

Data Matching,也叫 record linkage 或去重,指的是在多个数据集中识别并关联相关记录的过程。 它能把原始、杂乱的数据,转化为可直接用于营销、销售或数据分析的高价值资产。
市面上很多这类软件要么复杂、要么昂贵。Datablist 是一款在线应用,兼容 Mac OS、Microsoft Windows 和 Linux,可帮助你快速完成 Data Matching。它支持 exact match、phonetic,以及高级的fuzzy matching 算法。
在这篇指南中,你将系统了解 Data Matching 的核心方法,快速掌握实际操作。无论你是刚开始接触数据处理,还是已经有经验、想进一步优化流程的从业者,都能从中获得实用技巧。
下面是本文会讲到的 Data Matching 重点内容:
几秒内就能开始使用我们的在线 Data Matching 工具。 无需销售电话,也不用先看一堆 PPT 功能介绍。
第 1 步:导入数据集
第一步,是把你的数据集导入 Datablist。Datablist 是一款在线列表管理工具。你可以查看和编辑 CSV 文件以及 Excel 文件。它非常适合用于管理 leads 列表、清洗客户数据或清洗抓取的数据。
开始时,先新建一个 collection,用来导入你的第一个数据集。

然后点击 Import 按钮。

导入第一个数据集之后,你可以选择:
- 将其他结构相近的数据集导入同一个 collection。
- 将结构不同的数据集导入新的 collections。
Datablist 的 Duplicates Finder 可以在单个 collection 内查找匹配记录,也可以跨不同数据结构的 collections 进行匹配。
第 2 步:必要时先进行数据清洗与标准化
第二步是进行数据清洗。数据清洗是 Data Matching 的关键前置步骤,它决定了匹配结果是否准确、可靠。脏数据或格式混乱的数据,很容易导致错误匹配和不可信的结果。换句话说,做好数据清洗,才有可能做好 Data Matching。
当这些噪音出现在名称字段里(如人名、公司名)时,本身并没有实际价值,却可能让去重算法无法正确识别重复项。
Datablist 内置了多种数据清洗工具:
- 删除符号和标点 - 抓取文本里常会包含表情、ASCII 符号,或者名称中带有多余标点。Datablist 的匹配算法在 Data Matching 时会忽略它们,但在去重流程中,它们可能会阻碍自动合并。
- 删除多余空格 - 单词之间多一个空格,就足以让两段文本变成不同字符串。Datablist 的匹配算法会预处理文本并去除多余空格,但在去重流程中,这类问题同样会影响自动合并。
- 从文本中提取 email 地址、URL 等内容 - 如果你的数据是非结构化文本,里面包含 email、URL、成员提及、标签等内容,可以使用我们的 Data Extractor 抽取这些实体并将数据结构化。结构化之后,Data Matching 会轻松很多。
- 删除 HTML 标签 - 另一个常用清洗功能,是把带有 HTML 标签的字符串转换为纯文本。这样你就可以把包含 HTML 的抓取列表,与其他数据集做匹配。
- 将文本转换为 DateTime、Number、Boolean 等类型 - Datablist 提供真实的数据类型结构,内置支持 DateTime、Number、Boolean 等格式。数据清洗中非常重要的一步,就是把原始文本转换为原生类型。原生的 Datetime、Number 等类型,在高级合并规则中非常关键,尤其当你需要通过数值比较来选出 master item(例如保留最新日期)时。
- 统一文本大小写格式 - 大小写统一看似简单,却是很有必要的一步。Datablist 内置了多种大小写转换算法)。
- 拆分或合并字段 - 这个功能特别适合处理多值数据。如果某个字段中包含多个 email 地址,并且以逗号、分号或空格分隔,Datablist 的 Split Property 工具可以把它拆成多个字段,每个字段只保留一个 email 地址。
- 删除或替换空值 - 使用 Datablist 的 Filtering 功能来筛选空值或空行。
更多示例和具体操作说明,可以参考我们的数据清洗指南。
标准化人名
在数据去重场景中,处理包含人物信息的数据集非常常见。客户、Leads,以及prospects 数据集都是典型例子。理想情况下,针对人物数据做匹配,最好依赖 email 地址或身份编号这类唯一标识符。如果没有这些标识符,或者你需要跨数据集匹配同一个人,就通常需要依靠姓名来完成 data-matching。
在匹配前对姓名进行预处理,可以确保所有名字遵循统一格式,从而减少去重过程中的错误。
删除姓名中的噪音
人的姓名变化很多,比如昵称、缩写、不同拼写方式,以及特殊字符等,都是常见情况。
你可以使用强大的 Find & Replace 工具,去掉前缀、后缀、停用词、地区附加信息,以及其他无意义的词。
例如,要删除姓名中的称谓,可以使用下面这个正则表达式:
^\s*(mr|mrs|dr|miss|ms|sir|madam|m).?\s
并将其替换为空字符串。


说明 如果你不熟悉正则表达式,可以直接联系我们,我们可以协助你清洗数据。
将完整姓名拆分为多个部分
Datablist 不只是数据清洗工具,也提供数据 enrichment 功能。典型应用包括lead enrichment以及使用 Deepl 翻译 CSV。
Name Parser 是清洗姓名时非常实用的一项 enrichment。它会读取完整姓名,并返回其组成部分:first name、middle name、last name,同时还会给出该姓名最常见的性别和国家信息。
它基于统计数据来拆分 full name。
使用方法也很简单:先点击顶部按钮中的 "Enrich Menu"。

然后选择 "Name Parser"。

接着,选择包含姓名值的字段,并映射或新建字段来存储解析结果。原始的 full name 字段不会被修改,只有输出字段会写入解析后的结果。

标准化公司名称
公司名称同样可以做噪音清理。如果公司名中带有前缀、后缀、停用词、地区附加信息,或其他会影响匹配质量的内容,都建议先清理。
一个常见例子,是删除公司名称后缀,比如 “Inc.” 或 “GmbH”。
你可以在 Find & Replace 工具中使用下面这个正则表达式:
,?\s(llc|inc|incorporated|corporation|corp|co|gmbh|ltd).?$
并替换为空字符串。


对所有数据集中的公司名称和地址进行标准化,有助于把它们统一成一致格式,从而提升匹配效果。
标准化街道名称
如果你要对邮寄地址做 Data Matching,那么街道名称标准化非常重要。地址通常会出现缩写、方向前缀、数字后缀等不同写法。如果不先标准化,同一条街道可能会以多种形式重复出现,导致匹配变得困难。
例如:Main 9 St、Main 9TH St. 和 Main 9th Street 实际上指的是同一条街道;Washington Blvd 和 Washington Boulevard 也是同样的情况。
仅靠 fuzzy 算法来处理这些差异,效率并不高。比如 Washington Blvd 和 Washington Boulevard 之间需要多处字符变化,使用fuzzy-matching 算法计算出的相似度距离也会偏高。
更好的做法,是先对街道名称进行标准化。统一格式,才能提升一致性。
Datablist 提供了针对英文街道名称格式的标准化功能,可处理缩写、街道编号等问题。
说明
街道名称标准化适用于已拆分的地址。街道信息必须单独存放在一个字段中。 如果是完整地址放在同一个字段里,这个功能将无法正常工作。
在 "Clean" 菜单中点击 "Normalize Street Names"。

然后选择包含街道名称的字段,并选择 "Normalize english street names"。

确认预览中的修改结果后,点击 "Run"。

第 3 步:在单个或多个数据集合之间匹配记录
现在你的数据已经清洗并标准化完成,接下来就进入 Data Matching 阶段。在这一步,我们的目标是把相似记录分组到一起。

Datablist 提供两种记录比较方式:
- 按选定字段比较 - 这是最常用的模式。你可以自行定义要参与比较的字段。该模式支持多 collection 匹配。
- 比较所有字段 - 在这个模式下,Datablist 的 Duplicates Finder 会识别并删除完全相同的记录。也就是说,它们必须在相同字段上拥有完全一致的数据。只要某个字段为空值,就不会被判定为匹配。

选择要参与匹配的字段
在本指南的后续部分,我们将使用 “Selected Properties & Multi Collections” 模式。
下一步,是选择用于 Data Matching 的字段。如果你在前一步中选择了多个 collections,系统还会要求你为每个 collection 选择映射字段。
说明
Datablist 会尝试根据字段名称,自动完成不同 collections 之间的字段映射。

选择匹配算法
接下来的步骤中,系统会列出你选中的字段,你需要为每个字段配置比较算法。
Datablist 支持以下几种匹配算法:
-
Exact - Exact 算法最适合用于 DateTime、Number、Boolean 等非文本字段。用于文本字段时,你还可以设置是否区分文本差异。Exact 算法会去除文本前后的空格。
-
Smart - Smart 算法会先对数据做预处理,以识别轻微差异的内容。它可以匹配使用不同协议的 URL,也会处理词序和标点差异。例如,“John-Doe” 和 “Doe John” 会被识别为匹配。
-
基于 Double Metaphone 的 Phonetic - Datablist 实现了 Double Metaphone 算法,用于语音匹配。该算法会将单词转换为代表发音的编码,两个发音相近的词会得到相同的 Double Metaphone 编码。
-
基于距离算法的 Fuzzy matching - Datablist 同样支持基于 Jaro-Winkler 和 Levenshtein 距离的 fuzzy matching。选择该模式后,你需要设置相似度阈值。阈值越高,允许的差异就越小。
如果你想了解更多,可以查看官方文档中关于匹配算法的详细说明。

说明
- Smart、Phonetic 和 fuzzy 算法仅适用于文本类字段(包括 Email、Text、LongText 等)。
- URL 字段仅兼容 Exact 和 Smart 算法。
第 4 步:去重——删除或合并匹配组
Datablist 的 Duplicates Finder 通常只需几秒钟,就能返回匹配组列表。
单个 collection 去重时的自动合并
Datablist 的 Data Matching 工具提供了高级重复项合并算法,支持两种 dupes 合并模式:
- 无数据冲突时自动合并(见下文)
- 通过文本拼接或丢弃值来处理冲突并合并(见下文)
说明:
请注意,这项功能仅适用于单个 collection 的 deduplication。对于多 collection deduplication,不同 collections 之间的数据结构可能并不一致。
无数据冲突时自动合并
Datablist 会自动找出所有可以在不丢失信息的前提下直接合并的重复项。
具体逻辑如下:
- 如果所有重复记录在各字段上的值都相同,则只保留一条,其余记录删除。
- 如果这些重复记录的信息是互补的,系统会选出信息最完整的一条作为 primary item,并用其他记录中的字段值补全它。随后除 primary item 之外的记录都会被删除。
- 如果重复记录之间存在字段值冲突,则这些记录会被跳过,等待手动合并。
处理数据冲突的自动合并
运行 Auto-Merging 算法时,Datablist 的 Duplicates Finder 会自动识别冲突字段。所谓冲突,是指两条记录在同一字段上存在不同值。要完成合并,你需要在以下两种处理方式中进行选择:
- 合并字段值 - 该选项支持用分隔符将多个值拼接起来。例如,如果两条相似记录里存在两个不同的 “Phone” 值,你可以用分号把它们拼接在一起。这个选项特别适合 email 地址、电话号码、备注等字段。
- 丢弃冲突字段值 - 对于非文本字段,可以只保留一个值并丢弃冲突值。比如两个 Datetime 值冲突时,就无法直接拼接,此时只能保留其中一个。这个选项在处理外部标识符时也很有用。比如你在为 CRM 清洗数据时,外部账户 ID 必须唯一标识 CRM 中的一条记录,不能被拼接成字符串。
多 collection Data Matching 的清理规则
当你对多个数据集运行 Datablist Data Matching 工具时,auto-merging 功能将不可用,因为不同 collections 之间可能存在不同的数据结构和字段。
作为替代方案,Datablist 提供了一项清理功能:你可以删除除某一个 collection 以外其他 collections 中的重复项。这个功能非常适合用来保证多个数据集之间记录的唯一性。

在真正执行清理算法之前,系统会先展示即将发生的修改预览。

使用 Merging Assistant 手动合并
对于剩余无法自动处理的重复记录,还可以使用手动合并助手。
要合并重复项,请点击每个重复组左侧的 "Manual Merging Assistant" 按钮。

点击后会打开合并工具。右侧显示的是 "Primary Item",左侧其余重复记录则称为 "Secondary Items"。 Datablist 会自动把数据最完整的一条记录选为 "Primary item"。
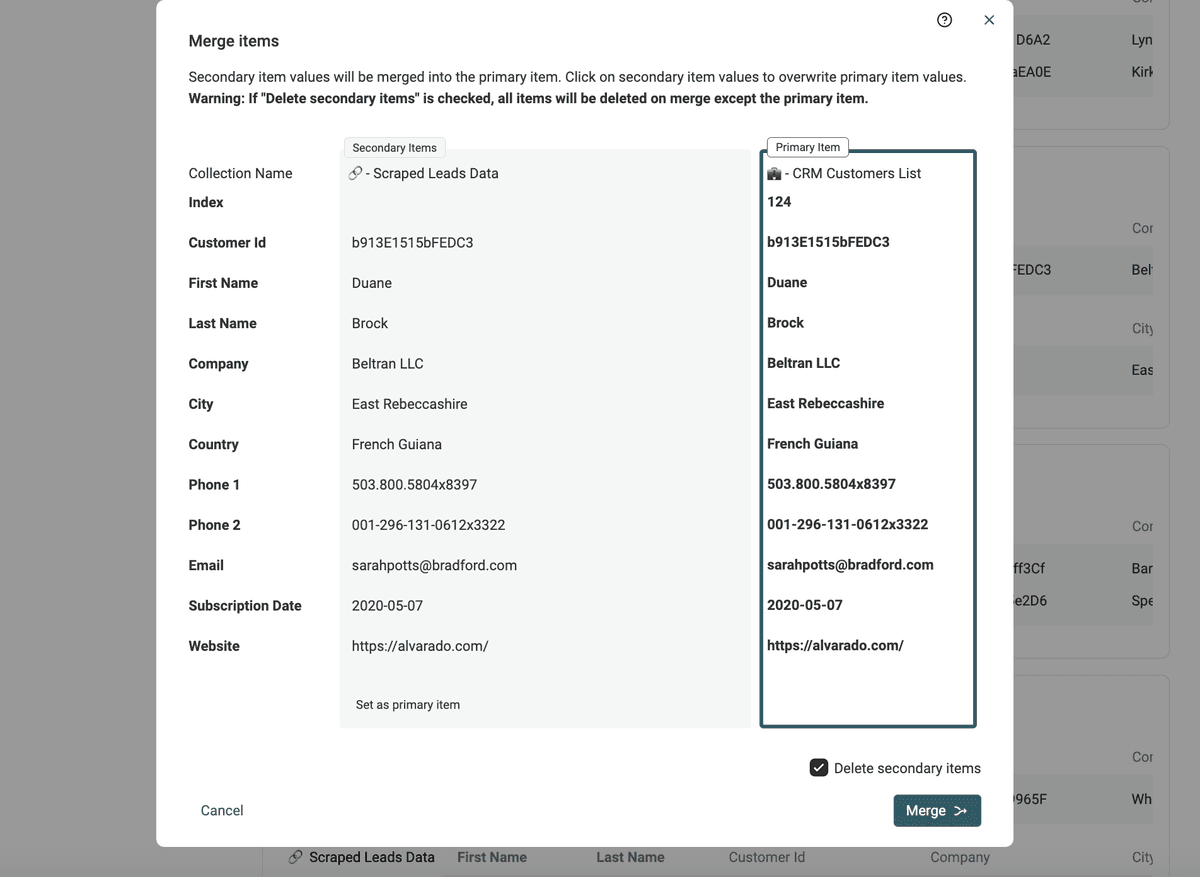
如果可以自动判断,Secondary Items 中的字段值会被默认选中并合并到 Primary item 中。如果多个值存在冲突,则需要你手动决定保留哪个值。
如果最终生成的 "Primary item" 符合你的预期,点击 Merge 按钮即可确认合并。所有 Secondary Items 都会被删除,只保留一条合并后的记录。
说明 当多个 collections 具有相似数据结构(相同字段)时,手动 Merging Assistant 也可用于多 collection deduplication。
导出重复组并在外部工具中处理
最后,Datablist 的 Data Matching 工具还支持导出检测到的重复组。你可以将所有重复记录按组连续导出为 CSV 或 Excel 文件。

你可以把导出的文件交给其他工具继续清洗(例如电子表格工具),或用于更复杂的后续分析。
FAQ
什么是 Data Matching?
Data Matching,也叫 record linkage 或 deduplication,是指在一个或多个数据集中识别并关联相关记录的过程。它的核心目标,是通过识别并整合同一实体、个人或对象的重复项或相似项,来提升数据质量、准确性和一致性。
这个过程非常适合用于清理那些随着时间推移不断累积重复记录的数据集,也适用于整合多个字段相似或存在重叠的数据集。
Data Matching 可以依赖 email 地址、网站 URL、身份编号/字符串等区分度较高的字段;也可以通过多个非唯一属性的组合(如姓名、出生日期、公司名称、地理位置)来计算记录之间的相似度。
Datablist 的 Data Matching 工具有多快?
Datablist 的 Data Matching 工具会将数据集加载到内存中进行匹配分析,因此比较适合处理 100 万条记录以内的数据集。大多数 Data Matching 分析都可以在几分钟内完成。
做 Data Matching 需要技术背景吗?
不需要。Datablist 是一款 no-code 解决方案,适合所有人使用——无论你是数据分析师,还是营销、销售团队成员。
什么场景适合使用 Data Matching?
Data Matching 广泛应用于金融、医疗、营销和客户管理等领域。在这些场景中,可靠的数据是做出正确决策或与其他工具进行数据集成的基础。
这个过程尤其适合用于欺诈检测、用户档案整合,以及从多个来源进行数据 enrichment 等任务。
接下来读什么?
如果你对数据清洗感兴趣,下面这些指南你也会有帮助: