
Sainsbury's does not have a public product API. That is why most teams trying to scrape Sainsbury's products either pay £2000+ for a freelancer or wire up an Apify scraper that breaks within a few days.
What most don’t know though, there is a third path called AI scraping. It reads the page like a human, so the same setup works on a Sainsbury's category, a brand listing, or a deals page, and survives the layout updates that kill traditional scrapers.
This guide walks through the full process: Why building a custom Sainsbury's product scraper is not worth your money, which Sainsbury's pages give the cleanest data, and a complete step-by-step using Datablist's AI Scraping Agent.
📌 Summary For Those In a Rush
This article shows how to scrape product data from Sainsbury's using Datablist's AI Scraping Agent.
Problem: Sainsbury's has no public product API, off-the-shelf scrapers break within weeks of every layout update, and a custom build costs £2000+ plus ongoing maintenance.
Solution: Use Datablist's AI Scraping Agent to scrape Sainsbury's products with plain English prompts and a single URL.
What You'll Learn:
- Why a custom Sainsbury's scraper is a money pit
- Which Sainsbury's pages return the cleanest data
- A 5-step process to scrape any Sainsbury's category in under 10 minutes
Why Datablist:
- AI scraping reads meaning, not HTML, so Sainsbury's layout updates do not break the run
- Pagination is handled automatically (up to 5,000 pages per run)
- No code, no API keys, just a Sainsbury's URL and a prompt
What This Guide Covers
- Why Building a Custom Sainsbury's Scraper Is Not Worth It
- How To Scrape Sainsbury's Products With Datablist's AI Agent
- Scraping Sainsbury's: The Full Step-by-Step
- Frequently Asked Questions About Scraping Sainsbury's
Building a Custom Sainsbury's Scraper Is a Money Pit
If you have ever considered building your own Sainsbury's scraper, three reasons to reconsider before you spend a penny.
It Is Expensive
A stable Sainsbury's scraper is not a weekend project sainsburys.co.uk loads its product grid dynamically with JavaScript, paginates across hundreds of category pages, and updates its layout often enough that any rule-based scraper needs constant fixing.
This is what most teams try, and where each path falls apart:
- Hire a freelance developer: £2000+ for the first build, plus ongoing fees every time Sainsbury's updates the grid
- Buy a prebuilt Sainsbury's product scraper from Apify or GitHub: works on day one, breaks within a few weeks of the next layout change
- Vibe-code a Puppeteer or Playwright script: Sainsbury's pagination, JavaScript rendering, and inconsistent product cards crack it open fast
If you only need a one-off snapshot, a freelancer might be fine. If you need fresh Sainsbury's data on a recurring basis (price monitoring, FMCG analysis, retail arbitrage), the maintenance cost compounds month after month.
It Is Slow To Build
Even with a strong developer, a clean Sainsbury's scraper takes weeks. They have to map every category page, handle the rendered HTML, write logic for paginated grids, and account for the cases where Sainsbury's returns "N/A" for sale prices or hides products behind age gates.
Datablist's AI Scraping Agent skips that entire build phase. You can paste a Sainsbury's URL and pull structured product data in under 10 minutes. No spec docs, no back-and-forth on edge cases, no waiting for v2.
It Breaks Constantly
This is the real cost Sainsbury's updates its product grid often. Every time the team ships a new category template or moves the price element, your custom Sainsbury’s scraper stops working.
That leaves two options: pay the developer again, or spend your own afternoon debugging.
AI scraping sidesteps this. Because the AI Agent reads page meaning instead of HTML structure, a price stays a price even after Sainsbury's changes the CSS class around it.
💡 The Core Difference
Traditional scrapers follow rules: "find the element with class .product-price and extract the text." AI scrapers follow meaning: "find the product price on this Sainsbury's page."
That is why the same setup that works on Sainsbury's today still works after Sainsbury's reorganises the grid next month, and why it transfers cleanly to Tesco, Morrisons, and Asda without per-site code.
How To Scrape Sainsbury's Products With Datablist's AI Agent
Before the step-by-step, let me briefly explain what the AI Scraping Agent actually is, which Sainsbury's pages give clean results, what data you can pull, and where the limits sit.
What Is Datablist's AI Scraping Agent?
Datablist is a workflow automation platform for building lead lists, enriching data, and running scraping workflows. Inside Datablist sit over 60 different sources and enrichments, and the AI Scraping Agent is the one you use to extract product data from a retailer's website.
The agent works by combining three things: A target URL, a prompt that describes what to extract, and a language model that reads the page the way you would.
For scraping Sainsbury's, you do not even need to write the prompt yourself. Datablist comes with a Retail Product Scraper template that pre-loads the prompt and the output columns. You paste a Sainsbury's URL, the template handles the rest.
Three things specifically about how the agent handles Sainsbury's:
- OpenAI GPT 4.1 mini by default, the best price-to-performance LLM for AI scraping
- Render HTML support, mandatory for Sainsbury's since the product grid loads via JavaScript
- Automatic pagination across up to 5,000 pages per run
This is also why the setup transfers without modification to other UK supermarkets. The same agent, same template, and same settings work on Tesco, Morrisons, Asda, Waitrose, and Aldi. Only the URL changes.
The Most Important Rule: Brand And Category Pages Only
Always scrape Sainsbury's category or brand pages, never the homepage or an "all products" view. Big lists overflow the AI Agent's context window, the run stops mid-way with no way to resume, and the credits are wasted.
What the AI Agent handles cleanly on Sainsbury's:
- ✅ Category pages on sainsburys.co.uk/gol-ui/groceries/...
- ✅ Brand pages (specific manufacturer listings)
- ✅ Deals or offers pages
What to avoid:
- ❌ The Sainsbury's homepage
- ❌ "All products" or full-site search results
- ❌ Anything that loads thousands of items into one infinite scroll
What Data You Can Pull From Sainsbury's
A single Sainsbury's run can extract every product data point you need for price monitoring, competitive research, or data enrichment into an existing catalog:
- Product Name: full product title as displayed on the Sainsbury's website
- Product URL: direct link to the product page on sainsburys.co.uk
- Brand Name: the manufacturer behind the product
- Price: current GBP price, including the £ symbol
- Sale Price: discounted price if a Sainsbury's promotion is active, "N/A" if no offer is running
- Product Category: the aisle or department the product sits in
- Availability: in stock, out of stock, or limited
- Rating: customer rating where Sainsbury's shows it
- Image URL: direct link to the main product image
- SKU: the internal Sainsbury's product ID
Pick the outputs you actually want before the run, so the export only contains the columns you'll use.
Scraping Sainsbury's: The Step-by-Step
The full Sainsbury's scraping setup takes 5 steps. Before starting, make sure you have:
- A Sainsbury's category or brand URL (not the homepage)
- A rough idea of which product fields you actually need
Step 1: Sign Up And Create a Collection
First, sign up for Datablist.com.

Then, create a New Collection.
Step 2: Navigate To The AI Scraping Agent
- Click on See all sources
- Scroll down, and select AI Scraping Agent (Site Scraper).
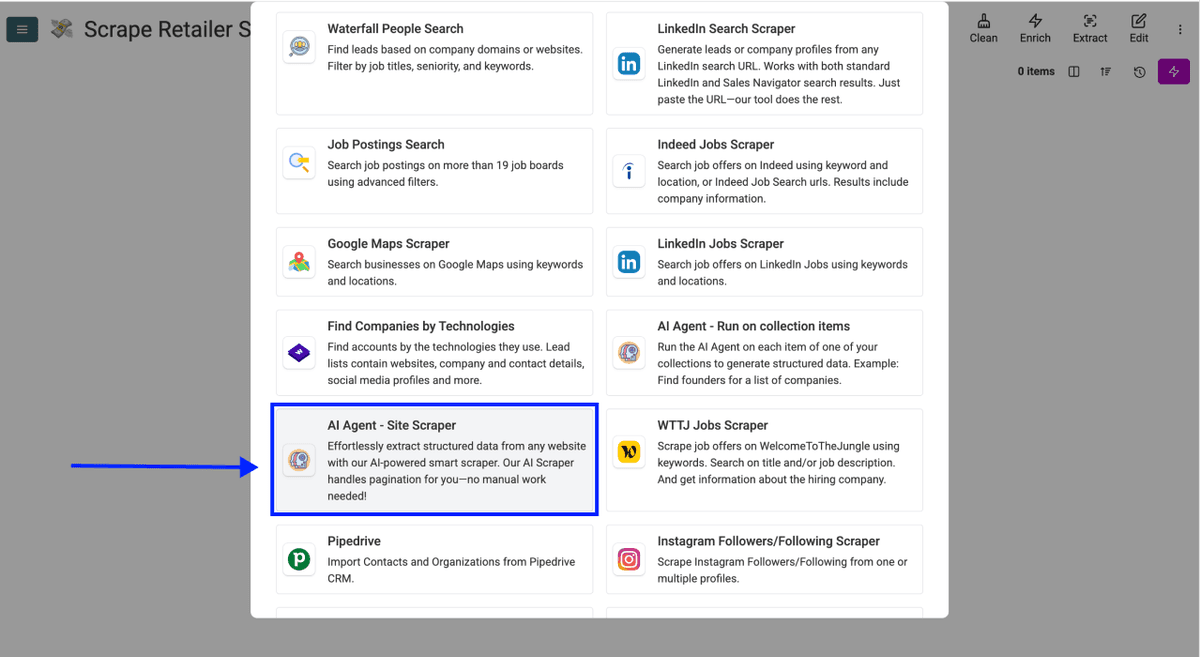
You should now see the source configuration interface, which looks like this:
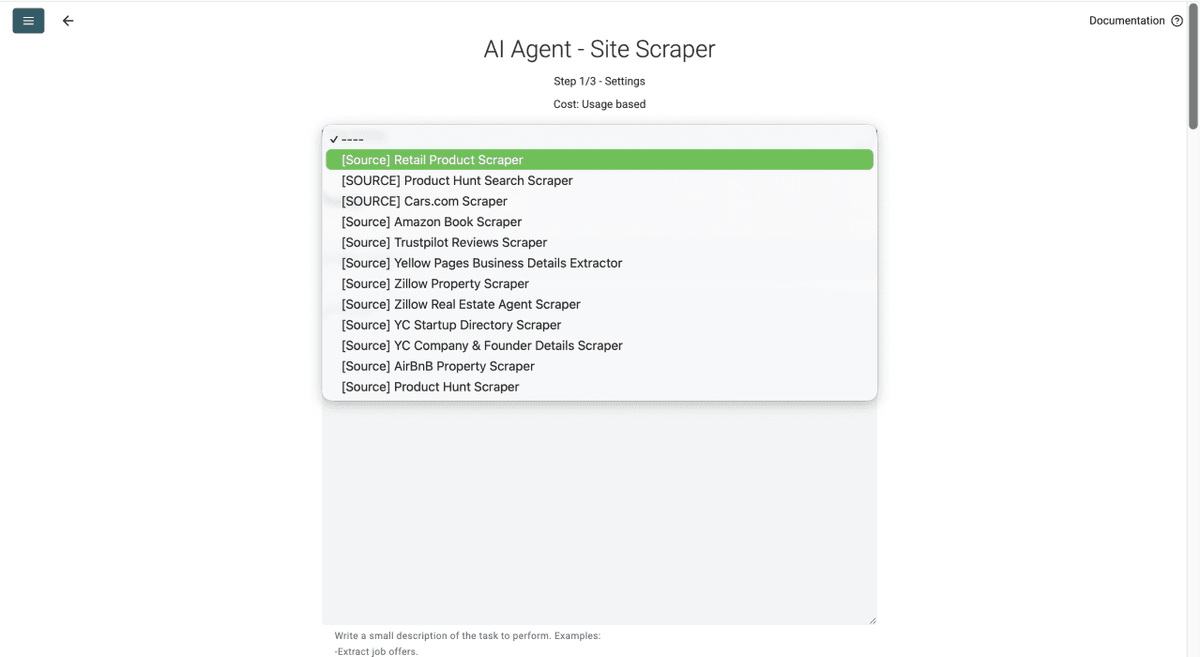
Step 3: Select The Retail Product Scraper Template And Paste a Sainsbury's URL
- Click on the Template Drop-Down and select "Retail Product Scraper"
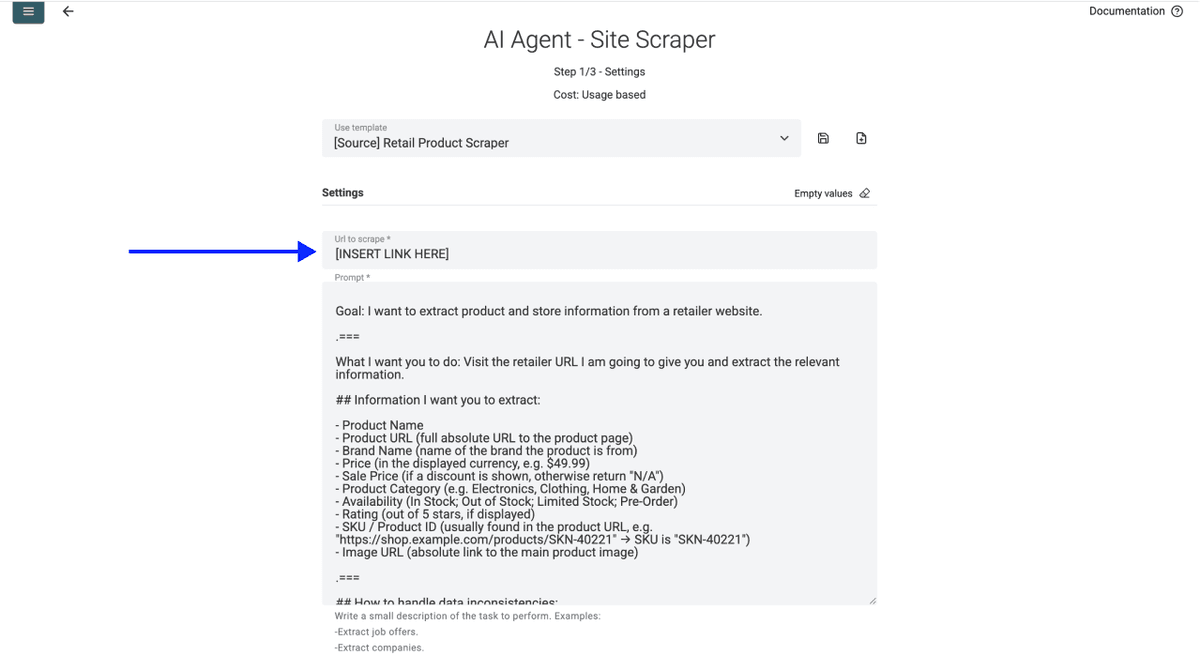
- Paste your Sainsbury's category URL into the URL field, e.g.
https://www.sainsburys.co.uk/gol-ui/groceries/frozen/fish-and-seafood/c:1019924/opt/page:2
❗️ Brand And Category Pages Only (Reminder)
Never paste the Sainsbury's homepage or an "all products" URL. Big lists blow past the AI Agent's context window. Scrape Sainsbury's one category at a time.
- Set the number of pages to scrape (Sainsbury's typically displays around 60 products per page, so a 200-product category needs roughly 3 to 4 pages)
- Scroll down and click on Continue
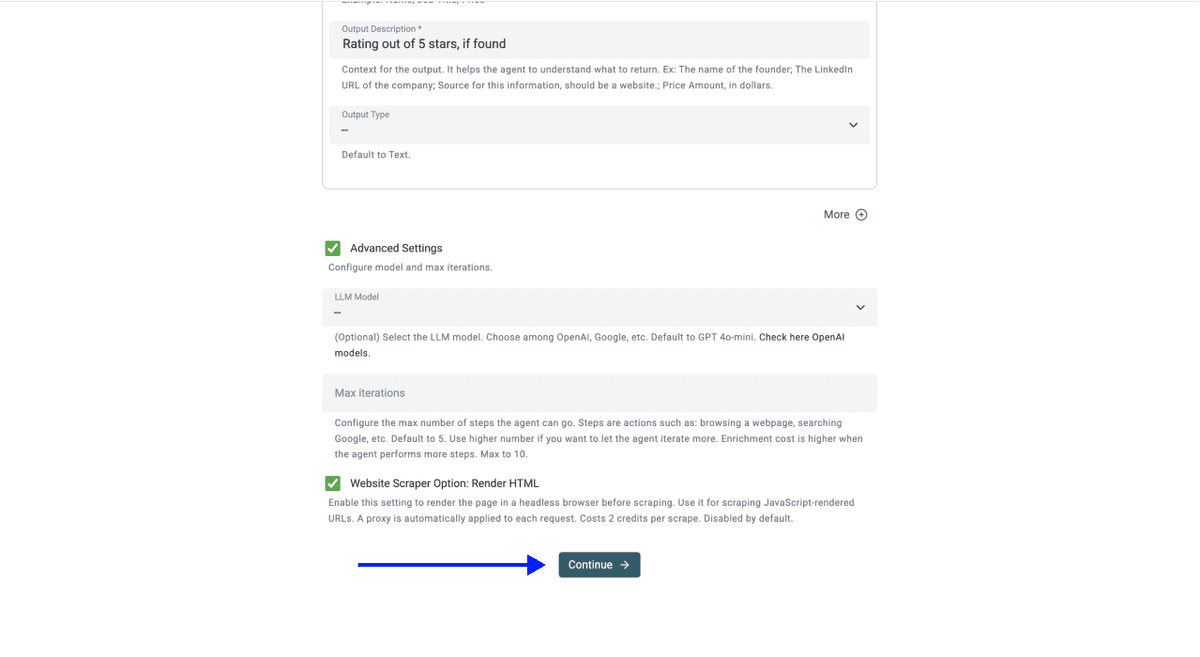
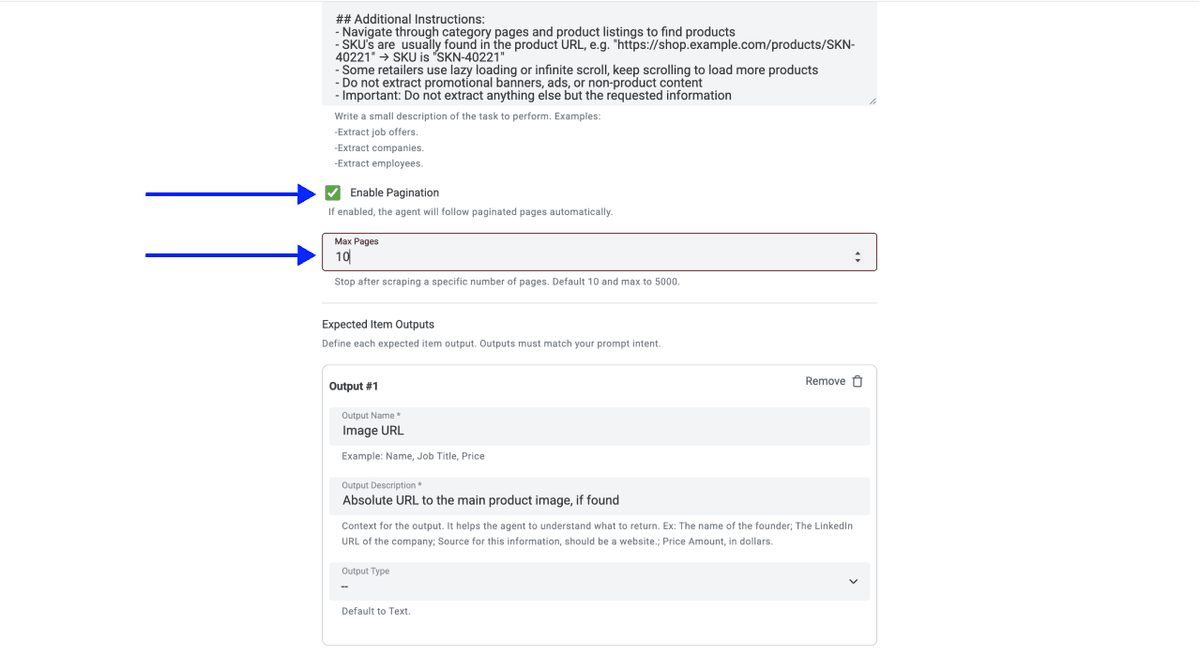
💡 Check Your Advanced Settings Before Clicking Continue
Make sure these are enabled:
- LLM: OpenAI GPT 4.1 mini (best performance-to-price ratio)
- Max Iterations: 10
- Website Scraper Option: Render HTML (critical for Sainsbury's, since the site loads its product grid dynamically with JavaScript)
Step 4: Configure Outputs
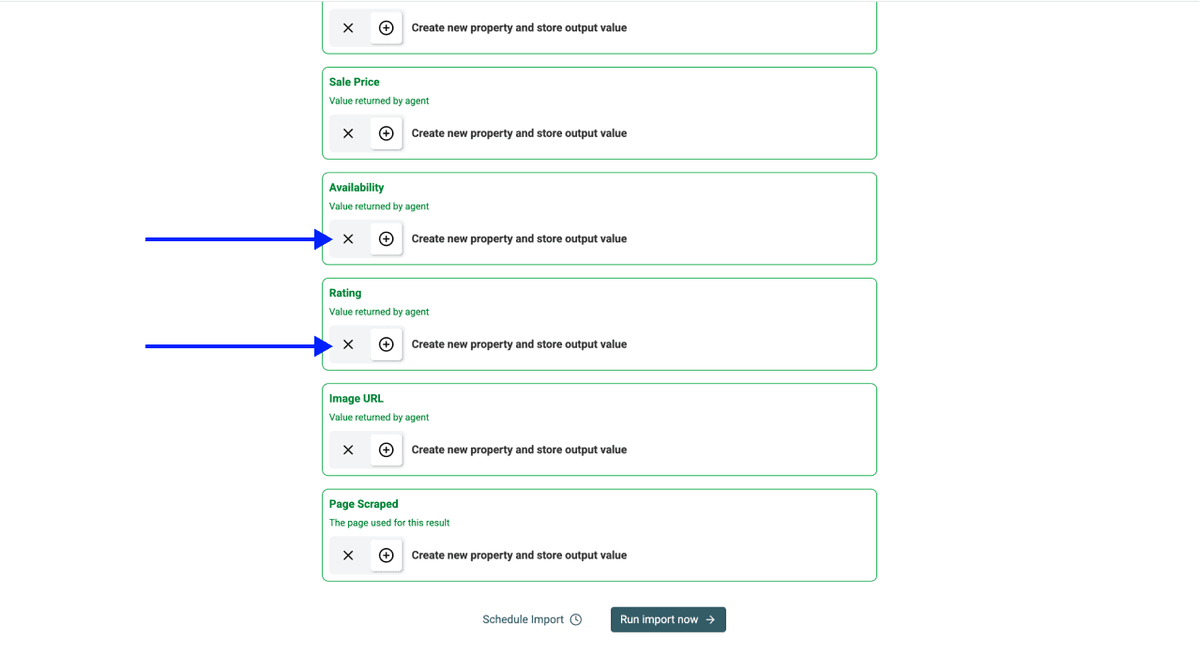
Datablist creates the output properties automatically.
Click the X Icons to drop any outputs you do not need (e.g. remove Rating if you are only doing Sainsbury's price monitoring).
Step 5: Run
Once your outputs are set, click on Run Import Now to start the Sainsbury's scrape.
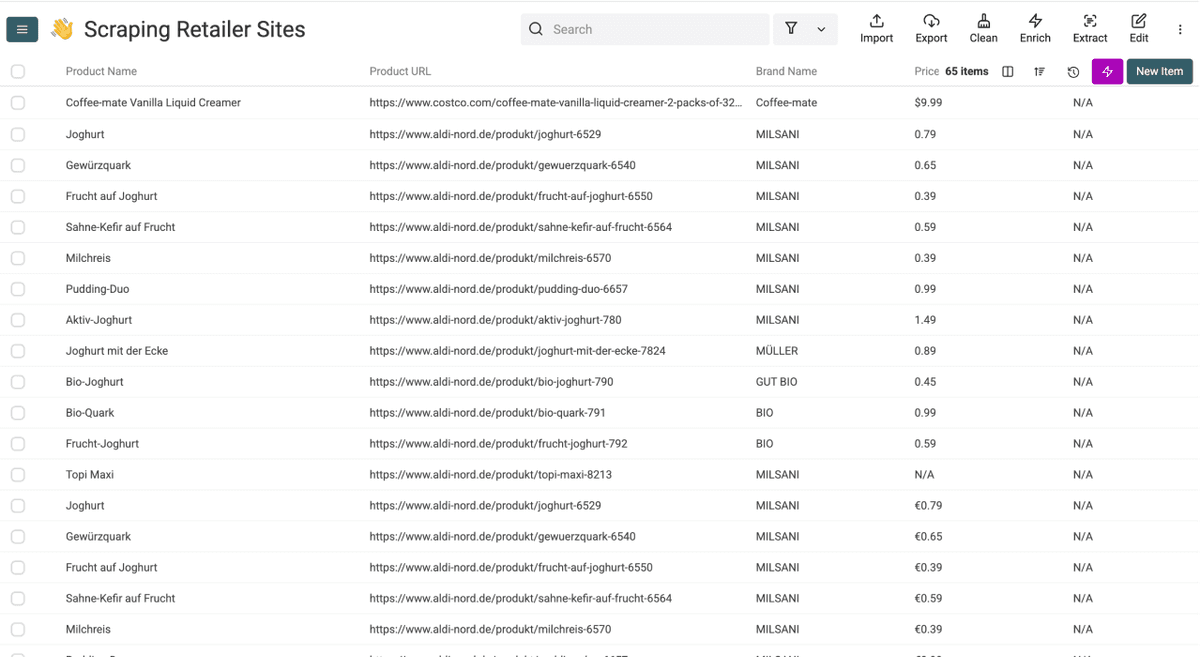
After a few minutes, your Sainsbury's results will look like this. From here, Datablist's workflow automation features can clean, dedupe, and export the data.
💡 Avoid Duplicates on Repeat Sainsbury's Runs
If you plan to scrape the same Sainsbury's category again later:
- Pick a unique identifier column (Product URL works best)
- Click the column header → Rename - Settings - Delete
- Check: Do not allow duplicate values
- Save Property
If you also pull data from Tesco, Morrisons, and Asda into the same file, our guide on removing duplicates from CSV files covers cross-retailer dedupe.
Datablist’s AI Agent Also Scrapes Other Retailer Websites
The Sainsbury's setup is not Sainsbury's-specific. The same AI Scraping Agent and the same Retail Product Scraper template work on every UK supermarket we have tried. Only the URL changes.
If you also pull product data from a similar retailer, check the step-by-step guides below:
Your Key Takeaways
- A custom Sainsbury's product scraper is a money pit. Build cost lands at £2000+, ongoing maintenance is on top, and Sainsbury's layout updates will break it on a regular cadence.
- AI scraping reads meaning, not HTML. That is why the same setup keeps scraping Sainsbury's products even after the grid changes, and why it transfers to Tesco, Morrisons, and Asda without per-site code.
- Always scrape brand or category pages, never the homepage. Big lists blow past the agent's context window and waste the run.
- The full setup takes under 5 minutes. Template, URL, outputs, run.
Frequently Asked Questions About Scraping Sainsbury's
How Much Does It Cost To Scrape Sainsbury's Products?
Datablist's AI Agent works based on a usage-based credit system. Cost per Sainsbury's run depends on how many products and pages the agent processes. Datablist plans start at $25/month with 5,000 free credits included, and top-up packs start at $20 for 20,000 credits with bulk discounts up to 35% on larger packages.
How Long Does It Take To Scrape The Full Sainsbury's Catalog?
Most Sainsbury's category pages with 50 to 200 products are scraped in 5 to 10 minutes. Larger runs across multiple paginated categories (500+ products) can take 10 to 20 minutes. First-time setup adds 2 to 3 minutes.
Why Should I Scrape a Sainsbury's Category Page Instead of "All Products"?
A Sainsbury's "all products" view loads thousands of items into one rendered page. That blows past the AI Agent's context window, the agent stops mid-run, and there is no resume option, so the partial run is wasted. Category and brand pages stay inside the safe range, scrape cleanly, and merge into one collection later if you need full coverage.
Can I Scrape Sainsbury's Sale Prices and Promotions?
Yes. The Retail Product Scraper template includes a Sale Price output. When a Sainsbury's promotion is active, the discounted price comes through. When no offer is running, the column returns "N/A", which is actually useful for filtering by promotion status across categories.
Is Scraping Sainsbury's Legal in the UK?
Scraping publicly visible Sainsbury's product data (names, prices, availability) is generally lawful in the UK under the same principles that apply to any public web data. You should still review Sainsbury's' terms of service, avoid scraping personal data, and stay within reasonable request volumes. For commercial use, run it past your legal team.
Does Sainsbury's Block Scrapers?
Sainsbury's' anti-bot protections are mild compared with Walmart or Costco. Most Sainsbury's runs through Datablist succeed on the first attempt, especially when Render HTML is enabled. If a category page does not return data, lower the page count and retry, or split the scrape across more specific subcategories.
Can I Schedule Repeat Scrapes for Sainsbury's Price Monitoring?
Yes. Datablist's workflow automation features let you set up recurring runs. Pair it with a unique identifier column (Product URL works best) and the duplicate-prevention setting, so each repeat Sainsbury's run only adds new products instead of duplicating the existing ones.
Can I Scrape Sainsbury's Without Coding Skills?
None needed. The whole flow is no-code: Select the Retail Product Scraper template, paste a Sainsbury's URL, choose your outputs, and hit run. If you can write a sentence, you can scrape Sainsbury's with Datablist.
What Sainsbury's Categories Work Best for Scraping?
Standard grocery categories on https://www.sainsburys.co.uk/gol-ui/groceries](https://www.sainsburys.co.uk/gol-ui/groceries return the cleanest data: fresh, frozen, bakery, drinks, household. Brand pages also work well. Promo or "Last chance" pages can be slightly noisier because product cards mix formats, but the AI Agent still pulls usable data from them.
Can The AI Agent Handle Sainsbury's Pagination Automatically?
Yes. With Enable Pagination turned on, the AI Agent walks every page in the Sainsbury's category up to your configured limit (default 10, max 5,000). For a 240-product Sainsbury's category that displays 24 items per page, set pagination to 10 and the agent picks up the full list.
What Is AI Scraping?
AI scraping is a method of pulling structured data from websites using a language model instead of fixed HTML rules. The agent visits a page, reads the content, and returns the fields you asked for in plain English. That is exactly what makes it resilient on sites like Sainsbury's that update their layouts often.
What Is the Difference Between AI Scraping and Traditional Web Scraping?
Traditional scrapers follow fixed rules (CSS selectors, XPath). When the site changes, the rules break. AI scraping reads page meaning, so a Sainsbury's price stays a Sainsbury's price even after the markup changes. That is why the same Datablist setup works across Tesco, Sainsbury's, Morrisons, and Asda without per-site code.