Step-by-step guide
Step 1: Load your CSV or Excel file on Datablist
Create a free account and import your data file. Datablist is a powerful CSV editor. Perfect for opening large CSV files or Excel files with a list of items.
Create a new collection and import your file.
Step 2: Select the "Bulk Scraper" enrichment
Click on the "Enrich" button, and search for "Bulk Scraper".
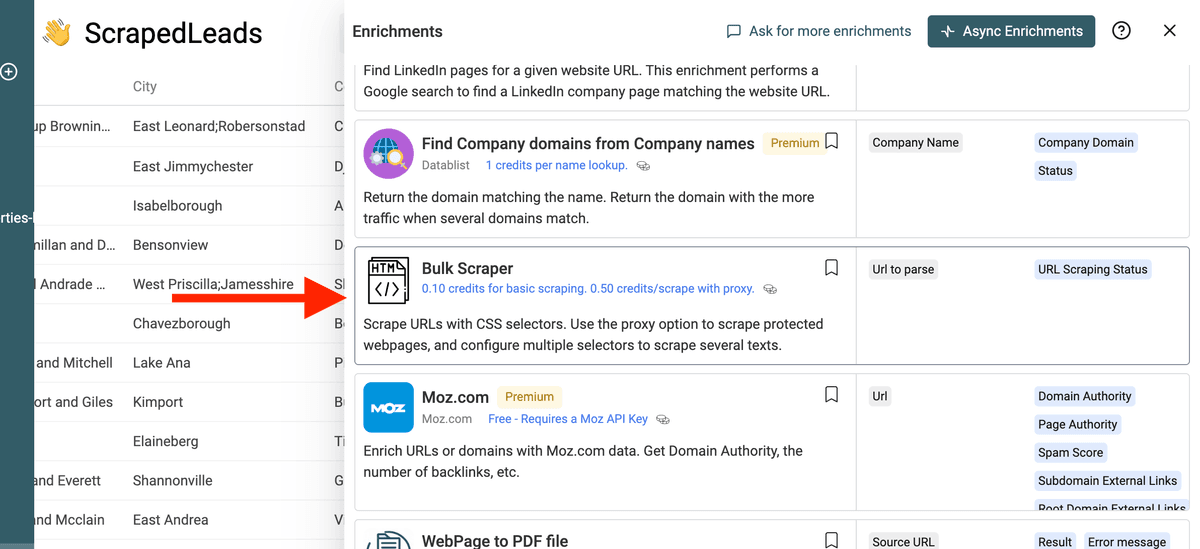
Configure CSS Selectors
The Bulk Scraper uses two ways to extract data from the HTML page: CSS Selectors and Regular Expressions.
CSS selectors allow you to target specific parts of an HTML document to extract information.
A CSS selector is defined with the following information:
- CSS Selector - The CSS path to the HTML element. Read this guide to learn how to write CSS Selector.
- CSS Selector Content - Data to extract for the HTML element.
- InnerText - Extract the text inside the HTML element. If the HTML element contains nested HTML elements, their texts are also extracted.
- HTML - Extract the outer HTML code for the HTML element
- Attribute - Extract a specific attribute text from the HTML element.
- Selector Attribute - Available when the
CSS Selector Contentis set onAttribute. Define the attribute to extract. Example: href, rel, title.
Note: When several elements match a CSS selector, all the results are returned concatenated with a semicolon (
;)
If you need one scraped link or value per row after export, run the file through the CSV Rows Splitter.
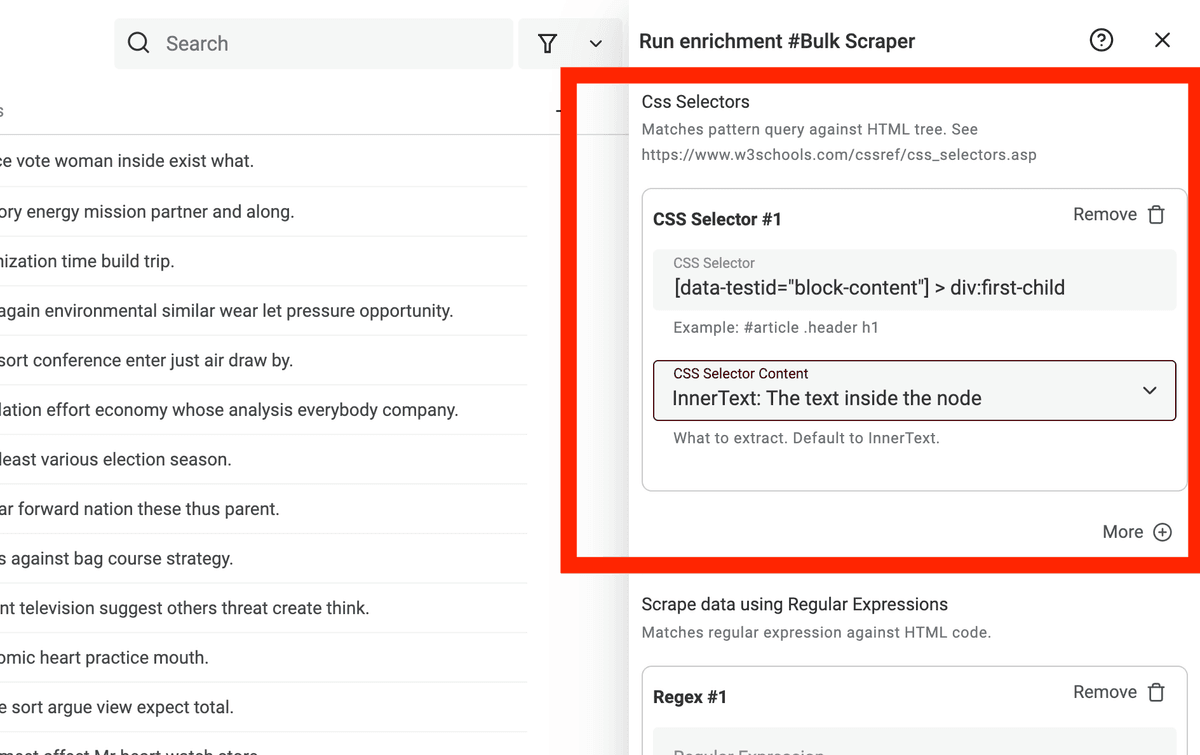
Selector Attribute field available on CSS Selector Content: Attribute.
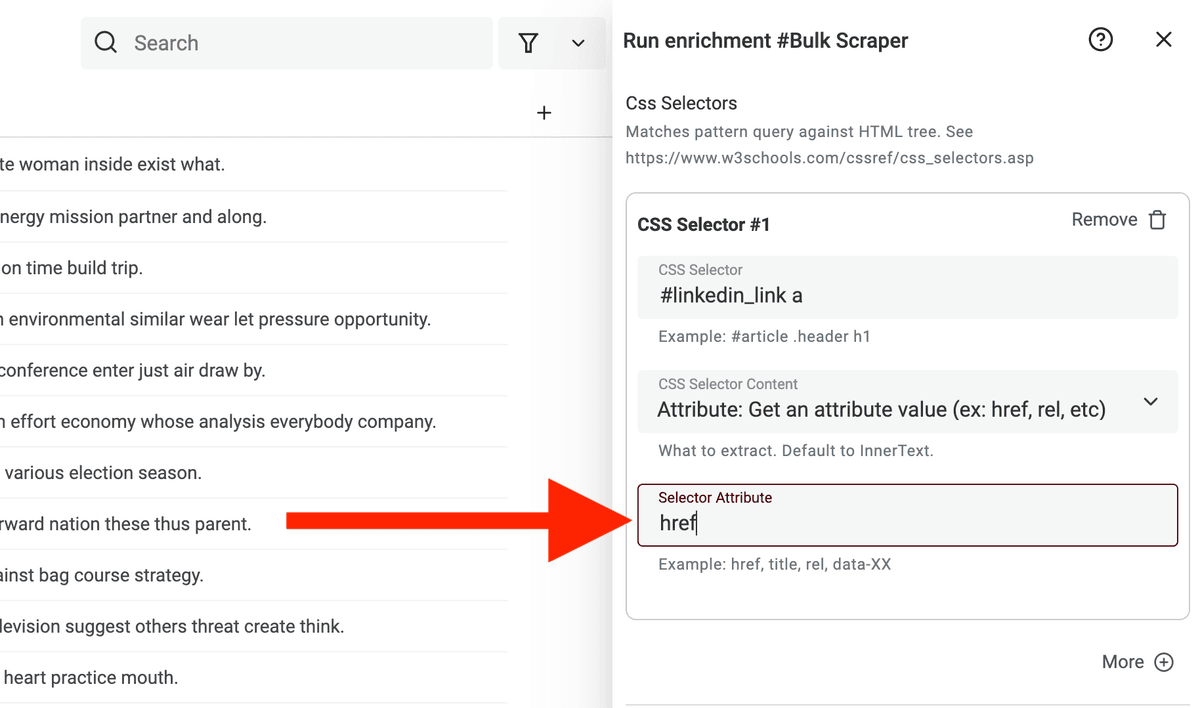
Examples of CSS Selectors
To learn how to write CSS Selector paths, please read this guide.
Getting the text of an HTML element.
<div class="section product-data">
<div class="product-name">New Phone</div>
</div>
The CSS selector would be .section.product-data .product-name with the CSS Selector Content to InnerText.
Getting the text of the first div after a custom HTML attribute.
<div data-testid="block-content">
<div>Info To Scrape</div>
<div>Useless Info</div>
<div>Useless Info</div>
</div>
The CSS selector would be [data-testid="block-content"] > div:first-child with the CSS Selector Content to InnerText.
Getting the URLs for links:
<div class="social-media">
<a href="https://fr.linkedin.com/company/datablist">Linkedin</a>
<a href="https://www.twitter.com/datablist">Twitter</a>
</div>
The CSS selector would be .social-media with the CSS Selector Content to Attribute and the Attribute to href.
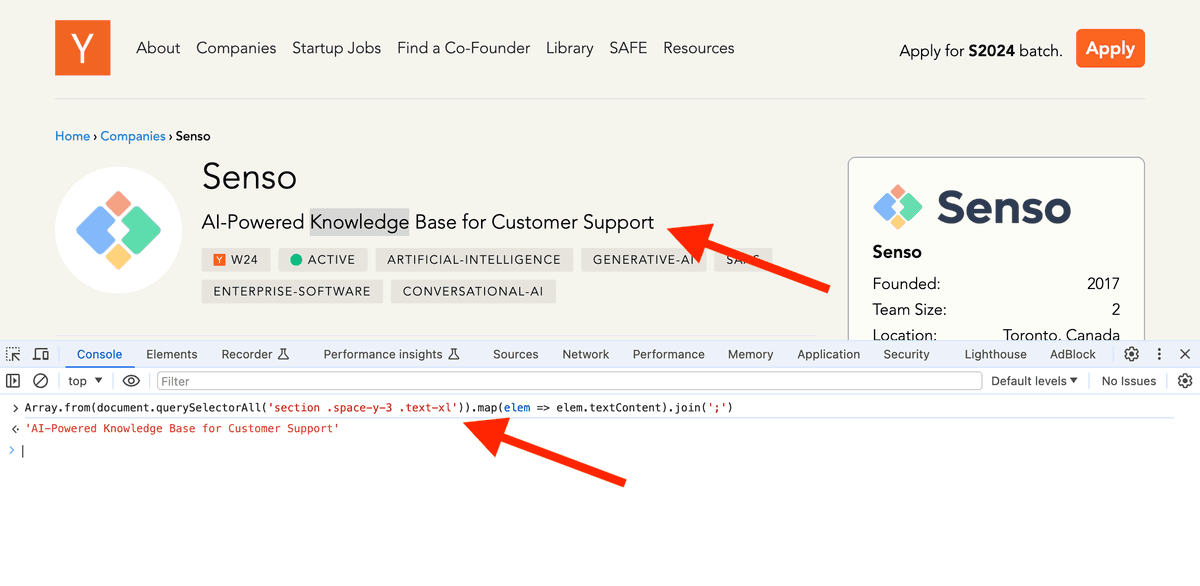
How to test CSS Selectors
An easy way to test your CSS Selectors before running them in bulk is to use your browser console.
To test for InnerText:
Array.from(document.querySelectorAll('{css-selector-path}')).map(elem => elem.textContent).join(';')
To test for HTML:
Array.from(document.querySelectorAll('{css-selector-path}')).map(elem => elem.outerHTML).join(';')
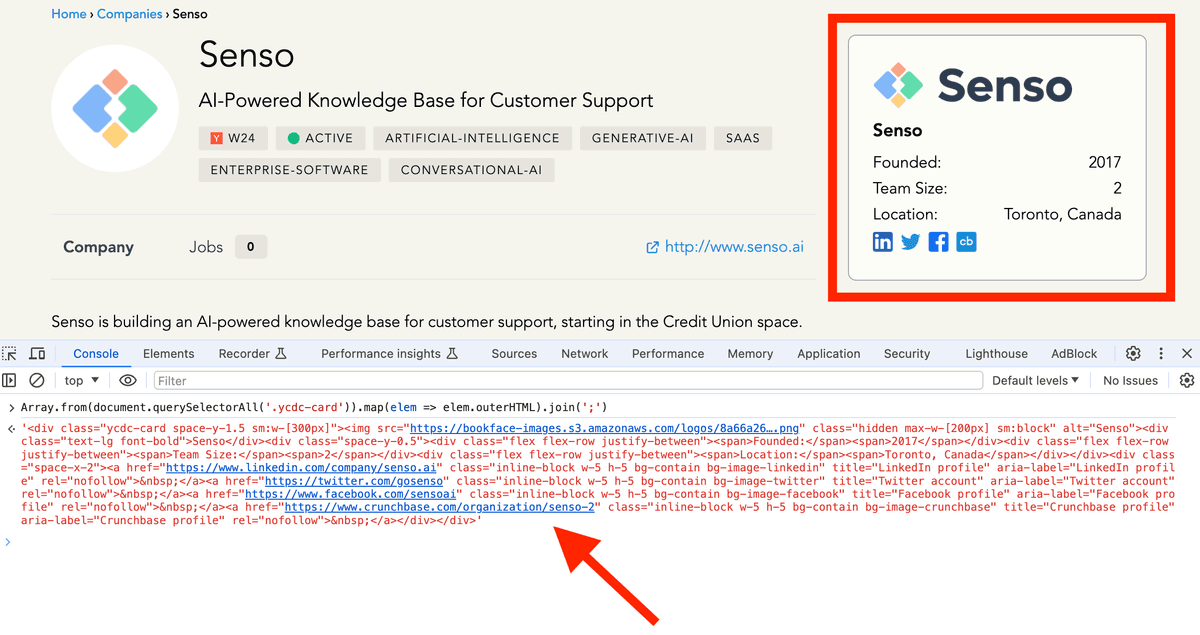
To test for the content of an Attribute:
Array.from(document.querySelectorAll('{css-selector-path}')).map(elem => elem.getAttribute('{attribute}')).join(';')
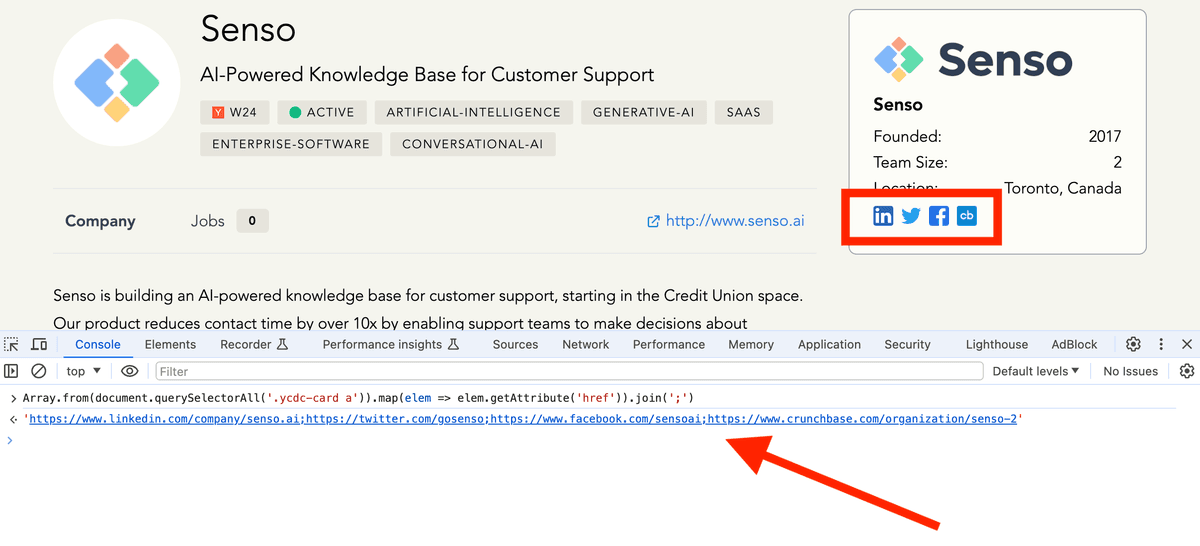
If you need help writing your CSS Selectors, please contact us.
Configure Regular Expressions
The second way to scrape data from several URLs is to use regular expressions. The bulk scraper matches the RegEx against the HTML code source.
If the pattern contains capturing groups, they are returned. And if there are no groups, the scraper returns the strings matching the whole pattern.
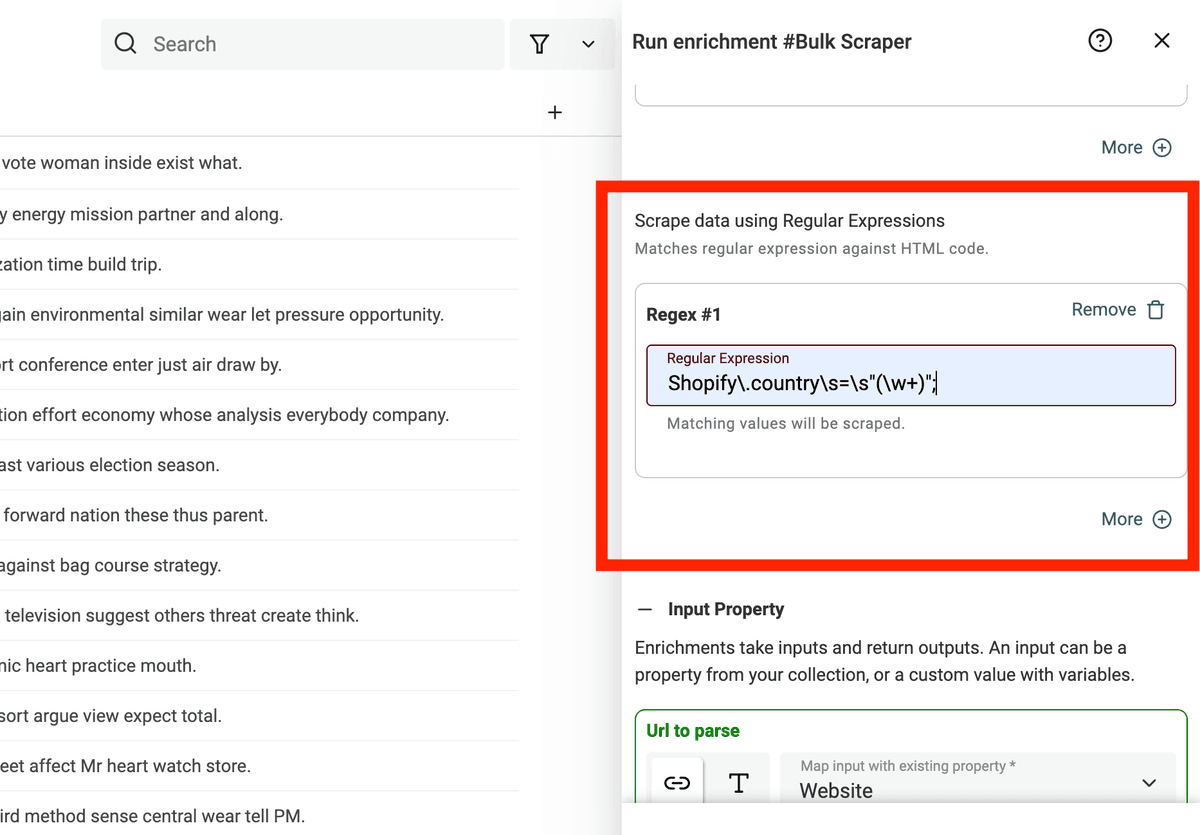
Capturing groups or pattern-matching
When writing a Regex, you can add a capturing group using parenthesis. When a capturing group is defined, the bulk scraper will return only the group text.
For example, in the HTML code:
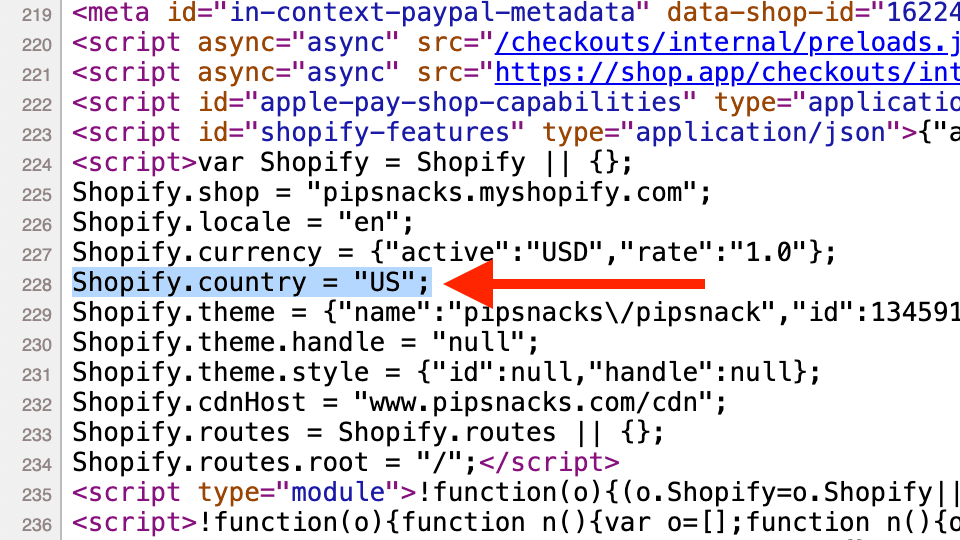
To capture only the "US" text from the Shopify.country line, you would write:
Shopify\.country\s=\s"(\w+)";
Notice the parenthesis in (\w+).
To capture the whole line, you would write:
Shopify\.country\s=\s"\w+";
Notice I removed the parenthesis.
Use Cases
Lead Generation
Bulk scraping allows you to enrich URLs from various sources, such as directories, social media platforms, forums, etc.. Using CSS Selector, bulk scraping lets you get structured information from HTML pages.
Price Monitoring
E-commerce businesses can use URL scraping to monitor competitor websites and track product prices, discounts, and promotions. This information can be used for competitive intelligence and pricing strategies to stay competitive in the market.
Job Board Scraping
Job boards often contain valuable job postings information. Scraping URLs from job boards allows businesses to aggregate job postings automatically, providing valuable insights into hiring trends, job requirements, and competitor recruitment strategies.
Best Inputs for the Bulk Scraper
Use URLs that share a similar page structure. CSS selectors and regular expressions work best when the same fields appear in the same part of each page.
Good inputs include:
- Product pages from one ecommerce site
- Job pages from one job board
- Directory profile pages
- Article pages with the same template
- Store locator pages with repeated fields
If your URLs come from many unrelated websites, use Smart Scraper or AI Agent instead.
FAQ
Can I scrape a CSV list of URLs with CSS selectors?
Yes. Import your CSV or Excel file, map the URL column, configure CSS selectors, and run the Bulk Scraper on each row.
Can I use regular expressions instead of CSS selectors?
Yes. The enrichment supports CSS selectors, regular expressions, or both. Regex is useful when the value follows a text pattern, such as an ID, price, email, or code.
What pages work best with this scraper?
Pages with the same structure work best. Use it for product pages, job postings, directory profiles, and other templated pages.
Should I test selectors first?
Yes. Test selectors on a few URLs before processing a large list. Small selector changes can affect every row.