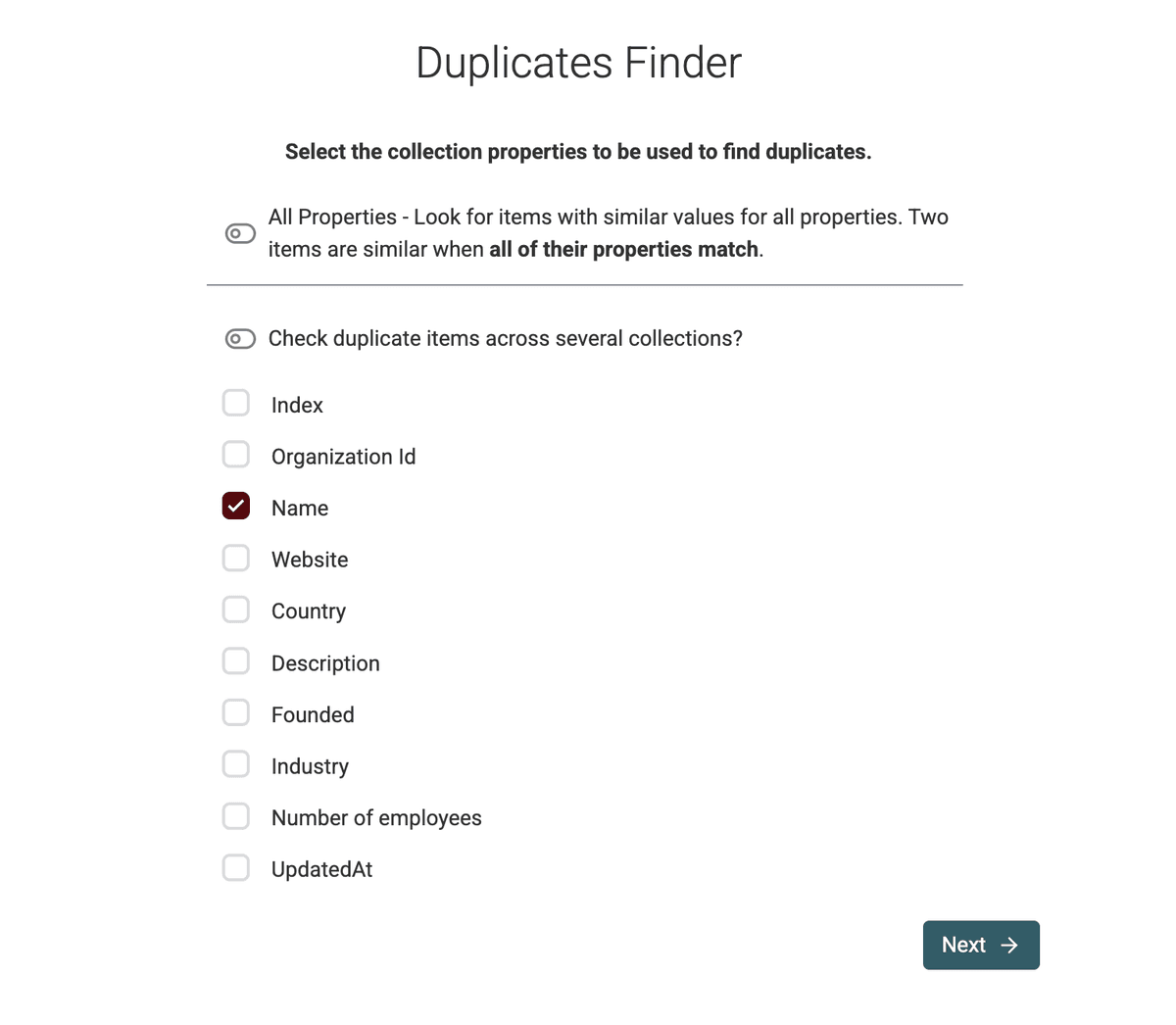
2.b Choose Deduplication Identifier(s)
Wähle das Property (oder mehrere), das ein Duplikat eindeutig identifiziert.
In unserem Beispiel wollen wir Firmennamen dedupen. Also wählen wir das Namensfeld aus.
Für Companies kannst Du alternativ auch
Website URLoderLinkedIn Company Page URLnutzen.Für Kontakte sind
Phone Numbertypische Identifikatoren.
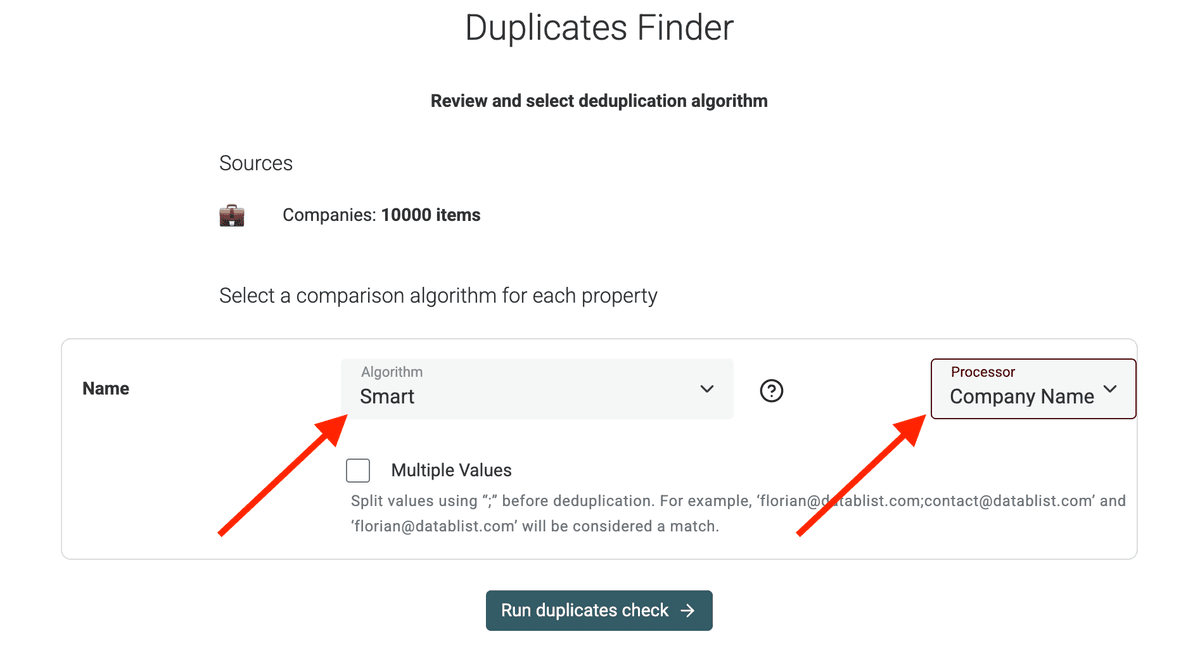
2.c Configure Algorithm
Im nächsten Schritt wählst Du den Matching-Algorithmus.
„Smart“ funktioniert oft gut für URLs oder Emails und kann kleine Abweichungen abfedern. „Exact“ ist strenger. Für Namen kannst Du außerdem phonetic oder fuzzy matching verwenden.
Wähle außerdem den Processor, der zu Deinen Daten passt.
Hier wähle ich den Company Name Processor, um typische Varianten in Firmennamen (Rechtsformen, geografische Begriffe usw.) besser zu behandeln.
2.c Run Check
Klicke auf „Run duplicates check“.
Datablist analysiert Deine Daten und zeigt Dir anschließend Gruppen potenzieller Duplikate an.
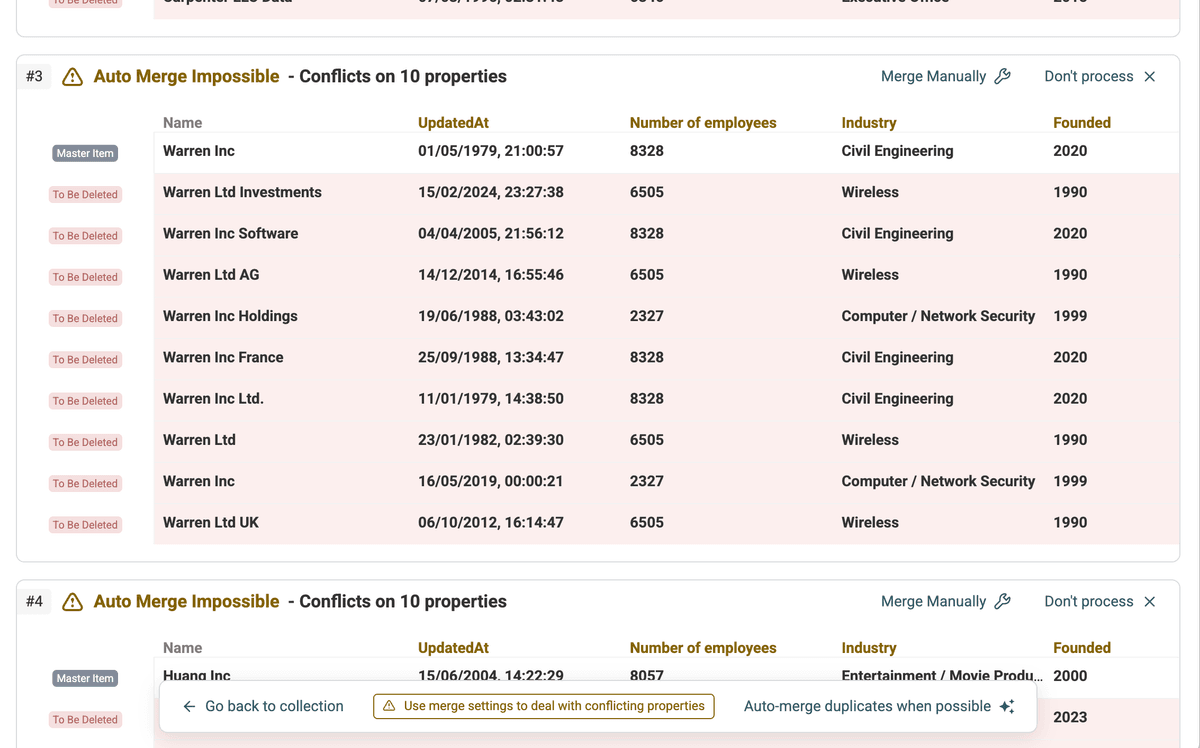
Step 3: Select AI Processing Mode
Statt die Standard-Optionen „Auto Merge“ oder manuelles Mergen zu verwenden, klickst Du auf der Ergebnisseite der Duplikate auf den Button AI Editing. Damit aktivierst Du den AI-basierten Processing-Modus.
Step 4: Write the Normalization Prompt
Jetzt sagst Du der AI, was sie tun soll. Der Prompt sollte klar machen, dass sie:
- Den häufigsten Wert für das Ziel-Property innerhalb jeder Duplicate-Gruppe identifiziert.
- Alle Records in dieser Gruppe so aktualisiert, dass sie genau diesen Wert für das Feld bekommen.
- Explizit keine Records löschen soll.
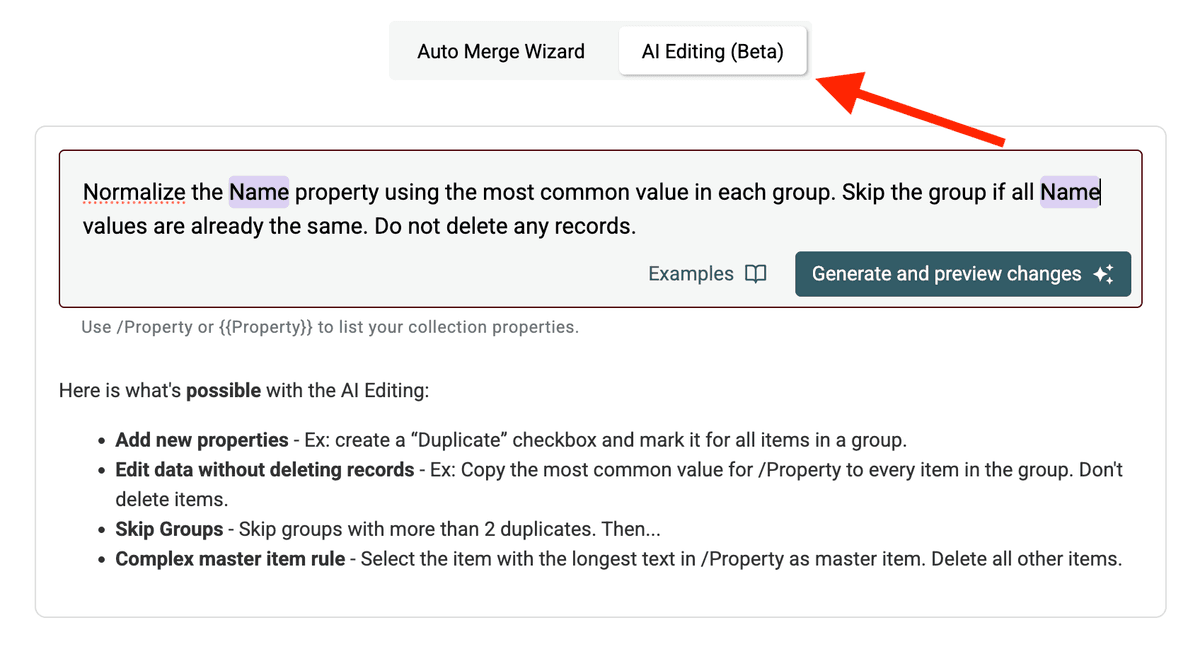
Hier ist ein Beispiel-Prompt, um das Property /Company Name zu normalisieren:
Prompt kurz erklärt:
Normalize the /CompanyName property...: Legt das Zielfeld fest. Nutze/PropertyNameoder{{PropertyName}}, um auf Deine Spalten zu referenzieren....using the most common value in each group.: Definiert die Logik für den Standardwert. Du könntest stattdessen auch Kriterien wie „longest value“, „shortest value“ verwenden oder ein anderes Feld als Referenz nutzen (z. B. „use the value from the record with the latest /UpdatedAt date“).Skip the group if all /CompanyName values are already the same.: Spart Zeit, weil identische Gruppen übersprungen werden.Do not delete any records.: Entscheidend, damit wirklich nur Felder aktualisiert werden – und nichts gemerged oder entfernt wird.
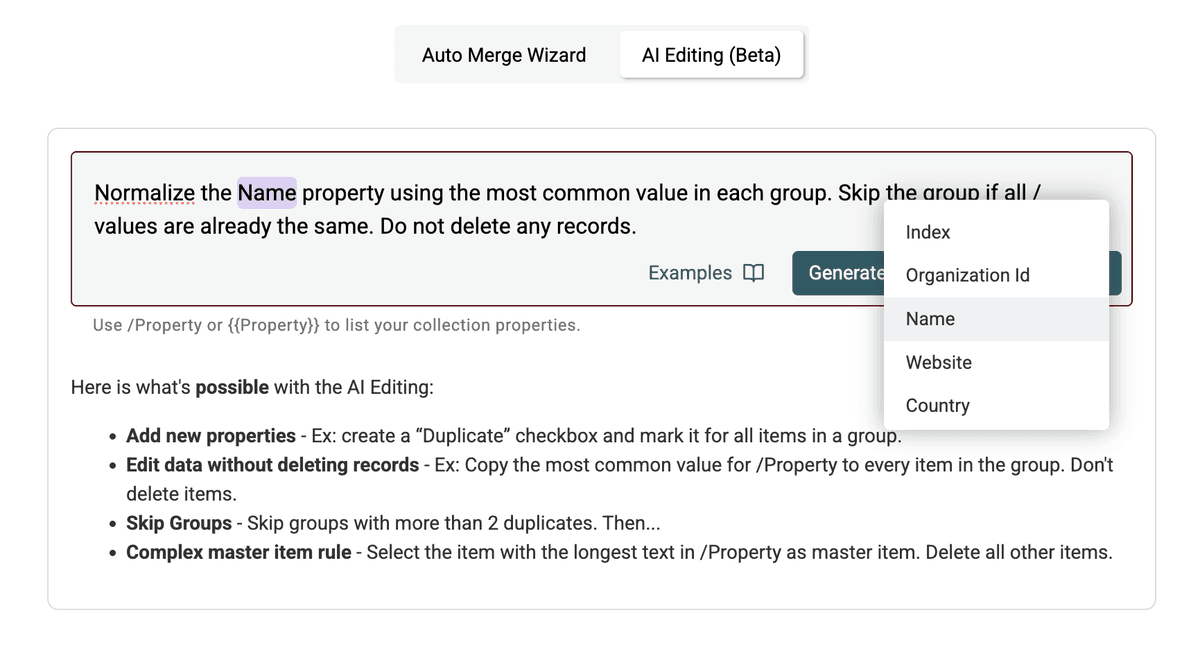
Step 5: Generate & Preview the Script
Klicke auf Generate and preview changes. Die Datablist-AI interpretiert Deinen Prompt und generiert ein Skript, das die Aktion ausführt.
Keine Sorge: Du musst kein Skript schreiben oder bearbeiten.
- Script Explanation: Eine Klartext-Zusammenfassung, was das Skript tun wird. Prüfe, ob das zu Deinem Ziel passt.
- Result Preview: Eine Tabelle, die exakt zeigt, wie das Skript ein Sample Deiner Duplicate-Gruppen verändern würde, bevor wirklich etwas angewendet wird. Checke im Preview-Feld (z. B.
/Company Name), ob überall der gewünschte normalisierte Wert gesetzt wird.
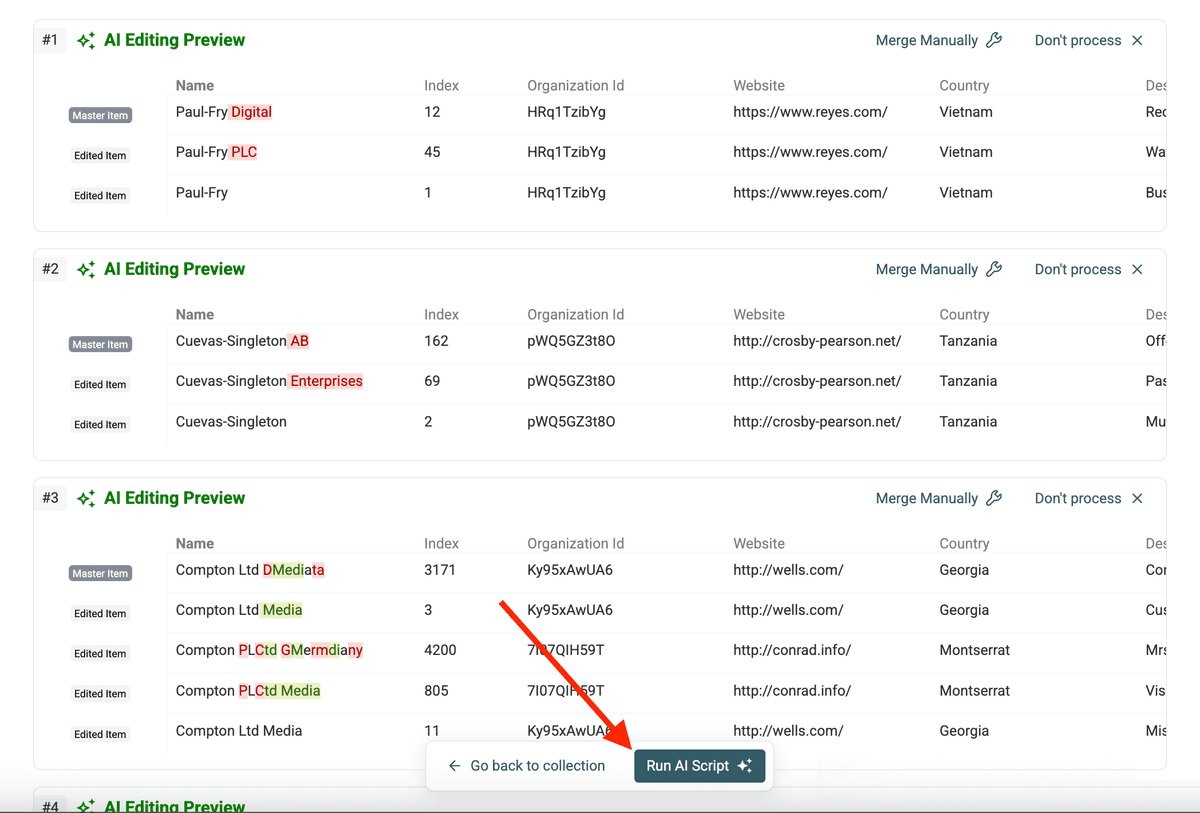
Step 6: Run the Script
Wenn Explanation und Preview passen, klicke auf Run AI Script. Datablist führt das generierte Skript dann über alle erkannten Duplicate-Gruppen aus.
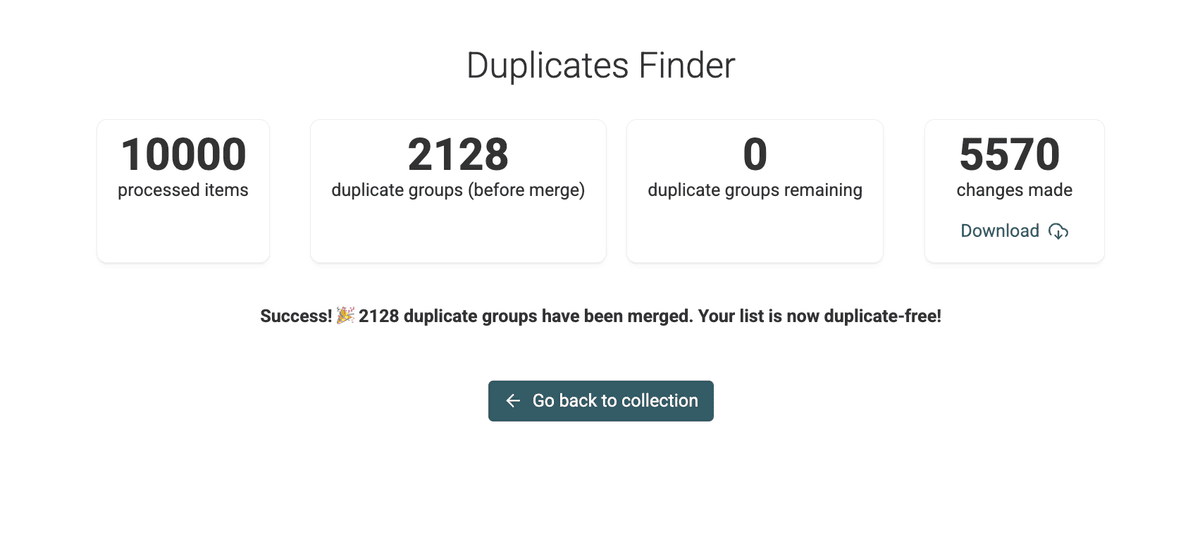
Step 7: Review Changes
Sobald das Skript fertig ist, bekommst Du eine Zusammenfassung und eine herunterladbare Changes List.
Das ist praktisch, wenn Du Änderungen in einem externen System nachziehen willst (z. B. um CRM leads zu bearbeiten etc.).
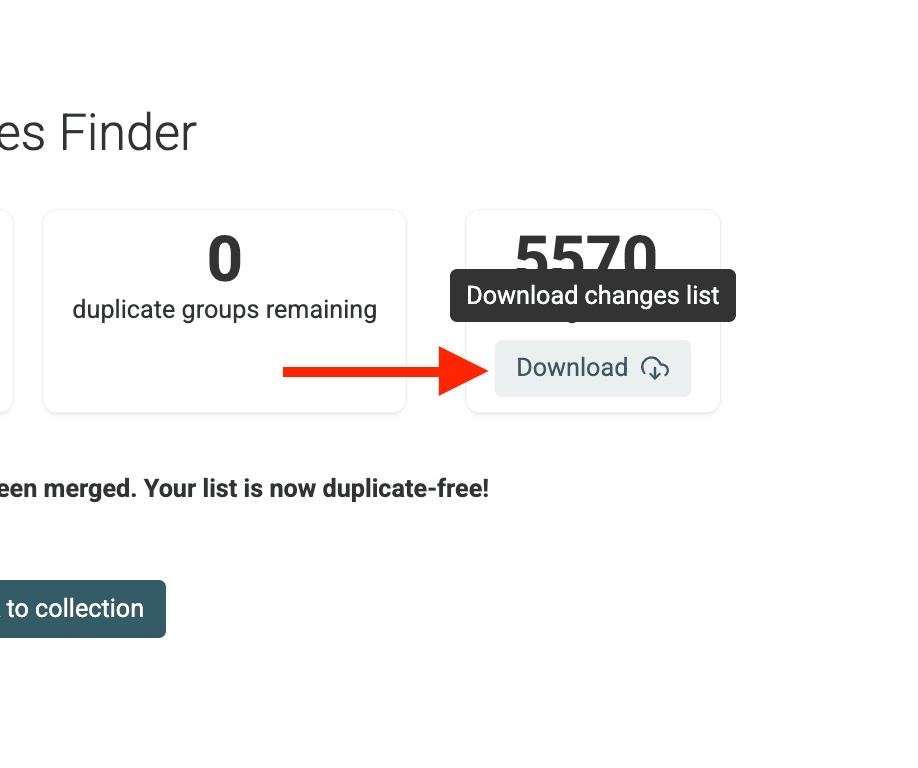
Wechsle zurück in die Hauptansicht Deiner Collection. Du wirst sehen, dass das Zielfeld (z. B. /CompanyName) innerhalb der Duplicate-Gruppen jetzt konsistent ist – während die Records selbst weiterhin getrennt bleiben.
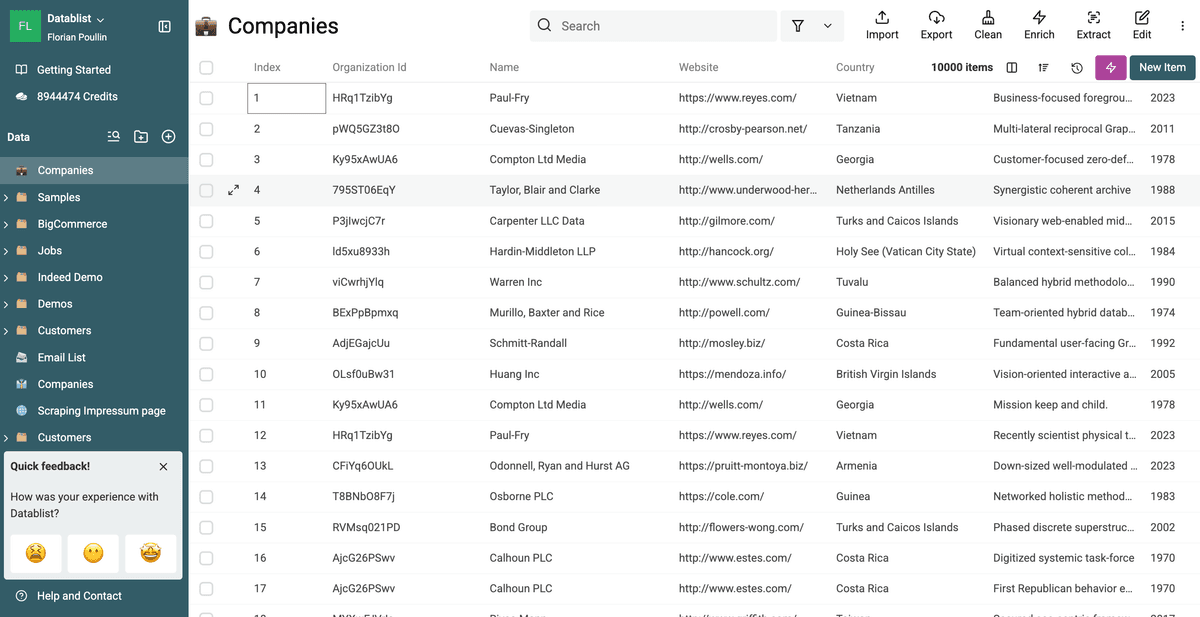
Damit hast Du erfolgreich ein Feld über Duplikate hinweg normalisiert, ohne zu mergen! 🚀
Use Cases for Normalizing Without Merging
Wann ist Normalisieren sinnvoller als ein vollständiger Merge?
- Firmennamen oder Kontaktnamen standardisieren: Bereinige Varianten wie „Example Ltd“, „Example Limited“ oder „Jon Doe“ vs. „Jonathan Doe“ in Duplikaten, bevor Du Dich auf eine finale Merge-Strategie festlegst.
- Jobtitel bereinigen: Vereinheitliche Titel wie „VP Marketing“, „Vice President Marketing“ oder „Marketing VP“ für sauberes Reporting und Analysen.
- Standorte normalisieren: Sorge für einheitliche Länderbezeichnungen („UK“, „United Kingdom“) oder Bundesstaaten-Kürzel („CA“, „California“) in doppelten Adressdatensätzen.
- CRM-Import/Update vorbereiten: Standardisiere wichtige Felder vor dem Import in ein CRM mit strikten Validierungsregeln – auch wenn Du Duplikate vorübergehend behältst.
- Data Auditing: Behalte originale Duplicate-Records für Audits oder historische Nachvollziehbarkeit, standardisiere aber Schlüssel-Felder für bessere Auswertungen.
- Schrittweise Bereinigung: Normalisiere ein Feld nach dem anderen als Teil eines größeren data cleaning-Workflows, bevor Du final mergst oder löschst.
Why Normalize Instead of Merging?
- Record-Granularität bleibt erhalten: Die einzelnen Duplicate-Records bleiben bestehen – wichtig, wenn Du Quellen, Interaktionen oder Historie pro Record nachvollziehen musst.
- Gut bei Unsicherheit: Praktisch, wenn Duplikate keine perfekten Matches sind. Du bringst Konsistenz rein, ohne riskant „falsch“ zu mergen.
- Stufenweises Vorgehen: Du kannst erst normalisieren, danach prüfen und später entscheiden, ob Du mergen oder löschen willst.
- Einfach & fokussiert: Du machst eine gezielte Änderung an genau einem Feld, ohne andere Daten in den Duplikaten anzutasten.
Conclusion
Das AI Processing im Duplicates Finder gibt Dir eine flexible und sehr leistungsfähige Möglichkeit, Duplicate-Daten zu managen. Indem Du bestimmte Felder über Duplicate-Gruppen hinweg normalisieren kannst, ohne Records zu mergen, bekommst Du einen extrem nützlichen Zwischenschritt für viele data-cleaning Workflows. Mit einfachen Prompts in natürlicher Sprache erreichst Du schnell konsistente Daten, sparst Dir Stunden manueller Arbeit und reduzierst Fehler. Ob Firmenname, Jobtitel oder Standort: Dieses Feature hilft Dir, Datenqualität aktiv in den Griff zu bekommen.
FAQ
-
Is AI Processing included in my Datablist plan? AI Processing – inklusive Skripte generieren und für Normalisierung ausführen – ist in den bezahlten Datablist-Plänen verfügbar. Details findest Du auf unserer Pricing Page.
-
Can I normalize multiple fields with one prompt? Ja. Du kannst in einem Prompt mehrere Felder normalisieren. Zum Beispiel: "Normalize the /Company Name property using the most common value in each group. Normalize the /Country property using the most common value in each group. Do not delete any records."
-
What if the AI misunderstands my prompt? Prüfe immer die Script Explanation und die Preview, bevor Du das Skript ausführst. Wenn die Vorschau nicht passt, mach den Prompt klarer und spezifischer und lass das Skript erneut generieren.
-
Can I undo the changes made by the AI script? Sobald Du das Skript ausführst, werden die Änderungen direkt angewendet. Datablist hat zwar eine undo feature für aktuelle Aktionen innerhalb der Session – trotzdem ist Best Practice: Klone Deine Collection, bevor Du größere Transformationen ausführst, damit Du bei Bedarf sauber zurück kannst.
-
How does this differ from the standard "Combine conflicting properties" merge option? Die Standard-Option „Combine“ merged Duplicate-Records zu einem Master Record und hängt widersprüchliche Text-Werte in einem einzigen Feld zusammen. AI Processing kann – mit dem richtigen Prompt – das Feld über alle Duplicate-Records hinweg auf einen ausgewählten Wert updaten und alle Records separat lassen. Es merged nicht und concatenated nichts, außer Du promptest es explizit so.