
Jeder codebasierte Scraper ist auf die Struktur einer einzigen Website gebaut. Sobald Du dasselbe Skript auf eine andere Website loslässt, greifen die Selektoren ins Leere, die Seite kommt ohne Daten zurück und das Skript bricht auseinander.
Mit einem Prompt passiert das nicht so. Du beschreibst einfach in klaren Worten, was Du brauchst, und ein AI-Agent liest jede Seite jedes Mal neu ein, statt sich auf fest verdrahtete Regeln für nur ein Layout zu verlassen.
Genau dieser Wechsel macht es möglich, ohne Code praktisch jede Website zu scrapen und in wenigen Minuten saubere Daten aus fast jeder Seite zu ziehen statt erst stundenlang herumzukonfigurieren.
📌 Kurzfassung für Eilige
Die Kernidee: Du brauchst nicht für jede Website einen eigenen Scraper. Codebasierte Scraper sind an die Struktur einer einzelnen Seite gebunden, ein AI Scraping Agent passt sich dagegen mit nur einem einfachen Prompt an verschiedene Websites an.
In diesem Artikel zeige ich Dir, warum ein einziges Tool heute fast jede Website scrapen kann und wie Du das mit dem AI Scraping Agent von Datablist umsetzt.
Das nimmst Du aus dem Artikel mit:
- Ein klares Verständnis dafür, warum Code- und Template-Scraper websiteübergreifend schnell kaputtgehen
- Wie sich AI Scraping von älteren No-Code-Methoden unterscheidet
- Eine Schritt-für-Schritt-Anleitung, wie Du praktisch jede Website scrapest
Was dieser Guide abdeckt
- Was „jede Website scrapen“ ohne Code wirklich bedeutet
- Wie AI Scraping im Vergleich zu älteren No-Code- und Code-Methoden abschneidet
- Worauf Du bei einem Tool achten solltest, das auf jeder Website funktioniert
- Eine Schritt-für-Schritt-Anleitung mit dem AI Scraping Agent von Datablist
- Häufige Fragen zum Website-Scraping ohne Code
Was „Scrape Any Website“ wirklich bedeutet
Vor zwei Jahren hieß eine Website ohne Code zu scrapen meistens: eine bekannte Seite mit einem fertigen Template im Hintergrund. Seit AI für alle zugänglich geworden ist, hat sich das verändert.
Heute bedeutet es tatsächlich das, was es sagt: Du gibst einem Tool fast jede öffentliche Seite und bekommst saubere, strukturierte Daten zurück, ganz ohne Skripting.
Warum Website-Scraping früher Code brauchte
Klassische Scraper sind Skripte, die auf das HTML einer einzelnen Website gemappt sind. Sie zielen auf bestimmte Selektoren, Klassennamen und Pagination-Muster, die genau auf dieser Seite existieren.
Das funktioniert so lange ganz gut, bis sich das Ziel ändert. Wenn Du dasselbe Skript auf eine andere Website ansetzt und nichts mehr zusammenpasst, bekommst Du leere Zeilen oder eine Fehlermeldung.
Was ein No-Code Web Scraper anders macht
Ein No-Code Web Scraper nimmt das Skript komplett aus der Gleichung. Statt Code zu schreiben, definierst Du über eine visuelle Oberfläche oder schriftliche Anweisungen, was Du extrahieren willst.
Das ist die Kategorie, die die meisten schon kennen. Allerdings sind die Tools darin alles andere als gleich. Deshalb teilen wir sie hier in zwei Unterkategorien auf:
- Point-and-Click- und Template-Tools: Du markierst Felder auf einer Seite oder lädst ein fertiges Template für eine bekannte Website.
- AI Scraping Agents: Du beschreibst die Daten in einfachem Englisch, und der Agent findet selbst heraus, wie er sie extrahiert.
Beide kommen ohne Code aus, aber nur eine dieser Varianten löst auch die Abhängigkeit davon, dass eine Website bekannt oder vorhersehbar sein muss.
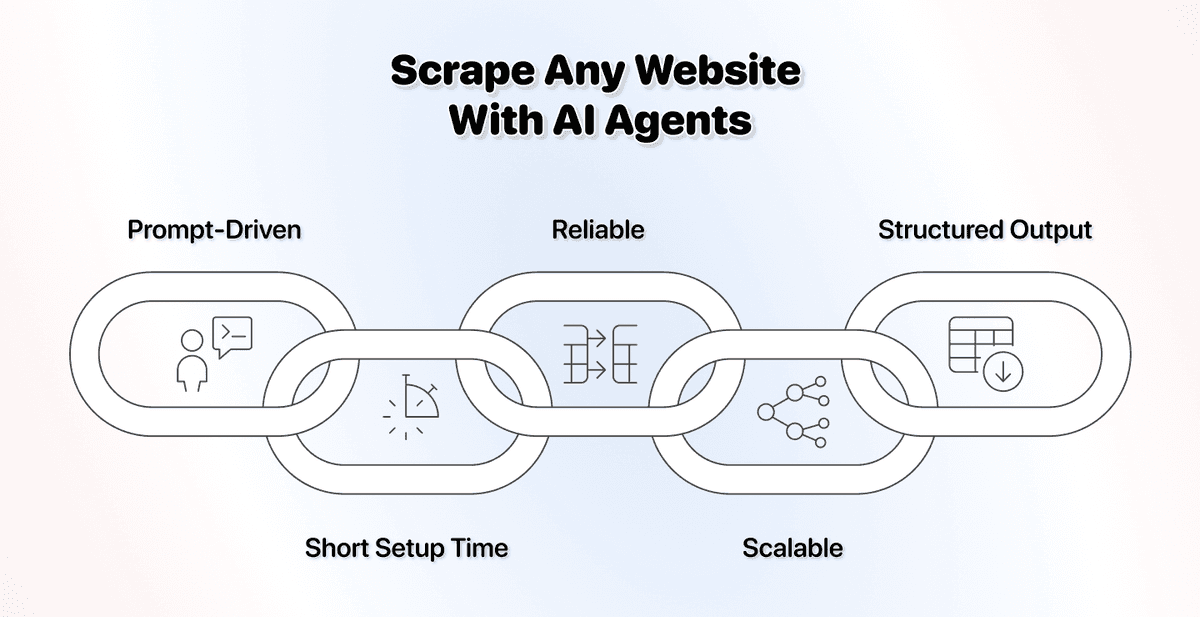
Warum Du heute praktisch jede Website ohne Code scrapen kannst
Die Veränderung kam durch die Art, wie AI eine Seite liest. Ein AI scraping agent schaut sich den Seiteninhalt zusammen mit Deinem Prompt an und entscheidet dann, was extrahiert werden soll.
Dieser AI-Scraping-Ansatz macht fest verdrahtete Selektoren überflüssig. Genau deshalb ist er so stark: Es gibt keine starre Regel mehr, die bei einem Layoutwechsel kaputtgehen kann, weil der Agent die Seite bei jedem Run neu liest.
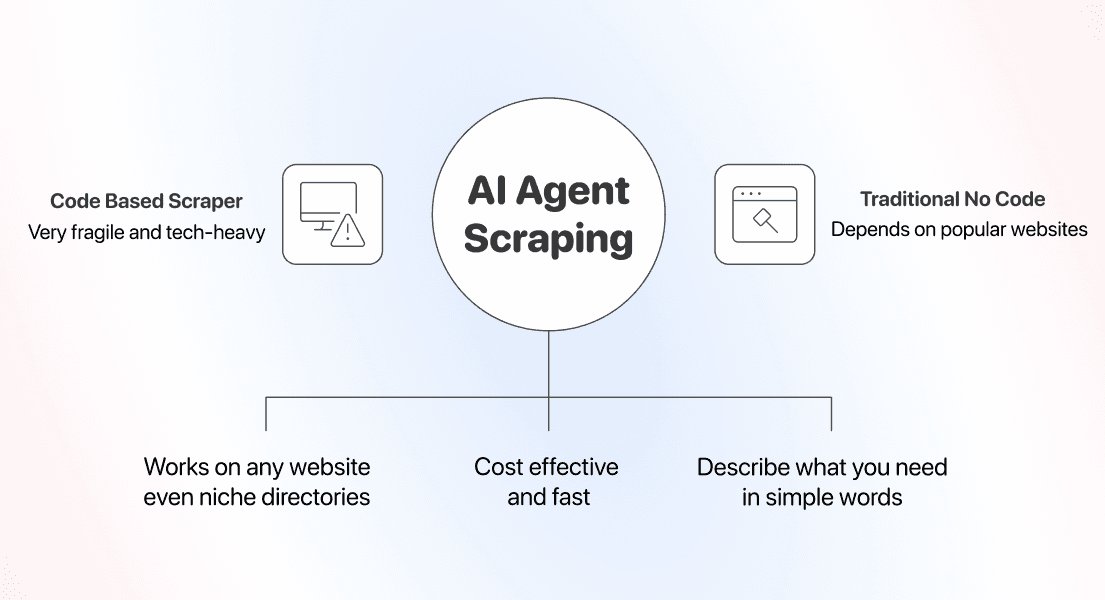
AI Scraping vs. ältere Methoden zum Website-Scraping ohne Code
No-Code ist nicht gleich No-Code. Der Unterschied zwischen den Methoden zeigt sich spätestens dann, wenn eine Seite sehr speziell ist oder eine populäre Website ihr Layout ändert.
Codebasierte Scraper: leistungsstark, aber an eine Website gebunden
Wenn Du Deinen eigenen Scraper in Python oder JavaScript schreibst, hast Du die volle Kontrolle. Du entscheidest über jeden Selektor, jede Pagination-Regel, jeden Retry und jeden Timeout.
Jedes Skript ist aber für genau eine Website gebaut, braucht eine Entwicklerin oder einen Entwickler für die Umsetzung und bricht, sobald sich das Layout der Seite ändert. Ja, codebasierte Scraper sind in der Ausführung günstig, aber sie bringen andere Kosten mit: ein Skript pro Website, jemanden auf Abruf für Fixes und laufende Wartung bei jedem Update der Zielseite.
Für Teams, die viele verschiedene Websites scrapen, summiert sich das extrem schnell. Fünf Ziele können fünf Skripte bedeuten und fünf unterschiedliche Baustellen, die jede Woche wieder Aufmerksamkeit brauchen.
Point-and-Click- und Template-Scraper: einfach, bis die Website zu speziell wird
Template- und Point-and-Click-Tools waren die ersten echten No-Code Scraper. Sie funktionieren gut auf bekannten Websites, weil jemand das Template schon gebaut hat oder weil die Seite simpel genug ist, um sie per Klick zu konfigurieren.
Die eigentlichen Probleme fangen an, wenn Du weniger bekannte Seiten scrapen willst, zum Beispiel Nischenverzeichnisse, regionale Shops oder ungewöhnliche Layouts. Dafür gibt es oft kein fertiges Template.
Und wie bei codebasierten Scrapern gilt auch hier: Sie funktionieren nur, solange die Seite in etwa gleich bleibt. Wenn sich die Struktur ändert, brechen die gespeicherten Auswahlen, der Datenfluss stoppt und Du musst wieder reparieren.
AI Scraping: ein Prompt, der sich an jede Website anpasst
AI Scraping löst zwei Probleme:
- Endlose Konfiguration
- Scraper, die kaputtgehen, sobald die Ziel-Website ihre Struktur ändert
Du beschreibst einfach die Daten, die Du brauchst, gibst dem Agenten eine URL und bekommst strukturierte Zeilen zurück.
Weil der Agent jede Seite genau in dem Moment liest, in dem sie gescrapet wird, kann derselbe Prompt auf unterschiedlichen Websites laufen. Produktseite, Verzeichnis, Listing-Seite: Der Workflow bleibt derselbe.
Genau hier kommt der AI Scraping Agent von Datablist ins Spiel. Du gibst eine Ziel-URL und einen Prompt in einfachem Englisch ein und kannst damit ohne Code praktisch jede Website scrapen — in Minuten statt in Stunden. Gleichzeitig wird auch data cleaning deutlich einfacher, weil die gescrapeten Daten direkt in einem Sheet landen, in dem Du sofort deduplizieren und enrichen kannst.
Wir haben No-Code-Scraping-Methoden anhand der wichtigsten Kriterien miteinander verglichen 👈🏽
Worauf Du bei einem Tool für Website-Scraping ohne Code achten solltest
Sobald klar ist, dass ein AI Scraper besser funktioniert als ein Scraper pro Website, stellt sich die Frage: Welchem Tool kannst Du wirklich vertrauen? Für mich sind dabei drei Punkte entscheidend: Wie breit ist die Abdeckung, wie oft geht es kaputt und wie einfach lässt es sich bedienen?
Abdeckung: Kommt das Tool auch mit Nischen- und Long-Tail-Websites klar?
Abdeckung ist der erste echte Test. Viele Scraping-Tools behaupten, sie könnten jede Website scrapen, hängen in Wahrheit aber still und heimlich nur an einer Bibliothek aus vorgefertigten Templates für bekannte Seiten.
Die wichtigste Frage lautet: Kann das Tool auch eine Website scrapen, die es noch nie gesehen hat?
Prompt-gesteuerte Agents bestehen diesen Test, weil sie überhaupt nicht auf Templates angewiesen sind. Wenn Deine Zielseiten also Nischenverzeichnisse oder regionale Websites umfassen, ist genau das das wichtigste Kriterium.
Ein schneller Reality-Check: Teste das Tool auf der ungewöhnlichsten Website in Deiner Liste und schau, ob es damit klarkommt.
Wartung: Bricht es jedes Mal, wenn sich eine Website verändert?
Die Wartung von Scrapern ist oft der Kostenfaktor, über den kaum jemand spricht. Selektoren, Pagination-Regeln und Proxies gehen kaputt, sobald die Zielseite ihr Layout ändert, und irgendwer muss das wieder richten.
Ein Tool, das auf festen Regeln basiert, schiebt genau diese Arbeit auf Dich ab. Jede Layoutänderung wird zu einem kleinen Reparaturprojekt und die Reparaturen hören nie wirklich auf.
Ein Prompt-gesteuerter Scraping Agent umgeht den Großteil davon, weil er die Seite bei jedem Run neu liest, statt auf die Selektoren von gestern zu vertrauen. Der Prompt bleibt gleich, auch wenn die Seite sich verändert.
Bedienung: So sollte sich ein No-Code Web Scraper anfühlen
Der letzte Test ist, ob Du das Tool wirklich ohne Entwicklerteam nutzen kannst. Ein universelles Tool hilft einem Recruiting-, Operations- oder Marketing-Team wenig, wenn am Ende doch eine Engineer-Person nötig ist, um es zu bedienen.
Beurteile es aus Deiner Perspektive. Kannst Du selbst einen einfachen Prompt schreiben, ein paar Felder definieren und das Ergebnis exportieren?
Genau dafür wurde der AI Scraping Agent von Datablist gebaut: Prompt schreiben, Felder konfigurieren, Daten exportieren. Kein Code, kein Developer, kein Setup pro Website.
Wenn Du nicht sicher bist, welches Tool zu Deinen Zielseiten passt, haben wir die besten No-Code-Scraping-Tools direkt miteinander verglichen 👈🏽
Schritt für Schritt: Jede Website scrapen
Jetzt wird es praktisch. Alles, was jetzt folgt, läuft direkt in Datablist, der Workflow-Automation-Plattform für AI Scraping und data enrichment.
Du gibst eine Ziel-URL und einen einfachen Prompt ein und bekommst in wenigen Minuten strukturierte Daten aus fast jeder Website zurück — ganz ohne Code und ohne stundenlanges Setup pro Seite.
Damit das greifbar wird, machen wir in diesem Walkthrough zwei Dinge:
- Den Scrape konfigurieren und ausführen
- Eine eindeutige Property anlegen, damit wiederholte Runs nicht dieselbe Zeile doppelt importieren
So scrapest Du jede Website mit dem AI Scraping Agent von Datablist
Um den Anspruch mit einer echten Website zu belegen, nutzen wir den AI Scraping Agent auf einer GymShark-Kategorieseite. Jeder einzelne Schritt funktioniert aber genauso auf jeder anderen Website, die Du damit scrapen willst.
Bevor Du loslegst, solltest Du Folgendes parat haben:
- Einen Datablist-Account
- Die URL der Seite, die Du scrapen willst
- Eine klare Liste der Felder, die Du extrahieren möchtest
- Beispiele für Felder, die missverstanden werden könnten
- Ein grobes Seitenlimit für den Run
Schritt 1: Registrieren und eine Collection erstellen
Registriere Dich zuerst bei Datablist.com.
Erstelle danach eine New Collection, in der die Daten gespeichert werden, die Du gleich scrapest.
Schritt 2: Den AI Agent - Site Scraper öffnen
Klicke in Deiner neuen Collection auf See all sources.
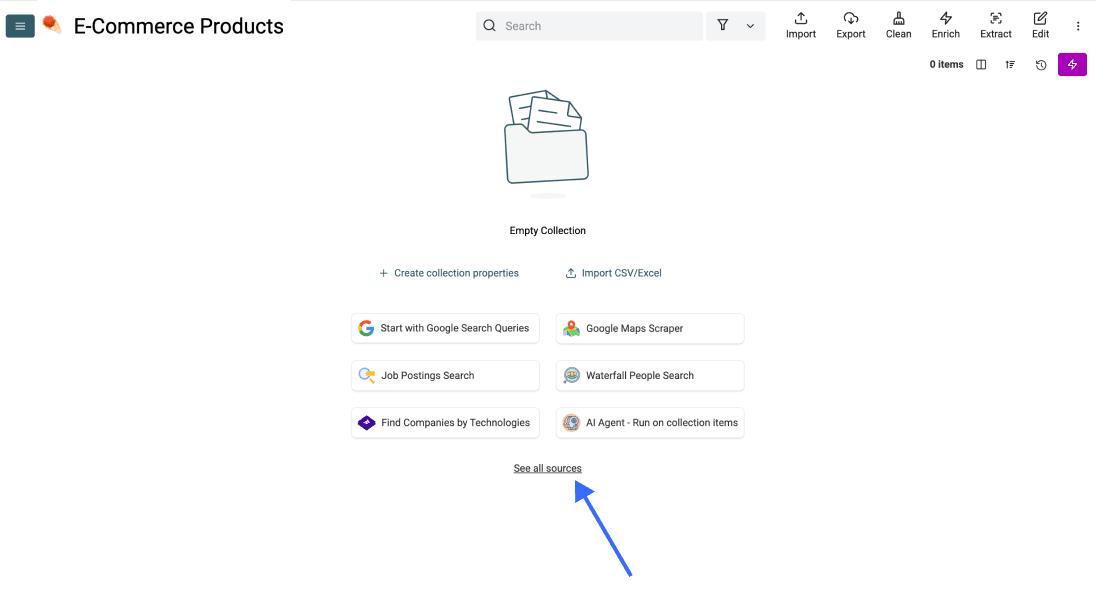
Scrolle nach unten und wähle AI Agent - Site Scraper aus.
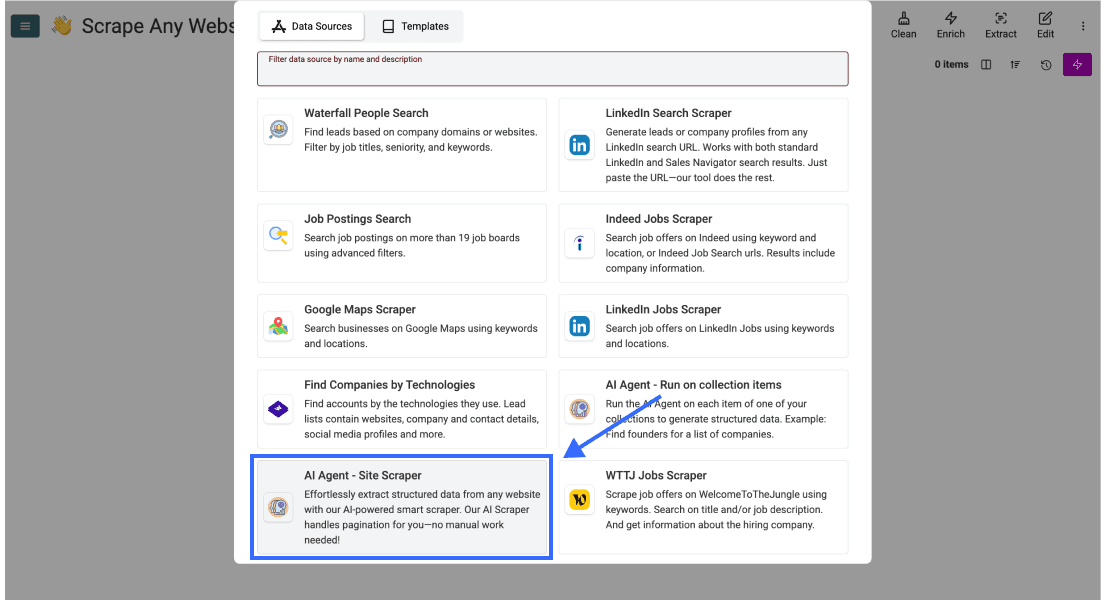
Schritt 3: Prompt schreiben und Task konfigurieren
Füge Deine Ziel-URL in das erste Feld ein. In diesem Beispiel ist das eine GymShark-Kategorieseite, aber Du kannst jede beliebige Website scrapen.
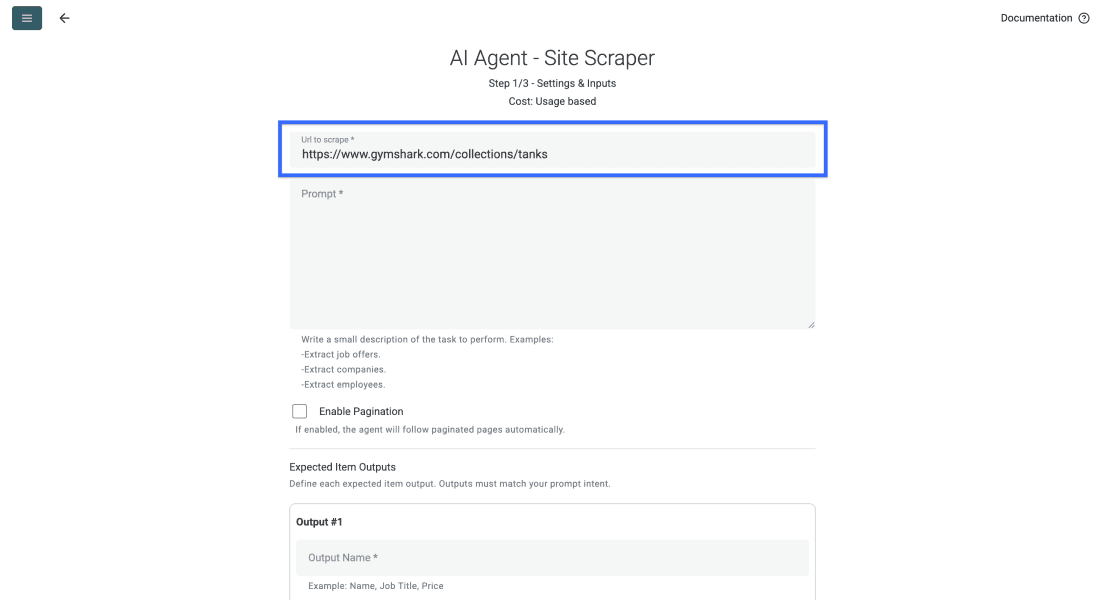
Scrolle dann zum Prompt-Feld und beschreibe, was der Agent von jeder Seite extrahieren soll. Weiter unten findest Du auch ein Beispiel für einen Prompt.
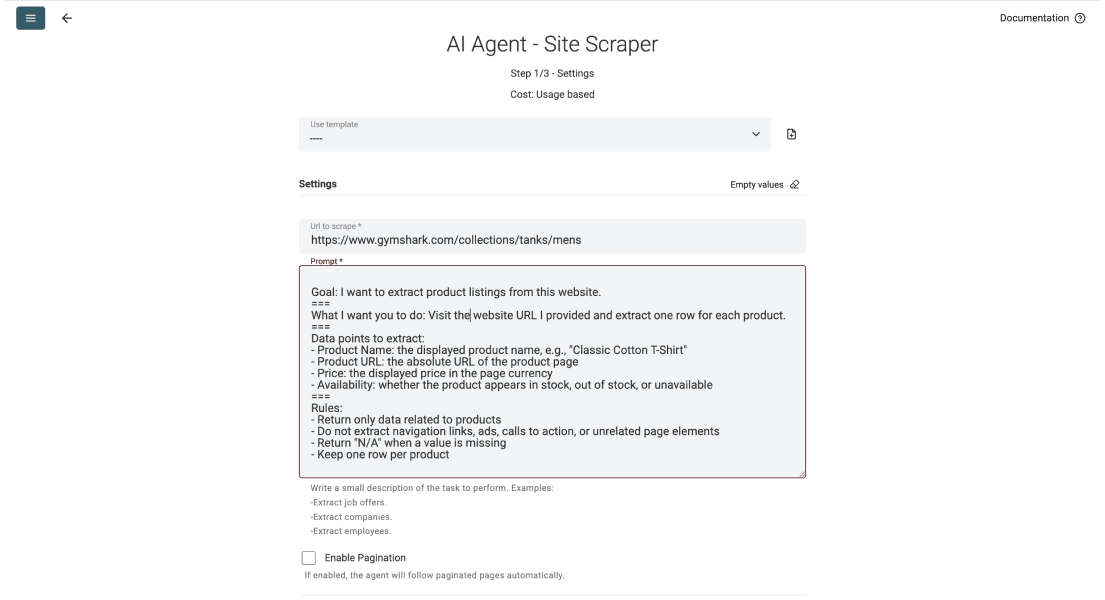
Ein guter Prompt sagt dem Agenten, was er extrahieren soll, was er ignorieren soll und wie jede Zeile aussehen muss. Du kannst die Struktur unten kopieren und einfach Deine eigenen Felder einsetzen.
Goal: I want to extract product listings from this website.
.===
What I want you to do: Visit the URL I provide and return one row per product.
.===
Data points to extract:
- Product Name (example: "Classic Cotton T-Shirt")
- Product URL: the absolute link to the product page
- Price: the displayed price in the page currency
- Availability: in stock, out of stock, or unavailable
.===
Mistakes to avoid:
- Return only product data; ignore navigation, ads, and call to actions
- Return "N/A" when a value is missing
- Keep one row per product
Der Agent folgt Anweisungen deutlich besser, wenn der Prompt jedes Feld klar benennt und ein Beispiel enthält. Zu vage Prompts sind der Hauptgrund dafür, dass ein Run unordentliche Ergebnisse liefert.
Mit diesen Regeln zum Schreiben von Prompts für AI Agents bekommst Du sauberere Ergebnisse 👈🏽
Lege danach fest, wie viele Seiten der Agent durchlaufen soll.
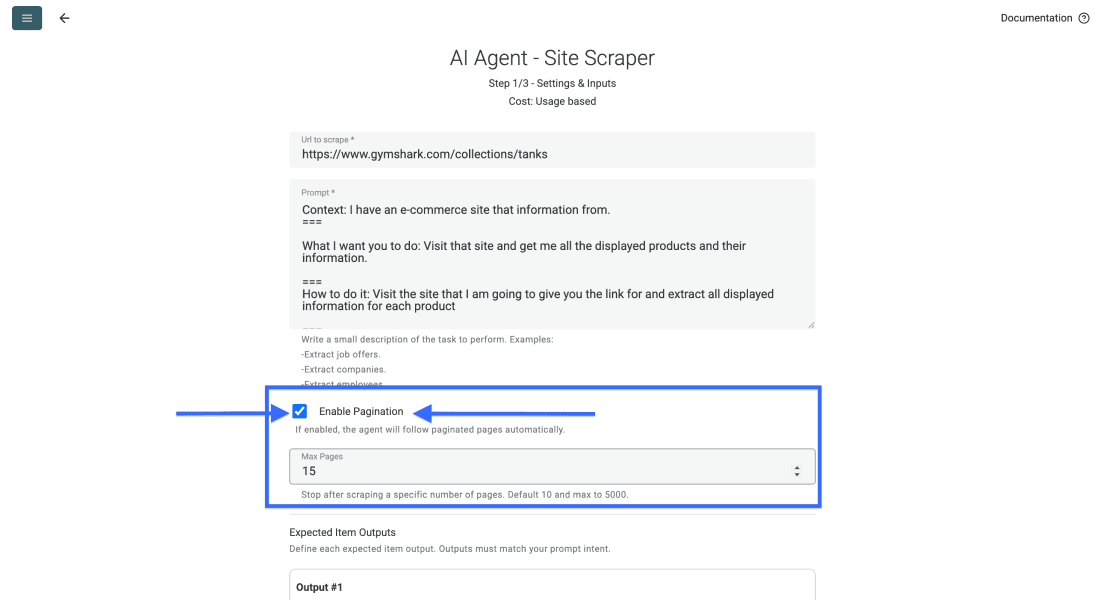
📘 Zur Pagination bei Listing-Seiten
Die meisten Listing-Seiten verteilen ihre Ergebnisse auf mehrere Unterseiten. Setze das Limit danach, wie viel von der Website Du erfassen willst. Datablist unterstützt bis zu 5.000 Seiten pro Run.
Sobald Prompt und Seitenlimit gesetzt sind, scrolle nach unten und konfiguriere Deine Output-Felder.
Schritt 4: Output-Felder definieren
Wenn Du den Prompt selbst schreibst, sollten die Output-Felder genau zu den Datenpunkten passen, die Du angefragt hast. Eine Spalte pro Feld hält die Daten sauber und gut nutzbar.
Für jeden Output gilt:
- Setze den Namen des Datenpunkts als Output Name
- Ergänze eine klare Output Description, bei Bedarf mit Beispiel
- Wähle den passenden Output Type, zum Beispiel Text, Zahl, URL oder E-Mail
- Klicke auf More, um weitere Output-Felder hinzuzufügen
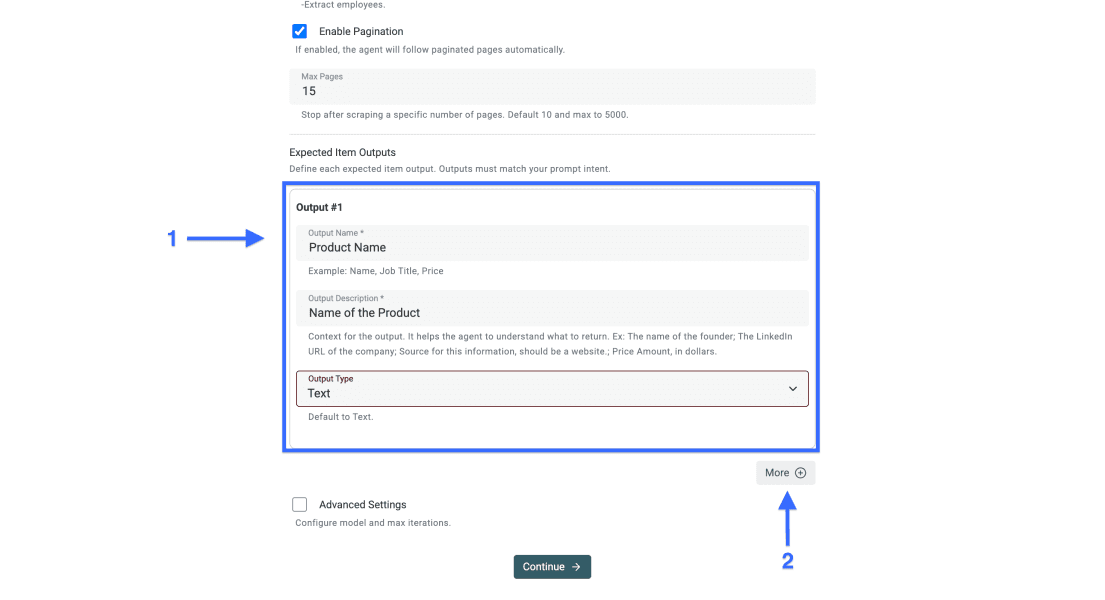
Schritt 5: Advanced Settings konfigurieren
Wenn Deine Outputs definiert sind, aktiviere das Kästchen neben Advanced Settings und setze Folgendes:
- LLM: OpenAI GPT-4o mini, für das beste Verhältnis aus Performance und Preis
- Max iterations: 10
- Render HTML: aktivieren, was bei Websites mit JavaScript-geladenen Inhalten entscheidend ist
Danach sollte Dein Bereich für Advanced Settings so aussehen.
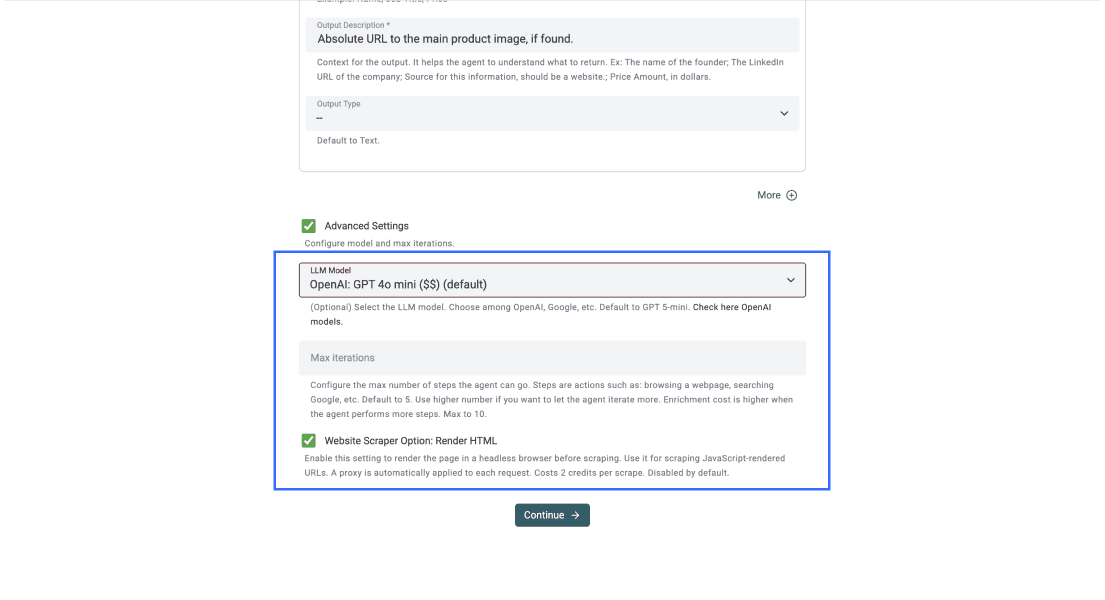
Schritt 6: Den Scrape starten
Sobald Prompt, Outputs und Einstellungen stehen, klicke auf Continue.
Datablist erstellt dann für jeden konfigurierten Output eine Property. Jetzt kannst Du noch einmal prüfen, ob nichts fehlt, und dann auf Run Import Now klicken, um den Scraping-Run zu starten.

Nach ein paar Minuten landen die Zeilen in Deiner Collection und sind bereit zum Cleanen, Enrichen, Deduplizieren oder Exportieren.
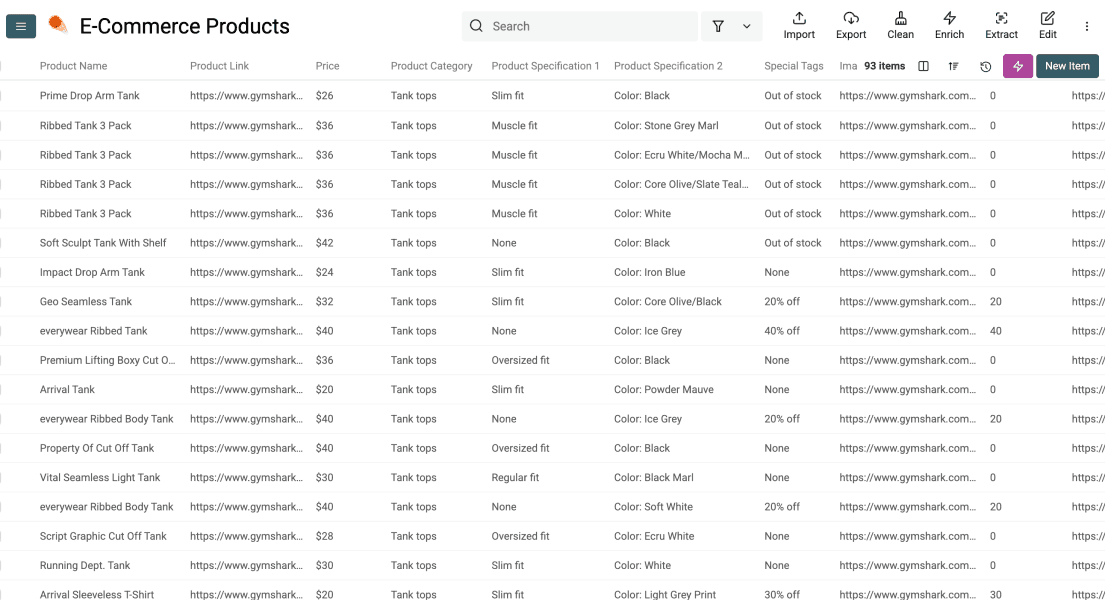
Wenn Du diesen Scrape später erneut laufen lassen willst, solltest Du zuerst den nächsten Abschnitt umsetzen, damit nicht dieselbe Zeile zweimal importiert wird.
Duplikate bei wiederholten Scraping-Tasks vermeiden
Jetzt zeige ich Dir, wie Du in Datablist Duplikate vermeidest, indem Du vor einem erneuten Scraping-Task einen eindeutigen Identifikator festlegst.
Schritt 1: Einen eindeutigen Identifikator auswählen
Wähle zuerst die Spalte aus, die Datablist zur Erkennung von Duplikaten verwenden soll.
Wenn Du zum Beispiel Produkte scrapest, nutze einen stabilen Wert wie Product URL oder Item URL. Wenn Du mit Unternehmen arbeitest, nimm Company Domain oder Business Name.
💡 Wähle einen stabilen Identifikator
Nimm einen Wert, der wirklich nur zu einer einzigen Zeile gehört. Product URLs, Item URLs, Company Domains und E-Mail-Adressen funktionieren meistens besser als Namen, weil Namen doppelt vorkommen können.
Schritt 2: Die Spalteneinstellungen öffnen
Klicke auf die Spaltenüberschrift Deines eindeutigen Identifikators.
Wähle danach Rename - Settings - Delete aus.

Schritt 3: Doppelte Werte verhindern
Aktiviere jetzt die Option Do not allow duplicate values.
Klicke anschließend auf Save Property.

Schritt 4: Das Schlüssel-Icon prüfen
Sobald die Spalte gespeichert ist, zeigt Datablist neben dem Spaltennamen ein Schlüssel-Icon an.
Dieses Icon bestätigt, dass die Spalte jetzt als eindeutiger Identifikator gesetzt ist.
Wenn Du denselben Scrape, dieselbe Source oder denselben Import später noch einmal ausführst, fügt Datablist nur noch Zeilen mit neuen eindeutigen Werten hinzu. So bleibt Deine Collection sauber, auch wenn Du denselben Prozess regelmäßig wiederholst.
Fazit: Nicht mehr Scraper konfigurieren, sondern einfach prompten
Der eigentliche Umbruch ist nicht nur ein einzelnes Tool. Entscheidend ist, dass eine Seite plus ein Prompt in einfachem Englisch das frühere Modell „ein Skript pro Website“ ersetzt hat, das Web Scraping so fragil gemacht hat. Genau deshalb kann derselbe Workflow heute praktisch jede Website scrapen — egal ob Verzeichnis, Marketplace oder Nischen-Shop.
Häufige Fragen zum Website-Scraping ohne Code
Kann der AI Scraping Agent von Datablist jede Website scrapen?
Er funktioniert auf fast jeder öffentlichen Website. Weil er jede Seite mit einem Prompt statt mit einem festen Template liest, passt er sich auch an Websites an, die er noch nie gesehen hat.
Gibt es eine kostenlose Testversion für den No-Code Web Scraper von Datablist?
Ja. Du kannst kostenlos starten, eine Collection anlegen und den AI Scraping Agent gratis ausprobieren.
Muss ich Code schreiben, um den AI Scraping Agent von Datablist zu nutzen?
Nein. Du beschreibst einfach in einfachem Englisch, was Du brauchst, ordnest ein paar Output-Felder zu und startest den Run. Es gibt kein Skript, das Du schreiben musst, und auch nichts, das Du bei Layoutänderungen neu bauen musst. Genau deshalb hilft Dir Datablist dabei, ohne Code praktisch jede Website zu scrapen.
Welche Daten kann der AI Scraping Agent aus einer Website extrahieren?
Alles, was auf der Seite sichtbar ist und was Du anforderst: Produktnamen, Preise, URLs, Verfügbarkeit, Kontaktdaten, Listings und mehr. Du definierst die Felder im Prompt und in den Outputs. Wichtig: Der AI Scraper von Datablist kann keine Backend-Informationen scrapen, zum Beispiel Lagerbestände, wenn diese nicht öffentlich auf der Website angezeigt werden.
Was kostet es, Websites mit Datablist zu scrapen?
Scraping läuft über nutzungsbasierte Credits, Du zahlst also nur für das, was Du tatsächlich verarbeitest. Ein kleiner Test-Run vor dem vollständigen Scrape ist der günstigste Weg, um alles zu validieren.
Kann ich die gescrapeten Daten als CSV oder Excel exportieren?
Ja. Sobald die Zeilen in Deiner Collection liegen, kannst Du sie direkt in Datablist cleanen, deduplizieren, enrichen und unter anderem als CSV oder Excel exportieren.
Was bedeutet es, eine Website ohne Code zu scrapen?
Damit ist gemeint, strukturierte Daten aus einer Seite zu extrahieren, ohne ein Skript schreiben oder pflegen zu müssen. Statt Selektoren zu programmieren, konfigurierst Du ein Tool oder beschreibst per Prompt in einfachem Englisch, welche Daten gescrapet werden sollen.
Kann man wirklich jede Website ohne Code scrapen?
Du kannst fast jede öffentliche Website ohne Code scrapen, wenn Du einen AI Scraping Agent nutzt. AI Agents passen sich mit einem einzigen Prompt an unterschiedliche Layouts an. Logins oder starker Anti-Bot-Schutz können auf manchen Seiten trotzdem Reibung verursachen.
Was ist der Unterschied zwischen AI Scraping und klassischem Web Scraping?
Klassisches Scraping arbeitet mit einem Skript, das fest auf die Struktur einer Website codiert ist. AI scraping liest die Seite bei jedem Run neu über einen Prompt, sodass sich dasselbe Setup an viele verschiedene Websites anpassen kann.
Warum gehen Scraper kaputt, wenn eine Website ihr Layout ändert?
Ein Scraper zielt auf bestimmte Selektoren und Seitenmuster. Wenn die Website diese ändert, findet das Skript die Daten nicht mehr und liefert leere Ergebnisse oder Fehler, bis jemand es anpasst.
Was ist ein No-Code Web Scraper und wie funktioniert er?
Ein no-code web scraper extrahiert Daten ohne Programmierung. Point-and-Click-Tools lassen Dich Felder visuell auswählen, während AI Scraping Agents einen Prompt in einfachem Englisch entgegennehmen und die Daten für Dich extrahieren.
Wie lange dauert es, eine Website ohne Code zu scrapen?
Das hängt vom Tool ab. Wenn wir Datablist.com als Beispiel nehmen, dauert es in der Regel nur wenige Minuten: registrieren, Prompt schreiben, Felder zuordnen und Run starten. Der eigentliche Scrape ist meist ebenfalls nach 5 bis 10 Minuten abgeschlossen — je nachdem, wie viele Seiten Du verarbeitest.