

Duplikate zu bereinigen heißt nicht einfach nur auf „Delete“ zu klicken!
Manche Datensätze sind 1:1 identisch. Andere enthalten widersprüchliche Werte. Und viele ergänzen sich – die solltest Du zusammenführen statt löschen.
Je nach Workflow willst Du Datensätze zusammenführen, einen Master-Datensatz aktualisieren oder Duplikate erstmal nur zur Prüfung markieren.
Einfache Tools löschen Zeilen, ohne Feld-Prioritäten oder Business-Regeln zu verstehen. Das vernichtet oft wertvolle Daten.
Saubere Deduplication braucht klare Logik: Lege fest, wie Du den Master auswählst, wie Konflikte gelöst werden – und was mit den „zweiten“ Datensätzen passiert.
In diesem Artikel lernst Du praxisnah, wie Du Duplikate in CSVs, Excel-Sheets und CRMs zusammenführst, aktualisierst oder entfernst.
Los geht’s!
📌 Kurzfassung für Eilige
In diesem Artikel lernst Du alles, was Du brauchst, um Deine Spreadsheets sauber zu deduplizieren – inklusive richtigem Mergen, Updaten und Löschen.
Problem: Ohne Priorisierungslogik und Bulk-Actions verlierst Du entweder wichtige Infos oder behältst am Ende die falschen Datensätze.
Lösung: Datablist bietet drei Dedupe-Methoden: simples Mergen/Löschen, AI Editing für komplexe Regeln und Multi-File-Deduplication.
Diese Deduplication-Methoden decken wir ab:
In den nächsten 10 Minuten lernst Du
- Was Datablist ist – und warum wir bei Duplikaten wirklich Ahnung haben
- Was Du über Duplikate wissen solltest, bevor Du Deine Liste scrubbst / deduplizierst
- Die 3 effektivsten Wege, Duplikate zu entfernen (mit Schritt-für-Schritt-Anleitung)
Warum Du uns vertrauen kannst
Datablist ist eine Plattform zum Aufbau von lead generation Workflows, mit der aktuell 26000 Nutzer Daten finden, enrichen und bereinigen – mit über 60 verschiedenen Tools, von AI Agents über Email Finders, AI processors, Technology enrichments und mehr.
Außerdem hat Datablist eine umfangreiche Deduplication-Suite, mit der Du Duplikate in ein paar Klicks mergen, updaten, entfernen oder markieren kannst – ganz ohne Code.
Grundlagen der Deduplication verstehen
Bevor wir in die Praxis gehen, kommen hier die Prinzipien hinter den wichtigsten Deduplication-Techniken.
In diesem Abschnitt geht’s um:
- Kurze Erklärung der Duplikat-Typen
- Grundlagen zum Deduplizieren bei widersprüchlichen Datensätzen
- Fragen, mit denen Du Dein Ziel schneller festlegst
Was Du verstehen musst: Deduplication-Grundlagen
Die folgenden Punkte sind nur für Deduplication innerhalb einer einzelnen Datei relevant. Bei Multi-File Deduplication kannst Du Kopien nur aus bestimmten Dateien entfernen – mergen oder updaten geht dort nicht. Deshalb ist das hier „nice to know“, aber nicht zwingend.
Standardmäßig versucht Datablist, doppelte Datensätze automatisch zu mergen. In der Praxis klappt das nicht immer, weil die meisten Nutzer widersprüchliche Duplikate haben.
Wenn es Konflikte gibt, basiert der Prozess auf zwei Bausteinen:
- Priorisierungslogik, um den Master-Datensatz innerhalb einer Duplikat-Gruppe festzulegen
- Bulk-Actions, um die sekundären Datensätze in dieser Gruppe zu verarbeiten
Duplikat-Typen verstehen
Wir unterscheiden Duplikate danach, wie ähnlich ihre Felder sind.
- Exakte Duplikate: Alle Spalten haben identische Werte. Passiert oft durch doppelten Import oder Copy-Paste.
- Widersprüchliche Duplikate: Es ist dieselbe Entität, aber einzelne Felder (z. B. Telefon, Jobtitel, Umsatz) unterscheiden sich.
- Sich ergänzende Duplikate: Jeder Datensatz enthält andere wertvolle Infos, die zusammengeführt werden sollten. Ein Datensatz hat vielleicht eine E-Mail-Adresse, der andere die Telefonnummer – zusammen ergibt’s ein vollständigeres Profil.

Erstens: Ein Priorisierungsmuster festlegen
Du musst entscheiden, welcher Datensatz als Referenz behalten wird. Das nennen wir die Master Item Rule. Merke Dir den Begriff – Du brauchst ihn gleich.
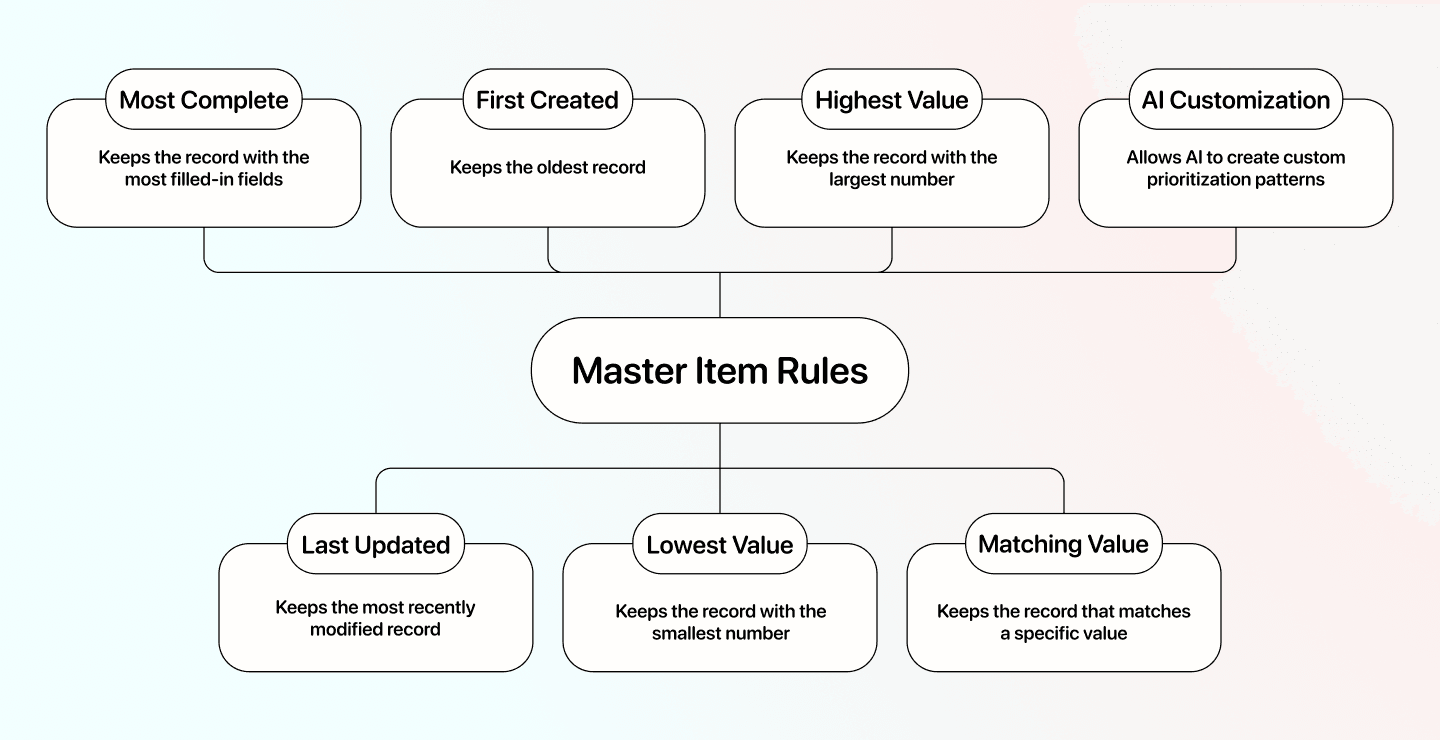
Beispiel-Priorisierungen / Master Item Rules:
- Most complete: Behält den Datensatz mit den meisten ausgefüllten Feldern
- Last updated: Behält den zuletzt bearbeiteten Datensatz
- First created: Behält den ältesten Datensatz
- Lowest value: Behält den Datensatz mit der kleinsten Zahl in einer bestimmten Spalte
- Highest value: Behält den Datensatz mit der größten Zahl in einer bestimmten Spalte
- Matching value: Behält den Datensatz, der auf einer von Dir definierten Eigenschaft einen bestimmten Wert matcht
📘 Master Item Rules
Wichtig: „Last updated“ und „First created“ sind nur sinnvoll, wenn Deine Daten über Zeit in Datablist gepflegt wurden. Wenn Du gerade erst eine Datei hochgeladen hast, funktionieren diese Optionen nicht, weil importierte Spreadsheets diese Metadaten nicht enthalten.
Wenn Du unsicher bist, empfehlen wir „Most complete“ oder die Technik aus dem zweiten Teil der Schritt-für-Schritt-Sektion.
Für komplexere Fälle kannst Du in Datablist AI nutzen, um eigene Priorisierungslogiken zu bauen – z. B. wenn Spalte A „Hello people“ enthält und Spalte B „of Germany“.
Mehr dazu im zweiten Teil der Schritt-für-Schritt-Anleitung.
Zweitens: Eine Bulk-Action auswählen
Wenn Du die Priorisierung festgelegt hast, kommt der nächste Schritt: Was soll mit den Datensätzen passieren, die nicht „gewinnen“?
Beispiele für Bulk-Actions zur Duplikat-Verarbeitung:
- Sekundäre Items löschen
- Master Item und sekundäres Item zu einem Datensatz mergen
- Ausgewählte Felder des sekundären Items in den Master übernehmen und den Rest löschen
- Ausgewählte Felder des Master Items mit Werten aus dem sekundären Item updaten
- Duplikate markieren, ohne sie zu löschen (besonders relevant in großen Organisationen, wenn Du z. B. aus Compliance-Gründen alles nachvollziehbar behalten musst)
- … und alles, was Du sonst noch brauchst
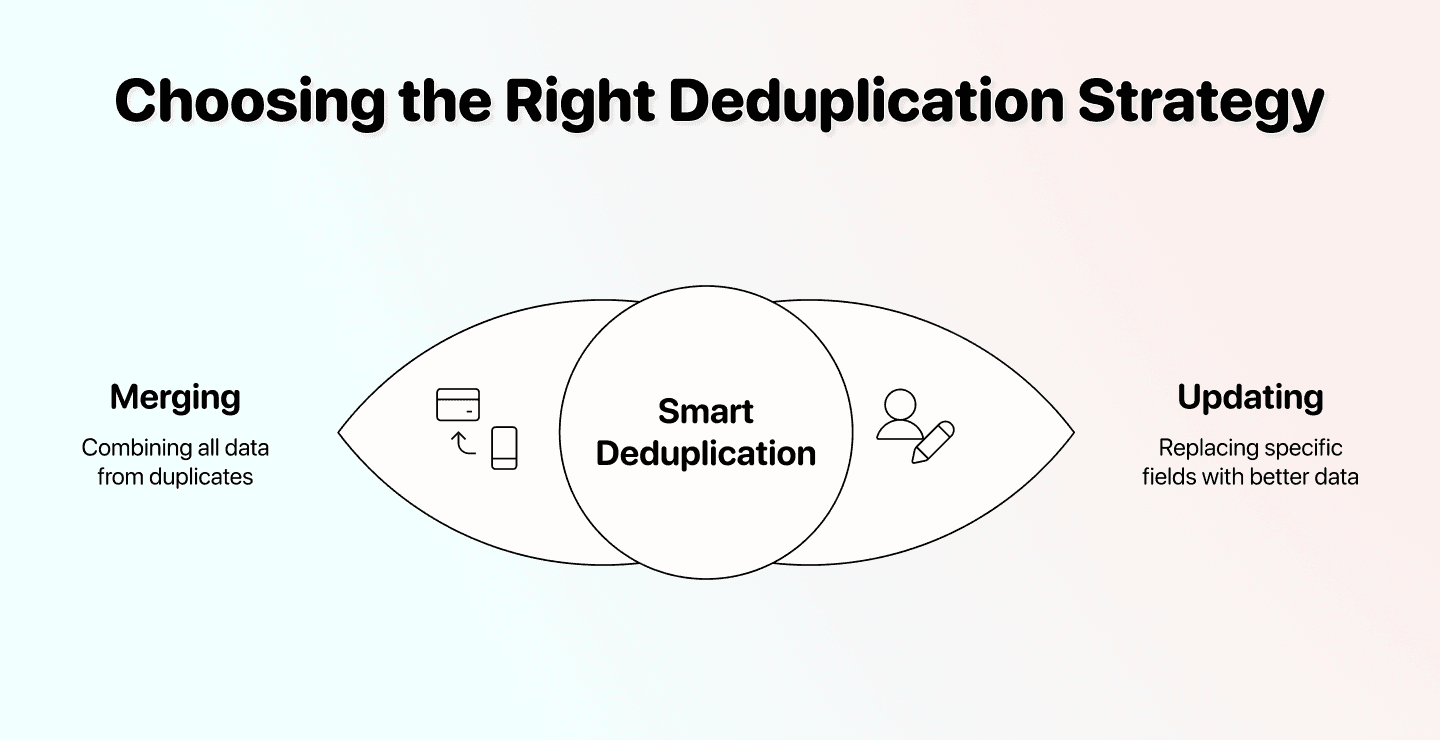
📘 Duplikate mergen vs. Duplikate updaten
Mergen heißt: Werte aus beiden Datensätzen zusammenführen. Das ist super bei doppelten CRM-Kontakten, wenn z. B. in beiden Datensätzen Notizen stehen.
Updaten heißt: bestimmte Werte durch bessere Daten aus einer anderen Quelle ersetzen. Nutze das, wenn jede Kopie teilweise korrekt ist – z. B. Kontakt A behalten, aber den Jobtitel mit dem korrekten Jobtitel aus Kontakt B ersetzen.
Fragen, die Du Dir vor der Deduplication stellen solltest
Jetzt kennst Du Priorisierung und Bulk-Actions. Mit den folgenden Fragen findest Du schnell heraus, welche Regel und welche Aktion Du brauchst.
Welcher Datensatz soll Dein Master Item sein?
Diese Frage hilft Dir beim Priorisierungsmuster. Überleg: Was macht ein Duplikat „besser“ als das andere?
Frag Dich:
- Ist ein Datensatz deutlich vollständiger als die anderen?
- Kommt ein Datensatz aus einer zuverlässigeren Quelle?
- Ist ein Datensatz neuer oder kürzlich aktualisiert?
- Hat ein Datensatz einen bestimmten Wert, der ihn zur „richtigen“ Version macht?
Deine Antwort bestimmt die Master Item Rule:
- Wenn Vollständigkeit am wichtigsten ist → „Most complete“
- Wenn Aktualität am wichtigsten ist → „Last updated“ oder „First created“
- Wenn ein bestimmter Wert entscheidet → „Matching value“
- Wenn die Logik komplexer ist → AI Editing (Methode 2)
Was soll mit den Nicht-Master-Datensätzen passieren?
Diese Frage bestimmt Deine Bulk-Action. Wenn ein Gewinner feststeht: Was passiert mit den übrigen?
Frag Dich:
- Steckt in den anderen Datensätzen noch etwas Wertvolles?
- Soll ich Infos aus mehreren Datensätzen in einem zusammenführen?
- Will ich die Extras einfach löschen und weitermachen?
- Muss ich Duplikate lieber markieren, statt sie zu löschen?
Deine Antwort bestimmt die Bulk-Action:
- Wenn die anderen Datensätze keinen Wert haben → konfliktierende Werte droppen / löschen
- Wenn die anderen Datensätze nützliche Infos haben → konfliktierende Werte kombinieren oder den Master updaten
- Wenn Du Compliance-Records brauchst → Duplikate markieren statt löschen
- Wenn Du gezielt einzelne Werte übernehmen willst → AI Editing (Methode 2)
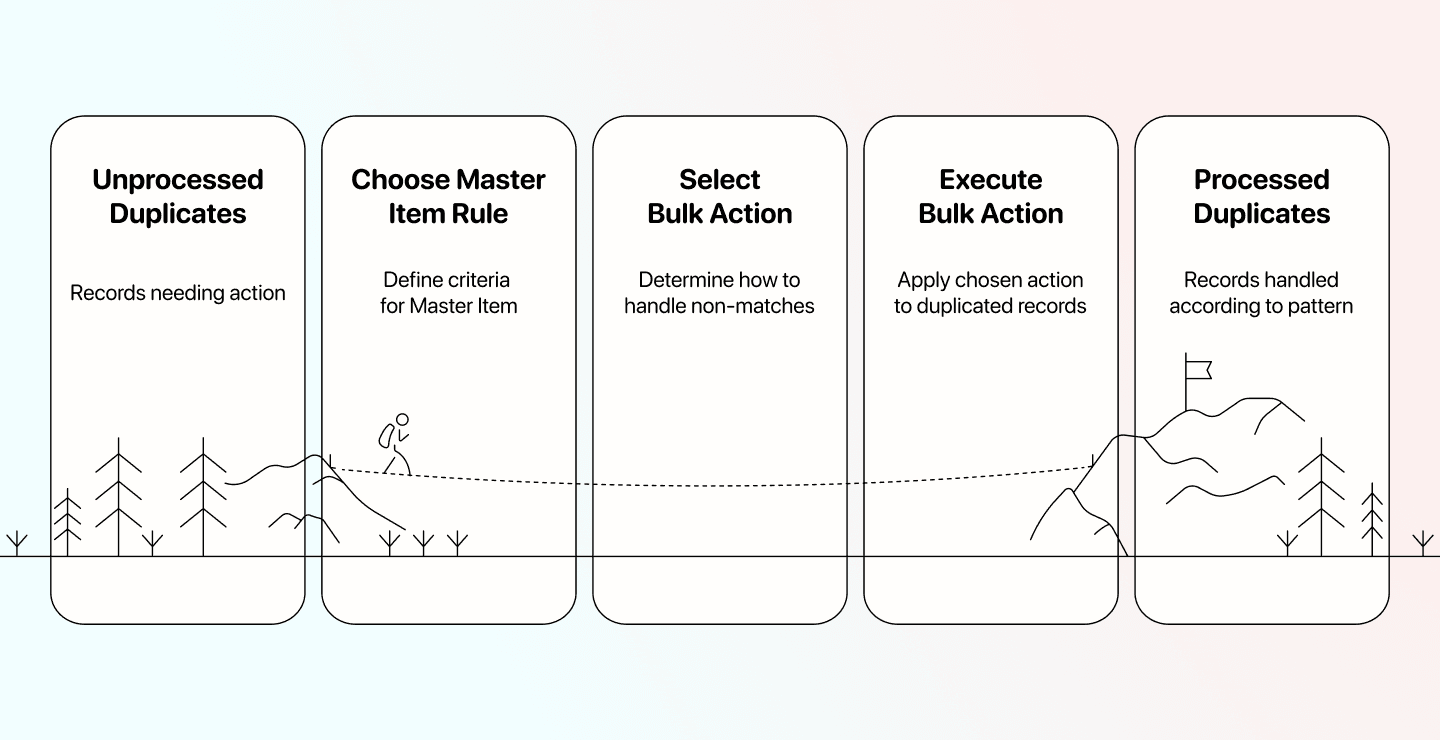
Deduplication: Duplikate aus Deinen Daten entfernen
Datablist hat eine Deduplication-Suite, die alles abdeckt – von einfachem Duplikate-Löschen bis hin zu Multi-File Deduplication. Deshalb zeigen wir Dir jetzt 3 Workflows:
- Duplikate in einer Datei mergen und entfernen (einfache Regeln)
- Duplikate in einer Datei updaten und entfernen (komplexe Regeln)
- Duplikate über mehrere Dateien hinweg entfernen; kein Mergen möglich
Los geht’s!
Wie Datablist Duplikate verarbeitet – kurzer Überblick
Wenn Du den letzten Abschnitt gelesen hast, kannst Du das überspringen; wenn nicht, hier die Kurzversion, damit Du genau weißt, was Du gleich machst.
- Datablist scannt Deine Daten und findet Zeilen, die in den Spalten matchen, die Du auswählst.
- Bei exakten Matches kannst Du automatisch mergen.
- Bei widersprüchlichen Duplikaten wählst Du eine Logik, nach der ein Datensatz priorisiert wird (die „Master Item Rule“).
- Danach kannst Du die zweite Kopie mergen, updaten, markieren oder löschen.
Einfaches Mergen und Entfernen von Duplikaten in einer Datei
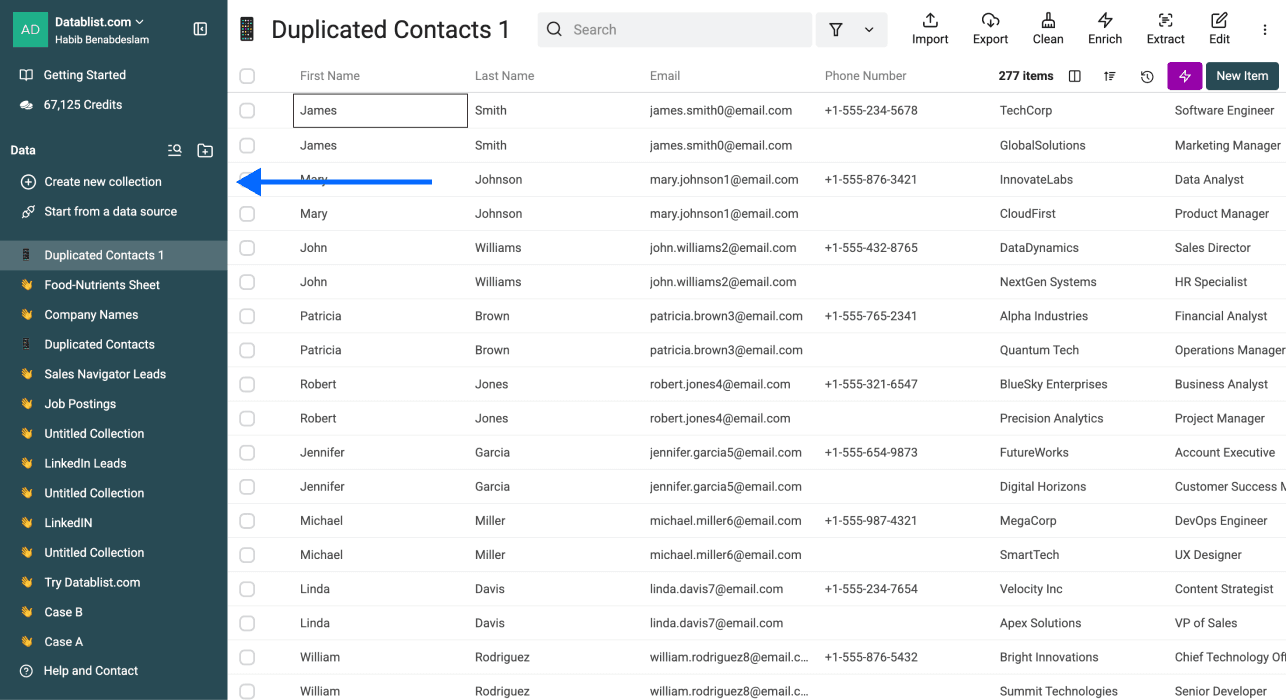
Das ist der schnellste Weg, Duplikate loszuwerden: Du hast eine Liste, in der Einträge mehrfach vorkommen, und willst pro Datensatz nur eine Version behalten.
Wann es sinnvoll ist:
- Du hast aus Versehen dieselbe CSV zweimal importiert
- Dein CRM-Export enthält doppelte Kontakte
- Gescrapte Daten haben durch Pagination-Fehler wiederholte Einträge
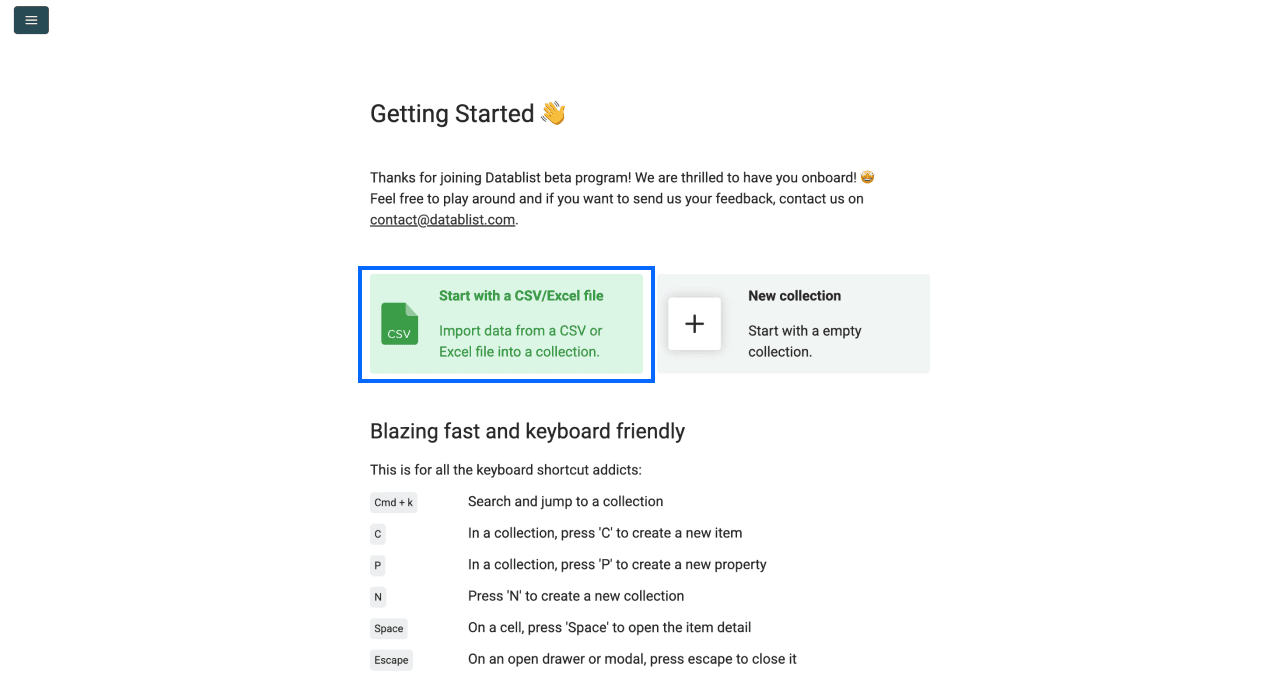
Schritt 1: Registrieren und Daten hochladen
- Registriere Dich bei Datablist
- Upload Deine CSV oder Excel
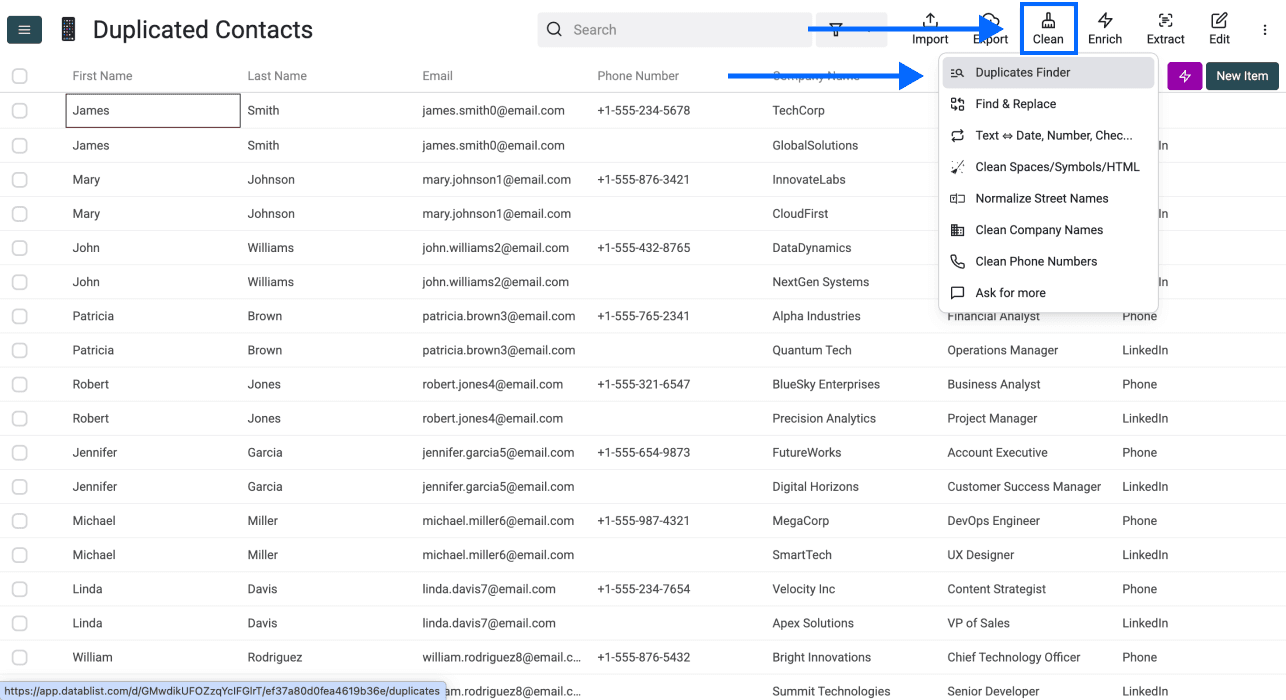
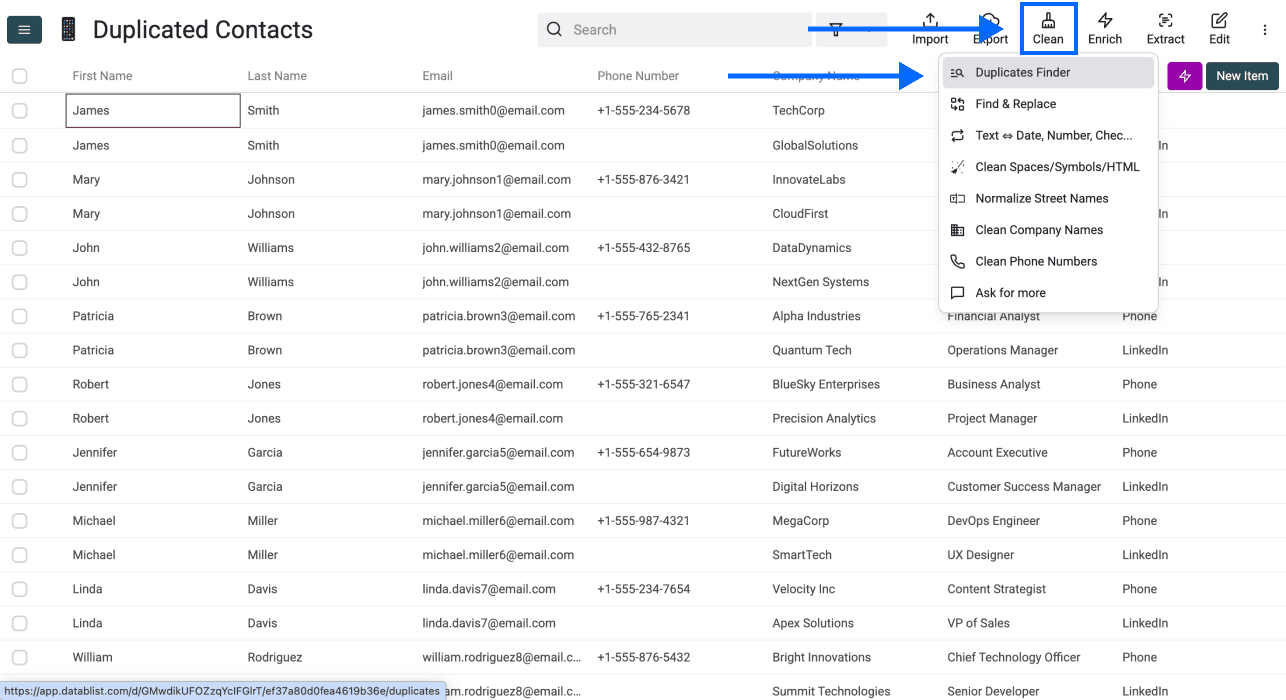
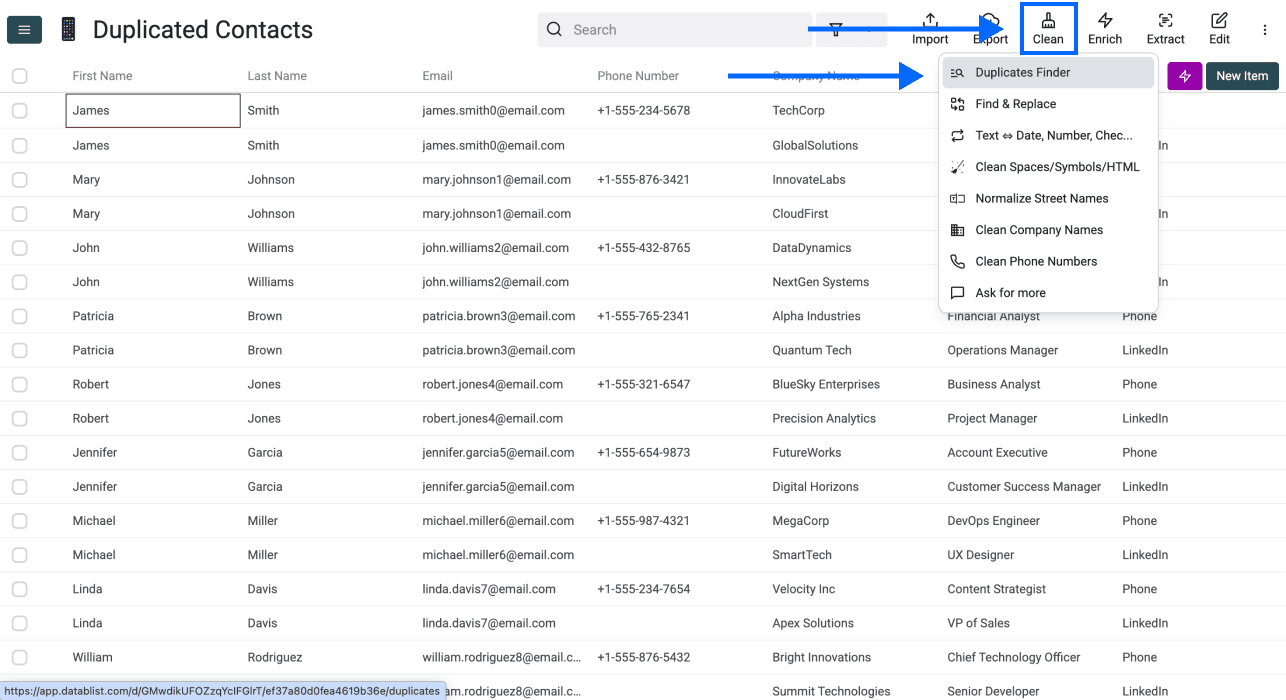
Schritt 2: Zum Duplicates Finder wechseln
Klicke im Top-Menü auf Clean und wähle Duplicates Finder
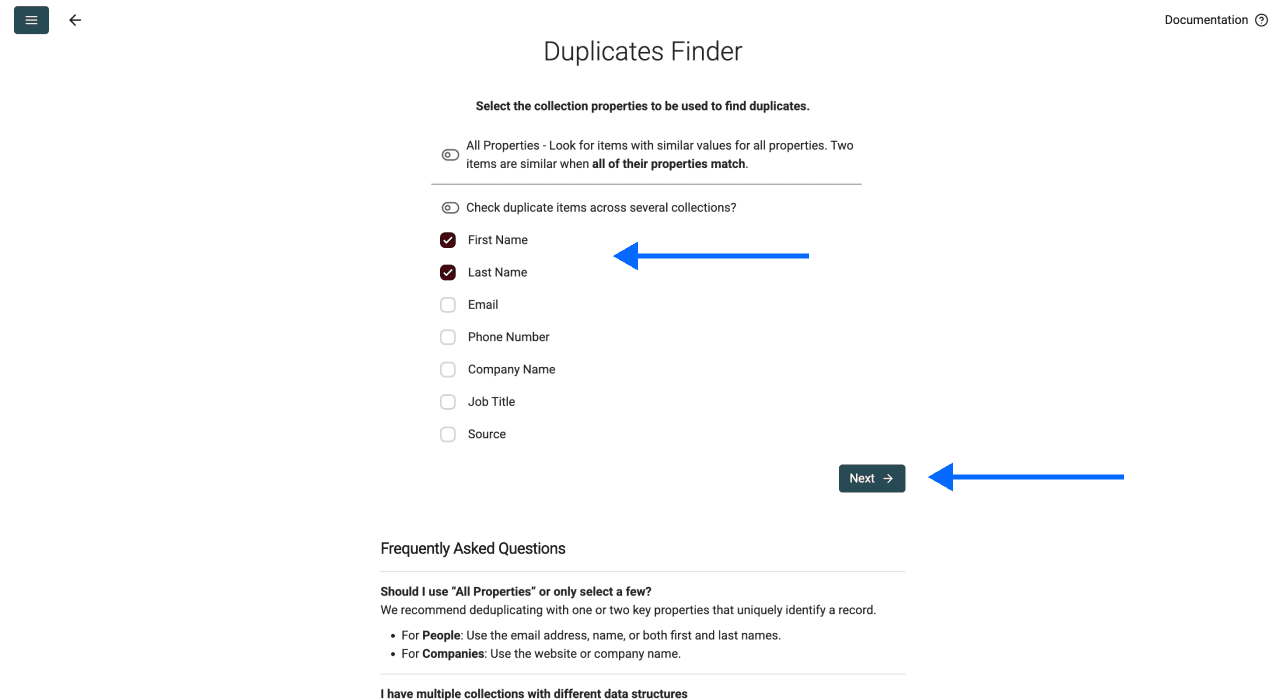
Schritt 3: Unique Identifier auswählen
In diesem Schritt hast Du zwei Optionen:
Option 1: Eine oder mehrere Spalten als Unique Identifier wählen – EMPFOHLEN
Ein Unique Identifier ist die Info, die einen Datensatz eindeutig macht. Zum Beispiel:
- Eine Spalte: Wenn Du „Email“ auswählst, gilt john@example.com als eindeutig – selbst wenn alles andere matcht
- Mehrere Spalten: Wenn Du „First Name“ + „Company“ kombinierst, ist „John“ bei „Microsoft“ etwas anderes als „John“ bei „Google“
Je mehr Spalten Du auswählst, desto strenger wird das Matching. Starte am besten mit einer oder zwei Spalten, die Deine Datensätze wirklich eindeutig identifizieren.
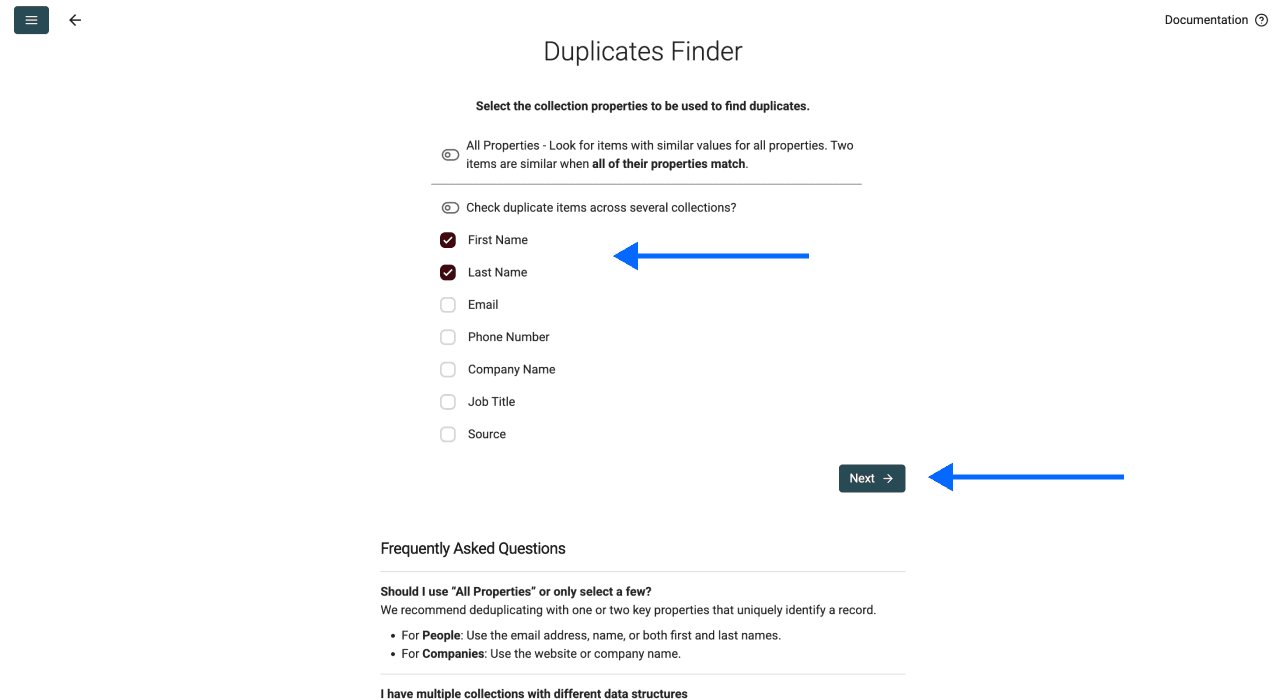
Option 2: Nach allen Properties deduplizieren – NICHT EMPFOHLEN
Diese Option prüft, ob jede einzelne Spalte einer Zeile exakt mit einer anderen Zeile übereinstimmt. Zwei Zeilen gelten also nur dann als Duplikate, wenn alle Daten identisch sind.
Warum wir das nicht empfehlen: In echten Datensätzen matchen Duplikate fast nie in allen Spalten perfekt. Eine Person hat z. B. leicht unterschiedliche Jobtitel – oder ein Unternehmen verschiedene Mitarbeiterzahlen je nach Quelle. Mit dieser Option übersiehst Du die meisten Duplikate.
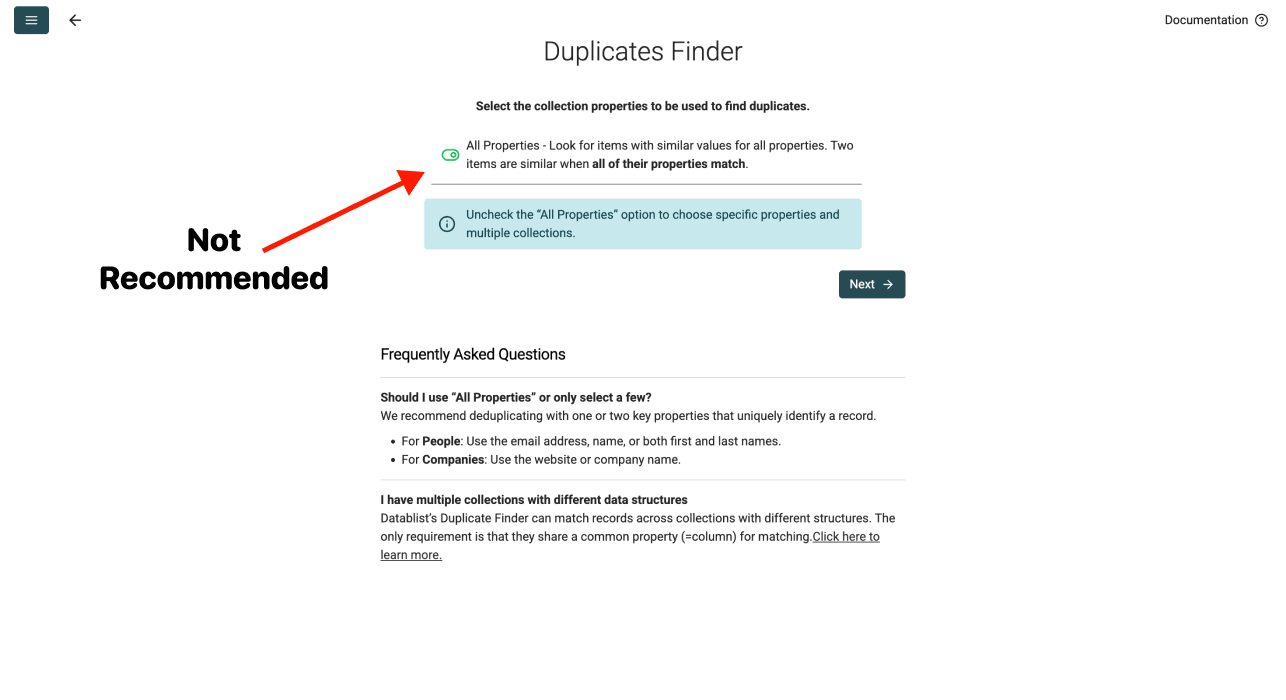
Wann Option 2 trotzdem Sinn macht: Wenn Du wirklich nur exakte Zeilen-Duplikate finden willst, die versehentlich doppelt importiert wurden.
Wenn Du Deine Properties ausgewählt hast, scrolle runter und klicke auf Next
Schritt 4: Comparison Algorithm auswählen
Hier wählst Du pro Property einen Vergleichsalgorithmus und einen Processor. Wir empfehlen, die Default-Einstellungen zu lassen – außer bei Firmennamen.
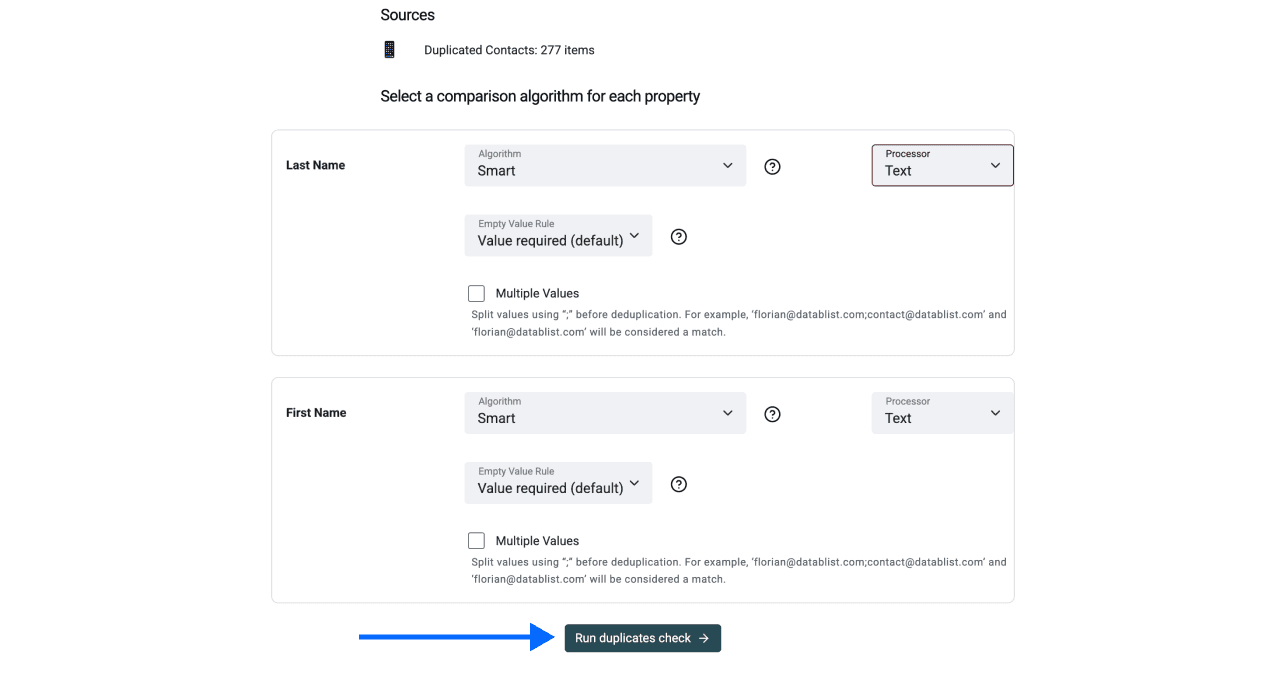
Wenn Du nach Firmennamen deduplizierst: Wähle den Firmennamen-Processor, weil Datablist das als einziges nicht automatisch erkennen kann.
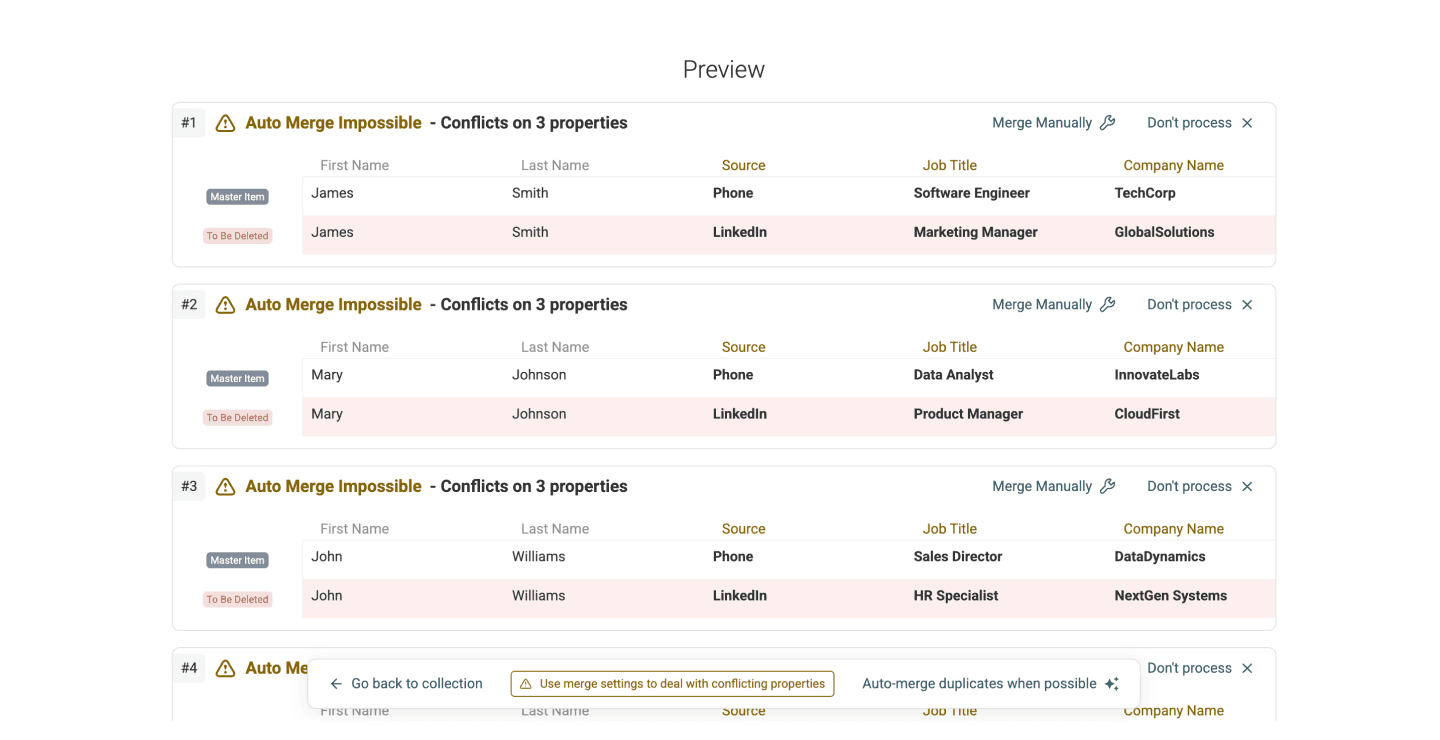
Schritt 5: Master Item wählen, prüfen und Konflikte lösen
- Master Item Rule auswählen: Wie im ersten Abschnitt erklärt, bittet Dich Datablist immer um eine Master Item Rule. Default ist „Most Complete“, Du kannst aber auch eine andere wählen.
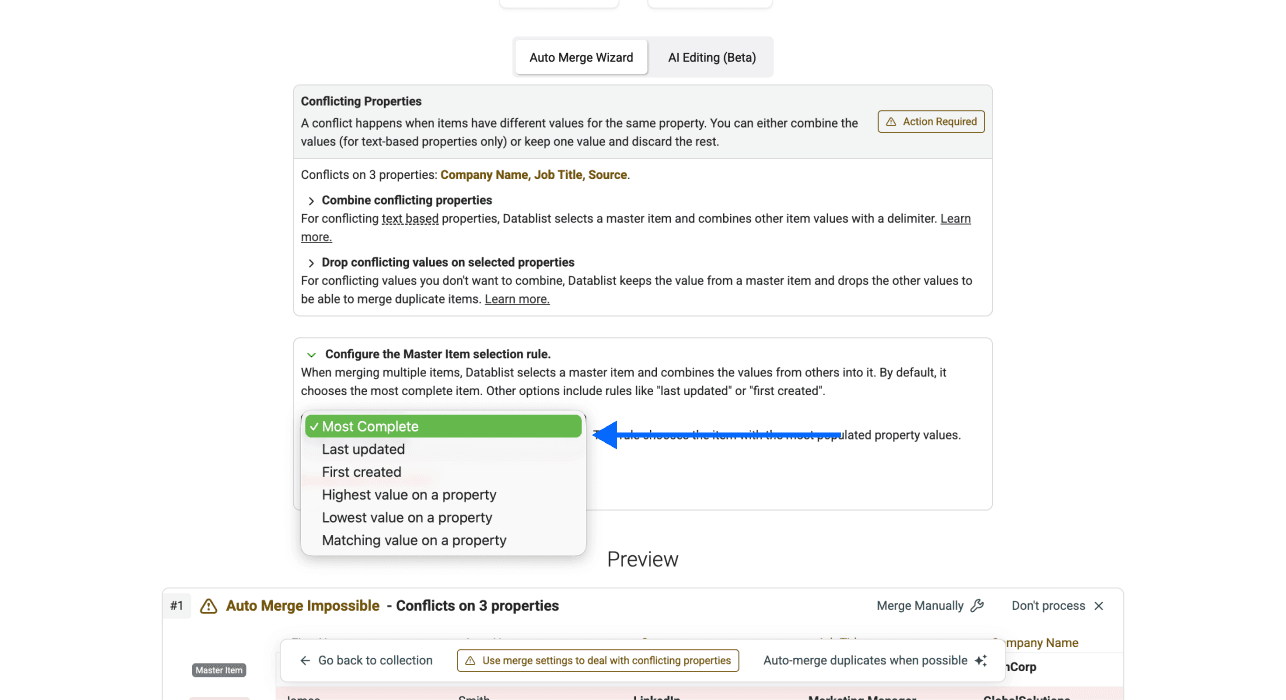
-
Falls nötig: Konflikte prüfen und lösen. Häufig sind Duplikate nicht in allen Properties identisch – genau deshalb brauchst Du eine Master Item Rule.
Zum Lösen kannst Du entweder Werte kombinieren oder konfliktierende Werte droppen. Kombinieren funktioniert allerdings nur bei Textfeldern. Bei Zahlen, Datum/Uhrzeit etc. brauchst Du meist eine Kombination aus beiden Regeln: kombinieren und droppen.
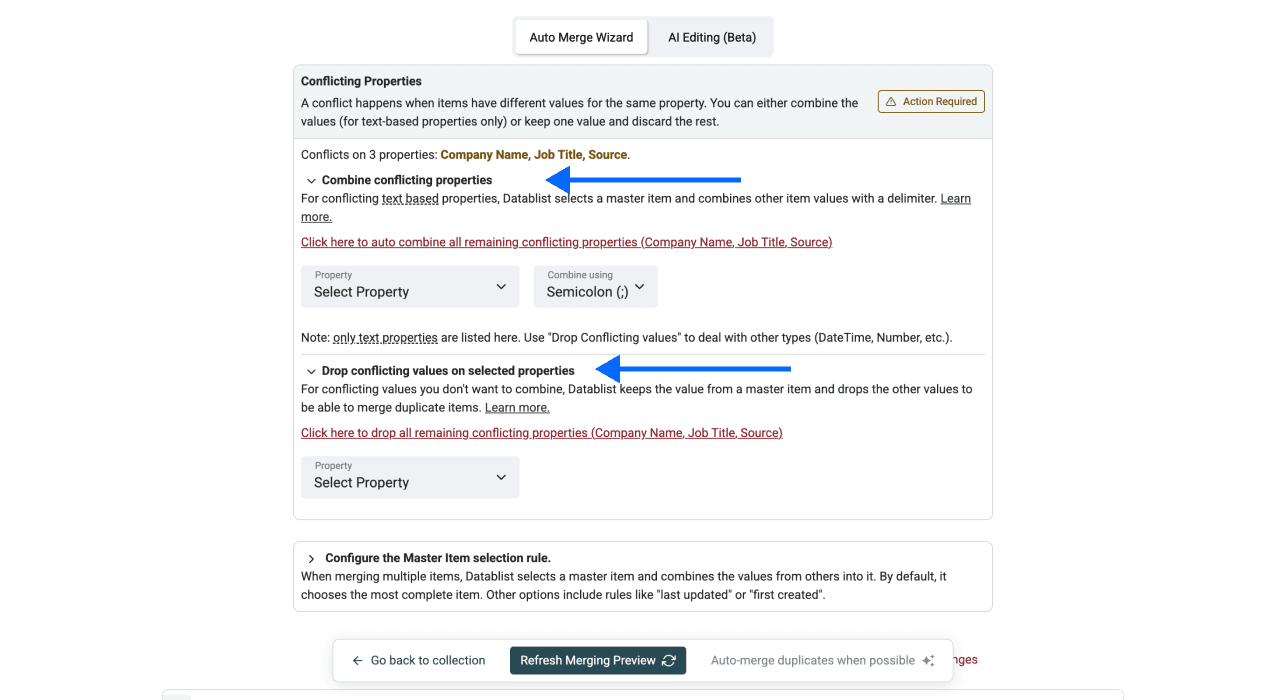
- Klicke auf Refresh Merging Preview, um die geplanten Änderungen zu sehen
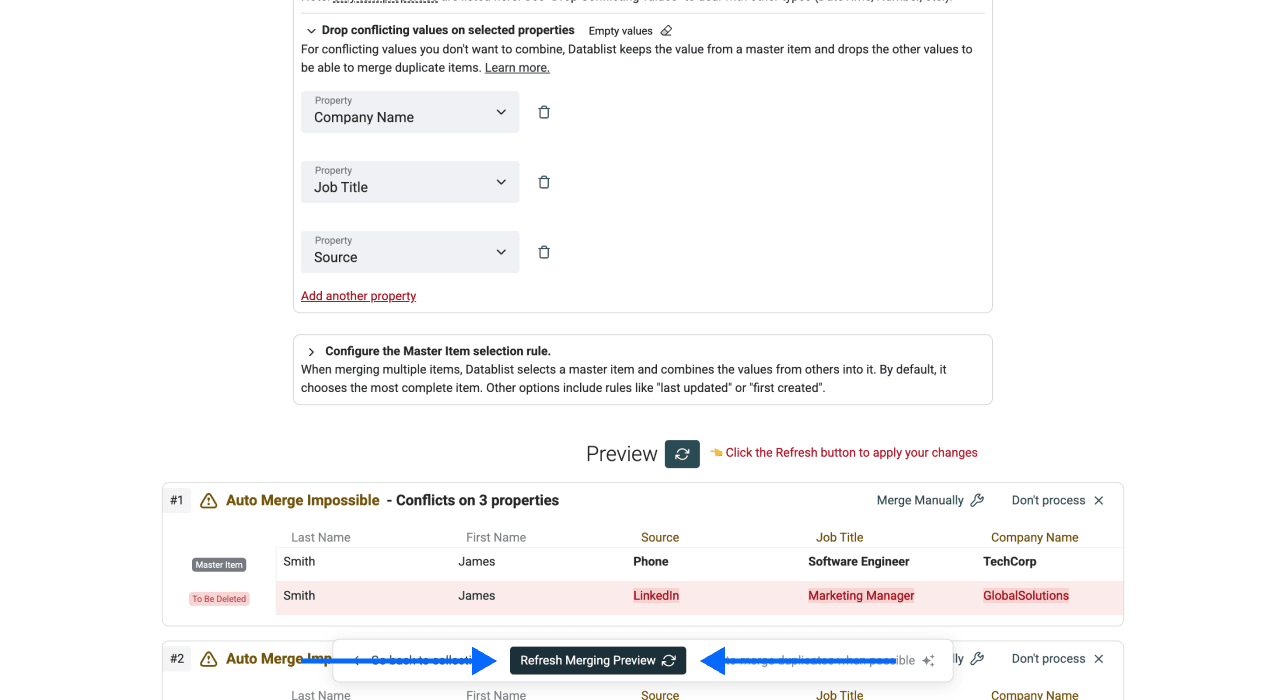
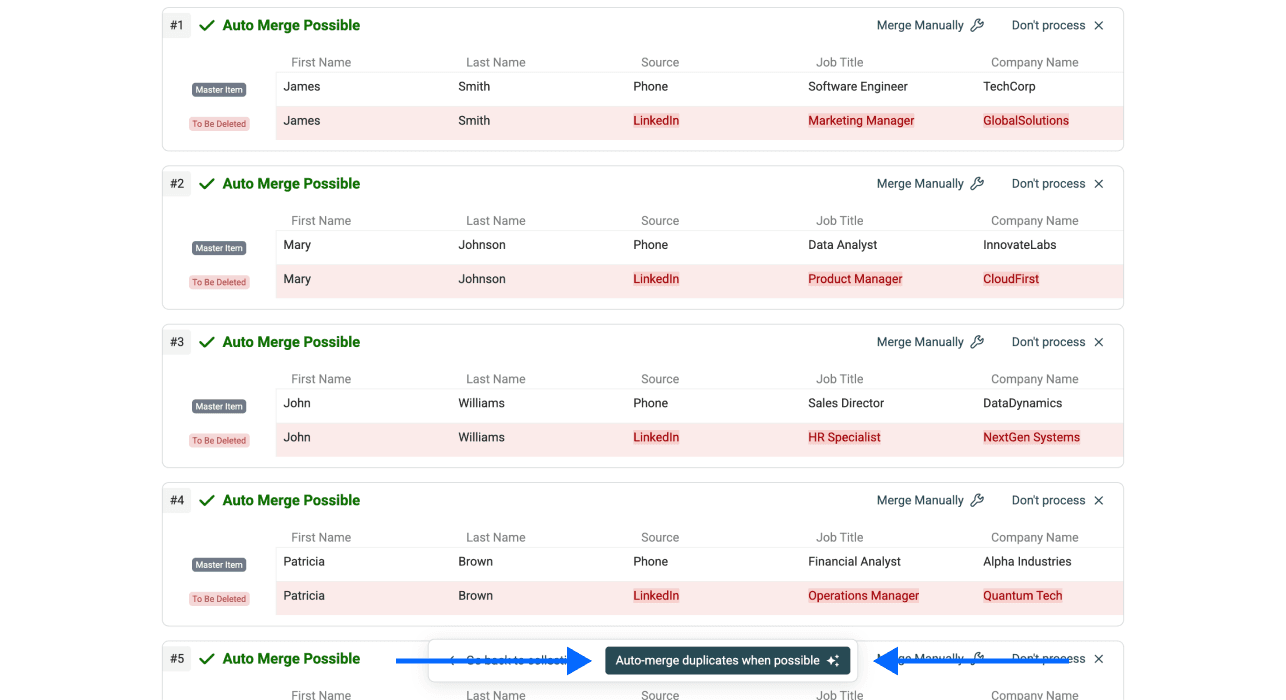
Schritt 6: Ausführen und Ergebnis prüfen
Jetzt musst Du nur noch auf Auto-merge when possible klicken.
Nach dem Mergen kannst Du die Änderungen als CSV herunterladen. Die Datei enthält:
- Alle Duplikate aus Deiner Datei
- Die Datensätze, in die gemerged wurde
- Die vorgenommenen Änderungen
- Die Datablist Record ID
Der Download ist optional.
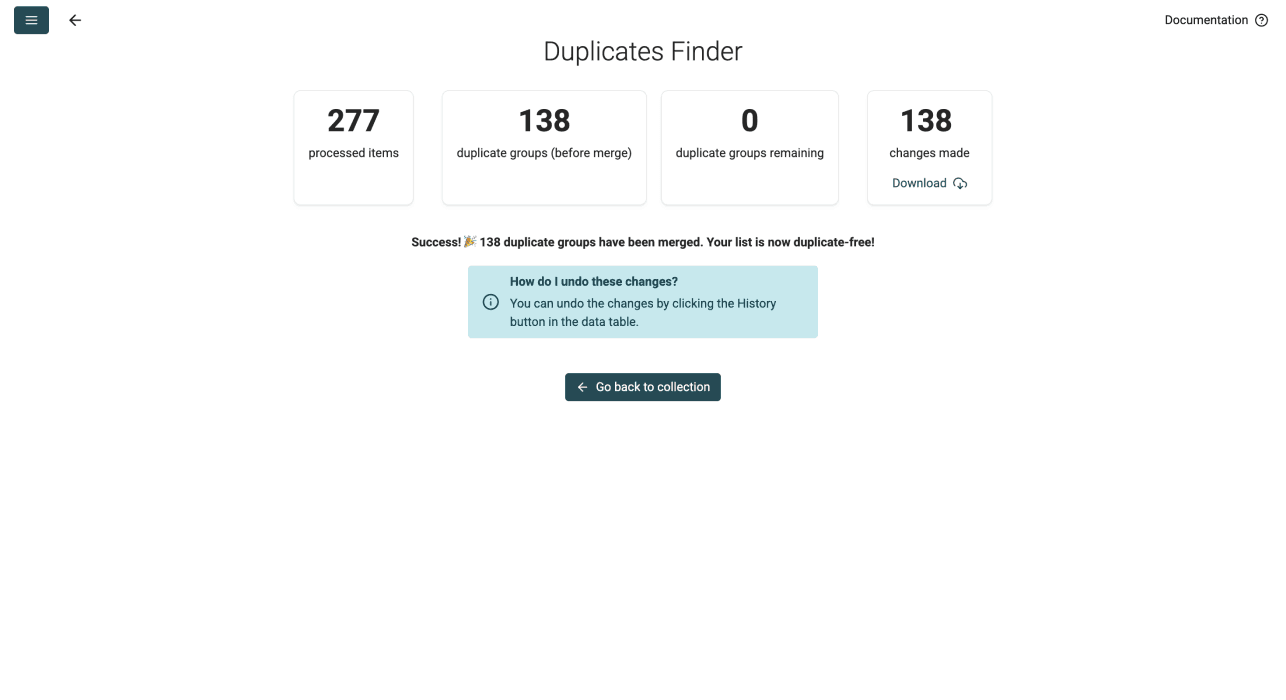
💡 Wenn Du Dich irgendwo vertan hast
Du kannst die Änderungen auch rückgängig machen: Klicke auf den History-Button und undo die Aktionen, nachdem Du zurück in die Spreadsheet-Ansicht gewechselt bist.
Duplikate vor dem Löschen bearbeiten
Manchmal reichen einfache Master Item Rules nicht. Was, wenn Du die Telefonnummer aus Datensatz A behalten willst – aber den Jobtitel aus Datensatz B? Genau dafür gibt es AI Editing.
So funktioniert’s: Statt eine vordefinierte Regel zu wählen, beschreibst Du in normalem Englisch, was passieren soll. Datablists AI liest Deine Anweisungen, erzeugt ein Script und wendet Deine Logik auf jede Duplikat-Gruppe an.
Wann es sinnvoll ist:
- Du hast Kontakte aus mehreren Quellen (CRM, LinkedIn, Telefonlisten) und willst die besten Daten je Quelle kombinieren
- Deine Duplikate haben unterschiedliche Felder ausgefüllt und Du willst gezielt Werte übernehmen
- Du brauchst eigene Logik, die nicht in die Standard-Master-Rules passt
- Du willst Datensätze vor dem Löschen updaten – nicht nur „einen Gewinner“ wählen
- Du willst Duplikate aus Compliance-Gründen markieren statt löschen
Schritt 1: Registrieren und Daten hochladen
- Registriere Dich bei Datablist
- Upload Deine CSV oder Excel
Schritt 2: Zum Duplicates Finder wechseln
Klicke im Top-Menü auf Clean und wähle Duplicates Finder
Schritt 3: Unique Identifier auswählen
Wähle die Spalte(n), die Du zum Matching verwenden willst. Danach scrolle runter und klicke auf Next
Schritt 4: Comparison Algorithm auswählen
Wähle pro Property einen Vergleichsalgorithmus und Processor. Wir empfehlen, die Default-Einstellungen zu lassen – außer bei Firmennamen.
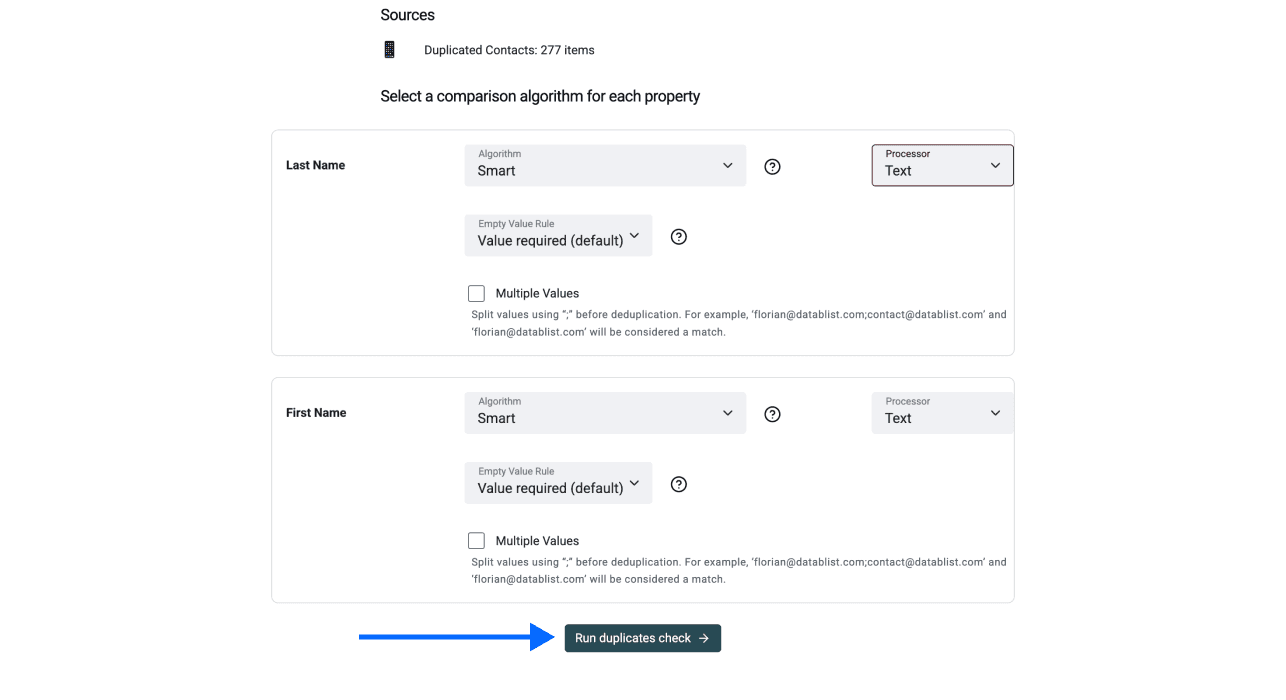
Schritt 5: AI Editing öffnen
Statt eine Master Item Rule auszuwählen, klicke im Deduplication-Panel auf AI Editing.
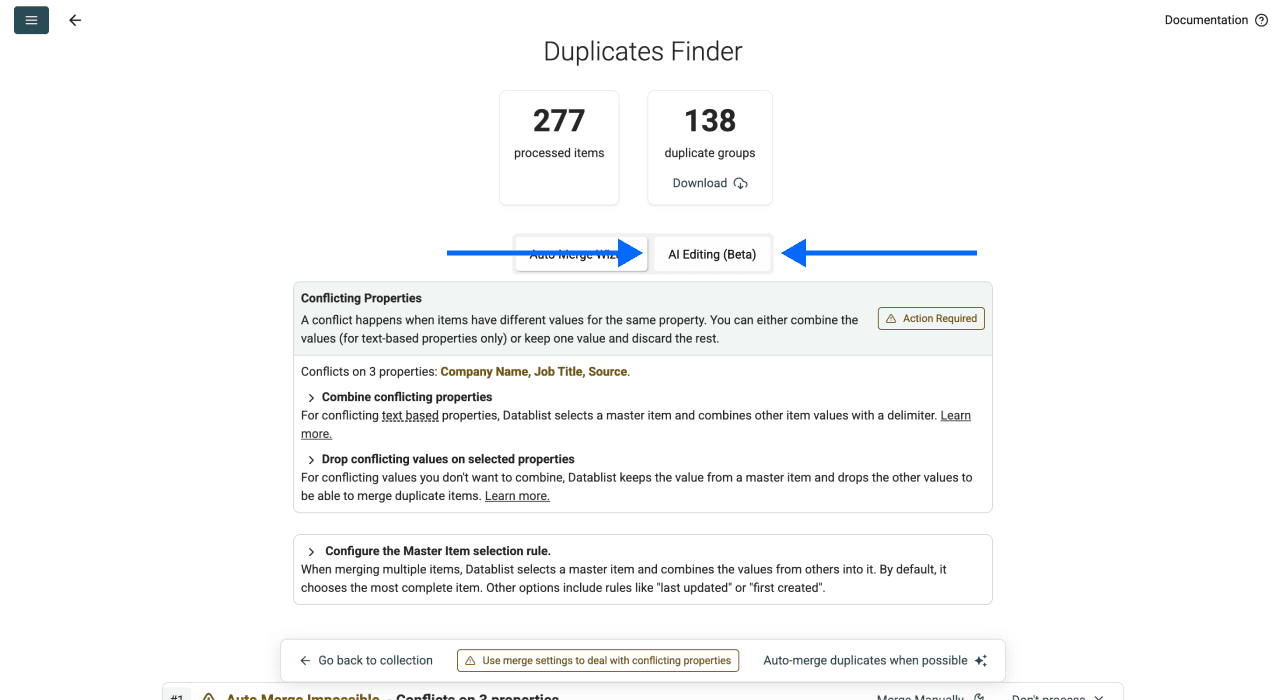
Schritt 6: Deinen Prompt schreiben
Beschreibe, was Du willst – in normalem Englisch. Hier ein praxisnahes Beispiel:
Angenommen, Du hast Kontaktdaten aus zwei Quellen: Telefon-Verifizierung und LinkedIn-Scraping. Die Telefon-Datensätze haben verifizierte Nummern, aber LinkedIn hat aktuellere Jobtitel und Firmennamen. Du willst den Telefon-Datensatz als Master behalten, ihn aber mit LinkedIn-Daten updaten.
Das ist der Prompt, den ich genutzt habe:
Select the records with "Phone" as source as master item and update them with the job title and company name from the record with the "LinkedIn" as source.
The source: /source
The job title: /job title
The company name: /company
Delete the second item when finished
Hinweis: Vergiss nicht, Deine Properties im Prompt mit / zu mappen.
Klicke auf Generate and preview changes, wenn Du ready bist.

Schritt 7: Änderungen prüfen und anwenden
Datablist zeigt Dir genau, welche Änderungen die AI vornehmen wird – bevor etwas angewendet wird. Check die Preview und stell sicher, dass es zu Deinem Ziel passt.
Wenn alles passt, klicke auf Run AI Script, um die Logik auf alle Duplikat-Gruppen anzuwenden. Danach exportierst Du Deine bereinigten Daten.
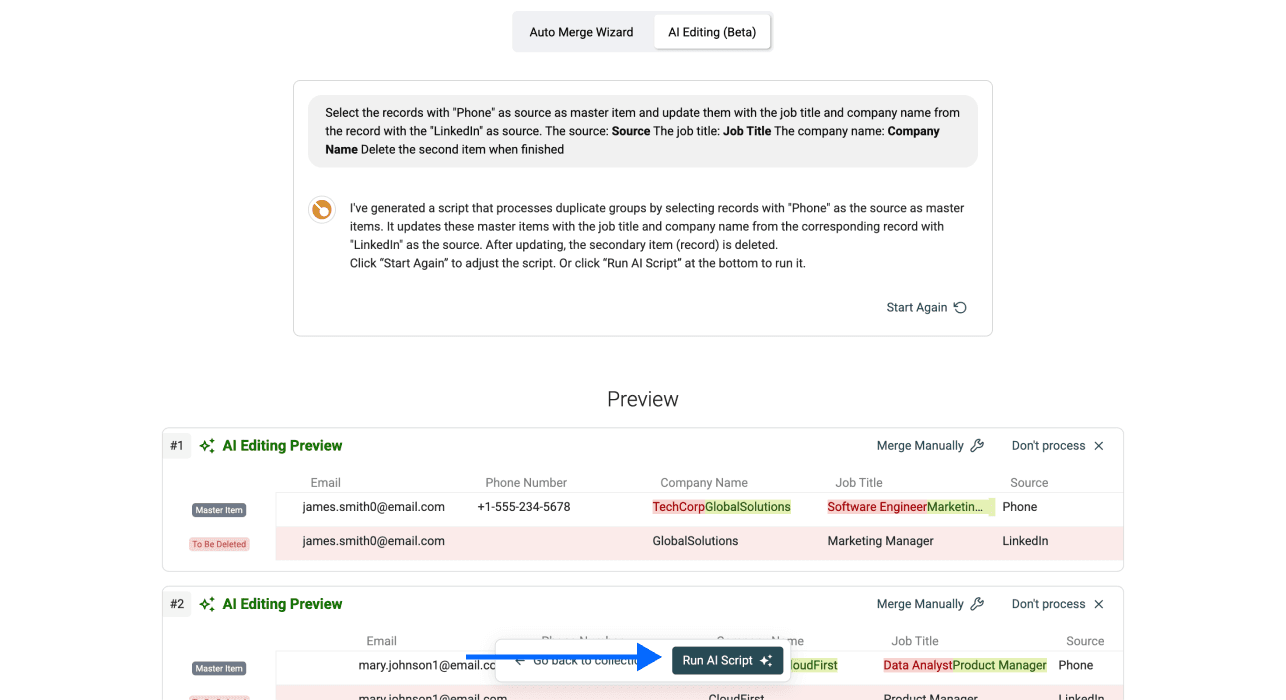
💡 Prompt-Tipps für bessere Ergebnisse
Sei so konkret wie möglich. Je klarer Du beschreibst, was passieren soll, desto besser wird das Ergebnis.
Damit kannst Du auch:
- Duplikate markieren statt löschen: Prompt z. B. „Add 'DUPLICATE' to the status column for all non-master items instead of deleting them“
- Textfelder zusammenführen: „Merge all notes from duplicate records into the master item's notes field, separated by line breaks“
- Nach Quell-Qualität priorisieren: „Use Salesforce records as master when available, otherwise use HubSpot, then spreadsheet imports“
- … oder alles andere, was Dir einfällt.
Duplikate über zwei oder mehr Sheets hinweg entfernen
Wenn Du zwei verschiedene CSVs hast und Datensätze finden willst, die in beiden vorkommen – oder eine neue lead list gegen Deinen bestehenden CRM-Export deduplizieren möchtest – macht Datablist es Dir leicht.
So funktioniert’s: Anders als bei Deduplication in einer Datei vergleicht dieser Workflow Datensätze über mehrere Dateien hinweg und entfernt Duplikate, die aus unterschiedlichen Quellen stammen. Du kannst zwei oder mehr Dateien auswählen – ohne Limit.
Wann es sinnvoll ist:
- Du importierst neue Leads und willst Duplikate zu bestehenden Kontakten vermeiden
- Du führst Daten aus mehreren Vendors oder Quellen zusammen
- Du willst die Überschneidung zwischen zwei Kundenlisten finden
- Du willst verhindern, dass Du denselben Prospect zweimal kontaktierst
- Du musst Kundendaten aus verschiedenen Teams/Standorten konsolidieren
- … und für viele weitere data cleaning Workflows
📘 Wichtiger Unterschied zur Single-File Deduplication
Bei Deduplication über mehrere Dateien entfernt Datablist Duplikate vollständig – statt sie zu mergen.
Schritt 1: Registrieren und Dateien hochladen
- Registriere Dich bei Datablist
- Import Deine erste CSV oder Excel
- Import Deine zweite Datei in eine andere Collection (und alle weiteren Dateien, über die Du deduplizieren willst)
- Stell sicher, dass Du einen Unique Identifier hast
Bevor Du weitermachst, prüfe, ob alle Dateien mindestens eine gemeinsame Spalte haben, die als Unique Identifier taugt. Das kann sein:
- E-Mail-Adresse
- LinkedIn URL
- Company domain
- Telefonnummer
- jedes andere Feld, das einen Datensatz eindeutig identifiziert
Schritt 2: Zum Duplicates Finder wechseln
Klicke im Top-Menü auf Clean und wähle Duplicates Finder
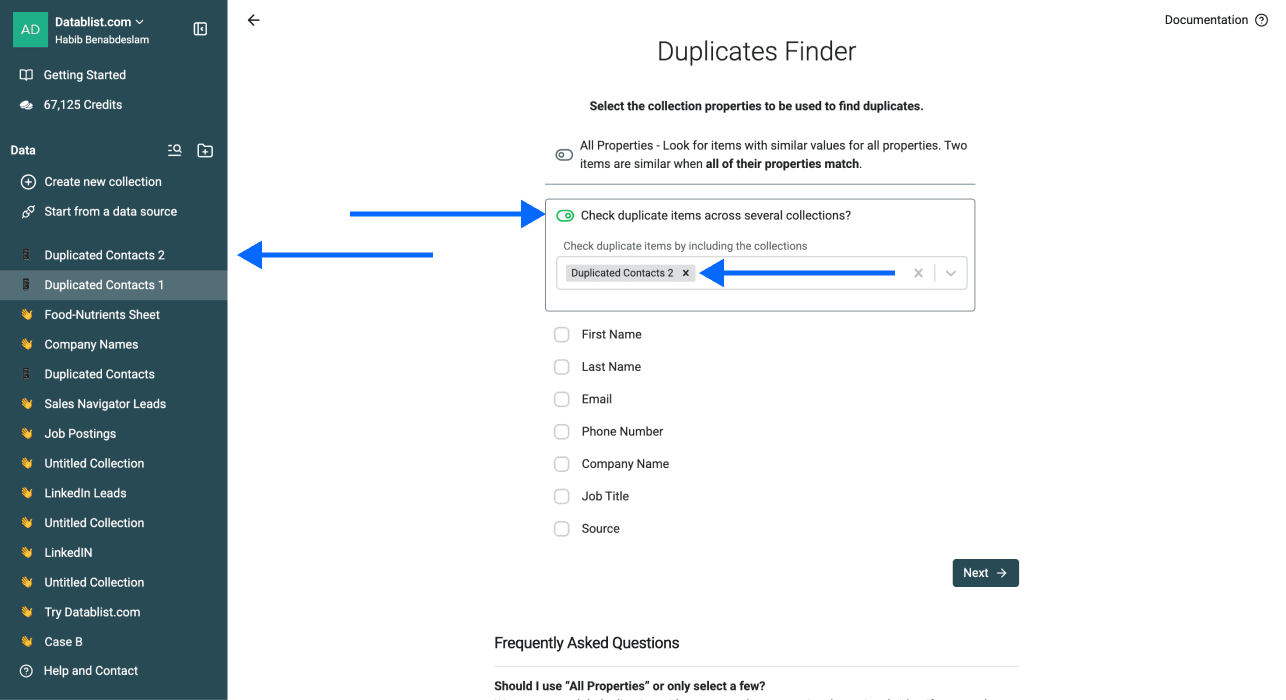
Schritt 3: Multi-Collection Deduplication aktivieren
- Aktiviere Check Duplicate Items Across Several Collections
- Wähle die Collection(s) / Datei(en), die Du gerade importiert hast
Schritt 4: Unique Identifier Property auswählen
Wähle die Property, über die Du Duplikate zwischen Dateien matchen willst. Du kannst mehrere Properties wählen – aber stell sicher, dass alle Dateien diese Properties enthalten, damit das Ergebnis sauber bleibt.
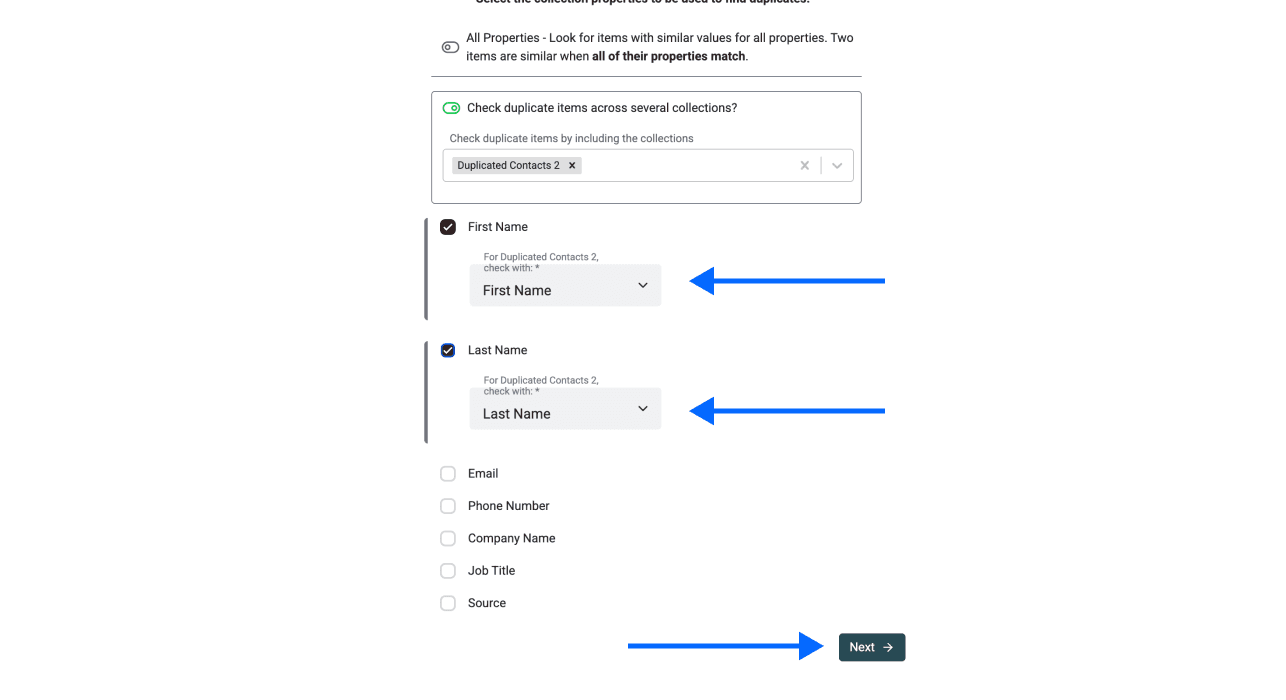
Schritt 5: Comparison Algorithm auswählen
Wähle den Vergleich, der zu Deinen Daten passt:
- Exact: Ideal für URLs, Domains oder IDs, wo es 100% exakt sein muss
- Smart: Ideal für Textfelder, bei denen kleine Abweichungen vorkommen
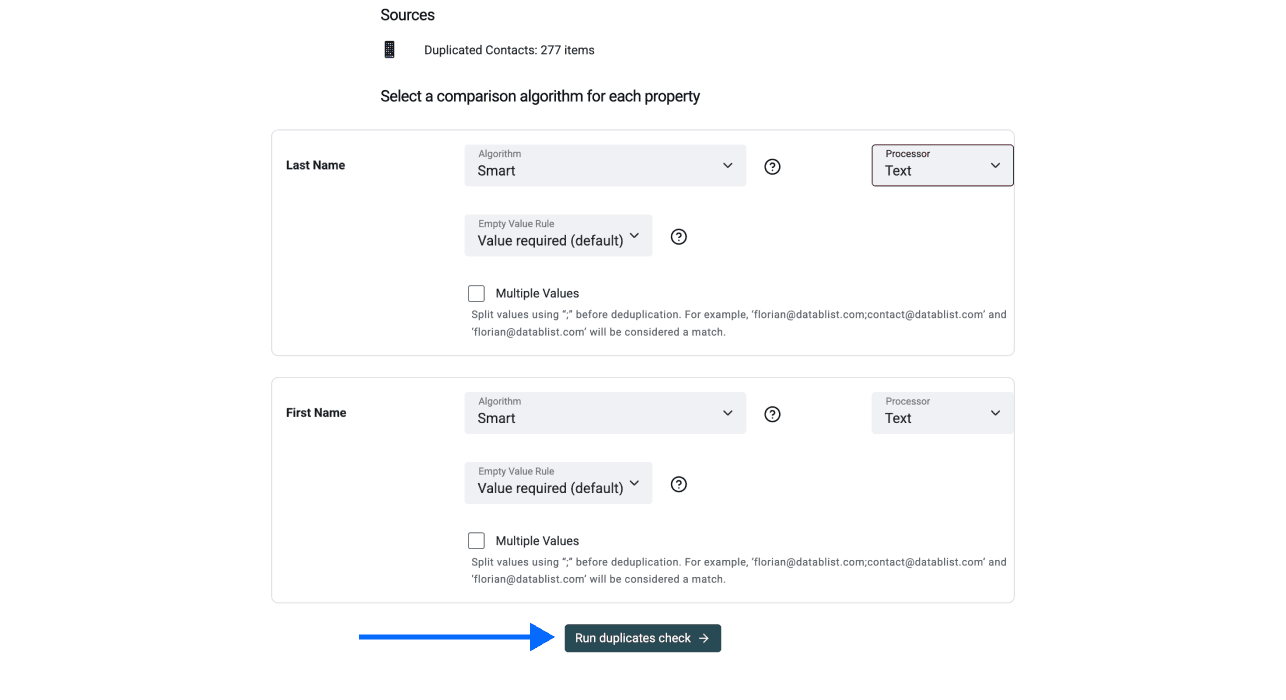
Klicke auf Run duplicates check, sobald Du die Methode ausgewählt hast.
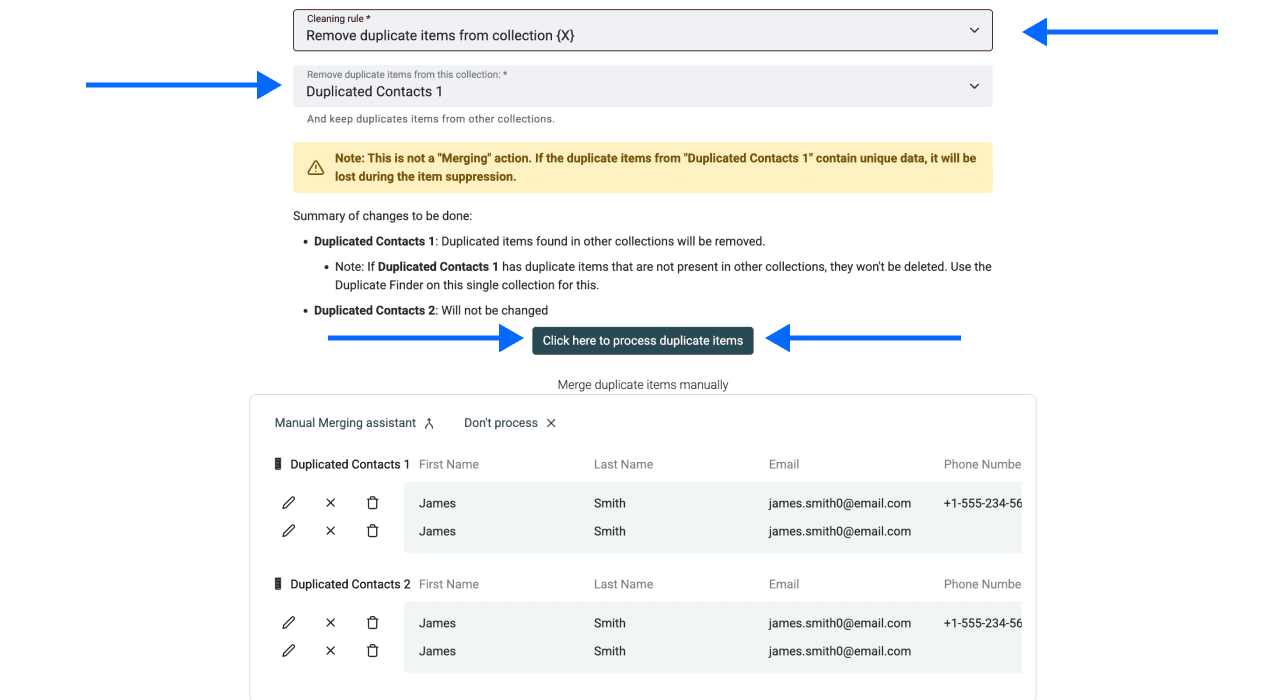
Schritt 6: Cleaning Rules einrichten
Wähle, wie Du mit den Duplikaten umgehen willst:
- Remove duplicate items from collection X: Entfernt Duplikate aus der ausgewählten Datei
- Keep duplicate items only in collection X: Nur verfügbar, wenn Du über 3 oder mehr Collections deduplizierst
Klicke auf Process duplicate items, um weiterzumachen.
Das war’s!
Fazit
Glückwunsch – Du bist durch und weißt jetzt mehr über Deduplication als die meisten jemals brauchen werden. Hier die wichtigsten Takeaways:
- Duplikate sind nicht gleich Duplikate – der Typ entscheidet, wie Du sauber vorgehst
- Das richtige Master Item + die passende Bulk-Action können Dir Stunden an manueller Arbeit sparen
- Während viele Tools Dich auf „Delete“ festnageln, lässt Dich Datablist Duplikate so behandeln, wie Du es wirklich brauchst
Egal ob Du Kontakte aus einem chaotischen CRM zusammenführst, mit AI eigene Logik umsetzt oder neue Leads gegen Deine bestehende Datenbank bereinigst: Du hast jetzt die Tools und das Know-how, um es richtig zu machen.
Frequently Asked Question
Wie entscheidet Datablist, welcher Duplikat-Datensatz bleibt?
Datablist entscheidet das nicht – Du entscheidest. Du wählst eine Master Item Rule (z. B. „Most complete“ oder „Last updated“), die festlegt, welcher Datensatz priorisiert wird. Wenn Deine Logik komplexer ist, nutzt Du AI Editing und definierst eigene Regeln in normalem Englisch (die AI übernimmt den Rest).
Was unterscheidet Datablists Deduplication- und Matching-Suite von anderen Tools?
Drei Dinge: Flexibilität, AI-powered Customization und Preis. Die meisten Tools lassen Dich Duplikate nur löschen. Datablist lässt Dich mergen, updaten, markieren oder löschen – basierend auf Regeln, die Du definierst. AI Editing deckt Logik ab, die andere Tools schlicht nicht können. Und das nächstvergleichbare Produkt kostet oft mehrere tausend Euro pro Jahr (Enterprise Software).
Was, wenn ich meine Duplikate nicht löschen will?
Dann markiere sie. Nutze AI Editing und schreibe z. B. einen Prompt wie: „Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.“ Das ist besonders hilfreich für Compliance oder wenn Du Duplikate erst prüfen willst, bevor Du sie entfernst.
Was, wenn die Master Item Rules nicht zu meinem Use Case passen?
Nutze AI Editing. Statt eine vordefinierte Regel zu wählen, beschreibst Du Deine Logik in normalem Englisch, und Datablists AI erstellt ein Custom Script für Dich. Beispiel: „Keep the record from Salesforce, but use the job title from LinkedIn.“
Kann ich eigene Master Item Rules erstellen?
Ja. Mit Datablists AI Editing kannst Du jede Priorisierungsregel schreiben, die Du beschreiben kannst. Du willst Datensätze behalten, bei denen Spalte A einen bestimmten Wert enthält? Oder nach mehreren Bedingungen priorisieren? Schreib einfach, was Du brauchst – die AI erledigt den Rest.
Was ist ein Unique Identifier bei Deduplication?
Ein Unique Identifier ist die Spalte (oder Kombination aus Spalten), die einen Datensatz eindeutig macht. Wenn Du z. B. „Email“ als Unique Identifier nutzt, gelten zwei Zeilen mit derselben E-Mail als Duplikate – auch wenn andere Felder abweichen. Du kannst auch Spalten kombinieren wie „First Name“ + „Company“ für strengeres Matching.
Wie dedupliziere ich eine Liste mit widersprüchlichen Werten?
Widersprüchliche Duplikate entstehen, wenn zwei Datensätze dieselbe Entität abbilden, aber einzelne Felder unterschiedliche Werte haben. So gehst Du vor: (1) Wähle eine Master Item Rule, um den Gewinner festzulegen, (2) entscheide, ob Du die konfliktierenden Werte kombinierst, droppst oder den Master updatest, (3) nutze Datablists Deduplication-Suite, um das in Bulk umzusetzen. Für komplexe Fälle kannst Du mit AI Editing gezielt einzelne Werte aus unterschiedlichen Datensätzen übernehmen.
Wie kann ich Duplikate markieren, ohne sie zu löschen?
Du kannst Datablists AI Editing Feature in der Deduplication and Matching Suite nutzen. Schreibe einfach einen Prompt wie: „Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.“ So markierst Du Duplikate zur Prüfung, ohne Daten zu verlieren – ideal für Compliance oder Freigabeprozesse.
Wie kann ich doppelte Datensätze updaten, ohne zu löschen?
Duplikate zu updaten heißt, bestimmte Werte im Master-Datensatz durch bessere Daten aus einer anderen Quelle zu ersetzen. Dafür nutzt Du Datablists AI Editing in der Deduplication and Matching Suite. Du beschreibst nur, was passieren soll, z. B.: „Keep records from Source A, but update the job title and company name using values from Source B.“ Die AI wendet Deine Logik auf alle Duplikat-Gruppen an – danach kannst Du die Extras löschen oder markiert behalten.